Deep learned, NVIDIA-accelerated 3D object pose estimation

Isaac ROS Pose Estimation contains three ROS 2 packages to predict the pose of an object. Please refer the following table to see the differences of them:
| Node | Novel Object wo/ Retraining | TAO Support | Speed | Quality | Maturity |
|---|---|---|---|---|---|
isaac_ros_foundationpose |
✓ | N/A | Fast | Best | New |
isaac_ros_dope |
x | x | Fastest | Good | Time-tested |
isaac_ros_centerpose |
x | ✓ | Faster | Better | Established |
Those packages use GPU acceleration for DNN inference to estimate the pose of an object. The output prediction can be used by perception functions when fusing with the corresponding depth to provide the 3D pose of an object and distance for navigation or manipulation.
isaac_ros_foundationpose is used in a graph of nodes to estimate the pose of
a novel object using 3D bounding cuboid dimensions. It’s developed on top of
FoundationPose model, which is
a pre-trained deep learning model developed by NVLabs. FoundationPose
is capable for both pose estimation and tracking on unseen objects without requiring fine-tuning,
and its accuracy outperforms existing state-of-art methods.
FoundationPose comprises two distinct models: the refine model and the score model. The refine model processes initial pose hypotheses, iteratively refining them, then passes these refined hypotheses to the score model, which selects and finalizes the pose estimation. Additionally, the refine model can serve for tracking, that updates the pose estimation based on new image inputs and the previous frame’s pose estimate. This tracking process is more efficient compared to pose estimation, which speeds exceeding 120 FPS on the Jetson Orin platform.
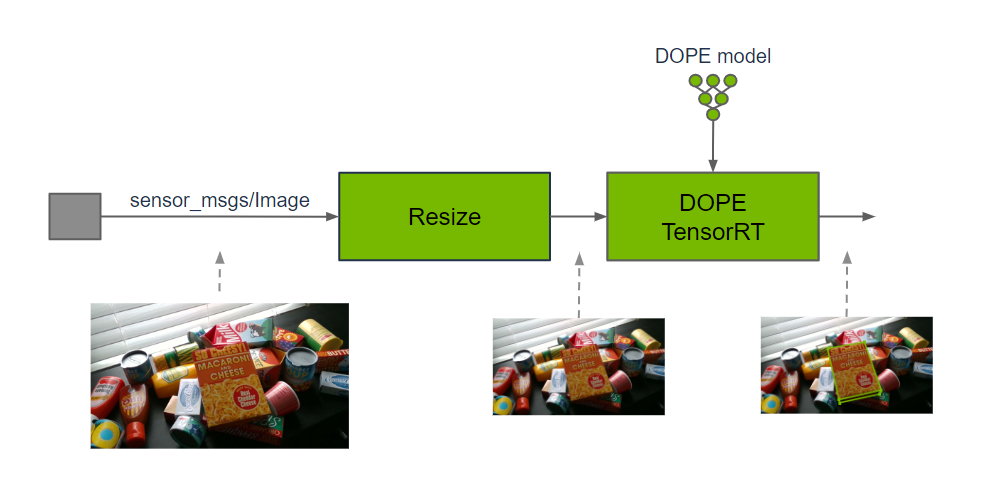
isaac_ros_dope is used in a graph of nodes to estimate the pose of a
known object with 3D bounding cuboid dimensions. To produce the
estimate, a DOPE (Deep
Object Pose Estimation) pre-trained model is required. Input images may
need to be cropped and resized to maintain the aspect ratio and match
the input resolution of DOPE. After DNN inference has produced an estimate, the
DNN decoder will use the specified object type, along with the belief
maps produced by model inference, to output object poses.
NVLabs has provided a DOPE pre-trained model using the
HOPE dataset. HOPE stands
for Household Objects for Pose Estimation. HOPE is a research-oriented
dataset that uses toy grocery objects and 3D textured meshes of the objects
for training on synthetic data. To use DOPE for other objects that are
relevant to your application, the model needs to be trained with another
dataset targeting these objects. For example, DOPE has been trained to
detect dollies for use with a mobile robot that navigates under, lifts,
and moves that type of dolly. To train your own DOPE model, please refer to the
Training your Own DOPE Model Tutorial.
isaac_ros_centerpose has similarities to isaac_ros_dope in that
both estimate an object pose; however, isaac_ros_centerpose provides
additional functionality. The
CenterPose DNN performs
object detection on the image, generates 2D keypoints for the object,
estimates the 6-DoF pose up to a scale, and regresses relative 3D bounding cuboid
dimensions. This is performed on a known object class without knowing
the instance-for example, a CenterPose model can detect a chair without having trained on
images of that specific chair.
Pose estimation is a compute-intensive task and therefore not performed at the frame rate of an input camera. To make efficient use of resources, object pose is estimated for a single frame and used as an input to navigation. Additional object pose estimates are computed to further refine navigation in progress at a lower frequency than the input rate of a typical camera.
Packages in this repository rely on accelerated DNN model inference
using Triton or
TensorRT from Isaac ROS DNN Inference.
For preprocessing, packages in this rely on the Isaac ROS DNN Image Encoder,
which can also be found at Isaac ROS DNN Inference.
| Sample Graph |
Input Size |
AGX Orin |
Orin NX |
Orin Nano 8GB |
x86_64 w/ RTX 4060 Ti |
x86_64 w/ RTX 4090 |
|---|---|---|---|---|---|---|
| FoundationPose Pose Estimation Node |
720p |
1.72 fps 690 ms @ 30Hz |
– |
– |
– |
7.02 fps 170 ms @ 30Hz |
| DOPE Pose Estimation Graph |
VGA |
41.3 fps 42 ms @ 30Hz |
17.5 fps 76 ms @ 30Hz |
– |
85.2 fps 24 ms @ 30Hz |
199 fps 14 ms @ 30Hz |
| Centerpose Pose Estimation Graph |
VGA |
36.3 fps 4.8 ms @ 30Hz |
19.7 fps 4.9 ms @ 30Hz |
13.8 fps 7.4 ms @ 30Hz |
50.2 fps 23 ms @ 30Hz |
50.2 fps 20 ms @ 30Hz |
Please visit the Isaac ROS Documentation to learn how to use this repository.
Update 2024-09-26: Update for ZED compatibility