Architectural Basics*
- How many layers
It depends on input data and complexity of data.
-
MaxPooling
Dimensional reduction of input data to make less step to reach global receptive field.
-
1x1 Convolutions
Its used for reduce or increase channel dimension based on use case. exp. 1x1 is a kernel whose size is 1x1 and process of convolving over input image using such kernel is 1x1 convolution. In simple terms 1x1 Convolution is used to reduce dimensionality, for instance if our image is 400 x 400 with 80 features and we perform a 30 filters of 1x1 convolution we will end up with a size of 400 x 400 x 30.
-
3x3 Convolutions
Convolution used for extract feature from image, we prefer 3 x 3 because coma table for hardware, also reduce number of parameter copier to other convolution like (7x7, 11x11, 21x21). 3x3 is the size of kernel which when we do convolution of such kernel over the input image it is called 3x3 convolution. Benefits of using a 3 x 3 Convolution is that it is very much effective to detect the local feature in the image. Being of smaller size the computation cost is also relatively less then the other let's say 5 x 5 convolution. When we apply a 3x3 convolution over a N x N image we get a feature map of (N-2) x (N-2). 3 x 3 convolution is very effective in finding out the edges and curves and other local features.
-
Receptive Field
receptive field define as where the pacific feature looking at input image.
-
SoftMax $$ \sigma \left ( z \right )j = \frac{e^{x_j}}{\sum{k=1}^{K}e^{z_k}} $$
its probabilistic function and normalise output between 0 and 1 by using above formula.
-
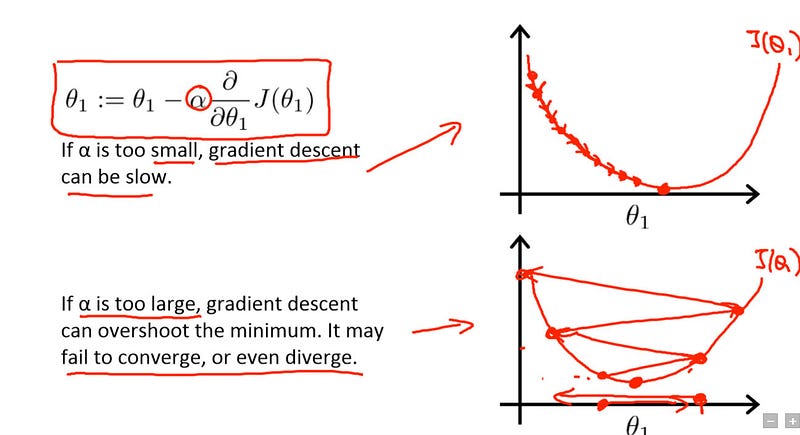
Learning Rate
The amount that the weights are updated during training is referred to as the step size or the learning rate. Specifically, the learning rate is a configurable hyper parameter used in the training of neural networks
-
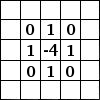
Kernels and how do we decide the number of kernels?
-
The 3x3 matrix shown in Image 2 is a Kernel/Filter and the same sliding matrix in the Image 3 is known as Filter or Kernel. In real world data the input image can be quite big and will contain lots of information most of which is not important for our deep learning or classification problem. To filter out those information which we require in order to solve a problem at our hands we use Kernel or Filters which are both same.
In the Question 1 we saw how we can generate a Convolved Feature matrix and the process involved in achieving it. We can filter out important features using the Convolution method described in Question 1.
Let us understand an intuitive example of Edge detection. The basic intuitive hypothesis for it will be that when we average pixels of an image with its neighbor we get a blurred image and we get edges.
Image 4 | Picture Credit : Denny Britz
Now, in Image 4 we see a matrix and an Image of Taj Mahal and can say that in the smooth parts i.e.
where the value of pixels are same e.g. sky and any point white in Taj Mahal we have same value of pixel represented by the matrix in which we have value [0,0] and [0,1] have values '0' belongs to sky and values in cell [1,2] and [1,3] belong to white parts of Taj Mahal.
When we do the process of Convolution described in Question 1, we slide the filters with stride 1 and the two matrix are multiplied and added, when we do it for the smooth part of the image during the 'addition part' (where we get Convolved Feature) the resulting value gets to 0 because that particular portion of image was smooth, but when we have different values in the neighboring cells we get a change in value e.g. blue to white we get large difference. And there is where we get an Edge.
Image 5 | Picture Credit : Denny Britz
Image 5 is a representational image of learned edges if our Image 4 was Black and White. And we can use different kernel and filters to learn different features based on our problem for Computer vision problems.
