Replace pycld3 dependency? #593
Comments
|
It should be noted that Lingua is a fairly new library and so has a very short track record, with only two releases so far. |
|
There is an issue asking about Python 3.10 support for pycld3: bsolomon1124/pycld3#31 |
|
As pointed out by @adulau in this comment, Lingua can use huge amounts of memory. I tested it in the default lazy loading configuration, and detecting the language of the example sentence |
|
Hello, I'm the author of Lingua. I've managed to reduce the memory consumption of the library. All language models together now just take around 800 MB in memory. Perhaps you want to re-evaluate Lingua for this project once again. If you have any questions, feel free to ask here or join this discussion that @osma has opened. |
|
Thanks @pemistahl , that is excellent news! We will take a new look at Lingua. |
|
@osma I have just released Lingua 1.1.0. In high accuracy mode, memory consumption is now at 800 MB. In low accuracy mode, it's even just 60 MB.
|
|
@pemistahl Whoa, that's quite an improvement! |
|
Yes, that's because the models are now stored in NumPy arrays instead of dictionaries. Querying the arrays is slower than querying dictionaries, that's the downside. But I still use a dictionary as a cache for already looked-up ngrams to speed up the process again. |
|
FYI: There was a little bug in version 1.1.0 that caused wrong probabilities to be returned for certain ngrams. I've just fixed that. So please use version 1.1.1 now for your tests. Thank you. |
|
I did some testing of Lingua in a draft PR #615, you may want to check that out @pemistahl |
|
@adbar suggested these other language detection approaches in #617 (comment) :
We could take a look at these and compare how well they work, similar to the Lingua experiments in PR #615 but testing on a different data set (e.g. Finnish language jyu-theses) where filtering by language actually improves results. |
|
Hi, just a quick evaluation on my side:
Quick and dirty approach, many questions left out here! I'm open for discussion and for wider benchmarks. |
|
@adbar Thank you very much for the benchmark. Do you have some statistics on memory usage too? I remember some libs where pretty fast but with significant memory usage compared to some others like |
|
I have now redone the benchmarks described in #615 (comment) with some changes. This time I used the parts of the Finto AI data set and Finnish language documents and YSO Filolaos as the vocabulary. Again I used two project configurations with two backend algorithms, MLLM and Omikuji Parabel. For training MLLM, I used the I compared current master (which uses pycld3) to the PR #615 branch which uses Lingua Again, for the baseline case with no filter I used
Evaluation results (higher is better):
Observations:
Some preliminary conclusions:
|
|
Reported the huge memory usage in Simplemma as adbar/simplemma#19 |
|
@osma My library is slower because it is written in pure Python. pycld3 is written in C++ and simplemma uses You should also add Lingua's high accuracy mode to this comparison because this is what makes the library superior to most other language detection libraries. Memory consumption and running time will be higher but accuracy should be much better. It is kind of unfair to leave out the high accuracy mode and then stating gives the least benefit in terms of quality. I've just released Lingua 1.1.3 which improves performance by roughly 30% compared to 1.1.2. So maybe you want to update your evaluation again. |
I understand. Simplemma uses a different, vocabulary-based approach for language detection though, not n-grams like most other language detectors including Lingua.
I apologize for the harsh wording. I was focused on the downstream results - how the language detection, when applied as a filter for training and evaluation data, affects the quality of automated subject indexing. This may or may not correlate with quality benchmarks that focus purely on the accuracy of language detection. It is entirely possible that even a perfect language detector with 100% accuracy would achieve a low score on this downstream benchmark because there are so many confounding factors. As I also noted above, the differences between the three language detection approaches are quite small ("not very dramatic"). Using Simplemma instead of Lingua (low accuracy mode) with Omikuji improved the F1 score by 0.7 points (pycld3 was halfway between those) and some of these differences could well be just random variation. I understand that Lingua's strong point is the high accuracy it achieves. But for an application like input preprocessing in Annif, it just doesn't make sense to spend so much computing resources (even just the low accuracy mode tested here) on the language detection part, when the maximum possible benefit is something like half a percentage point in F1 score compared to other, more lightweight approaches. Those resources would likely be better spent in other parts of the process, for example the classification algorithms themselves rather than the preprocessing.
