Каждый раз, когда Вы открываете браузер, вводите URL-адрес и нажимаете клавишу enter, вы видите красивые веб-страницы на вашем экране. Но знаете ли вы, что стоит за этим простым действием?
Обычно ваш браузер, как клиент, отправляет запрос к DNS серверу и получает IP адрес, соответствующий введенному вами URL. Затем он находит соответствующий сервер по IP-адресу и запрашивает установку TCP-соединения. Когда браузер закончит отправку HTTP запросов, сервер запускает обработку этих запросов и затем возвращает пакеты HTTP ответов в ваш браузер. И, наконец, браузер отрисовывает текст веб-страниц и отключается от сервера.

Рисунок 3.1 процессы происходящие при посещении веб-сайта
Веб-сервер также называют HTTP сервером; Он использует протокол HTTP для взаимодействия с клиентами. Все веб-браузеры могут рассматриваться в качестве клиентов веб-сервера.
Мы можем представить принципы работы Веб в виде следующих шагов:
- Клиент использует протокол TCP/IP для подключения к серверу.
- Клиент отправляет пакеты HTTP запросов на сервер.
- Сервер возвращает пакеты HTTP ответов клиенту. Если запрос ресурсов включает динамические скрипты, то сервер сначала вызывает обработчик сценариев.
- Клиент отключается от сервера и начинает рендеринг HTML.
Это пример простого сценария работы по HTTP протоколу. Обратите внимание, что сервер закрывает соединение сразу же после того, как он направил данные клиенту, а затем ждет следующего запроса.
Мы всегда используем URL для доступа к веб-страницам, но знаете ли вы как работает URL?
URL расшифровывается как Uniform Resource Locator, в переводе на русский - единый указатель ресурса. URL служит стандартизированным способом записи адреса ресурса в сети Интернет. Структура URL в общем виде выглядит следующим образом:
<схема>://<хост>:<порт>/<URL‐путь>?<параметры>#<якорь>
<схема> назначение базового протокола (например, HTTP, HTTPS, ftp)
<хост> IP-адрес или доменное имя HTTP сервера
<порт> по умолчанию используется порт 80, в этом случае данный параметр обычно не указывается
Если вы хотите использовать другие порты, необходимо указать, какой порт нужно использовать.
Например, http://www.cnblogs.com:8080/
<URL-путь> путь к ресурсу
<параметры> данные, которые будут отправлены на сервер
<якорь> якорьDNS - это аббревиатура Domain Name System - система доменных имен. Это система имен для компьютерных сетевых служб, которая преобразует доменное имя в фактические IP-адреса (своеобразный переводчик).

Рисунок 3.2 принципы работы DNS
Для понимания принципов работы DNS давайте подробно рассмотрим процесс разрешения имен DNS.
- После того, как вы введете доменное имя в вашем браузере (например
www.qq.com), операционная система должна проверить, существует ли сопоставление IP адреса данному доменному имени в файле hosts на вашем компьютере, если такое соответствие найдено, разрешение имени завершается. - Если соответствие в hosts не найдено, операционная система должна проверить локальный кэш DNS. Если в локальном кэше соответствие найдено, то разрешение доменного имени завершается.
- Если соответствие не найдено ни в hosts ни в кэше DNS, операционная система находит первый по списку сервер DNS, обозначенный в настройках TCP/IP, который, как правило, является локальным DNS сервером. Когда локальный DNS-сервер получает запрос, он проверяет, содержится ли запрашиваемое доменное имя в локальной конфигурации региональных ресурсов, а затем возвращает результаты клиенту. Это разрешение DNS является авторитетным.
- Если локальный DNS не содержит информацию о доменном имени и соответствия не найдены в кэше, локальный DNS сервер возвращает этот результат клиенту. Это разрешение DNS не является авторитетным.
- Если локальный DNS не смог разрешить данное доменное имя локальной конфигурацией региональных ресурсов или кэшем, он переходит к следующему шагу, зависящему от локальных настроек DNS сервера. Если локальный DNS не является рекурсивным, он отправляет запрос к корневому DNS серверу, а затем возвращает IP адреса DNS серверов верхнего уровня, которые могут знать доменное имя
.comв нашем примере. Если первый DNS сервер верхнего уровня ничего не знает о запрашиваемом имени, он отправляет запрос следующему верхнеуровневому DNS и так происходит до тех пор, пока кто-нибудь из них не узнает доменное имя. Затем DNS сервер верхнего уровня запрашивает у DNS сервера следующего уровня информацию о доменеqq.com, затем находит информацию о доменеwww.qq.comна других серверах. - Если DNS сервер является рекурсивным, он отправляет запрос DNS серверу более высоко уровня. Если DNS сервер более высокого уровня также не знает имя домена, он продолжает посылать запрос на более высокий уровень. Если локальный DNS является рекурсивным, разрешенное в IP адрес доменное имя возвращается к локальному DNS серверу, который, в свою очередь, отправляет его клиенту.

