
* Equal Contribution ♠ Equal appreciation on assistance ✉ Corresponding Author
Technical Report | Demo | Benchmarks
We introduce OtterHD-8B, a multimodal model fine-tuned from Fuyu-8B to facilitate a more fine-grained interpretation of high-resolution visual input without requiring a vision encoder. OtterHD-8B also supports flexible input sizes at test time, ensuring adaptability to diverse inference budgets.
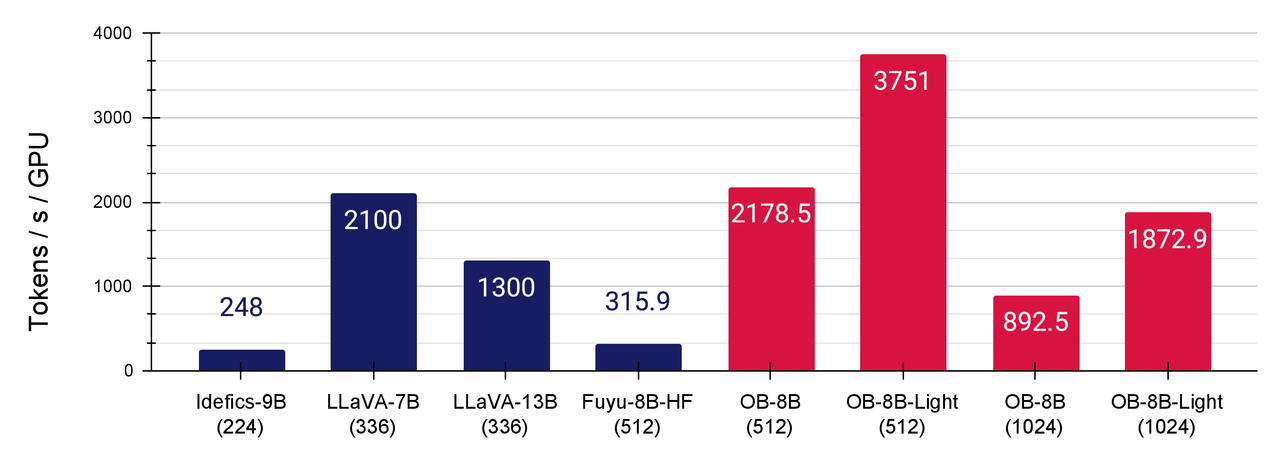
We improve the native HuggingFace implementation of Fuyu-8B is highly unoptimized with FlashAttention-2 and other fused operators including fused layernorm, fused square ReLU, and fused rotary positional embedding. Fuyu's simplified architecture facilitates us to do this in a fairly convenient way. As illustrated in the following, the modifications substantially enhance GPU utilization and training throughput (> 5 times larger than the vanilla HF implementation of Fuyu). Checkout the details at here.
To our best knowledge and experiment trials, OtterHD achieves fastest training throughput among current leading LMMs, as it can be fully optimized and benefit from the simplified architecture.
On top of the regular Otter environment, we need to install Flash-Attention 2 and other fused operators:
pip uninstall -y ninja && pip install ninja
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention
python setup.py install
cd csrc/rotary && pip install .
cd ../csrc/fused_dense_lib && pip install .
cd ../layer_norm && pip install .
cd ../xentropy && pip install .
cd ../.. && rm -rf flash-attentionaccelerate launch \
--config_file=pipeline/accelerate_configs/accelerate_config_zero2.yaml \
--num_processes=8 \
--main_process_port=25000 \
pipeline/train/instruction_following.py \
--pretrained_model_name_or_path=adept/fuyu-8b \
--training_data_yaml=./Demo_Data.yaml \
--model_name=fuyu \
--instruction_format=fuyu \
--batch_size=8 \
--gradient_accumulation_steps=2 \
--num_epochs=3 \
--wandb_entity=ntu-slab \
--external_save_dir=./checkpoints \
--save_hf_model \
--run_name=OtterHD_Tester \
--wandb_project=Fuyu \
--report_to_wandb \
--workers=1 \
--lr_scheduler=linear \
--learning_rate=1e-5 \
--warmup_steps_ratio=0.01 \
--dynamic_resolution \
--weight_decay 0.1 \

The human visual system can naturally perceive the details of small objects within a wide field of view, but current benchmarks for testing LMMs have not specifically focused on assessing this ability. This may be because the input sizes of mainstream Vision-Language models are constrained to relatively small resolutions. With the advent of the Fuyu and OtterHD models, we can extend the input resolution to a much larger range. Therefore, there is an urgent need for a benchmark that can test the ability to discern the details of small objects (often 1% image size) in high-resolution input images.
Create a yaml file benchmark.yaml with below content:
datasets:
- name: magnifierbench
split: test
data_path: Otter-AI/MagnifierBench
prompt: Answer with the option letter from the given choices directly.
api_key: [You GPT-4 API]
models:
- name: fuyu
model_path: azure_storage/fuyu-8b
resolution: 1440Then run
python -m pipeline.benchmarks.evaluate --confg benchmark.yaml