diff --git a/.github/ISSUE_TEMPLATE/bug_report.md b/.github/ISSUE_TEMPLATE/bug_report.md
index bc9683596..66b38c309 100644
--- a/.github/ISSUE_TEMPLATE/bug_report.md
+++ b/.github/ISSUE_TEMPLATE/bug_report.md
@@ -8,9 +8,9 @@ about: Create a report to help us improve
A clear and concise description of what the bug is.
**To Reproduce**
-1. OS used:
-2. SLM-Lab git SHA (run `git rev-parse HEAD`):
-3. `spec` and `config/experiments.json` used:
+1. OS and environment:
+2. SLM Lab git SHA (run `git rev-parse HEAD` to get it):
+3. `spec` file used:
**Additional context**
Add any other context about the problem here.
diff --git a/README.md b/README.md
index b0892907a..2e034ed95 100644
--- a/README.md
+++ b/README.md
@@ -3,310 +3,199 @@
Modular Deep Reinforcement Learning framework in PyTorch.
-|||||
-|:---:|:---:|:---:|:---:|
-|  |  | | |
-| BeamRider | Breakout | Enduro | Pong |
-|  |  |  | |
-| Qbert | Seaquest | SpaceInvaders | |
-
-| | | |
+||||
|:---:|:---:|:---:|
-|  Multitask DQN solving OpenAI Cartpole-v0 and Unity Ball2D. |  DQN Atari Pong solution in SLM Lab. |  DDQN Lunar solution in SLM Lab. |
+|  |  | |
+| BeamRider | Breakout | Pong |
+|  |  |  |
+| Qbert | Seaquest | SpaceInvaders |
+
| References | |
|------------|--|
-| [Github](https://github.com/kengz/SLM-Lab) | Github repository |
| [Installation](#installation) | How to install SLM Lab |
| [Documentation](https://kengz.gitbooks.io/slm-lab/content/) | Usage documentation |
| [Benchmark](https://github.com/kengz/SLM-Lab/blob/master/BENCHMARK.md)| Benchmark results |
-| [Tutorials](https://github.com/kengz/SLM-Lab/blob/master/TUTORIALS.md)| Tutorial resources |
-| [Contributing](https://github.com/kengz/SLM-Lab/blob/master/CONTRIBUTING.md)| How to contribute |
-| [Roadmap](https://github.com/kengz/SLM-Lab/projects) | Research and engineering roadmap |
| [Gitter](https://gitter.im/SLM-Lab/SLM-Lab) | SLM Lab user chatroom |
-SLM Lab is created for deep reinforcement learning research and applications. The design was guided by four principles
-- **modularity**
-- **simplicity**
-- **analytical clarity**
-- **reproducibility**
-#### Modularity
+## Features
-- makes research easier and more accessible: reuse well-tested components and only focus on the relevant work
-- makes learning deep RL easier: the algorithms are complex; SLM Lab breaks them down into more manageable, digestible components
-- components get reused maximally, which means less code, more tests, and fewer bugs
+### [Algorithms](#algorithms)
-#### Simplicity
+SLM Lab implements a number of canonical RL [algorithms](https://github.com/kengz/SLM-Lab/tree/master/slm_lab/agent/algorithm) with reusable **modular components** and *class-inheritance*, with commitment to code quality and performance.
-- the components are designed to closely correspond to the way papers or books discuss RL
-- modular libraries are not necessarily simple. Simplicity balances modularity to prevent overly complex abstractions that are difficult to understand and use
+The benchmark results also include complete [spec files](https://github.com/kengz/SLM-Lab/tree/master/slm_lab/spec/benchmark) to enable full **reproducibility** using SLM Lab.
-#### Analytical clarity
+Below shows the latest benchmark status. See [benchmark results here](https://github.com/kengz/SLM-Lab/blob/master/BENCHMARK.md).
-- hyperparameter search results are automatically analyzed and presented hierarchically in increasingly granular detail
-- it should take less than 1 minute to understand if an experiment yielded a successful result using the [experiment graph](https://kengz.gitbooks.io/slm-lab/content/analytics/experiment-graph.html)
-- it should take less than 5 minutes to find and review the top 3 parameter settings using the [trial](https://kengz.gitbooks.io/slm-lab/content/analytics/trial-graph.html) and [session](https://kengz.gitbooks.io/slm-lab/content/analytics/session-graph.html) graphs
+| **Algorithm\Benchmark** | Atari | Roboschool |
+|-------------------------|-------|------------|
+| SARSA | - | |
+| DQN, distributed-DQN | :white_check_mark: | |
+| Double-DQN, PER-DQN | :white_check_mark: | |
+| REINFORCE | - | |
+| A2C, A3C (N-step & GAE) | :white_check_mark: | |
+| PPO, distributed-PPO | :white_check_mark: | |
+| SIL (A2C, PPO) | | |
-#### Reproducibility
+### [Environments](#environments)
-- only the spec file and a git SHA are needed to fully reproduce an experiment
-- all the results are recorded in [BENCHMARK.md](https://github.com/kengz/SLM-Lab/blob/master/BENCHMARK.md)
-- experiment reproduction instructions are submitted to the Lab via [`result` Pull Requests](https://github.com/kengz/SLM-Lab/pulls?utf8=%E2%9C%93&q=is%3Apr+label%3Aresult+)
-- the full experiment datas contributed are [public on Dropbox ](https://www.dropbox.com/sh/y738zvzj3nxthn1/AAAg1e6TxXVf3krD81TD5V0Ra?dl=0)
+SLM Lab integrates with multiple environment offerings:
+ - [OpenAI gym](https://github.com/openai/gym)
+ - [OpenAI Roboschool](https://github.com/openai/roboschool)
+ - [VizDoom](https://github.com/mwydmuch/ViZDoom#documentation) (credit: joelouismarino)
+ - [Unity environments](https://github.com/Unity-Technologies/ml-agents) with prebuilt binaries
-## Features
+*Contributions are welcome to integrate more environments!*
+
+### [Metrics and Experimentation](#experimentation-framework)
+
+To facilitate better RL development, SLM Lab also comes with prebuilt *metrics* and *experimentation framework*:
+- every run generates metrics, graphs and data for analysis, as well as spec for reproducibility
+- scalable hyperparameter search using [Ray tune](https://ray.readthedocs.io/en/latest/tune.html)
-#### [Algorithms](#link-algos)
-- numerous canonical algorithms ([listed below](#algorithm))
-- reusable and well-tested modular components: algorithm, network, memory, policy
-- simple and easy to use for building new algorithms
-
-#### Environments
-- supports multiple environments:
- - [OpenAI gym](https://github.com/openai/gym)
- - [VizDoom](https://github.com/mwydmuch/ViZDoom#documentation) (credit: joelouismarino)
- - [Unity environments](https://github.com/Unity-Technologies/ml-agents) with prebuilt binaries
- - *contributions welcome!*
-- supports multi-agents, multi-environments
-- API for adding custom environments
-
-#### [Experimentation](#experimentation-framework)
-- scalable hyperparameter search using [ray](https://github.com/ray-project/ray)
-- analytical clarity with auto-generated results and graphs at session, trial, experiment levels
-- fitness metric as a richer measurement of an algorithm's performance
## Installation
-1. Clone the [SLM-Lab repo](https://github.com/kengz/SLM-Lab):
+1. Clone the [SLM Lab repo](https://github.com/kengz/SLM-Lab):
```shell
git clone https://github.com/kengz/SLM-Lab.git
```
-2. Install dependencies (or inspect `bin/setup_*` first):
+2. Install dependencies (this uses Conda for optimality):
```shell
cd SLM-Lab/
bin/setup
```
->For optional extra setup, use `bin/setup extra` instead. E.g. to install Unity environments
->Alternatively, run the content of [`bin/setup_macOS` or `bin/setup_ubuntu`](https://github.com/kengz/SLM-Lab/tree/master/bin) on your terminal manually.
->Docker image and Dockerfile with instructions are also available
+ >Alternatively, instead of `bin/setup`, copy-paste from [`bin/setup_macOS` or `bin/setup_ubuntu`](https://github.com/kengz/SLM-Lab/tree/master/bin) into your terminal to install manually.
->Useful reference: [Debugging](https://kengz.gitbooks.io/slm-lab/content/installation/debugging.html)
+ >Useful reference: [Debugging](https://kengz.gitbooks.io/slm-lab/content/installation/debugging.html)
-### Update
+## Quick Start
-To update SLM Lab, pull the latest git commits and run update:
+#### DQN CartPole
-```shell
-git pull
-conda env update -f environment.yml
-```
+Everything in the lab is ran using a `spec file`, which contains all the information for the run to be reproducible. These are located in `slm_lab/spec/`.
->To update Unity environments obtained from the `extra` setup, run `yarn install`
+Run a quick demo of DQN and CartPole:
-### Demo
+```shell
+conda activate lab
+python run_lab.py slm_lab/spec/demo.json dqn_cartpole dev
+```
-Run the demo to quickly see the lab in action (and to test your installation).
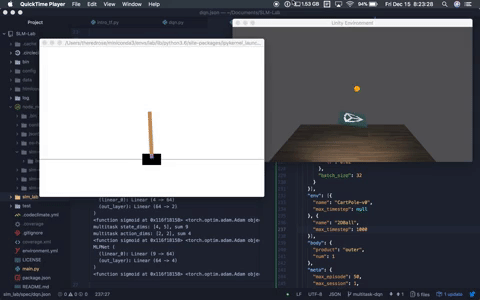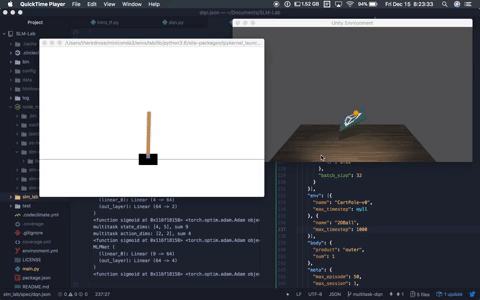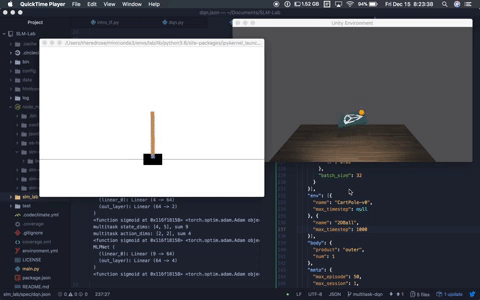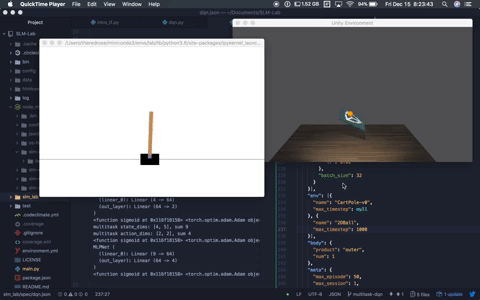
+This will launch a `Trial` in *development mode*, which enables verbose logging and environment rendering. An example screenshot is shown below.

-It is `DQN` in `CartPole-v0`:
-
-1. See `slm_lab/spec/demo.json` for example spec:
- ```json
- "dqn_cartpole": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- ...
- }
- }]
- }
- ```
-
-2. Launch terminal in the repo directory, run the lab with the demo spec in `dev` lab mode:
- ```shell
- conda activate lab
- python run_lab.py slm_lab/spec/demo.json dqn_cartpole dev
- ```
- >To run any lab commands, conda environment must be activated first. See [Installation](#installation) for more.
- >Spec file is autoresolved from `slm_lab/spec/`, so you may use just `demo.json` too.
-
- >With extra setup: `yarn start` can be used as a shorthand for `python run_lab.py`
-
-3. This demo will run a single trial using the default parameters, and render the environment. After completion, check the output for data `data/dqn_cartpole_2018_06_16_214527/` (timestamp will differ). You should see some healthy graphs.
-
- 
- >Trial graph showing average envelope of repeated sessions.
-
- 
- >Session graph showing total rewards, exploration variable and loss for the episodes.
-
-4. Enjoy mode - when a session ends, a model file will automatically save. You can find the session `prepath` that ends in its trial and session numbers. The example above is trial 1 session 0, and you can see a pytorch model saved at `data/dqn_cartpole_2018_06_16_214527/dqn_cartpole_t1_s0_model_net.pth`. Use the following command to run from the saved folder in `data/`:
- ```bash
- python run_lab.py data/dqn_cartpole_2018_06_16_214527/dqn_cartpole_spec.json dqn_cartpole enjoy@dqn_cartpole_t1_s0
- ```
- >Enjoy mode will automatically disable learning and exploration. Graphs will still save.
-
- >To run the best model, use the best saved checkpoint `enjoy@dqn_cartpole_t1_s0_ckptbest`
-
-5. The above was in `dev` mode. To run in proper training mode, which is faster without rendering, change the `dev` lab mode to `train`, and the same data is produced.
- ```shell
- python run_lab.py slm_lab/spec/demo.json dqn_cartpole train
- ```
-
-6. Next, perform a hyperparameter search using the lab mode `search`. This runs experiments of multiple trials with hyperparameter search, defined at the bottom section of the demo spec.
- ```bash
- python run_lab.py slm_lab/spec/demo.json dqn_cartpole search
- ```
-
- When it ends, refer to `{prepath}_experiment_graph.png` and `{prepath}_experiment_df.csv` to find the best trials.
-
->If the demo fails, consult [Debugging](https://kengz.gitbooks.io/slm-lab/content/installation/debugging.html).
-
-Now the lab is ready for usage.
+Next, run it in training mode. The `total_reward` should converge to 200 within a few minutes.
-**Read on: [Github](https://github.com/kengz/SLM-Lab) | [Documentation](https://kengz.gitbooks.io/slm-lab/content/)**
+```shell
+python run_lab.py slm_lab/spec/demo.json dqn_cartpole train
+```
-## Implementations
+>Tip: All lab command should be ran from within a Conda environment. Run `conda activate lab` once at the beginning of a new terminal session.
-SLM Lab implements most of the recent canonical algorithms and various extensions. These are used as the base of research. All the implementations follow this design:
+This will run a new `Trial` in *training mode*. At the end of it, all the metrics and graphs will be output to the `data/` folder.
-- `Agent`: the base class containing all the components. It has the API methods to interface with the environment.
- - `Algorithm`: the main class containing the implementation details of a specific algorithm. It contains components that are reusable.
- - `Net`: the neural network for the algorithm. An algorithm can have multiple networks, e.g. Actor-Critic, DDQN.
- - `Body`: connects the agent-env, and stores the proper agent-env data, such as entropy/log_prob. Multitask agent will have multiple bodies, each handling a specific environment. Conversely, a multiagent environment will accept multiple bodies from different agents. Essentially, each body keeps track of an agent-env pair.
- - `Memory`: stores the numpy/plain type data produced from the agent-env interactions used for training.
+
-- `BaseEnv`: the environment wrapper class. It has the API methods to interface with the agent. Currently, the Lab contains:
- - `OpenAIEnv` for [OpenAI gym](https://github.com/openai/gym)
- - `UnityEnv` for [Unity ML-Agents](https://github.com/Unity-Technologies/ml-agents)
+#### A2C Atari
-### Algorithm
+Run A2C to solve Atari Pong:
-code: [slm_lab/agent/algorithm](https://github.com/kengz/SLM-Lab/tree/master/slm_lab/agent/algorithm)
+```shell
+conda activate lab
+python run_lab.py slm_lab/spec/benchmark/a2c/a2c_pong.json a2c_pong train
+```
-Various algorithms are in fact extensions of some simpler ones, and they are implemented as such. This allows for concise and safer code.
+
+>Atari Pong ran with `dev` mode to render the environment
-**Policy Gradient:**
-- REINFORCE
-- AC (Vanilla Actor-Critic)
- - shared or separate actor critic networks
- - plain TD
- - entropy term control
-- A2C (Advantage Actor-Critic)
- - extension of AC with with advantage function
- - N-step returns as advantage
- - GAE (Generalized Advantage Estimate) as advantage
-- PPO (Proximal Policy Optimization)
- - extension of A2C with PPO loss function
-- SIL (Self-Imitation Learning)
- - extension of A2C with off-policy training on custom loss
-- PPOSIL
- - SIL with PPO instead of A2C
+This will run a `Trial` with multiple Sessions in *training mode*. In the beginning, the `total_reward` should be around -21. After about 1 million frames, it should begin to converge to around +21 (perfect score). At the end of it, all the metrics and graphs will be output to the `data/` folder.
-Using the lab's unified API, **all the algorithms can be distributed hogwild-style**. Session takes the role of workers under a Trial. Some of the distributed algorithms have their own name:
+Below shows a trial graph with multiple sessions:
-- A3C (Asynchronous A2C / distributed A2C)
-- DPPO (Distributed PPO)
+
-**Value-based:**
-- SARSA
-- DQN (Deep Q Learning)
- - boltzmann or epsilon-greedy policy
-- DRQN (DQN + Recurrent Network)
-- Dueling DQN
-- DDQN (Double DQN)
-- DDRQN
-- Dueling DDQN
-- Hydra DQN (multi-environment DQN)
+#### Benchmark
-As mentioned above, **all these algorithms can be turned into distributed algorithms too**, although we do not have special names for them.
+To run a full benchmark, simply pick a file and run it in train mode. For example, for A2C Atari benchmark, the spec file is `slm_lab/spec/benchmark/a2c/a2c_atari.json`. This file is parametrized to run on a set of environments. Run the benchmark:
-Below are the modular building blocks for the algorithms. They are designed to be general, and are reused extensively.
+```shell
+python run_lab.py slm_lab/spec/benchmark/a2c/a2c_atari.json a2c_atari train
+```
-### Memory
+This will spawn multiple processes to run each environment in its separate `Trial`, and the data is saved to `data/` as usual.
-code: [slm_lab/agent/memory](https://github.com/kengz/SLM-Lab/tree/master/slm_lab/agent/memory)
+#### Experimentation / Hyperparameter search
-`Memory` is a numpy/plain type storage of data which gets reused for more efficient computations (without having to call `tensor.detach()` repeatedly). For storing graph tensor with the gradient, use `agent.body`.
+An [`Experiment`](https://github.com/kengz/SLM-Lab/blob/master/slm_lab/experiment/control.py) is a hyperparameter search, which samples multiple `spec`s from a search space. `Experiment` spawns a `Trial` for each `spec`, and each `Trial` runs multiple duplicated `Session`s for averaging its results.
-Note that some particular types of algorithm/network need particular types of Memory, e.g. `RecurrentNet` needs any of the `SeqReplay`. See the class definition for more.
+Given a spec file in `slm_lab/spec/`, if it has a `search` field defining a search space, then it can be ran as an Experiment. For example,
-For on-policy algorithms (policy gradient):
-- OnPolicyReplay
-- OnPolicySeqReplay
-- OnPolicyBatchReplay
-- OnPolicySeqBatchReplay
-- OnPolicyConcatReplay
-- OnPolicyAtariReplay
-- OnPolicyImageReplay (credit: joelouismarino)
+```shell
+python run_lab.py slm_lab/spec/demo.json dqn_cartpole search
+```
-For off-policy algorithms (value-based)
-- Replay
-- SeqReplay
-- SILReplay (special Replay for SIL)
-- SILSeqReplay (special SeqReplay for SIL)
-- ConcatReplay
-- AtariReplay
-- ImageReplay
-- PrioritizedReplay
-- AtariPrioritizedReplay
+Deep Reinforcement Learning is highly empirical. The lab enables rapid and massive experimentations, hence it needs a way to quickly analyze data from many trials. The experiment and analytics framework is the scientific method of the lab.
-### Neural Network
+
+>Experiment graph summarizing the trials in hyperparameter search.
-code: [slm_lab/agent/net](https://github.com/kengz/SLM-Lab/tree/master/slm_lab/agent/net)
+
+>Trial graph showing average envelope of repeated sessions.
-These networks are usable for all algorithms, and the lab takes care of the proper initialization with proper input/output sizing. One can swap out the network for any algorithm with just a spec change, e.g. make `DQN` into `DRQN` by substituting the net spec `"type": "MLPNet"` with `"type": "RecurrentNet"`.
+
+>Session graph showing total rewards.
-- MLPNet (Multi Layer Perceptron, with multi-heads, multi-tails)
-- RecurrentNet (with multi-tails support)
-- ConvNet (with multi-tails support)
+This is the end of the quick start tutorial. Continue reading the full documentation to start using SLM Lab.
-These networks are usable for Q-learning algorithms. For more details see [this paper](http://proceedings.mlr.press/v48/wangf16.pdf).
+**Read on: [Github](https://github.com/kengz/SLM-Lab) | [Documentation](https://kengz.gitbooks.io/slm-lab/content/)**
-- DuelingMLPNet
-- DuelingConvNet
+## Design Principles
-### Policy
+SLM Lab is created for deep reinforcement learning research and applications. The design was guided by four principles
+- **modularity**
+- **simplicity**
+- **analytical clarity**
+- **reproducibility**
-code: [slm_lab/agent/algorithm/policy_util.py](https://github.com/kengz/SLM-Lab/blob/master/slm_lab/agent/algorithm/policy_util.py)
+#### Modularity
-The policy module takes the network output `pdparam`, constructs a probability distribution, and samples for it to produce actions. To use a different distribution, just specify it in the algorithm spec `"action_pdtype"`.
+- makes research easier and more accessible: reuse well-tested components and only focus on the relevant work
+- makes learning deep RL easier: the algorithms are complex; SLM Lab breaks them down into more manageable, digestible components
+- components get reused maximally, which means less code, more tests, and fewer bugs
-- different probability distributions for sampling actions
-- default policy
-- Boltzmann policy
-- Epsilon-greedy policy
-- numerous rate decay methods
+#### Simplicity
-## Experimentation framework
+- the components are designed to closely correspond to the way papers or books discuss RL
+- modular libraries are not necessarily simple. Simplicity balances modularity to prevent overly complex abstractions that are difficult to understand and use
-Deep Reinforcement Learning is highly empirical. The lab enables rapid and massive experimentations, hence it needs a way to quickly analyze data from many trials. The experiment and analytics framework is the scientific method of the lab.
+#### Analytical clarity
-
->Experiment graph summarizing the trials in hyperparameter search.
+- hyperparameter search results are automatically analyzed and presented hierarchically in increasingly granular detail
+- it should take less than 1 minute to understand if an experiment yielded a successful result using the [experiment graph](https://kengz.gitbooks.io/slm-lab/content/analytics/experiment-graph.html)
+- it should take less than 5 minutes to find and review the top 3 parameter settings using the [trial](https://kengz.gitbooks.io/slm-lab/content/analytics/trial-graph.html) and [session](https://kengz.gitbooks.io/slm-lab/content/analytics/session-graph.html) graphs
-
->Trial graph showing average envelope of repeated sessions.
+#### Reproducibility
-
->Session graph showing total rewards, exploration variable and loss for the episodes.
+- only the spec file and a git SHA are needed to fully reproduce an experiment
+- all the results are recorded in [BENCHMARK.md](https://github.com/kengz/SLM-Lab/blob/master/BENCHMARK.md)
+- experiment reproduction instructions are submitted to the Lab via [`result` Pull Requests](https://github.com/kengz/SLM-Lab/pulls?utf8=%E2%9C%93&q=is%3Apr+label%3Aresult+)
+- the full experiment datas contributed are [public on Dropbox ](https://www.dropbox.com/sh/y738zvzj3nxthn1/AAAg1e6TxXVf3krD81TD5V0Ra?dl=0)
## Citing
-If you use `SLM-Lab` in your research, please cite below:
+If you use `SLM Lab` in your research, please cite below:
```
@misc{kenggraesser2017slmlab,
author = {Wah Loon Keng, Laura Graesser},
- title = {SLM-Lab},
+ title = {SLM Lab},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
diff --git a/bin/setup_arch_extra b/bin/setup_arch_extra
index bff85d65e..85a2da0e7 100755
--- a/bin/setup_arch_extra
+++ b/bin/setup_arch_extra
@@ -24,3 +24,6 @@ echo "--- Installing Unity ML agents ---"
conda activate lab
pip install unityagents==0.2.0
pip uninstall -y tensorflow tensorboard
+
+echo "--- Installing VizDoom ---"
+pip install vizdoom==1.1.6
diff --git a/bin/setup_macOS_extra b/bin/setup_macOS_extra
index 96a1d7343..06919d495 100755
--- a/bin/setup_macOS_extra
+++ b/bin/setup_macOS_extra
@@ -24,3 +24,6 @@ echo "--- Installing Unity ML agents ---"
conda activate lab
pip install unityagents==0.2.0
pip uninstall -y tensorflow tensorboard
+
+echo "--- Installing VizDoom ---"
+pip install vizdoom==1.1.6
diff --git a/bin/setup_ubuntu_extra b/bin/setup_ubuntu_extra
index f0cff0fb4..456db1155 100755
--- a/bin/setup_ubuntu_extra
+++ b/bin/setup_ubuntu_extra
@@ -25,3 +25,6 @@ echo "--- Installing Unity ML agents ---"
conda activate lab
pip install unityagents==0.2.0
pip uninstall -y tensorflow tensorboard
+
+echo "--- Installing VizDoom ---"
+pip install vizdoom==1.1.6
diff --git a/environment.yml b/environment.yml
index 6ca4e9b4f..b308be7d1 100644
--- a/environment.yml
+++ b/environment.yml
@@ -21,9 +21,9 @@ dependencies:
- pandas=0.22.0=py36_0
- pillow=5.0.0=py36_0
- pip=9.0.1=py36_1
- - plotly=3.4.2
+ - plotly=3.8.1
- plotly-orca=1.2.1
- - psutil=5.4.7
+ - psutil=5.6.2
- pycodestyle=2.3.1=py36_0
- pydash=4.2.1=py_0
- pytest-cov=2.5.1=py36_0
@@ -42,18 +42,17 @@ dependencies:
- xlrd=1.1.0=py_2
- pytorch=1.0.1
- pip:
- - atari-py==0.1.1
- box2d-py==2.3.8
- cloudpickle==0.5.2
- colorlover==0.3.0
- - deap==1.2.2
- - gym==0.10.9
- - gym[atari]
- - gym[box2d]
- - gym[classic_control]
- opencv-python==3.4.0.12
- pyopengl==3.1.0
- - ray==0.5.3
+ - ray==0.7.0
- redis==2.10.6
- xvfbwrapper==0.2.9
- - vizdoom==1.1.6
+ - gym==0.12.1
+ - gym[atari]
+ - gym[box2d]
+ - gym[classic_control]
+ - roboschool==1.0.46
+ - atari-py
diff --git a/job/a2c_gae_benchmark.json b/job/a2c_gae_benchmark.json
new file mode 100644
index 000000000..8f30d59d2
--- /dev/null
+++ b/job/a2c_gae_benchmark.json
@@ -0,0 +1,11 @@
+{
+ "experimental/a2c/a2c_gae_atari.json": {
+ "a2c_gae_atari": "train"
+ },
+ "experimental/a2c/a2c_gae_cont.json": {
+ "a2c_gae_cont": "train"
+ },
+ "experimental/a2c/a2c_gae_cont_hard.json": {
+ "a2c_gae_cont_hard": "train"
+ },
+}
diff --git a/job/a2c_nstep_benchmark.json b/job/a2c_nstep_benchmark.json
new file mode 100644
index 000000000..d4b5a27a3
--- /dev/null
+++ b/job/a2c_nstep_benchmark.json
@@ -0,0 +1,8 @@
+{
+ "experimental/a2c/a2c_atari.json": {
+ "a2c_atari": "train"
+ },
+ "experimental/a2c/a2c_cont.json": {
+ "a2c_cont": "train"
+ },
+}
diff --git a/job/a3c_gae_benchmark.json b/job/a3c_gae_benchmark.json
new file mode 100644
index 000000000..f49264181
--- /dev/null
+++ b/job/a3c_gae_benchmark.json
@@ -0,0 +1,5 @@
+{
+ "experimental/a3c/a3c_gae_atari.json": {
+ "a3c_gae_atari": "train"
+ },
+}
diff --git a/job/dqn_benchmark.json b/job/dqn_benchmark.json
new file mode 100644
index 000000000..d975abc07
--- /dev/null
+++ b/job/dqn_benchmark.json
@@ -0,0 +1,14 @@
+{
+ "experimental/dqn/dqn_atari.json": {
+ "dqn_atari": "train"
+ },
+ "experimental/dqn/dqn_per_atari.json": {
+ "dqn_per_atari": "train"
+ },
+ "experimental/dqn/ddqn_atari.json": {
+ "ddqn_atari": "train"
+ },
+ "experimental/dqn/ddqn_per_atari.json": {
+ "ddqn_per_atari": "train"
+ },
+}
diff --git a/config/experiments.json b/job/experiments.json
similarity index 100%
rename from config/experiments.json
rename to job/experiments.json
diff --git a/job/ppo_benchmark.json b/job/ppo_benchmark.json
new file mode 100644
index 000000000..df9ba1dfd
--- /dev/null
+++ b/job/ppo_benchmark.json
@@ -0,0 +1,11 @@
+{
+ "experimental/ppo/ppo_atari.json": {
+ "ppo_atari": "train"
+ },
+ "experimental/ppo/ppo_cont.json": {
+ "ppo_cont": "train"
+ },
+ "experimental/ppo/ppo_cont_hard.json": {
+ "ppo_cont_hard": "train"
+ },
+}
diff --git a/package.json b/package.json
index 2d75b47d4..1c89dc117 100644
--- a/package.json
+++ b/package.json
@@ -1,13 +1,11 @@
{
"name": "slm_lab",
- "version": "2.1.2",
+ "version": "4.0.0",
"description": "Modular Deep Reinforcement Learning framework in PyTorch.",
"main": "index.js",
"scripts": {
"start": "python run_lab.py",
"debug": "LOG_LEVEL=DEBUG python run_lab.py",
- "debug2": "LOG_LEVEL=DEBUG2 python run_lab.py",
- "debug3": "LOG_LEVEL=DEBUG3 python run_lab.py",
"retro_analyze": "python -c 'import sys; from slm_lab.experiment import retro_analysis; retro_analysis.retro_analyze(sys.argv[1])'",
"retro_eval": "python -c 'import sys; from slm_lab.experiment import retro_analysis; retro_analysis.retro_eval(sys.argv[1])'",
"reset": "rm -rf data/* .cache __pycache__ */__pycache__ *egg-info .pytest* htmlcov .coverage* *.xml",
diff --git a/run_lab.py b/run_lab.py
index 844198099..fd4f9f381 100644
--- a/run_lab.py
+++ b/run_lab.py
@@ -1,19 +1,17 @@
-'''
-The entry point of SLM Lab
-Specify what to run in `config/experiments.json`
-Then run `python run_lab.py` or `yarn start`
-'''
-import os
-# NOTE increase if needed. Pytorch thread overusage https://github.com/pytorch/pytorch/issues/975
-os.environ['OMP_NUM_THREADS'] = '1'
+# The SLM Lab entrypoint
+# to run scheduled set of specs:
+# python run_lab.py job/experiments.json
+# to run a single spec:
+# python run_lab.py slm_lab/spec/experimental/a2c_pong.json a2c_pong train
from slm_lab import EVAL_MODES, TRAIN_MODES
-from slm_lab.experiment import analysis, retro_analysis
from slm_lab.experiment.control import Session, Trial, Experiment
-from slm_lab.experiment.monitor import InfoSpace
from slm_lab.lib import logger, util
from slm_lab.spec import spec_util
from xvfbwrapper import Xvfb
+import os
+import pydash as ps
import sys
+import torch
import torch.multiprocessing as mp
@@ -22,81 +20,70 @@
]
debug_level = 'DEBUG'
logger.toggle_debug(debug_modules, debug_level)
+logger = logger.get_logger(__name__)
-def run_new_mode(spec_file, spec_name, lab_mode):
- '''Run to generate new data with `search, train, dev`'''
- spec = spec_util.get(spec_file, spec_name)
- info_space = InfoSpace()
- analysis.save_spec(spec, info_space, unit='experiment') # first save the new spec
- if lab_mode == 'search':
- info_space.tick('experiment')
- Experiment(spec, info_space).run()
- elif lab_mode.startswith('train'):
- info_space.tick('trial')
- Trial(spec, info_space).run()
- elif lab_mode == 'dev':
- spec = spec_util.override_dev_spec(spec)
- info_space.tick('trial')
- Trial(spec, info_space).run()
- else:
- raise ValueError(f'Unrecognizable lab_mode not of {TRAIN_MODES}')
-
-
-def run_old_mode(spec_file, spec_name, lab_mode):
- '''Run using existing data with `enjoy, eval`. The eval mode is also what train mode's online eval runs in a subprocess via bash command'''
- # reconstruct spec and info_space from existing data
- lab_mode, prename = lab_mode.split('@')
- predir, _, _, _, _, _ = util.prepath_split(spec_file)
- prepath = f'{predir}/{prename}'
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- # see InfoSpace def for more on these
- info_space.ckpt = 'eval'
- info_space.eval_model_prepath = prepath
-
- # no info_space.tick() as they are reconstructed
- if lab_mode == 'enjoy':
+def run_spec(spec, lab_mode):
+ '''Run a spec in lab_mode'''
+ os.environ['lab_mode'] = lab_mode
+ if lab_mode in TRAIN_MODES:
+ spec_util.save(spec) # first save the new spec
+ if lab_mode == 'dev':
+ spec = spec_util.override_dev_spec(spec)
+ if lab_mode == 'search':
+ spec_util.tick(spec, 'experiment')
+ Experiment(spec).run()
+ else:
+ spec_util.tick(spec, 'trial')
+ Trial(spec).run()
+ elif lab_mode in EVAL_MODES:
spec = spec_util.override_enjoy_spec(spec)
- Session(spec, info_space).run()
- elif lab_mode == 'eval':
- # example eval command:
- # python run_lab.py data/dqn_cartpole_2018_12_19_224811/dqn_cartpole_t0_spec.json dqn_cartpole eval@dqn_cartpole_t0_s1_ckpt-epi10-totalt1000
- spec = spec_util.override_eval_spec(spec)
- Session(spec, info_space).run()
- util.clear_periodic_ckpt(prepath) # cleanup after itself
- retro_analysis.analyze_eval_trial(spec, info_space, predir)
+ Session(spec).run()
else:
- raise ValueError(f'Unrecognizable lab_mode not of {EVAL_MODES}')
+ raise ValueError(f'Unrecognizable lab_mode not of {TRAIN_MODES} or {EVAL_MODES}')
-def run_by_mode(spec_file, spec_name, lab_mode):
- '''The main run lab function for all lab_modes'''
- logger.info(f'Running lab in mode: {lab_mode}')
- # '@' is reserved for 'enjoy@{prename}'
- os.environ['lab_mode'] = lab_mode.split('@')[0]
+def read_spec_and_run(spec_file, spec_name, lab_mode):
+ '''Read a spec and run it in lab mode'''
+ logger.info(f'Running lab spec_file:{spec_file} spec_name:{spec_name} in mode:{lab_mode}')
if lab_mode in TRAIN_MODES:
- run_new_mode(spec_file, spec_name, lab_mode)
- else:
- run_old_mode(spec_file, spec_name, lab_mode)
+ spec = spec_util.get(spec_file, spec_name)
+ else: # eval mode
+ lab_mode, prename = lab_mode.split('@')
+ spec = spec_util.get_eval_spec(spec_file, prename)
+
+ if 'spec_params' not in spec:
+ run_spec(spec, lab_mode)
+ else: # spec is parametrized; run them in parallel
+ param_specs = spec_util.get_param_specs(spec)
+ num_pro = spec['meta']['param_spec_process']
+ # can't use Pool since it cannot spawn nested Process, which is needed for VecEnv and parallel sessions. So these will run and wait by chunks
+ workers = [mp.Process(target=run_spec, args=(spec, lab_mode)) for spec in param_specs]
+ for chunk_w in ps.chunk(workers, num_pro):
+ for w in chunk_w:
+ w.start()
+ for w in chunk_w:
+ w.join()
def main():
- if len(sys.argv) > 1:
- args = sys.argv[1:]
+ '''Main method to run jobs from scheduler or from a spec directly'''
+ args = sys.argv[1:]
+ if len(args) <= 1: # use scheduler
+ job_file = args[0] if len(args) == 1 else 'job/experiments.json'
+ for spec_file, spec_and_mode in util.read(job_file).items():
+ for spec_name, lab_mode in spec_and_mode.items():
+ read_spec_and_run(spec_file, spec_name, lab_mode)
+ else: # run single spec
assert len(args) == 3, f'To use sys args, specify spec_file, spec_name, lab_mode'
- run_by_mode(*args)
- return
-
- experiments = util.read('config/experiments.json')
- for spec_file in experiments:
- for spec_name, lab_mode in experiments[spec_file].items():
- run_by_mode(spec_file, spec_name, lab_mode)
+ read_spec_and_run(*args)
if __name__ == '__main__':
+ torch.set_num_threads(1) # prevent multithread slowdown
mp.set_start_method('spawn') # for distributed pytorch to work
if sys.platform == 'darwin':
- # avoid xvfb for MacOS: https://github.com/nipy/nipype/issues/1400
+ # avoid xvfb on MacOS: https://github.com/nipy/nipype/issues/1400
main()
else:
with Xvfb() as xvfb: # safety context for headless machines
diff --git a/setup.py b/setup.py
index 8bbe5e128..3047e59ad 100644
--- a/setup.py
+++ b/setup.py
@@ -36,7 +36,7 @@ def run_tests(self):
setup(
name='slm_lab',
- version='3.0.0',
+ version='4.0.0',
description='Modular Deep Reinforcement Learning framework in PyTorch.',
long_description='https://github.com/kengz/slm_lab',
keywords='SLM Lab',
diff --git a/slm_lab/agent/__init__.py b/slm_lab/agent/__init__.py
index aa90eab69..b43fc2091 100644
--- a/slm_lab/agent/__init__.py
+++ b/slm_lab/agent/__init__.py
@@ -1,91 +1,64 @@
-'''
-The agent module
-Contains graduated components from experiments for building agents and be taught, tested, evaluated on curriculum.
-To be designed by human and evolution module, based on the experiment aim (trait) and fitness metrics.
-Main SLM components (refer to SLM doc for more):
-- primary survival objective
-- control policies
-- sensors (input) for embodiment
-- motors (output) for embodiment
-- neural architecture
-- memory (with time)
-- prioritization mechanism and "emotions"
-- strange loop must be created
-- social aspect
-- high level properties of thinking, e.g. creativity, planning.
-
-Agent components:
-- algorithm (with net, policy)
-- memory (per body)
-'''
+# The agent module
from slm_lab.agent import algorithm, memory
+from slm_lab.agent.algorithm import policy_util
+from slm_lab.agent.net import net_util
from slm_lab.lib import logger, util
from slm_lab.lib.decorator import lab_api
import numpy as np
+import pandas as pd
import pydash as ps
+import torch
+
-AGENT_DATA_NAMES = ['action', 'loss', 'explore_var']
logger = logger.get_logger(__name__)
class Agent:
'''
- Class for all Agents.
- Standardizes the Agent design to work in Lab.
- Access Envs properties by: Agents - AgentSpace - AEBSpace - EnvSpace - Envs
+ Agent abstraction; implements the API to interface with Env in SLM Lab
+ Contains algorithm, memory, body
'''
- def __init__(self, spec, info_space, body, a=None, agent_space=None, global_nets=None):
+ def __init__(self, spec, body, a=None, global_nets=None):
self.spec = spec
- self.info_space = info_space
- self.a = a or 0 # for compatibility with agent_space
+ self.a = a or 0 # for multi-agent
self.agent_spec = spec['agent'][self.a]
self.name = self.agent_spec['name']
assert not ps.is_list(global_nets), f'single agent global_nets must be a dict, got {global_nets}'
- if agent_space is None: # singleton mode
- self.body = body
- body.agent = self
- MemoryClass = getattr(memory, ps.get(self.agent_spec, 'memory.name'))
- self.body.memory = MemoryClass(self.agent_spec['memory'], self.body)
- AlgorithmClass = getattr(algorithm, ps.get(self.agent_spec, 'algorithm.name'))
- self.algorithm = AlgorithmClass(self, global_nets)
- else:
- self.space_init(agent_space, body, global_nets)
+ # set components
+ self.body = body
+ body.agent = self
+ MemoryClass = getattr(memory, ps.get(self.agent_spec, 'memory.name'))
+ self.body.memory = MemoryClass(self.agent_spec['memory'], self.body)
+ AlgorithmClass = getattr(algorithm, ps.get(self.agent_spec, 'algorithm.name'))
+ self.algorithm = AlgorithmClass(self, global_nets)
logger.info(util.self_desc(self))
- @lab_api
- def reset(self, state):
- '''Do agent reset per session, such as memory pointer'''
- logger.debug(f'Agent {self.a} reset')
- self.body.memory.epi_reset(state)
-
@lab_api
def act(self, state):
'''Standard act method from algorithm.'''
- action = self.algorithm.act(state)
- logger.debug(f'Agent {self.a} act: {action}')
+ with torch.no_grad(): # for efficiency, only calc grad in algorithm.train
+ action = self.algorithm.act(state)
return action
@lab_api
- def update(self, action, reward, state, done):
+ def update(self, state, action, reward, next_state, done):
'''Update per timestep after env transitions, e.g. memory, algorithm, update agent params, train net'''
- self.body.action_pd_update()
- self.body.memory.update(action, reward, state, done)
+ self.body.update(state, action, reward, next_state, done)
+ if util.in_eval_lab_modes(): # eval does not update agent for training
+ return
+ self.body.memory.update(state, action, reward, next_state, done)
loss = self.algorithm.train()
if not np.isnan(loss): # set for log_summary()
self.body.loss = loss
explore_var = self.algorithm.update()
- logger.debug(f'Agent {self.a} loss: {loss}, explore_var {explore_var}')
- if done:
- self.body.epi_update()
return loss, explore_var
@lab_api
def save(self, ckpt=None):
'''Save agent'''
- if util.in_eval_lab_modes():
- # eval does not save new models
+ if util.in_eval_lab_modes(): # eval does not save new models
return
self.algorithm.save(ckpt=ckpt)
@@ -94,134 +67,160 @@ def close(self):
'''Close and cleanup agent at the end of a session, e.g. save model'''
self.save()
- @lab_api
- def space_init(self, agent_space, body_a, global_nets):
- '''Post init override for space env. Note that aeb is already correct from __init__'''
- self.agent_space = agent_space
- self.body_a = body_a
- self.aeb_space = agent_space.aeb_space
- self.nanflat_body_a = util.nanflatten(self.body_a)
- for idx, body in enumerate(self.nanflat_body_a):
- if idx == 0: # NOTE set default body
- self.body = body
- body.agent = self
- body.nanflat_a_idx = idx
- MemoryClass = getattr(memory, ps.get(self.agent_spec, 'memory.name'))
- body.memory = MemoryClass(self.agent_spec['memory'], body)
- self.body_num = len(self.nanflat_body_a)
- AlgorithmClass = getattr(algorithm, ps.get(self.agent_spec, 'algorithm.name'))
- self.algorithm = AlgorithmClass(self, global_nets)
- # after algo init, transfer any missing variables from default body
- for idx, body in enumerate(self.nanflat_body_a):
- for k, v in vars(self.body).items():
- if util.gen_isnan(getattr(body, k, None)):
- setattr(body, k, v)
-
- @lab_api
- def space_reset(self, state_a):
- '''Do agent reset per session, such as memory pointer'''
- logger.debug(f'Agent {self.a} reset')
- for eb, body in util.ndenumerate_nonan(self.body_a):
- body.memory.epi_reset(state_a[eb])
-
- @lab_api
- def space_act(self, state_a):
- '''Standard act method from algorithm.'''
- action_a = self.algorithm.space_act(state_a)
- logger.debug(f'Agent {self.a} act: {action_a}')
- return action_a
- @lab_api
- def space_update(self, action_a, reward_a, state_a, done_a):
- '''Update per timestep after env transitions, e.g. memory, algorithm, update agent params, train net'''
- for eb, body in util.ndenumerate_nonan(self.body_a):
- body.action_pd_update()
- body.memory.update(action_a[eb], reward_a[eb], state_a[eb], done_a[eb])
- loss_a = self.algorithm.space_train()
- loss_a = util.guard_data_a(self, loss_a, 'loss')
- for eb, body in util.ndenumerate_nonan(self.body_a):
- if not np.isnan(loss_a[eb]): # set for log_summary()
- body.loss = loss_a[eb]
- explore_var_a = self.algorithm.space_update()
- explore_var_a = util.guard_data_a(self, explore_var_a, 'explore_var')
- logger.debug(f'Agent {self.a} loss: {loss_a}, explore_var_a {explore_var_a}')
- for eb, body in util.ndenumerate_nonan(self.body_a):
- if body.env.done:
- body.epi_update()
- return loss_a, explore_var_a
-
-
-class AgentSpace:
+class Body:
'''
- Subspace of AEBSpace, collection of all agents, with interface to Session logic; same methods as singleton agents.
- Access EnvSpace properties by: AgentSpace - AEBSpace - EnvSpace - Envs
+ Body of an agent inside an environment, it:
+ - enables the automatic dimension inference for constructing network input/output
+ - acts as reference bridge between agent and environment (useful for multi-agent, multi-env)
+ - acts as non-gradient variable storage for monitoring and analysis
'''
- def __init__(self, spec, aeb_space, global_nets=None):
- self.spec = spec
- self.aeb_space = aeb_space
- aeb_space.agent_space = self
- self.info_space = aeb_space.info_space
- self.aeb_shape = aeb_space.aeb_shape
- assert not ps.is_dict(global_nets), f'multi agent global_nets must be a list of dicts, got {global_nets}'
- assert ps.is_list(self.spec['agent'])
- self.agents = []
- for a in range(len(self.spec['agent'])):
- body_a = self.aeb_space.body_space.get(a=a)
- if global_nets is not None:
- agent_global_nets = global_nets[a]
- else:
- agent_global_nets = None
- agent = Agent(self.spec, self.info_space, body=body_a, a=a, agent_space=self, global_nets=agent_global_nets)
- self.agents.append(agent)
- logger.info(util.self_desc(self))
-
- def get(self, a):
- return self.agents[a]
-
- @lab_api
- def reset(self, state_space):
- logger.debug3('AgentSpace.reset')
- _action_v, _loss_v, _explore_var_v = self.aeb_space.init_data_v(AGENT_DATA_NAMES)
- for agent in self.agents:
- state_a = state_space.get(a=agent.a)
- agent.space_reset(state_a)
- _action_space, _loss_space, _explore_var_space = self.aeb_space.add(AGENT_DATA_NAMES, (_action_v, _loss_v, _explore_var_v))
- logger.debug3(f'action_space: {_action_space}')
- return _action_space
-
- @lab_api
- def act(self, state_space):
- data_names = ('action',)
- action_v, = self.aeb_space.init_data_v(data_names)
- for agent in self.agents:
- a = agent.a
- state_a = state_space.get(a=a)
- action_a = agent.space_act(state_a)
- action_v[a, 0:len(action_a)] = action_a
- action_space, = self.aeb_space.add(data_names, (action_v,))
- logger.debug3(f'\naction_space: {action_space}')
- return action_space
-
- @lab_api
- def update(self, action_space, reward_space, state_space, done_space):
- data_names = ('loss', 'explore_var')
- loss_v, explore_var_v = self.aeb_space.init_data_v(data_names)
- for agent in self.agents:
- a = agent.a
- action_a = action_space.get(a=a)
- reward_a = reward_space.get(a=a)
- state_a = state_space.get(a=a)
- done_a = done_space.get(a=a)
- loss_a, explore_var_a = agent.space_update(action_a, reward_a, state_a, done_a)
- loss_v[a, 0:len(loss_a)] = loss_a
- explore_var_v[a, 0:len(explore_var_a)] = explore_var_a
- loss_space, explore_var_space = self.aeb_space.add(data_names, (loss_v, explore_var_v))
- logger.debug3(f'\nloss_space: {loss_space}\nexplore_var_space: {explore_var_space}')
- return loss_space, explore_var_space
-
- @lab_api
- def close(self):
- logger.info('AgentSpace.close')
- for agent in self.agents:
- agent.close()
+ def __init__(self, env, agent_spec, aeb=(0, 0, 0)):
+ # essential reference variables
+ self.agent = None # set later
+ self.env = env
+ self.aeb = aeb
+ self.a, self.e, self.b = aeb
+
+ # variables set during init_algorithm_params
+ self.explore_var = np.nan # action exploration: epsilon or tau
+ self.entropy_coef = np.nan # entropy for exploration
+
+ # debugging/logging variables, set in train or loss function
+ self.loss = np.nan
+ self.mean_entropy = np.nan
+ self.mean_grad_norm = np.nan
+
+ self.ckpt_total_reward = np.nan
+ self.total_reward = 0 # init to 0, but dont ckpt before end of an epi
+ self.total_reward_ma = np.nan
+ self.ma_window = 100
+ # store current and best reward_ma for model checkpointing and early termination if all the environments are solved
+ self.best_reward_ma = -np.inf
+ self.eval_reward_ma = np.nan
+
+ # dataframes to track data for analysis.analyze_session
+ # track training data per episode
+ self.train_df = pd.DataFrame(columns=[
+ 'epi', 't', 'wall_t', 'opt_step', 'frame', 'fps', 'total_reward', 'total_reward_ma', 'loss', 'lr',
+ 'explore_var', 'entropy_coef', 'entropy', 'grad_norm'])
+ # track eval data within run_eval. the same as train_df except for reward
+ self.eval_df = self.train_df.copy()
+
+ # the specific agent-env interface variables for a body
+ self.observation_space = self.env.observation_space
+ self.action_space = self.env.action_space
+ self.observable_dim = self.env.observable_dim
+ self.state_dim = self.observable_dim['state']
+ self.action_dim = self.env.action_dim
+ self.is_discrete = self.env.is_discrete
+ # set the ActionPD class for sampling action
+ self.action_type = policy_util.get_action_type(self.action_space)
+ self.action_pdtype = agent_spec[self.a]['algorithm'].get('action_pdtype')
+ if self.action_pdtype in (None, 'default'):
+ self.action_pdtype = policy_util.ACTION_PDS[self.action_type][0]
+ self.ActionPD = policy_util.get_action_pd_cls(self.action_pdtype, self.action_type)
+
+ def update(self, state, action, reward, next_state, done):
+ '''Interface update method for body at agent.update()'''
+ if hasattr(self.env.u_env, 'raw_reward'): # use raw_reward if reward is preprocessed
+ reward = self.env.u_env.raw_reward
+ if self.ckpt_total_reward is np.nan: # init
+ self.ckpt_total_reward = reward
+ else: # reset on epi_start, else keep adding. generalized for vec env
+ self.ckpt_total_reward = self.ckpt_total_reward * (1 - self.epi_start) + reward
+ self.total_reward = done * self.ckpt_total_reward + (1 - done) * self.total_reward
+ self.epi_start = done
+
+ def __str__(self):
+ return f'body: {util.to_json(util.get_class_attr(self))}'
+
+ def calc_df_row(self, env):
+ '''Calculate a row for updating train_df or eval_df.'''
+ frame = self.env.clock.get('frame')
+ wall_t = env.clock.get_elapsed_wall_t()
+ fps = 0 if wall_t == 0 else frame / wall_t
+
+ # update debugging variables
+ if net_util.to_check_train_step():
+ grad_norms = net_util.get_grad_norms(self.agent.algorithm)
+ self.mean_grad_norm = np.nan if ps.is_empty(grad_norms) else np.mean(grad_norms)
+
+ row = pd.Series({
+ # epi and frame are always measured from training env
+ 'epi': self.env.clock.get('epi'),
+ # t and reward are measured from a given env or eval_env
+ 't': env.clock.get('t'),
+ 'wall_t': wall_t,
+ 'opt_step': self.env.clock.get('opt_step'),
+ 'frame': frame,
+ 'fps': fps,
+ 'total_reward': np.nanmean(self.total_reward), # guard for vec env
+ 'total_reward_ma': np.nan, # update outside
+ 'loss': self.loss,
+ 'lr': self.get_mean_lr(),
+ 'explore_var': self.explore_var,
+ 'entropy_coef': self.entropy_coef if hasattr(self, 'entropy_coef') else np.nan,
+ 'entropy': self.mean_entropy,
+ 'grad_norm': self.mean_grad_norm,
+ }, dtype=np.float32)
+ assert all(col in self.train_df.columns for col in row.index), f'Mismatched row keys: {row.index} vs df columns {self.train_df.columns}'
+ return row
+
+ def train_ckpt(self):
+ '''Checkpoint to update body.train_df data'''
+ row = self.calc_df_row(self.env)
+ # append efficiently to df
+ self.train_df.loc[len(self.train_df)] = row
+ # update current reward_ma
+ self.total_reward_ma = self.train_df[-self.ma_window:]['total_reward'].mean()
+ self.train_df.iloc[-1]['total_reward_ma'] = self.total_reward_ma
+
+ def eval_ckpt(self, eval_env, total_reward):
+ '''Checkpoint to update body.eval_df data'''
+ row = self.calc_df_row(eval_env)
+ row['total_reward'] = total_reward
+ # append efficiently to df
+ self.eval_df.loc[len(self.eval_df)] = row
+ # update current reward_ma
+ self.eval_reward_ma = self.eval_df[-self.ma_window:]['total_reward'].mean()
+ self.eval_df.iloc[-1]['total_reward_ma'] = self.eval_reward_ma
+
+ def get_mean_lr(self):
+ '''Gets the average current learning rate of the algorithm's nets.'''
+ if not hasattr(self.agent.algorithm, 'net_names'):
+ return np.nan
+ lrs = []
+ for attr, obj in self.agent.algorithm.__dict__.items():
+ if attr.endswith('lr_scheduler'):
+ lrs.append(obj.get_lr())
+ return np.mean(lrs)
+
+ def get_log_prefix(self):
+ '''Get the prefix for logging'''
+ spec = self.agent.spec
+ spec_name = spec['name']
+ trial_index = spec['meta']['trial']
+ session_index = spec['meta']['session']
+ prefix = f'Trial {trial_index} session {session_index} {spec_name}_t{trial_index}_s{session_index}'
+ return prefix
+
+ def log_metrics(self, metrics, df_mode):
+ '''Log session metrics'''
+ prefix = self.get_log_prefix()
+ row_str = ' '.join([f'{k}: {v:g}' for k, v in metrics.items()])
+ msg = f'{prefix} [{df_mode}_df metrics] {row_str}'
+ logger.info(msg)
+
+ def log_summary(self, df_mode):
+ '''
+ Log the summary for this body when its environment is done
+ @param str:df_mode 'train' or 'eval'
+ '''
+ prefix = self.get_log_prefix()
+ df = getattr(self, f'{df_mode}_df')
+ last_row = df.iloc[-1]
+ row_str = ' '.join([f'{k}: {v:g}' for k, v in last_row.items()])
+ msg = f'{prefix} [{df_mode}_df] {row_str}'
+ logger.info(msg)
diff --git a/slm_lab/agent/algorithm/__init__.py b/slm_lab/agent/algorithm/__init__.py
index 948dc4137..fe345d91d 100644
--- a/slm_lab/agent/algorithm/__init__.py
+++ b/slm_lab/agent/algorithm/__init__.py
@@ -1,13 +1,8 @@
-'''
-The algorithm module
-Contains implementations of reinforcement learning algorithms.
-Uses the nets module to build neural networks as the relevant function approximators
-'''
-
-# expose all the classes
+# The algorithm module
+# Contains implementations of reinforcement learning algorithms.
+# Uses the nets module to build neural networks as the relevant function approximators
from .actor_critic import *
from .dqn import *
-from .hydra_dqn import *
from .ppo import *
from .random import *
from .reinforce import *
diff --git a/slm_lab/agent/algorithm/actor_critic.py b/slm_lab/agent/algorithm/actor_critic.py
index 4884c16e1..6fef48fed 100644
--- a/slm_lab/agent/algorithm/actor_critic.py
+++ b/slm_lab/agent/algorithm/actor_critic.py
@@ -18,8 +18,8 @@ class ActorCritic(Reinforce):
https://arxiv.org/abs/1602.01783
Algorithm specific spec param:
memory.name: batch (through OnPolicyBatchReplay memory class) or episodic through (OnPolicyReplay memory class)
- lam: if not null, used as the lambda value of generalized advantage estimation (GAE) introduced in "High-Dimensional Continuous Control Using Generalized Advantage Estimation https://arxiv.org/abs/1506.02438. The algorithm becomes A2C. This lambda controls the bias variance tradeoff for GAE. Floating point value between 0 and 1. Lower values correspond to more bias, less variance. Higher values to more variance, less bias.
- num_step_returns: if lam is null and this is not null, specifies the number of steps for N-step returns from "Asynchronous Methods for Deep Reinforcement Learning". The algorithm becomes A2C.
+ lam: if not null, used as the lambda value of generalized advantage estimation (GAE) introduced in "High-Dimensional Continuous Control Using Generalized Advantage Estimation https://arxiv.org/abs/1506.02438. This lambda controls the bias variance tradeoff for GAE. Floating point value between 0 and 1. Lower values correspond to more bias, less variance. Higher values to more variance, less bias. Algorithm becomes A2C(GAE).
+ num_step_returns: if lam is null and this is not null, specifies the number of steps for N-step returns from "Asynchronous Methods for Deep Reinforcement Learning". The algorithm becomes A2C(Nstep).
If both lam and num_step_returns are null, use the default TD error. Then the algorithm stays as AC.
net.type: whether the actor and critic should share params (e.g. through 'MLPNetShared') or have separate params (e.g. through 'MLPNetSeparate'). If param sharing is used then there is also the option to control the weight given to the policy and value components of the loss function through 'policy_loss_coef' and 'val_loss_coef'
Algorithm - separate actor and critic:
@@ -61,8 +61,6 @@ class ActorCritic(Reinforce):
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
}
e.g. special net_spec param "shared" to share/separate Actor/Critic
@@ -96,8 +94,6 @@ def init_algorithm_params(self):
'policy_loss_coef',
'val_loss_coef',
'training_frequency',
- 'training_epoch',
- 'normalize_state',
])
self.to_train = 0
self.action_policy = getattr(policy_util, self.action_policy)
@@ -106,13 +102,13 @@ def init_algorithm_params(self):
if self.entropy_coef_spec is not None:
self.entropy_coef_scheduler = policy_util.VarScheduler(self.entropy_coef_spec)
self.body.entropy_coef = self.entropy_coef_scheduler.start_val
- # Select appropriate methods to calculate adv_targets and v_targets for training
+ # Select appropriate methods to calculate advs and v_targets for training
if self.lam is not None:
self.calc_advs_v_targets = self.calc_gae_advs_v_targets
elif self.num_step_returns is not None:
self.calc_advs_v_targets = self.calc_nstep_advs_v_targets
else:
- self.calc_advs_v_targets = self.calc_td_advs_v_targets
+ self.calc_advs_v_targets = self.calc_ret_advs_v_targets
@lab_api
def init_nets(self, global_nets=None):
@@ -128,7 +124,7 @@ def init_nets(self, global_nets=None):
- Discrete action spaces: The return list contains 2 element. The first element is a tensor containing the logits for a categorical probability distribution over the actions. The second element contains the state-value estimated by the network.
3. If the network type is feedforward, convolutional, or recurrent
- Feedforward and convolutional networks take a single state as input and require an OnPolicyReplay or OnPolicyBatchReplay memory
- - Recurrent networks take n states as input and require an OnPolicySeqReplay or OnPolicySeqBatchReplay memory
+ - Recurrent networks take n states as input and require env spec "frame_op": "concat", "frame_op_len": seq_len
'''
assert 'shared' in self.net_spec, 'Specify "shared" for ActorCritic network in net_spec'
self.shared = self.net_spec['shared']
@@ -146,198 +142,163 @@ def init_nets(self, global_nets=None):
if critic_net_spec['use_same_optim']:
critic_net_spec = actor_net_spec
- if global_nets is None:
- in_dim = self.body.state_dim
- out_dim = net_util.get_out_dim(self.body, add_critic=self.shared)
- # main actor network, may contain out_dim self.shared == True
- NetClass = getattr(net, actor_net_spec['type'])
- self.net = NetClass(actor_net_spec, in_dim, out_dim)
- self.net_names = ['net']
- if not self.shared: # add separate network for critic
- critic_out_dim = 1
- CriticNetClass = getattr(net, critic_net_spec['type'])
- self.critic = CriticNetClass(critic_net_spec, in_dim, critic_out_dim)
- self.net_names.append('critic')
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
+ in_dim = self.body.state_dim
+ out_dim = net_util.get_out_dim(self.body, add_critic=self.shared)
+ # main actor network, may contain out_dim self.shared == True
+ NetClass = getattr(net, actor_net_spec['type'])
+ self.net = NetClass(actor_net_spec, in_dim, out_dim)
+ self.net_names = ['net']
+ if not self.shared: # add separate network for critic
+ critic_out_dim = 1
+ CriticNetClass = getattr(net, critic_net_spec['type'])
+ self.critic_net = CriticNetClass(critic_net_spec, in_dim, critic_out_dim)
+ self.net_names.append('critic_net')
+ # init net optimizer and its lr scheduler
+ self.optim = net_util.get_optim(self.net, self.net.optim_spec)
+ self.lr_scheduler = net_util.get_lr_scheduler(self.optim, self.net.lr_scheduler_spec)
+ if not self.shared:
+ self.critic_optim = net_util.get_optim(self.critic_net, self.critic_net.optim_spec)
+ self.critic_lr_scheduler = net_util.get_lr_scheduler(self.critic_optim, self.critic_net.lr_scheduler_spec)
+ net_util.set_global_nets(self, global_nets)
self.post_init_nets()
@lab_api
- def calc_pdparam(self, x, evaluate=True, net=None):
+ def calc_pdparam(self, x, net=None):
'''
The pdparam will be the logits for discrete prob. dist., or the mean and std for continuous prob. dist.
'''
- pdparam = super(ActorCritic, self).calc_pdparam(x, evaluate=evaluate, net=net)
- if self.shared: # output: policy, value
- if len(pdparam) == 2: # single policy outputs, value
- pdparam = pdparam[0]
- else: # multiple policy outputs, value
- pdparam = pdparam[:-1]
- logger.debug(f'pdparam: {pdparam}')
+ out = super().calc_pdparam(x, net=net)
+ if self.shared:
+ assert ps.is_list(out), f'Shared output should be a list [pdparam, v]'
+ if len(out) == 2: # single policy
+ pdparam = out[0]
+ else: # multiple-task policies, still assumes 1 value
+ pdparam = out[:-1]
+ self.v_pred = out[-1].view(-1) # cache for loss calc to prevent double-pass
+ else: # out is pdparam
+ pdparam = out
return pdparam
- def calc_v(self, x, evaluate=True, net=None):
+ def calc_v(self, x, net=None, use_cache=True):
'''
- Forward-pass to calculate the predicted state-value from critic.
+ Forward-pass to calculate the predicted state-value from critic_net.
'''
- net = self.net if net is None else net
if self.shared: # output: policy, value
- if evaluate:
- out = net.wrap_eval(x)
+ if use_cache: # uses cache from calc_pdparam to prevent double-pass
+ v_pred = self.v_pred
else:
- net.train()
- out = net(x)
- v = out[-1].squeeze(dim=1) # get value only
+ net = self.net if net is None else net
+ v_pred = net(x)[-1].view(-1)
else:
- if evaluate:
- out = self.critic.wrap_eval(x)
- else:
- self.critic.train()
- out = self.critic(x)
- v = out.squeeze(dim=1)
- logger.debug(f'v: {v}')
- return v
+ net = self.critic_net if net is None else net
+ v_pred = net(x).view(-1)
+ return v_pred
- @lab_api
- def train(self):
- '''Trains the algorithm'''
- if util.in_eval_lab_modes():
- self.body.flush()
- return np.nan
- if self.shared:
- return self.train_shared()
- else:
- return self.train_separate()
+ def calc_pdparam_v(self, batch):
+ '''Efficiently forward to get pdparam and v by batch for loss computation'''
+ states = batch['states']
+ if self.body.env.is_venv:
+ states = math_util.venv_unpack(states)
+ pdparam = self.calc_pdparam(states)
+ v_pred = self.calc_v(states) # uses self.v_pred from calc_pdparam if self.shared
+ return pdparam, v_pred
+
+ def calc_ret_advs_v_targets(self, batch, v_preds):
+ '''Calculate plain returns, and advs = rets - v_preds, v_targets = rets'''
+ v_preds = v_preds.detach() # adv does not accumulate grad
+ if self.body.env.is_venv:
+ v_preds = math_util.venv_pack(v_preds, self.body.env.num_envs)
+ rets = math_util.calc_returns(batch['rewards'], batch['dones'], self.gamma)
+ advs = rets - v_preds
+ v_targets = rets
+ if self.body.env.is_venv:
+ advs = math_util.venv_unpack(advs)
+ v_targets = math_util.venv_unpack(v_targets)
+ logger.debug(f'advs: {advs}\nv_targets: {v_targets}')
+ return advs, v_targets
- def train_shared(self):
+ def calc_nstep_advs_v_targets(self, batch, v_preds):
'''
- Trains the network when the actor and critic share parameters
- loss = self.policy_loss_coef * policy_loss + self.val_loss_coef * val_loss
+ Calculate N-step returns, and advs = nstep_rets - v_preds, v_targets = nstep_rets
+ See n-step advantage under http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_5_actor_critic_pdf.pdf
'''
- clock = self.body.env.clock
- if self.to_train == 1:
- batch = self.sample()
- with torch.no_grad():
- advs, v_targets = self.calc_advs_v_targets(batch)
- policy_loss = self.calc_policy_loss(batch, advs) # from actor
- val_loss = self.calc_val_loss(batch, v_targets) # from critic
- loss = policy_loss + val_loss
- self.net.training_step(loss=loss, lr_clock=clock)
- # reset
- self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
- return loss.item()
- else:
- return np.nan
+ next_states = batch['next_states'][-1]
+ if not self.body.env.is_venv:
+ next_states = next_states.unsqueeze(dim=0)
+ with torch.no_grad():
+ next_v_pred = self.calc_v(next_states, use_cache=False)
+ v_preds = v_preds.detach() # adv does not accumulate grad
+ if self.body.env.is_venv:
+ v_preds = math_util.venv_pack(v_preds, self.body.env.num_envs)
+ nstep_rets = math_util.calc_nstep_returns(batch['rewards'], batch['dones'], next_v_pred, self.gamma, self.num_step_returns)
+ advs = nstep_rets - v_preds
+ v_targets = nstep_rets
+ if self.body.env.is_venv:
+ advs = math_util.venv_unpack(advs)
+ v_targets = math_util.venv_unpack(v_targets)
+ logger.debug(f'advs: {advs}\nv_targets: {v_targets}')
+ return advs, v_targets
- def train_separate(self):
+ def calc_gae_advs_v_targets(self, batch, v_preds):
'''
- Trains the network when the actor and critic are separate networks
- loss = val_loss + abs(policy_loss)
+ Calculate GAE, and advs = GAE, v_targets = advs + v_preds
+ See GAE from Schulman et al. https://arxiv.org/pdf/1506.02438.pdf
'''
- if self.to_train == 1:
- batch = self.sample()
- policy_loss = self.train_actor(batch)
- val_loss = self.train_critic(batch)
- loss = val_loss + abs(policy_loss)
- # reset
- self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name}, loss: {loss:g}')
- return loss.item()
- else:
- return np.nan
-
- def train_actor(self, batch):
- '''Trains the actor when the actor and critic are separate networks'''
+ next_states = batch['next_states'][-1]
+ if not self.body.env.is_venv:
+ next_states = next_states.unsqueeze(dim=0)
with torch.no_grad():
- advs, _v_targets = self.calc_advs_v_targets(batch)
- policy_loss = self.calc_policy_loss(batch, advs)
- self.net.training_step(loss=policy_loss, lr_clock=self.body.env.clock)
- return policy_loss
-
- def train_critic(self, batch):
- '''Trains the critic when the actor and critic are separate networks'''
- total_val_loss = torch.tensor(0.0, device=self.net.device)
- # training iters only applicable to separate critic network
- for _ in range(self.training_epoch):
- with torch.no_grad():
- _advs, v_targets = self.calc_advs_v_targets(batch)
- val_loss = self.calc_val_loss(batch, v_targets)
- self.critic.training_step(loss=val_loss, lr_clock=self.body.env.clock)
- total_val_loss += val_loss
- val_loss = total_val_loss / self.training_epoch
- return val_loss
+ next_v_pred = self.calc_v(next_states, use_cache=False)
+ v_preds = v_preds.detach() # adv does not accumulate grad
+ if self.body.env.is_venv:
+ v_preds = math_util.venv_pack(v_preds, self.body.env.num_envs)
+ next_v_pred = next_v_pred.unsqueeze(dim=0)
+ v_preds_all = torch.cat((v_preds, next_v_pred), dim=0)
+ advs = math_util.calc_gaes(batch['rewards'], batch['dones'], v_preds_all, self.gamma, self.lam)
+ v_targets = advs + v_preds
+ advs = math_util.standardize(advs) # standardize only for advs, not v_targets
+ if self.body.env.is_venv:
+ advs = math_util.venv_unpack(advs)
+ v_targets = math_util.venv_unpack(v_targets)
+ logger.debug(f'advs: {advs}\nv_targets: {v_targets}')
+ return advs, v_targets
- def calc_policy_loss(self, batch, advs):
+ def calc_policy_loss(self, batch, pdparams, advs):
'''Calculate the actor's policy loss'''
- assert len(self.body.log_probs) == len(advs), f'batch_size of log_probs {len(self.body.log_probs)} vs advs: {len(advs)}'
- log_probs = torch.stack(self.body.log_probs)
- policy_loss = - self.policy_loss_coef * log_probs * advs
- if self.entropy_coef_spec is not None:
- entropies = torch.stack(self.body.entropies)
- policy_loss += (-self.body.entropy_coef * entropies)
- policy_loss = torch.mean(policy_loss)
- logger.debug(f'Actor policy loss: {policy_loss:g}')
- return policy_loss
+ return super().calc_policy_loss(batch, pdparams, advs)
- def calc_val_loss(self, batch, v_targets):
+ def calc_val_loss(self, v_preds, v_targets):
'''Calculate the critic's value loss'''
- v_targets = v_targets.unsqueeze(dim=-1)
- v_preds = self.calc_v(batch['states'], evaluate=False).unsqueeze(dim=-1)
- assert v_preds.shape == v_targets.shape
+ assert v_preds.shape == v_targets.shape, f'{v_preds.shape} != {v_targets.shape}'
val_loss = self.val_loss_coef * self.net.loss_fn(v_preds, v_targets)
logger.debug(f'Critic value loss: {val_loss:g}')
return val_loss
- def calc_gae_advs_v_targets(self, batch):
- '''
- Calculate the GAE advantages and value targets for training actor and critic respectively
- adv_targets = GAE (see math_util method)
- v_targets = adv_targets + v_preds
- before output, adv_targets is standardized (so v_targets used the unstandardized version)
- Used for training with GAE
- '''
- states = torch.cat((batch['states'], batch['next_states'][-1:]), dim=0) # prevent double-pass
- v_preds = self.calc_v(states)
- next_v_preds = v_preds[1:] # shift for only the next states
- # v_target = r_t + gamma * V(s_(t+1)), i.e. 1-step return
- v_targets = math_util.calc_nstep_returns(batch['rewards'], batch['dones'], self.gamma, 1, next_v_preds)
- adv_targets = math_util.calc_gaes(batch['rewards'], batch['dones'], v_preds, self.gamma, self.lam)
- adv_targets = math_util.standardize(adv_targets)
- logger.debug(f'adv_targets: {adv_targets}\nv_targets: {v_targets}')
- return adv_targets, v_targets
-
- def calc_nstep_advs_v_targets(self, batch):
- '''
- Calculate N-step returns advantage = nstep_returns - v_pred
- See n-step advantage under http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_5_actor_critic_pdf.pdf
- Used for training with N-step (not GAE)
- Returns 2-tuple for API-consistency with GAE
- '''
- next_v_preds = self.calc_v(batch['next_states'])
- v_preds = self.calc_v(batch['states'])
- # v_target = r_t + gamma * V(s_(t+1)), i.e. 1-step return
- v_targets = math_util.calc_nstep_returns(batch['rewards'], batch['dones'], self.gamma, 1, next_v_preds)
- nstep_returns = math_util.calc_nstep_returns(batch['rewards'], batch['dones'], self.gamma, self.num_step_returns, next_v_preds)
- nstep_advs = nstep_returns - v_preds
- adv_targets = nstep_advs
- logger.debug(f'adv_targets: {adv_targets}\nv_targets: {v_targets}')
- return adv_targets, v_targets
-
- def calc_td_advs_v_targets(self, batch):
- '''
- Estimate Q(s_t, a_t) with r_t + gamma * V(s_t+1 ) for simplest AC algorithm
- '''
- next_v_preds = self.calc_v(batch['next_states'])
- # Equivalent to 1-step return
- # v_target = r_t + gamma * V(s_(t+1)), i.e. 1-step return
- v_targets = math_util.calc_nstep_returns(batch['rewards'], batch['dones'], self.gamma, 1, next_v_preds)
- adv_targets = v_targets # Plain Q estimate, called adv for API consistency
- logger.debug(f'adv_targets: {adv_targets}\nv_targets: {v_targets}')
- return adv_targets, v_targets
+ def train(self):
+ '''Train actor critic by computing the loss in batch efficiently'''
+ if util.in_eval_lab_modes():
+ return np.nan
+ clock = self.body.env.clock
+ if self.to_train == 1:
+ batch = self.sample()
+ clock.set_batch_size(len(batch))
+ pdparams, v_preds = self.calc_pdparam_v(batch)
+ advs, v_targets = self.calc_advs_v_targets(batch, v_preds)
+ policy_loss = self.calc_policy_loss(batch, pdparams, advs) # from actor
+ val_loss = self.calc_val_loss(v_preds, v_targets) # from critic
+ if self.shared: # shared network
+ loss = policy_loss + val_loss
+ self.net.train_step(loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
+ else:
+ self.net.train_step(policy_loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
+ self.critic_net.train_step(val_loss, self.critic_optim, self.critic_lr_scheduler, clock=clock, global_net=self.global_critic_net)
+ loss = policy_loss + val_loss
+ # reset
+ self.to_train = 0
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
+ return loss.item()
+ else:
+ return np.nan
@lab_api
def update(self):
diff --git a/slm_lab/agent/algorithm/base.py b/slm_lab/agent/algorithm/base.py
index e60792aff..1d41f7672 100644
--- a/slm_lab/agent/algorithm/base.py
+++ b/slm_lab/agent/algorithm/base.py
@@ -3,17 +3,12 @@
from slm_lab.lib import logger, util
from slm_lab.lib.decorator import lab_api
import numpy as np
-import pydash as ps
logger = logger.get_logger(__name__)
class Algorithm(ABC):
- '''
- Abstract class ancestor to all Algorithms,
- specifies the necessary design blueprint for agent to work in Lab.
- Mostly, implement just the abstract methods and properties.
- '''
+ '''Abstract Algorithm class to define the API methods'''
def __init__(self, agent, global_nets=None):
'''
@@ -48,29 +43,22 @@ def post_init_nets(self):
Call at the end of init_nets() after setting self.net_names
'''
assert hasattr(self, 'net_names')
+ for net_name in self.net_names:
+ assert net_name.endswith('net'), f'Naming convention: net_name must end with "net"; got {net_name}'
if util.in_eval_lab_modes():
- logger.info(f'Loaded algorithm models for lab_mode: {util.get_lab_mode()}')
self.load()
+ logger.info(f'Loaded algorithm models for lab_mode: {util.get_lab_mode()}')
else:
logger.info(f'Initialized algorithm models for lab_mode: {util.get_lab_mode()}')
@lab_api
- def calc_pdparam(self, x, evaluate=True, net=None):
+ def calc_pdparam(self, x, net=None):
'''
To get the pdparam for action policy sampling, do a forward pass of the appropriate net, and pick the correct outputs.
The pdparam will be the logits for discrete prob. dist., or the mean and std for continuous prob. dist.
'''
raise NotImplementedError
- def nanflat_to_data_a(self, data_name, nanflat_data_a):
- '''Reshape nanflat_data_a, e.g. action_a, from a single pass back into the API-conforming data_a'''
- data_names = (data_name,)
- data_a, = self.agent.agent_space.aeb_space.init_data_s(data_names, a=self.agent.a)
- for body, data in zip(self.agent.nanflat_body_a, nanflat_data_a):
- e, b = body.e, body.b
- data_a[(e, b)] = data
- return data_a
-
@lab_api
def act(self, state):
'''Standard act method.'''
@@ -115,58 +103,6 @@ def load(self):
net_util.load_algorithm(self)
# set decayable variables to final values
for k, v in vars(self).items():
- if k.endswith('_scheduler'):
+ if k.endswith('_scheduler') and hasattr(v, 'end_val'):
var_name = k.replace('_scheduler', '')
setattr(self.body, var_name, v.end_val)
-
- # NOTE optional extension for multi-agent-env
-
- @lab_api
- def space_act(self, state_a):
- '''Interface-level agent act method for all its bodies. Resolves state to state; get action and compose into action.'''
- data_names = ('action',)
- action_a, = self.agent.agent_space.aeb_space.init_data_s(data_names, a=self.agent.a)
- for eb, body in util.ndenumerate_nonan(self.agent.body_a):
- state = state_a[eb]
- self.body = body
- action_a[eb] = self.act(state)
- # set body reference back to default
- self.body = self.agent.nanflat_body_a[0]
- return action_a
-
- @lab_api
- def space_sample(self):
- '''Samples a batch from memory'''
- batches = []
- for body in self.agent.nanflat_body_a:
- self.body = body
- batches.append(self.sample())
- # set body reference back to default
- self.body = self.agent.nanflat_body_a[0]
- batch = util.concat_batches(batches)
- batch = util.to_torch_batch(batch, self.net.device, self.body.memory.is_episodic)
- return batch
-
- @lab_api
- def space_train(self):
- if util.in_eval_lab_modes():
- return np.nan
- losses = []
- for body in self.agent.nanflat_body_a:
- self.body = body
- losses.append(self.train())
- # set body reference back to default
- self.body = self.agent.nanflat_body_a[0]
- loss_a = self.nanflat_to_data_a('loss', losses)
- return loss_a
-
- @lab_api
- def space_update(self):
- explore_vars = []
- for body in self.agent.nanflat_body_a:
- self.body = body
- explore_vars.append(self.update())
- # set body reference back to default
- self.body = self.agent.nanflat_body_a[0]
- explore_var_a = self.nanflat_to_data_a('explore_var', explore_vars)
- return explore_var_a
diff --git a/slm_lab/agent/algorithm/dqn.py b/slm_lab/agent/algorithm/dqn.py
index ab4c6e970..e09d32349 100644
--- a/slm_lab/agent/algorithm/dqn.py
+++ b/slm_lab/agent/algorithm/dqn.py
@@ -2,7 +2,7 @@
from slm_lab.agent.algorithm import policy_util
from slm_lab.agent.algorithm.sarsa import SARSA
from slm_lab.agent.net import net_util
-from slm_lab.lib import logger, util
+from slm_lab.lib import logger, math_util, util
from slm_lab.lib.decorator import lab_api
import numpy as np
import pydash as ps
@@ -43,11 +43,10 @@ class VanillaDQN(SARSA):
"end_step": 1000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 10,
"training_start_step": 10,
- "normalize_state": true
}
'''
@@ -66,58 +65,58 @@ def init_algorithm_params(self):
# these control the trade off between exploration and exploitaton
'explore_var_spec',
'gamma', # the discount factor
- 'training_batch_epoch', # how many gradient updates per batch
- 'training_epoch', # how many batches to train each time
+ 'training_batch_iter', # how many gradient updates per batch
+ 'training_iter', # how many batches to train each time
'training_frequency', # how often to train (once a few timesteps)
'training_start_step', # how long before starting training
- 'normalize_state',
])
- super(VanillaDQN, self).init_algorithm_params()
+ super().init_algorithm_params()
@lab_api
def init_nets(self, global_nets=None):
'''Initialize the neural network used to learn the Q function from the spec'''
if self.algorithm_spec['name'] == 'VanillaDQN':
assert all(k not in self.net_spec for k in ['update_type', 'update_frequency', 'polyak_coef']), 'Network update not available for VanillaDQN; use DQN.'
- if global_nets is None:
- in_dim = self.body.state_dim
- out_dim = net_util.get_out_dim(self.body)
- NetClass = getattr(net, self.net_spec['type'])
- self.net = NetClass(self.net_spec, in_dim, out_dim)
- self.net_names = ['net']
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
+ in_dim = self.body.state_dim
+ out_dim = net_util.get_out_dim(self.body)
+ NetClass = getattr(net, self.net_spec['type'])
+ self.net = NetClass(self.net_spec, in_dim, out_dim)
+ self.net_names = ['net']
+ # init net optimizer and its lr scheduler
+ self.optim = net_util.get_optim(self.net, self.net.optim_spec)
+ self.lr_scheduler = net_util.get_lr_scheduler(self.optim, self.net.lr_scheduler_spec)
+ net_util.set_global_nets(self, global_nets)
self.post_init_nets()
def calc_q_loss(self, batch):
'''Compute the Q value loss using predicted and target Q values from the appropriate networks'''
- q_preds = self.net.wrap_eval(batch['states'])
+ states = batch['states']
+ next_states = batch['next_states']
+ q_preds = self.net(states)
+ with torch.no_grad():
+ next_q_preds = self.net(next_states)
act_q_preds = q_preds.gather(-1, batch['actions'].long().unsqueeze(-1)).squeeze(-1)
- next_q_preds = self.net.wrap_eval(batch['next_states'])
# Bellman equation: compute max_q_targets using reward and max estimated Q values (0 if no next_state)
max_next_q_preds, _ = next_q_preds.max(dim=-1, keepdim=True)
max_q_targets = batch['rewards'] + self.gamma * (1 - batch['dones']) * max_next_q_preds
- max_q_targets = max_q_targets.detach()
+ logger.debug(f'act_q_preds: {act_q_preds}\nmax_q_targets: {max_q_targets}')
q_loss = self.net.loss_fn(act_q_preds, max_q_targets)
# TODO use the same loss_fn but do not reduce yet
if 'Prioritized' in util.get_class_name(self.body.memory): # PER
- errors = torch.abs(max_q_targets - act_q_preds.detach())
+ errors = (max_q_targets - act_q_preds.detach()).abs().cpu().numpy()
self.body.memory.update_priorities(errors)
return q_loss
@lab_api
def act(self, state):
'''Selects and returns a discrete action for body using the action policy'''
- return super(VanillaDQN, self).act(state)
+ return super().act(state)
@lab_api
def sample(self):
'''Samples a batch from memory of size self.memory_spec['batch_size']'''
batch = self.body.memory.sample()
- if self.normalize_state:
- batch = policy_util.normalize_states_and_next_states(self.body, batch)
batch = util.to_torch_batch(batch, self.net.device, self.body.memory.is_episodic)
return batch
@@ -131,24 +130,21 @@ def train(self):
Otherwise this function does nothing.
'''
if util.in_eval_lab_modes():
- self.body.flush()
return np.nan
clock = self.body.env.clock
- tick = clock.get(clock.max_tick_unit)
- self.to_train = (tick > self.training_start_step and tick % self.training_frequency == 0)
if self.to_train == 1:
- total_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
+ total_loss = torch.tensor(0.0)
+ for _ in range(self.training_iter):
batch = self.sample()
- for _ in range(self.training_batch_epoch):
+ clock.set_batch_size(len(batch))
+ for _ in range(self.training_batch_iter):
loss = self.calc_q_loss(batch)
- self.net.training_step(loss=loss, lr_clock=clock)
+ self.net.train_step(loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
total_loss += loss
- loss = total_loss / (self.training_epoch * self.training_batch_epoch)
+ loss = total_loss / (self.training_iter * self.training_batch_iter)
# reset
self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
return loss.item()
else:
return np.nan
@@ -156,7 +152,7 @@ def train(self):
@lab_api
def update(self):
'''Update the agent after training'''
- return super(VanillaDQN, self).update()
+ return super().update()
class DQNBase(VanillaDQN):
@@ -180,47 +176,48 @@ def init_nets(self, global_nets=None):
'''Initialize networks'''
if self.algorithm_spec['name'] == 'DQNBase':
assert all(k not in self.net_spec for k in ['update_type', 'update_frequency', 'polyak_coef']), 'Network update not available for DQNBase; use DQN.'
- if global_nets is None:
- in_dim = self.body.state_dim
- out_dim = net_util.get_out_dim(self.body)
- NetClass = getattr(net, self.net_spec['type'])
- self.net = NetClass(self.net_spec, in_dim, out_dim)
- self.target_net = NetClass(self.net_spec, in_dim, out_dim)
- self.net_names = ['net', 'target_net']
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
+ in_dim = self.body.state_dim
+ out_dim = net_util.get_out_dim(self.body)
+ NetClass = getattr(net, self.net_spec['type'])
+ self.net = NetClass(self.net_spec, in_dim, out_dim)
+ self.target_net = NetClass(self.net_spec, in_dim, out_dim)
+ self.net_names = ['net', 'target_net']
+ # init net optimizer and its lr scheduler
+ self.optim = net_util.get_optim(self.net, self.net.optim_spec)
+ self.lr_scheduler = net_util.get_lr_scheduler(self.optim, self.net.lr_scheduler_spec)
+ net_util.set_global_nets(self, global_nets)
self.post_init_nets()
self.online_net = self.target_net
self.eval_net = self.target_net
def calc_q_loss(self, batch):
'''Compute the Q value loss using predicted and target Q values from the appropriate networks'''
- q_preds = self.net.wrap_eval(batch['states'])
+ states = batch['states']
+ next_states = batch['next_states']
+ q_preds = self.net(states)
+ with torch.no_grad():
+ # Use online_net to select actions in next state
+ online_next_q_preds = self.online_net(next_states)
+ # Use eval_net to calculate next_q_preds for actions chosen by online_net
+ next_q_preds = self.eval_net(next_states)
act_q_preds = q_preds.gather(-1, batch['actions'].long().unsqueeze(-1)).squeeze(-1)
- # Use online_net to select actions in next state
- online_next_q_preds = self.online_net.wrap_eval(batch['next_states'])
- # Use eval_net to calculate next_q_preds for actions chosen by online_net
- next_q_preds = self.eval_net.wrap_eval(batch['next_states'])
- max_next_q_preds = next_q_preds.gather(-1, online_next_q_preds.argmax(dim=-1, keepdim=True)).squeeze(-1)
+ online_actions = online_next_q_preds.argmax(dim=-1, keepdim=True)
+ max_next_q_preds = next_q_preds.gather(-1, online_actions).squeeze(-1)
max_q_targets = batch['rewards'] + self.gamma * (1 - batch['dones']) * max_next_q_preds
- max_q_targets = max_q_targets.detach()
+ logger.debug(f'act_q_preds: {act_q_preds}\nmax_q_targets: {max_q_targets}')
q_loss = self.net.loss_fn(act_q_preds, max_q_targets)
# TODO use the same loss_fn but do not reduce yet
if 'Prioritized' in util.get_class_name(self.body.memory): # PER
- errors = torch.abs(max_q_targets - act_q_preds.detach())
+ errors = (max_q_targets - act_q_preds.detach()).abs().cpu().numpy()
self.body.memory.update_priorities(errors)
return q_loss
def update_nets(self):
- total_t = self.body.env.clock.total_t
- if total_t % self.net.update_frequency == 0:
+ if util.frame_mod(self.body.env.clock.frame, self.net.update_frequency, self.body.env.num_envs):
if self.net.update_type == 'replace':
- logger.debug('Updating target_net by replacing')
net_util.copy(self.net, self.target_net)
elif self.net.update_type == 'polyak':
- logger.debug('Updating net by averaging')
net_util.polyak_update(self.net, self.target_net, self.net.polyak_coef)
else:
raise ValueError('Unknown net.update_type. Should be "replace" or "polyak". Exiting.')
@@ -229,7 +226,7 @@ def update_nets(self):
def update(self):
'''Updates self.target_net and the explore variables'''
self.update_nets()
- return super(DQNBase, self).update()
+ return super().update()
class DQN(DQNBase):
@@ -249,15 +246,15 @@ class DQN(DQNBase):
"end_step": 1000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 10,
"training_start_step": 10
}
'''
@lab_api
def init_nets(self, global_nets=None):
- super(DQN, self).init_nets(global_nets)
+ super().init_nets(global_nets)
class DoubleDQN(DQN):
@@ -277,14 +274,14 @@ class DoubleDQN(DQN):
"end_step": 1000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 10,
"training_start_step": 10
}
'''
@lab_api
def init_nets(self, global_nets=None):
- super(DoubleDQN, self).init_nets(global_nets)
+ super().init_nets(global_nets)
self.online_net = self.net
self.eval_net = self.target_net
diff --git a/slm_lab/agent/algorithm/hydra_dqn.py b/slm_lab/agent/algorithm/hydra_dqn.py
deleted file mode 100644
index 80a19fc62..000000000
--- a/slm_lab/agent/algorithm/hydra_dqn.py
+++ /dev/null
@@ -1,123 +0,0 @@
-from slm_lab.agent import net
-from slm_lab.agent.algorithm import policy_util
-from slm_lab.agent.algorithm.sarsa import SARSA
-from slm_lab.agent.algorithm.dqn import DQN
-from slm_lab.lib import logger, util
-from slm_lab.lib.decorator import lab_api
-import numpy as np
-import torch
-
-logger = logger.get_logger(__name__)
-
-
-class HydraDQN(DQN):
- '''Multi-task DQN with separate state and action processors per environment'''
-
- @lab_api
- def init_nets(self, global_nets=None):
- '''Initialize nets with multi-task dimensions, and set net params'''
- # NOTE: Separate init from MultitaskDQN despite similarities so that this implementation can support arbitrary sized state and action heads (e.g. multiple layers)
- self.state_dims = in_dims = [body.state_dim for body in self.agent.nanflat_body_a]
- self.action_dims = out_dims = [body.action_dim for body in self.agent.nanflat_body_a]
- if global_nets is None:
- NetClass = getattr(net, self.net_spec['type'])
- self.net = NetClass(self.net_spec, in_dims, out_dims)
- self.target_net = NetClass(self.net_spec, in_dims, out_dims)
- self.net_names = ['net', 'target_net']
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
- self.post_init_nets()
- self.online_net = self.target_net
- self.eval_net = self.target_net
-
- @lab_api
- def calc_pdparam(self, xs, evaluate=True, net=None):
- '''
- Calculate pdparams for multi-action by chunking the network logits output
- '''
- pdparam = SARSA.calc_pdparam(self, xs, evaluate=evaluate, net=net)
- return pdparam
-
- @lab_api
- def space_act(self, state_a):
- '''Non-atomizable act to override agent.act(), do a single pass on the entire state_a instead of composing act() via iteration'''
- # gather and flatten
- states = []
- for eb, body in util.ndenumerate_nonan(self.agent.body_a):
- state = state_a[eb]
- if self.normalize_state:
- state = policy_util.update_online_stats_and_normalize_state(body, state)
- states.append(state)
- xs = [torch.from_numpy(state).float() for state in states]
- pdparam = self.calc_pdparam(xs, evaluate=False)
- # use multi-policy. note arg change
- action_a, action_pd_a = self.action_policy(states, self, self.agent.nanflat_body_a, pdparam)
- for idx, body in enumerate(self.agent.nanflat_body_a):
- body.action_tensor, body.action_pd = action_a[idx], action_pd_a[idx] # used for body.action_pd_update later
- return action_a.cpu().numpy()
-
- @lab_api
- def space_sample(self):
- '''Samples a batch per body, which may experience different environment'''
- batch = {k: [] for k in self.body.memory.data_keys}
- for body in self.agent.nanflat_body_a:
- body_batch = body.memory.sample()
- if self.normalize_state:
- body_batch = policy_util.normalize_states_and_next_states(body, body_batch)
- body_batch = util.to_torch_batch(body_batch, self.net.device, body.memory.is_episodic)
- for k, arr in batch.items():
- arr.append(body_batch[k])
- return batch
-
- def calc_q_loss(self, batch):
- '''Compute the Q value loss for Hydra network by apply the singleton logic on generalized aggregate.'''
- q_preds = torch.stack(self.net.wrap_eval(batch['states']))
- act_q_preds = q_preds.gather(-1, torch.stack(batch['actions']).long().unsqueeze(-1)).squeeze(-1)
- # Use online_net to select actions in next state
- online_next_q_preds = torch.stack(self.online_net.wrap_eval(batch['next_states']))
- # Use eval_net to calculate next_q_preds for actions chosen by online_net
- next_q_preds = torch.stack(self.eval_net.wrap_eval(batch['next_states']))
- max_next_q_preds = online_next_q_preds.gather(-1, next_q_preds.argmax(dim=-1, keepdim=True)).squeeze(-1)
- max_q_targets = torch.stack(batch['rewards']) + self.gamma * (1 - torch.stack(batch['dones'])) * max_next_q_preds
- q_loss = self.net.loss_fn(act_q_preds, max_q_targets)
-
- # TODO use the same loss_fn but do not reduce yet
- for body in self.agent.nanflat_body_a:
- if 'Prioritized' in util.get_class_name(body.memory): # PER
- errors = torch.abs(max_q_targets - act_q_preds)
- body.memory.update_priorities(errors)
- return q_loss
-
- @lab_api
- def space_train(self):
- '''
- Completes one training step for the agent if it is time to train.
- i.e. the environment timestep is greater than the minimum training timestep and a multiple of the training_frequency.
- Each training step consists of sampling n batches from the agent's memory.
- For each of the batches, the target Q values (q_targets) are computed and a single training step is taken k times
- Otherwise this function does nothing.
- '''
- if util.in_eval_lab_modes():
- self.body.flush()
- return np.nan
- clock = self.body.env.clock # main clock
- tick = util.s_get(self, 'aeb_space.clock').get(clock.max_tick_unit)
- self.to_train = (tick > self.training_start_step and tick % self.training_frequency == 0)
- if self.to_train == 1:
- total_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
- batch = self.space_sample()
- for _ in range(self.training_batch_epoch):
- loss = self.calc_q_loss(batch)
- self.net.training_step(loss=loss, lr_clock=clock)
- total_loss += loss
- loss = total_loss / (self.training_epoch * self.training_batch_epoch)
- # reset
- self.to_train = 0
- for body in self.agent.nanflat_body_a:
- body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
- return loss.item()
- else:
- return np.nan
diff --git a/slm_lab/agent/algorithm/policy_util.py b/slm_lab/agent/algorithm/policy_util.py
index 5cd7aa23f..679821220 100644
--- a/slm_lab/agent/algorithm/policy_util.py
+++ b/slm_lab/agent/algorithm/policy_util.py
@@ -1,200 +1,151 @@
-'''
-Action policy methods to sampling actions
-Algorithm provides a `calc_pdparam` which takes a state and do a forward pass through its net,
-and the pdparam is used to construct an action probability distribution as appropriate per the action type as indicated by the body
-Then the prob. dist. is used to sample action.
-
-The default form looks like:
-```
-ActionPD, pdparam, body = init_action_pd(state, algorithm, body)
-action, action_pd = sample_action_pd(ActionPD, pdparam, body)
-```
-
-We can also augment pdparam before sampling - as in the case of Boltzmann sampling,
-or do epsilon-greedy to use pdparam-sampling or random sampling.
-'''
+# Action policy module
+# Constructs action probability distribution used by agent to sample action and calculate log_prob, entropy, etc.
+from gym import spaces
from slm_lab.env.wrapper import LazyFrames
-from slm_lab.lib import logger, math_util, util
+from slm_lab.lib import distribution, logger, math_util, util
from torch import distributions
import numpy as np
import pydash as ps
import torch
+import torch.nn.functional as F
logger = logger.get_logger(__name__)
-
+# register custom distributions
+setattr(distributions, 'Argmax', distribution.Argmax)
+setattr(distributions, 'GumbelCategorical', distribution.GumbelCategorical)
+setattr(distributions, 'MultiCategorical', distribution.MultiCategorical)
# probability distributions constraints for different action types; the first in the list is the default
ACTION_PDS = {
'continuous': ['Normal', 'Beta', 'Gumbel', 'LogNormal'],
'multi_continuous': ['MultivariateNormal'],
- 'discrete': ['Categorical', 'Argmax'],
+ 'discrete': ['Categorical', 'Argmax', 'GumbelCategorical'],
'multi_discrete': ['MultiCategorical'],
'multi_binary': ['Bernoulli'],
}
-class Argmax(distributions.Categorical):
- '''
- Special distribution class for argmax sampling, where probability is always 1 for the argmax.
- NOTE although argmax is not a sampling distribution, this implementation is for API consistency.
- '''
-
- def __init__(self, probs=None, logits=None, validate_args=None):
- if probs is not None:
- new_probs = torch.zeros_like(probs, dtype=torch.float)
- new_probs[torch.argmax(probs, dim=0)] = 1.0
- probs = new_probs
- elif logits is not None:
- new_logits = torch.full_like(logits, -1e8, dtype=torch.float)
- max_idx = torch.argmax(logits, dim=0)
- new_logits[max_idx] = logits[max_idx]
- logits = new_logits
-
- super(Argmax, self).__init__(probs=probs, logits=logits, validate_args=validate_args)
-
-
-class MultiCategorical(distributions.Categorical):
- '''MultiCategorical as collection of Categoricals'''
-
- def __init__(self, probs=None, logits=None, validate_args=None):
- self.categoricals = []
- if probs is None:
- probs = [None] * len(logits)
- elif logits is None:
- logits = [None] * len(probs)
+def get_action_type(action_space):
+ '''Method to get the action type to choose prob. dist. to sample actions from NN logits output'''
+ if isinstance(action_space, spaces.Box):
+ shape = action_space.shape
+ assert len(shape) == 1
+ if shape[0] == 1:
+ return 'continuous'
else:
- raise ValueError('Either probs or logits must be None')
-
- for sub_probs, sub_logits in zip(probs, logits):
- categorical = distributions.Categorical(probs=sub_probs, logits=sub_logits, validate_args=validate_args)
- self.categoricals.append(categorical)
-
- @property
- def logits(self):
- return [cat.logits for cat in self.categoricals]
-
- @property
- def probs(self):
- return [cat.probs for cat in self.categoricals]
-
- @property
- def param_shape(self):
- return [cat.param_shape for cat in self.categoricals]
-
- @property
- def mean(self):
- return torch.stack([cat.mean for cat in self.categoricals])
-
- @property
- def variance(self):
- return torch.stack([cat.variance for cat in self.categoricals])
-
- def sample(self, sample_shape=torch.Size()):
- return torch.stack([cat.sample(sample_shape=sample_shape) for cat in self.categoricals])
-
- def log_prob(self, value):
- return torch.stack([cat.log_prob(value[idx]) for idx, cat in enumerate(self.categoricals)])
-
- def entropy(self):
- return torch.stack([cat.entropy() for cat in self.categoricals])
-
- def enumerate_support(self):
- return [cat.enumerate_support() for cat in self.categoricals]
+ return 'multi_continuous'
+ elif isinstance(action_space, spaces.Discrete):
+ return 'discrete'
+ elif isinstance(action_space, spaces.MultiDiscrete):
+ return 'multi_discrete'
+ elif isinstance(action_space, spaces.MultiBinary):
+ return 'multi_binary'
+ else:
+ raise NotImplementedError
-setattr(distributions, 'Argmax', Argmax)
-setattr(distributions, 'MultiCategorical', MultiCategorical)
+# action_policy base methods
+def get_action_pd_cls(action_pdtype, action_type):
+ '''
+ Verify and get the action prob. distribution class for construction
+ Called by body at init to set its own ActionPD
+ '''
+ pdtypes = ACTION_PDS[action_type]
+ assert action_pdtype in pdtypes, f'Pdtype {action_pdtype} is not compatible/supported with action_type {action_type}. Options are: {pdtypes}'
+ ActionPD = getattr(distributions, action_pdtype)
+ return ActionPD
-# base methods
-def try_preprocess(state, algorithm, body, append=True):
- '''Try calling preprocess as implemented in body's memory to use for net input'''
+def guard_tensor(state, body):
+ '''Guard-cast tensor before being input to network'''
if isinstance(state, LazyFrames):
- state = state.__array__() # from global env preprocessor
- if hasattr(body.memory, 'preprocess_state'):
- state = body.memory.preprocess_state(state, append=append)
- # as float, and always as minibatch for net input
- state = torch.from_numpy(state).float().unsqueeze(dim=0)
+ state = state.__array__() # realize data
+ state = torch.from_numpy(state.astype(np.float32))
+ if not body.env.is_venv or util.in_eval_lab_modes():
+ # singleton state, unsqueeze as minibatch for net input
+ state = state.unsqueeze(dim=0)
return state
-def cond_squeeze(out):
- '''Helper to squeeze output depending if it is tensor (discrete pdparam) or list of tensors (continuous pdparam of loc and scale)'''
- if isinstance(out, list):
- return [out_t.squeeze(dim=0) for out_t in out]
- else:
- return out.squeeze(dim=0)
+def calc_pdparam(state, algorithm, body):
+ '''
+ Prepare the state and run algorithm.calc_pdparam to get pdparam for action_pd
+ @param tensor:state For pdparam = net(state)
+ @param algorithm The algorithm containing self.net
+ @param body Body which links algorithm to the env which the action is for
+ @returns tensor:pdparam
+ @example
+
+ pdparam = calc_pdparam(state, algorithm, body)
+ action_pd = ActionPD(logits=pdparam) # e.g. ActionPD is Categorical
+ action = action_pd.sample()
+ '''
+ if not torch.is_tensor(state): # dont need to cast from numpy
+ state = guard_tensor(state, body)
+ state = state.to(algorithm.net.device)
+ pdparam = algorithm.calc_pdparam(state)
+ return pdparam
-def init_action_pd(state, algorithm, body, append=True):
+def init_action_pd(ActionPD, pdparam):
'''
- Build the proper action prob. dist. to use for action sampling.
- state is passed through algorithm's net via calc_pdparam, which the algorithm must implement using its proper net.
- This will return body, ActionPD and pdparam to allow augmentation, e.g. applying temperature tau to pdparam for boltzmann.
- Then, output must be called with sample_action_pd(body, ActionPD, pdparam) to sample action.
- @returns {cls, tensor, *} ActionPD, pdparam, body
+ Initialize the action_pd for discrete or continuous actions:
+ - discrete: action_pd = ActionPD(logits)
+ - continuous: action_pd = ActionPD(loc, scale)
'''
- pdtypes = ACTION_PDS[body.action_type]
- assert body.action_pdtype in pdtypes, f'Pdtype {body.action_pdtype} is not compatible/supported with action_type {body.action_type}. Options are: {ACTION_PDS[body.action_type]}'
- ActionPD = getattr(distributions, body.action_pdtype)
-
- state = try_preprocess(state, algorithm, body, append=append)
- state = state.to(algorithm.net.device)
- pdparam = algorithm.calc_pdparam(state, evaluate=False)
- return ActionPD, pdparam, body
+ if 'logits' in ActionPD.arg_constraints: # discrete
+ action_pd = ActionPD(logits=pdparam)
+ else: # continuous, args = loc and scale
+ if isinstance(pdparam, list): # split output
+ loc, scale = pdparam
+ else:
+ loc, scale = pdparam.transpose(0, 1)
+ # scale (stdev) must be > 0, use softplus with positive
+ scale = F.softplus(scale) + 1e-8
+ if isinstance(pdparam, list): # split output
+ # construct covars from a batched scale tensor
+ covars = torch.diag_embed(scale)
+ action_pd = ActionPD(loc=loc, covariance_matrix=covars)
+ else:
+ action_pd = ActionPD(loc=loc, scale=scale)
+ return action_pd
-def sample_action_pd(ActionPD, pdparam, body):
+def sample_action(ActionPD, pdparam):
'''
- This uses the outputs from init_action_pd and an optionally augmented pdparam to construct a action_pd for sampling action
- @returns {tensor, distribution} action, action_pd A sampled action, and the prob. dist. used for sampling to enable calculations like kl, entropy, etc. later.
+ Convenience method to sample action(s) from action_pd = ActionPD(pdparam)
+ Works with batched pdparam too
+ @returns tensor:action Sampled action(s)
+ @example
+
+ # policy contains:
+ pdparam = calc_pdparam(state, algorithm, body)
+ action = sample_action(body.ActionPD, pdparam)
'''
- pdparam = cond_squeeze(pdparam)
- if body.is_discrete:
- action_pd = ActionPD(logits=pdparam)
- else: # continuous outputs a list, loc and scale
- assert len(pdparam) == 2, pdparam
- # scale (stdev) must be >0, use softplus
- if pdparam[1] < 5:
- pdparam[1] = torch.log(1 + torch.exp(pdparam[1])) + 1e-8
- action_pd = ActionPD(*pdparam)
+ action_pd = init_action_pd(ActionPD, pdparam)
action = action_pd.sample()
- return action, action_pd
+ return action
-# interface action sampling methods
+# action_policy used by agent
def default(state, algorithm, body):
- '''Plain policy by direct sampling using outputs of net as logits and constructing ActionPD as appropriate'''
- ActionPD, pdparam, body = init_action_pd(state, algorithm, body)
- action, action_pd = sample_action_pd(ActionPD, pdparam, body)
- return action, action_pd
+ '''Plain policy by direct sampling from a default action probability defined by body.ActionPD'''
+ pdparam = calc_pdparam(state, algorithm, body)
+ action = sample_action(body.ActionPD, pdparam)
+ return action
def random(state, algorithm, body):
- '''Random action sampling that returns the same data format as default(), but without forward pass. Uses gym.space.sample()'''
- state = try_preprocess(state, algorithm, body, append=True) # for consistency with init_action_pd inner logic
- if body.action_type == 'discrete':
- action_pd = distributions.Categorical(logits=torch.ones(body.action_space.high, device=algorithm.net.device))
- elif body.action_type == 'continuous':
- # Possibly this should this have a 'device' set
- action_pd = distributions.Uniform(
- low=torch.tensor(body.action_space.low).float(),
- high=torch.tensor(body.action_space.high).float())
- elif body.action_type == 'multi_discrete':
- action_pd = distributions.Categorical(
- logits=torch.ones(body.action_space.high.size, body.action_space.high[0], device=algorithm.net.device))
- elif body.action_type == 'multi_continuous':
- raise NotImplementedError
- elif body.action_type == 'multi_binary':
- raise NotImplementedError
+ '''Random action using gym.action_space.sample(), with the same format as default()'''
+ if body.env.is_venv and not util.in_eval_lab_modes():
+ _action = [body.action_space.sample() for _ in range(body.env.num_envs)]
else:
- raise NotImplementedError
- sample = body.action_space.sample()
- action = torch.tensor(sample, device=algorithm.net.device)
- return action, action_pd
+ _action = body.action_space.sample()
+ action = torch.tensor([_action])
+ return action
def epsilon_greedy(state, algorithm, body):
@@ -211,13 +162,14 @@ def boltzmann(state, algorithm, body):
Boltzmann policy: adjust pdparam with temperature tau; the higher the more randomness/noise in action.
'''
tau = body.explore_var
- ActionPD, pdparam, body = init_action_pd(state, algorithm, body)
+ pdparam = calc_pdparam(state, algorithm, body)
pdparam /= tau
- action, action_pd = sample_action_pd(ActionPD, pdparam, body)
- return action, action_pd
+ action = sample_action(body.ActionPD, pdparam)
+ return action
-# multi-body policy with a single forward pass to calc pdparam
+# multi-body/multi-env action_policy used by agent
+# TODO rework
def multi_default(states, algorithm, body_list, pdparam):
'''
@@ -225,70 +177,61 @@ def multi_default(states, algorithm, body_list, pdparam):
Note, for efficiency, do a single forward pass to calculate pdparam, then call this policy like:
@example
- pdparam = self.calc_pdparam(state, evaluate=False)
- action_a, action_pd_a = self.action_policy(pdparam, self, body_list)
+ pdparam = self.calc_pdparam(state)
+ action_a = self.action_policy(pdparam, self, body_list)
'''
- pdparam = pdparam.squeeze(dim=0)
# assert pdparam has been chunked
assert len(pdparam.shape) > 1 and len(pdparam) == len(body_list), f'pdparam shape: {pdparam.shape}, bodies: {len(body_list)}'
- action_list, action_pd_a = [], []
+ action_list = []
for idx, sub_pdparam in enumerate(pdparam):
body = body_list[idx]
- try_preprocess(states[idx], algorithm, body, append=True) # for consistency with init_action_pd inner logic
- ActionPD = getattr(distributions, body.action_pdtype)
- action, action_pd = sample_action_pd(ActionPD, sub_pdparam, body)
+ guard_tensor(states[idx], body) # for consistency with singleton inner logic
+ action = sample_action(body.ActionPD, sub_pdparam)
action_list.append(action)
- action_pd_a.append(action_pd)
action_a = torch.tensor(action_list, device=algorithm.net.device).unsqueeze(dim=1)
- return action_a, action_pd_a
+ return action_a
def multi_random(states, algorithm, body_list, pdparam):
'''Apply random policy body-wise.'''
- pdparam = pdparam.squeeze(dim=0)
- action_list, action_pd_a = [], []
+ action_list = []
for idx, body in body_list:
- action, action_pd = random(states[idx], algorithm, body)
+ action = random(states[idx], algorithm, body)
action_list.append(action)
- action_pd_a.append(action_pd)
action_a = torch.tensor(action_list, device=algorithm.net.device).unsqueeze(dim=1)
- return action_a, action_pd_a
+ return action_a
def multi_epsilon_greedy(states, algorithm, body_list, pdparam):
'''Apply epsilon-greedy policy body-wise'''
assert len(pdparam) > 1 and len(pdparam) == len(body_list), f'pdparam shape: {pdparam.shape}, bodies: {len(body_list)}'
- action_list, action_pd_a = [], []
+ action_list = []
for idx, sub_pdparam in enumerate(pdparam):
body = body_list[idx]
epsilon = body.explore_var
if epsilon > np.random.rand():
- action, action_pd = random(states[idx], algorithm, body)
+ action = random(states[idx], algorithm, body)
else:
- try_preprocess(states[idx], algorithm, body, append=True) # for consistency with init_action_pd inner logic
- ActionPD = getattr(distributions, body.action_pdtype)
- action, action_pd = sample_action_pd(ActionPD, sub_pdparam, body)
+ guard_tensor(states[idx], body) # for consistency with singleton inner logic
+ action = sample_action(body.ActionPD, sub_pdparam)
action_list.append(action)
- action_pd_a.append(action_pd)
action_a = torch.tensor(action_list, device=algorithm.net.device).unsqueeze(dim=1)
- return action_a, action_pd_a
+ return action_a
def multi_boltzmann(states, algorithm, body_list, pdparam):
'''Apply Boltzmann policy body-wise'''
assert len(pdparam) > 1 and len(pdparam) == len(body_list), f'pdparam shape: {pdparam.shape}, bodies: {len(body_list)}'
- action_list, action_pd_a = [], []
+ action_list = []
for idx, sub_pdparam in enumerate(pdparam):
body = body_list[idx]
- try_preprocess(states[idx], algorithm, body, append=True) # for consistency with init_action_pd inner logic
+ guard_tensor(states[idx], body) # for consistency with singleton inner logic
tau = body.explore_var
sub_pdparam /= tau
- ActionPD = getattr(distributions, body.action_pdtype)
- action, action_pd = sample_action_pd(ActionPD, sub_pdparam, body)
+ action = sample_action(body.ActionPD, sub_pdparam)
action_list.append(action)
- action_pd_a.append(action_pd)
action_a = torch.tensor(action_list, device=algorithm.net.device).unsqueeze(dim=1)
- return action_a, action_pd_a
+ return action_a
# action policy update methods
@@ -326,162 +269,6 @@ def update(self, algorithm, clock):
'''Get an updated value for var'''
if (util.in_eval_lab_modes()) or self._updater_name == 'no_decay':
return self.end_val
- step = clock.get(clock.max_tick_unit)
+ step = clock.get()
val = self._updater(self.start_val, self.end_val, self.start_step, self.end_step, step)
return val
-
-
-# misc calc methods
-
-def guard_multi_pdparams(pdparams, body):
- '''Guard pdparams for multi action'''
- action_dim = body.action_dim
- is_multi_action = ps.is_iterable(action_dim)
- if is_multi_action:
- assert ps.is_list(pdparams)
- pdparams = [t.clone() for t in pdparams] # clone for grad safety
- assert len(pdparams) == len(action_dim), pdparams
- # transpose into (batch_size, [action_dims])
- pdparams = [list(torch.split(t, action_dim, dim=0)) for t in torch.cat(pdparams, dim=1)]
- return pdparams
-
-
-def calc_log_probs(algorithm, net, body, batch):
- '''
- Method to calculate log_probs fresh from batch data
- Body already stores log_prob from self.net. This is used for PPO where log_probs needs to be recalculated.
- '''
- states, actions = batch['states'], batch['actions']
- action_dim = body.action_dim
- is_multi_action = ps.is_iterable(action_dim)
- # construct log_probs for each state-action
- pdparams = algorithm.calc_pdparam(states, net=net)
- pdparams = guard_multi_pdparams(pdparams, body)
- assert len(pdparams) == len(states), f'batch_size of pdparams: {len(pdparams)} vs states: {len(states)}'
-
- pdtypes = ACTION_PDS[body.action_type]
- ActionPD = getattr(distributions, body.action_pdtype)
-
- log_probs = []
- for idx, pdparam in enumerate(pdparams):
- if not is_multi_action: # already cloned for multi_action above
- pdparam = pdparam.clone() # clone for grad safety
- _action, action_pd = sample_action_pd(ActionPD, pdparam, body)
- log_probs.append(action_pd.log_prob(actions[idx].float()).sum(dim=0))
- log_probs = torch.stack(log_probs)
- assert not torch.isnan(log_probs).any(), f'log_probs: {log_probs}, \npdparams: {pdparams} \nactions: {actions}'
- logger.debug(f'log_probs: {log_probs}')
- return log_probs
-
-
-def update_online_stats(body, state):
- '''
- Method to calculate the running mean and standard deviation of the state space.
- See https://www.johndcook.com/blog/standard_deviation/ for more details
- for n >= 1
- M_n = M_n-1 + (state - M_n-1) / n
- S_n = S_n-1 + (state - M_n-1) * (state - M_n)
- variance = S_n / (n - 1)
- std_dev = sqrt(variance)
- '''
- logger.debug(f'mean: {body.state_mean}, std: {body.state_std_dev}, num examples: {body.state_n}')
- # Assumes only one state is given
- if ('Atari' in util.get_class_name(body.memory)):
- assert state.ndim == 3
- elif getattr(body.memory, 'raw_state_dim', False):
- assert state.size == body.memory.raw_state_dim
- else:
- assert state.size == body.state_dim or state.shape == body.state_dim
- mean = body.state_mean
- body.state_n += 1
- if np.isnan(mean).any():
- assert np.isnan(body.state_std_dev_int)
- assert np.isnan(body.state_std_dev)
- body.state_mean = state
- body.state_std_dev_int = 0
- body.state_std_dev = 0
- else:
- assert body.state_n > 1
- body.state_mean = mean + (state - mean) / body.state_n
- body.state_std_dev_int = body.state_std_dev_int + (state - mean) * (state - body.state_mean)
- body.state_std_dev = np.sqrt(body.state_std_dev_int / (body.state_n - 1))
- # Guard against very small std devs
- if (body.state_std_dev < 1e-8).any():
- body.state_std_dev[np.where(body.state_std_dev < 1e-8)] += 1e-8
- logger.debug(f'new mean: {body.state_mean}, new std: {body.state_std_dev}, num examples: {body.state_n}')
-
-
-def normalize_state(body, state):
- '''
- Normalizes one or more states using a running mean and standard deviation
- Details of the normalization from Deep RL Bootcamp, L6
- https://www.youtube.com/watch?v=8EcdaCk9KaQ&feature=youtu.be
- '''
- same_shape = False if type(state) == list else state.shape == body.state_mean.shape
- has_preprocess = getattr(body.memory, 'preprocess_state', False)
- if ('Atari' in util.get_class_name(body.memory)):
- # never normalize atari, it has its own normalization step
- logger.debug('skipping normalizing for Atari, already handled by preprocess')
- return state
- elif ('Replay' in util.get_class_name(body.memory)) and has_preprocess:
- # normalization handled by preprocess_state function in the memory
- logger.debug('skipping normalizing, already handled by preprocess')
- return state
- elif same_shape:
- # if not atari, always normalize the state the first time we see it during act
- # if the shape is not transformed in some way
- if np.sum(body.state_std_dev) == 0:
- return np.clip(state - body.state_mean, -10, 10)
- else:
- return np.clip((state - body.state_mean) / body.state_std_dev, -10, 10)
- else:
- # broadcastable sample from an un-normalized memory so we should normalize
- logger.debug('normalizing sample from memory')
- if np.sum(body.state_std_dev) == 0:
- return np.clip(state - body.state_mean, -10, 10)
- else:
- return np.clip((state - body.state_mean) / body.state_std_dev, -10, 10)
-
-
-# TODO Not currently used, this will crash for more exotic memory structures
-# def unnormalize_state(body, state):
-# '''
-# Un-normalizes one or more states using a running mean and new_std_dev
-# '''
-# return state * body.state_mean + body.state_std_dev
-
-
-def update_online_stats_and_normalize_state(body, state):
- '''
- Convenience combination function for updating running state mean and std_dev and normalizing the state in one go.
- '''
- logger.debug(f'state: {state}')
- update_online_stats(body, state)
- state = normalize_state(body, state)
- logger.debug(f'normalized state: {state}')
- return state
-
-
-def normalize_states_and_next_states(body, batch, episodic_flag=None):
- '''
- Convenience function for normalizing the states and next states in a batch of data
- '''
- logger.debug(f'states: {batch["states"]}')
- logger.debug(f'next states: {batch["next_states"]}')
- episodic = episodic_flag if episodic_flag is not None else body.memory.is_episodic
- logger.debug(f'Episodic: {episodic}, episodic_flag: {episodic_flag}, body.memory: {body.memory.is_episodic}')
- if episodic:
- normalized = []
- for epi in batch['states']:
- normalized.append(normalize_state(body, epi))
- batch['states'] = normalized
- normalized = []
- for epi in batch['next_states']:
- normalized.append(normalize_state(body, epi))
- batch['next_states'] = normalized
- else:
- batch['states'] = normalize_state(body, batch['states'])
- batch['next_states'] = normalize_state(body, batch['next_states'])
- logger.debug(f'normalized states: {batch["states"]}')
- logger.debug(f'normalized next states: {batch["next_states"]}')
- return batch
diff --git a/slm_lab/agent/algorithm/ppo.py b/slm_lab/agent/algorithm/ppo.py
index ab340ca61..c3b509ee2 100644
--- a/slm_lab/agent/algorithm/ppo.py
+++ b/slm_lab/agent/algorithm/ppo.py
@@ -51,9 +51,9 @@ class PPO(ActorCritic):
"start_step": 100,
"end_step": 5000,
},
+ "minibatch_size": 256,
"training_frequency": 1,
"training_epoch": 8,
- "normalize_state": true
}
e.g. special net_spec param "shared" to share/separate Actor/Critic
@@ -72,6 +72,7 @@ def init_algorithm_params(self):
action_policy='default',
explore_var_spec=None,
entropy_coef_spec=None,
+ minibatch_size=4,
val_loss_coef=1.0,
))
util.set_attr(self, self.algorithm_spec, [
@@ -84,9 +85,9 @@ def init_algorithm_params(self):
'clip_eps_spec',
'entropy_coef_spec',
'val_loss_coef',
+ 'minibatch_size',
'training_frequency', # horizon
'training_epoch',
- 'normalize_state',
])
self.to_train = 0
self.action_policy = getattr(policy_util, self.action_policy)
@@ -104,12 +105,12 @@ def init_algorithm_params(self):
@lab_api
def init_nets(self, global_nets=None):
'''PPO uses old and new to calculate ratio for loss'''
- super(PPO, self).init_nets(global_nets)
+ super().init_nets(global_nets)
# create old net to calculate ratio
self.old_net = deepcopy(self.net)
assert id(self.old_net) != id(self.net)
- def calc_policy_loss(self, batch, advs):
+ def calc_policy_loss(self, batch, pdparams, advs):
'''
The PPO loss function (subscript t is omitted)
L^{CLIP+VF+S} = E[ L^CLIP - c1 * L^VF + c2 * S[pi](s) ]
@@ -123,92 +124,84 @@ def calc_policy_loss(self, batch, advs):
3. S = E[ entropy ]
'''
clip_eps = self.body.clip_eps
+ action_pd = policy_util.init_action_pd(self.body.ActionPD, pdparams)
+ states = batch['states']
+ actions = batch['actions']
+ if self.body.env.is_venv:
+ states = math_util.venv_unpack(states)
+ actions = math_util.venv_unpack(actions)
# L^CLIP
- log_probs = policy_util.calc_log_probs(self, self.net, self.body, batch)
- old_log_probs = policy_util.calc_log_probs(self, self.old_net, self.body, batch).detach()
+ log_probs = action_pd.log_prob(actions)
+ with torch.no_grad():
+ old_pdparams = self.calc_pdparam(states, net=self.old_net)
+ old_action_pd = policy_util.init_action_pd(self.body.ActionPD, old_pdparams)
+ old_log_probs = old_action_pd.log_prob(actions)
assert log_probs.shape == old_log_probs.shape
- assert advs.shape[0] == log_probs.shape[0] # batch size
ratios = torch.exp(log_probs - old_log_probs) # clip to prevent overflow
logger.debug(f'ratios: {ratios}')
sur_1 = ratios * advs
sur_2 = torch.clamp(ratios, 1.0 - clip_eps, 1.0 + clip_eps) * advs
# flip sign because need to maximize
- clip_loss = -torch.mean(torch.min(sur_1, sur_2))
+ clip_loss = -torch.min(sur_1, sur_2).mean()
logger.debug(f'clip_loss: {clip_loss}')
# L^VF (inherit from ActorCritic)
# S entropy bonus
- entropies = torch.stack(self.body.entropies)
- ent_penalty = torch.mean(-self.body.entropy_coef * entropies)
+ entropy = action_pd.entropy().mean()
+ self.body.mean_entropy = entropy # update logging variable
+ ent_penalty = -self.body.entropy_coef * entropy
logger.debug(f'ent_penalty: {ent_penalty}')
policy_loss = clip_loss + ent_penalty
logger.debug(f'PPO Actor policy loss: {policy_loss:g}')
return policy_loss
- def train_shared(self):
- '''
- Trains the network when the actor and critic share parameters
- '''
- clock = self.body.env.clock
- if self.to_train == 1:
- # update old net
- torch.cuda.empty_cache()
- net_util.copy(self.net, self.old_net)
- batch = self.sample()
- total_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
- with torch.no_grad():
- advs, v_targets = self.calc_advs_v_targets(batch)
- policy_loss = self.calc_policy_loss(batch, advs) # from actor
- val_loss = self.calc_val_loss(batch, v_targets) # from critic
- loss = policy_loss + val_loss
- # retain for entropies etc.
- self.net.training_step(loss=loss, lr_clock=clock, retain_graph=True)
- total_loss += loss
- loss = total_loss / self.training_epoch
- # reset
- self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
- return loss.item()
- else:
+ def train(self):
+ if util.in_eval_lab_modes():
return np.nan
-
- def train_separate(self):
- '''
- Trains the network when the actor and critic share parameters
- '''
clock = self.body.env.clock
if self.to_train == 1:
- torch.cuda.empty_cache()
- net_util.copy(self.net, self.old_net)
+ net_util.copy(self.net, self.old_net) # update old net
batch = self.sample()
- policy_loss = self.train_actor(batch)
- val_loss = self.train_critic(batch)
- loss = val_loss + policy_loss
+ clock.set_batch_size(len(batch))
+ _pdparams, v_preds = self.calc_pdparam_v(batch)
+ advs, v_targets = self.calc_advs_v_targets(batch, v_preds)
+ # piggy back on batch, but remember to not pack or unpack
+ batch['advs'], batch['v_targets'] = advs, v_targets
+ if self.body.env.is_venv: # unpack if venv for minibatch sampling
+ for k, v in batch.items():
+ if k not in ('advs', 'v_targets'):
+ batch[k] = math_util.venv_unpack(v)
+ total_loss = torch.tensor(0.0)
+ for _ in range(self.training_epoch):
+ minibatches = util.split_minibatch(batch, self.minibatch_size)
+ for minibatch in minibatches:
+ if self.body.env.is_venv: # re-pack to restore proper shape
+ for k, v in minibatch.items():
+ if k not in ('advs', 'v_targets'):
+ minibatch[k] = math_util.venv_pack(v, self.body.env.num_envs)
+ advs, v_targets = minibatch['advs'], minibatch['v_targets']
+ pdparams, v_preds = self.calc_pdparam_v(minibatch)
+ policy_loss = self.calc_policy_loss(minibatch, pdparams, advs) # from actor
+ val_loss = self.calc_val_loss(v_preds, v_targets) # from critic
+ if self.shared: # shared network
+ loss = policy_loss + val_loss
+ self.net.train_step(loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
+ else:
+ self.net.train_step(policy_loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
+ self.critic_net.train_step(val_loss, self.critic_optim, self.critic_lr_scheduler, clock=clock, global_net=self.global_critic_net)
+ loss = policy_loss + val_loss
+ total_loss += loss
+ loss = total_loss / self.training_epoch / len(minibatches)
# reset
self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
return loss.item()
else:
return np.nan
- def train_actor(self, batch):
- '''Trains the actor when the actor and critic are separate networks'''
- total_policy_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
- with torch.no_grad():
- advs, _v_targets = self.calc_advs_v_targets(batch)
- policy_loss = self.calc_policy_loss(batch, advs)
- # retain for entropies etc.
- self.net.training_step(loss=policy_loss, lr_clock=self.body.env.clock, retain_graph=True)
- val_loss = total_policy_loss / self.training_epoch
- return policy_loss
-
@lab_api
def update(self):
self.body.explore_var = self.explore_var_scheduler.update(self, self.body.env.clock)
diff --git a/slm_lab/agent/algorithm/random.py b/slm_lab/agent/algorithm/random.py
index 3ee1079d5..6fbb876d6 100644
--- a/slm_lab/agent/algorithm/random.py
+++ b/slm_lab/agent/algorithm/random.py
@@ -1,7 +1,5 @@
-'''
-The random agent algorithm
-For basic dev purpose.
-'''
+# The random agent algorithm
+# For basic dev purpose
from slm_lab.agent.algorithm.base import Algorithm
from slm_lab.lib import logger
from slm_lab.lib.decorator import lab_api
@@ -20,16 +18,21 @@ def init_algorithm_params(self):
'''Initialize other algorithm parameters'''
self.to_train = 0
self.training_frequency = 1
+ self.training_start_step = 0
@lab_api
def init_nets(self, global_nets=None):
'''Initialize the neural network from the spec'''
- pass
+ self.net_names = []
@lab_api
def act(self, state):
'''Random action'''
- action = self.body.action_space.sample()
+ body = self.body
+ if body.env.is_venv and not util.in_eval_lab_modes():
+ action = np.array([body.action_space.sample() for _ in range(body.env.num_envs)])
+ else:
+ action = body.action_space.sample()
return action
@lab_api
@@ -41,6 +44,7 @@ def sample(self):
@lab_api
def train(self):
self.sample()
+ self.body.env.clock.tick('opt_step') # to simulate metrics calc
loss = np.nan
return loss
diff --git a/slm_lab/agent/algorithm/reinforce.py b/slm_lab/agent/algorithm/reinforce.py
index 33a9d7351..528edd1ba 100644
--- a/slm_lab/agent/algorithm/reinforce.py
+++ b/slm_lab/agent/algorithm/reinforce.py
@@ -5,8 +5,6 @@
from slm_lab.lib import logger, math_util, util
from slm_lab.lib.decorator import lab_api
import numpy as np
-import pydash as ps
-import torch
logger = logger.get_logger(__name__)
@@ -39,7 +37,6 @@ class Reinforce(Algorithm):
"end_step": 5000,
},
"training_frequency": 1,
- "normalize_state": true
}
'''
@@ -52,6 +49,7 @@ def init_algorithm_params(self):
action_policy='default',
explore_var_spec=None,
entropy_coef_spec=None,
+ policy_loss_coef=1.0,
))
util.set_attr(self, self.algorithm_spec, [
'action_pdtype',
@@ -60,8 +58,8 @@ def init_algorithm_params(self):
'explore_var_spec',
'gamma', # the discount factor
'entropy_coef_spec',
+ 'policy_loss_coef',
'training_frequency',
- 'normalize_state',
])
self.to_train = 0
self.action_policy = getattr(policy_util, self.action_policy)
@@ -79,86 +77,90 @@ def init_nets(self, global_nets=None):
Networks for continuous action spaces have two heads and return two values, the first is a tensor containing the mean of the action policy, the second is a tensor containing the std deviation of the action policy. The distribution is assumed to be a Gaussian (Normal) distribution.
Networks for discrete action spaces have a single head and return the logits for a categorical probability distribution over the discrete actions
'''
- if global_nets is None:
- in_dim = self.body.state_dim
- out_dim = net_util.get_out_dim(self.body)
- NetClass = getattr(net, self.net_spec['type'])
- self.net = NetClass(self.net_spec, in_dim, out_dim)
- self.net_names = ['net']
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
+ in_dim = self.body.state_dim
+ out_dim = net_util.get_out_dim(self.body)
+ NetClass = getattr(net, self.net_spec['type'])
+ self.net = NetClass(self.net_spec, in_dim, out_dim)
+ self.net_names = ['net']
+ # init net optimizer and its lr scheduler
+ self.optim = net_util.get_optim(self.net, self.net.optim_spec)
+ self.lr_scheduler = net_util.get_lr_scheduler(self.optim, self.net.lr_scheduler_spec)
+ net_util.set_global_nets(self, global_nets)
self.post_init_nets()
@lab_api
- def calc_pdparam(self, x, evaluate=True, net=None):
+ def calc_pdparam(self, x, net=None):
'''
The pdparam will be the logits for discrete prob. dist., or the mean and std for continuous prob. dist.
'''
net = self.net if net is None else net
- if evaluate:
- pdparam = net.wrap_eval(x)
- else:
- net.train()
- pdparam = net(x)
- logger.debug(f'pdparam: {pdparam}')
+ pdparam = net(x)
return pdparam
@lab_api
def act(self, state):
body = self.body
- if self.normalize_state:
- state = policy_util.update_online_stats_and_normalize_state(body, state)
- action, action_pd = self.action_policy(state, self, body)
- body.action_tensor, body.action_pd = action, action_pd # used for body.action_pd_update later
- if len(action.shape) == 0: # scalar
- return action.cpu().numpy().astype(body.action_space.dtype).item()
- else:
- return action.cpu().numpy()
+ action = self.action_policy(state, self, body)
+ return action.cpu().squeeze().numpy() # squeeze to handle scalar
@lab_api
def sample(self):
'''Samples a batch from memory'''
batch = self.body.memory.sample()
- if self.normalize_state:
- batch = policy_util.normalize_states_and_next_states(self.body, batch)
batch = util.to_torch_batch(batch, self.net.device, self.body.memory.is_episodic)
return batch
+ def calc_pdparam_batch(self, batch):
+ '''Efficiently forward to get pdparam and by batch for loss computation'''
+ states = batch['states']
+ if self.body.env.is_venv:
+ states = math_util.venv_unpack(states)
+ pdparam = self.calc_pdparam(states)
+ return pdparam
+
+ def calc_ret_advs(self, batch):
+ '''Calculate plain returns; which is generalized to advantage in ActorCritic'''
+ rets = math_util.calc_returns(batch['rewards'], batch['dones'], self.gamma)
+ advs = rets
+ if self.body.env.is_venv:
+ advs = math_util.venv_unpack(advs)
+ logger.debug(f'advs: {advs}')
+ return advs
+
+ def calc_policy_loss(self, batch, pdparams, advs):
+ '''Calculate the actor's policy loss'''
+ action_pd = policy_util.init_action_pd(self.body.ActionPD, pdparams)
+ actions = batch['actions']
+ if self.body.env.is_venv:
+ actions = math_util.venv_unpack(actions)
+ log_probs = action_pd.log_prob(actions)
+ policy_loss = - self.policy_loss_coef * (log_probs * advs).mean()
+ if self.entropy_coef_spec:
+ entropy = action_pd.entropy().mean()
+ self.body.mean_entropy = entropy # update logging variable
+ policy_loss += (-self.body.entropy_coef * entropy)
+ logger.debug(f'Actor policy loss: {policy_loss:g}')
+ return policy_loss
+
@lab_api
def train(self):
if util.in_eval_lab_modes():
- self.body.flush()
return np.nan
clock = self.body.env.clock
if self.to_train == 1:
batch = self.sample()
- loss = self.calc_policy_loss(batch)
- self.net.training_step(loss=loss, lr_clock=clock)
+ clock.set_batch_size(len(batch))
+ pdparams = self.calc_pdparam_batch(batch)
+ advs = self.calc_ret_advs(batch)
+ loss = self.calc_policy_loss(batch, pdparams, advs)
+ self.net.train_step(loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
# reset
self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
return loss.item()
else:
return np.nan
- def calc_policy_loss(self, batch):
- '''Calculate the policy loss for a batch of data.'''
- # use simple returns as advs
- advs = math_util.calc_returns(batch['rewards'], batch['dones'], self.gamma)
- advs = math_util.standardize(advs)
- logger.debug(f'advs: {advs}')
- assert len(self.body.log_probs) == len(advs), f'batch_size of log_probs {len(self.body.log_probs)} vs advs: {len(advs)}'
- log_probs = torch.stack(self.body.log_probs)
- policy_loss = - log_probs * advs
- if self.entropy_coef_spec is not None:
- entropies = torch.stack(self.body.entropies)
- policy_loss += (-self.body.entropy_coef * entropies)
- policy_loss = torch.sum(policy_loss)
- logger.debug(f'Actor policy loss: {policy_loss:g}')
- return policy_loss
-
@lab_api
def update(self):
self.body.explore_var = self.explore_var_scheduler.update(self, self.body.env.clock)
diff --git a/slm_lab/agent/algorithm/sarsa.py b/slm_lab/agent/algorithm/sarsa.py
index 5a7ad8cc7..16c90c4bd 100644
--- a/slm_lab/agent/algorithm/sarsa.py
+++ b/slm_lab/agent/algorithm/sarsa.py
@@ -2,7 +2,7 @@
from slm_lab.agent.algorithm import policy_util
from slm_lab.agent.algorithm.base import Algorithm
from slm_lab.agent.net import net_util
-from slm_lab.lib import logger, util
+from slm_lab.lib import logger, math_util, util
from slm_lab.lib.decorator import lab_api
import numpy as np
import pydash as ps
@@ -39,7 +39,6 @@ class SARSA(Algorithm):
},
"gamma": 0.99,
"training_frequency": 10,
- "normalize_state": true
}
'''
@@ -60,7 +59,6 @@ def init_algorithm_params(self):
'explore_var_spec',
'gamma', # the discount factor
'training_frequency', # how often to train for batch training (once each training_frequency time steps)
- 'normalize_state',
])
self.to_train = 0
self.action_policy = getattr(policy_util, self.action_policy)
@@ -72,54 +70,33 @@ def init_nets(self, global_nets=None):
'''Initialize the neural network used to learn the Q function from the spec'''
if 'Recurrent' in self.net_spec['type']:
self.net_spec.update(seq_len=self.net_spec['seq_len'])
- if global_nets is None:
- in_dim = self.body.state_dim
- out_dim = net_util.get_out_dim(self.body)
- NetClass = getattr(net, self.net_spec['type'])
- self.net = NetClass(self.net_spec, in_dim, out_dim)
- self.net_names = ['net']
- else:
- util.set_attr(self, global_nets)
- self.net_names = list(global_nets.keys())
+ in_dim = self.body.state_dim
+ out_dim = net_util.get_out_dim(self.body)
+ NetClass = getattr(net, self.net_spec['type'])
+ self.net = NetClass(self.net_spec, in_dim, out_dim)
+ self.net_names = ['net']
+ # init net optimizer and its lr scheduler
+ self.optim = net_util.get_optim(self.net, self.net.optim_spec)
+ self.lr_scheduler = net_util.get_lr_scheduler(self.optim, self.net.lr_scheduler_spec)
+ net_util.set_global_nets(self, global_nets)
self.post_init_nets()
@lab_api
- def calc_pdparam(self, x, evaluate=True, net=None):
+ def calc_pdparam(self, x, net=None):
'''
To get the pdparam for action policy sampling, do a forward pass of the appropriate net, and pick the correct outputs.
The pdparam will be the logits for discrete prob. dist., or the mean and std for continuous prob. dist.
'''
net = self.net if net is None else net
- if evaluate:
- pdparam = net.wrap_eval(x)
- else:
- net.train()
- pdparam = net(x)
- logger.debug(f'pdparam: {pdparam}')
+ pdparam = net(x)
return pdparam
@lab_api
def act(self, state):
'''Note, SARSA is discrete-only'''
body = self.body
- if self.normalize_state:
- state = policy_util.update_online_stats_and_normalize_state(body, state)
- action, action_pd = self.action_policy(state, self, body)
- body.action_tensor, body.action_pd = action, action_pd # used for body.action_pd_update later
- if len(action.shape) == 0: # scalar
- return action.cpu().numpy().astype(body.action_space.dtype).item()
- else:
- return action.cpu().numpy()
-
- def calc_q_loss(self, batch):
- '''Compute the Q value loss using predicted and target Q values from the appropriate networks'''
- q_preds = self.net.wrap_eval(batch['states'])
- act_q_preds = q_preds.gather(-1, batch['actions'].long().unsqueeze(-1)).squeeze(-1)
- next_q_preds = self.net.wrap_eval(batch['next_states'])
- act_next_q_preds = q_preds.gather(-1, batch['next_actions'].long().unsqueeze(-1)).squeeze(-1)
- act_q_targets = batch['rewards'] + self.gamma * (1 - batch['dones']) * act_next_q_preds
- q_loss = self.net.loss_fn(act_q_preds, act_q_targets)
- return q_loss
+ action = self.action_policy(state, self, body)
+ return action.cpu().squeeze().numpy() # squeeze to handle scalar
@lab_api
def sample(self):
@@ -128,11 +105,29 @@ def sample(self):
# this is safe for next_action at done since the calculated act_next_q_preds will be multiplied by (1 - batch['dones'])
batch['next_actions'] = np.zeros_like(batch['actions'])
batch['next_actions'][:-1] = batch['actions'][1:]
- if self.normalize_state:
- batch = policy_util.normalize_states_and_next_states(self.body, batch)
batch = util.to_torch_batch(batch, self.net.device, self.body.memory.is_episodic)
return batch
+ def calc_q_loss(self, batch):
+ '''Compute the Q value loss using predicted and target Q values from the appropriate networks'''
+ states = batch['states']
+ next_states = batch['next_states']
+ if self.body.env.is_venv:
+ states = math_util.venv_unpack(states)
+ next_states = math_util.venv_unpack(next_states)
+ q_preds = self.net(states)
+ with torch.no_grad():
+ next_q_preds = self.net(next_states)
+ if self.body.env.is_venv:
+ q_preds = math_util.venv_pack(q_preds, self.body.env.num_envs)
+ next_q_preds = math_util.venv_pack(next_q_preds, self.body.env.num_envs)
+ act_q_preds = q_preds.gather(-1, batch['actions'].long().unsqueeze(-1)).squeeze(-1)
+ act_next_q_preds = next_q_preds.gather(-1, batch['next_actions'].long().unsqueeze(-1)).squeeze(-1)
+ act_q_targets = batch['rewards'] + self.gamma * (1 - batch['dones']) * act_next_q_preds
+ logger.debug(f'act_q_preds: {act_q_preds}\nact_q_targets: {act_q_targets}')
+ q_loss = self.net.loss_fn(act_q_preds, act_q_targets)
+ return q_loss
+
@lab_api
def train(self):
'''
@@ -140,17 +135,16 @@ def train(self):
Otherwise this function does nothing.
'''
if util.in_eval_lab_modes():
- self.body.flush()
return np.nan
clock = self.body.env.clock
if self.to_train == 1:
batch = self.sample()
+ clock.set_batch_size(len(batch))
loss = self.calc_q_loss(batch)
- self.net.training_step(loss=loss, lr_clock=clock)
+ self.net.train_step(loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
# reset
self.to_train = 0
- self.body.flush()
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
return loss.item()
else:
return np.nan
diff --git a/slm_lab/agent/algorithm/sil.py b/slm_lab/agent/algorithm/sil.py
index e1e3d1c79..2c66c2c68 100644
--- a/slm_lab/agent/algorithm/sil.py
+++ b/slm_lab/agent/algorithm/sil.py
@@ -36,16 +36,15 @@ class SIL(ActorCritic):
"val_loss_coef": 0.01,
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.01,
- "training_batch_epoch": 8,
+ "training_batch_iter": 8,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_iter": 8,
}
e.g. special memory_spec
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -53,7 +52,7 @@ class SIL(ActorCritic):
'''
def __init__(self, agent, global_nets=None):
- super(SIL, self).__init__(agent, global_nets)
+ super().__init__(agent, global_nets)
# create the extra replay memory for SIL
MemoryClass = getattr(memory, self.memory_spec['sil_replay_name'])
self.body.replay_memory = MemoryClass(self.memory_spec, self.body)
@@ -84,98 +83,68 @@ def init_algorithm_params(self):
'sil_policy_loss_coef',
'sil_val_loss_coef',
'training_frequency',
- 'training_batch_epoch',
- 'training_epoch',
- 'normalize_state'
+ 'training_batch_iter',
+ 'training_iter',
])
- super(SIL, self).init_algorithm_params()
+ super().init_algorithm_params()
def sample(self):
'''Modify the onpolicy sample to also append to replay'''
batch = self.body.memory.sample()
batch = {k: np.concatenate(v) for k, v in batch.items()} # concat episodic memory
- batch['rets'] = math_util.calc_returns(batch['rewards'], batch['dones'], self.gamma)
for idx in range(len(batch['dones'])):
tuples = [batch[k][idx] for k in self.body.replay_memory.data_keys]
self.body.replay_memory.add_experience(*tuples)
- if self.normalize_state:
- batch = policy_util.normalize_states_and_next_states(self.body, batch)
batch = util.to_torch_batch(batch, self.net.device, self.body.replay_memory.is_episodic)
return batch
def replay_sample(self):
'''Samples a batch from memory'''
batch = self.body.replay_memory.sample()
- if self.normalize_state:
- batch = policy_util.normalize_states_and_next_states(
- self.body, batch, episodic_flag=self.body.replay_memory.is_episodic)
batch = util.to_torch_batch(batch, self.net.device, self.body.replay_memory.is_episodic)
- assert not torch.isnan(batch['states']).any(), batch['states']
return batch
- def calc_sil_policy_val_loss(self, batch):
+ def calc_sil_policy_val_loss(self, batch, pdparams):
'''
Calculate the SIL policy losses for actor and critic
sil_policy_loss = -log_prob * max(R - v_pred, 0)
sil_val_loss = (max(R - v_pred, 0)^2) / 2
This is called on a randomly-sample batch from experience replay
'''
- returns = batch['rets']
- v_preds = self.calc_v(batch['states'], evaluate=False)
- clipped_advs = torch.clamp(returns - v_preds, min=0.0)
- log_probs = policy_util.calc_log_probs(self, self.net, self.body, batch)
-
- sil_policy_loss = self.sil_policy_loss_coef * torch.mean(- log_probs * clipped_advs)
- sil_val_loss = self.sil_val_loss_coef * torch.pow(clipped_advs, 2) / 2
- sil_val_loss = torch.mean(sil_val_loss)
+ v_preds = self.calc_v(batch['states'], use_cache=False)
+ rets = math_util.calc_returns(batch['rewards'], batch['dones'], self.gamma)
+ clipped_advs = torch.clamp(rets - v_preds, min=0.0)
+
+ action_pd = policy_util.init_action_pd(self.body.ActionPD, pdparams)
+ actions = batch['actions']
+ if self.body.env.is_venv:
+ actions = math_util.venv_unpack(actions)
+ log_probs = action_pd.log_prob(actions)
+
+ sil_policy_loss = - self.sil_policy_loss_coef * (log_probs * clipped_advs).mean()
+ sil_val_loss = self.sil_val_loss_coef * clipped_advs.pow(2).mean() / 2
logger.debug(f'SIL actor policy loss: {sil_policy_loss:g}')
logger.debug(f'SIL critic value loss: {sil_val_loss:g}')
return sil_policy_loss, sil_val_loss
- def train_shared(self):
- '''
- Trains the network when the actor and critic share parameters
- '''
+ def train(self):
clock = self.body.env.clock
if self.to_train == 1:
# onpolicy update
- super_loss = super(SIL, self).train_shared()
+ super_loss = super().train()
# offpolicy sil update with random minibatch
- total_sil_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
+ total_sil_loss = torch.tensor(0.0)
+ for _ in range(self.training_iter):
batch = self.replay_sample()
- for _ in range(self.training_batch_epoch):
- sil_policy_loss, sil_val_loss = self.calc_sil_policy_val_loss(batch)
+ for _ in range(self.training_batch_iter):
+ pdparams, _v_preds = self.calc_pdparam_v(batch)
+ sil_policy_loss, sil_val_loss = self.calc_sil_policy_val_loss(batch, pdparams)
sil_loss = sil_policy_loss + sil_val_loss
- self.net.training_step(loss=sil_loss, lr_clock=clock)
+ self.net.train_step(sil_loss, self.optim, self.lr_scheduler, clock=clock, global_net=self.global_net)
total_sil_loss += sil_loss
- sil_loss = total_sil_loss / self.training_epoch
- loss = super_loss + sil_loss
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
- return loss.item()
- else:
- return np.nan
-
- def train_separate(self):
- '''
- Trains the network when the actor and critic are separate networks
- '''
- clock = self.body.env.clock
- if self.to_train == 1:
- # onpolicy update
- super_loss = super(SIL, self).train_separate()
- # offpolicy sil update with random minibatch
- total_sil_loss = torch.tensor(0.0, device=self.net.device)
- for _ in range(self.training_epoch):
- batch = self.replay_sample()
- for _ in range(self.training_batch_epoch):
- sil_policy_loss, sil_val_loss = self.calc_sil_policy_val_loss(batch)
- self.net.training_step(loss=sil_policy_loss, lr_clock=clock, retain_graph=True)
- self.critic.training_step(loss=sil_val_loss, lr_clock=clock)
- total_sil_loss += sil_policy_loss + sil_val_loss
- sil_loss = total_sil_loss / self.training_epoch
+ sil_loss = total_sil_loss / self.training_iter
loss = super_loss + sil_loss
- logger.debug(f'Trained {self.name} at epi: {clock.epi}, total_t: {clock.total_t}, t: {clock.t}, total_reward so far: {self.body.memory.total_reward}, loss: {loss:g}')
+ logger.debug(f'Trained {self.name} at epi: {clock.epi}, frame: {clock.frame}, t: {clock.t}, total_reward so far: {self.body.total_reward}, loss: {loss:g}')
return loss.item()
else:
return np.nan
@@ -210,15 +179,15 @@ class PPOSIL(SIL, PPO):
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.01,
"training_frequency": 1,
- "training_batch_epoch": 8,
+ "training_batch_iter": 8,
+ "training_iter": 8,
"training_epoch": 8,
- "normalize_state": true
}
e.g. special memory_spec
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
diff --git a/slm_lab/agent/memory/__init__.py b/slm_lab/agent/memory/__init__.py
index 394eaa320..5745a0a65 100644
--- a/slm_lab/agent/memory/__init__.py
+++ b/slm_lab/agent/memory/__init__.py
@@ -1,9 +1,5 @@
-'''
-The memory module
-Contains different ways of storing an agents experiences and sampling from them
-'''
-
-# expose all the classes
+# The memory module
+# Implements various methods for memory storage
from .replay import *
from .onpolicy import *
from .prioritized import *
diff --git a/slm_lab/agent/memory/base.py b/slm_lab/agent/memory/base.py
index c3d8a5ee5..fa2252c8c 100644
--- a/slm_lab/agent/memory/base.py
+++ b/slm_lab/agent/memory/base.py
@@ -8,12 +8,7 @@
class Memory(ABC):
- '''
- Abstract class ancestor to all Memories,
- specifies the necessary design blueprint for agent body to work in Lab.
- Mostly, implement just the abstract methods and properties.
- Memory is singleton to each body for modularity, and there is no gains to do multi-body memory now. Shall be constructed when body_space is built.
- '''
+ '''Abstract Memory class to define the API methods'''
def __init__(self, memory_spec, body):
'''
@@ -21,65 +16,20 @@ def __init__(self, memory_spec, body):
'''
self.memory_spec = memory_spec
self.body = body
-
# declare what data keys to store
self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones', 'priorities']
- # the basic variables for every memory
- self.last_state = None
- # method to log size warning only once to prevent spamming log
- self.warn_size_once = ps.once(lambda msg: logger.warn(msg))
- # for API consistency, reset to some max_len in your specific memory class
- self.state_buffer = deque(maxlen=0)
- # total_reward and its history over episodes
- self.total_reward = 0
@abstractmethod
def reset(self):
'''Method to fully reset the memory storage and related variables'''
raise NotImplementedError
- def epi_reset(self, state):
- '''Method to reset at new episode'''
- self.last_state = state
- self.body.epi_reset()
- self.total_reward = 0
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.body.state_dim))
-
- def base_update(self, action, reward, state, done):
- '''Method to do base memory update, like stats'''
- from slm_lab.experiment import analysis
- if np.isnan(reward): # the start of episode
- self.epi_reset(state)
- return
-
- self.total_reward += reward
- return
-
@abstractmethod
- def update(self, action, reward, state, done):
- '''Implement memory update given the full info from the latest timestep. Hint: use self.last_state to construct SARS. NOTE: guard for np.nan reward and done when individual env resets.'''
- self.base_update(action, reward, state, done)
+ def update(self, state, action, reward, next_state, done):
+ '''Implement memory update given the full info from the latest timestep. NOTE: guard for np.nan reward and done when individual env resets.'''
raise NotImplementedError
@abstractmethod
def sample(self):
'''Implement memory sampling mechanism'''
raise NotImplementedError
-
- def preprocess_append(self, state, append=True):
- '''Method to conditionally append to state buffer'''
- if append:
- assert id(state) != id(self.state_buffer[-1]), 'Do not append to buffer other than during action'
- self.state_buffer.append(state)
-
- def preprocess_state(self, state, append=True):
- '''Transforms the raw state into format that is fed into the network'''
- return state
-
- def print_memory_info(self):
- '''Prints size of all of the memory arrays'''
- for k in self.data_keys:
- d = getattr(self, k)
- logger.info(f'Memory for body {self.body.aeb}: {k} :shape: {d.shape}, dtype: {d.dtype}, size: {util.sizeof(d)}MB')
diff --git a/slm_lab/agent/memory/onpolicy.py b/slm_lab/agent/memory/onpolicy.py
index a958bf3f9..11ce5dfc1 100644
--- a/slm_lab/agent/memory/onpolicy.py
+++ b/slm_lab/agent/memory/onpolicy.py
@@ -36,14 +36,13 @@ class OnPolicyReplay(Memory):
'''
def __init__(self, memory_spec, body):
- super(OnPolicyReplay, self).__init__(memory_spec, body)
+ super().__init__(memory_spec, body)
# NOTE for OnPolicy replay, frequency = episode; for other classes below frequency = frames
util.set_attr(self, self.body.agent.agent_spec['algorithm'], ['training_frequency'])
- self.state_buffer = deque(maxlen=0) # for API consistency
# Don't want total experiences reset when memory is
self.is_episodic = True
- self.true_size = 0 # to number of experiences stored
- self.seen_size = 0 # the number of experiences seen, including those stored and discarded
+ self.size = 0 # total experiences stored
+ self.seen_size = 0 # total experiences seen cumulatively
# declare what data keys to store
self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones']
self.reset()
@@ -54,27 +53,21 @@ def reset(self):
for k in self.data_keys:
setattr(self, k, [])
self.cur_epi_data = {k: [] for k in self.data_keys}
- self.most_recent = [None] * len(self.data_keys)
- self.true_size = 0 # Size of the current memory
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.body.state_dim))
+ self.most_recent = (None,) * len(self.data_keys)
+ self.size = 0
@lab_api
- def update(self, action, reward, state, done):
+ def update(self, state, action, reward, next_state, done):
'''Interface method to update memory'''
- self.base_update(action, reward, state, done)
- if not np.isnan(reward): # not the start of episode
- self.add_experience(self.last_state, action, reward, state, done)
- self.last_state = state
+ self.add_experience(state, action, reward, next_state, done)
def add_experience(self, state, action, reward, next_state, done):
'''Interface helper method for update() to add experience to memory'''
- self.most_recent = [state, action, reward, next_state, done]
+ self.most_recent = (state, action, reward, next_state, done)
for idx, k in enumerate(self.data_keys):
self.cur_epi_data[k].append(self.most_recent[idx])
# If episode ended, add to memory and clear cur_epi_data
- if done:
+ if util.epi_done(done):
for k in self.data_keys:
getattr(self, k).append(self.cur_epi_data[k])
self.cur_epi_data = {k: [] for k in self.data_keys}
@@ -83,9 +76,7 @@ def add_experience(self, state, action, reward, next_state, done):
if len(self.states) == self.body.agent.algorithm.training_frequency:
self.body.agent.algorithm.to_train = 1
# Track memory size and num experiences
- self.true_size += 1
- if self.true_size > 1000:
- self.warn_size_once('Large memory size: {}'.format(self.true_size))
+ self.size += 1
self.seen_size += 1
def get_most_recent_experience(self):
@@ -109,78 +100,6 @@ def sample(self):
return batch
-class OnPolicySeqReplay(OnPolicyReplay):
- '''
- Same as OnPolicyReplay Memory but returns the last `seq_len` states and next_states for input to a recurrent network.
- Experiences with less than `seq_len` previous examples are padded with a 0 valued state and action vector.
-
- e.g. memory_spec
- "memory": {
- "name": "OnPolicySeqReplay"
- }
- * seq_len provided by net_spec
- '''
-
- def __init__(self, memory_spec, body):
- super(OnPolicySeqReplay, self).__init__(memory_spec, body)
- self.seq_len = self.body.agent.agent_spec['net']['seq_len']
- self.state_buffer = deque(maxlen=self.seq_len)
- self.reset()
-
- def preprocess_state(self, state, append=True):
- '''
- Transforms the raw state into format that is fed into the network
- NOTE for onpolicy memory this method only gets called in policy util, not here.
- '''
- self.preprocess_append(state, append)
- return np.stack(self.state_buffer)
-
- def sample(self):
- '''
- Returns all the examples from memory in a single batch. Batch is stored as a dict.
- Keys are the names of the different elements of an experience. Values are nested lists of the corresponding sampled elements. Elements are nested into episodes
- states and next_states have are further nested into sequences containing the previous `seq_len` - 1 relevant states
- e.g.
- let s_seq_0 be [0, ..., s0] (zero-padded), s_seq_k be [s_{k-seq_len}, ..., s_k], so the states are nested for passing into RNN.
- batch = {
- 'states' : [
- [s_seq_0, s_seq_1, ..., s_seq_k]_epi_1,
- [s_seq_0, s_seq_1, ..., s_seq_k]_epi_2,
- ...]
- 'actions' : [[a_epi1], [a_epi2], ...],
- 'rewards' : [[r_epi1], [r_epi2], ...],
- 'next_states: [
- [ns_seq_0, ns_seq_1, ..., ns_seq_k]_epi_1,
- [ns_seq_0, ns_seq_1, ..., ns_seq_k]_epi_2,
- ...]
- 'dones' : [[d_epi1], [d_epi2], ...]}
- '''
- batch = {}
- batch['states'] = self.build_seqs(self.states)
- batch['actions'] = self.actions
- batch['rewards'] = self.rewards
- batch['next_states'] = self.build_seqs(self.next_states)
- batch['dones'] = self.dones
- self.reset()
- return batch
-
- def build_seqs(self, data):
- '''Construct the epi-nested-seq data for sampling'''
- all_epi_data_seq = []
- for epi_data in data:
- data_seq = []
- # make [0, ..., *epi_data]
- padded_epi_data = deepcopy(epi_data)
- padding = np.zeros_like(epi_data[0])
- for i in range(self.seq_len - 1):
- padded_epi_data.insert(0, padding)
- # slide seqs and build for one epi
- for i in range(len(epi_data)):
- data_seq.append(padded_epi_data[i:i + self.seq_len])
- all_epi_data_seq.append(data_seq)
- return all_epi_data_seq
-
-
class OnPolicyBatchReplay(OnPolicyReplay):
'''
Same as OnPolicyReplay Memory with the following difference.
@@ -197,7 +116,7 @@ class OnPolicyBatchReplay(OnPolicyReplay):
'''
def __init__(self, memory_spec, body):
- super(OnPolicyBatchReplay, self).__init__(memory_spec, body)
+ super().__init__(memory_spec, body)
self.is_episodic = False
def add_experience(self, state, action, reward, next_state, done):
@@ -206,9 +125,7 @@ def add_experience(self, state, action, reward, next_state, done):
for idx, k in enumerate(self.data_keys):
getattr(self, k).append(self.most_recent[idx])
# Track memory size and num experiences
- self.true_size += 1
- if self.true_size > 1000:
- self.warn_size_once('Large memory size: {}'.format(self.true_size))
+ self.size += 1
self.seen_size += 1
# Decide if agent is to train
if len(self.states) == self.body.agent.algorithm.training_frequency:
@@ -226,149 +143,4 @@ def sample(self):
'next_states': next_states,
'dones' : dones}
'''
- return super(OnPolicyBatchReplay, self).sample()
-
-
-class OnPolicySeqBatchReplay(OnPolicyBatchReplay):
- '''
- Same as OnPolicyBatchReplay Memory but returns the last `seq_len` states and next_states for input to a recurrent network.
- Experiences with less than `seq_len` previous examples are padded with a 0 valued state and action vector.
-
- e.g. memory_spec
- "memory": {
- "name": "OnPolicySeqBatchReplay"
- }
- * seq_len provided by net_spec
- * batch_size is training_frequency provided by algorithm_spec
- '''
-
- def __init__(self, memory_spec, body):
- super(OnPolicySeqBatchReplay, self).__init__(memory_spec, body)
- self.is_episodic = False
- self.seq_len = self.body.agent.agent_spec['net']['seq_len']
- self.state_buffer = deque(maxlen=self.seq_len)
- self.reset()
-
- def preprocess_state(self, state, append=True):
- # delegate to OnPolicySeqReplay sequential method
- return OnPolicySeqReplay.preprocess_state(self, state, append)
-
- def sample(self):
- '''
- Batched version of OnPolicySeqBatchReplay.sample()
- e.g.
- let s_seq_0 be [0, ..., s0] (zero-padded), s_seq_k be [s_{k-seq_len}, ..., s_k], so the states are nested for passing into RNN.
- batch = {
- 'states' : [[s_seq_0, s_seq_1, ..., s_seq_k]],
- 'actions' : actions,
- 'rewards' : rewards,
- 'next_states': [[ns_seq_0, ns_seq_1, ..., ns_seq_k]],
- 'dones' : dones}
- '''
- # delegate method
- return OnPolicySeqReplay.sample(self)
-
- def build_seqs(self, data):
- '''Construct the seq data for sampling'''
- data_seq = []
- # make [0, ..., *data]
- padded_data = deepcopy(data)
- padding = np.zeros_like(data[0])
- for i in range(self.seq_len - 1):
- padded_data.insert(0, padding)
- # slide seqs and build for one epi
- for i in range(len(data)):
- data_seq.append(padded_data[i:i + self.seq_len])
- return data_seq
-
-
-class OnPolicyConcatReplay(OnPolicyReplay):
- '''
- Preprocesses a state to be the concatenation of the last n states. Otherwise the same as Replay memory
-
- e.g. memory_spec
- "memory": {
- "name": "OnPolicyConcatReplay",
- "concat_len": 4
- }
- '''
-
- def __init__(self, memory_spec, body):
- util.set_attr(self, memory_spec, [
- 'concat_len', # number of stack states
- ])
- self.raw_state_dim = deepcopy(body.state_dim) # used for state_buffer
- body.state_dim = body.state_dim * self.concat_len # modify to use for net init for concat input
- super(OnPolicyConcatReplay, self).__init__(memory_spec, body)
- self.state_buffer = deque(maxlen=self.concat_len)
- self.reset()
-
- def reset(self):
- '''Initializes the memory arrays, size and head pointer'''
- super(OnPolicyConcatReplay, self).reset()
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.raw_state_dim))
-
- def epi_reset(self, state):
- '''Method to reset at new episode'''
- state = self.preprocess_state(state, append=False) # prevent conflict with preprocess in epi_reset
- super(OnPolicyConcatReplay, self).epi_reset(state)
- # reappend buffer with custom shape
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.raw_state_dim))
-
- def preprocess_state(self, state, append=True):
- '''Transforms the raw state into format that is fed into the network'''
- # append when state is first seen when acting in policy_util, don't append elsewhere in memory
- self.preprocess_append(state, append)
- return np.concatenate(self.state_buffer)
-
- @lab_api
- def update(self, action, reward, state, done):
- '''Interface method to update memory'''
- self.base_update(action, reward, state, done)
- state = self.preprocess_state(state, append=False) # prevent conflict with preprocess in epi_reset
- if not np.isnan(reward): # not the start of episode
- self.add_experience(self.last_state, action, reward, state, done)
- self.last_state = state
-
-
-class OnPolicyAtariReplay(OnPolicyReplay):
- '''
- Preprocesses an state to be the concatenation of the last four states, after converting the 210 x 160 x 3 image to 84 x 84 x 1 grayscale image, and clips all rewards to [-10, 10] as per "Playing Atari with Deep Reinforcement Learning", Mnih et al, 2013
- Note: Playing Atari with Deep RL clips the rewards to + / - 1
- Otherwise the same as OnPolicyReplay memory
- '''
-
- def __init__(self, memory_spec, body):
- util.set_attr(self, memory_spec, [
- 'stack_len', # number of stack states
- ])
- OnPolicyReplay.__init__(self, memory_spec, body)
-
- def add_experience(self, state, action, reward, next_state, done):
- # clip reward, done here to minimize change to only training data data
- super(OnPolicyAtariReplay, self).add_experience(state, action, np.sign(reward), next_state, done)
-
-
-class OnPolicyAtariBatchReplay(OnPolicyBatchReplay, OnPolicyAtariReplay):
- '''
- OnPolicyBatchReplay with Atari concat
- '''
- pass
-
-
-class OnPolicyImageReplay(OnPolicyReplay):
- '''
- An on policy replay buffer that normalizes (preprocesses) images through
- division by 255 and subtraction of 0.5.
- '''
-
- def __init__(self, memory_spec, body):
- super(OnPolicyImageReplay, self).__init__(memory_spec, body)
-
- def preprocess_state(self, state, append=True):
- state = util.normalize_image(state) - 0.5
- return state
+ return super().sample()
diff --git a/slm_lab/agent/memory/prioritized.py b/slm_lab/agent/memory/prioritized.py
index 55f09fb04..8b65936f7 100644
--- a/slm_lab/agent/memory/prioritized.py
+++ b/slm_lab/agent/memory/prioritized.py
@@ -1,9 +1,8 @@
-from slm_lab.agent.memory.replay import Replay, AtariReplay
+from slm_lab.agent.memory.replay import Replay
from slm_lab.lib import util
from slm_lab.lib.decorator import lab_api
import numpy as np
import random
-import torch
class SumTree:
@@ -113,16 +112,16 @@ def __init__(self, memory_spec, body):
'max_size',
'use_cer',
])
- super(PrioritizedReplay, self).__init__(memory_spec, body)
+ super().__init__(memory_spec, body)
- self.epsilon = torch.full((1,), self.epsilon)
- self.alpha = torch.full((1,), self.alpha)
+ self.epsilon = np.full((1,), self.epsilon)
+ self.alpha = np.full((1,), self.alpha)
# adds a 'priorities' scalar to the data_keys and call reset again
self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones', 'priorities']
self.reset()
def reset(self):
- super(PrioritizedReplay, self).reset()
+ super().reset()
self.tree = SumTree(self.max_size)
def add_experience(self, state, action, reward, next_state, done, error=100000):
@@ -130,16 +129,14 @@ def add_experience(self, state, action, reward, next_state, done, error=100000):
Implementation for update() to add experience to memory, expanding the memory size if necessary.
All experiences are added with a high priority to increase the likelihood that they are sampled at least once.
'''
- super(PrioritizedReplay, self).add_experience(state, action, reward, next_state, done)
- error = torch.zeros(1).fill_(error)
+ super().add_experience(state, action, reward, next_state, done)
priority = self.get_priority(error)
self.priorities[self.head] = priority
self.tree.add(priority, self.head)
def get_priority(self, error):
'''Takes in the error of one or more examples and returns the proportional priority'''
- p = torch.pow(error.cpu().detach() + self.epsilon, self.alpha)
- return p.squeeze().detach().numpy()
+ return np.power(error + self.epsilon, self.alpha).squeeze()
def sample_idxs(self, batch_size):
'''Samples batch_size indices from memory in proportional to their priority.'''
@@ -158,43 +155,14 @@ def sample_idxs(self, batch_size):
batch_idxs[-1] = self.head
return batch_idxs
- def get_body_errors(self, errors):
- '''Get the slice of errors belonging to a body in network output'''
- body_idx = self.body.nanflat_a_idx
- start_idx = body_idx * self.batch_size
- end_idx = start_idx + self.batch_size
- body_errors = errors[start_idx:end_idx]
- return body_errors
-
def update_priorities(self, errors):
'''
Updates the priorities from the most recent batch
Assumes the relevant batch indices are stored in self.batch_idxs
'''
- body_errors = self.get_body_errors(errors)
- priorities = self.get_priority(body_errors)
+ priorities = self.get_priority(errors)
assert len(priorities) == self.batch_idxs.size
- self.priorities[self.batch_idxs] = priorities
+ for idx, p in zip(self.batch_idxs, priorities):
+ self.priorities[idx] = p
for p, i in zip(priorities, self.tree_idxs):
self.tree.update(i, p)
-
-
-class AtariPrioritizedReplay(PrioritizedReplay, AtariReplay):
- '''Make a Prioritized AtariReplay via nice multi-inheritance (python magic)'''
-
- def __init__(self, memory_spec, body):
- util.set_attr(self, memory_spec, [
- 'alpha',
- 'epsilon',
- 'batch_size',
- 'max_size',
- 'use_cer',
- ])
- AtariReplay.__init__(self, memory_spec, body)
- self.epsilon = torch.full((1,), self.epsilon)
- self.alpha = torch.full((1,), self.alpha)
- # adds a 'priorities' scalar to the data_keys and call reset again
- self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones', 'priorities']
- self.reset()
- self.states_shape = self.scalar_shape
- self.states = [None] * self.max_size
diff --git a/slm_lab/agent/memory/replay.py b/slm_lab/agent/memory/replay.py
index fa72712b2..18ed346e6 100644
--- a/slm_lab/agent/memory/replay.py
+++ b/slm_lab/agent/memory/replay.py
@@ -9,6 +9,35 @@
logger = logger.get_logger(__name__)
+def sample_next_states(head, max_size, ns_idx_offset, batch_idxs, states, ns_buffer):
+ '''Method to sample next_states from states, with proper guard for next_state idx being out of bound'''
+ # idxs for next state is state idxs with offset, modded
+ ns_batch_idxs = (batch_idxs + ns_idx_offset) % max_size
+ # if head < ns_idx <= head + ns_idx_offset, ns is stored in ns_buffer
+ ns_batch_idxs = ns_batch_idxs % max_size
+ buffer_ns_locs = np.argwhere(
+ (head < ns_batch_idxs) & (ns_batch_idxs <= head + ns_idx_offset)).flatten()
+ # find if there is any idxs to get from buffer
+ to_replace = buffer_ns_locs.size != 0
+ if to_replace:
+ # extract the buffer_idxs first for replacement later
+ # given head < ns_idx <= head + offset, and valid buffer idx is [0, offset)
+ # get 0 < ns_idx - head <= offset, or equiv.
+ # get -1 < ns_idx - head - 1 <= offset - 1, i.e.
+ # get 0 <= ns_idx - head - 1 < offset, hence:
+ buffer_idxs = ns_batch_idxs[buffer_ns_locs] - head - 1
+ # set them to 0 first to allow sampling, then replace later with buffer
+ ns_batch_idxs[buffer_ns_locs] = 0
+ # guard all against overrun idxs from offset
+ ns_batch_idxs = ns_batch_idxs % max_size
+ next_states = util.batch_get(states, ns_batch_idxs)
+ if to_replace:
+ # now replace using buffer_idxs and ns_buffer
+ buffer_ns = util.batch_get(ns_buffer, buffer_idxs)
+ next_states[buffer_ns_locs] = buffer_ns
+ return next_states
+
+
class Replay(Memory):
'''
Stores agent experiences and samples from them for agent training
@@ -39,70 +68,60 @@ class Replay(Memory):
'''
def __init__(self, memory_spec, body):
- super(Replay, self).__init__(memory_spec, body)
+ super().__init__(memory_spec, body)
util.set_attr(self, self.memory_spec, [
'batch_size',
'max_size',
'use_cer',
])
- self.state_buffer = deque(maxlen=0) # for API consistency
self.is_episodic = False
self.batch_idxs = None
- self.true_size = 0 # to number of experiences stored
- self.seen_size = 0 # the number of experiences seen, including those stored and discarded
+ self.size = 0 # total experiences stored
+ self.seen_size = 0 # total experiences seen cumulatively
self.head = -1 # index of most recent experience
+ # generic next_state buffer to store last next_states (allow for multiple for venv)
+ self.ns_idx_offset = self.body.env.num_envs if body.env.is_venv else 1
+ self.ns_buffer = deque(maxlen=self.ns_idx_offset)
# declare what data keys to store
self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones']
- self.scalar_shape = (self.max_size,)
- self.states_shape = self.scalar_shape + tuple(np.reshape(self.body.state_dim, -1))
- self.actions_shape = self.scalar_shape + self.body.action_space.shape
self.reset()
def reset(self):
'''Initializes the memory arrays, size and head pointer'''
- # set data keys as self.{data_keys}
+ # set self.states, self.actions, ...
for k in self.data_keys:
- if k == 'states':
- setattr(self, k, np.zeros(self.states_shape, dtype=np.float16))
- elif k == 'next_states':
- # don't store next_states, but create a place holder to track it for sampling
- self.latest_next_state = None
- elif k == 'actions':
- setattr(self, k, np.zeros(self.actions_shape, dtype=self.body.action_space.dtype))
- else:
- setattr(self, k, np.zeros(self.scalar_shape, dtype=np.float16))
- self.true_size = 0
+ if k != 'next_states': # reuse self.states
+ # list add/sample is over 10x faster than np, also simpler to handle
+ setattr(self, k, [None] * self.max_size)
+ self.size = 0
self.head = -1
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.body.state_dim))
-
- def epi_reset(self, state):
- '''Method to reset at new episode'''
- super(Replay, self).epi_reset(self.preprocess_state(state, append=False))
+ self.ns_buffer.clear()
@lab_api
- def update(self, action, reward, state, done):
+ def update(self, state, action, reward, next_state, done):
'''Interface method to update memory'''
- self.base_update(action, reward, state, done)
- state = self.preprocess_state(state, append=False) # prevent conflict with preprocess in epi_reset
- if not np.isnan(reward): # not the start of episode
- self.add_experience(self.last_state, action, reward, state, done)
- self.last_state = state
+ if self.body.env.is_venv:
+ for sarsd in zip(state, action, reward, next_state, done):
+ self.add_experience(*sarsd)
+ else:
+ self.add_experience(state, action, reward, next_state, done)
def add_experience(self, state, action, reward, next_state, done):
'''Implementation for update() to add experience to memory, expanding the memory size if necessary'''
# Move head pointer. Wrap around if necessary
self.head = (self.head + 1) % self.max_size
- self.states[self.head] = state
+ self.states[self.head] = state.astype(np.float16)
self.actions[self.head] = action
self.rewards[self.head] = reward
- self.latest_next_state = next_state
+ self.ns_buffer.append(next_state.astype(np.float16))
self.dones[self.head] = done
# Actually occupied size of memory
- if self.true_size < self.max_size:
- self.true_size += 1
+ if self.size < self.max_size:
+ self.size += 1
self.seen_size += 1
+ # set to_train using memory counters head, seen_size instead of tick since clock will step by num_envs when on venv; to_train will be set to 0 after training step
+ algorithm = self.body.agent.algorithm
+ algorithm.to_train = algorithm.to_train or (self.seen_size > algorithm.training_start_step and self.head % algorithm.training_frequency == 0)
@lab_api
def sample(self):
@@ -121,199 +140,14 @@ def sample(self):
batch = {}
for k in self.data_keys:
if k == 'next_states':
- batch[k] = self._sample_next_states(self.batch_idxs)
+ batch[k] = sample_next_states(self.head, self.max_size, self.ns_idx_offset, self.batch_idxs, self.states, self.ns_buffer)
else:
- batch[k] = util.cond_multiget(getattr(self, k), self.batch_idxs)
+ batch[k] = util.batch_get(getattr(self, k), self.batch_idxs)
return batch
- def _sample_next_states(self, batch_idxs):
- '''Method to sample next_states from states, with proper guard for last idx (out of bound)'''
- # idxs for next state is state idxs + 1
- ns_batch_idxs = batch_idxs + 1
- # find the locations to be replaced with latest_next_state
- latest_ns_locs = np.argwhere(ns_batch_idxs == self.true_size).flatten()
- to_replace = latest_ns_locs.size != 0
- # set to 0, a safe sentinel for ns_batch_idxs due to the +1 above
- # then sample safely from self.states, and replace at locs with latest_next_state
- if to_replace:
- ns_batch_idxs[latest_ns_locs] = 0
- next_states = util.cond_multiget(self.states, ns_batch_idxs)
- if to_replace:
- next_states[latest_ns_locs] = self.latest_next_state
- return next_states
-
def sample_idxs(self, batch_size):
'''Batch indices a sampled random uniformly'''
- batch_idxs = np.random.randint(self.true_size, size=batch_size)
+ batch_idxs = np.random.randint(self.size, size=batch_size)
if self.use_cer: # add the latest sample
batch_idxs[-1] = self.head
return batch_idxs
-
-
-class SeqReplay(Replay):
- '''
- Preprocesses a state to be the stacked sequence of the last n states. Otherwise the same as Replay memory
-
- e.g. memory_spec
- "memory": {
- "name": "SeqReplay",
- "batch_size": 32,
- "max_size": 10000,
- "use_cer": true
- }
- * seq_len provided by net_spec
- '''
-
- def __init__(self, memory_spec, body):
- super(SeqReplay, self).__init__(memory_spec, body)
- self.seq_len = self.body.agent.agent_spec['net']['seq_len']
- self.state_buffer = deque(maxlen=self.seq_len)
- # update states_shape and call reset again
- self.states_shape = self.scalar_shape + tuple(np.reshape([self.seq_len, self.body.state_dim], -1))
- self.reset()
-
- def preprocess_state(self, state, append=True):
- '''Transforms the raw state into format that is fed into the network'''
- # append when state is first seen when acting in policy_util, don't append elsewhere in memory
- self.preprocess_append(state, append)
- return np.stack(self.state_buffer)
-
-
-class SILReplay(Replay):
- '''
- Special Replay for SIL, which adds the returns calculated from its OnPolicyReplay
-
- e.g. memory_spec
- "memory": {
- "name": "SILReplay",
- "batch_size": 32,
- "max_size": 10000,
- "use_cer": true
- }
- '''
-
- def __init__(self, memory_spec, body):
- super(SILReplay, self).__init__(memory_spec, body)
- # adds a 'rets' scalar to the data_keys and call reset again
- self.data_keys = ['states', 'actions', 'rewards', 'next_states', 'dones', 'rets']
- self.reset()
-
- @lab_api
- def update(self, action, reward, state, done):
- '''Interface method to update memory'''
- raise AssertionError('Do not call SIL memory in main API control loop')
-
- def add_experience(self, state, action, reward, next_state, done, ret):
- '''Used to add memory from onpolicy memory'''
- super(SILReplay, self).add_experience(state, action, reward, next_state, done)
- self.rets[self.head] = ret
-
-
-class SILSeqReplay(SILReplay, SeqReplay):
- '''
- Preprocesses a state to be the stacked sequence of the last n states. Otherwise the same as SILReplay memory
-
- e.g. memory_spec
- "memory": {
- "name": "SILSeqReplay",
- "batch_size": 32,
- "max_size": 10000,
- "use_cer": true
- }
- * seq_len provided by net_spec
- '''
- pass
-
-
-class ConcatReplay(Replay):
- '''
- Preprocesses a state to be the concatenation of the last n states. Otherwise the same as Replay memory
-
- e.g. memory_spec
- "memory": {
- "name": "ConcatReplay",
- "batch_size": 32,
- "max_size": 10000,
- "concat_len": 4,
- "use_cer": true
- }
- '''
-
- def __init__(self, memory_spec, body):
- util.set_attr(self, memory_spec, [
- 'batch_size',
- 'max_size',
- 'concat_len', # number of stack states
- 'use_cer',
- ])
- self.raw_state_dim = deepcopy(body.state_dim) # used for state_buffer
- body.state_dim = body.state_dim * self.concat_len # modify to use for net init for concat input
- super(ConcatReplay, self).__init__(memory_spec, body)
- self.state_buffer = deque(maxlen=self.concat_len)
- self.reset()
-
- def reset(self):
- '''Initializes the memory arrays, size and head pointer'''
- super(ConcatReplay, self).reset()
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.raw_state_dim))
-
- def epi_reset(self, state):
- '''Method to reset at new episode'''
- super(ConcatReplay, self).epi_reset(state)
- # reappend buffer with custom shape
- self.state_buffer.clear()
- for _ in range(self.state_buffer.maxlen):
- self.state_buffer.append(np.zeros(self.raw_state_dim))
-
- def preprocess_state(self, state, append=True):
- '''Transforms the raw state into format that is fed into the network'''
- # append when state is first seen when acting in policy_util, don't append elsewhere in memory
- self.preprocess_append(state, append)
- return np.concatenate(self.state_buffer)
-
-
-class AtariReplay(Replay):
- '''
- Preprocesses an state to be the concatenation of the last four states, after converting the 210 x 160 x 3 image to 84 x 84 x 1 grayscale image, and clips all rewards to [-10, 10] as per "Playing Atari with Deep Reinforcement Learning", Mnih et al, 2013
- Note: Playing Atari with Deep RL clips the rewards to + / - 1
-
- e.g. memory_spec
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 250000,
- "stack_len": 4,
- "use_cer": true
- }
- '''
-
- def __init__(self, memory_spec, body):
- util.set_attr(self, memory_spec, [
- 'batch_size',
- 'max_size',
- 'stack_len', # number of stack states
- 'use_cer',
- ])
- Replay.__init__(self, memory_spec, body)
- self.states_shape = self.scalar_shape
- self.states = [None] * self.max_size
-
- def add_experience(self, state, action, reward, next_state, done):
- # clip reward, done here to minimize change to only training data data
- super(AtariReplay, self).add_experience(state, action, np.sign(reward), next_state, done)
-
-
-class ImageReplay(Replay):
- '''
- An off policy replay buffer that normalizes (preprocesses) images through
- division by 255 and subtraction of 0.5.
- '''
-
- def __init__(self, memory_spec, body):
- super(ImageReplay, self).__init__(memory_spec, body)
-
- def preprocess_state(self, state, append=True):
- state = util.normalize_image(state) - 0.5
- return state
diff --git a/slm_lab/agent/net/__init__.py b/slm_lab/agent/net/__init__.py
index ad9af50d1..5290ec8cd 100644
--- a/slm_lab/agent/net/__init__.py
+++ b/slm_lab/agent/net/__init__.py
@@ -1,8 +1,5 @@
-'''
-The nets module
-Contains classes of neural network architectures
-'''
-
+# The nets module
+# Implements differents types of neural network
from slm_lab.agent.net.conv import *
from slm_lab.agent.net.mlp import *
from slm_lab.agent.net.recurrent import *
diff --git a/slm_lab/agent/net/base.py b/slm_lab/agent/net/base.py
index 5f6235a66..c8d996bad 100644
--- a/slm_lab/agent/net/base.py
+++ b/slm_lab/agent/net/base.py
@@ -1,13 +1,12 @@
from abc import ABC, abstractmethod
+from slm_lab.agent.net import net_util
+import pydash as ps
import torch
+import torch.nn as nn
class Net(ABC):
- '''
- Abstract class ancestor to all Nets,
- specifies the necessary design blueprint for algorithm to work in Lab.
- Mostly, implement just the abstract methods and properties.
- '''
+ '''Abstract Net class to define the API methods'''
def __init__(self, net_spec, in_dim, out_dim):
'''
@@ -27,6 +26,21 @@ def __init__(self, net_spec, in_dim, out_dim):
else:
self.device = 'cpu'
+ @net_util.dev_check_train_step
+ def train_step(self, loss, optim, lr_scheduler, clock=None, global_net=None):
+ lr_scheduler.step(epoch=ps.get(clock, 'frame'))
+ optim.zero_grad()
+ loss.backward()
+ if self.clip_grad_val is not None:
+ nn.utils.clip_grad_norm_(self.parameters(), self.clip_grad_val)
+ if global_net is not None:
+ net_util.push_global_grads(self, global_net)
+ optim.step()
+ if global_net is not None:
+ net_util.copy(global_net, self)
+ clock.tick('opt_step')
+ return loss
+
def store_grad_norms(self):
'''Stores the gradient norms for debugging.'''
norms = [param.grad.norm().item() for param in self.parameters()]
diff --git a/slm_lab/agent/net/conv.py b/slm_lab/agent/net/conv.py
index b6e787ac6..d2c52cc46 100644
--- a/slm_lab/agent/net/conv.py
+++ b/slm_lab/agent/net/conv.py
@@ -1,13 +1,10 @@
from slm_lab.agent.net import net_util
from slm_lab.agent.net.base import Net
-from slm_lab.lib import logger, math_util, util
-import numpy as np
+from slm_lab.lib import math_util, util
import pydash as ps
import torch
import torch.nn as nn
-logger = logger.get_logger(__name__)
-
class ConvNet(Net, nn.Module):
'''
@@ -33,6 +30,7 @@ class ConvNet(Net, nn.Module):
"hid_layers_activation": "relu",
"out_layer_activation": "tanh",
"init_fn": null,
+ "normalize": false,
"batch_norm": false,
"clip_grad_val": 1.0,
"loss_spec": {
@@ -65,6 +63,7 @@ def __init__(self, net_spec, in_dim, out_dim):
hid_layers_activation: activation function for the hidden layers
out_layer_activation: activation function for the output layer, same shape as out_dim
init_fn: weight initialization function
+ normalize: whether to divide by 255.0 to normalize image input
batch_norm: whether to add batch normalization after each convolutional layer, excluding the input layer.
clip_grad_val: clip gradient norm if value is not None
loss_spec: measure of error between model predictions and correct outputs
@@ -77,11 +76,12 @@ def __init__(self, net_spec, in_dim, out_dim):
'''
assert len(in_dim) == 3 # image shape (c,w,h)
nn.Module.__init__(self)
- super(ConvNet, self).__init__(net_spec, in_dim, out_dim)
+ super().__init__(net_spec, in_dim, out_dim)
# set default
util.set_attr(self, dict(
out_layer_activation=None,
init_fn=None,
+ normalize=False,
batch_norm=True,
clip_grad_val=None,
loss_spec={'name': 'MSELoss'},
@@ -98,6 +98,7 @@ def __init__(self, net_spec, in_dim, out_dim):
'hid_layers_activation',
'out_layer_activation',
'init_fn',
+ 'normalize',
'batch_norm',
'clip_grad_val',
'loss_spec',
@@ -135,14 +136,9 @@ def __init__(self, net_spec, in_dim, out_dim):
self.model_tails = nn.ModuleList(tails)
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
-
- def __str__(self):
- return super(ConvNet, self).__str__() + f'\noptim: {self.optim}'
+ self.to(self.device)
+ self.train()
def get_conv_output_size(self):
'''Helper function to calculate the size of the flattened features after the final convolutional layer'''
@@ -161,7 +157,8 @@ def build_conv_layers(self, conv_hid_layers):
hid_layer = [tuple(e) if ps.is_list(e) else e for e in hid_layer] # guard list-to-tuple
# hid_layer = out_d, kernel, stride, padding, dilation
conv_layers.append(nn.Conv2d(in_d, *hid_layer))
- conv_layers.append(net_util.get_activation_fn(self.hid_layers_activation))
+ if self.hid_layers_activation is not None:
+ conv_layers.append(net_util.get_activation_fn(self.hid_layers_activation))
# Don't include batch norm in the first layer
if self.batch_norm and i != 0:
conv_layers.append(nn.BatchNorm2d(in_d))
@@ -172,8 +169,10 @@ def build_conv_layers(self, conv_hid_layers):
def forward(self, x):
'''
The feedforward step
- Note that PyTorch takes (c,w,h) but gym provides (w,h,c), so preprocessing must be done before passing to network
+ Note that PyTorch takes (c,h,w) but gym provides (h,w,c), so preprocessing must be done before passing to network
'''
+ if self.normalize:
+ x = x / 255.0
x = self.conv_model(x)
x = x.view(x.size(0), -1) # to (batch_size, -1)
if hasattr(self, 'fc_model'):
@@ -187,32 +186,6 @@ def forward(self, x):
else:
return self.model_tail(x)
- @net_util.dev_check_training_step
- def training_step(self, x=None, y=None, loss=None, retain_graph=False, lr_clock=None):
- '''Takes a single training step: one forward and one backwards pass'''
- if hasattr(self, 'model_tails') and x is not None:
- raise ValueError('Loss computation from x,y not supported for multitails')
- self.lr_scheduler.step(epoch=ps.get(lr_clock, 'total_t'))
- self.train()
- self.optim.zero_grad()
- if loss is None:
- out = self(x)
- loss = self.loss_fn(out, y)
- assert not torch.isnan(loss).any(), loss
- loss.backward(retain_graph=retain_graph)
- if self.clip_grad_val is not None:
- nn.utils.clip_grad_norm_(self.parameters(), self.clip_grad_val)
- self.optim.step()
- logger.debug(f'Net training_step loss: {loss}')
- return loss
-
- def wrap_eval(self, x):
- '''
- Completes one feedforward step, ensuring net is set to evaluation model returns: network output given input x
- '''
- self.eval()
- return self(x)
-
class DuelingConvNet(ConvNet):
'''
@@ -238,6 +211,7 @@ class DuelingConvNet(ConvNet):
"fc_hid_layers": [512],
"hid_layers_activation": "relu",
"init_fn": "xavier_uniform_",
+ "normalize": false,
"batch_norm": false,
"clip_grad_val": 1.0,
"loss_spec": {
@@ -266,6 +240,7 @@ def __init__(self, net_spec, in_dim, out_dim):
# set default
util.set_attr(self, dict(
init_fn=None,
+ normalize=False,
batch_norm=False,
clip_grad_val=None,
loss_spec={'name': 'MSELoss'},
@@ -281,6 +256,7 @@ def __init__(self, net_spec, in_dim, out_dim):
'fc_hid_layers',
'hid_layers_activation',
'init_fn',
+ 'normalize',
'batch_norm',
'clip_grad_val',
'loss_spec',
@@ -313,14 +289,14 @@ def __init__(self, net_spec, in_dim, out_dim):
self.model_tails = nn.ModuleList(self.v, self.adv)
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
+ self.to(self.device)
+ self.train()
def forward(self, x):
'''The feedforward step'''
+ if self.normalize:
+ x = x / 255.0
x = self.conv_model(x)
x = x.view(x.size(0), -1) # to (batch_size, -1)
if hasattr(self, 'fc_model'):
diff --git a/slm_lab/agent/net/mlp.py b/slm_lab/agent/net/mlp.py
index 8a015593a..b993bec90 100644
--- a/slm_lab/agent/net/mlp.py
+++ b/slm_lab/agent/net/mlp.py
@@ -1,13 +1,11 @@
from slm_lab.agent.net import net_util
from slm_lab.agent.net.base import Net
-from slm_lab.lib import logger, math_util, util
+from slm_lab.lib import math_util, util
import numpy as np
import pydash as ps
import torch
import torch.nn as nn
-logger = logger.get_logger(__name__)
-
class MLPNet(Net, nn.Module):
'''
@@ -59,7 +57,7 @@ def __init__(self, net_spec, in_dim, out_dim):
gpu: whether to train using a GPU. Note this will only work if a GPU is available, othewise setting gpu=True does nothing
'''
nn.Module.__init__(self)
- super(MLPNet, self).__init__(net_spec, in_dim, out_dim)
+ super().__init__(net_spec, in_dim, out_dim)
# set default
util.set_attr(self, dict(
out_layer_activation=None,
@@ -106,14 +104,9 @@ def __init__(self, net_spec, in_dim, out_dim):
self.model_tails = nn.ModuleList(tails)
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
-
- def __str__(self):
- return super(MLPNet, self).__str__() + f'\noptim: {self.optim}'
+ self.to(self.device)
+ self.train()
def forward(self, x):
'''The feedforward step'''
@@ -126,36 +119,6 @@ def forward(self, x):
else:
return self.model_tail(x)
- @net_util.dev_check_training_step
- def training_step(self, x=None, y=None, loss=None, retain_graph=False, lr_clock=None):
- '''
- Takes a single training step: one forward and one backwards pass
- More most RL usage, we have custom, often complicated, loss functions. Compute its value and put it in a pytorch tensor then pass it in as loss
- '''
- if hasattr(self, 'model_tails') and x is not None:
- raise ValueError('Loss computation from x,y not supported for multitails')
- self.lr_scheduler.step(epoch=ps.get(lr_clock, 'total_t'))
- self.train()
- self.optim.zero_grad()
- if loss is None:
- out = self(x)
- loss = self.loss_fn(out, y)
- assert not torch.isnan(loss).any(), loss
- loss.backward(retain_graph=retain_graph)
- if self.clip_grad_val is not None:
- nn.utils.clip_grad_norm_(self.parameters(), self.clip_grad_val)
- self.optim.step()
- logger.debug(f'Net training_step loss: {loss}')
- return loss
-
- def wrap_eval(self, x):
- '''
- Completes one feedforward step, ensuring net is set to evaluation model
- returns: network output given input x
- '''
- self.eval()
- return self(x)
-
class HydraMLPNet(Net, nn.Module):
'''
@@ -218,7 +181,7 @@ def __init__(self, net_spec, in_dim, out_dim):
env 1 action env 2 action
'''
nn.Module.__init__(self)
- super(HydraMLPNet, self).__init__(net_spec, in_dim, out_dim)
+ super().__init__(net_spec, in_dim, out_dim)
# set default
util.set_attr(self, dict(
out_layer_activation=None,
@@ -264,14 +227,9 @@ def __init__(self, net_spec, in_dim, out_dim):
self.model_tails = self.build_model_tails(self.out_dim, self.out_layer_activation)
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
-
- def __str__(self):
- return super(HydraMLPNet, self).__str__() + f'\noptim: {self.optim}'
+ self.to(self.device)
+ self.train()
def build_model_heads(self, in_dim):
'''Build each model_head. These are stored as Sequential models in model_heads'''
@@ -314,37 +272,6 @@ def forward(self, xs):
outs.append(model_tail(body_x))
return outs
- @net_util.dev_check_training_step
- def training_step(self, xs=None, ys=None, loss=None, retain_graph=False, lr_clock=None):
- '''
- Takes a single training step: one forward and one backwards pass. Both x and y are lists of the same length, one x and y per environment
- '''
- self.lr_scheduler.step(epoch=ps.get(lr_clock, 'total_t'))
- self.train()
- self.optim.zero_grad()
- if loss is None:
- outs = self(xs)
- total_loss = torch.tensor(0.0, device=self.device)
- for out, y in zip(outs, ys):
- loss = self.loss_fn(out, y)
- total_loss += loss
- loss = total_loss
- assert not torch.isnan(loss).any(), loss
- loss.backward(retain_graph=retain_graph)
- if self.clip_grad_val is not None:
- nn.utils.clip_grad_norm_(self.parameters(), self.clip_grad_val)
- self.optim.step()
- logger.debug(f'Net training_step loss: {loss}')
- return loss
-
- def wrap_eval(self, x):
- '''
- Completes one feedforward step, ensuring net is set to evaluation model
- returns: network output given input x
- '''
- self.eval()
- return self(x)
-
class DuelingMLPNet(MLPNet):
'''
@@ -416,11 +343,8 @@ def __init__(self, net_spec, in_dim, out_dim):
self.v = nn.Linear(dims[-1], 1) # state value
self.adv = nn.Linear(dims[-1], out_dim) # action dependent raw advantage
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
+ self.to(self.device)
def forward(self, x):
'''The feedforward step'''
diff --git a/slm_lab/agent/net/net_util.py b/slm_lab/agent/net/net_util.py
index b50850dd7..18b9a1492 100644
--- a/slm_lab/agent/net/net_util.py
+++ b/slm_lab/agent/net/net_util.py
@@ -1,6 +1,5 @@
from functools import partial, wraps
-from slm_lab import ROOT_DIR
-from slm_lab.lib import logger, util
+from slm_lab.lib import logger, optimizer, util
import os
import pydash as ps
import torch
@@ -8,6 +7,9 @@
logger = logger.get_logger(__name__)
+# register custom torch.optim
+setattr(torch.optim, 'GlobalAdam', optimizer.GlobalAdam)
+
class NoOpLRScheduler:
'''Symbolic LRScheduler class for API consistency'''
@@ -19,7 +21,10 @@ def step(self, epoch=None):
pass
def get_lr(self):
- return self.optim.defaults['lr']
+ if hasattr(self.optim, 'defaults'):
+ return self.optim.defaults['lr']
+ else: # TODO retrieve lr more generally
+ return self.optim.param_groups[0]['lr']
def build_fc_model(dims, activation=None):
@@ -46,7 +51,6 @@ def get_nn_name(uncased_name):
def get_activation_fn(activation):
'''Helper to generate activation function layers for net'''
- activation = activation or 'relu'
ActivationClass = getattr(nn, get_nn_name(activation))
return ActivationClass()
@@ -59,26 +63,26 @@ def get_loss_fn(cls, loss_spec):
return loss_fn
-def get_lr_scheduler(cls, lr_scheduler_spec):
+def get_lr_scheduler(optim, lr_scheduler_spec):
'''Helper to parse lr_scheduler param and construct Pytorch optim.lr_scheduler'''
if ps.is_empty(lr_scheduler_spec):
- lr_scheduler = NoOpLRScheduler(cls.optim)
+ lr_scheduler = NoOpLRScheduler(optim)
elif lr_scheduler_spec['name'] == 'LinearToZero':
LRSchedulerClass = getattr(torch.optim.lr_scheduler, 'LambdaLR')
- total_t = float(lr_scheduler_spec['total_t'])
- lr_scheduler = LRSchedulerClass(cls.optim, lr_lambda=lambda x: 1 - x / total_t)
+ frame = float(lr_scheduler_spec['frame'])
+ lr_scheduler = LRSchedulerClass(optim, lr_lambda=lambda x: 1 - x / frame)
else:
LRSchedulerClass = getattr(torch.optim.lr_scheduler, lr_scheduler_spec['name'])
lr_scheduler_spec = ps.omit(lr_scheduler_spec, 'name')
- lr_scheduler = LRSchedulerClass(cls.optim, **lr_scheduler_spec)
+ lr_scheduler = LRSchedulerClass(optim, **lr_scheduler_spec)
return lr_scheduler
-def get_optim(cls, optim_spec):
+def get_optim(net, optim_spec):
'''Helper to parse optim param and construct optim for net'''
OptimClass = getattr(torch.optim, optim_spec['name'])
optim_spec = ps.omit(optim_spec, 'name')
- optim = OptimClass(cls.parameters(), **optim_spec)
+ optim = OptimClass(net.parameters(), **optim_spec)
return optim
@@ -93,16 +97,11 @@ def get_policy_out_dim(body):
assert ps.is_integer(action_dim), action_dim
policy_out_dim = action_dim
else:
- if body.action_type == 'multi_continuous':
- assert ps.is_list(action_dim), action_dim
- raise NotImplementedError('multi_continuous not supported yet')
- else:
- assert ps.is_integer(action_dim), action_dim
- if action_dim == 1:
- policy_out_dim = 2 # singleton stay as int
- else:
- # TODO change this to one slicable layer for efficiency
- policy_out_dim = action_dim * [2]
+ assert ps.is_integer(action_dim), action_dim
+ if action_dim == 1: # single action, use [loc, scale]
+ policy_out_dim = 2
+ else: # multi-action, use [locs], [scales]
+ policy_out_dim = [action_dim, action_dim]
return policy_out_dim
@@ -119,36 +118,38 @@ def get_out_dim(body, add_critic=False):
return out_dim
-def init_layers(net, init_fn):
- if init_fn is None:
+def init_layers(net, init_fn_name):
+ '''Primary method to initialize the weights of the layers of a network'''
+ if init_fn_name is None:
return
+
+ # get nonlinearity
nonlinearity = get_nn_name(net.hid_layers_activation).lower()
if nonlinearity == 'leakyrelu':
- nonlinearity = 'leaky_relu'
- if init_fn == 'xavier_uniform_':
- try:
- gain = nn.init.calculate_gain(nonlinearity)
- except ValueError:
- gain = 1
- init_fn = partial(nn.init.xavier_uniform_, gain=gain)
- elif 'kaiming' in init_fn:
+ nonlinearity = 'leaky_relu' # guard name
+
+ # get init_fn and add arguments depending on nonlinearity
+ init_fn = getattr(nn.init, init_fn_name)
+ if 'kaiming' in init_fn_name: # has 'nonlinearity' as arg
assert nonlinearity in ['relu', 'leaky_relu'], f'Kaiming initialization not supported for {nonlinearity}'
- init_fn = nn.init.__dict__[init_fn]
init_fn = partial(init_fn, nonlinearity=nonlinearity)
+ elif 'orthogonal' in init_fn_name or 'xavier' in init_fn_name: # has 'gain' as arg
+ gain = nn.init.calculate_gain(nonlinearity)
+ init_fn = partial(init_fn, gain=gain)
else:
- init_fn = nn.init.__dict__[init_fn]
- net.apply(partial(init_parameters, init_fn=init_fn))
+ pass
+ # finally, apply init_params to each layer in its modules
+ net.apply(partial(init_params, init_fn=init_fn))
-def init_parameters(module, init_fn):
- '''
- Initializes module's weights using init_fn, which is the name of function from from nn.init
- Initializes module's biases to either 0.01 or 0.0, depending on module
- The only exception is BatchNorm layers, for which we use uniform initialization
- '''
+
+def init_params(module, init_fn):
+ '''Initialize module's weights using init_fn, and biases to 0.0'''
bias_init = 0.0
classname = util.get_class_name(module)
- if 'BatchNorm' in classname:
+ if 'Net' in classname: # skip if it's a net, not pytorch layer
+ pass
+ elif any(k in classname for k in ('BatchNorm', 'Conv', 'Linear')):
init_fn(module.weight)
nn.init.constant_(module.bias, bias_init)
elif 'GRU' in classname:
@@ -156,10 +157,9 @@ def init_parameters(module, init_fn):
if 'weight' in name:
init_fn(param)
elif 'bias' in name:
- nn.init.constant_(param, 0.0)
- elif 'Linear' in classname or ('Conv' in classname and 'Net' not in classname):
- init_fn(module.weight)
- nn.init.constant_(module.bias, bias_init)
+ nn.init.constant_(param, bias_init)
+ else:
+ pass
# params methods
@@ -168,30 +168,31 @@ def init_parameters(module, init_fn):
def save(net, model_path):
'''Save model weights to path'''
torch.save(net.state_dict(), util.smart_path(model_path))
- logger.info(f'Saved model to {model_path}')
def save_algorithm(algorithm, ckpt=None):
'''Save all the nets for an algorithm'''
agent = algorithm.agent
net_names = algorithm.net_names
- prepath = util.get_prepath(agent.spec, agent.info_space, unit='session')
+ model_prepath = agent.spec['meta']['model_prepath']
if ckpt is not None:
- prepath = f'{prepath}_ckpt-{ckpt}'
- logger.info(f'Saving algorithm {util.get_class_name(algorithm)} nets {net_names}')
+ model_prepath = f'{model_prepath}_ckpt-{ckpt}'
for net_name in net_names:
net = getattr(algorithm, net_name)
- model_path = f'{prepath}_{net_name}_model.pth'
+ model_path = f'{model_prepath}_{net_name}_model.pt'
save(net, model_path)
- optim_path = f'{prepath}_{net_name}_optim.pth'
- save(net.optim, optim_path)
+ optim_name = net_name.replace('net', 'optim')
+ optim = getattr(algorithm, optim_name, None)
+ if optim is not None: # only trainable net has optim
+ optim_path = f'{model_prepath}_{net_name}_optim.pt'
+ save(optim, optim_path)
+ logger.debug(f'Saved algorithm {util.get_class_name(algorithm)} nets {net_names} to {model_prepath}_*.pt')
def load(net, model_path):
'''Save model weights from a path into a net module'''
device = None if torch.cuda.is_available() else 'cpu'
net.load_state_dict(torch.load(util.smart_path(model_path), map_location=device))
- logger.info(f'Loaded model from {model_path}')
def load_algorithm(algorithm):
@@ -200,16 +201,19 @@ def load_algorithm(algorithm):
net_names = algorithm.net_names
if util.in_eval_lab_modes():
# load specific model in eval mode
- prepath = agent.info_space.eval_model_prepath
+ model_prepath = agent.spec['meta']['eval_model_prepath']
else:
- prepath = util.get_prepath(agent.spec, agent.info_space, unit='session')
- logger.info(f'Loading algorithm {util.get_class_name(algorithm)} nets {net_names}')
+ model_prepath = agent.spec['meta']['model_prepath']
+ logger.info(f'Loading algorithm {util.get_class_name(algorithm)} nets {net_names} from {model_prepath}_*.pt')
for net_name in net_names:
net = getattr(algorithm, net_name)
- model_path = f'{prepath}_{net_name}_model.pth'
+ model_path = f'{model_prepath}_{net_name}_model.pt'
load(net, model_path)
- optim_path = f'{prepath}_{net_name}_optim.pth'
- load(net.optim, optim_path)
+ optim_name = net_name.replace('net', 'optim')
+ optim = getattr(algorithm, optim_name, None)
+ if optim is not None: # only trainable net has optim
+ optim_path = f'{model_prepath}_{net_name}_optim.pt'
+ load(optim, optim_path)
def copy(src_net, tar_net):
@@ -226,32 +230,33 @@ def polyak_update(src_net, tar_net, old_ratio=0.5):
tar_param.data.copy_(old_ratio * src_param.data + (1.0 - old_ratio) * tar_param.data)
-def to_check_training_step():
+def to_check_train_step():
'''Condition for running assert_trained'''
return os.environ.get('PY_ENV') == 'test' or util.get_lab_mode() == 'dev'
-def dev_check_training_step(fn):
+def dev_check_train_step(fn):
'''
- Decorator to check if net.training_step actually updates the network weights properly
- Triggers only if to_check_training_step is True (dev/test mode)
+ Decorator to check if net.train_step actually updates the network weights properly
+ Triggers only if to_check_train_step is True (dev/test mode)
@example
- @net_util.dev_check_training_step
- def training_step(self, ...):
+ @net_util.dev_check_train_step
+ def train_step(self, ...):
...
'''
@wraps(fn)
def check_fn(*args, **kwargs):
- if not to_check_training_step():
+ if not to_check_train_step():
return fn(*args, **kwargs)
net = args[0] # first arg self
# get pre-update parameters to compare
pre_params = [param.clone() for param in net.parameters()]
- # run training_step, get loss
+ # run train_step, get loss
loss = fn(*args, **kwargs)
+ assert not torch.isnan(loss).any(), loss
# get post-update parameters to compare
post_params = [param.clone() for param in net.parameters()]
@@ -263,8 +268,8 @@ def check_fn(*args, **kwargs):
else:
# check parameter updates
try:
- assert not all(torch.equal(w1, w2) for w1, w2 in zip(pre_params, post_params)), f'Model parameter is not updated in training_step(), check if your tensor is detached from graph. Loss: {loss:g}'
- logger.info(f'Model parameter is updated in training_step(). Loss: {loss: g}')
+ assert not all(torch.equal(w1, w2) for w1, w2 in zip(pre_params, post_params)), f'Model parameter is not updated in train_step(), check if your tensor is detached from graph. Loss: {loss:g}'
+ logger.info(f'Model parameter is updated in train_step(). Loss: {loss: g}')
except Exception as e:
logger.error(e)
if os.environ.get('PY_ENV') == 'test':
@@ -277,9 +282,9 @@ def check_fn(*args, **kwargs):
try:
grad_norm = param.grad.norm()
assert min_norm < grad_norm < max_norm, f'Gradient norm for {p_name} is {grad_norm:g}, fails the extreme value check {min_norm} < grad_norm < {max_norm}. Loss: {loss:g}. Check your network and loss computation.'
- logger.info(f'Gradient norm for {p_name} is {grad_norm:g}; passes value check.')
except Exception as e:
- logger.warn(e)
+ logger.warning(e)
+ logger.info(f'Gradient norms passed value check.')
logger.debug('Passed network parameter update check.')
# store grad norms for debugging
net.store_grad_norms()
@@ -295,3 +300,54 @@ def get_grad_norms(algorithm):
if net.grad_norms is not None:
grad_norms.extend(net.grad_norms)
return grad_norms
+
+
+def init_global_nets(algorithm):
+ '''
+ Initialize global_nets for Hogwild using an identical instance of an algorithm from an isolated Session
+ in spec.meta.distributed, specify either:
+ - 'shared': global network parameter is shared all the time. In this mode, algorithm local network will be replaced directly by global_net via overriding by identify attribute name
+ - 'synced': global network parameter is periodically synced to local network after each gradient push. In this mode, algorithm will keep a separate reference to `global_{net}` for each of its network
+ '''
+ dist_mode = algorithm.agent.spec['meta']['distributed']
+ assert dist_mode in ('shared', 'synced'), f'Unrecognized distributed mode'
+ global_nets = {}
+ for net_name in algorithm.net_names:
+ optim_name = net_name.replace('net', 'optim')
+ if not hasattr(algorithm, optim_name): # only for trainable network, i.e. has an optim
+ continue
+ g_net = getattr(algorithm, net_name)
+ g_net.share_memory() # make net global
+ if dist_mode == 'shared': # use the same name to override the local net
+ global_nets[net_name] = g_net
+ else: # keep a separate reference for syncing
+ global_nets[f'global_{net_name}'] = g_net
+ # if optim is Global, set to override the local optim and its scheduler
+ optim = getattr(algorithm, optim_name)
+ if 'Global' in util.get_class_name(optim):
+ optim.share_memory() # make optim global
+ global_nets[optim_name] = optim
+ lr_scheduler_name = net_name.replace('net', 'lr_scheduler')
+ lr_scheduler = getattr(algorithm, lr_scheduler_name)
+ global_nets[lr_scheduler_name] = lr_scheduler
+ logger.info(f'Initialized global_nets attr {list(global_nets.keys())} for Hogwild')
+ return global_nets
+
+
+def set_global_nets(algorithm, global_nets):
+ '''For Hogwild, set attr built in init_global_nets above. Use in algorithm init.'''
+ # set attr first so algorithm always has self.global_{net} to pass into train_step
+ for net_name in algorithm.net_names:
+ setattr(algorithm, f'global_{net_name}', None)
+ # set attr created in init_global_nets
+ if global_nets is not None:
+ util.set_attr(algorithm, global_nets)
+ logger.info(f'Set global_nets attr {list(global_nets.keys())} for Hogwild')
+
+
+def push_global_grads(net, global_net):
+ '''Push gradients to global_net, call inside train_step between loss.backward() and optim.step()'''
+ for param, global_param in zip(net.parameters(), global_net.parameters()):
+ if global_param.grad is not None:
+ return # quick skip
+ global_param._grad = param.grad
diff --git a/slm_lab/agent/net/recurrent.py b/slm_lab/agent/net/recurrent.py
index e8af3ec73..7bbf0761b 100644
--- a/slm_lab/agent/net/recurrent.py
+++ b/slm_lab/agent/net/recurrent.py
@@ -1,13 +1,9 @@
from slm_lab.agent.net import net_util
from slm_lab.agent.net.base import Net
-from slm_lab.lib import logger, util
-import numpy as np
+from slm_lab.lib import util
import pydash as ps
-import torch
import torch.nn as nn
-logger = logger.get_logger(__name__)
-
class RecurrentNet(Net, nn.Module):
'''
@@ -75,7 +71,7 @@ def __init__(self, net_spec, in_dim, out_dim):
gpu: whether to train using a GPU. Note this will only work if a GPU is available, othewise setting gpu=True does nothing
'''
nn.Module.__init__(self)
- super(RecurrentNet, self).__init__(net_spec, in_dim, out_dim)
+ super().__init__(net_spec, in_dim, out_dim)
# set default
util.set_attr(self, dict(
out_layer_activation=None,
@@ -111,6 +107,8 @@ def __init__(self, net_spec, in_dim, out_dim):
'polyak_coef',
'gpu',
])
+ # restore proper in_dim from env stacked state_dim (stack_len, *raw_state_dim)
+ self.in_dim = in_dim[1:] if len(in_dim) > 2 else in_dim[1]
# fc body: state processing model
if ps.is_empty(self.fc_hid_layers):
self.rnn_input_dim = self.in_dim
@@ -140,14 +138,9 @@ def __init__(self, net_spec, in_dim, out_dim):
self.model_tails = nn.ModuleList(tails)
net_util.init_layers(self, self.init_fn)
- for module in self.modules():
- module.to(self.device)
self.loss_fn = net_util.get_loss_fn(self, self.loss_spec)
- self.optim = net_util.get_optim(self, self.optim_spec)
- self.lr_scheduler = net_util.get_lr_scheduler(self, self.lr_scheduler_spec)
-
- def __str__(self):
- return super(RecurrentNet, self).__str__() + f'\noptim: {self.optim}'
+ self.to(self.device)
+ self.train()
def forward(self, x):
'''The feedforward step. Input is batch_size x seq_len x state_dim'''
@@ -171,29 +164,3 @@ def forward(self, x):
return outs
else:
return self.model_tail(hid_x)
-
- @net_util.dev_check_training_step
- def training_step(self, x=None, y=None, loss=None, retain_graph=False, lr_clock=None):
- '''Takes a single training step: one forward and one backwards pass'''
- if hasattr(self, 'model_tails') and x is not None:
- raise ValueError('Loss computation from x,y not supported for multitails')
- self.lr_scheduler.step(epoch=ps.get(lr_clock, 'total_t'))
- self.train()
- self.optim.zero_grad()
- if loss is None:
- out = self(x)
- loss = self.loss_fn(out, y)
- assert not torch.isnan(loss).any(), loss
- loss.backward(retain_graph=retain_graph)
- if self.clip_grad_val is not None:
- nn.utils.clip_grad_norm_(self.parameters(), self.clip_grad_val)
- self.optim.step()
- logger.debug(f'Net training_step loss: {loss}')
- return loss
-
- def wrap_eval(self, x):
- '''
- Completes one feedforward step, ensuring net is set to evaluation model returns: network output given input x
- '''
- self.eval()
- return self(x)
diff --git a/slm_lab/env/__init__.py b/slm_lab/env/__init__.py
index a9e22921f..db9b2078c 100644
--- a/slm_lab/env/__init__.py
+++ b/slm_lab/env/__init__.py
@@ -1,82 +1,11 @@
-'''
-The environment module
-Contains graduated components from experiments for building/using environment.
-Provides the rich experience for agent embodiment, reflects the curriculum and allows teaching (possibly allows teacher to enter).
-To be designed by human and evolution module, based on the curriculum and fitness metrics.
-'''
-from slm_lab.env.base import Clock, ENV_DATA_NAMES
-from slm_lab.lib import logger, util
-from slm_lab.lib.decorator import lab_api
-import pydash as ps
+# the environment module
-logger = logger.get_logger(__name__)
-
-
-def make_env(spec, e=None, env_space=None):
+def make_env(spec, e=None):
try:
from slm_lab.env.openai import OpenAIEnv
- env = OpenAIEnv(spec, e, env_space)
+ env = OpenAIEnv(spec, e)
except Exception:
from slm_lab.env.unity import UnityEnv
- env = UnityEnv(spec, e, env_space)
+ env = UnityEnv(spec, e)
return env
-
-
-class EnvSpace:
- '''
- Subspace of AEBSpace, collection of all envs, with interface to Session logic; same methods as singleton envs.
- Access AgentSpace properties by: AgentSpace - AEBSpace - EnvSpace - Envs
- '''
-
- def __init__(self, spec, aeb_space):
- self.spec = spec
- self.aeb_space = aeb_space
- aeb_space.env_space = self
- self.info_space = aeb_space.info_space
- self.envs = []
- for e in range(len(self.spec['env'])):
- env = make_env(self.spec, e, env_space=self)
- self.envs.append(env)
- logger.info(util.self_desc(self))
-
- def get(self, e):
- return self.envs[e]
-
- def get_base_clock(self):
- '''Get the clock with the finest time unit, i.e. ticks the most cycles in a given time, or the highest clock_speed'''
- fastest_env = ps.max_by(self.envs, lambda env: env.clock_speed)
- clock = fastest_env.clock
- return clock
-
- @lab_api
- def reset(self):
- logger.debug3('EnvSpace.reset')
- _reward_v, state_v, done_v = self.aeb_space.init_data_v(ENV_DATA_NAMES)
- for env in self.envs:
- _reward_e, state_e, done_e = env.space_reset()
- state_v[env.e, 0:len(state_e)] = state_e
- done_v[env.e, 0:len(done_e)] = done_e
- _reward_space, state_space, done_space = self.aeb_space.add(ENV_DATA_NAMES, (_reward_v, state_v, done_v))
- logger.debug3(f'\nstate_space: {state_space}')
- return _reward_space, state_space, done_space
-
- @lab_api
- def step(self, action_space):
- reward_v, state_v, done_v = self.aeb_space.init_data_v(ENV_DATA_NAMES)
- for env in self.envs:
- e = env.e
- action_e = action_space.get(e=e)
- reward_e, state_e, done_e = env.space_step(action_e)
- reward_v[e, 0:len(reward_e)] = reward_e
- state_v[e, 0:len(state_e)] = state_e
- done_v[e, 0:len(done_e)] = done_e
- reward_space, state_space, done_space = self.aeb_space.add(ENV_DATA_NAMES, (reward_v, state_v, done_v))
- logger.debug3(f'\nreward_space: {reward_space}\nstate_space: {state_space}\ndone_space: {done_space}')
- return reward_space, state_space, done_space
-
- @lab_api
- def close(self):
- logger.info('EnvSpace.close')
- for env in self.envs:
- env.close()
diff --git a/slm_lab/env/base.py b/slm_lab/env/base.py
index 2e36e83e6..3c3f960ba 100644
--- a/slm_lab/env/base.py
+++ b/slm_lab/env/base.py
@@ -3,10 +3,9 @@
from slm_lab.lib import logger, util
from slm_lab.lib.decorator import lab_api
import numpy as np
+import pydash as ps
import time
-ENV_DATA_NAMES = ['reward', 'state', 'done']
-NUM_EVAL_EPI = 100 # set the number of episodes to eval a model ckpt
logger = logger.get_logger(__name__)
@@ -33,39 +32,41 @@ def set_gym_space_attr(gym_space):
class Clock:
'''Clock class for each env and space to keep track of relative time. Ticking and control loop is such that reset is at t=0 and epi=0'''
- def __init__(self, clock_speed=1):
+ def __init__(self, max_frame=int(1e7), clock_speed=1):
+ self.max_frame = max_frame
self.clock_speed = int(clock_speed)
- self.ticks = 0 # multiple ticks make a timestep; used for clock speed
+ self.reset()
+
+ def reset(self):
self.t = 0
- self.total_t = 0
- self.epi = -1 # offset so epi is 0 when it gets ticked at start
+ self.frame = 0 # i.e. total_t
+ self.epi = 0
self.start_wall_t = time.time()
+ self.batch_size = 1 # multiplier to accurately count opt steps
+ self.opt_step = 0 # count the number of optimizer updates
- def get(self, unit='t'):
+ def get(self, unit='frame'):
return getattr(self, unit)
def get_elapsed_wall_t(self):
'''Calculate the elapsed wall time (int seconds) since self.start_wall_t'''
return int(time.time() - self.start_wall_t)
+ def set_batch_size(self, batch_size):
+ self.batch_size = batch_size
+
def tick(self, unit='t'):
if unit == 't': # timestep
- if self.to_step():
- self.t += 1
- self.total_t += 1
- else:
- pass
- self.ticks += 1
+ self.t += self.clock_speed
+ self.frame += self.clock_speed
elif unit == 'epi': # episode, reset timestep
self.epi += 1
self.t = 0
+ elif unit == 'opt_step':
+ self.opt_step += self.batch_size
else:
raise KeyError
- def to_step(self):
- '''Step signal from clock_speed. Step only if the base unit of time in this clock has moved. Used to control if env of different clock_speed should step()'''
- return self.ticks % self.clock_speed == 0
-
class BaseEnv(ABC):
'''
@@ -73,46 +74,59 @@ class BaseEnv(ABC):
e.g. env_spec
"env": [{
- "name": "CartPole-v0",
- "max_t": null,
- "max_tick": 150,
- }],
-
- # or using total_t
- "env": [{
- "name": "CartPole-v0",
- "max_t": null,
- "max_tick": 10000,
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "normalize_state": false,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
}],
'''
- def __init__(self, spec, e=None, env_space=None):
- self.e = e or 0 # for compatibility with env_space
- self.clock_speed = 1
- self.clock = Clock(self.clock_speed)
+ def __init__(self, spec, e=None):
+ self.e = e or 0 # for multi-env
self.done = False
self.env_spec = spec['env'][self.e]
+ # set default
util.set_attr(self, dict(
- reward_scale=1.0,
+ log_frequency=None, # default to log at epi done
+ frame_op=None,
+ frame_op_len=None,
+ normalize_state=False,
+ reward_scale=None,
+ num_envs=None,
))
util.set_attr(self, spec['meta'], [
+ 'log_frequency',
'eval_frequency',
- 'max_tick_unit',
])
util.set_attr(self, self.env_spec, [
'name',
- 'max_t',
- 'max_tick',
+ 'frame_op',
+ 'frame_op_len',
+ 'normalize_state',
'reward_scale',
+ 'num_envs',
+ 'max_t',
+ 'max_frame',
])
- if util.get_lab_mode() == 'eval':
- # override for eval, offset so epi is 0 - (num_eval_epi - 1)
- logger.info(f'Override max_tick for eval mode to {NUM_EVAL_EPI} epi')
- self.max_tick = NUM_EVAL_EPI - 1
- self.max_tick_unit = 'epi'
- # set max_tick info to clock
- self.clock.max_tick = self.max_tick
- self.clock.max_tick_unit = self.max_tick_unit
+ seq_len = ps.get(spec, 'agent.0.net.seq_len')
+ if seq_len is not None: # infer if using RNN
+ self.frame_op = 'stack'
+ self.frame_op_len = seq_len
+ if util.in_eval_lab_modes(): # use singleton for eval
+ self.num_envs = 1
+ self.log_frequency = None
+ if spec['meta']['distributed'] != False: # divide max_frame for distributed
+ self.max_frame = int(self.max_frame / spec['meta']['max_session'])
+ self.is_venv = (self.num_envs is not None and self.num_envs > 1)
+ if self.is_venv:
+ assert self.log_frequency is not None, f'Specify log_frequency when using venv'
+ self.clock_speed = 1 * (self.num_envs or 1) # tick with a multiple of num_envs to properly count frames
+ self.clock = Clock(self.max_frame, self.clock_speed)
+ self.to_render = util.to_render()
def _set_attr_from_u_env(self, u_env):
'''Set the observation, action dimensions and action type from u_env'''
@@ -156,13 +170,13 @@ def _is_discrete(self, action_space):
@abstractmethod
@lab_api
def reset(self):
- '''Reset method, return _reward, state, done'''
+ '''Reset method, return state'''
raise NotImplementedError
@abstractmethod
@lab_api
def step(self, action):
- '''Step method, return reward, state, done'''
+ '''Step method, return state, reward, done, info'''
raise NotImplementedError
@abstractmethod
@@ -170,27 +184,3 @@ def step(self, action):
def close(self):
'''Method to close and cleanup env'''
raise NotImplementedError
-
- @lab_api
- def set_body_e(self, body_e):
- '''Method called by body_space.init_body_space to complete the necessary backward reference needed for EnvSpace to work'''
- self.body_e = body_e
- self.nanflat_body_e = util.nanflatten(self.body_e)
- for idx, body in enumerate(self.nanflat_body_e):
- body.nanflat_e_idx = idx
- self.body_num = len(self.nanflat_body_e)
-
- @lab_api
- def space_init(self, env_space):
- '''Post init override for space env. Note that aeb is already correct from __init__'''
- raise NotImplementedError
-
- @lab_api
- def space_reset(self):
- '''Space (multi-env) reset method, return _reward_e, state_e, done_e'''
- raise NotImplementedError
-
- @lab_api
- def space_step(self, action_e):
- '''Space (multi-env) step method, return reward_e, state_e, done_e'''
- raise NotImplementedError
diff --git a/slm_lab/env/openai.py b/slm_lab/env/openai.py
index 5f3ba247d..e9bf304d2 100644
--- a/slm_lab/env/openai.py
+++ b/slm_lab/env/openai.py
@@ -1,22 +1,16 @@
-from slm_lab.env.base import BaseEnv, ENV_DATA_NAMES
-from slm_lab.env.wrapper import wrap_atari, wrap_deepmind
-from slm_lab.env.registration import register_env
+from slm_lab.env.base import BaseEnv
+from slm_lab.env.wrapper import make_gym_env
+from slm_lab.env.vec_env import make_gym_venv
+from slm_lab.env.registration import try_register_env
from slm_lab.lib import logger, util
from slm_lab.lib.decorator import lab_api
import gym
import numpy as np
import pydash as ps
-
-logger = logger.get_logger(__name__)
+import roboschool
-def guard_reward(reward):
- '''Some gym environments have buggy format and reward is in a np array'''
- if np.isscalar(reward):
- return reward
- else: # some gym envs have weird reward format
- assert len(reward) == 1
- return reward[0]
+logger = logger.get_logger(__name__)
class OpenAIEnv(BaseEnv):
@@ -25,106 +19,53 @@ class OpenAIEnv(BaseEnv):
e.g. env_spec
"env": [{
- "name": "CartPole-v0",
- "max_t": null,
- "max_tick": 150,
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "normalize_state": false,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
}],
'''
- def __init__(self, spec, e=None, env_space=None):
- super(OpenAIEnv, self).__init__(spec, e, env_space)
- try:
- # register any additional environments first. guard for re-registration
- register_env(spec)
- except Exception as e:
- pass
- env = gym.make(self.name)
- if 'NoFrameskip' in env.spec.id: # for Atari
- stack_len = ps.get(spec, 'agent.0.memory.stack_len')
- env = wrap_atari(env)
- if util.get_lab_mode() == 'eval':
- env = wrap_deepmind(env, stack_len=stack_len, clip_rewards=False, episode_life=False)
- else:
- # no reward clipping in training since Atari Memory classes handle it
- env = wrap_deepmind(env, stack_len=stack_len, clip_rewards=False)
- self.u_env = env
+ def __init__(self, spec, e=None):
+ super().__init__(spec, e)
+ try_register_env(spec) # register if it's a custom gym env
+ seed = ps.get(spec, 'meta.random_seed')
+ if self.is_venv: # make vector environment
+ self.u_env = make_gym_venv(self.name, self.num_envs, seed, self.frame_op, self.frame_op_len, self.reward_scale, self.normalize_state)
+ else:
+ self.u_env = make_gym_env(self.name, seed, self.frame_op, self.frame_op_len, self.reward_scale, self.normalize_state)
self._set_attr_from_u_env(self.u_env)
self.max_t = self.max_t or self.u_env.spec.max_episode_steps
assert self.max_t is not None
- if env_space is None: # singleton mode
- pass
- else:
- self.space_init(env_space)
logger.info(util.self_desc(self))
+ def seed(self, seed):
+ self.u_env.seed(seed)
+
@lab_api
def reset(self):
- _reward = np.nan
+ self.done = False
state = self.u_env.reset()
- self.done = done = False
- if util.to_render():
+ if self.to_render:
self.u_env.render()
- logger.debug(f'Env {self.e} reset reward: {_reward}, state: {state}, done: {done}')
- return _reward, state, done
+ return state
@lab_api
def step(self, action):
- if not self.is_discrete: # guard for continuous
- action = np.array([action])
- state, reward, done, _info = self.u_env.step(action)
- reward = guard_reward(reward)
- reward *= self.reward_scale
- if util.to_render():
+ if not self.is_discrete and self.action_dim == 1: # guard for continuous with action_dim 1, make array
+ action = np.expand_dims(action, axis=-1)
+ state, reward, done, info = self.u_env.step(action)
+ if self.to_render:
self.u_env.render()
- if self.max_t is not None:
- done = done or self.clock.t > self.max_t
+ if not self.is_venv and self.clock.t > self.max_t:
+ done = True
self.done = done
- logger.debug(f'Env {self.e} step reward: {reward}, state: {state}, done: {done}')
- return reward, state, done
+ return state, reward, done, info
@lab_api
def close(self):
self.u_env.close()
-
- # NOTE optional extension for multi-agent-env
-
- @lab_api
- def space_init(self, env_space):
- '''Post init override for space env. Note that aeb is already correct from __init__'''
- self.env_space = env_space
- self.aeb_space = env_space.aeb_space
- self.observation_spaces = [self.observation_space]
- self.action_spaces = [self.action_space]
-
- @lab_api
- def space_reset(self):
- _reward_e, state_e, done_e = self.env_space.aeb_space.init_data_s(ENV_DATA_NAMES, e=self.e)
- for ab, body in util.ndenumerate_nonan(self.body_e):
- state = self.u_env.reset()
- state_e[ab] = state
- done_e[ab] = self.done = False
- if util.to_render():
- self.u_env.render()
- logger.debug(f'Env {self.e} reset reward_e: {_reward_e}, state_e: {state_e}, done_e: {done_e}')
- return _reward_e, state_e, done_e
-
- @lab_api
- def space_step(self, action_e):
- action = action_e[(0, 0)] # single body
- if self.done: # space envs run continually without a central reset signal
- return self.space_reset()
- if not self.is_discrete:
- action = np.array([action])
- state, reward, done, _info = self.u_env.step(action)
- reward = guard_reward(reward)
- reward *= self.reward_scale
- if util.to_render():
- self.u_env.render()
- self.done = done = done or self.clock.t > self.max_t
- reward_e, state_e, done_e = self.env_space.aeb_space.init_data_s(ENV_DATA_NAMES, e=self.e)
- for ab, body in util.ndenumerate_nonan(self.body_e):
- reward_e[ab] = reward
- state_e[ab] = state
- done_e[ab] = done
- logger.debug(f'Env {self.e} step reward_e: {reward_e}, state_e: {state_e}, done_e: {done_e}')
- return reward_e, state_e, done_e
diff --git a/slm_lab/env/registration.py b/slm_lab/env/registration.py
index 36faa4f01..fd42403d1 100644
--- a/slm_lab/env/registration.py
+++ b/slm_lab/env/registration.py
@@ -13,13 +13,15 @@ def get_env_path(env_name):
return env_path
-def register_env(spec):
- '''Register additional environments for OpenAI gym.'''
- env_name = spec['env'][0]['name']
-
- if env_name.lower() == 'vizdoom-v0':
- assert 'cfg_name' in spec['env'][0].keys(), 'Environment config name must be defined for vizdoom.'
- cfg_name = spec['env'][0]['cfg_name']
- register(id='vizdoom-v0',
- entry_point='slm_lab.env.vizdoom.vizdoom_env:VizDoomEnv',
- kwargs={'cfg_name': cfg_name})
+def try_register_env(spec):
+ '''Try to additional environments for OpenAI gym.'''
+ try:
+ env_name = spec['env'][0]['name']
+ if env_name.lower() == 'vizdoom-v0':
+ assert 'cfg_name' in spec['env'][0].keys(), 'Environment config name must be defined for vizdoom.'
+ cfg_name = spec['env'][0]['cfg_name']
+ register(id='vizdoom-v0',
+ entry_point='slm_lab.env.vizdoom.vizdoom_env:VizDoomEnv',
+ kwargs={'cfg_name': cfg_name})
+ except Exception as e:
+ pass
diff --git a/slm_lab/env/unity.py b/slm_lab/env/unity.py
index 8c24ffa3d..69cdd98dd 100644
--- a/slm_lab/env/unity.py
+++ b/slm_lab/env/unity.py
@@ -1,6 +1,7 @@
from gym import spaces
-from slm_lab.env.base import BaseEnv, ENV_DATA_NAMES, set_gym_space_attr
+from slm_lab.env.base import BaseEnv, set_gym_space_attr
from slm_lab.env.registration import get_env_path
+from slm_lab.env.wrapper import try_scale_reward
from slm_lab.lib import logger, util
from slm_lab.lib.decorator import lab_api
from unityagents import brain, UnityEnvironment
@@ -49,7 +50,7 @@ class UnityEnv(BaseEnv):
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
"unity": {
"gridSize": 6,
"numObstacles": 2,
@@ -58,19 +59,16 @@ class UnityEnv(BaseEnv):
}],
'''
- def __init__(self, spec, e=None, env_space=None):
- super(UnityEnv, self).__init__(spec, e, env_space)
+ def __init__(self, spec, e=None):
+ super().__init__(spec, e)
util.set_attr(self, self.env_spec, ['unity'])
worker_id = int(f'{os.getpid()}{self.e+int(ps.unique_id())}'[-4:])
+ seed = ps.get(spec, 'meta.random_seed')
+ # TODO update Unity ml-agents to use seed=seed below
self.u_env = UnityEnvironment(file_name=get_env_path(self.name), worker_id=worker_id)
self.patch_gym_spaces(self.u_env)
self._set_attr_from_u_env(self.u_env)
assert self.max_t is not None
- if env_space is None: # singleton mode
- pass
- else:
- self.space_init(env_space)
-
logger.info(util.self_desc(self))
def patch_gym_spaces(self, u_env):
@@ -108,13 +106,13 @@ def _get_brain(self, u_env, a):
def _check_u_brain_to_agent(self):
'''Check the size match between unity brain and agent'''
u_brain_num = self.u_env.number_brains
- agent_num = len(self.body_e)
+ agent_num = 1 # TODO rework unity outdated
assert u_brain_num == agent_num, f'There must be a Unity brain for each agent. e:{self.e}, brain: {u_brain_num} != agent: {agent_num}.'
def _check_u_agent_to_body(self, env_info_a, a):
'''Check the size match between unity agent and body'''
u_agent_num = len(env_info_a.agents)
- body_num = util.count_nonan(self.body_e[a])
+ body_num = 1 # rework unity
assert u_agent_num == body_num, f'There must be a Unity agent for each body; a:{a}, e:{self.e}, agent_num: {u_agent_num} != body_num: {body_num}.'
def _get_env_info(self, env_info_dict, a):
@@ -123,71 +121,32 @@ def _get_env_info(self, env_info_dict, a):
env_info_a = env_info_dict[name_a]
return env_info_a
+ def seed(self, seed):
+ self.u_env.seed(seed)
+
@lab_api
def reset(self):
- _reward = np.nan
+ self.done = False
env_info_dict = self.u_env.reset(train_mode=(util.get_lab_mode() != 'dev'), config=self.env_spec.get('unity'))
- a, b = 0, 0 # default singleton aeb
+ a, b = 0, 0 # default singleton agent and body
env_info_a = self._get_env_info(env_info_dict, a)
state = env_info_a.states[b]
- self.done = done = False
- logger.debug(f'Env {self.e} reset reward: {_reward}, state: {state}, done: {done}')
- return _reward, state, done
+ return state
@lab_api
def step(self, action):
env_info_dict = self.u_env.step(action)
- a, b = 0, 0 # default singleton aeb
+ a, b = 0, 0 # default singleton agent and body
env_info_a = self._get_env_info(env_info_dict, a)
- reward = env_info_a.rewards[b] * self.reward_scale
state = env_info_a.states[b]
+ reward = env_info_a.rewards[b]
+ reward = try_scale_reward(self, reward)
done = env_info_a.local_done[b]
- self.done = done = done or self.clock.t > self.max_t
- logger.debug(f'Env {self.e} step reward: {reward}, state: {state}, done: {done}')
- return reward, state, done
+ if not self.is_venv and self.clock.t > self.max_t:
+ done = True
+ self.done = done
+ return state, reward, done, env_info_a
@lab_api
def close(self):
self.u_env.close()
-
- # NOTE optional extension for multi-agent-env
-
- @lab_api
- def space_init(self, env_space):
- '''Post init override for space env. Note that aeb is already correct from __init__'''
- self.env_space = env_space
- self.aeb_space = env_space.aeb_space
- self.observation_spaces = [self.observation_space]
- self.action_spaces = [self.action_space]
-
- @lab_api
- def space_reset(self):
- self._check_u_brain_to_agent()
- self.done = False
- env_info_dict = self.u_env.reset(train_mode=(util.get_lab_mode() != 'dev'), config=self.env_spec.get('unity'))
- _reward_e, state_e, done_e = self.env_space.aeb_space.init_data_s(ENV_DATA_NAMES, e=self.e)
- for (a, b), body in util.ndenumerate_nonan(self.body_e):
- env_info_a = self._get_env_info(env_info_dict, a)
- self._check_u_agent_to_body(env_info_a, a)
- state = env_info_a.states[b]
- state_e[(a, b)] = state
- done_e[(a, b)] = self.done
- logger.debug(f'Env {self.e} reset reward_e: {_reward_e}, state_e: {state_e}, done_e: {done_e}')
- return _reward_e, state_e, done_e
-
- @lab_api
- def space_step(self, action_e):
- # TODO implement clock_speed: step only if self.clock.to_step()
- if self.done:
- return self.space_reset()
- action_e = util.nanflatten(action_e)
- env_info_dict = self.u_env.step(action_e)
- reward_e, state_e, done_e = self.env_space.aeb_space.init_data_s(ENV_DATA_NAMES, e=self.e)
- for (a, b), body in util.ndenumerate_nonan(self.body_e):
- env_info_a = self._get_env_info(env_info_dict, a)
- reward_e[(a, b)] = env_info_a.rewards[b] * self.reward_scale
- state_e[(a, b)] = env_info_a.states[b]
- done_e[(a, b)] = env_info_a.local_done[b]
- self.done = (util.nonan_all(done_e) or self.clock.t > self.max_t)
- logger.debug(f'Env {self.e} step reward_e: {reward_e}, state_e: {state_e}, done_e: {done_e}')
- return reward_e, state_e, done_e
diff --git a/slm_lab/env/vec_env.py b/slm_lab/env/vec_env.py
new file mode 100644
index 000000000..86a1aac84
--- /dev/null
+++ b/slm_lab/env/vec_env.py
@@ -0,0 +1,499 @@
+# Wrappers for parallel vector environments.
+# Adapted from OpenAI Baselines (MIT) https://github.com/openai/baselines/tree/master/baselines/common/vec_env
+from abc import ABC, abstractmethod
+from collections import OrderedDict
+from functools import partial
+from gym import spaces
+from slm_lab.env.wrapper import make_gym_env, try_scale_reward
+from slm_lab.lib import logger
+import contextlib
+import ctypes
+import gym
+import numpy as np
+import os
+import torch.multiprocessing as mp
+
+
+_NP_TO_CT = {
+ np.float32: ctypes.c_float,
+ np.int32: ctypes.c_int32,
+ np.int8: ctypes.c_int8,
+ np.uint8: ctypes.c_char,
+ np.bool: ctypes.c_bool,
+}
+
+
+# helper methods
+
+
+@contextlib.contextmanager
+def clear_mpi_env_vars():
+ '''
+ from mpi4py import MPI will call MPI_Init by default. If the child process has MPI environment variables, MPI will think that the child process is an MPI process just like the parent and do bad things such as hang.
+ This context manager is a hacky way to clear those environment variables temporarily such as when we are starting multiprocessing Processes.
+ '''
+ removed_environment = {}
+ for k, v in list(os.environ.items()):
+ for prefix in ['OMPI_', 'PMI_']:
+ if k.startswith(prefix):
+ removed_environment[k] = v
+ del os.environ[k]
+ try:
+ yield
+ finally:
+ os.environ.update(removed_environment)
+
+
+def copy_obs_dict(obs):
+ '''Deep-copy an observation dict.'''
+ return {k: np.copy(v) for k, v in obs.items()}
+
+
+def dict_to_obs(obs_dict):
+ '''Convert an observation dict into a raw array if the original observation space was not a Dict space.'''
+ if set(obs_dict.keys()) == {None}:
+ return obs_dict[None]
+ return obs_dict
+
+
+def obs_to_dict(obs):
+ '''Convert an observation into a dict.'''
+ if isinstance(obs, dict):
+ return obs
+ return {None: obs}
+
+
+def obs_space_info(obs_space):
+ '''
+ Get dict-structured information about a gym.Space.
+ @returns (keys, shapes, dtypes)
+ - keys: a list of dict keys.
+ - shapes: a dict mapping keys to shapes.
+ - dtypes: a dict mapping keys to dtypes.
+ '''
+ if isinstance(obs_space, gym.spaces.Dict):
+ assert isinstance(obs_space.spaces, OrderedDict)
+ subspaces = obs_space.spaces
+ else:
+ subspaces = {None: obs_space}
+ keys = []
+ shapes = {}
+ dtypes = {}
+ for key, box in subspaces.items():
+ keys.append(key)
+ shapes[key] = box.shape
+ dtypes[key] = box.dtype
+ return keys, shapes, dtypes
+
+
+def tile_images(img_nhwc):
+ '''
+ Tile N images into a rectangular grid for rendering
+
+ @param img_nhwc list or array of images, with shape (batch, h, w, c)
+ @returns bigim_HWc ndarray with shape (h',w',c)
+ '''
+ img_nhwc = np.asarray(img_nhwc)
+ N, h, w, c = img_nhwc.shape
+ H = int(np.ceil(np.sqrt(N)))
+ W = int(np.ceil(float(N) / H))
+ img_nhwc = np.array(list(img_nhwc) + [img_nhwc[0] * 0 for _ in range(N, H * W)])
+ img_HWhwc = img_nhwc.reshape(H, W, h, w, c)
+ img_HhWwc = img_HWhwc.transpose(0, 2, 1, 3, 4)
+ img_Hh_Ww_c = img_HhWwc.reshape(H * h, W * w, c)
+ return img_Hh_Ww_c
+
+
+def subproc_worker(
+ pipe, parent_pipe, env_fn_wrapper,
+ obs_bufs, obs_shapes, obs_dtypes, keys):
+ '''
+ Control a single environment instance using IPC and shared memory. Used by ShmemVecEnv.
+ '''
+ def _write_obs(maybe_dict_obs):
+ flatdict = obs_to_dict(maybe_dict_obs)
+ for k in keys:
+ dst = obs_bufs[k].get_obj()
+ dst_np = np.frombuffer(dst, dtype=obs_dtypes[k]).reshape(obs_shapes[k])
+ np.copyto(dst_np, flatdict[k])
+
+ env = env_fn_wrapper.x()
+ parent_pipe.close()
+ try:
+ while True:
+ cmd, data = pipe.recv()
+ if cmd == 'reset':
+ pipe.send(_write_obs(env.reset()))
+ elif cmd == 'step':
+ obs, reward, done, info = env.step(data)
+ if done:
+ obs = env.reset()
+ pipe.send((_write_obs(obs), reward, done, info))
+ elif cmd == 'render':
+ pipe.send(env.render(mode='rgb_array'))
+ elif cmd == 'close':
+ pipe.send(None)
+ break
+ else:
+ raise RuntimeError(f'Got unrecognized cmd {cmd}')
+ except KeyboardInterrupt:
+ logger.exception('ShmemVecEnv worker: got KeyboardInterrupt')
+ finally:
+ env.close()
+
+
+# vector environment wrappers
+
+
+class CloudpickleWrapper(object):
+ '''
+ Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
+ '''
+
+ def __init__(self, x):
+ self.x = x
+
+ def __getstate__(self):
+ import cloudpickle
+ return cloudpickle.dumps(self.x)
+
+ def __setstate__(self, ob):
+ import pickle
+ self.x = pickle.loads(ob)
+
+
+class VecEnv(ABC):
+ '''
+ An abstract asynchronous, vectorized environment.
+ Used to batch data from multiple copies of an environment, so that each observation becomes an batch of observations, and expected action is a batch of actions to be applied per-environment.
+ '''
+ closed = False
+ viewer = None
+
+ metadata = {
+ 'render.modes': ['human', 'rgb_array']
+ }
+
+ def __init__(self, num_envs, observation_space, action_space):
+ self.num_envs = num_envs
+ self.observation_space = observation_space
+ self.action_space = action_space
+
+ @abstractmethod
+ def reset(self):
+ '''
+ Reset all the environments and return an array of observations, or a dict of observation arrays.
+
+ If step_async is still doing work, that work will be cancelled and step_wait() should not be called until step_async() is invoked again.
+ '''
+ pass
+
+ @abstractmethod
+ def step_async(self, actions):
+ '''
+ Tell all the environments to start taking a step with the given actions.
+ Call step_wait() to get the results of the step.
+
+ You should not call this if a step_async run is already pending.
+ '''
+ pass
+
+ @abstractmethod
+ def step_wait(self):
+ '''
+ Wait for the step taken with step_async().
+
+ @returns (obs, rews, dones, infos)
+ - obs: an array of observations, or a dict of arrays of observations.
+ - rews: an array of rewards
+ - dones: an array of 'episode done' booleans
+ - infos: a sequence of info objects
+ '''
+ pass
+
+ def close_extras(self):
+ '''
+ Clean up the extra resources, beyond what's in this base class.
+ Only runs when not self.closed.
+ '''
+ pass
+
+ def close(self):
+ if self.closed:
+ return
+ if self.viewer is not None:
+ self.viewer.close()
+ self.close_extras()
+ self.closed = True
+
+ def step(self, actions):
+ '''
+ Step the environments synchronously.
+
+ This is available for backwards compatibility.
+ '''
+ self.step_async(actions)
+ return self.step_wait()
+
+ def render(self, mode='human'):
+ imgs = self.get_images()
+ bigimg = tile_images(imgs)
+ if mode == 'human':
+ self.get_viewer().imshow(bigimg)
+ return self.get_viewer().isopen
+ elif mode == 'rgb_array':
+ return bigimg
+ else:
+ raise NotImplementedError
+
+ def get_images(self):
+ '''Return RGB images from each environment'''
+ raise NotImplementedError
+
+ @property
+ def unwrapped(self):
+ if isinstance(self, VecEnvWrapper):
+ return self.venv.unwrapped
+ else:
+ return self
+
+ def get_viewer(self):
+ if self.viewer is None:
+ from gym.envs.classic_control import rendering
+ self.viewer = rendering.SimpleImageViewer()
+ return self.viewer
+
+
+class DummyVecEnv(VecEnv):
+ '''
+ VecEnv that does runs multiple environments sequentially, that is, the step and reset commands are send to one environment at a time.
+ Useful when debugging and when num_envs == 1 (in the latter case, avoids communication overhead)
+ '''
+
+ def __init__(self, env_fns):
+ '''
+ @param env_fns iterable of functions that build environments
+ '''
+ self.envs = [fn() for fn in env_fns]
+ env = self.envs[0]
+ VecEnv.__init__(self, len(env_fns), env.observation_space, env.action_space)
+ obs_space = env.observation_space
+ self.keys, shapes, dtypes = obs_space_info(obs_space)
+
+ self.buf_obs = {k: np.zeros((self.num_envs,) + tuple(shapes[k]), dtype=dtypes[k]) for k in self.keys}
+ self.buf_dones = np.zeros((self.num_envs,), dtype=np.bool)
+ self.buf_rews = np.zeros((self.num_envs,), dtype=np.float32)
+ self.buf_infos = [{} for _ in range(self.num_envs)]
+ self.actions = None
+ self.spec = self.envs[0].spec
+
+ def step_async(self, actions):
+ listify = True
+ try:
+ if len(actions) == self.num_envs:
+ listify = False
+ except TypeError:
+ pass
+
+ if not listify:
+ self.actions = actions
+ else:
+ assert self.num_envs == 1, f'actions {actions} is either not a list or has a wrong size - cannot match to {self.num_envs} environments'
+ self.actions = [actions]
+
+ def step_wait(self):
+ for e in range(self.num_envs):
+ action = self.actions[e]
+
+ obs, self.buf_rews[e], self.buf_dones[e], self.buf_infos[e] = self.envs[e].step(action)
+ if self.buf_dones[e]:
+ obs = self.envs[e].reset()
+ self._save_obs(e, obs)
+ return (self._obs_from_buf(), np.copy(self.buf_rews), np.copy(self.buf_dones),
+ self.buf_infos.copy())
+
+ def reset(self):
+ for e in range(self.num_envs):
+ obs = self.envs[e].reset()
+ self._save_obs(e, obs)
+ return self._obs_from_buf()
+
+ def _save_obs(self, e, obs):
+ for k in self.keys:
+ if k is None:
+ self.buf_obs[k][e] = obs
+ else:
+ self.buf_obs[k][e] = obs[k]
+
+ def _obs_from_buf(self):
+ return dict_to_obs(copy_obs_dict(self.buf_obs))
+
+ def get_images(self):
+ return [env.render(mode='rgb_array') for env in self.envs]
+
+ def render(self, mode='human'):
+ if self.num_envs == 1:
+ return self.envs[0].render(mode=mode)
+ else:
+ return super().render(mode=mode)
+
+
+class VecEnvWrapper(VecEnv):
+ '''
+ An environment wrapper that applies to an entire batch of environments at once.
+ '''
+
+ def __init__(self, venv, observation_space=None, action_space=None):
+ self.venv = venv
+ observation_space = observation_space or venv.observation_space
+ action_space = action_space or venv.action_space
+ VecEnv.__init__(self, venv.num_envs, observation_space, action_space)
+
+ def step_async(self, actions):
+ self.venv.step_async(actions)
+
+ @abstractmethod
+ def reset(self):
+ pass
+
+ @abstractmethod
+ def step_wait(self):
+ pass
+
+ def close(self):
+ return self.venv.close()
+
+ def render(self, mode='human'):
+ return self.venv.render(mode=mode)
+
+ def get_images(self):
+ return self.venv.get_images()
+
+
+class ShmemVecEnv(VecEnv):
+ '''
+ Optimized version of SubprocVecEnv that uses shared variables to communicate observations.
+ '''
+
+ def __init__(self, env_fns, context='spawn'):
+ ctx = mp.get_context(context)
+ dummy = env_fns[0]()
+ observation_space, action_space = dummy.observation_space, dummy.action_space
+ self.spec = dummy.spec
+ dummy.close()
+ del dummy
+ VecEnv.__init__(self, len(env_fns), observation_space, action_space)
+ self.obs_keys, self.obs_shapes, self.obs_dtypes = obs_space_info(observation_space)
+ self.obs_bufs = [
+ {k: ctx.Array(_NP_TO_CT[self.obs_dtypes[k].type], int(np.prod(self.obs_shapes[k]))) for k in self.obs_keys}
+ for _ in env_fns]
+ self.parent_pipes = []
+ self.procs = []
+ with clear_mpi_env_vars():
+ for env_fn, obs_buf in zip(env_fns, self.obs_bufs):
+ wrapped_fn = CloudpickleWrapper(env_fn)
+ parent_pipe, child_pipe = ctx.Pipe()
+ proc = ctx.Process(
+ target=subproc_worker,
+ args=(child_pipe, parent_pipe, wrapped_fn, obs_buf, self.obs_shapes, self.obs_dtypes, self.obs_keys))
+ proc.daemon = True
+ self.procs.append(proc)
+ self.parent_pipes.append(parent_pipe)
+ proc.start()
+ child_pipe.close()
+ self.waiting_step = False
+ self.viewer = None
+
+ def reset(self):
+ if self.waiting_step:
+ logger.warning('Called reset() while waiting for the step to complete')
+ self.step_wait()
+ for pipe in self.parent_pipes:
+ pipe.send(('reset', None))
+ return self._decode_obses([pipe.recv() for pipe in self.parent_pipes])
+
+ def step_async(self, actions):
+ assert len(actions) == len(self.parent_pipes)
+ for pipe, act in zip(self.parent_pipes, actions):
+ pipe.send(('step', act))
+
+ def step_wait(self):
+ outs = [pipe.recv() for pipe in self.parent_pipes]
+ obs, rews, dones, infos = zip(*outs)
+ return self._decode_obses(obs), np.array(rews), np.array(dones), infos
+
+ def close_extras(self):
+ if self.waiting_step:
+ self.step_wait()
+ for pipe in self.parent_pipes:
+ pipe.send(('close', None))
+ for pipe in self.parent_pipes:
+ pipe.recv()
+ pipe.close()
+ for proc in self.procs:
+ proc.join()
+
+ def get_images(self, mode='human'):
+ for pipe in self.parent_pipes:
+ pipe.send(('render', None))
+ return [pipe.recv() for pipe in self.parent_pipes]
+
+ def _decode_obses(self, obs):
+ result = {}
+ for k in self.obs_keys:
+ bufs = [b[k] for b in self.obs_bufs]
+ o = [np.frombuffer(b.get_obj(), dtype=self.obs_dtypes[k]).reshape(self.obs_shapes[k]) for b in bufs]
+ result[k] = np.array(o)
+ return dict_to_obs(result)
+
+
+class VecFrameStack(VecEnvWrapper):
+ '''Frame stack wrapper for vector environment'''
+
+ def __init__(self, venv, frame_op, frame_op_len, reward_scale=None):
+ self.venv = venv
+ assert frame_op == 'concat', 'VecFrameStack only supports concat frame_op for now'
+ self.frame_op = frame_op
+ self.frame_op_len = frame_op_len
+ self.reward_scale = reward_scale
+ self.sign_reward = self.reward_scale == 'sign'
+ self.spec = venv.spec
+ wos = venv.observation_space # wrapped ob space
+ self.shape_dim0 = wos.shape[0]
+ low = np.repeat(wos.low, self.frame_op_len, axis=0)
+ high = np.repeat(wos.high, self.frame_op_len, axis=0)
+ self.stackedobs = np.zeros((venv.num_envs,) + low.shape, low.dtype)
+ observation_space = spaces.Box(low=low, high=high, dtype=venv.observation_space.dtype)
+ VecEnvWrapper.__init__(self, venv, observation_space=observation_space)
+
+ def step_wait(self):
+ obs, rews, news, infos = self.venv.step_wait()
+ self.stackedobs[:, :-self.shape_dim0] = self.stackedobs[:, self.shape_dim0:]
+ for (i, new) in enumerate(news):
+ if new:
+ self.stackedobs[i] = 0
+ self.stackedobs[:, -self.shape_dim0:] = obs
+ rews = try_scale_reward(self, rews)
+ return self.stackedobs.copy(), rews, news, infos
+
+ def reset(self):
+ obs = self.venv.reset()
+ self.stackedobs[...] = 0
+ self.stackedobs[:, -self.shape_dim0:] = obs
+ return self.stackedobs.copy()
+
+
+def make_gym_venv(name, num_envs=4, seed=0, frame_op=None, frame_op_len=None, reward_scale=None, normalize_state=False):
+ '''General method to create any parallel vectorized Gym env; auto wraps Atari'''
+ venv = [
+ # don't concat frame or clip reward on individual env; do that at vector level
+ partial(make_gym_env, name, seed + i, frame_op=None, frame_op_len=None, reward_scale=None, normalize_state=normalize_state)
+ for i in range(num_envs)
+ ]
+ if len(venv) > 1:
+ venv = ShmemVecEnv(venv, context='fork')
+ else:
+ venv = DummyVecEnv(venv)
+ if frame_op is not None:
+ venv = VecFrameStack(venv, frame_op, frame_op_len, reward_scale)
+ return venv
diff --git a/slm_lab/env/vizdoom/vizdoom_env.py b/slm_lab/env/vizdoom/vizdoom_env.py
index 712881e58..9445227aa 100644
--- a/slm_lab/env/vizdoom/vizdoom_env.py
+++ b/slm_lab/env/vizdoom/vizdoom_env.py
@@ -1,9 +1,10 @@
# inspired by nsavinov/gym-vizdoom and ppaquette/gym-doom
-import numpy as np
-import gym.spaces as spaces
from gym import Env
from gym.envs.classic_control import rendering
+from slm_lab.lib import util
from vizdoom import DoomGame
+import gym.spaces as spaces
+import numpy as np
class VizDoomEnv(Env):
@@ -13,9 +14,9 @@ class VizDoomEnv(Env):
metadata = {'render.modes': ['human', 'rgb_array']}
def __init__(self, cfg_name, repeat=1):
- super(VizDoomEnv, self).__init__()
+ super().__init__()
self.game = DoomGame()
- self.game.load_config('./slm_lab/env/vizdoom/cfgs/' + cfg_name + '.cfg')
+ self.game.load_config(f'./slm_lab/env/vizdoom/cfgs/{cfg_name}.cfg')
self._viewer = None
self.repeat = 1
# TODO In future, need to update action to handle (continuous) DELTA buttons using gym's Box space
@@ -47,7 +48,6 @@ def step(self, action):
return observation, reward, done, info
def reset(self):
- # self.seed(seed)
self.game.new_episode()
return self.game.get_state().screen_buffer
@@ -69,7 +69,7 @@ def render(self, mode='human', close=False):
elif mode is 'human':
if self._viewer is None:
self._viewer = rendering.SimpleImageViewer()
- self._viewer.imshow(img.transpose(1, 2, 0))
+ self._viewer.imshow(util.to_opencv_image(img))
def _get_game_variables(self, state_variables):
info = {}
diff --git a/slm_lab/env/wrapper.py b/slm_lab/env/wrapper.py
index 9a88b4707..62c8388ef 100644
--- a/slm_lab/env/wrapper.py
+++ b/slm_lab/env/wrapper.py
@@ -1,6 +1,6 @@
-# Module of custom Atari wrappers modified from OpenAI baselines (MIT)
-# these don't come with Gym but are crucial for Atari to work
-# https://github.com/openai/baselines/blob/master/baselines/common/atari_wrappers.py
+# Generic env wrappers, including for Atari/images
+# They don't come with Gym but are crucial for Atari to work
+# Many were adapted from OpenAI Baselines (MIT) https://github.com/openai/baselines/blob/master/baselines/common/atari_wrappers.py
from collections import deque
from gym import spaces
from slm_lab.lib import util
@@ -8,9 +8,23 @@
import numpy as np
+def try_scale_reward(cls, reward):
+ '''Env class to scale reward and set raw_reward'''
+ if util.in_eval_lab_modes(): # only trigger on training
+ return reward
+ if cls.reward_scale is not None:
+ cls.raw_reward = reward
+ if cls.sign_reward:
+ reward = np.sign(reward)
+ else:
+ reward *= cls.reward_scale
+ return reward
+
+
class NoopResetEnv(gym.Wrapper):
def __init__(self, env, noop_max=30):
- '''Sample initial states by taking random number of no-ops on reset.
+ '''
+ Sample initial states by taking random number of no-ops on reset.
No-op is assumed to be action 0.
'''
gym.Wrapper.__init__(self, env)
@@ -25,7 +39,7 @@ def reset(self, **kwargs):
if self.override_num_noops is not None:
noops = self.override_num_noops
else:
- noops = self.unwrapped.np_random.randint(1, self.noop_max + 1) # pylint: disable=E1101
+ noops = self.unwrapped.np_random.randint(1, self.noop_max + 1)
assert noops > 0
obs = None
for _ in range(noops):
@@ -61,7 +75,8 @@ def step(self, ac):
class EpisodicLifeEnv(gym.Wrapper):
def __init__(self, env):
- '''Make end-of-life == end-of-episode, but only reset on true game over.
+ '''
+ Make end-of-life == end-of-episode, but only reset on true game over.
Done by DeepMind for the DQN and co. since it helps value estimation.
'''
gym.Wrapper.__init__(self, env)
@@ -83,7 +98,8 @@ def step(self, action):
return obs, reward, done, info
def reset(self, **kwargs):
- '''Reset only when lives are exhausted.
+ '''
+ Reset only when lives are exhausted.
This way all states are still reachable even though lives are episodic,
and the learner need not know about any of this behind-the-scenes.
'''
@@ -97,9 +113,7 @@ def reset(self, **kwargs):
class MaxAndSkipEnv(gym.Wrapper):
- '''
- OpenAI max-skipframe wrapper from baselines (not available from gym itself)
- '''
+ '''OpenAI max-skipframe wrapper used for a NoFrameskip env'''
def __init__(self, env, skip=4):
'''Return only every `skip`-th frame'''
@@ -129,19 +143,54 @@ def reset(self, **kwargs):
return self.env.reset(**kwargs)
-class ClipRewardEnv(gym.RewardWrapper):
+class ScaleRewardEnv(gym.RewardWrapper):
+ def __init__(self, env, reward_scale):
+ '''
+ Rescale reward
+ @param (str,float):reward_scale If 'sign', use np.sign, else multiply with the specified float scale
+ '''
+ gym.Wrapper.__init__(self, env)
+ self.reward_scale = reward_scale
+ self.sign_reward = self.reward_scale == 'sign'
+
def reward(self, reward):
- '''Atari reward, to -1, 0 or +1. Not usually used as SLM Lab memory class does the clipping'''
- return np.sign(reward)
+ '''Set self.raw_reward for retrieving the original reward'''
+ return try_scale_reward(self, reward)
+
+
+class NormalizeStateEnv(gym.ObservationWrapper):
+ def __init__(self, env=None):
+ '''
+ Normalize observations on-line
+ Adapted from https://github.com/ikostrikov/pytorch-a3c/blob/e898f7514a03de73a2bf01e7b0f17a6f93963389/envs.py (MIT)
+ '''
+ super().__init__(env)
+ self.state_mean = 0
+ self.state_std = 0
+ self.alpha = 0.9999
+ self.num_steps = 0
+ def _observation(self, observation):
+ self.num_steps += 1
+ self.state_mean = self.state_mean * self.alpha + \
+ observation.mean() * (1 - self.alpha)
+ self.state_std = self.state_std * self.alpha + \
+ observation.std() * (1 - self.alpha)
-class TransformImage(gym.ObservationWrapper):
+ unbiased_mean = self.state_mean / (1 - pow(self.alpha, self.num_steps))
+ unbiased_std = self.state_std / (1 - pow(self.alpha, self.num_steps))
+
+ return (observation - unbiased_mean) / (unbiased_std + 1e-8)
+
+
+class PreprocessImage(gym.ObservationWrapper):
def __init__(self, env):
'''
Apply image preprocessing:
- grayscale
- downsize to 84x84
- - transform shape from w,h,c to PyTorch format c,h,w '''
+ - transpose shape from h,w,c to PyTorch format c,h,w
+ '''
gym.ObservationWrapper.__init__(self, env)
self.width = 84
self.height = 84
@@ -149,24 +198,29 @@ def __init__(self, env):
low=0, high=255, shape=(1, self.width, self.height), dtype=np.uint8)
def observation(self, frame):
- frame = util.transform_image(frame, method='openai')
- frame = np.transpose(frame) # reverses all axes
- frame = np.expand_dims(frame, 0)
- return frame
+ return util.preprocess_image(frame)
class LazyFrames(object):
- def __init__(self, frames):
- '''This object ensures that common frames between the observations are only stored once.
+ def __init__(self, frames, frame_op='stack'):
+ '''
+ Wrapper to stack or concat frames by keeping unique soft reference insted of copies of data.
+ So this should only be converted to numpy array before being passed to the model.
It exists purely to optimize memory usage which can be huge for DQN's 1M frames replay buffers.
- This object should only be converted to numpy array before being passed to the model.
+ @param str:frame_op 'stack' or 'concat'
'''
self._frames = frames
self._out = None
+ if frame_op == 'stack':
+ self._frame_op = np.stack
+ elif frame_op == 'concat':
+ self._frame_op = np.concatenate
+ else:
+ raise ValueError('frame_op not recognized for LazyFrames. Choose from "stack", "concat"')
def _force(self):
if self._out is None:
- self._out = np.concatenate(self._frames, axis=0)
+ self._out = self._frame_op(self._frames, axis=0)
self._frames = None
return self._out
@@ -182,31 +236,48 @@ def __len__(self):
def __getitem__(self, i):
return self._force()[i]
+ def astype(self, dtype):
+ '''To prevent state.astype(np.float16) breaking on LazyFrames'''
+ return self
+
class FrameStack(gym.Wrapper):
- def __init__(self, env, k):
- '''Stack k last frames. Returns lazy array, which is much more memory efficient.'''
+ def __init__(self, env, frame_op, frame_op_len):
+ '''
+ Stack/concat last k frames. Returns lazy array, which is much more memory efficient.
+ @param str:frame_op 'concat' or 'stack'. Note: use concat for image since the shape is (1, 84, 84) concat-able.
+ @param int:frame_op_len The number of frames to keep for frame_op
+ '''
gym.Wrapper.__init__(self, env)
- self.k = k
- self.frames = deque([], maxlen=k)
- shp = env.observation_space.shape
+ self.frame_op = frame_op
+ self.frame_op_len = frame_op_len
+ self.frames = deque([], maxlen=self.frame_op_len)
+ old_shape = env.observation_space.shape
+ if self.frame_op == 'concat': # concat multiplies first dim
+ shape = (self.frame_op_len * old_shape[0],) + old_shape[1:]
+ elif self.frame_op == 'stack': # stack creates new dim
+ shape = (self.frame_op_len,) + old_shape
+ else:
+ raise ValueError('frame_op not recognized for FrameStack. Choose from "stack", "concat".')
self.observation_space = spaces.Box(
- low=0, high=255, shape=(k, ) + shp[1:], dtype=env.observation_space.dtype)
+ low=np.min(env.observation_space.low),
+ high=np.max(env.observation_space.high),
+ shape=shape, dtype=env.observation_space.dtype)
def reset(self):
ob = self.env.reset()
- for _ in range(self.k):
- self.frames.append(ob)
+ for _ in range(self.frame_op_len):
+ self.frames.append(ob.astype(np.float16))
return self._get_ob()
def step(self, action):
ob, reward, done, info = self.env.step(action)
- self.frames.append(ob)
+ self.frames.append(ob.astype(np.float16))
return self._get_ob(), reward, done, info
def _get_ob(self):
- assert len(self.frames) == self.k
- return LazyFrames(list(self.frames))
+ assert len(self.frames) == self.frame_op_len
+ return LazyFrames(list(self.frames), self.frame_op)
def wrap_atari(env):
@@ -217,15 +288,39 @@ def wrap_atari(env):
return env
-def wrap_deepmind(env, episode_life=True, clip_rewards=True, stack_len=None):
+def wrap_deepmind(env, episode_life=True, stack_len=None):
'''Wrap Atari environment DeepMind-style'''
if episode_life:
env = EpisodicLifeEnv(env)
if 'FIRE' in env.unwrapped.get_action_meanings():
env = FireResetEnv(env)
- if clip_rewards:
- env = ClipRewardEnv(env)
- env = TransformImage(env)
- if stack_len is not None:
- env = FrameStack(env, stack_len)
+ env = PreprocessImage(env)
+ if stack_len is not None: # use concat for image (1, 84, 84)
+ env = FrameStack(env, 'concat', stack_len)
+ return env
+
+
+def make_gym_env(name, seed=None, frame_op=None, frame_op_len=None, reward_scale=None, normalize_state=False):
+ '''General method to create any Gym env; auto wraps Atari'''
+ env = gym.make(name)
+ if seed is not None:
+ env.seed(seed)
+ if 'NoFrameskip' in env.spec.id: # Atari
+ env = wrap_atari(env)
+ # no reward clipping to allow monitoring; Atari memory clips it
+ episode_life = not util.in_eval_lab_modes()
+ env = wrap_deepmind(env, episode_life, frame_op_len)
+ elif len(env.observation_space.shape) == 3: # image-state env
+ env = PreprocessImage(env)
+ if normalize_state:
+ env = NormalizeStateEnv(env)
+ if frame_op_len is not None: # use concat for image (1, 84, 84)
+ env = FrameStack(env, 'concat', frame_op_len)
+ else: # vector-state env
+ if normalize_state:
+ env = NormalizeStateEnv(env)
+ if frame_op is not None:
+ env = FrameStack(env, frame_op, frame_op_len)
+ if reward_scale is not None:
+ env = ScaleRewardEnv(env, reward_scale)
return env
diff --git a/slm_lab/experiment/__init__.py b/slm_lab/experiment/__init__.py
index 3ff5d45fe..a9d8b9139 100644
--- a/slm_lab/experiment/__init__.py
+++ b/slm_lab/experiment/__init__.py
@@ -1,4 +1,2 @@
-'''
-The experiment module
-Handles experimentation logic: control, design, monitoring, analysis, evolution
-'''
+# The experiment module
+# Handles experimentation logic: control, analysis
diff --git a/slm_lab/experiment/analysis.py b/slm_lab/experiment/analysis.py
index 36ade7940..93c20f27a 100644
--- a/slm_lab/experiment/analysis.py
+++ b/slm_lab/experiment/analysis.py
@@ -1,563 +1,268 @@
-'''
-The analysis module
-Handles the analyses of the info and data space for experiment evaluation and design.
-'''
-from slm_lab.agent import AGENT_DATA_NAMES
-from slm_lab.env import ENV_DATA_NAMES
-from slm_lab.lib import logger, math_util, util, viz
-from slm_lab.spec import spec_util
+from slm_lab.lib import logger, util, viz
+from slm_lab.spec import random_baseline
import numpy as np
import os
import pandas as pd
import pydash as ps
-import regex as re
import shutil
+import torch
+
+
+NUM_EVAL = 4
+METRICS_COLS = [
+ 'strength', 'max_strength', 'final_strength',
+ 'sample_efficiency', 'training_efficiency',
+ 'stability', 'consistency',
+]
-FITNESS_COLS = ['strength', 'speed', 'stability', 'consistency']
-# TODO improve to make it work with any reward mean
-FITNESS_STD = util.read('slm_lab/spec/_fitness_std.json')
-NOISE_WINDOW = 0.05
-NORM_ORDER = 1 # use L1 norm in fitness vector norm
-MA_WINDOW = 100
logger = logger.get_logger(__name__)
-'''
-Fitness analysis
-'''
+# methods to generate returns (total rewards)
-def calc_strength_sr(aeb_df, rand_reward, std_reward):
- '''
- Calculate strength for each reward as
- strength = (reward - rand_reward) / (std_reward - rand_reward)
- '''
- return (aeb_df['reward'] - rand_reward) / (std_reward - rand_reward)
+def gen_return(agent, env):
+ '''Generate return for an agent and an env in eval mode'''
+ state = env.reset()
+ done = False
+ total_reward = 0
+ while not done:
+ action = agent.act(state)
+ state, reward, done, info = env.step(action)
+ total_reward += reward
+ return total_reward
-def calc_strength(aeb_df):
- '''
- Strength of an agent in fitness is its maximum strength_ma. Moving average is used to denoise signal.
- For an agent total reward at a time, calculate strength by normalizing it with a given baseline rand_reward and solution std_reward, i.e.
- strength = (reward - rand_reward) / (std_reward - rand_reward)
-
- **Properties:**
- - random agent has strength 0, standard agent has strength 1.
- - strength is standardized to be independent of the actual sign and scale of raw reward
- - scales relative to std_reward: if an agent achieve x2 std_reward, the strength is x2, and so on.
- This allows for standard comparison between agents on the same problem using an intuitive measurement of strength. With proper scaling by a difficulty factor, we can compare across problems of different difficulties.
- '''
- return aeb_df['strength_ma'].max()
+def gen_avg_return(agent, env, num_eval=NUM_EVAL):
+ '''Generate average return for agent and an env'''
+ with util.ctx_lab_mode('eval'): # enter eval context
+ agent.algorithm.update() # set explore_var etc. to end_val under ctx
+ with torch.no_grad():
+ returns = [gen_return(agent, env) for i in range(num_eval)]
+ # exit eval context, restore variables simply by updating
+ agent.algorithm.update()
+ return np.mean(returns)
+
+# metrics calculation methods
-def calc_speed(aeb_df, std_timestep):
+def calc_strength(mean_returns, mean_rand_returns):
'''
- Find the maximum strength_ma, and the time to first reach it. Then the strength/time divided by the standard std_strength/std_timestep is speed, i.e.
- speed = (max_strength_ma / timestep_to_first_reach) / (std_strength / std_timestep)
- **Properties:**
- - random agent has speed 0, standard agent has speed 1.
- - if both agents reach the same max strength_ma, and one reaches it in half the timesteps, it is twice as fast.
- - speed is standardized regardless of the scaling of absolute timesteps, or even the max strength attained
- This allows an intuitive measurement of learning speed and the standard comparison between agents on the same problem.
+ Calculate strength for metric
+ str &= \frac{1}{N} \sum_{i=0}^N \overline{R}_i - \overline{R}_{rand}
+ @param Series:mean_returns A series of mean returns from each checkpoint
+ @param float:mean_rand_returns The random baseline
+ @returns float:str, Series:local_strs
'''
- first_max_idx = aeb_df['strength_ma'].idxmax() # this returns the first max
- max_row = aeb_df.loc[first_max_idx]
- std_strength = 1.
- if max_row['total_t'] == 0: # especially for random agent
- speed = 0.
- else:
- speed = (max_row['strength_ma'] / max_row['total_t']) / (std_strength / std_timestep)
- return speed
+ local_strs = mean_returns - mean_rand_returns
+ str_ = local_strs.mean()
+ return str_, local_strs
-def calc_stability(aeb_df):
+def calc_efficiency(local_strs, ts):
'''
- Stability = fraction of monotonically increasing elements in the denoised series of strength_ma, or 0 if strength_ma is all <= 0.
- **Properties:**
- - stable agent has value 1, unstable agent < 1, and non-solution = 0.
- - uses strength_ma to be more robust to noise
- - sharp gain in strength is considered stable
- - monotonically increasing implies strength can keep growing and as long as it does not fall much, it is considered stable
+ Calculate efficiency for metric
+ e &= \frac{\sum_{i=0}^N \frac{1}{t_i} str_i}{\sum_{i=0}^N \frac{1}{t_i}}
+ @param Series:local_strs A series of local strengths
+ @param Series:ts A series of times units (frame or opt_steps)
+ @returns float:eff, Series:local_effs
'''
- if (aeb_df['strength_ma'].values <= 0.).all():
- stability = 0.
- else:
- mono_inc_sr = np.diff(aeb_df['strength_ma']) >= 0.
- stability = mono_inc_sr.sum() / mono_inc_sr.size
- return stability
+ eff = (local_strs / ts).sum() / local_strs.sum()
+ local_effs = (local_strs / ts).cumsum() / local_strs.cumsum()
+ return eff, local_effs
-def calc_consistency(aeb_fitness_df):
+def calc_stability(local_strs):
'''
- Calculate the consistency of trial by the fitness_vectors of its sessions:
- consistency = ratio of non-outlier vectors
- **Properties:**
- - outliers are calculated using MAD modified z-score
- - if all the fitness vectors are zero or all strength are zero, consistency = 0
- - works for all sorts of session fitness vectors, with the standard scale
- When an agent fails to achieve standard strength, it is meaningless to measure consistency or give false interpolation, so consistency is 0.
+ Calculate stability for metric
+ sta &= 1 - \left| \frac{\sum_{i=0}^{N-1} \min(str_{i+1} - str_i, 0)}{\sum_{i=0}^{N-1} str_i} \right|
+ @param Series:local_strs A series of local strengths
+ @returns float:sta, Series:local_stas
'''
- fitness_vecs = aeb_fitness_df.values
- if ~np.any(fitness_vecs) or ~np.any(aeb_fitness_df['strength']):
- # no consistency if vectors all 0
- consistency = 0.
- elif len(fitness_vecs) == 2:
- # if only has 2 vectors, check norm_diff
- diff_norm = np.linalg.norm(np.diff(fitness_vecs, axis=0), NORM_ORDER) / np.linalg.norm(np.ones(len(fitness_vecs[0])), NORM_ORDER)
- consistency = diff_norm <= NOISE_WINDOW
- else:
- is_outlier_arr = math_util.is_outlier(fitness_vecs)
- consistency = (~is_outlier_arr).sum() / len(is_outlier_arr)
- return consistency
-
-
-def calc_epi_reward_ma(aeb_df, ckpt=None):
- '''Calculates the episode reward moving average with the MA_WINDOW'''
- rewards = aeb_df['reward']
- if ckpt == 'eval':
- # online eval mode reward is reward_ma from avg
- aeb_df['reward_ma'] = rewards
- else:
- aeb_df['reward_ma'] = rewards.rolling(window=MA_WINDOW, min_periods=0, center=False).mean()
- return aeb_df
-
-
-def calc_fitness(fitness_vec):
- '''
- Takes a vector of qualifying standardized dimensions of fitness and compute the normalized length as fitness
- use L1 norm for simplicity and intuititveness of linearity
- '''
- if isinstance(fitness_vec, pd.Series):
- fitness_vec = fitness_vec.values
- elif isinstance(fitness_vec, pd.DataFrame):
- fitness_vec = fitness_vec.iloc[0].values
- std_fitness_vector = np.ones(len(fitness_vec))
- fitness = np.linalg.norm(fitness_vec, NORM_ORDER) / np.linalg.norm(std_fitness_vector, NORM_ORDER)
- return fitness
-
-
-def calc_aeb_fitness_sr(aeb_df, env_name):
- '''Top level method to calculate fitness vector for AEB level data (strength, speed, stability)'''
- std = FITNESS_STD.get(env_name)
- if std is None:
- std = FITNESS_STD.get('template')
- logger.warn(f'The fitness standard for env {env_name} is not built yet. Contact author. Using a template standard for now.')
-
- # calculate the strength sr and the moving-average (to denoise) first before calculating fitness
- aeb_df['strength'] = calc_strength_sr(aeb_df, std['rand_epi_reward'], std['std_epi_reward'])
- aeb_df['strength_ma'] = aeb_df['strength'].rolling(MA_WINDOW, min_periods=0, center=False).mean()
-
- strength = calc_strength(aeb_df)
- speed = calc_speed(aeb_df, std['std_timestep'])
- stability = calc_stability(aeb_df)
- aeb_fitness_sr = pd.Series({
- 'strength': strength, 'speed': speed, 'stability': stability})
- return aeb_fitness_sr
-
-
-'''
-Checkpoint and early termination analysis
-'''
-
-
-def get_reward_mas(agent, name='eval_reward_ma'):
- '''Return array of the named reward_ma for all of an agent's bodies.'''
- bodies = getattr(agent, 'nanflat_body_a', [agent.body])
- return np.array([getattr(body, name) for body in bodies], dtype=np.float16)
-
-
-def get_std_epi_rewards(agent):
- '''Return array of std_epi_reward for each of the environments.'''
- bodies = getattr(agent, 'nanflat_body_a', [agent.body])
- return np.array([ps.get(FITNESS_STD, f'{body.env.name}.std_epi_reward') for body in bodies], dtype=np.float16)
-
-
-def new_best(agent):
- '''Check if algorithm is now the new best result, then update the new best'''
- best_reward_mas = get_reward_mas(agent, 'best_reward_ma')
- eval_reward_mas = get_reward_mas(agent, 'eval_reward_ma')
- best = (eval_reward_mas >= best_reward_mas).all()
- if best:
- bodies = getattr(agent, 'nanflat_body_a', [agent.body])
- for body in bodies:
- body.best_reward_ma = body.eval_reward_ma
- return best
-
-
-def all_solved(agent):
- '''Check if envs have all been solved using std from slm_lab/spec/_fitness_std.json'''
- eval_reward_mas = get_reward_mas(agent, 'eval_reward_ma')
- std_epi_rewards = get_std_epi_rewards(agent)
- solved = (
- not np.isnan(std_epi_rewards).any() and
- (eval_reward_mas >= std_epi_rewards).all()
- )
- return solved
-
-
-def is_unfit(fitness_df, session):
- '''Check if a fitness_df is unfit. Used to determine of trial should stop running more sessions'''
- if FITNESS_STD.get(session.spec['env'][0]['name']) is None:
- return False # fitness not known
- mean_fitness_df = calc_mean_fitness(fitness_df)
- return mean_fitness_df['strength'].iloc[0] <= NOISE_WINDOW
-
-
-'''
-Analysis interface methods
-'''
-
+ # shift to keep indices for division
+ drops = local_strs.diff().shift(-1).iloc[:-1].clip(upper=0.0)
+ denoms = local_strs.iloc[:-1]
+ local_stas = 1 - (drops / denoms).abs()
+ sum_drops = drops.sum()
+ sum_denom = denoms.sum()
+ sta = 1 - np.abs(sum_drops / sum_denom)
+ return sta, local_stas
-def save_spec(spec, info_space, unit='experiment'):
- '''Save spec to proper path. Called at Experiment or Trial init.'''
- prepath = util.get_prepath(spec, info_space, unit)
- util.write(spec, f'{prepath}_spec.json')
-
-def calc_mean_fitness(fitness_df):
- '''Method to calculated mean over all bodies for a fitness_df'''
- return fitness_df.mean(axis=1, level=3)
-
-
-def get_session_data(session, body_df_kind='eval', tmp_space_session_sub=False):
- '''
- Gather data from session from all the bodies
- Depending on body_df_kind, will use eval_df or train_df
- '''
- session_data = {}
- for aeb, body in util.ndenumerate_nonan(session.aeb_space.body_space.data):
- aeb_df = body.eval_df if body_df_kind == 'eval' else body.train_df
- # TODO tmp substitution since SpaceSession does not have run_eval_episode yet
- if tmp_space_session_sub:
- aeb_df = body.train_df
- session_data[aeb] = aeb_df.copy()
- return session_data
-
-
-def calc_session_fitness_df(session, session_data):
- '''Calculate the session fitness df'''
- session_fitness_data = {}
- for aeb in session_data:
- aeb_df = session_data[aeb]
- aeb_df = calc_epi_reward_ma(aeb_df, ps.get(session.info_space, 'ckpt'))
- util.downcast_float32(aeb_df)
- body = session.aeb_space.body_space.data[aeb]
- aeb_fitness_sr = calc_aeb_fitness_sr(aeb_df, body.env.name)
- aeb_fitness_df = pd.DataFrame([aeb_fitness_sr], index=[session.index])
- aeb_fitness_df = aeb_fitness_df.reindex(FITNESS_COLS[:3], axis=1)
- session_fitness_data[aeb] = aeb_fitness_df
- # form multi_index df, then take mean across all bodies
- session_fitness_df = pd.concat(session_fitness_data, axis=1)
- mean_fitness_df = calc_mean_fitness(session_fitness_df)
- session_fitness = calc_fitness(mean_fitness_df)
- logger.info(f'Session mean fitness: {session_fitness}\n{mean_fitness_df}')
- return session_fitness_df
-
-
-def calc_trial_fitness_df(trial):
- '''
- Calculate the trial fitness df by aggregating from the collected session_data_dict (session_fitness_df's).
- Adds a consistency dimension to fitness vector.
- '''
- trial_fitness_data = {}
- try:
- all_session_fitness_df = pd.concat(list(trial.session_data_dict.values()))
- except ValueError as e:
- logger.exception('Sessions failed, no data to analyze. Check stack trace above')
- for aeb in util.get_df_aeb_list(all_session_fitness_df):
- aeb_fitness_df = all_session_fitness_df.loc[:, aeb]
- aeb_fitness_sr = aeb_fitness_df.mean()
- consistency = calc_consistency(aeb_fitness_df)
- aeb_fitness_sr = aeb_fitness_sr.append(pd.Series({'consistency': consistency}))
- aeb_fitness_df = pd.DataFrame([aeb_fitness_sr], index=[trial.index])
- aeb_fitness_df = aeb_fitness_df.reindex(FITNESS_COLS, axis=1)
- trial_fitness_data[aeb] = aeb_fitness_df
- # form multi_index df, then take mean across all bodies
- trial_fitness_df = pd.concat(trial_fitness_data, axis=1)
- mean_fitness_df = calc_mean_fitness(trial_fitness_df)
- trial_fitness_df = mean_fitness_df
- trial_fitness = calc_fitness(mean_fitness_df)
- logger.info(f'Trial mean fitness: {trial_fitness}\n{mean_fitness_df}')
- return trial_fitness_df
-
-
-def plot_session(session_spec, info_space, session_data):
- '''Plot the session graph, 2 panes: reward, loss & explore_var. Each aeb_df gets its own color'''
- max_tick_unit = ps.get(session_spec, 'meta.max_tick_unit')
- aeb_count = len(session_data)
- palette = viz.get_palette(aeb_count)
- fig = viz.tools.make_subplots(rows=3, cols=1, shared_xaxes=True, print_grid=False)
- for idx, (a, e, b) in enumerate(session_data):
- aeb_str = f'{a}{e}{b}'
- aeb_df = session_data[(a, e, b)]
- aeb_df.fillna(0, inplace=True) # for saving plot, cant have nan
- fig_1 = viz.plot_line(aeb_df, 'reward_ma', max_tick_unit, legend_name=aeb_str, draw=False, trace_kwargs={'legendgroup': aeb_str, 'line': {'color': palette[idx]}})
- fig.append_trace(fig_1.data[0], 1, 1)
-
- fig_2 = viz.plot_line(aeb_df, ['loss'], max_tick_unit, y2_col=['explore_var'], trace_kwargs={'legendgroup': aeb_str, 'showlegend': False, 'line': {'color': palette[idx]}}, draw=False)
- fig.append_trace(fig_2.data[0], 2, 1)
- fig.append_trace(fig_2.data[1], 3, 1)
-
- fig.layout['xaxis1'].update(title=max_tick_unit, zerolinewidth=1)
- fig.layout['yaxis1'].update(fig_1.layout['yaxis'])
- fig.layout['yaxis1'].update(domain=[0.55, 1])
- fig.layout['yaxis2'].update(fig_2.layout['yaxis'])
- fig.layout['yaxis2'].update(showgrid=False, domain=[0, 0.45])
- fig.layout['yaxis3'].update(fig_2.layout['yaxis2'])
- fig.layout['yaxis3'].update(overlaying='y2', anchor='x2')
- fig.layout.update(ps.pick(fig_1.layout, ['legend']))
- fig.layout.update(title=f'session graph: {session_spec["name"]} t{info_space.get("trial")} s{info_space.get("session")}', width=500, height=600)
- viz.plot(fig)
- return fig
-
-
-def gather_aeb_rewards_df(aeb, session_datas, max_tick_unit):
- '''Gather rewards from each session for a body into a df'''
- aeb_session_rewards = {}
- for s, session_data in session_datas.items():
- aeb_df = session_data[aeb]
- aeb_reward_sr = aeb_df['reward_ma']
- aeb_reward_sr.index = aeb_df[max_tick_unit]
- # guard for duplicate eval result
- aeb_reward_sr = aeb_reward_sr[~aeb_reward_sr.index.duplicated()]
- if util.in_eval_lab_modes():
- # guard for eval appending possibly not ordered
- aeb_reward_sr.sort_index(inplace=True)
- aeb_session_rewards[s] = aeb_reward_sr
- aeb_rewards_df = pd.DataFrame(aeb_session_rewards)
- return aeb_rewards_df
-
-
-def build_aeb_reward_fig(aeb_rewards_df, aeb_str, color, max_tick_unit):
- '''Build the aeb_reward envelope figure'''
- mean_sr = aeb_rewards_df.mean(axis=1)
- std_sr = aeb_rewards_df.std(axis=1).fillna(0)
- max_sr = mean_sr + std_sr
- min_sr = mean_sr - std_sr
- x = aeb_rewards_df.index.tolist()
- max_y = max_sr.tolist()
- min_y = min_sr.tolist()
-
- envelope_trace = viz.go.Scatter(
- x=x + x[::-1],
- y=max_y + min_y[::-1],
- fill='tozerox',
- fillcolor=viz.lower_opacity(color, 0.2),
- line=dict(color='rgba(0, 0, 0, 0)'),
- showlegend=False,
- legendgroup=aeb_str,
- )
- df = pd.DataFrame({max_tick_unit: x, 'mean_reward': mean_sr})
- fig = viz.plot_line(
- df, ['mean_reward'], [max_tick_unit], legend_name=aeb_str, draw=False, trace_kwargs={'legendgroup': aeb_str, 'line': {'color': color}}
- )
- fig.add_traces([envelope_trace])
- return fig
-
-
-def calc_trial_df(trial_spec, info_space):
- '''Calculate trial_df as mean of all session_df'''
- from slm_lab.experiment import retro_analysis
- prepath = util.get_prepath(trial_spec, info_space)
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- session_datas = retro_analysis.session_datas_from_file(predir, trial_spec, info_space.get('trial'), ps.get(info_space, 'ckpt'))
- aeb_transpose = {aeb: [] for aeb in session_datas[list(session_datas.keys())[0]]}
- max_tick_unit = ps.get(trial_spec, 'meta.max_tick_unit')
- for s, session_data in session_datas.items():
- for aeb, aeb_df in session_data.items():
- aeb_transpose[aeb].append(aeb_df.sort_values(by=[max_tick_unit]).set_index(max_tick_unit, drop=False))
-
- trial_data = {}
- for aeb, df_list in aeb_transpose.items():
- trial_data[aeb] = pd.concat(df_list).groupby(level=0).mean().reset_index(drop=True)
-
- trial_df = pd.concat(trial_data, axis=1)
- return trial_df
-
-
-def plot_trial(trial_spec, info_space):
- '''Plot the trial graph, 1 pane: mean and error envelope of reward graphs from all sessions. Each aeb_df gets its own color'''
- from slm_lab.experiment import retro_analysis
- prepath = util.get_prepath(trial_spec, info_space)
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- session_datas = retro_analysis.session_datas_from_file(predir, trial_spec, info_space.get('trial'), ps.get(info_space, 'ckpt'))
- rand_session_data = session_datas[list(session_datas.keys())[0]]
- max_tick_unit = ps.get(trial_spec, 'meta.max_tick_unit')
- aeb_count = len(rand_session_data)
- palette = viz.get_palette(aeb_count)
- fig = None
- for idx, (a, e, b) in enumerate(rand_session_data):
- aeb = (a, e, b)
- aeb_str = f'{a}{e}{b}'
- color = palette[idx]
- aeb_rewards_df = gather_aeb_rewards_df(aeb, session_datas, max_tick_unit)
- aeb_fig = build_aeb_reward_fig(aeb_rewards_df, aeb_str, color, max_tick_unit)
- if fig is None:
- fig = aeb_fig
- else:
- fig.add_traces(aeb_fig.data)
- fig.layout.update(title=f'trial graph: {trial_spec["name"]} t{info_space.get("trial")}, {len(session_datas)} sessions', width=500, height=600)
- viz.plot(fig)
- return fig
-
-
-def plot_experiment(experiment_spec, experiment_df):
+def calc_consistency(local_strs_list):
'''
- Plot the variable specs vs fitness vector of an experiment, where each point is a trial.
- ref colors: https://plot.ly/python/heatmaps-contours-and-2dhistograms-tutorial/#plotlys-predefined-color-scales
+ Calculate consistency for metric
+ con &= 1 - \frac{\sum_{i=0}^N 2 stdev_j(str_{i,j})}{\sum_{i=0}^N avg_j(str_{i,j})}
+ @param Series:local_strs_list A list of multiple series of local strengths from different sessions
+ @returns float:con, Series:local_cons
'''
- y_cols = ['fitness'] + FITNESS_COLS
- x_cols = ps.difference(experiment_df.columns.tolist(), y_cols)
-
- fig = viz.tools.make_subplots(rows=len(y_cols), cols=len(x_cols), shared_xaxes=True, shared_yaxes=True, print_grid=False)
- fitness_sr = experiment_df['fitness']
- min_fitness = fitness_sr.values.min()
- max_fitness = fitness_sr.values.max()
- for row_idx, y in enumerate(y_cols):
- for col_idx, x in enumerate(x_cols):
- x_sr = experiment_df[x]
- guard_cat_x = x_sr.astype(str) if x_sr.dtype == 'object' else x_sr
- trace = viz.go.Scatter(
- y=experiment_df[y], yaxis=f'y{row_idx+1}',
- x=guard_cat_x, xaxis=f'x{col_idx+1}',
- showlegend=False, mode='markers',
- marker={
- 'symbol': 'circle-open-dot', 'color': experiment_df['fitness'], 'opacity': 0.5,
- # dump first quarter of colorscale that is too bright
- 'cmin': min_fitness - 0.50 * (max_fitness - min_fitness), 'cmax': max_fitness,
- 'colorscale': 'YlGnBu', 'reversescale': True
- },
- )
- fig.append_trace(trace, row_idx + 1, col_idx + 1)
- fig.layout[f'xaxis{col_idx+1}'].update(title='
'.join(ps.chunk(x, 20)), zerolinewidth=1, categoryarray=sorted(guard_cat_x.unique()))
- fig.layout[f'yaxis{row_idx+1}'].update(title=y, rangemode='tozero')
- fig.layout.update(title=f'experiment graph: {experiment_spec["name"]}', width=max(600, len(x_cols) * 300), height=700)
- viz.plot(fig)
- return fig
-
-
-def save_session_df(session_data, filepath, info_space):
- '''Save session_df, and if is in eval mode, modify it and save with append'''
- if util.in_eval_lab_modes():
- ckpt = util.find_ckpt(info_space.eval_model_prepath)
- epi = int(re.search('epi(\d+)', ckpt)[1])
- totalt = int(re.search('totalt(\d+)', ckpt)[1])
- session_df = pd.concat(session_data, axis=1)
- mean_sr = session_df.mean()
- mean_sr.name = totalt # set index to prevent all being the same
- eval_session_df = pd.DataFrame(data=[mean_sr])
- # set sr name too, to total_t
- for aeb in util.get_df_aeb_list(eval_session_df):
- eval_session_df.loc[:, aeb + ('epi',)] = epi
- eval_session_df.loc[:, aeb + ('total_t',)] = totalt
- # if eval, save with append mode
- header = not os.path.exists(filepath)
- with open(filepath, 'a') as f:
- eval_session_df.to_csv(f, header=header)
- else:
- session_df = pd.concat(session_data, axis=1)
- util.write(session_df, filepath)
-
-
-def save_session_data(spec, info_space, session_data, session_fitness_df, session_fig, body_df_kind='eval'):
- '''
- Save the session data: session_df, session_fitness_df, session_graph.
- session_data is saved as session_df; multi-indexed with (a,e,b), 3 extra levels
- to read, use:
- session_df = util.read(filepath, header=[0, 1, 2, 3], index_col=0)
- session_data = util.session_df_to_data(session_df)
- '''
- prepath = util.get_prepath(spec, info_space, unit='session')
- logger.info(f'Saving session data to {prepath}')
- prefix = 'train' if body_df_kind == 'train' else ''
- if 'retro_analyze' not in os.environ['PREPATH']:
- save_session_df(session_data, f'{prepath}_{prefix}session_df.csv', info_space)
- util.write(session_fitness_df, f'{prepath}_{prefix}session_fitness_df.csv')
- viz.save_image(session_fig, f'{prepath}_{prefix}session_graph.png')
-
-
-def save_trial_data(spec, info_space, trial_df, trial_fitness_df, trial_fig, zip=True):
- '''Save the trial data: spec, trial_fitness_df.'''
- prepath = util.get_prepath(spec, info_space, unit='trial')
- logger.info(f'Saving trial data to {prepath}')
- util.write(trial_df, f'{prepath}_trial_df.csv')
- util.write(trial_fitness_df, f'{prepath}_trial_fitness_df.csv')
- viz.save_image(trial_fig, f'{prepath}_trial_graph.png')
- if util.get_lab_mode() == 'train' and zip:
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- shutil.make_archive(predir, 'zip', predir)
- logger.info(f'All trial data zipped to {predir}.zip')
-
-
-def save_experiment_data(spec, info_space, experiment_df, experiment_fig):
- '''Save the experiment data: best_spec, experiment_df, experiment_graph.'''
- prepath = util.get_prepath(spec, info_space, unit='experiment')
- logger.info(f'Saving experiment data to {prepath}')
- util.write(experiment_df, f'{prepath}_experiment_df.csv')
- viz.save_image(experiment_fig, f'{prepath}_experiment_graph.png')
- # zip for ease of upload
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- shutil.make_archive(predir, 'zip', predir)
- logger.info(f'All experiment data zipped to {predir}.zip')
-
+ mean_local_strs, std_local_strs = util.calc_srs_mean_std(local_strs_list)
+ local_cons = 1 - 2 * std_local_strs / mean_local_strs
+ con = 1 - 2 * std_local_strs.sum() / mean_local_strs.sum()
+ return con, local_cons
-def _analyze_session(session, session_data, body_df_kind='eval'):
- '''Helper method for analyze_session to run using eval_df and train_df'''
- session_fitness_df = calc_session_fitness_df(session, session_data)
- session_fig = plot_session(session.spec, session.info_space, session_data)
- save_session_data(session.spec, session.info_space, session_data, session_fitness_df, session_fig, body_df_kind)
- return session_fitness_df
-
-def analyze_session(session, eager_analyze_trial=False, tmp_space_session_sub=False):
- '''
- Gather session data, plot, and return fitness df for high level agg.
- @returns {DataFrame} session_fitness_df Single-row df of session fitness vector (avg over aeb), indexed with session index.
+def calc_session_metrics(session_df, env_name, info_prepath=None, df_mode=None):
'''
- logger.info('Analyzing session')
- session_data = get_session_data(session, body_df_kind='train')
- session_fitness_df = _analyze_session(session, session_data, body_df_kind='train')
- session_data = get_session_data(session, body_df_kind='eval', tmp_space_session_sub=tmp_space_session_sub)
- session_fitness_df = _analyze_session(session, session_data, body_df_kind='eval')
- if eager_analyze_trial:
- # for live trial graph, analyze trial after analyzing session, this only takes a second
- from slm_lab.experiment import retro_analysis
- prepath = util.get_prepath(session.spec, session.info_space, unit='session')
- # use new ones to prevent side effects
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- retro_analysis.analyze_eval_trial(spec, info_space, predir)
- return session_fitness_df
-
-
-def analyze_trial(trial, zip=True):
+ Calculate the session metrics: strength, efficiency, stability
+ @param DataFrame:session_df Dataframe containing reward, frame, opt_step
+ @param str:env_name Name of the environment to get its random baseline
+ @param str:info_prepath Optional info_prepath to auto-save the output to
+ @param str:df_mode Optional df_mode to save with info_prepath
+ @returns dict:metrics Consists of scalar metrics and series local metrics
'''
- Gather trial data, plot, and return trial df for high level agg.
- @returns {DataFrame} trial_fitness_df Single-row df of trial fitness vector (avg over aeb, sessions), indexed with trial index.
- '''
- logger.info('Analyzing trial')
- trial_df = calc_trial_df(trial.spec, trial.info_space)
- trial_fitness_df = calc_trial_fitness_df(trial)
- trial_fig = plot_trial(trial.spec, trial.info_space)
- save_trial_data(trial.spec, trial.info_space, trial_df, trial_fitness_df, trial_fig, zip)
- return trial_fitness_df
-
-
-def analyze_experiment(experiment):
+ rand_bl = random_baseline.get_random_baseline(env_name)
+ mean_rand_returns = rand_bl['mean']
+ mean_returns = session_df['total_reward']
+ frames = session_df['frame']
+ opt_steps = session_df['opt_step']
+
+ str_, local_strs = calc_strength(mean_returns, mean_rand_returns)
+ max_str, final_str = local_strs.max(), local_strs.iloc[-1]
+ sample_eff, local_sample_effs = calc_efficiency(local_strs, frames)
+ train_eff, local_train_effs = calc_efficiency(local_strs, opt_steps)
+ sta, local_stas = calc_stability(local_strs)
+
+ # all the scalar session metrics
+ scalar = {
+ 'strength': str_,
+ 'max_strength': max_str,
+ 'final_strength': final_str,
+ 'sample_efficiency': sample_eff,
+ 'training_efficiency': train_eff,
+ 'stability': sta,
+ }
+ # all the session local metrics
+ local = {
+ 'strengths': local_strs,
+ 'sample_efficiencies': local_sample_effs,
+ 'training_efficiencies': local_train_effs,
+ 'stabilities': local_stas,
+ 'mean_returns': mean_returns,
+ 'frames': frames,
+ 'opt_steps': opt_steps,
+ }
+ metrics = {
+ 'scalar': scalar,
+ 'local': local,
+ }
+ if info_prepath is not None: # auto-save if info_prepath is given
+ util.write(metrics, f'{info_prepath}_session_metrics_{df_mode}.pkl')
+ util.write(scalar, f'{info_prepath}_session_metrics_scalar_{df_mode}.json')
+ # save important metrics in info_prepath directly
+ util.write(scalar, f'{info_prepath.replace("info/", "")}_session_metrics_scalar_{df_mode}.json')
+ return metrics
+
+
+def calc_trial_metrics(session_metrics_list, info_prepath=None):
'''
- Gather experiment trial_data_dict as experiment_df, plot.
- Search module must return best_spec and experiment_data with format {trial_index: exp_trial_data},
- where trial_data = {**var_spec, **fitness_vec, fitness}.
- This is then made into experiment_df.
- @returns {DataFrame} experiment_df Of var_specs, fitness_vec, fitness for all trials.
+ Calculate the trial metrics: mean(strength), mean(efficiency), mean(stability), consistency
+ @param list:session_metrics_list The metrics collected from each session; format: {session_index: {'scalar': {...}, 'local': {...}}}
+ @param str:info_prepath Optional info_prepath to auto-save the output to
+ @returns dict:metrics Consists of scalar metrics and series local metrics
'''
- logger.info('Analyzing experiment')
- experiment_df = pd.DataFrame(experiment.trial_data_dict).transpose()
- cols = FITNESS_COLS + ['fitness']
+ # calculate mean of session metrics
+ scalar_list = [sm['scalar'] for sm in session_metrics_list]
+ mean_scalar = pd.DataFrame(scalar_list).mean().to_dict()
+
+ local_strs_list = [sm['local']['strengths'] for sm in session_metrics_list]
+ local_se_list = [sm['local']['sample_efficiencies'] for sm in session_metrics_list]
+ local_te_list = [sm['local']['training_efficiencies'] for sm in session_metrics_list]
+ local_sta_list = [sm['local']['stabilities'] for sm in session_metrics_list]
+ mean_returns_list = [sm['local']['mean_returns'] for sm in session_metrics_list]
+ frames = session_metrics_list[0]['local']['frames']
+ opt_steps = session_metrics_list[0]['local']['opt_steps']
+ # calculate consistency
+ con, local_cons = calc_consistency(local_strs_list)
+
+ # all the scalar trial metrics
+ scalar = {
+ 'strength': mean_scalar['strength'],
+ 'max_strength': mean_scalar['max_strength'],
+ 'final_strength': mean_scalar['final_strength'],
+ 'sample_efficiency': mean_scalar['sample_efficiency'],
+ 'training_efficiency': mean_scalar['training_efficiency'],
+ 'stability': mean_scalar['stability'],
+ 'consistency': con,
+ }
+ assert set(scalar.keys()) == set(METRICS_COLS)
+ # for plotting: gather all local series of sessions
+ local = {
+ 'strengths': local_strs_list,
+ 'sample_efficiencies': local_se_list,
+ 'training_efficiencies': local_te_list,
+ 'stabilities': local_sta_list,
+ 'consistencies': local_cons, # this is a list
+ 'mean_returns': mean_returns_list,
+ 'frames': frames,
+ 'opt_steps': opt_steps,
+ }
+ metrics = {
+ 'scalar': scalar,
+ 'local': local,
+ }
+ if info_prepath is not None: # auto-save if info_prepath is given
+ util.write(metrics, f'{info_prepath}_trial_metrics.pkl')
+ util.write(scalar, f'{info_prepath}_trial_metrics_scalar.json')
+ # save important metrics in info_prepath directly
+ util.write(scalar, f'{info_prepath.replace("info/", "")}_trial_metrics_scalar.json')
+ return metrics
+
+
+def calc_experiment_df(trial_data_dict, info_prepath=None):
+ '''Collect all trial data (metrics and config) from trials into a dataframe'''
+ experiment_df = pd.DataFrame(trial_data_dict).transpose()
+ cols = METRICS_COLS
config_cols = sorted(ps.difference(experiment_df.columns.tolist(), cols))
sorted_cols = config_cols + cols
experiment_df = experiment_df.reindex(sorted_cols, axis=1)
- experiment_df.sort_values(by=['fitness'], ascending=False, inplace=True)
- logger.info(f'Experiment data:\n{experiment_df}')
- experiment_fig = plot_experiment(experiment.spec, experiment_df)
- save_experiment_data(experiment.spec, experiment.info_space, experiment_df, experiment_fig)
+ experiment_df.sort_values(by=['strength'], ascending=False, inplace=True)
+ if info_prepath is not None:
+ util.write(experiment_df, f'{info_prepath}_experiment_df.csv')
+ # save important metrics in info_prepath directly
+ util.write(experiment_df, f'{info_prepath.replace("info/", "")}_experiment_df.csv')
+ return experiment_df
+
+
+# interface analyze methods
+
+def analyze_session(session_spec, session_df, df_mode):
+ '''Analyze session and save data, then return metrics. Note there are 2 types of session_df: body.eval_df and body.train_df'''
+ info_prepath = session_spec['meta']['info_prepath']
+ session_df = session_df.copy()
+ assert len(session_df) > 1, f'Need more than 1 datapoint to calculate metrics'
+ util.write(session_df, f'{info_prepath}_session_df_{df_mode}.csv')
+ # calculate metrics
+ session_metrics = calc_session_metrics(session_df, ps.get(session_spec, 'env.0.name'), info_prepath, df_mode)
+ # plot graph
+ viz.plot_session(session_spec, session_metrics, session_df, df_mode)
+ return session_metrics
+
+
+def analyze_trial(trial_spec, session_metrics_list):
+ '''Analyze trial and save data, then return metrics'''
+ info_prepath = trial_spec['meta']['info_prepath']
+ # calculate metrics
+ trial_metrics = calc_trial_metrics(session_metrics_list, info_prepath)
+ # plot graphs
+ viz.plot_trial(trial_spec, trial_metrics)
+ # zip files
+ if util.get_lab_mode() == 'train':
+ predir, _, _, _, _, _ = util.prepath_split(info_prepath)
+ shutil.make_archive(predir, 'zip', predir)
+ logger.info(f'All trial data zipped to {predir}.zip')
+ return trial_metrics
+
+
+def analyze_experiment(spec, trial_data_dict):
+ '''Analyze experiment and save data'''
+ info_prepath = spec['meta']['info_prepath']
+ util.write(trial_data_dict, f'{info_prepath}_trial_data_dict.json')
+ # calculate experiment df
+ experiment_df = calc_experiment_df(trial_data_dict, info_prepath)
+ # plot graph
+ viz.plot_experiment(spec, experiment_df, METRICS_COLS)
+ # zip files
+ predir, _, _, _, _, _ = util.prepath_split(info_prepath)
+ shutil.make_archive(predir, 'zip', predir)
+ logger.info(f'All experiment data zipped to {predir}.zip')
return experiment_df
diff --git a/slm_lab/experiment/control.py b/slm_lab/experiment/control.py
index ea34a23f9..52f1e41b0 100644
--- a/slm_lab/experiment/control.py
+++ b/slm_lab/experiment/control.py
@@ -1,324 +1,197 @@
-'''
-The control module
-Creates and controls the units of SLM lab: Experiment, Trial, Session
-'''
+# The control module
+# Creates and runs control loops at levels: Experiment, Trial, Session
from copy import deepcopy
-from importlib import reload
-from slm_lab.agent import AgentSpace, Agent
-from slm_lab.env import EnvSpace, make_env
-from slm_lab.experiment import analysis, retro_analysis, search
-from slm_lab.experiment.monitor import AEBSpace, Body, enable_aeb_space
+from slm_lab.agent import Agent, Body
+from slm_lab.agent.net import net_util
+from slm_lab.env import make_env
+from slm_lab.experiment import analysis, search
from slm_lab.lib import logger, util
from slm_lab.spec import spec_util
-import os
import torch.multiprocessing as mp
+def make_agent_env(spec, global_nets=None):
+ '''Helper to create agent and env given spec'''
+ env = make_env(spec)
+ body = Body(env, spec['agent'])
+ agent = Agent(spec, body=body, global_nets=global_nets)
+ return agent, env
+
+
+def mp_run_session(spec, global_nets, mp_dict):
+ '''Wrap for multiprocessing with shared variable'''
+ session = Session(spec, global_nets)
+ metrics = session.run()
+ mp_dict[session.index] = metrics
+
+
class Session:
'''
- The base unit of instantiated RL system.
- Given a spec,
- session creates agent(s) and environment(s),
- run the RL system and collect data, e.g. fitness metrics, till it ends,
- then return the session data.
+ The base lab unit to run a RL session for a spec.
+ Given a spec, it creates the agent and env, runs the RL loop,
+ then gather data and analyze it to produce session data.
'''
- def __init__(self, spec, info_space, global_nets=None):
+ def __init__(self, spec, global_nets=None):
self.spec = spec
- self.info_space = info_space
- self.index = self.info_space.get('session')
- util.set_logger(self.spec, self.info_space, logger, 'session')
- self.data = None
+ self.index = self.spec['meta']['session']
+ util.set_random_seed(self.spec)
+ util.set_cuda_id(self.spec)
+ util.set_logger(self.spec, logger, 'session')
+ spec_util.save(spec, unit='session')
- # init singleton agent and env
- self.env = make_env(self.spec)
- util.set_rand_seed(self.info_space.get_random_seed(), self.env)
+ self.agent, self.env = make_agent_env(self.spec, global_nets)
with util.ctx_lab_mode('eval'): # env for eval
self.eval_env = make_env(self.spec)
- util.set_rand_seed(self.info_space.get_random_seed(), self.eval_env)
- util.try_set_cuda_id(self.spec, self.info_space)
- body = Body(self.env, self.spec['agent'])
- self.agent = Agent(self.spec, self.info_space, body=body, global_nets=global_nets)
-
- enable_aeb_space(self) # to use lab's data analysis framework
logger.info(util.self_desc(self))
- logger.info(f'Initialized session {self.index}')
- def try_ckpt(self, agent, env):
- '''Try to checkpoint agent at the start, save_freq, and the end'''
- tick = env.clock.get(env.max_tick_unit)
- to_ckpt = False
- if not util.in_eval_lab_modes() and tick <= env.max_tick:
- to_ckpt = (tick % env.eval_frequency == 0) or tick == env.max_tick
- if env.max_tick_unit == 'epi': # extra condition for epi
- to_ckpt = to_ckpt and env.done
+ def to_ckpt(self, env, mode='eval'):
+ '''Check with clock whether to run log/eval ckpt: at the start, save_freq, and the end'''
+ if mode == 'eval' and util.in_eval_lab_modes(): # avoid double-eval: eval-ckpt in eval mode
+ return False
+ clock = env.clock
+ frame = clock.get()
+ frequency = env.eval_frequency if mode == 'eval' else env.log_frequency
+ if frame == 0 or clock.get('opt_step') == 0: # avoid ckpt at init
+ to_ckpt = False
+ elif frequency is None: # default episodic
+ to_ckpt = env.done
+ else: # normal ckpt condition by mod remainder (general for venv)
+ to_ckpt = util.frame_mod(frame, frequency, env.num_envs) or frame == clock.max_frame
+ return to_ckpt
- if to_ckpt:
- if self.spec['meta'].get('parallel_eval'):
- retro_analysis.run_parallel_eval(self, agent, env)
- else:
- self.run_eval_episode()
- if analysis.new_best(agent):
+ def try_ckpt(self, agent, env):
+ '''Check then run checkpoint log/eval'''
+ body = agent.body
+ if self.to_ckpt(env, 'log'):
+ body.train_ckpt()
+ body.log_summary('train')
+
+ if self.to_ckpt(env, 'eval'):
+ avg_return = analysis.gen_avg_return(agent, self.eval_env)
+ body.eval_ckpt(self.eval_env, avg_return)
+ body.log_summary('eval')
+ if body.eval_reward_ma >= body.best_reward_ma:
+ body.best_reward_ma = body.eval_reward_ma
agent.save(ckpt='best')
- if tick > 0: # nothing to analyze at start
- analysis.analyze_session(self, eager_analyze_trial=True)
-
- def run_eval_episode(self):
- with util.ctx_lab_mode('eval'): # enter eval context
- self.agent.algorithm.update() # set explore_var etc. to end_val under ctx
- self.eval_env.clock.tick('epi')
- logger.info(f'Running eval episode for trial {self.info_space.get("trial")} session {self.index}')
- total_reward = 0
- reward, state, done = self.eval_env.reset()
- while not done:
- self.eval_env.clock.tick('t')
- action = self.agent.act(state)
- reward, state, done = self.eval_env.step(action)
- total_reward += reward
- # exit eval context, restore variables simply by updating
- self.agent.algorithm.update()
- # update body.eval_df
- self.agent.body.eval_update(self.eval_env, total_reward)
- self.agent.body.log_summary(body_df_kind='eval')
-
- def run_episode(self):
- self.env.clock.tick('epi')
- logger.info(f'Running trial {self.info_space.get("trial")} session {self.index} episode {self.env.clock.epi}')
- reward, state, done = self.env.reset()
- self.agent.reset(state)
- while not done:
+ if len(body.train_df) > 1: # need > 1 row to calculate stability
+ metrics = analysis.analyze_session(self.spec, body.train_df, 'train')
+ body.log_metrics(metrics['scalar'], 'train')
+ if len(body.eval_df) > 1: # need > 1 row to calculate stability
+ metrics = analysis.analyze_session(self.spec, body.eval_df, 'eval')
+ body.log_metrics(metrics['scalar'], 'eval')
+
+ def run_rl(self):
+ '''Run the main RL loop until clock.max_frame'''
+ logger.info(f'Running RL loop for trial {self.spec["meta"]["trial"]} session {self.index}')
+ clock = self.env.clock
+ state = self.env.reset()
+ done = False
+ while True:
+ if util.epi_done(done): # before starting another episode
+ self.try_ckpt(self.agent, self.env)
+ if clock.get() < clock.max_frame: # reset and continue
+ clock.tick('epi')
+ state = self.env.reset()
+ done = False
self.try_ckpt(self.agent, self.env)
- self.env.clock.tick('t')
+ if clock.get() >= clock.max_frame: # finish
+ break
+ clock.tick('t')
action = self.agent.act(state)
- reward, state, done = self.env.step(action)
- self.agent.update(action, reward, state, done)
- self.try_ckpt(self.agent, self.env) # final timestep ckpt
- self.agent.body.log_summary(body_df_kind='train')
+ next_state, reward, done, info = self.env.step(action)
+ self.agent.update(state, action, reward, next_state, done)
+ state = next_state
def close(self):
- '''
- Close session and clean up.
- Save agent, close env.
- '''
+ '''Close session and clean up. Save agent, close env.'''
self.agent.close()
self.env.close()
self.eval_env.close()
- logger.info('Session done and closed.')
+ logger.info(f'Session {self.index} done')
def run(self):
- while self.env.clock.get(self.env.max_tick_unit) < self.env.max_tick:
- self.run_episode()
- retro_analysis.try_wait_parallel_eval(self)
- self.data = analysis.analyze_session(self) # session fitness
+ self.run_rl()
+ metrics = analysis.analyze_session(self.spec, self.agent.body.eval_df, 'eval')
+ self.agent.body.log_metrics(metrics['scalar'], 'eval')
self.close()
- return self.data
-
-
-class SpaceSession(Session):
- '''Session for multi-agent/env setting'''
-
- def __init__(self, spec, info_space, global_nets=None):
- self.spec = spec
- self.info_space = info_space
- self.index = self.info_space.get('session')
- util.set_logger(self.spec, self.info_space, logger, 'session')
- self.data = None
-
- self.aeb_space = AEBSpace(self.spec, self.info_space)
- self.env_space = EnvSpace(self.spec, self.aeb_space)
- self.aeb_space.init_body_space()
- util.set_rand_seed(self.info_space.get_random_seed(), self.env_space)
- util.try_set_cuda_id(self.spec, self.info_space)
- self.agent_space = AgentSpace(self.spec, self.aeb_space, global_nets)
-
- logger.info(util.self_desc(self))
- logger.info(f'Initialized session {self.index}')
-
- def try_ckpt(self, agent_space, env_space):
- '''Try to checkpoint agent at the start, save_freq, and the end'''
- # TODO ckpt and eval not implemented for SpaceSession
- pass
- # for agent in agent_space.agents:
- # for body in agent.nanflat_body_a:
- # env = body.env
- # super(SpaceSession, self).try_ckpt(agent, env)
-
- def run_all_episodes(self):
- '''
- Continually run all episodes, where each env can step and reset at its own clock_speed and timeline.
- Will terminate when all envs done are done.
- '''
- all_done = self.aeb_space.tick('epi')
- reward_space, state_space, done_space = self.env_space.reset()
- self.agent_space.reset(state_space)
- while not all_done:
- self.try_ckpt(self.agent_space, self.env_space)
- all_done = self.aeb_space.tick()
- action_space = self.agent_space.act(state_space)
- reward_space, state_space, done_space = self.env_space.step(action_space)
- self.agent_space.update(action_space, reward_space, state_space, done_space)
- self.try_ckpt(self.agent_space, self.env_space)
- retro_analysis.try_wait_parallel_eval(self)
-
- def close(self):
- '''
- Close session and clean up.
- Save agent, close env.
- '''
- self.agent_space.close()
- self.env_space.close()
- logger.info('Session done and closed.')
-
- def run(self):
- self.run_all_episodes()
- self.data = analysis.analyze_session(self, tmp_space_session_sub=True) # session fitness
- self.close()
- return self.data
-
-
-def init_run_session(*args):
- '''Runner for multiprocessing'''
- session = Session(*args)
- return session.run()
-
-
-def init_run_space_session(*args):
- '''Runner for multiprocessing'''
- session = SpaceSession(*args)
- return session.run()
+ return metrics
class Trial:
'''
- The base unit of an experiment.
- Given a spec and number s,
- trial creates and runs s sessions,
- gather and aggregate data from sessions as trial data,
- then return the trial data.
+ The lab unit which runs repeated sessions for a same spec, i.e. a trial
+ Given a spec and number s, trial creates and runs s sessions,
+ then gathers session data and analyze it to produce trial data.
'''
- def __init__(self, spec, info_space):
+ def __init__(self, spec):
self.spec = spec
- self.info_space = info_space
- self.index = self.info_space.get('trial')
- info_space.set('session', None) # Session starts anew for new trial
- util.set_logger(self.spec, self.info_space, logger, 'trial')
- self.session_data_dict = {}
- self.data = None
-
- analysis.save_spec(spec, info_space, unit='trial')
- self.is_singleton = spec_util.is_singleton(spec) # singleton mode as opposed to multi-agent-env space
- self.SessionClass = Session if self.is_singleton else SpaceSession
- self.mp_runner = init_run_session if self.is_singleton else init_run_space_session
- logger.info(f'Initialized trial {self.index}')
+ self.index = self.spec['meta']['trial']
+ util.set_logger(self.spec, logger, 'trial')
+ spec_util.save(spec, unit='trial')
def parallelize_sessions(self, global_nets=None):
+ mp_dict = mp.Manager().dict()
workers = []
for _s in range(self.spec['meta']['max_session']):
- self.info_space.tick('session')
- w = mp.Process(target=self.mp_runner, args=(deepcopy(self.spec), deepcopy(self.info_space), global_nets))
+ spec_util.tick(self.spec, 'session')
+ w = mp.Process(target=mp_run_session, args=(deepcopy(self.spec), global_nets, mp_dict))
w.start()
workers.append(w)
for w in workers:
w.join()
- session_datas = retro_analysis.session_data_dict_for_dist(self.spec, self.info_space)
- return session_datas
+ session_metrics_list = [mp_dict[idx] for idx in sorted(mp_dict.keys())]
+ return session_metrics_list
def run_sessions(self):
logger.info('Running sessions')
- if util.get_lab_mode() in ('train', 'eval') and self.spec['meta']['max_session'] > 1:
- # when training a single spec over multiple sessions
- session_datas = self.parallelize_sessions()
- else:
- session_datas = []
- for _s in range(self.spec['meta']['max_session']):
- self.info_space.tick('session')
- session = self.SessionClass(deepcopy(self.spec), deepcopy(self.info_space))
- session_data = session.run()
- session_datas.append(session_data)
- if analysis.is_unfit(session_data, session):
- break
- return session_datas
-
- def make_global_nets(self, agent):
- global_nets = {}
- for net_name in agent.algorithm.net_names:
- g_net = getattr(agent.algorithm, net_name)
- g_net.share_memory() # make net global
- # TODO also create shared optimizer here
- global_nets[net_name] = g_net
- return global_nets
+ session_metrics_list = self.parallelize_sessions()
+ return session_metrics_list
def init_global_nets(self):
- session = self.SessionClass(deepcopy(self.spec), deepcopy(self.info_space))
- if self.is_singleton:
- session.env.close() # safety
- global_nets = self.make_global_nets(session.agent)
- else:
- session.env_space.close() # safety
- global_nets = [self.make_global_nets(agent) for agent in session.agent_space.agents]
+ session = Session(deepcopy(self.spec))
+ session.env.close() # safety
+ global_nets = net_util.init_global_nets(session.agent.algorithm)
return global_nets
def run_distributed_sessions(self):
logger.info('Running distributed sessions')
global_nets = self.init_global_nets()
- session_datas = self.parallelize_sessions(global_nets)
- return session_datas
+ session_metrics_list = self.parallelize_sessions(global_nets)
+ return session_metrics_list
def close(self):
- logger.info('Trial done and closed.')
+ logger.info(f'Trial {self.index} done')
def run(self):
- if self.spec['meta'].get('distributed'):
- session_datas = self.run_distributed_sessions()
+ if self.spec['meta'].get('distributed') == False:
+ session_metrics_list = self.run_sessions()
else:
- session_datas = self.run_sessions()
- self.session_data_dict = {data.index[0]: data for data in session_datas}
- self.data = analysis.analyze_trial(self)
+ session_metrics_list = self.run_distributed_sessions()
+ metrics = analysis.analyze_trial(self.spec, session_metrics_list)
self.close()
- return self.data
+ return metrics['scalar']
class Experiment:
'''
- The core high level unit of Lab.
- Given a spec-space/generator of cardinality t,
- a number s,
- a hyper-optimization algorithm hopt(spec, fitness-metric) -> spec_next/null
- experiment creates and runs up to t trials of s sessions each to optimize (maximize) the fitness metric,
- gather the trial data,
- then return the experiment data for analysis and use in evolution graph.
- Experiment data will include the trial data, notes on design, hypothesis, conclusion, analysis data, e.g. fitness metric, evolution link of ancestors to potential descendants.
- An experiment then forms a node containing its data in the evolution graph with the evolution link and suggestion at the adjacent possible new experiments
- On the evolution graph level, an experiment and its neighbors could be seen as test/development of traits.
+ The lab unit to run experiments.
+ It generates a list of specs to search over, then run each as a trial with s repeated session,
+ then gathers trial data and analyze it to produce experiment data.
'''
- def __init__(self, spec, info_space):
+ def __init__(self, spec):
self.spec = spec
- self.info_space = info_space
- self.index = self.info_space.get('experiment')
- util.set_logger(self.spec, self.info_space, logger, 'trial')
- self.trial_data_dict = {}
- self.data = None
- analysis.save_spec(spec, info_space, unit='experiment')
- SearchClass = getattr(search, spec['meta'].get('search'))
- self.search = SearchClass(self)
- logger.info(f'Initialized experiment {self.index}')
-
- def init_trial_and_run(self, spec, info_space):
- '''
- Method to run trial with the properly updated info_space (trial_index) from experiment.search.lab_trial.
- '''
- trial = Trial(spec, info_space)
- trial_data = trial.run()
- return trial_data
+ self.index = self.spec['meta']['experiment']
+ util.set_logger(self.spec, logger, 'trial')
+ spec_util.save(spec, unit='experiment')
def close(self):
- reload(search) # fixes ray consecutive run crashing due to bad cleanup
- logger.info('Experiment done and closed.')
+ logger.info('Experiment done')
def run(self):
- self.trial_data_dict = self.search.run()
- self.data = analysis.analyze_experiment(self)
+ trial_data_dict = search.run_ray_search(self.spec)
+ experiment_df = analysis.analyze_experiment(self.spec, trial_data_dict)
self.close()
- return self.data
+ return experiment_df
diff --git a/slm_lab/experiment/monitor.py b/slm_lab/experiment/monitor.py
deleted file mode 100644
index 4faf34e22..000000000
--- a/slm_lab/experiment/monitor.py
+++ /dev/null
@@ -1,495 +0,0 @@
-'''
-The monitor module with data_space
-Monitors agents, environments, sessions, trials, experiments, evolutions, and handles all the data produced by the Lab components.
-InfoSpace handles the unified hyperdimensional data for SLM Lab, used for analysis and experiment planning. Sources data from monitor.
-Each dataframe resolves from the coarsest dimension to the finest, with data coordinates coor in the form: (evolution,experiment,trial,session,agent,env,body)
-The resolution after session is the AEB space, hence it is a subspace.
-AEB space is not necessarily tabular, and hence the data is NoSQL.
-
-The data_space is congruent to the coor, with proper resolution.
-E.g. (evolution,experiment,trial,session) specifies the session_data of a session, ran over multiple episodes on the AEB space.
-
-Space ordering:
-InfoSpace: the general space for complete information
-AEBSpace: subspace of InfoSpace for a specific session
-AgentSpace: space agent instances, subspace of AEBSpace
-EnvSpace: space of env instances, subspace of AEBSpace
-DataSpace: a data space storing an AEB data projected to a-axis, and its dual projected to e-axis. This is so that a-proj data like action_space from agent_space can be used by env_space, which requires e-proj data, and vice versa.
-
-Object reference (for agent to access env properties, vice versa):
-Agents - AgentSpace - AEBSpace - EnvSpace - Envs
-'''
-from gym import spaces
-from slm_lab.agent import AGENT_DATA_NAMES
-from slm_lab.agent.algorithm import policy_util
-from slm_lab.agent.net import net_util
-from slm_lab.env import ENV_DATA_NAMES
-from slm_lab.experiment import analysis
-from slm_lab.lib import logger, util
-from slm_lab.spec import spec_util
-import numpy as np
-import pandas as pd
-import pydash as ps
-import time
-import torch
-
-# These correspond to the control unit classes, lower cased
-COOR_AXES = [
- 'evolution',
- 'experiment',
- 'trial',
- 'session',
-]
-COOR_AXES_ORDER = {
- axis: idx for idx, axis in enumerate(COOR_AXES)
-}
-COOR_DIM = len(COOR_AXES)
-logger = logger.get_logger(__name__)
-
-
-def enable_aeb_space(session):
- '''Enable aeb_space to session use Lab's data-monitor and analysis modules'''
- session.aeb_space = AEBSpace(session.spec, session.info_space)
- # make compatible with the generic multiagent setup
- session.aeb_space.body_space = DataSpace('body', session.aeb_space)
- body_v = np.full(session.aeb_space.aeb_shape, np.nan, dtype=object)
- body_v[0, 0, 0] = session.agent.body
- session.aeb_space.body_space.add(body_v)
- session.agent.aeb_space = session.aeb_space
- session.env.aeb_space = session.aeb_space
-
-
-def get_action_type(action_space):
- '''Method to get the action type to choose prob. dist. to sample actions from NN logits output'''
- if isinstance(action_space, spaces.Box):
- shape = action_space.shape
- assert len(shape) == 1
- if shape[0] == 1:
- return 'continuous'
- else:
- return 'multi_continuous'
- elif isinstance(action_space, spaces.Discrete):
- return 'discrete'
- elif isinstance(action_space, spaces.MultiDiscrete):
- return 'multi_discrete'
- elif isinstance(action_space, spaces.MultiBinary):
- return 'multi_binary'
- else:
- raise NotImplementedError
-
-
-class Body:
- '''
- Body of an agent inside an environment. This acts as the main variable storage and bridge between agent and environment to pair them up properly in the generalized multi-agent-env setting.
- '''
-
- def __init__(self, env, agent_spec, aeb=(0, 0, 0), aeb_space=None):
- # essential reference variables
- self.agent = None # set later
- self.env = env
- self.aeb = aeb
- self.a, self.e, self.b = aeb
- self.nanflat_a_idx, self.nanflat_e_idx = self.a, self.e
-
- # for action policy exploration, so be set in algo during init_algorithm_params()
- self.explore_var = np.nan
-
- # body stats variables
- self.loss = np.nan # training losses
- # diagnostics variables/stats from action_policy prob. dist.
- self.action_tensor = None
- self.action_pd = None # for the latest action, to compute entropy and log prob
- self.entropies = [] # action entropies for exploration
- self.log_probs = [] # action log probs
- # mean values for debugging
- self.mean_entropy = np.nan
- self.mean_log_prob = np.nan
- self.mean_grad_norm = np.nan
-
- # stores running mean and std dev of states
- self.state_mean = np.nan
- self.state_std_dev_int = np.nan
- self.state_std_dev = np.nan
- self.state_n = 0
-
- # store current and best reward_ma for model checkpointing and early termination if all the environments are solved
- self.best_reward_ma = -np.inf
- self.eval_reward_ma = np.nan
-
- # dataframes to track data for analysis.analyze_session
- # track training data within run_episode
- self.train_df = pd.DataFrame(columns=[
- 'epi', 'total_t', 't', 'wall_t', 'fps', 'reward', 'loss', 'lr',
- 'explore_var', 'entropy_coef', 'entropy', 'log_prob', 'grad_norm'])
- # track eval data within run_eval_episode. the same as train_df except for reward
- self.eval_df = self.train_df.copy()
-
- if aeb_space is None: # singleton mode
- # the specific agent-env interface variables for a body
- self.observation_space = self.env.observation_space
- self.action_space = self.env.action_space
- self.observable_dim = self.env.observable_dim
- self.state_dim = self.observable_dim['state']
- self.action_dim = self.env.action_dim
- self.is_discrete = self.env.is_discrete
- else:
- self.space_init(aeb_space)
-
- self.action_type = get_action_type(self.action_space)
- self.action_pdtype = agent_spec[self.a]['algorithm'].get('action_pdtype')
- if self.action_pdtype in (None, 'default'):
- self.action_pdtype = policy_util.ACTION_PDS[self.action_type][0]
-
- def action_pd_update(self):
- '''Calculate and update action entropy and log_prob using self.action_pd. Call this in agent.update()'''
- if self.action_pd is None: # skip if None
- return
- # mean for single and multi-action
- entropy = self.action_pd.entropy().mean(dim=0)
- self.entropies.append(entropy)
- log_prob = self.action_pd.log_prob(self.action_tensor).mean(dim=0)
- self.log_probs.append(log_prob)
- assert not torch.isnan(log_prob)
-
- def calc_df_row(self, env, total_reward):
- '''Calculate a row for updating train_df or eval_df, given a total_reward.'''
- total_t = self.env.clock.get('total_t')
- wall_t = env.clock.get_elapsed_wall_t()
- fps = 0 if wall_t == 0 else total_t / wall_t
- row = pd.Series({
- # epi and total_t are always measured from training env
- 'epi': self.env.clock.get('epi'),
- 'total_t': total_t,
- # t and reward are measured from a given env or eval_env
- 't': env.clock.get('t'),
- 'wall_t': wall_t,
- 'fps': fps,
- 'reward': total_reward,
- 'loss': self.loss,
- 'lr': self.get_mean_lr(),
- 'explore_var': self.explore_var,
- 'entropy_coef': self.entropy_coef if hasattr(self, 'entropy_coef') else np.nan,
- 'entropy': self.mean_entropy,
- 'log_prob': self.mean_log_prob,
- 'grad_norm': self.mean_grad_norm,
- }, dtype=np.float32)
- assert all(col in self.train_df.columns for col in row.index), f'Mismatched row keys: {row.index} vs df columns {self.train_df.columns}'
- return row
-
- def epi_reset(self):
- '''
- Handles any body attribute reset at the start of an episode.
- This method is called automatically at base memory.epi_reset().
- '''
- t = self.env.clock.t
- assert t == 0, f'aeb: {self.aeb}, t: {t}'
- if hasattr(self, 'aeb_space'):
- self.space_fix_stats()
-
- def epi_update(self):
- '''Update to append data at the end of an episode (when env.done is true)'''
- assert self.env.done
- row = self.calc_df_row(self.env, self.memory.total_reward)
- # append efficiently to df
- self.train_df.loc[len(self.train_df)] = row
-
- def eval_update(self, eval_env, total_reward):
- '''Update to append data at eval checkpoint'''
- row = self.calc_df_row(eval_env, total_reward)
- # append efficiently to df
- self.eval_df.loc[len(self.eval_df)] = row
- # update current reward_ma
- self.eval_reward_ma = self.eval_df[-analysis.MA_WINDOW:]['reward'].mean()
-
- def flush(self):
- '''Update and flush gradient-related variables after training step similar.'''
- # update
- self.mean_entropy = torch.tensor(self.entropies).mean().item()
- self.mean_log_prob = torch.tensor(self.log_probs).mean().item()
- # net.grad_norms is only available in dev mode for efficiency
- grad_norms = net_util.get_grad_norms(self.agent.algorithm)
- self.mean_grad_norm = np.nan if ps.is_empty(grad_norms) else np.mean(grad_norms)
-
- # flush
- self.action_tensor = None
- self.action_pd = None
- self.entropies = []
- self.log_probs = []
-
- def __str__(self):
- return 'body: ' + util.to_json(util.get_class_attr(self))
-
- def get_mean_lr(self):
- '''Gets the average current learning rate of the algorithm's nets.'''
