
- Should now support Mixtral, with updated AutoGPTQ 0.6 and llama-cpp-python 0.2.23
- Updated PyTorch to 2.1.1
- Container will now launch text-generation-webui with arg
--extensions openai - Update API documentation link
- Logs from text-generation-webui will now appear in the Runpod log viewer, as well as
/workspace/logs/text-generation-webui.log
- The instances now use CUDA 12.1.1, which fixes issues with EXL2
- Note that for now the main container is still called cuda11.8.0-ubuntu22.04-oneclick
- This is because I need to get in touch with Runpod to update the name of the container used in their instances
- This is just a naming issue; the container does now use CUDA 12.1.1 and EXL2 is confirmed to work again.
- Llama 2 models, including Llama 2 70B, are now fully supported
- Updated to latest text-generation-webui
requirements.txt - Removed the exllama pip package installed by text-generation-webui
- Therefore the ExLlama kernel will build automatically on first use
- This ensures that ExLlama is always up-to-date with any new ExLlama commits (which are pulled automatically on each boot)
- Updated to latest ExLlama code, fixing issue with SuperHOT GPTQs
- ExLlama now automaticaly updates on boot, like text-generation-webui already did
- This should result in the template automatically supporting new ExLlama features in future
- Major update to the template
- text-generation-webui is now integrated with:
- AutoGPTQ with support for all Runpod GPU types
- ExLlama, turbo-charged Llama GPTQ engine - performs 2x faster than AutoGPTQ (Llama 4bit GPTQs only)
- CUDA-accelerated GGML support, with support for all Runpod systems and GPUs.
- All text-generation-webui extensions are included and supported (Chat, SuperBooga, Whisper, etc).
- text-generation-webui is always up-to-date with the latest code and features.
- Automatic model download and loading via environment variable
MODEL. - Pass text-generation-webui parameters via environment variable
UI_ARGS.
This template will automatically start oobabooga's text-generation-webui on port 7860.
It can load quantised GPTQ models (3-bit, 4-bit and 8-bit), quantised GGML models (2, 3, 4, 5, 6 and 8-bit) with full GPU acceleration, as well as pytorch format models in 16-bit, 8-bit and 4-bit.
It provides:
- text-generation-webui with all extensions.
- GPTQ support via AutoGPTQ - 2, 3, 4 and 8-bit, all model types.
- GPTQ support via ExLlama and ExLlamav2 - 4-bit Llama models only.
- GGUF with GPU acceleration via llama-cpp-python.
- AWQ support via AutoAWQ.
This template supports volumes mounted under /workspace.
On boot, text-generation-webui will be moved to /workspace/text-generation-webui. Therefore all downloaded models, and any saved settings/characters/etc, will be persisted on your volume, including Network Volumes.
With default settings, it will create a 100GB volume on /workspace. This storage is persistent after shutting down and then restarting the pod. But its contents will be lost if you delete the pod. Runpod support Network Volumes in some datacentres. If you create a Network Volume and use it with this template, your models will be stored on the Network Volume and will be persistent permanently, including working between different kinds of pods (within that same datacentre).
Once the pod is started, click Connect and then HTTP [Port 7860].
The HTTP API on port 5000 can be accessed directly from the Connect tab:
Right-click on HTTP [Port 5000] and choose to "Copy Link Address" (or similar wording).
This will copy your HTTP API URL to your clipboard.
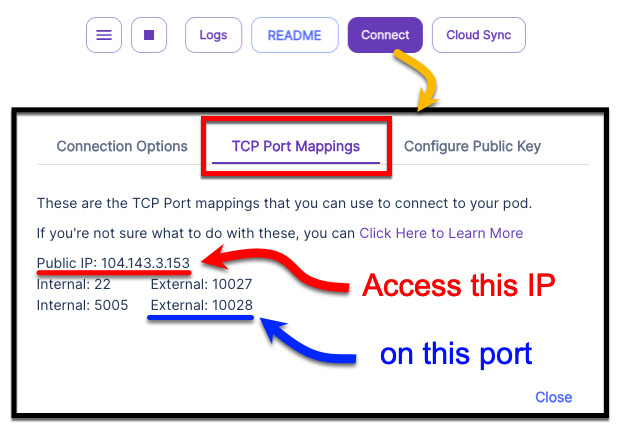
A TCP port will be opened on the public IP of the pod.
You can see the public IP and the external port under:
- My Pods -> Connect -> TCP port forwarding
- The connect to the Public IP on the External port that's listed against
Internal: 5005
text-generation-webui API documentation
Once you're in the UI:
- Click the Model tab.
- Under Download custom model or LoRA, enter an HF repo to download, for example:
TheBloke/vicuna-13b-v1.3-GPTQ. - Click Download.
- Wait until it says it's finished downloading.
- Click the Refresh icon next to Model in the top left.
- In the Model drop-down: choose the model you just downloaded, eg
vicuna-13b-v1.3-GPTQ. - Once it says it's loaded, click the Text Generation tab and enter a prompt!
For Llama 4-bit GPTQs, you have the option of using ExLlama instead of AutoGPTQ.
- Download the model as described above.
- On the Models tab, change the Loader dropdown to ExLlama
- Click Reload to load the model with ExLlama.
- For most systems, you're done! You can now run inference as normal, and expect to see better performance.