That is great news, congratulations! I might consider doing another round (also including py3langid for example, or a possible new version of Simplemma with lower memory use) but for now I have other, more urgent tasks. |
|
I realized that I can just run the Omikuji evaluation part again with Lingua 1.1.3, without redoing the whole benchmark. Hang on... |
|
@pemistahl I upgraded to Lingua 1.1.3 and reran the Omikuji and MLLM evaluations. The Omikuji evaluation runtime decreased from 935 to 856 seconds and the MLLM runtime from 1210 to 1133 seconds. So it's an improvement for sure, but not super dramatic. I updated the table above. Evaluation scores didn't change at all. Benchmark with Lingua in high accuracy mode is currently running, but as expected, it's taking a while... |
|
I finished the (partial) benchmark of Lingua in high-accuracy mode and edited the results table above accordingly. The runtime was at least an order of magnitude larger than in low-accuracy mode. Sorry @pemistahl but the result quality almost did not change at all. I don't think this is because Lingua would be less accurate than the others, it's just for some reason not very well suited to this particular task (and it's possible that tweaking the way it's used could improve the results). |
|
Thanks for the tip @adbar , I wasn't aware of hyperfine. Though it seems to me it will only measure execution time, not memory usage. |
No worries, @osma. I'm not resentful. :)
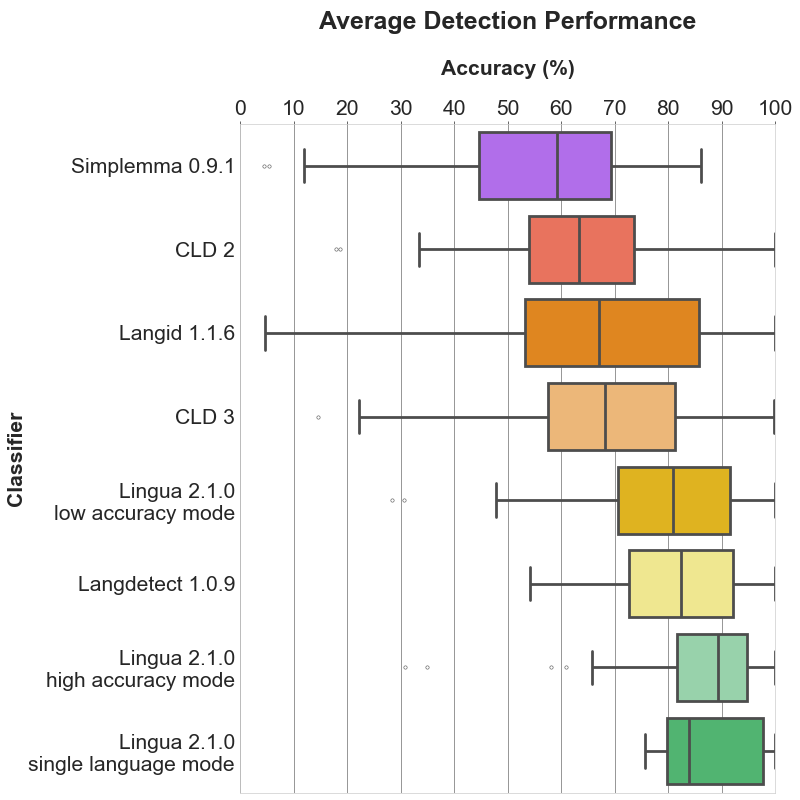
This is absolutely reasonable. Then Lingua is simply not the right tool for your job. That's ok. Luckily, there are enough language detectors to choose from, especially in the Python ecosystem. I was curious and added Simplemma to my own evaluation of language detectors. As expected, the vocabulary-based approach is not as good as the ngram-based approach. The detection accuracy differs significantly between the languages. For Finnish, Simplemma is pretty accurate with 81% on average. But other languages, such as Spanish, for instance, do not perform so well. You can find the accuracy reports in the Lingua repo.
|
Yes, right. There's also the issue of API design - Simplemma provides the in_target_language function which is well suited for this specific task of filtering by language. It gives the estimated proportion of words in the text that are in the expected target language, and it only needs to load and make use of a single language model. I couldn't find anything similar in Lingua, so what I did in PR #615 was to use Lingua to detect the language of a sentence out of all languages it knows, which requires loading and using all available 75 language models (or at least a significant proportion of those). This means Lingua has to do a lot more work than Simplemma to accomplish the same and at least partly explains the difference in performance.
This is great, thanks a lot! It's very useful to have a benchmark that is evaluated on many different detectors. I didn't expect Simplemma to be super accurate, as language detection is just an extra feature and the main purpose of the library is lemmatization. Also there seem to be large differences between the languages supported by Simplemma in the size of the vocabularies it knows about. It's quite natural that Simplemma has difficulties detecting languages with small vocabulary sizes. Finnish happens to be the language with the largest included vocabulary, though this has a lot to do also with the complex morphology of the language. Would it be possible for you to also include the spent CPU time and memory for each detector in the benchmark results? At least for me those are important considerations, and also @adulau asked about it above, so others would likely be interested too. Since you run the same tests on every detector, the resource usage should be quite easily comparable, right? |
|
Thanks @pemistahl for the detailed evaluation! I also like the bar plots you made to compare the results by language. A quick remark on the methodology, you write that "a random unsorted subset of 1000 single words, 1000 word pairs and 1000 sentences has been extracted". The fact that a n-gram approach works well on single words and on word pairs explains the overall performance of Lingua and others but not the relatively poor performance of CLD, that's interesting. Simplemma works as expected IMO, it's a meaningful baseline or a good trade-off between simplicity and accuracy, and as @osma says language detection isn't its main purpose anyway. |
I think it is not too difficult to implement something like this in Lingua. I will try to do that.
I have to rewrite some parts of the accuracy reports script to do so, but yes, it is surely possible. I don't know when I will have the time, though.
Maybe I will try to find a better source for test data for certain languages but that is not on my todo list at the moment. In the later future perhaps. |
The pycld3 language detection library which we depend on seems to have install issues on Python 3.10 (see #589). The last release 0.22 was in March 2021.
I think we should consider switching to a more actively maintained library. This should be easy now that we are only using language detection for language filtering but not in other parts of the Annif codebase.
A possible promising candidate would be Lingua but there are others.
The text was updated successfully, but these errors were encountered: