diff --git a/README.md b/README.md
index 5888477..cd01c32 100644
--- a/README.md
+++ b/README.md
@@ -74,7 +74,17 @@ or install from source code:
```python
import numpy as np
-from pygrinder import mcar, mar_logistic, mnar_x, mnar_t
+
+from pygrinder import (
+ mcar,
+ mar_logistic,
+ mnar_x,
+ mnar_t,
+ rdo,
+ seq_missing,
+ block_missing,
+ calc_missing_rate
+)
# given a time-series dataset with 128 samples, each sample with 10 time steps and 36 data features
ts_dataset = np.random.randn(128, 10, 36)
@@ -87,11 +97,29 @@ X_with_mar_data = mar_logistic(ts_dataset[:, 0, :], obs_rate=0.1, missing_rate=0
# grind the dataset with MNAR pattern
X_with_mnar_x_data = mnar_x(ts_dataset, offset=0.1)
-X_with_mnar_t_data = mnar_t(ts_dataset, cycle=20, pos = 10, scale = 3)
+X_with_mnar_t_data = mnar_t(ts_dataset, cycle=20, pos=10, scale=3)
+
+# grind the dataset with RDO pattern
+X_with_rdo_data = rdo(ts_dataset, p=0.1)
+
+# grind the dataset with Sequence-Missing pattern
+X_with_seq_missing_data = seq_missing(ts_dataset, p=0.1, seq_len=5)
+
+# grind the dataset with Block-Missing pattern
+X_with_block_missing_data = block_missing(ts_dataset, factor=0.1, block_width=3, block_len=3)
+
+# calculate the missing rate of the dataset
+missing_rate = calc_missing_rate(X_with_mcar_data)
```
## ❖ Citing PyGrinder/PyPOTS
+
+
+ 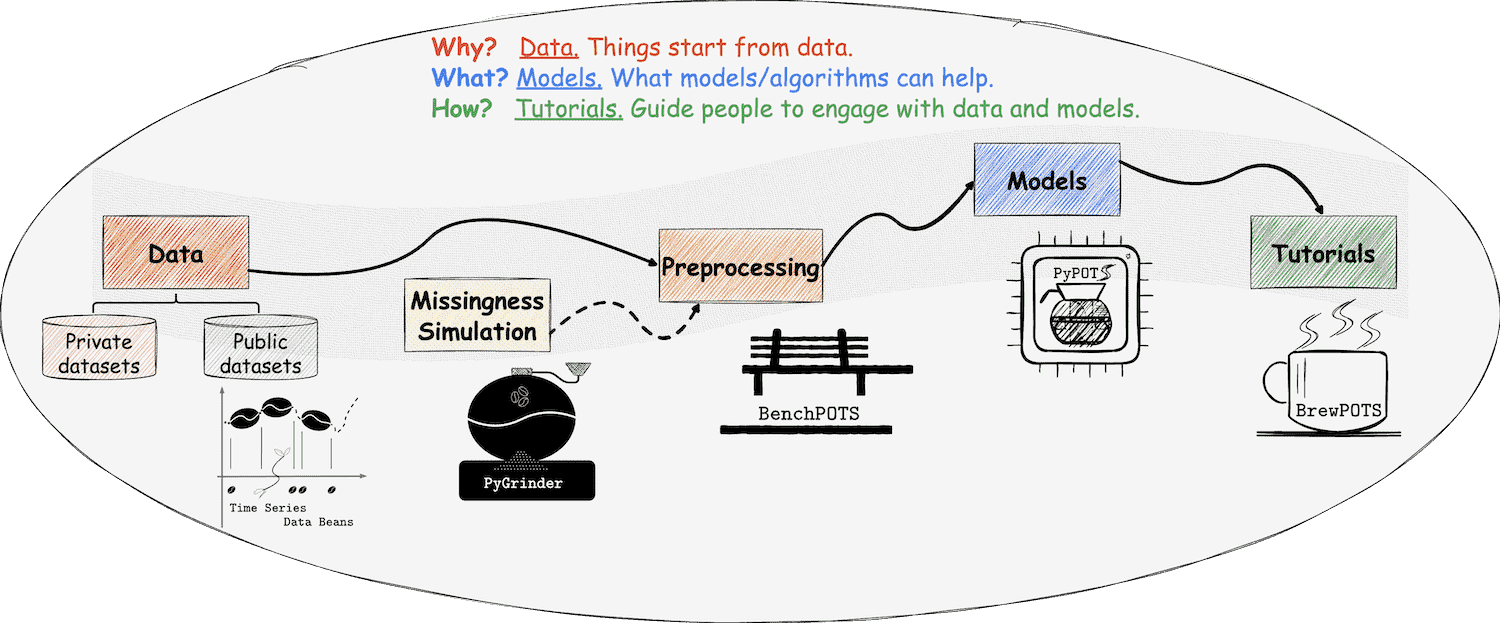 +
+
+
+
+
The paper introducing PyPOTS is available [on arXiv](https://arxiv.org/abs/2305.18811),
A short version of it is accepted by the 9th SIGKDD international workshop on Mining and Learning from Time Series ([MiLeTS'23](https://kdd-milets.github.io/milets2023/))).
**Additionally**, PyPOTS has been included as a [PyTorch Ecosystem](https://pytorch.org/ecosystem/) project.
@@ -102,12 +130,6 @@ please cite it as below and 🌟star this repository to make others notice this
There are scientific research projects using PyPOTS and referencing in their papers.
Here is [an incomplete list of them](https://scholar.google.com/scholar?as_ylo=2022&q=%E2%80%9CPyPOTS%E2%80%9D&hl=en).
-
-
-
-
-
-
``` bibtex
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
@@ -117,9 +139,9 @@ year={2023},
}
```
or
-> Wenjie Du. (2023).
+> Wenjie Du.
> PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series.
-> arXiv, abs/2305.18811. https://arxiv.org/abs/2305.18811
+> arXiv, abs/2305.18811, 2023.
diff --git a/pygrinder/__init__.py b/pygrinder/__init__.py
index 676acab..447b8f1 100644
--- a/pygrinder/__init__.py
+++ b/pygrinder/__init__.py
@@ -21,7 +21,7 @@
#
# Dev branch marker is: 'X.Y.dev' or 'X.Y.devN' where N is an integer.
# 'X.Y.dev0' is the canonical version of 'X.Y.dev'
-__version__ = "0.6"
+__version__ = "0.6.1"
from .missing_at_random import mar_logistic
from .missing_completely_at_random import mcar, mcar_little_test
diff --git a/pygrinder/block_missing/block_missing.py b/pygrinder/block_missing/block_missing.py
index cd59b4d..8b06014 100644
--- a/pygrinder/block_missing/block_missing.py
+++ b/pygrinder/block_missing/block_missing.py
@@ -112,12 +112,40 @@ def block_missing(
feature_idx: list = None,
step_idx: list = None,
) -> Union[np.ndarray, torch.Tensor]:
+ """Create block missing data.
+
+ Parameters
+ ----------
+ X :
+ Data vector. If X has any missing values, they should be numpy.nan.
+
+ factor :
+ The actual missing rate of block_missing is hard to be strictly controlled.
+ Hence, we use ``factor`` to help adjust the final missing rate.
+
+ block_len :
+ The length of the mask block.
+
+ block_width :
+ The width of the mask block.
+
+ feature_idx :
+ The indices of features for missing block to star with.
+
+ step_idx :
+ The indices of steps for a missing block to start with.
+
+ Returns
+ -------
+ corrupted_X :
+ Original X with artificial missing values.
+ Both originally-missing and artificially-missing values are left as NaN.
+
+ """
if isinstance(X, list):
X = np.asarray(X)
n_samples, n_steps, n_features = X.shape
- # assert 0 < p <= 1, f"p must be in range (0, 1), but got {p}"
-
assert isinstance(
block_len, int
), f"`block_len` must be type of int, but got {type(block_len)}"
diff --git a/pygrinder/sequential_missing/seq_missing.py b/pygrinder/sequential_missing/seq_missing.py
index a752cde..62d5367 100644
--- a/pygrinder/sequential_missing/seq_missing.py
+++ b/pygrinder/sequential_missing/seq_missing.py
@@ -109,6 +109,32 @@ def seq_missing(
feature_idx: list = None,
step_idx: list = None,
) -> Union[np.ndarray, torch.Tensor]:
+ """Create subsequence missing data.
+
+ Parameters
+ ----------
+ X :
+ Data vector. If X has any missing values, they should be numpy.nan.
+
+ p :
+ The probability that values may be masked as missing completely at random.
+
+ seq_len :
+ The length of missing sequence.
+
+ feature_idx :
+ The indices of features for missing sequences to be corrupted.
+
+ step_idx :
+ The indices of steps for a missing sequence to start with.
+
+ Returns
+ -------
+ corrupted_X :
+ Original X with artificial missing values.
+ Both originally-missing and artificially-missing values are left as NaN.
+
+ """
if isinstance(X, list):
X = np.asarray(X)
n_samples, n_steps, n_features = X.shape
diff --git a/pygrinder/utils.py b/pygrinder/utils.py
index 8fbcd2b..f2a71a1 100644
--- a/pygrinder/utils.py
+++ b/pygrinder/utils.py
@@ -8,20 +8,23 @@
from typing import Union, Tuple
import numpy as np
+import pandas as pd
import torch
-def calc_missing_rate(X: Union[np.ndarray, torch.Tensor]) -> float:
+def calc_missing_rate(
+ X: Union[np.ndarray, torch.Tensor, pd.DataFrame],
+) -> float:
"""Calculate the originally missing rate of the raw data.
Parameters
----------
X:
- Data array that may contain missing values.
+ Data array/tensor/frame that may contain missing values.
Returns
-------
- originally_missing_rate,
+ missing_rate,
The originally missing rate of the raw data. Its value should be in the range [0,1].
"""
@@ -29,16 +32,18 @@ def calc_missing_rate(X: Union[np.ndarray, torch.Tensor]) -> float:
X = np.asarray(X)
if isinstance(X, np.ndarray):
- originally_missing_rate = np.sum(np.isnan(X)) / np.prod(X.shape)
+ missing_rate = np.sum(np.isnan(X)) / np.prod(X.shape)
elif isinstance(X, torch.Tensor):
- originally_missing_rate = torch.sum(torch.isnan(X)) / np.prod(X.shape)
- originally_missing_rate = originally_missing_rate.item()
+ missing_rate = torch.sum(torch.isnan(X)) / np.prod(X.shape)
+ missing_rate = missing_rate.item()
+ elif isinstance(X, pd.DataFrame):
+ missing_rate = pd.isna(X).sum().sum() / np.prod(X.shape)
else:
raise TypeError(
- f"X must be type of list/numpy.ndarray/torch.Tensor, but got {type(X)}"
+ f"X must be type of list/numpy.ndarray/torch.Tensor/pandas.DataFrame, but got {type(X)}"
)
- return originally_missing_rate
+ return missing_rate
def masked_fill(