- If you're using a dual-GPU system, you can configure ExLlama to use both GPUs:
- In the gpu-split text box, enter a comma-separated list of the VRAM to use on each GPU
- For example, if using a system with 2 x 24GB GPUs, you could enter
23,23 - Note: Multiple GPUs should only be used for loading larger models than can load on one GPU. Multi-GPU inference is not faster than single GPU in cases where one GPU has enough VRAM to load the model.
- To optionally save ExLlama as the loader for this model, click Save Settings.
If you want to use ExLlama permanently, for all models, you can add the --loader exllama parameter to text-generation-webui.
This can be done either by editing /workspace/run-text-generation-webui.sh, or by passing the UI_ARGS environment variable via Template Overrides. Both methods are described below.
The UI doesn't currently support downloading a single GGML model via the UI. Therefore it's recommended to either use the MODEL environment variable described below, or else to SSH in.
To download a model via SSH:
- SSH to the server, then:
cd /workspace/text-generation-webui/models
wget https://huggingface.co/<repo>/resolve/main/<filename>
For example, to download vicuna-13b-v1.3.ggmlv3.q4_K_M.bin from TheBloke/vicuna-13b-v1.3-GGML:
wget https://huggingface.co/TheBloke/vicuna-13b-v1.3-GGML/resolve/main/vicuna-13b-v1.3.ggmlv3.q4_K_M.bin
Once the download is finished, you can access the UI and:
- Click the Models tab;
- Untick Autoload the model;
- Click the *Refresh icon next to Model in the top left;
- Choose the GGML file you just downloaded;
- In the Loader dropdown, choose llama.cpp;
- For full GPU acceleration, set Threads to 1 and n-gpu-layers to 100;
- Note that whether you can do full acceleration will depend on the GPU you've chosen, the size of the model, and the quantisation size. If using one of my models, refer to the README for the list of quant sizes and pay attention to the "Max RAM" column. For full acceleration, pick a quant size which has "Max RAM" 2-3GB lower than the total VRAM of your GPU.
- If you can't do full GPU acceleration, set Threads to 8 to start with and n-gpu-layers to as many layers as the GPU has VRAM for.
- You can experiment with higher Threads value, which depending on the system in question may result in slightly higher performance.
- Click Save settings and then Reload
- The model will now load.
- Once it says it's loaded, click the Text generation tab and enter a prompt!
This template supports two environment variables which you can specify via Template Overrides.
MODEL- Pass in the ID of a Hugging Face repo, or an
https://link to a single GGML model file - Examples of valid values for
MODEL:TheBloke/vicuna-13b-v1.3-GPTQhttps://huggingface.co/TheBloke/vicuna-13b-v1.3-GGML/resolve/main/vicuna-13b-v1.3.ggmlv3.q4_K_M.bin
- When a
MODELvalue is passed, the following will happen:- On Docker launch, the passed model will be automatically downloaded to
/workspace/text-generation-webui/models - Note: this may take some time and the UI will not be available until the model has finished downloading.
- Once the model is downloaded, text-generation-webui will load this model automatically
- To monitor the progress of the download, you can SSH in and run:
tail -100f /workspace/logs/fetch-model.log
- On Docker launch, the passed model will be automatically downloaded to
- Pass in the ID of a Hugging Face repo, or an
UI_ARGS- Pass in any text-generation-webui launch parameters you want to use
- For a guide to valid parameters, please see: https://github.com/oobabooga/text-generation-webui/tree/main#basic-settings
- Example value:
--n-gpu-layers 100 --threads 1to ensure a GGML model is fully loaded onto GPU, with optimal performance parameters. - Note: no checking for valid parameters is currently done. So if invalid params are entered, it can block text-generation-webui from launching.
- If the UI does not launch, SSH in and run:
tail -100f /workspace/logs/text-generation-webui.logto see what the UI is doing.
To change in to Chat mode, click the Interface Settings tab then change Mode to chat and click Apply and restart the interface. To go back, change Mode back to Default.
You can also try change other settings in the Interface Settings tab, including enabling extensions.
To have the UI always launch with certain settings, you can SSH in and edit the script /workspace/run-text-generation-webui.sh
Add or change any command line arguments you want in that script, then save it. Your settings will persist on the volume between pod restarts, and will persist permanently if a Network Volume is being used.
Once you've changed settings you can then restart the server by running:
/root/scripts/restart-text-generation-webui.sh
For an alternative method of specifying parameters, refer to the Environment Variables section above for details on how to use UI_ARGS in a Template Override.
The logs from launching text-generation-webui are stored at /workspace/log/text-generation-webui.log
You can read them by SSHing in and typing:
cat /workspace/text-generation-webui.log
Or to watch them live:
tail -100f /workspace/text-generation-webui.log
I have over 250 repos at HuggingFace, see them here: https://huggingface.co/TheBloke
This template uses Docker thebloke/cuda11.8.0-ubuntu22.04-oneclick:latest
The source files for this Docker can be found at: https://github.com/TheBlokeAI/dockerLLM
To get support, or to chat about AI/LLM in general, join us at my fast-growing Discord: https://discord.gg/Jq4vkcDakD
I accept donations towards my time and efforts in the open source LLM community:
- Patreon: https://www.patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI