You can use the 🦩 Flamingo model / 🦦 Otter model as a 🤗 Hugging Face model with only a few lines! One-click and then model configs/weights are downloaded automatically.
from flamingo import FlamingoModel
flamingo_model = FlamingoModel.from_pretrained("luodian/openflamingo-9b-hf", device_map=auto)
from otter import OtterModel
otter_model = OtterModel.from_pretrained("luodian/otter-9b-hf", device_map=auto)Previous OpenFlamingo was developed with DistributedDataParallel (DDP) on A100 cluster. Loading OpenFlamingo-9B to GPU requires at least 33G GPU memory, which is only available on A100 GPUs.
In order to allow more researchers without access to A100 machines to try training OpenFlamingo, we wrap the OpenFlamingo model into a 🤗 hugging Face model (Jinghao has submitted a PR to the /huggingface/transformers!). Via device_map=auto, the large model is sharded across multiple GPUs when loading and training. This can help researchers who do not have access to A100-80G GPUs to achieve similar throughput in training, testing on 4x RTX-3090-24G GPUs, and model deployment on 2x RTX-3090-24G GPUs. Specific details are below (may vary depending on the CPU and disk performance, as we conducted training on different machines).
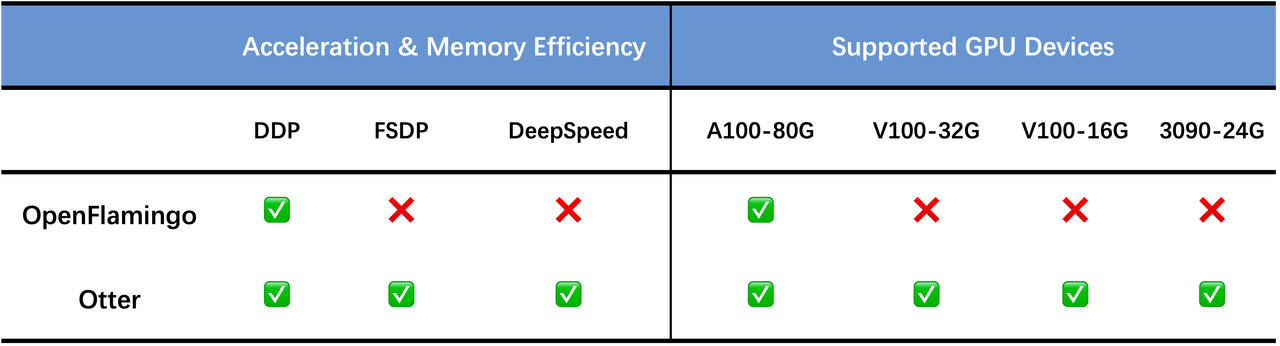
Our Otter model is also developed in this way and it's deployed on the 🤗 Hugging Face model hub. Our model can be hosted on two RTX-3090-24G GPUs and achieve a similar speed to one A100-80G machine.