**Please note that this is not the repo for the MSG-GAN research paper. Please head over to the msg-stylegan-tf repository for the official code and trained models for the MSG-GAN paper.
MSG-GAN (Multi-Scale Gradients GAN): A Network architecture inspired from the ProGAN.
The architecture of this gan contains connections between the intermediate layers of the singular Generator and the Discriminator. The network is not trained by progressively growing the layers. All the layers get trained at the same time.
Implementation uses the PyTorch framework.

Please note that all the samples at various scales are generated by the network simultaneously.
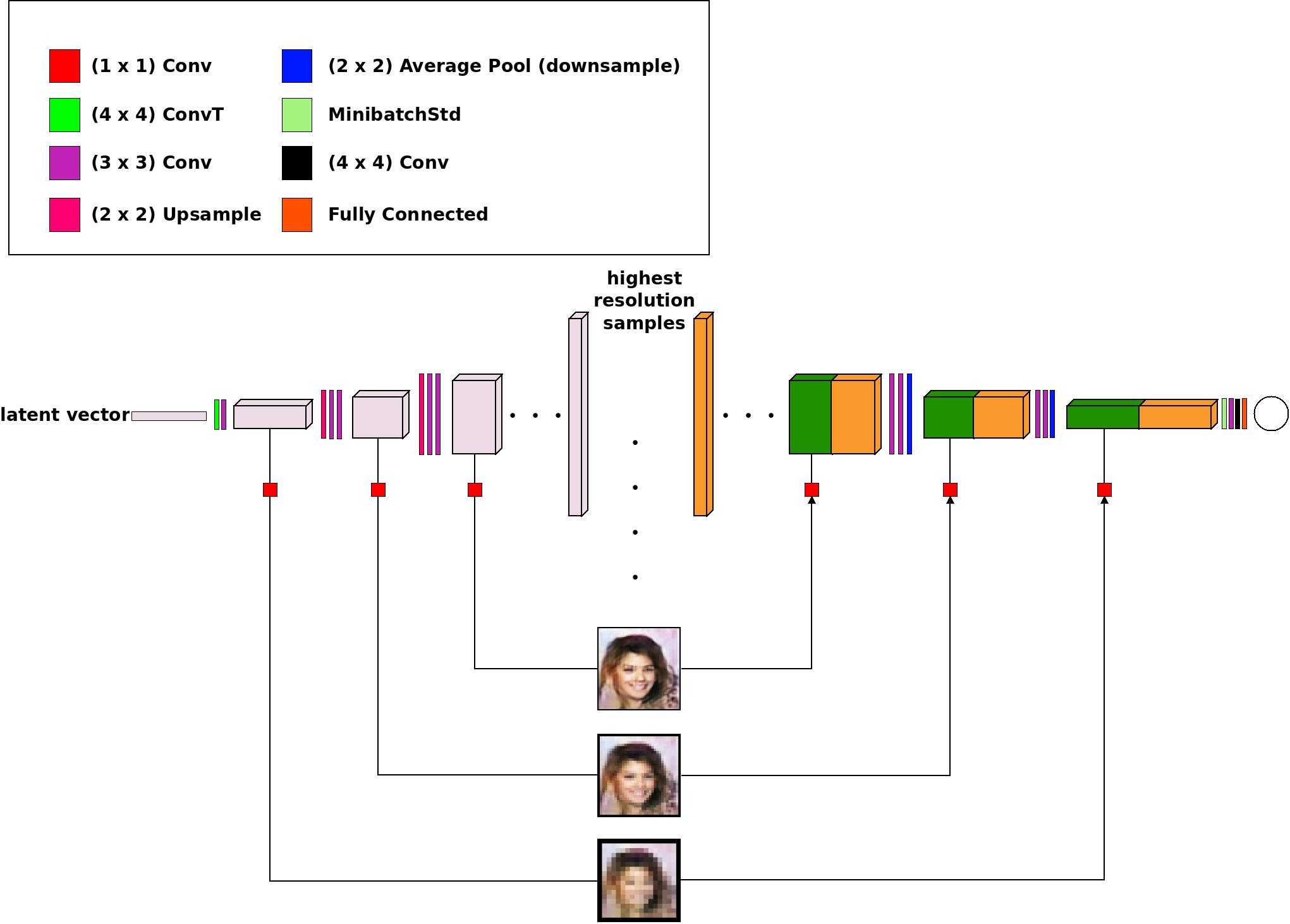
The above figure describes the architecture of the proposed Multi-Scale gradients GAN. As you can notice, from every intermediate layer of the Generator, a particular resolution image is extracted through (1 x 1) convolutions. These extracted images are in turn fed to the appropriate layers of the Discriminator. This allows for gradients to flow from the Discriminator to the Generator at multiple scales.
For the discrimination process, appropriately downsampled versions of the real images are fed to corresponding layers of the discriminator as shown in the diagram.
The problem of occurence of random gradients for GANs at the higher resolutions is tackled by layerwise training in the ProGAN paper. I present another solution for it. I have run the following experiment that preliminarily validates the proposed approach.

Above figure explains how the Meaningful Gradients penetrate the Generator from Bottoms-up. Initially, only the lower resolution gradients are menaingful and thus start generating good images at those resolutions, but eventually, all the scales synchronize and start producing images. This results in a stabler training for the higher resolution.
I ran the experiment on a skimmed version of the architecture as described in the
ProGAN paper. Following table summarize the details of the Networks:
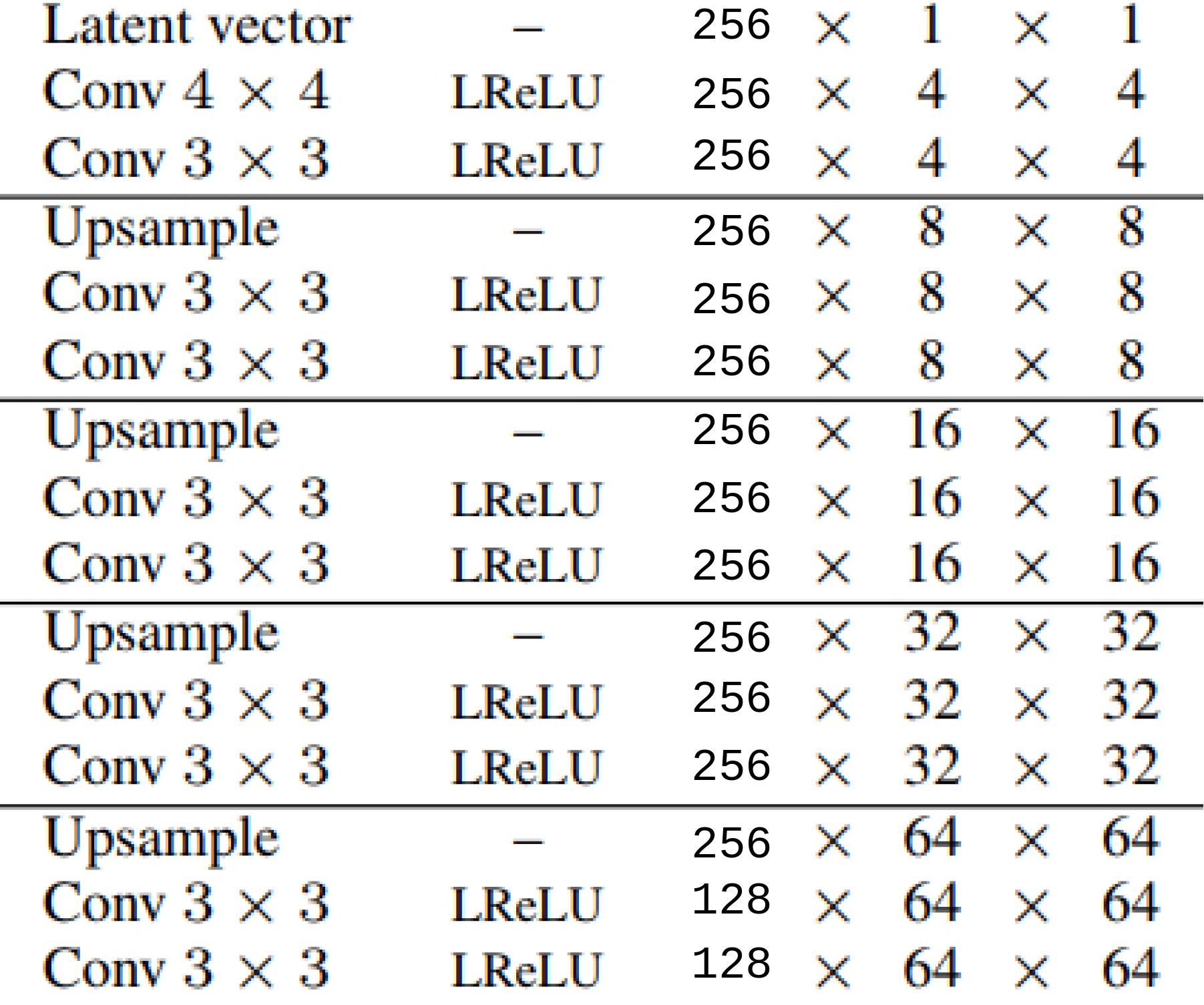
For extracting images after every 3 layer block at that resolution, I used 1 x 1 convolutions. Similar operation is performed for feeding the images to discriminator intermediate layers.
The architecture for the discriminator is also the same (reverse mirror), with the distinction that half of the channels come from the (1 x 1 convolution) transformed downsampled real images and half from conventional top-to-bottom path.
All the 3 x 3 convolution weights have a forward hook that applies
spectral normalization on them. Apart from that, in the discriminator
for the 4 x 4 layer, there is a MinibatchStd layer for improving
sample diversity. No other stablization techniques are applied.
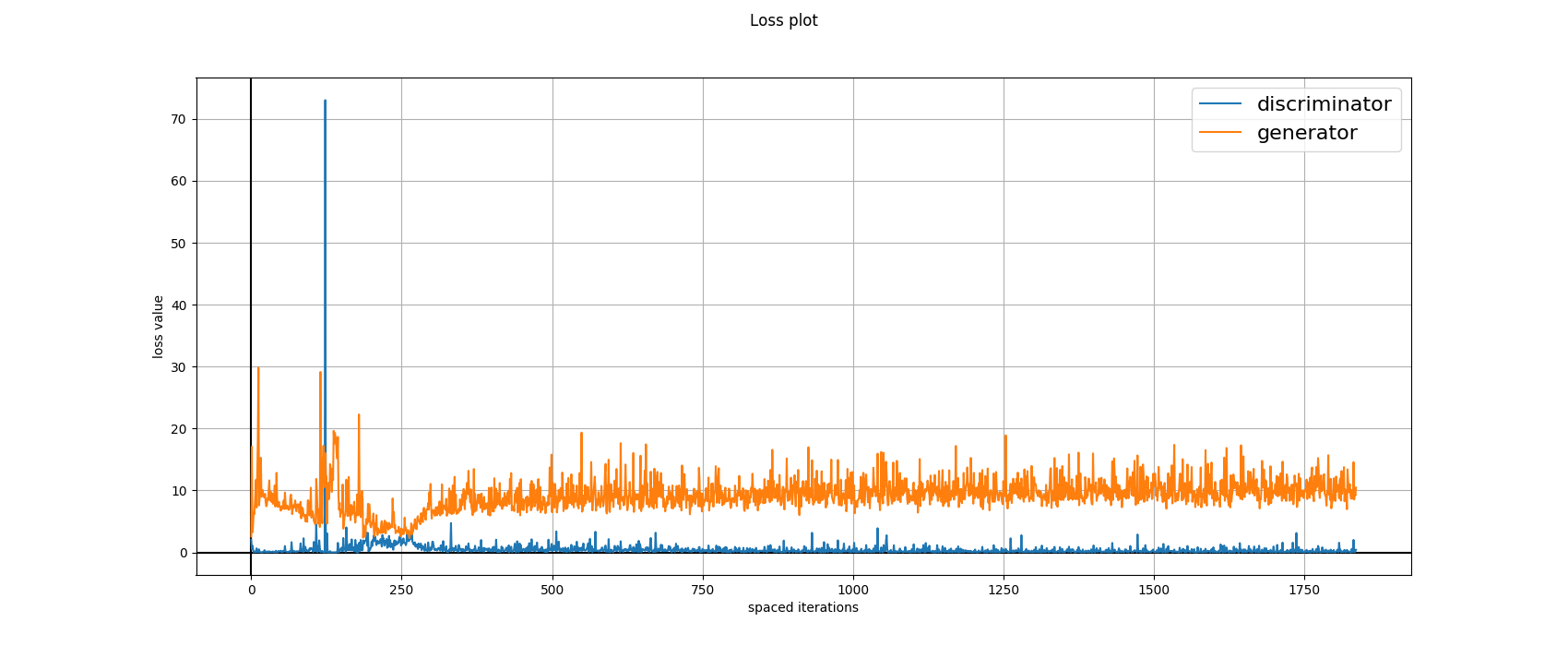
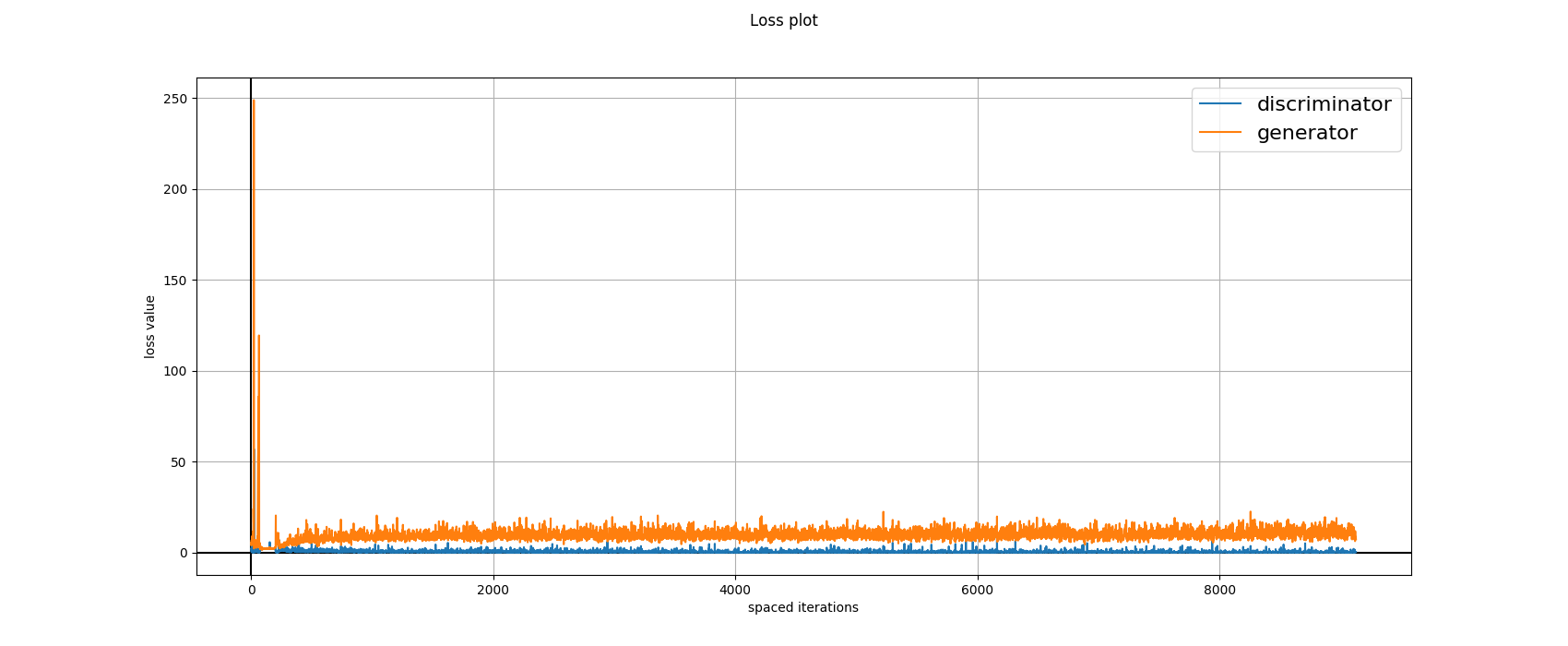
The above diagrams are the loss plots obtained during
training the Networks in an adversarial manner. The loss function used is
Relativistic Hinge-GAN. Apart from some initial aberrations, the training
has stayed smooth.
Please note to use value of learning_rate=0.0003 for both G and D for all experiments.
TTUR doesn't work with this architecture (from experience). And, you can find other better
learning rates, but the value 0.0003 always seems to work.
Running the training is actually very simple.
Just start the training by running the train.py script in the sourcecode/
directory. Refer to the following parameters for tweaking for your own use:
-h, --help show this help message and exit
--generator_file GENERATOR_FILE
pretrained weights file for generator
--discriminator_file DISCRIMINATOR_FILE
pretrained_weights file for discriminator
--images_dir IMAGES_DIR
path for the images directory
--sample_dir SAMPLE_DIR
path for the generated samples directory
--model_dir MODEL_DIR
path for saved models directory
--loss_function LOSS_FUNCTION
loss function to be used: 'hinge', 'relativistic-
hinge'
--depth DEPTH Depth of the GAN
--latent_size LATENT_SIZE
latent size for the generator
--batch_size BATCH_SIZE
batch_size for training
--start START starting epoch number
--num_epochs NUM_EPOCHS
number of epochs for training
--feedback_factor FEEDBACK_FACTOR
number of logs to generate per epoch
--num_samples NUM_SAMPLES
number of samples to generate for creating the grid
should be a square number preferably
--gen_dilation GEN_DILATION
amount of dilation for the generator
--dis_dilation DIS_DILATION
amount of dilation for the discriminator
--checkpoint_factor CHECKPOINT_FACTOR
save model per n epochs
--g_lr G_LR learning rate for generator
--d_lr D_LR learning rate for discriminator
--adam_beta1 ADAM_BETA1
value of beta_1 for adam optimizer
--adam_beta2 ADAM_BETA2
value of beta_2 for adam optimizer
--use_spectral_norm USE_SPECTRAL_NORM
Whether to use spectral normalization or not
--data_percentage DATA_PERCENTAGE
percentage of data to use
--num_workers NUM_WORKERS
number of parallel workers for reading files
For training a network as per the ProGAN CelebaHQ experiment, use the following arguments:
$ python train.py --depth=9 \
--latent_size=512 \
--images_dir=<path to CelebaHQ images> \
--sample_dir=samples/CelebaHQ_experiment \
--model_dir=models/CelebaHQ_experiment
Set the batch_size, feedback_factor and checkpoint_factor accordingly.
This experiment was carried out by me on a DGX-1 machine. The samples displayed in Figure 1. of this readme are the output of this experiment.
You can use the models pretrained for 3 epochs at [1024 x 1024] for your training. These are available at -> https://drive.google.com/drive/folders/119n0CoMDGq2K1dnnGpOA3gOf4RwFAGFs
Please refer to the models/Celeba/1/GAN_GEN_3.pth for the saved weights for
this model in PyTorch format.
medium blog -> https://medium.com/@animeshsk3/msg-gan-multi-scale-gradients-gan-ee2170f55d50
Training video -> https://www.youtube.com/watch?v=dx7ZHRcbFr8
Please feel free to open PRs here if
you train on other datasets using this architecture.
Best regards,
@akanimax :)