对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction), 在CTR问题的探究历史上来看就是如何更好地学习特征组合,进而更加精确地描述数据的特点。可以说这是基础推荐模型到深度学习推荐模型遵循的一个主要的思想。而组合特征大牛们研究过组合二阶特征,三阶甚至更高阶,但是面临一个问题就是随着阶数的提升,复杂度就成几何倍的升高。这样即使模型的表现更好了,但是推荐系统在实时性的要求也不能满足了。所以很多模型的出现都是为了解决另外一个更加深入的问题:如何更高效的学习特征组合?
为了解决上述问题,出现了FM和FFM来优化LR的特征组合较差这一个问题。并且在这个时候科学家们已经发现了DNN在特征组合方面的优势,所以又出现了FNN和PNN等使用深度网络的模型。但是DNN也存在局限性。
- DNN局限 当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片:
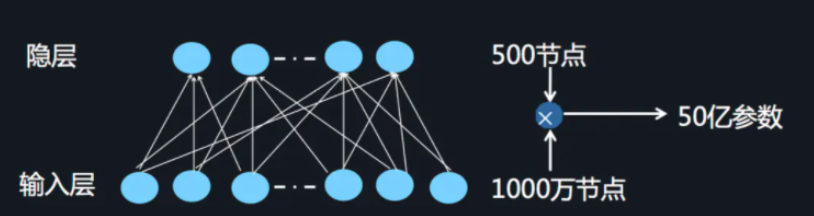
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
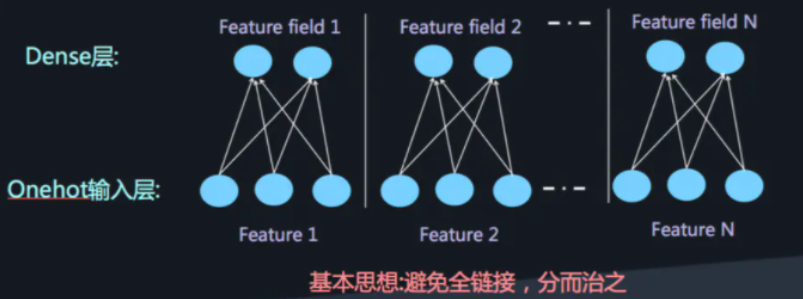
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
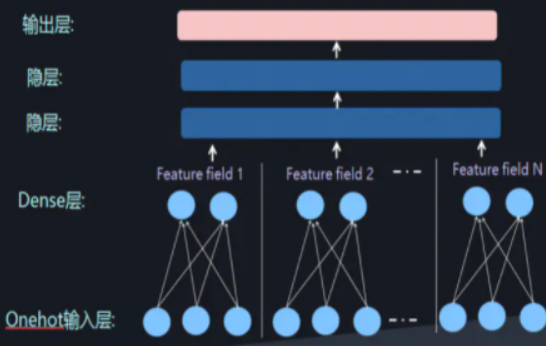
- FNN和PNN 结合FM和DNN其实有两种方式,可以并行结合也可以串行结合。这两种方式各有几种代表模型。在DeepFM之前有FNN,虽然在影响力上可能并不如DeepFM,但是了解FNN的思想对我们理解DeepFM的特点和优点是很有帮助的。
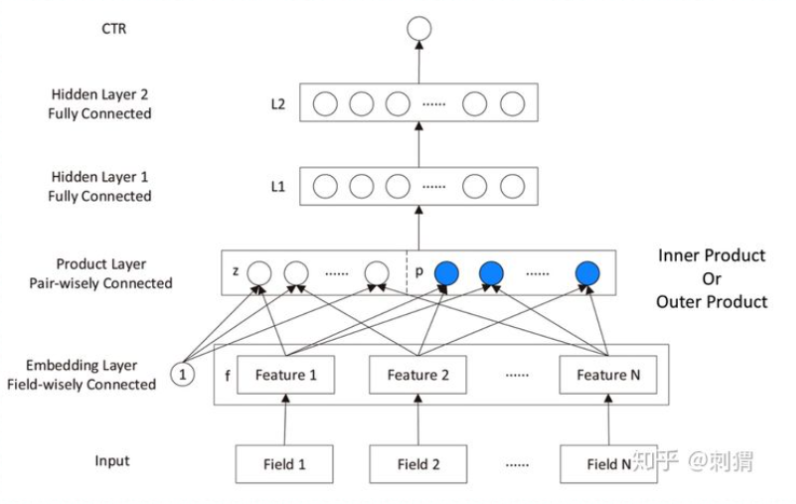
FNN是使用预训练好的FM模块,得到隐向量,然后把隐向量作为DNN的输入,但是经过实验进一步发现,在Embedding layer和hidden layer1之间增加一个product层(如上图所示)可以提高模型的表现,所以提出了PNN,使用product layer替换FM预训练层。
- Wide&Deep FNN和PNN模型仍然有一个比较明显的尚未解决的缺点:对于低阶组合特征学习到的比较少,这一点主要是由于FM和DNN的串行方式导致的,也就是虽然FM学到了低阶特征组合,但是DNN的全连接结构导致低阶特征并不能在DNN的输出端较好的表现。看来我们已经找到问题了,将串行方式改进为并行方式能比较好的解决这个问题。于是Google提出了Wide&Deep模型(将前几章),但是如果深入探究Wide&Deep的构成方式,虽然将整个模型的结构调整为了并行结构,在实际的使用中Wide Module中的部分需要较为精巧的特征工程,换句话说人工处理对于模型的效果具有比较大的影响(这一点可以在Wide&Deep模型部分得到验证)。
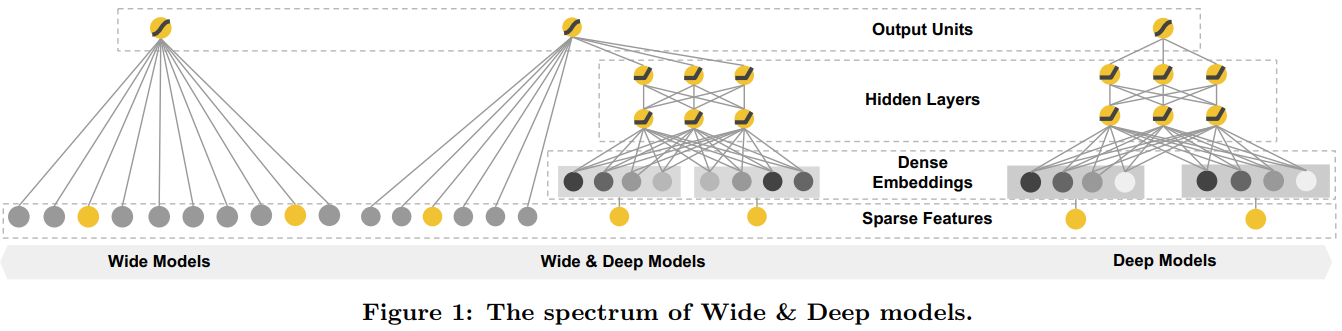
综上所示,DeepFM模型横空出世。
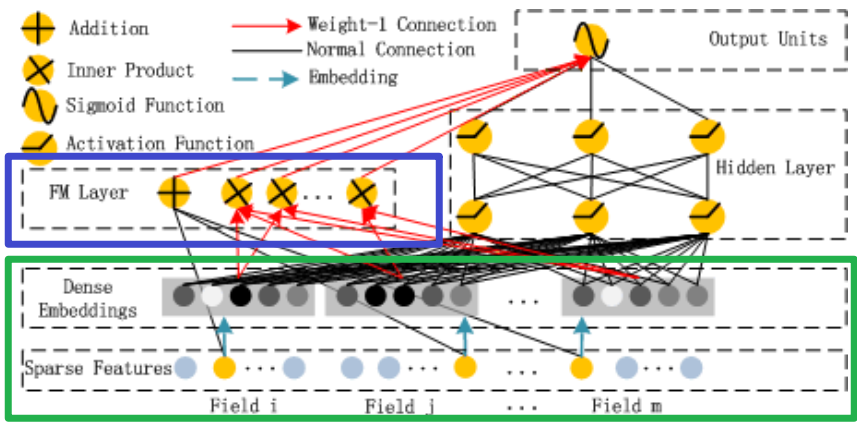
前面的Field和Embedding处理是和前面的方法是相同的,如上图中的绿色部分;DeepFM将Wide部分替换为了FM layer如上图中的蓝色部分
这幅图其实有很多的点需要注意,很多人都一眼略过了,这里我个人认为在DeepFM模型中有三点需要注意:
- Deep模型部分
- FM模型部分
- Sparse Feature中黄色和灰色节点代表什么意思
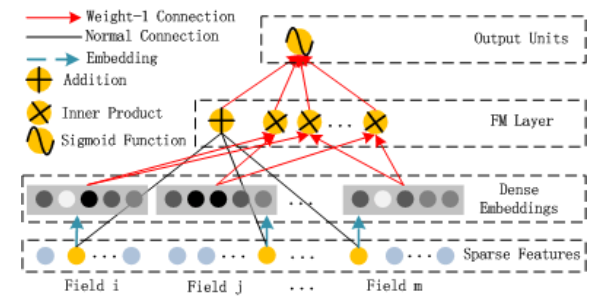
详细内容参考FM模型部分的内容,下图是FM的一个结构图,从图中大致可以看出FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits(结合FM的公式一起看),所以在实现的时候需要单独考虑linear部分和FM交叉特征部分。 $$ \hat{y}{FM}(x) = w_0+\sum{i=1}^N w_ix_i + \sum_{i=1}^N \sum_{j=i+1}^N v_i^T v_j x_ix_j $$
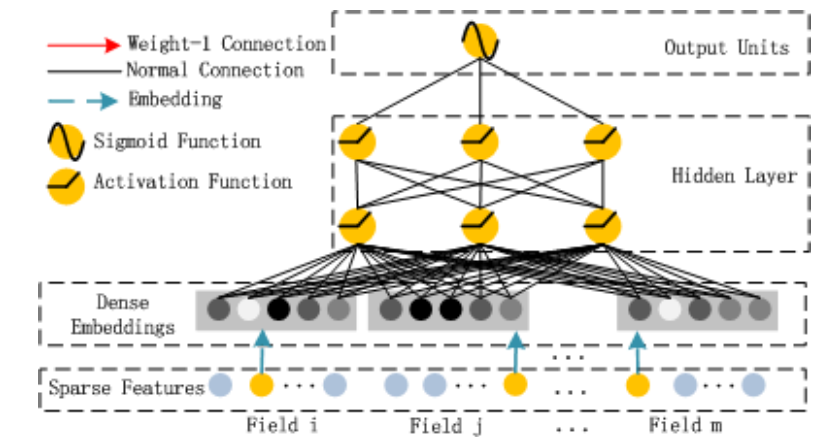
Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。其中$v_i$表示第i个field的embedding,m是field的数量。 $$ z_1=[v_1, v_2, ..., v_m] $$ 上一层的输出作为下一层的输入,我们得到: $$ z_L=\sigma(W_{L-1} z_{L-1}+b_{L-1}) $$ 其中$\sigma$表示激活函数,$z, W, b $分别表示该层的输入、权重和偏置。
最后进入DNN部分输出使用sigmod激活函数进行激活: $$ y_{DNN}=\sigma(W^{L}a^L+b^L) $$
DeepFM在模型的结构图中显示,模型大致由两部分组成,一部分是FM,还有一部分就是DNN, 而FM又由一阶特征部分与二阶特征交叉部分组成,所以可以将整个模型拆成三部分,分别是一阶特征处理linear部分,二阶特征交叉FM以及DNN的高阶特征交叉。在下面的代码中也能够清晰的看到这个结构。此外每一部分可能由是由不同的特征组成,所以在构建模型的时候需要分别对这三部分输入的特征进行选择。
- linear_logits: 这部分是有关于线性计算,也就是FM的前半部分$w1x1+w2x2...wnxn+b$的计算。对于这一块的计算,我们用了一个get_linear_logits函数实现,后面再说,总之通过这个函数,我们就可以实现上面这个公式的计算过程,得到linear的输出, 这部分特征由数值特征和类别特征的onehot编码组成的一维向量组成,实际应用中根据自己的业务放置不同的一阶特征(这里的dense特征并不是必须的,有可能会将数值特征进行分桶,然后在当做类别特征来处理)
- fm_logits: 这一块主要是针对离散的特征,首先过embedding,然后使用FM特征交叉的方式,两两特征进行交叉,得到新的特征向量,最后计算交叉特征的logits
- dnn_logits: 这一块主要是针对离散的特征,首先过embedding,然后将得到的embedding拼接成一个向量(具体的可以看代码,也可以看一下下面的模型结构图),通过dnn学习类别特征之间的隐式特征交叉并输出logits值
def DeepFM(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# embedding层用户构建FM交叉部分和DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 将输入到dnn中的所有sparse特征筛选出来
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
# 将所有的Embedding都拼起来,一起输入到dnn中
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,FM,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layers = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layers)
return model关于每一块的细节,这里就不解释了,在我们给出的GitHub代码中,我们已经加了非常详细的注释,大家看那个应该很容易看明白, 为了方便大家的阅读,我们这里还给大家画了一个整体的模型架构图,帮助大家更好的了解每一块以及前向传播(画的图不是很规范,先将就看一下,后面我们会统一在优化一下这个手工图)。
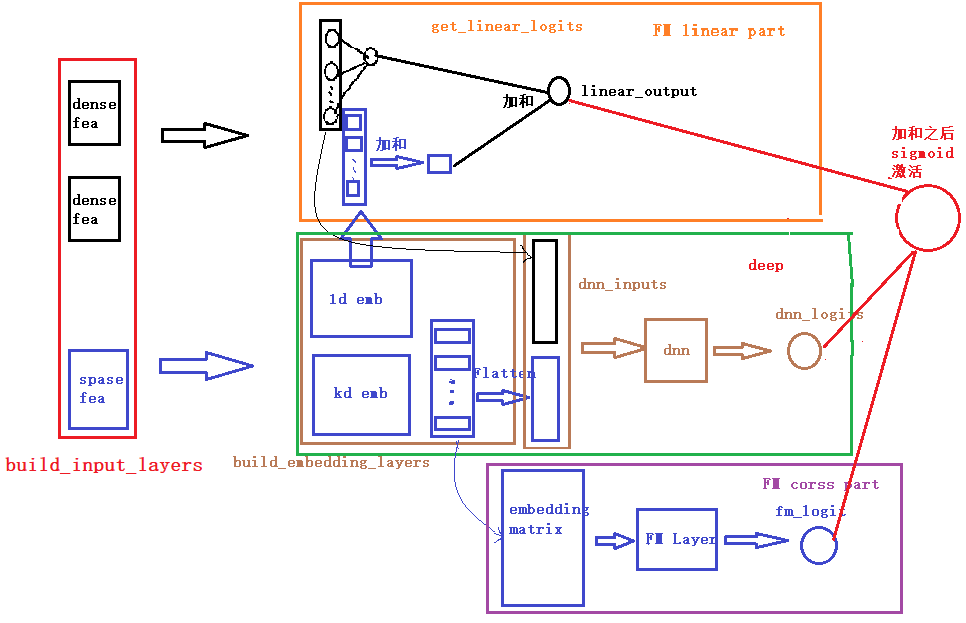
下面是一个通过keras画的模型结构图,为了更好的显示,数值特征和类别特征都只是选择了一小部分,画图的代码也在github中。

- 如果对于FM采用随机梯度下降SGD训练模型参数,请写出模型各个参数的梯度和FM参数训练的复杂度
- 对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思
参考资料