Рисунок 3.3 схема разрешения доменного имени
Термином Рекурсия в DNS обозначают алгоритм поведения DNS-сервера, при котором сервер выполняет от имени клиента полный поиск нужной информации во всей системе DNS, при необходимости обращаясь к другим DNS-серверам.
Теперь мы знаем, как происходит преобразование доменного имени в IP адрес. Браузеры взаимодействуют с серверами посредством IP-адресов.
Протокол HTTP является ключевой частью веб-приложений. Необходимо полное понимание HTTP протокола прежде чем вы сможете понять, как работает веб.
HTTP — протокол, который используется для обмена данными между браузерами и веб-серверами. Он базируется на протоколе TCP и обычно использует 80-й порт на стороне веб-сервера. HTTP использует модель запрос - ответ: клиент отправляет запрос, а сервер возвращает ответ. В соответствии с HTTP протоколом, клиент всегда устанавливает новое соединение с сервером и отправляет HTTP новый запрос. Сервер не может подключиться к клиенту проактивно (или установить обратное соединение). Связь между клиентом и сервером может быть закрыта с обеих сторон. Например вы всегда можете отменить загрузку файла и прервать HTTP соединение. Это приведет к отключению от сервера до завершения процесса загрузки.
HTTP является протоколом независимой обработки соединений. Это означает, что сервер не имеет никакого представления о взаимосвязи между двумя соединениями, даже несмотря на то, что они от одного клиента. Для решения этой проблемы веб-приложения используют файлы cookie для сохранения информации о состоянии соединений.
Поскольку HTTP протокол базируется на TCP протоколе, все атаки, характерные для TCP, такие как: SYN Flood, DoS and DDoS, будут влиять на связь по протоколу HTTP.
Все пакеты запросов состоят из трех частей: строка запроса, заголовок запроса и тело запроса. Между заголовком запроса и телом запроса идет одна пустая строка.
GET /domains/example/ HTTP/1.1 // request line: request method, URL, protocol and its version
Host:www.iana.org // имя домена
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 //информация о браузере
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 // означает, что клиент может принимать запросы
Accept-Encoding:gzip,deflate,sdch // потоковое сжатие
Accept-Charset:UTF-8,*;q=0.5 // кодировка на стороне клиента
// пустая строка
// тело, запрос ресурсов, аргументы (например аргументы, переданные в POST)Мы используем fiddler для получения сведений о запросах.
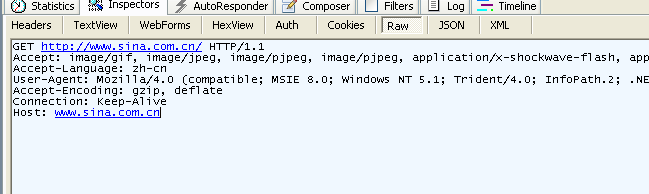
Рисунок 3.4 Информация о методе GET, перехваченная fiddler
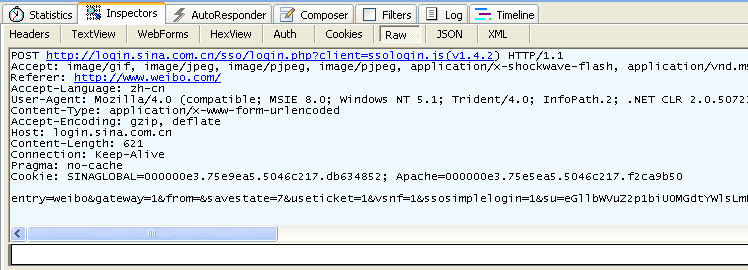
Рисунок 3.5 информация о методе POST, перехваченная fiddler
Обратите внимание, что метод GET не имеет тела запроса, а метод POST имеет
Есть много методов, которые можно использовать для взаимодействия с серверами по HTTP. Четыре основных метода, которые мы будем использовать, это GET, POST, PUT, DELETE. Эти четыре метода означают запрос, изменение, добавление и удаление соответственно. GET и POST используются в HTTP чаще всего. GET добавляет данные в URL и использует ? в качестве разделителя данных, а & в качестве разделителя аргументов. Например: EditPosts.aspx?name=test1&id=123456.
POST помещает данные в теле запроса, поскольку URL имеет ограничение длины, заданное браузером, так что POST может предоставить гораздо больше данных, чем метод GET. Например, когда мы отправляем на сервер логин и пароль, то весьма нежелательно, чтобы эта информация содержалась в URL запроса, поэтому, логичнее было бы использовать для передачи таких данных метод POST, чтобы сделать их невидимыми.
Давайте посмотрим, какая информация содержится в пакетах ответов.
HTTP/1.1 200 OK // строка состояния
Server: nginx/1.0.8 // название сервера и его версия
Date:Date: Tue, 30 Oct 2012 04:14:25 GMT // время ответа
Content-Type: text/html // тип данных ответа
Transfer-Encoding: chunked // это означает, что данные были отправлены фрагментами
Connection: keep-alive // сохранить подключение
Content-Length: 90 // длина тела (размер)
// пустая строка
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... // тело сообщенияПервая строка называется строкой состояния, она состоит из версии протокола HTTP, кода состояния и сообщения состояния.
Клиент узнаёт по коду состояния о результатах его запроса и определяет, какие действия ему предпринимать дальше. В HTTP/1.1 определено 5 видов кодов состояний:
- 1xx информационные коды
- 2xx коды успешного завершения
- 3xx коды перенаправления
- 4xx ошибка клиента
- 5xx ошибка сервера
Давайте рассмотрим несколько примеров пакетов ответа и обратим внимание на коды состояний. 200 означает, что сервер отработал корректно, 302 означает перенаправление.

Рисунок 3.6 полная запись ответов сервера при посещении веб-сайта
Независимая обработка запросов вовсе не означает, что сервер не имеет возможности поддерживать соединение. Независимая обработка означает, что сервер ничего не знает о взаимосвязи между запросами.
В HTTP/1.1, Keep-alive соединения используются по умолчанию. Это означает, что множество запросов клиента будут использовать одно подключение.
Обратите внимание, что Keep-alive не может удерживать соединение вечно. Программное обеспечение сервера имеет ограничение по времени на удержание одного соединения. Вы можете изменить это ограничение в настройках сервера.
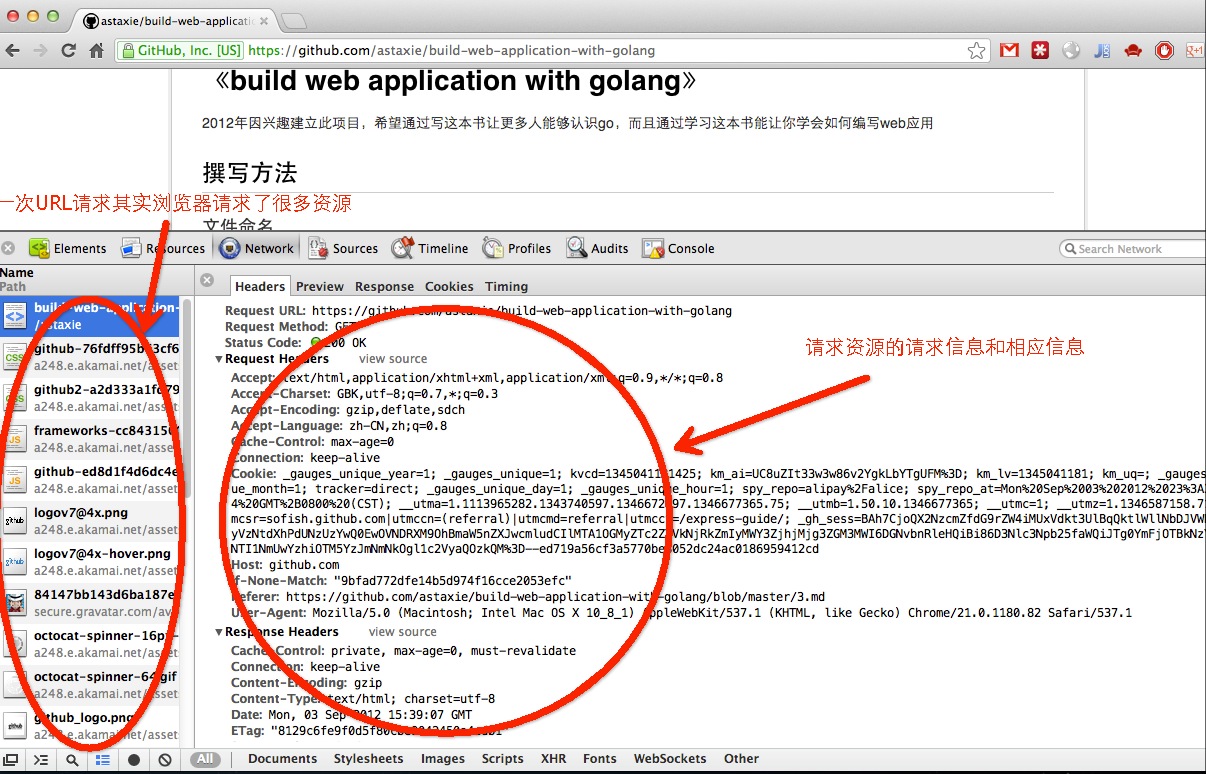
Рисунок 3.7 все пакеты, запрашиваемые и отправляемые при открытии веб-страницы
На этой картинке мы видим весь процесс общения между клиентом и сервером при обращении к веб-странице. Вы наверняка заметили, что в списке очень много файлов с ресурсами. Они называются статическими файлами. В языке Go существуют специальные методы обработки таких файлов.
Получение данных по URL c веб-сервера и последующая визуализация этих данных является важнейшей функцией браузера. Браузер запрашивает все файлы, найденные в DOM, например CSS или JS файлы, до тех пор, пока все ресурсы не визуализируются на экране.
Сокращение времени HTTP запроса является одним из методов повышения скорости загрузки веб-страниц. Можно значительно уменьшить нагрузку на веб-сервера за счет уменьшения размера файлов CSS и JS.
- Содержание
- Предыдущий раздел: Основы Веба
- Следующий раздел: Создание простого веб-сервера