
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
# 动态规划:单词拆分题目链接:https://leetcode-cn.com/problems/word-break/
给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1: 输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
示例 2: 输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。 注意你可以重复使用字典中的单词。
示例 3: 输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
看到这道题目的时候,大家应该回想起我们之前讲解回溯法专题的时候,讲过的一道题目回溯算法:分割回文串,就是枚举字符串的所有分割情况。
回溯算法:分割回文串:是枚举分割后的所有子串,判断是否回文。
本道是枚举分割所有字符串,判断是否在字典里出现过。
那么这里我也给出回溯法C++代码:
class Solution {
private:
bool backtracking (const string& s, const unordered_set<string>& wordSet, int startIndex) {
if (startIndex >= s.size()) {
return true;
}
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, i + 1)) {
return true;
}
}
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
return backtracking(s, wordSet, 0);
}
};- 时间复杂度:O(2^n),因为每一个单词都有两个状态,切割和不切割
- 空间复杂度:O(n),算法递归系统调用栈的空间
那么以上代码很明显要超时了,超时的数据如下:
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab"
["a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa","aaaaaaaaa","aaaaaaaaaa"]
递归的过程中有很多重复计算,可以使用数组保存一下递归过程中计算的结果。
这个叫做记忆化递归,这种方法我们之前已经提过很多次了。
使用memory数组保存每次计算的以startIndex起始的计算结果,如果memory[startIndex]里已经被赋值了,直接用memory[startIndex]的结果。
C++代码如下:
class Solution {
private:
bool backtracking (const string& s,
const unordered_set<string>& wordSet,
vector<int>& memory,
int startIndex) {
if (startIndex >= s.size()) {
return true;
}
// 如果memory[startIndex]不是初始值了,直接使用memory[startIndex]的结果
if (memory[startIndex] != -1) return memory[startIndex];
for (int i = startIndex; i < s.size(); i++) {
string word = s.substr(startIndex, i - startIndex + 1);
if (wordSet.find(word) != wordSet.end() && backtracking(s, wordSet, memory, i + 1)) {
memory[startIndex] = 1; // 记录以startIndex开始的子串是可以被拆分的
return true;
}
}
memory[startIndex] = 0; // 记录以startIndex开始的子串是不可以被拆分的
return false;
}
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<int> memory(s.size(), -1); // -1 表示初始化状态
return backtracking(s, wordSet, memory, 0);
}
};这个时间复杂度其实也是:O(2^n)。只不过对于上面那个超时测试用例优化效果特别明显。
这个代码就可以AC了,当然回溯算法不是本题的主菜,背包才是!
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。
拆分时可以重复使用字典中的单词,说明就是一个完全背包!
动规五部曲分析如下:
- 确定dp数组以及下标的含义
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
- 确定递推公式
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
- dp数组如何初始化
从递归公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递归的根基,dp[0]一定要为true,否则递归下去后面都都是false了。
那么dp[0]有没有意义呢?
dp[0]表示如果字符串为空的话,说明出现在字典里。
但题目中说了“给定一个非空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。
下标非0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为一个或多个在字典中出现的单词。
- 确定遍历顺序
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
还要讨论两层for循环的前后循序。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
对这个结论还有疑问的同学可以看这篇本周小结!(动态规划系列五),这篇本周小节中,我做了如下总结:
求组合数:动态规划:518.零钱兑换II 求排列数:动态规划:377. 组合总和 Ⅳ、动态规划:70. 爬楼梯进阶版(完全背包) 求最小数:动态规划:322. 零钱兑换、动态规划:279.完全平方数
本题最终要求的是是否都出现过,所以对出现单词集合里的元素是组合还是排列,并不在意!
那么本题使用求排列的方式,还是求组合的方式都可以。
即:外层for循环遍历物品,内层for遍历背包 或者 外层for遍历背包,内层for循环遍历物品 都是可以的。
但本题还有特殊性,因为是要求子串,最好是遍历背包放在外循环,将遍历物品放在内循环。
如果要是外层for循环遍历物品,内层for遍历背包,就需要把所有的子串都预先放在一个容器里。(如果不理解的话,可以自己尝试这么写一写就理解了)
所以最终我选择的遍历顺序为:遍历背包放在外循环,将遍历物品放在内循环。内循环从前到后。
- 举例推导dp[i]
以输入: s = "leetcode", wordDict = ["leet", "code"]为例,dp状态如图:
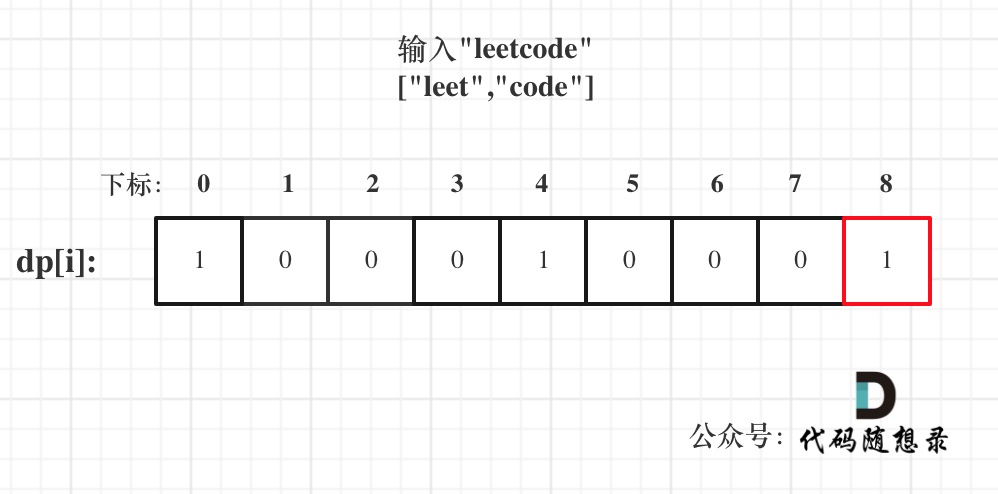
dp[s.size()]就是最终结果。
动规五部曲分析完毕,C++代码如下:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
unordered_set<string> wordSet(wordDict.begin(), wordDict.end());
vector<bool> dp(s.size() + 1, false);
dp[0] = true;
for (int i = 1; i <= s.size(); i++) { // 遍历背包
for (int j = 0; j < i; j++) { // 遍历物品
string word = s.substr(j, i - j); //substr(起始位置,截取的个数)
if (wordSet.find(word) != wordSet.end() && dp[j]) {
dp[i] = true;
}
}
}
return dp[s.size()];
}
};- 时间复杂度:O(n^3),因为substr返回子串的副本是O(n)的复杂度(这里的n是substring的长度)
- 空间复杂度:O(n)
本题和我们之前讲解回溯专题的回溯算法:分割回文串非常像,所以我也给出了对应的回溯解法。
稍加分析,便可知道本题是完全背包,而且是求能否组成背包,所以遍历顺序理论上来讲 两层for循环谁先谁后都可以!
但因为分割子串的特殊性,遍历背包放在外循环,将遍历物品放在内循环更方便一些。
本题其实递推公式都不是重点,遍历顺序才是重点,如果我直接把代码贴出来,估计同学们也会想两个for循环的顺序理所当然就是这样,甚至都不会想为什么遍历背包的for循环为什么在外层。
不分析透彻不是Carl的风格啊,哈哈
Java:
Python:
Go:
