题目四
自动生成多模态的指令微调数据
基于原始python版本,仅需要额外装openai和tqdm两个库即可
pip install openai tqdm准备好mscoco的caption文件,或者使用github库自带的mscoco2017文件
python generate.py --captiondata "captions_val2017.json" --output 'instructons.json'可选的参数有:
--num_processings指定进程数,默认10--num_per_slice指定每个进程每次处理多少数据,默认128--num_icls指定in-context阶段采样的上下文数量。
-
输入一个包含N个图片captions的json文件,调用gpt-3.5-turbo生成相应QA对儿,构造instructions数据,输出JSON文件
-
成功构造基于mscoco2017数据集captions的instruction QA数据
-
能够多进程的向Openai发起请求并构造instructions
-
能够处理网络中断等异常情况
-
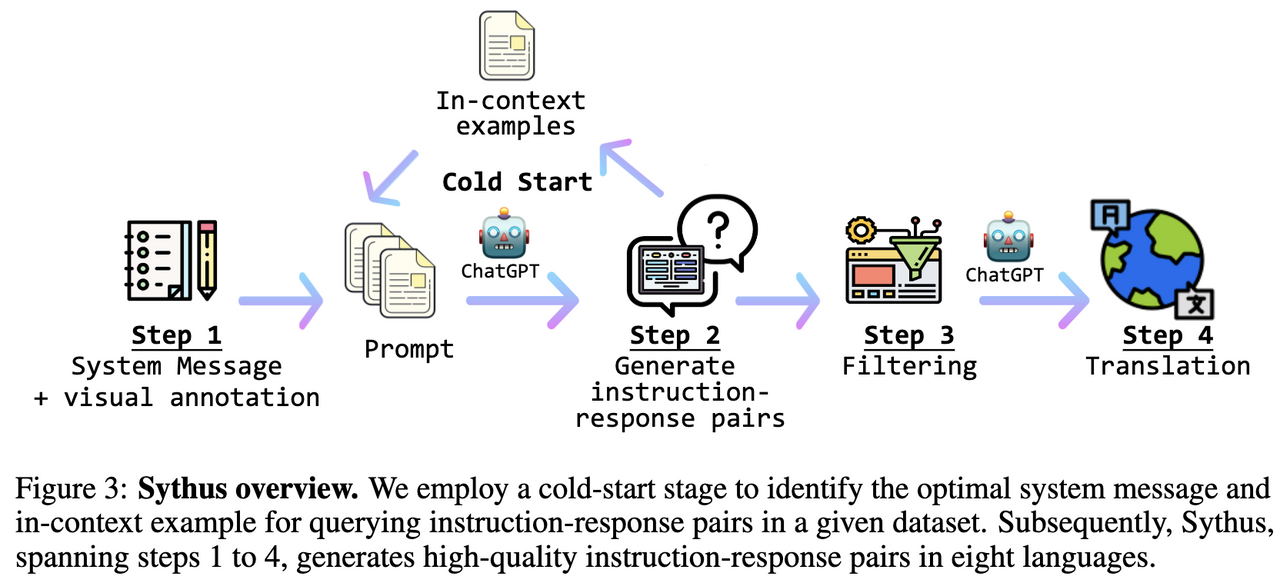
参考mimic概念图,设计冷启动收集ICL的策略
-
制定更丰富的指令数据微调策略
-
batch长度处理(本任务用不到太长的因此没写)
成功在colab上调试运行,遇到网络问题时进程会不断等待尝试,最终可运行完毕
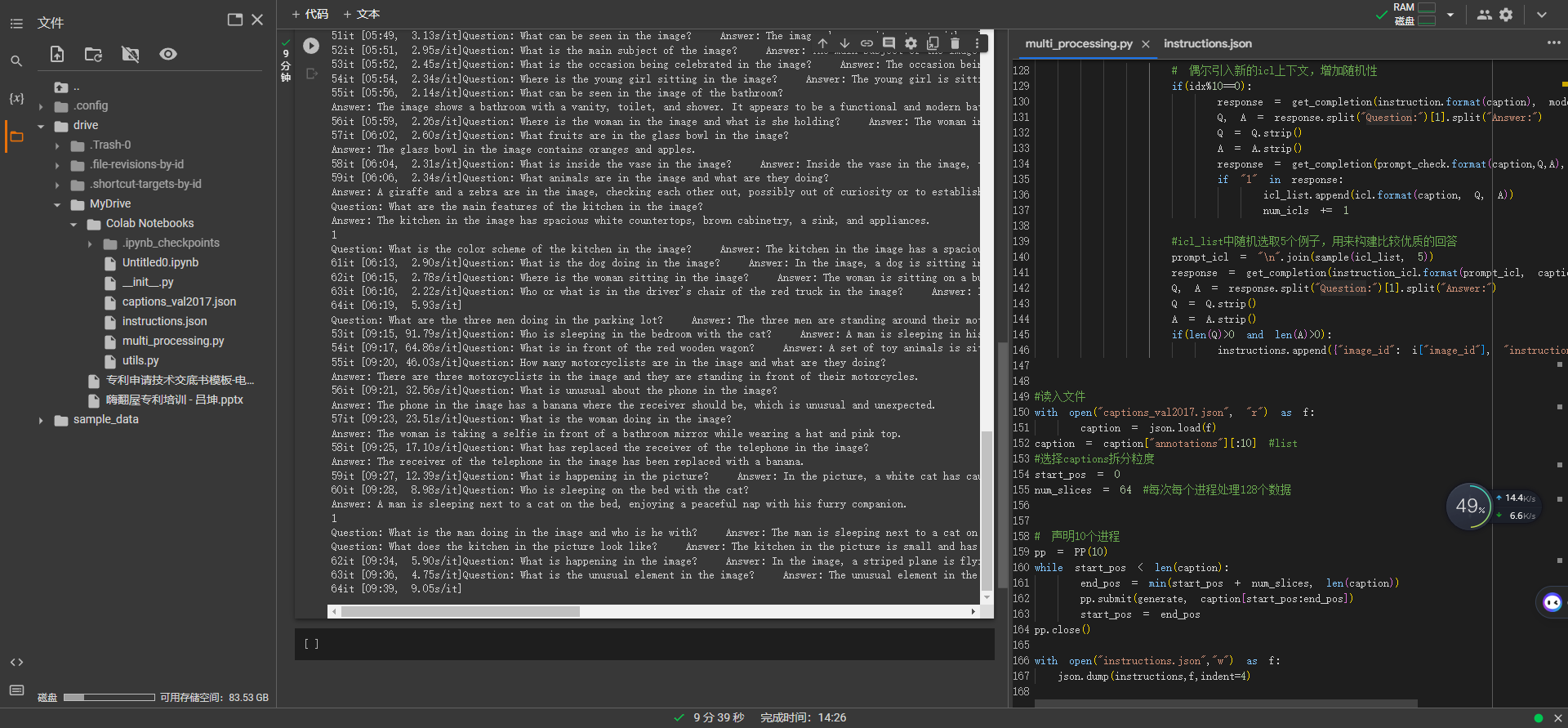
在本地ubuntu系统上成功运行,并收集了一些instructions样例
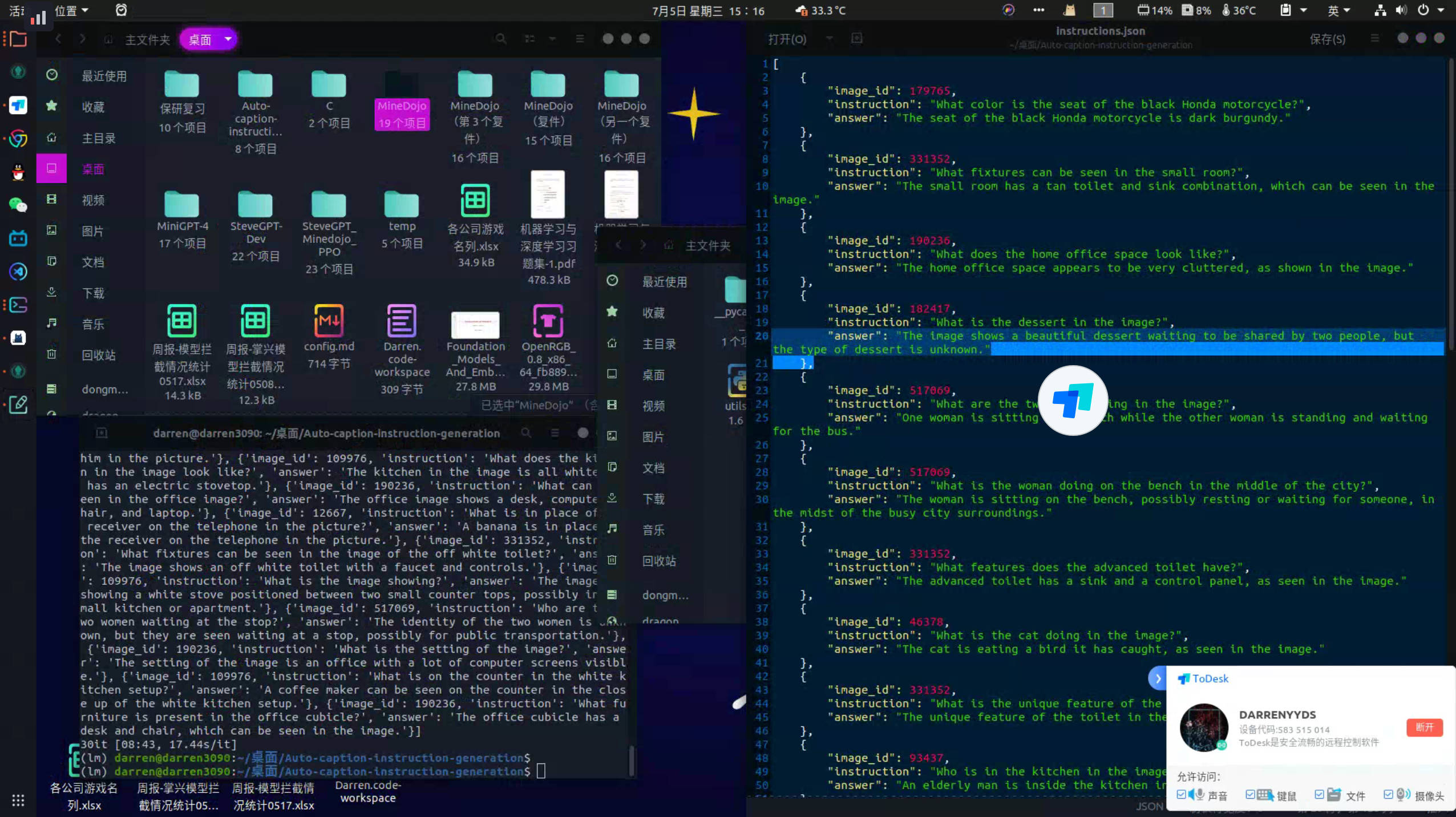
- 多进程技术,构造一个进程池,声明进程数(最好和CPU虚拟核数一致),每个进程轮流处理划分的数据,处理好后如果还有剩下的数据就继续申请任务执行【实习的时候leader给我分享的工具类】。
- 调用OpenAI API,构建合适的提示prompt,让gpt-3.5-turbo根据caption来提出问题并给出答案,同时用异常捕获监测openai API网络调用情况,如果连接失败,等待后继续查询,经过测试,最终都能完成任务
- 参照mimic概念图(没看实现QWQ)写了个简单的冷启动
在最初时,对每个收集的QA对儿,询问gpt3.5该QA对儿是否对于caption来说是高质量的,如果是则加入in-context列表,当列表内收集了一定(5个以上)高质量样例后,改为每生成一些数据后(10对儿)判别一次QA质量,继续加入in-context列表,同时每次生成时都从列表内采样若干(5个)样例拼接在context和instruction前面。
-
多进程执行完后写入文件的问题
发现json.dump时是空的,debug发现每个进程执行完后,并不会保留对全局变量的更改,全局变量也在进程内部,因此改成在每个进程结尾时通过追加(a)的方式保存构造的数据
-
规范化输出的问题
一开始我构造的instruction中未显式要求gpt3.5规范化输出,而是用正则解析,很麻烦而且遇到了特例解析不出来报错,后来查博客发现可以要求其规范化输出,然后用简单的规则就能解析出正确的结果