So in short, Kernel and feature are the matrix which help us filter down or learn the features from the input image which will help us to solve the Computer Vision problem. It only retains the specific features which we want to learn from the input image.
-
-
Batch Normalization
batch normalization generally applies when drastically large input distribution because of large value it create disturbance in nurons ,And it's perform as specific layer when its perform input pass through activation function its scale to specific range and its improve training speed.
-
Image Normalization
Scale image between 0 and 1 by doing image /= 255, normalize in scale of 0 and 1.
-
Position of MaxPooling
In transition block we preform max pooling (MP) its basically C-C-C-MP this is transaction block, but before softmax not to perform MP because its loose some important feature.
-
Concept of Transition Layers
As above explanation C-C-C-MP that is block-1 there is so many blokes in network when we are combining some block to next block link block-4 output to block-1.
-
Position of Transition Layer
Its perform before output layer.
-
Number of Epochs and when to increase them
In general language Epochs can be defined as the number of time our learning algorithm has seen the complete training data i.e. all the images in our training data has been through the algorithm and based on the in accuracies of the output we perform a backward pass aiming to lower the value of loss function. This complete one forward and one backward pass of all the instances of training data is termed as an Epoch.
The difference between an iteration and Epoch is that the any neural network first divide the whole training data set into batches e.g. If there are 1000 images in our training data set we divide them into batch of 4 i.e. 500 each. Then every time a batch of 500 is processed we get one iteration. So in our example we will require 4 iteration to complete an Epoch.
Multiple Epochs are needed to converge any deep learning neural network, as using a single Epoch will train a model that is under-fit and will be of no use. The reason behind why we need multiple Epoch or why one epoch will not have much effect on weight is because generally we use Gradient Descent algorithm for learning the weights, so with one epoch we might not end up with weights that minimize our loss function, that is we may not have the best minima and there can be other minimas which can reduce the loss function even further, so we require more amount of epochs till we make gains in achieving minimization or till our algorithm converges.
-
DropOut
While testing dropping some trained neurons for exp. 100 neurons we trained, Droupout(0.25) meas that among 100 neurons we are using 75 neurons for validation this technique proposed by Srivastava in 2014.
-
When do we introduce DropOut, or when do we know we have some overfitting
When taring and testing accuracy gap is more then we can go for dropout.
-
The distance of MaxPooling from Prediction
We can't preform max-pooling at just before output layer, Because we are missing some important feature from kernels. used to prefer after convolution block.like C-C-C-MP.
-
The distance of Batch Normalization from Prediction
Batch normalization basically normalize value at specific layer we can't just put above output layer because it normalize output it make impact on output, we place generally at before the transaction layer or after transaction layer.
-
When do we stop convolutions and go ahead with a larger kernel or some other alternative (which we have not yet covered)
when we able to see receptive field of data, Kernels with a large size can be helpful for incorporating information with large receptive fields, but two successive layers can increase the receptive field, mitigating this advantage.
To explain what I mean: a kernel of size 3x3 can “see” (has a receptive field of) a 9 pixel square. By contrast, a 5x5 kernel size has a receptive field of 25 pixels in a square. This means that during each dot product, the kernel will be able to incorporate more information. So bigger kernel sizes=better, right
As it turns out, you can get the same receptive field size by stacking two 3x3 layers. Ignoring computational benefits (although they're quite large, since too many parameters can lead to overfitting), if you have two stacked layers, you can insert nonlinearities between them, which increases the representational power of the network and subsequently, leads to an accuracy increase.
-
How do we know our network is not going well, comparatively, very early
In first few epoch what is training and test accuracy compare to previous one, after final network each epoch training accuracy is improving or adding batch norm and dropout .
-
Batch Size, and effects of batch size
Batch size is defined as number of images pass for froward propagation at once.
Batch size increases RAM memory increased batch size effect on memory because of foreword pass store all images to memory.
-
When to add validation checks
After training each epoch we should do validation check.
-
LR schedule and concept behind it
when number of epoch increases LR should decrease for good deep neural network.
-
Adam vs SGD
Optimizer algorithms is used to minimize error rate and reach at global receptive field, Adam is an algorithm for gradient-based optimization of stochastic objective functions.It combines the advantages of two SGD extensions — Root Mean Square Propagation (RMSProp) and Adaptive Gradient Algorithm (AdaGrad) — and computes individual adaptive learning rates for different parameters. (To learn more about Adam, Synced recommends .Adam latest trends in deep learning optimization.) based on conclusion we can use any optimiser based on our need.