- if not hasattr(self.agent.algorithm, 'net_names'):
- return np.nan
- lrs = []
- for net_name in self.agent.algorithm.net_names:
- # we are only interested in directly trainable network, so exclude target net
- if net_name is 'target_net':
- continue
- net = getattr(self.agent.algorithm, net_name)
- lrs.append(net.lr_scheduler.get_lr())
- return np.mean(lrs)
-
- def get_log_prefix(self):
- '''Get the prefix for logging'''
- spec = self.agent.spec
- info_space = self.agent.info_space
- clock = self.env.clock
- prefix = f'{spec["name"]}_t{info_space.get("trial")}_s{info_space.get("session")}, aeb{self.aeb}'
- return prefix
-
- def log_summary(self, body_df_kind='eval'):
- '''Log the summary for this body when its environment is done'''
- prefix = self.get_log_prefix()
- df = self.eval_df if body_df_kind == 'eval' else self.train_df
- last_row = df.iloc[-1]
- row_str = ', '.join([f'{k}: {v:g}' for k, v in last_row.items()])
- reward_ma = df[-analysis.MA_WINDOW:]['reward'].mean()
- reward_ma_str = f'last-{analysis.MA_WINDOW}-epi avg: {reward_ma:g}'
- msg = f'{prefix} [{body_df_kind}_df] {row_str}, {reward_ma_str}'
- logger.info(msg)
-
- def space_init(self, aeb_space):
- '''Post init override for space body. Note that aeb is already correct from __init__'''
- self.aeb_space = aeb_space
- # to be reset properly later
- self.nanflat_a_idx, self.nanflat_e_idx = None, None
-
- self.observation_space = self.env.observation_spaces[self.a]
- self.action_space = self.env.action_spaces[self.a]
- self.observable_dim = self.env._get_observable_dim(self.observation_space)
- self.state_dim = self.observable_dim['state']
- self.action_dim = self.env._get_action_dim(self.action_space)
- self.is_discrete = self.env._is_discrete(self.action_space)
-
- def space_fix_stats(self):
- '''the space control loop will make agent append stat at done, so to offset for that, pop it at reset'''
- for action_stat in [self.entropies, self.log_probs]:
- if len(action_stat) > 0:
- action_stat.pop()
-
-
-class DataSpace:
- '''
- AEB data space. Store all data from RL system in standard aeb-shaped tensors.
- '''
-
- def __init__(self, data_name, aeb_space):
- self.data_name = data_name
- self.aeb_space = aeb_space
- self.aeb_shape = aeb_space.aeb_shape
-
- # data from env have shape (eab), need to swap
- self.to_swap = self.data_name in ENV_DATA_NAMES
- self.swap_aeb_shape = self.aeb_shape[1], self.aeb_shape[0], self.aeb_shape[2]
-
- self.data_shape = self.swap_aeb_shape if self.to_swap else self.aeb_shape
- self.data_type = object if self.data_name in ['state', 'action'] else np.float32
- self.data = None # standard data in aeb_shape
- self.swap_data = None
-
- def __str__(self):
- if self.data is None:
- return ''
- s = '['
- for a, a_arr in enumerate(self.data):
- s += f'\n a:{a} ['
- for e, e_arr in enumerate(a_arr):
- s += f'\n e:{e} ['
- for b, val in enumerate(e_arr):
- s += f'\n b:{b} {val}'
- s += ']'
- s += ']'
- s += '\n]'
- return s
-
- def __bool__(self):
- return util.nonan_all(self.data)
-
- def init_data_v(self):
- '''Method to init a data volume filled with np.nan'''
- data_v = np.full(self.data_shape, np.nan, dtype=self.data_type)
- return data_v
-
- def init_data_s(self, a=None, e=None):
- '''Method to init a data surface (subset of data volume) filled with np.nan.'''
- body_s = self.aeb_space.body_space.get(a=a, e=e)
- data_s = np.full(body_s.shape, np.nan, dtype=self.data_type)
- return data_s
-
- def add(self, data_v):
- '''
- Take raw data from RL system and construct numpy object self.data.
- If data is from env, auto-swap the data to aeb standard shape.
- @param {[x: [y: [body_v]]} data_v As collected in RL sytem.
- @returns {array} data Tensor in standard aeb shape.
- '''
- new_data = np.array(data_v) # no type restriction, auto-infer
- if self.to_swap: # data from env has shape eab
- self.swap_data = new_data
- self.data = new_data.swapaxes(0, 1)
- else:
- self.data = new_data
- self.swap_data = new_data.swapaxes(0, 1)
- return self.data
-
- def get(self, a=None, e=None):
- '''
- Get the data projected on a or e axes for use by agent_space, env_space.
- @param {int} a The index a of an agent in agent_space
- @param {int} e The index e of an env in env_space
- @returns {array} data_x Where x is a or e.
- '''
- if e is None:
- return self.data[a]
- elif a is None:
- return self.swap_data[e]
- else:
- return self.data[a][e]
-
-
-class AEBSpace:
-
- def __init__(self, spec, info_space):
- self.info_space = info_space
- self.spec = spec
- self.clock = None # the finest common refinement as space clock
- self.agent_space = None
- self.env_space = None
- self.body_space = None
- (self.aeb_list, self.aeb_shape, self.aeb_sig) = self.get_aeb_info(self.spec)
- self.data_spaces = self.init_data_spaces()
-
- def get_aeb_info(cls, spec):
- '''
- Get from spec the aeb_list, aeb_shape and aeb_sig, which are used to resolve agent_space and env_space.
- @returns {list, (a,e,b), array([a, e, b])} aeb_list, aeb_shape, aeb_sig
- '''
- aeb_list = spec_util.resolve_aeb(spec)
- aeb_shape = util.get_aeb_shape(aeb_list)
- aeb_sig = np.full(aeb_shape, np.nan)
- for aeb in aeb_list:
- aeb_sig.itemset(aeb, 1)
- return aeb_list, aeb_shape, aeb_sig
-
- def init_data_spaces(self):
- self.data_spaces = {
- data_name: DataSpace(data_name, self)
- for data_name in AGENT_DATA_NAMES + ENV_DATA_NAMES
- }
- return self.data_spaces
-
- def init_data_s(self, data_names, a=None, e=None):
- '''Shortcut to init data_s_1, data_s_2, ...'''
- return tuple(self.data_spaces[data_name].init_data_s(a=a, e=e) for data_name in data_names)
-
- def init_data_v(self, data_names):
- '''Shortcut to init data_v_1, data_v_2, ...'''
- return tuple(self.data_spaces[data_name].init_data_v() for data_name in data_names)
-
- def init_body_space(self):
- '''Initialize the body_space (same class as data_space) used for AEB body resolution, and set reference in agents and envs'''
- self.body_space = DataSpace('body', self)
- body_v = np.full(self.aeb_shape, np.nan, dtype=object)
- for (a, e, b), sig in np.ndenumerate(self.aeb_sig):
- if sig == 1:
- env = self.env_space.get(e)
- body = Body(env, self.spec['agent'], aeb=(a, e, b), aeb_space=self)
- body_v[(a, e, b)] = body
- self.body_space.add(body_v)
- # complete the backward reference to env_space
- for env in self.env_space.envs:
- body_e = self.body_space.get(e=env.e)
- env.set_body_e(body_e)
- self.clock = self.env_space.get_base_clock()
- logger.info(util.self_desc(self))
- return self.body_space
-
- def add(self, data_name, data_v):
- '''
- Add a data to a data space, e.g. data actions collected per body, per agent, from agent_space, with AEB shape projected on a-axis, added to action_space.
- Could also be a shortcut to do batch add data_v_1, data_v_2, ...
- @param {str|[str]} data_name
- @param {[x: [yb_idx:[body_v]]} data_v, where x, y could be a, e interchangeably.
- @returns {DataSpace} data_space (aeb is implied)
- '''
- if ps.is_string(data_name):
- data_space = self.data_spaces[data_name]
- data_space.add(data_v)
- return data_space
- else:
- return tuple(self.add(d_name, d_v) for d_name, d_v in zip(data_name, data_v))
-
- def tick(self, unit=None):
- '''Tick all the clocks in env_space, and tell if all envs are done'''
- end_sessions = []
- for env in self.env_space.envs:
- if env.done:
- for body in env.nanflat_body_e:
- body.log_summary(body_df_kind='train')
- env.clock.tick(unit or ('epi' if env.done else 't'))
- end_session = not (env.clock.get(env.max_tick_unit) < env.max_tick)
- end_sessions.append(end_session)
- return all(end_sessions)
-
-
-class InfoSpace:
- def __init__(self, last_coor=None):
- '''
- Initialize the coor, the global point in info space that will advance according to experiment progress.
- The coor starts with null first since the coor may not start at the origin.
- '''
- self.coor = last_coor or {k: None for k in COOR_AXES}
- self.covered_space = []
- # used to id experiment sharing the same spec name
- self.experiment_ts = util.get_ts()
- # ckpt gets appened to extend prepath using util.get_prepath for saving models, e.g. ckpt_str = ckpt-epi10-totalt1000
- # ckpt = 'eval' is special for eval mode, so data files will save with `ckpt-eval`; no models will be saved, but to load models with normal ckpt it will find them using eval_model_prepath
- # e.g. 'epi24-totalt1000', 'eval', 'best'
- self.ckpt = None
- # e.g. 'data/dqn_cartpole_2018_12_19_085843/dqn_cartpole_t0_s0_ckpt-epi24-totalt1000'
- self.eval_model_prepath = None
-
- def reset_lower_axes(cls, coor, axis):
- '''Reset the axes lower than the given axis in coor'''
- axis_idx = COOR_AXES_ORDER[axis]
- for post_idx in range(axis_idx + 1, COOR_DIM):
- post_axis = COOR_AXES[post_idx]
- coor[post_axis] = None
- return coor
-
- def tick(self, axis):
- '''
- Advance the coor to the next point in axis (control unit class).
- If the axis value has been reset, update to 0, else increment. For all axes lower than the specified axis, reset to None.
- Note this will not skip coor in space, even though the covered space may not be rectangular.
- @example
-
- info_space.tick('session')
- session = Session(spec, info_space)
- '''
- assert axis in self.coor
- if axis == 'experiment':
- self.experiment_ts = util.get_ts()
- new_coor = self.coor.copy()
- if new_coor[axis] is None:
- new_coor[axis] = 0
- else:
- new_coor[axis] += 1
- new_coor = self.reset_lower_axes(new_coor, axis)
- self.covered_space.append(self.coor)
- self.coor = new_coor
- return self.coor
-
- def get(self, axis):
- return self.coor[axis]
-
- def set(self, axis, val):
- self.coor[axis] = val
- return self.coor[axis]
-
- def get_random_seed(self):
- '''Standard method to get random seed for a session'''
- return int(1e5 * (self.get('trial') or 0) + 1e3 * (self.get('session') or 0) + time.time())
diff --git a/slm_lab/experiment/retro_analysis.py b/slm_lab/experiment/retro_analysis.py
index b8f82bd58..28df6581b 100644
--- a/slm_lab/experiment/retro_analysis.py
+++ b/slm_lab/experiment/retro_analysis.py
@@ -1,249 +1,75 @@
-'''
-The retro analysis module
-Runs analysis after a lab run using existing data files
-e.g. yarn retro_analyze data/reinforce_cartpole_2018_01_22_211751
-'''
+# The retro analysis module
+# Runs analysis post-hoc using existing data files
+# example: yarn retro_analyze data/reinforce_cartpole_2018_01_22_211751/
+from glob import glob
from slm_lab.experiment import analysis
from slm_lab.lib import logger, util
-from slm_lab.spec import spec_util
-import numpy as np
import os
import pydash as ps
-import regex as re
logger = logger.get_logger(__name__)
-def session_data_from_file(predir, trial_index, session_index, ckpt=None, prefix=''):
- '''Build session.session_data from file'''
- ckpt_str = '' if ckpt is None else f'_ckpt-{ckpt}'
- for filename in os.listdir(predir):
- if filename.endswith(f'_t{trial_index}_s{session_index}{ckpt_str}_{prefix}session_df.csv'):
- filepath = f'{predir}/{filename}'
- session_df = util.read(filepath, header=[0, 1, 2, 3], index_col=0)
- session_data = util.session_df_to_data(session_df)
- return session_data
-
-
-def session_datas_from_file(predir, trial_spec, trial_index, ckpt=None):
- '''Return a dict of {session_index: session_data} for a trial'''
- session_datas = {}
- for s in range(trial_spec['meta']['max_session']):
- session_data = session_data_from_file(predir, trial_index, s, ckpt)
- if session_data is not None:
- session_datas[s] = session_data
- return session_datas
-
-
-def session_data_dict_from_file(predir, trial_index, ckpt=None):
- '''Build trial.session_data_dict from file'''
- ckpt_str = '' if ckpt is None else f'_ckpt-{ckpt}'
- session_data_dict = {}
- for filename in os.listdir(predir):
- if f'_t{trial_index}_' in filename and filename.endswith(f'{ckpt_str}_session_fitness_df.csv'):
- filepath = f'{predir}/{filename}'
- fitness_df = util.read(filepath, header=[0, 1, 2, 3], index_col=0, dtype=np.float32)
- util.fix_multi_index_dtype(fitness_df)
- session_index = fitness_df.index[0]
- session_data_dict[session_index] = fitness_df
- return session_data_dict
-
-
-def session_data_dict_for_dist(spec, info_space):
- '''Method to retrieve session_datas (fitness df, so the same as session_data_dict above) when a trial with distributed sessions is done, to avoid messy multiprocessing data communication'''
- prepath = util.get_prepath(spec, info_space)
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- session_datas = session_data_dict_from_file(predir, info_space.get('trial'), ps.get(info_space, 'ckpt'))
- session_datas = [session_datas[k] for k in sorted(session_datas.keys())]
- return session_datas
-
-
-def trial_data_dict_from_file(predir):
- '''Build experiment.trial_data_dict from file'''
- trial_data_dict = {}
- for filename in os.listdir(predir):
- if filename.endswith('_trial_data.json'):
- filepath = f'{predir}/{filename}'
- exp_trial_data = util.read(filepath)
- trial_index = exp_trial_data.pop('trial_index')
- trial_data_dict[trial_index] = exp_trial_data
- return trial_data_dict
-
-
-'''
-Interface retro methods
-'''
-
-
-def analyze_eval_trial(spec, info_space, predir):
- '''Create a trial and run analysis to get the trial graph and other trial data'''
- from slm_lab.experiment.control import Trial
- trial = Trial(spec, info_space)
- trial.session_data_dict = session_data_dict_from_file(predir, trial.index, ps.get(info_space, 'ckpt'))
- # don't zip for eval analysis, slow otherwise
- analysis.analyze_trial(trial, zip=False)
-
-
-def parallel_eval(spec, info_space, ckpt):
- '''
- Calls a subprocess to run lab in eval mode with the constructed ckpt prepath, same as how one would manually run the bash cmd
- @example
-
- python run_lab.py data/dqn_cartpole_2018_12_19_224811/dqn_cartpole_t0_spec.json dqn_cartpole eval@dqn_cartpole_t0_s1_ckpt-epi10-totalt1000
- '''
- prepath_t = util.get_prepath(spec, info_space, unit='trial')
- prepath_s = util.get_prepath(spec, info_space, unit='session')
- predir, _, prename, spec_name, _, _ = util.prepath_split(prepath_s)
- cmd = f'python run_lab.py {prepath_t}_spec.json {spec_name} eval@{prename}_ckpt-{ckpt}'
- logger.info(f'Running parallel eval for ckpt-{ckpt}')
- return util.run_cmd(cmd)
-
-
-def run_parallel_eval(session, agent, env):
- '''Plugin to session to run parallel eval for train mode'''
- if util.get_lab_mode() == 'train':
- ckpt = f'epi{env.clock.epi}-totalt{env.clock.total_t}'
- agent.save(ckpt=ckpt)
- # set reference to eval process for handling
- session.eval_proc = parallel_eval(session.spec, session.info_space, ckpt)
-
-
-def try_wait_parallel_eval(session):
- '''Plugin to wait for session's final parallel eval if any'''
- if hasattr(session, 'eval_proc') and session.eval_proc is not None: # wait for final eval before closing
- util.run_cmd_wait(session.eval_proc)
- session_retro_eval(session) # rerun failed eval
-
-
-def run_parallel_eval_from_prepath(prepath):
- '''Used by retro_eval'''
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- ckpt = util.find_ckpt(prepath)
- return parallel_eval(spec, info_space, ckpt)
-
-
-def run_wait_eval(prepath):
- '''Used by retro_eval'''
- eval_proc = run_parallel_eval_from_prepath(prepath)
- util.run_cmd_wait(eval_proc)
-
-
def retro_analyze_sessions(predir):
- '''Retro-analyze all session level datas.'''
- logger.info('Retro-analyzing sessions from file')
- from slm_lab.experiment.control import Session, SpaceSession
- for filename in os.listdir(predir):
- # to account for both types of session_df
- if filename.endswith('_session_df.csv'):
- body_df_kind = 'eval' # from body.eval_df
- prefix = ''
- is_session_df = True
- elif filename.endswith('_trainsession_df.csv'):
- body_df_kind = 'train' # from body.train_df
- prefix = 'train'
- is_session_df = True
- else:
- is_session_df = False
+ '''Retro analyze all sessions'''
+ logger.info('Running retro_analyze_sessions')
+ session_spec_paths = glob(f'{predir}/*_s*_spec.json')
+ util.parallelize(_retro_analyze_session, [(p,) for p in session_spec_paths], num_cpus=util.NUM_CPUS)
- if is_session_df:
- prepath = f'{predir}/{filename}'.replace(f'_{prefix}session_df.csv', '')
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- trial_index, session_index = util.prepath_to_idxs(prepath)
- SessionClass = Session if spec_util.is_singleton(spec) else SpaceSession
- session = SessionClass(spec, info_space)
- session_data = session_data_from_file(predir, trial_index, session_index, ps.get(info_space, 'ckpt'), prefix)
- analysis._analyze_session(session, session_data, body_df_kind)
+
+def _retro_analyze_session(session_spec_path):
+ '''Method to retro analyze a single session given only a path to its spec'''
+ session_spec = util.read(session_spec_path)
+ info_prepath = session_spec['meta']['info_prepath']
+ for df_mode in ('eval', 'train'):
+ session_df = util.read(f'{info_prepath}_session_df_{df_mode}.csv')
+ analysis.analyze_session(session_spec, session_df, df_mode)
def retro_analyze_trials(predir):
- '''Retro-analyze all trial level datas.'''
- logger.info('Retro-analyzing trials from file')
- from slm_lab.experiment.control import Trial
- filenames = ps.filter_(os.listdir(predir), lambda filename: filename.endswith('_trial_df.csv'))
- for idx, filename in enumerate(filenames):
- filepath = f'{predir}/{filename}'
- prepath = filepath.replace('_trial_df.csv', '')
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- trial_index, _ = util.prepath_to_idxs(prepath)
- trial = Trial(spec, info_space)
- trial.session_data_dict = session_data_dict_from_file(predir, trial_index, ps.get(info_space, 'ckpt'))
- # zip only at the last
- zip = (idx == len(filenames) - 1)
- trial_fitness_df = analysis.analyze_trial(trial, zip)
+ '''Retro analyze all trials'''
+ logger.info('Running retro_analyze_trials')
+ session_spec_paths = glob(f'{predir}/*_s*_spec.json')
+ # remove session spec paths
+ trial_spec_paths = ps.difference(glob(f'{predir}/*_t*_spec.json'), session_spec_paths)
+ util.parallelize(_retro_analyze_trial, [(p,) for p in trial_spec_paths], num_cpus=util.NUM_CPUS)
+
- # write trial_data that was written from ray search
- trial_data_filepath = filepath.replace('_trial_df.csv', '_trial_data.json')
- if os.path.exists(trial_data_filepath):
- fitness_vec = trial_fitness_df.iloc[0].to_dict()
- fitness = analysis.calc_fitness(trial_fitness_df)
- trial_data = util.read(trial_data_filepath)
- trial_data.update({
- **fitness_vec, 'fitness': fitness, 'trial_index': trial_index,
- })
- util.write(trial_data, trial_data_filepath)
+def _retro_analyze_trial(trial_spec_path):
+ '''Method to retro analyze a single trial given only a path to its spec'''
+ trial_spec = util.read(trial_spec_path)
+ meta_spec = trial_spec['meta']
+ info_prepath = meta_spec['info_prepath']
+ session_metrics_list = [util.read(f'{info_prepath}_s{s}_session_metrics_eval.pkl') for s in range(meta_spec['max_session'])]
+ analysis.analyze_trial(trial_spec, session_metrics_list)
def retro_analyze_experiment(predir):
- '''Retro-analyze all experiment level datas.'''
- logger.info('Retro-analyzing experiment from file')
- from slm_lab.experiment.control import Experiment
- _, _, _, spec_name, _, _ = util.prepath_split(predir)
- prepath = f'{predir}/{spec_name}'
- spec, info_space = util.prepath_to_spec_info_space(prepath)
- if 'search' not in spec:
- return
- experiment = Experiment(spec, info_space)
- experiment.trial_data_dict = trial_data_dict_from_file(predir)
- if not ps.is_empty(experiment.trial_data_dict):
- return analysis.analyze_experiment(experiment)
+ '''Retro analyze an experiment'''
+ logger.info('Running retro_analyze_experiment')
+ trial_spec_paths = glob(f'{predir}/*_t*_spec.json')
+ # remove trial and session spec paths
+ experiment_spec_paths = ps.difference(glob(f'{predir}/*_spec.json'), trial_spec_paths)
+ experiment_spec_path = experiment_spec_paths[0]
+ spec = util.read(experiment_spec_path)
+ info_prepath = spec['meta']['info_prepath']
+ if os.path.exists(f'{info_prepath}_trial_data_dict.json'):
+ return # only run analysis if experiment had been ran
+ trial_data_dict = util.read(f'{info_prepath}_trial_data_dict.json')
+ analysis.analyze_experiment(spec, trial_data_dict)
def retro_analyze(predir):
'''
- Method to analyze experiment from file after it ran.
- Read from files, constructs lab units, run retro analyses on all lab units.
- This method has no side-effects, i.e. doesn't overwrite data it should not.
+ Method to analyze experiment/trial from files after it ran.
@example
- yarn retro_analyze data/reinforce_cartpole_2018_01_22_211751
+ yarn retro_analyze data/reinforce_cartpole_2018_01_22_211751/
'''
- os.environ['PREPATH'] = f'{predir}/retro_analyze' # to prevent overwriting log file
- logger.info(f'Retro-analyzing {predir}')
+ predir = predir.strip('/') # sanitary
+ os.environ['LOG_PREPATH'] = f'{predir}/log/retro_analyze' # to prevent overwriting log file
+ logger.info(f'Running retro-analysis on {predir}')
retro_analyze_sessions(predir)
retro_analyze_trials(predir)
retro_analyze_experiment(predir)
-
-
-def retro_eval(predir, session_index=None):
- '''
- Method to run eval sessions by scanning a predir for ckpt files. Used to rerun failed eval sessions.
- @example
-
- yarn retro_eval data/reinforce_cartpole_2018_01_22_211751
- '''
- logger.info(f'Retro-evaluate sessions from predir {predir}')
- # collect all unique prepaths first
- prepaths = []
- s_filter = '' if session_index is None else f'_s{session_index}_'
- for filename in os.listdir(predir):
- if filename.endswith('model.pth') and s_filter in filename:
- res = re.search('.+epi(\d+)-totalt(\d+)', filename)
- if res is not None:
- prepath = f'{predir}/{res[0]}'
- if prepath not in prepaths:
- prepaths.append(prepath)
- if ps.is_empty(prepaths):
- return
-
- logger.info(f'Starting retro eval')
- np.random.shuffle(prepaths) # so that CUDA_ID by trial/session index is spread out
- rand_spec = util.prepath_to_spec(prepaths[0]) # get any prepath, read its max session
- max_session = rand_spec['meta']['max_session']
- util.parallelize_fn(run_wait_eval, prepaths, num_cpus=max_session)
-
-
-def session_retro_eval(session):
- '''retro_eval but for session at the end to rerun failed evals'''
- prepath = util.get_prepath(session.spec, session.info_space, unit='session')
- predir, _, _, _, _, _ = util.prepath_split(prepath)
- retro_eval(predir, session.index)
+ logger.info('Finished retro-analysis')
diff --git a/slm_lab/experiment/search.py b/slm_lab/experiment/search.py
index addd582ba..b49620f87 100644
--- a/slm_lab/experiment/search.py
+++ b/slm_lab/experiment/search.py
@@ -1,34 +1,16 @@
-from abc import ABC, abstractmethod
from copy import deepcopy
-from deap import creator, base, tools, algorithms
-from ray.tune import grid_search
-from ray.tune.suggest import variant_generator
-from slm_lab.experiment import analysis
from slm_lab.lib import logger, util
-from slm_lab.lib.decorator import lab_api
-import json
import numpy as np
-import os
import pydash as ps
import random
import ray
+import ray.tune as tune
import torch
logger = logger.get_logger(__name__)
-def register_ray_serializer():
- '''Helper to register so objects can be serialized in Ray'''
- from slm_lab.experiment.control import Experiment
- from slm_lab.experiment.monitor import InfoSpace
- import pandas as pd
- ray.register_custom_serializer(Experiment, use_pickle=True)
- ray.register_custom_serializer(InfoSpace, use_pickle=True)
- ray.register_custom_serializer(pd.DataFrame, use_pickle=True)
- ray.register_custom_serializer(pd.Series, use_pickle=True)
-
-
-def build_config_space(experiment):
+def build_config_space(spec):
'''
Build ray config space from flattened spec.search
Specify a config space in spec using `"{key}__{space_type}": {v}`.
@@ -47,249 +29,97 @@ def build_config_space(experiment):
'''
space_types = ('grid_search', 'choice', 'randint', 'uniform', 'normal')
config_space = {}
- for k, v in util.flatten_dict(experiment.spec['search']).items():
+ for k, v in util.flatten_dict(spec['search']).items():
key, space_type = k.split('__')
assert space_type in space_types, f'Please specify your search variable as {key}__ in one of {space_types}'
if space_type == 'grid_search':
- config_space[key] = grid_search(v)
+ config_space[key] = tune.grid_search(v)
elif space_type == 'choice':
- config_space[key] = lambda spec, v=v: random.choice(v)
+ config_space[key] = tune.sample_from(lambda spec, v=v: random.choice(v))
else:
np_fn = getattr(np.random, space_type)
- config_space[key] = lambda spec, v=v: np_fn(*v)
+ config_space[key] = tune.sample_from(lambda spec, v=v: np_fn(*v))
return config_space
-def calc_population_size(experiment):
- '''Calculate the population size for RandomSearch or EvolutionarySearch'''
- pop_size = 2 # x2 for more search coverage
- for k, v in util.flatten_dict(experiment.spec['search']).items():
- if '__' in k:
- key, space_type = k.split('__')
- else:
- key, space_type = k, 'grid_search'
- if space_type in ('grid_search', 'choice'):
- pop_size *= len(v)
- else:
- pop_size *= 3
- return pop_size
+def infer_trial_resources(spec):
+ '''Infer the resources_per_trial for ray from spec'''
+ meta_spec = spec['meta']
+ num_cpus = min(util.NUM_CPUS, meta_spec['max_session'])
+
+ use_gpu = any(agent_spec['net'].get('gpu') for agent_spec in spec['agent'])
+ requested_gpu = meta_spec['max_session'] if use_gpu else 0
+ gpu_count = torch.cuda.device_count() if torch.cuda.is_available() else 0
+ num_gpus = min(gpu_count, requested_gpu)
+ resources_per_trial = {'cpu': num_cpus, 'gpu': num_gpus}
+ return resources_per_trial
-def spec_from_config(experiment, config):
- '''Helper to create spec from config - variables in spec.'''
- spec = deepcopy(experiment.spec)
+def inject_config(spec, config):
+ '''Inject flattened config into SLM Lab spec.'''
+ spec = deepcopy(spec)
spec.pop('search', None)
for k, v in config.items():
ps.set_(spec, k, v)
return spec
-def create_remote_fn(experiment):
- ray_gpu = int(bool(ps.get(experiment.spec, 'agent.0.net.gpu') and torch.cuda.device_count()))
- # TODO fractional ray_gpu is broken
-
- @ray.remote(num_gpus=ray_gpu) # hack around bad Ray design of hard-coding
- def run_trial(experiment, config):
- trial_index = config.pop('trial_index')
- spec = spec_from_config(experiment, config)
- info_space = deepcopy(experiment.info_space)
- info_space.set('trial', trial_index)
- trial_fitness_df = experiment.init_trial_and_run(spec, info_space)
- fitness_vec = trial_fitness_df.iloc[0].to_dict()
- fitness = analysis.calc_fitness(trial_fitness_df)
- trial_data = {**config, **fitness_vec, 'fitness': fitness, 'trial_index': trial_index}
- prepath = util.get_prepath(spec, info_space, unit='trial')
- util.write(trial_data, f'{prepath}_trial_data.json')
- return trial_data
- return run_trial
-
-
-def get_ray_results(pending_ids, ray_id_to_config):
- '''Helper to wait and get ray results into a new trial_data_dict, or handle ray error'''
- trial_data_dict = {}
- for _t in range(len(pending_ids)):
- ready_ids, pending_ids = ray.wait(pending_ids, num_returns=1)
- ready_id = ready_ids[0]
- try:
- trial_data = ray.get(ready_id)
- trial_index = trial_data.pop('trial_index')
- trial_data_dict[trial_index] = trial_data
- except:
- logger.exception(f'Trial failed: {ray_id_to_config[ready_id]}')
- return trial_data_dict
-
-
-class RaySearch(ABC):
+def ray_trainable(config, reporter):
'''
- RaySearch module for Experiment - Ray API integration with Lab
- Abstract class ancestor to all RaySearch (using Ray).
- specifies the necessary design blueprint for agent to work in Lab.
- Mostly, implement just the abstract methods and properties.
+ Create an instance of a trainable function for ray: https://ray.readthedocs.io/en/latest/tune-usage.html#training-api
+ Lab needs a spec and a trial_index to be carried through config, pass them with config in ray.run() like so:
+ config = {
+ 'spec': spec,
+ 'trial_index': tune.sample_from(lambda spec: gen_trial_index()),
+ ... # normal ray config with sample, grid search etc.
+ }
'''
-
- def __init__(self, experiment):
- self.experiment = experiment
- self.config_space = build_config_space(experiment)
- logger.info(f'Running {util.get_class_name(self)}, with meta spec:\n{self.experiment.spec["meta"]}')
-
- @abstractmethod
- def generate_config(self):
- '''
- Generate the next config given config_space, may update belief first.
- Remember to update trial_index in config here, since run_trial() on ray.remote is not thread-safe.
- '''
- # use self.config_space to build config
- config['trial_index'] = self.experiment.info_space.tick('trial')['trial']
- raise NotImplementedError
- return config
-
- @abstractmethod
- @lab_api
- def run(self):
- '''
- Implement the main run_trial loop.
- Remember to call ray init and cleanup before and after loop.
- '''
- ray.init()
- register_ray_serializer()
- # loop for max_trial: generate_config(); run_trial.remote(config)
- ray.shutdown()
- raise NotImplementedError
- return trial_data_dict
-
-
-class RandomSearch(RaySearch):
-
- def generate_config(self):
- configs = [] # to accommodate for grid_search
- for resolved_vars, config in variant_generator._generate_variants(self.config_space):
- config['trial_index'] = self.experiment.info_space.tick('trial')['trial']
- configs.append(config)
- return configs
-
- @lab_api
- def run(self):
- run_trial = create_remote_fn(self.experiment)
- meta_spec = self.experiment.spec['meta']
- ray.init(**meta_spec.get('resources', {}))
- register_ray_serializer()
- max_trial = meta_spec['max_trial']
- trial_data_dict = {}
- ray_id_to_config = {}
- pending_ids = []
-
- for _t in range(max_trial):
- configs = self.generate_config()
- for config in configs:
- ray_id = run_trial.remote(self.experiment, config)
- ray_id_to_config[ray_id] = config
- pending_ids.append(ray_id)
-
- trial_data_dict.update(get_ray_results(pending_ids, ray_id_to_config))
- ray.shutdown()
- return trial_data_dict
-
-
-class EvolutionarySearch(RaySearch):
-
- def generate_config(self):
- for resolved_vars, config in variant_generator._generate_variants(self.config_space):
- # trial_index is set at population level
- return config
-
- def mutate(self, individual, indpb):
- '''
- Deap implementation for dict individual (config),
- mutate an attribute with some probability - resample using the generate_config method and ensuring the new value is different.
- @param {dict} individual Individual to be mutated.
- @param {float} indpb Independent probability for each attribute to be mutated.
- @returns A tuple of one individual.
- '''
- for k, v in individual.items():
- if random.random() < indpb:
- while True:
- new_ind = self.generate_config()
- if new_ind[k] != v:
- individual[k] = new_ind[k]
- break
- return individual,
-
- def cx_uniform(cls, ind1, ind2, indpb):
- '''
- Deap implementation for dict individual (config),
- do a uniform crossover that modify in place the two individuals. The attributes are swapped with probability indpd.
- @param {dict} ind1 The first individual participating in the crossover.
- @param {dict} ind2 The second individual participating in the crossover.
- @param {float} indpb Independent probabily for each attribute to be exchanged.
- @returns A tuple of two individuals.
- '''
- for k in ind1:
- if random.random() < indpb:
- ind1[k], ind2[k] = ind2[k], ind1[k]
- return ind1, ind2
-
- def init_deap(self):
- creator.create('FitnessMax', base.Fitness, weights=(1.0,))
- creator.create('Individual', dict, fitness=creator.FitnessMax)
- toolbox = base.Toolbox()
- toolbox.register('attr', self.generate_config)
- toolbox.register('individual', tools.initIterate,
- creator.Individual, toolbox.attr)
- toolbox.register('population', tools.initRepeat,
- list, toolbox.individual)
-
- toolbox.register('mate', self.cx_uniform, indpb=0.5)
- toolbox.register('mutate', self.mutate, indpb=1 /
- len(toolbox.individual()))
- toolbox.register('select', tools.selTournament, tournsize=3)
- return toolbox
-
- @lab_api
- def run(self):
- run_trial = create_remote_fn(self.experiment)
- meta_spec = self.experiment.spec['meta']
- ray.init(**meta_spec.get('resources', {}))
- register_ray_serializer()
- max_generation = meta_spec['max_generation']
- pop_size = meta_spec['max_trial'] or calc_population_size(self.experiment)
- logger.info(f'EvolutionarySearch max_generation: {max_generation}, population size: {pop_size}')
- trial_data_dict = {}
- config_hash = {} # config hash_str to trial_index
-
- toolbox = self.init_deap()
- population = toolbox.population(n=pop_size)
- for gen in range(1, max_generation + 1):
- logger.info(f'Running generation: {gen}/{max_generation}')
- ray_id_to_config = {}
- pending_ids = []
- for individual in population:
- config = dict(individual.items())
- hash_str = util.to_json(config, indent=0)
- if hash_str not in config_hash:
- trial_index = self.experiment.info_space.tick('trial')['trial']
- config_hash[hash_str] = config['trial_index'] = trial_index
- ray_id = run_trial.remote(self.experiment, config)
- ray_id_to_config[ray_id] = config
- pending_ids.append(ray_id)
- individual['trial_index'] = config_hash[hash_str]
-
- trial_data_dict.update(get_ray_results(pending_ids, ray_id_to_config))
-
- for individual in population:
- trial_index = individual.pop('trial_index')
- trial_data = trial_data_dict.get(trial_index, {'fitness': 0}) # if trial errored
- individual.fitness.values = trial_data['fitness'],
-
- preview = 'Fittest of population preview:'
- for individual in tools.selBest(population, k=min(10, pop_size)):
- preview += f'\nfitness: {individual.fitness.values[0]}, {individual}'
- logger.info(preview)
-
- # prepare offspring for next generation
- if gen < max_generation:
- population = toolbox.select(population, len(population))
- # Vary the pool of individuals
- population = algorithms.varAnd(population, toolbox, cxpb=0.5, mutpb=0.5)
-
- ray.shutdown()
- return trial_data_dict
+ from slm_lab.experiment.control import Trial
+ # restore data carried from ray.run() config
+ spec = config.pop('spec')
+ trial_index = config.pop('trial_index')
+ spec['meta']['trial'] = trial_index
+ spec = inject_config(spec, config)
+ # run SLM Lab trial
+ metrics = Trial(spec).run()
+ metrics.update(config) # carry config for analysis too
+ # ray report to carry data in ray trial.last_result
+ reporter(trial_data={trial_index: metrics})
+
+
+def run_ray_search(spec):
+ '''
+ Method to run ray search from experiment. Uses RandomSearch now.
+ TODO support for other ray search algorithms: https://ray.readthedocs.io/en/latest/tune-searchalg.html
+ '''
+ logger.info(f'Running ray search for spec {spec["name"]}')
+ # generate trial index to pass into Lab Trial
+ global trial_index # make gen_trial_index passable into ray.run
+ trial_index = -1
+
+ def gen_trial_index():
+ global trial_index
+ trial_index += 1
+ return trial_index
+
+ ray.init()
+
+ ray_trials = tune.run(
+ ray_trainable,
+ name=spec['name'],
+ config={
+ "spec": spec,
+ "trial_index": tune.sample_from(lambda spec: gen_trial_index()),
+ **build_config_space(spec)
+ },
+ resources_per_trial=infer_trial_resources(spec),
+ num_samples=spec['meta']['max_trial'],
+ queue_trials=True,
+ )
+ trial_data_dict = {} # data for Lab Experiment to analyze
+ for ray_trial in ray_trials:
+ ray_trial_data = ray_trial.last_result['trial_data']
+ trial_data_dict.update(ray_trial_data)
+
+ ray.shutdown()
+ return trial_data_dict
diff --git a/slm_lab/lib/__init__.py b/slm_lab/lib/__init__.py
index 456c86ceb..e69de29bb 100644
--- a/slm_lab/lib/__init__.py
+++ b/slm_lab/lib/__init__.py
@@ -1,4 +0,0 @@
-'''
-The generic lib module
-Contains generic library methods for the Lab
-'''
diff --git a/slm_lab/lib/decorator.py b/slm_lab/lib/decorator.py
index efec5baac..6178b8968 100644
--- a/slm_lab/lib/decorator.py
+++ b/slm_lab/lib/decorator.py
@@ -38,6 +38,6 @@ def time_fn(*args, **kwargs):
start = time.time()
output = fn(*args, **kwargs)
end = time.time()
- logger.debug3(f'Timed: {fn.__name__} {round((end - start) * 1000, 4)}ms')
+ logger.debug(f'Timed: {fn.__name__} {round((end - start) * 1000, 4)}ms')
return output
return time_fn
diff --git a/slm_lab/lib/distribution.py b/slm_lab/lib/distribution.py
new file mode 100644
index 000000000..6fed22812
--- /dev/null
+++ b/slm_lab/lib/distribution.py
@@ -0,0 +1,87 @@
+# Custom PyTorch distribution classes to be registered in policy_util.py
+# Mainly used by policy_util action distribution
+from torch import distributions
+import torch
+
+
+class Argmax(distributions.Categorical):
+ '''
+ Special distribution class for argmax sampling, where probability is always 1 for the argmax.
+ NOTE although argmax is not a sampling distribution, this implementation is for API consistency.
+ '''
+
+ def __init__(self, probs=None, logits=None, validate_args=None):
+ if probs is not None:
+ new_probs = torch.zeros_like(probs, dtype=torch.float)
+ new_probs[probs == probs.max(dim=-1, keepdim=True)[0]] = 1.0
+ probs = new_probs
+ elif logits is not None:
+ new_logits = torch.full_like(logits, -1e8, dtype=torch.float)
+ new_logits[logits == logits.max(dim=-1, keepdim=True)[0]] = 1.0
+ logits = new_logits
+
+ super().__init__(probs=probs, logits=logits, validate_args=validate_args)
+
+
+class GumbelCategorical(distributions.Categorical):
+ '''
+ Special Categorical using Gumbel distribution to simulate softmax categorical for discrete action.
+ Similar to OpenAI's https://github.com/openai/baselines/blob/98257ef8c9bd23a24a330731ae54ed086d9ce4a7/baselines/a2c/utils.py#L8-L10
+ Explanation http://amid.fish/assets/gumbel.html
+ '''
+
+ def sample(self, sample_shape=torch.Size()):
+ '''Gumbel softmax sampling'''
+ u = torch.empty(self.logits.size(), device=self.logits.device, dtype=self.logits.dtype).uniform_(0, 1)
+ noisy_logits = self.logits - torch.log(-torch.log(u))
+ return torch.argmax(noisy_logits, dim=0)
+
+
+class MultiCategorical(distributions.Categorical):
+ '''MultiCategorical as collection of Categoricals'''
+
+ def __init__(self, probs=None, logits=None, validate_args=None):
+ self.categoricals = []
+ if probs is None:
+ probs = [None] * len(logits)
+ elif logits is None:
+ logits = [None] * len(probs)
+ else:
+ raise ValueError('Either probs or logits must be None')
+
+ for sub_probs, sub_logits in zip(probs, logits):
+ categorical = distributions.Categorical(probs=sub_probs, logits=sub_logits, validate_args=validate_args)
+ self.categoricals.append(categorical)
+
+ @property
+ def logits(self):
+ return [cat.logits for cat in self.categoricals]
+
+ @property
+ def probs(self):
+ return [cat.probs for cat in self.categoricals]
+
+ @property
+ def param_shape(self):
+ return [cat.param_shape for cat in self.categoricals]
+
+ @property
+ def mean(self):
+ return torch.stack([cat.mean for cat in self.categoricals])
+
+ @property
+ def variance(self):
+ return torch.stack([cat.variance for cat in self.categoricals])
+
+ def sample(self, sample_shape=torch.Size()):
+ return torch.stack([cat.sample(sample_shape=sample_shape) for cat in self.categoricals])
+
+ def log_prob(self, value):
+ value_t = value.transpose(0, 1)
+ return torch.stack([cat.log_prob(value_t[idx]) for idx, cat in enumerate(self.categoricals)])
+
+ def entropy(self):
+ return torch.stack([cat.entropy() for cat in self.categoricals])
+
+ def enumerate_support(self):
+ return [cat.enumerate_support() for cat in self.categoricals]
diff --git a/slm_lab/lib/logger.py b/slm_lab/lib/logger.py
index 03d9199f3..ce62964b8 100644
--- a/slm_lab/lib/logger.py
+++ b/slm_lab/lib/logger.py
@@ -14,23 +14,19 @@ def append(self, e):
pass
-# extra debugging level deeper than the default debug
-NEW_LVLS = {'DEBUG2': 9, 'DEBUG3': 8}
-for name, val in NEW_LVLS.items():
- logging.addLevelName(val, name)
- setattr(logging, name, val)
LOG_FORMAT = '[%(asctime)s PID:%(process)d %(levelname)s %(filename)s %(funcName)s] %(message)s'
color_formatter = colorlog.ColoredFormatter('%(log_color)s[%(asctime)s PID:%(process)d %(levelname)s %(filename)s %(funcName)s]%(reset)s %(message)s')
sh = logging.StreamHandler(sys.stdout)
sh.setFormatter(color_formatter)
lab_logger = logging.getLogger()
lab_logger.handlers = FixedList([sh])
+logging.getLogger('ray').propagate = False # hack to mute poorly designed ray TF warning log
# this will trigger from Experiment init on reload(logger)
-if os.environ.get('PREPATH') is not None:
+if os.environ.get('LOG_PREPATH') is not None:
warnings.filterwarnings('ignore', category=pd.io.pytables.PerformanceWarning)
- log_filepath = os.environ['PREPATH'] + '.log'
+ log_filepath = os.environ['LOG_PREPATH'] + '.log'
os.makedirs(os.path.dirname(log_filepath), exist_ok=True)
# create file handler
formatter = logging.Formatter(LOG_FORMAT)
@@ -45,15 +41,6 @@ def append(self, e):
lab_logger.setLevel('INFO')
-def to_init(spec, info_space):
- '''
- Whether the lab's logger had been initialized:
- - prepath present in env
- - importlib.reload(logger) had been called
- '''
- return os.environ.get('PREPATH') is None
-
-
def set_level(lvl):
lab_logger.setLevel(lvl)
os.environ['LOG_LEVEL'] = lvl
@@ -67,14 +54,6 @@ def debug(msg, *args, **kwargs):
return lab_logger.debug(msg, *args, **kwargs)
-def debug2(msg, *args, **kwargs):
- return lab_logger.log(NEW_LVLS['DEBUG2'], msg, *args, **kwargs)
-
-
-def debug3(msg, *args, **kwargs):
- return lab_logger.log(NEW_LVLS['DEBUG3'], msg, *args, **kwargs)
-
-
def error(msg, *args, **kwargs):
return lab_logger.error(msg, *args, **kwargs)
@@ -87,23 +66,13 @@ def info(msg, *args, **kwargs):
return lab_logger.info(msg, *args, **kwargs)
-def warn(msg, *args, **kwargs):
- return lab_logger.warn(msg, *args, **kwargs)
+def warning(msg, *args, **kwargs):
+ return lab_logger.warning(msg, *args, **kwargs)
def get_logger(__name__):
'''Create a child logger specific to a module'''
- module_logger = logging.getLogger(__name__)
-
- def debug2(msg, *args, **kwargs):
- return module_logger.log(NEW_LVLS['DEBUG2'], msg, *args, **kwargs)
-
- def debug3(msg, *args, **kwargs):
- return module_logger.log(NEW_LVLS['DEBUG3'], msg, *args, **kwargs)
-
- setattr(module_logger, 'debug2', debug2)
- setattr(module_logger, 'debug3', debug3)
- return module_logger
+ return logging.getLogger(__name__)
def toggle_debug(modules, level='DEBUG'):
diff --git a/slm_lab/lib/math_util.py b/slm_lab/lib/math_util.py
index ce0c6d1a7..ee6da6a25 100644
--- a/slm_lab/lib/math_util.py
+++ b/slm_lab/lib/math_util.py
@@ -1,13 +1,54 @@
-'''
-Calculations used by algorithms
-All calculations for training shall have a standard API that takes in `batch` from algorithm.sample() method and return np array for calculation.
-`batch` is a dict containing keys to any data type you wish, e.g. {rewards: np.array([...])}
-'''
-from slm_lab.lib import logger
+# Various math calculations used by algorithms
import numpy as np
import torch
-logger = logger.get_logger(__name__)
+
+# general math methods
+
+def normalize(v):
+ '''Method to normalize a rank-1 np array'''
+ v_min = v.min()
+ v_max = v.max()
+ v_range = v_max - v_min
+ v_range += 1e-08 # division guard
+ v_norm = (v - v_min) / v_range
+ return v_norm
+
+
+def standardize(v):
+ '''Method to standardize a rank-1 np array'''
+ assert len(v) > 1, 'Cannot standardize vector of size 1'
+ v_std = (v - v.mean()) / (v.std() + 1e-08)
+ return v_std
+
+
+def to_one_hot(data, max_val):
+ '''Convert an int list of data into one-hot vectors'''
+ return np.eye(max_val)[np.array(data)]
+
+
+def venv_pack(batch_tensor, num_envs):
+ '''Apply the reverse of venv_unpack to pack a batch tensor from (b*num_envs, *shape) to (b, num_envs, *shape)'''
+ shape = list(batch_tensor.shape)
+ if len(shape) < 2: # scalar data (b, num_envs,)
+ return batch_tensor.view(-1, num_envs)
+ else: # non-scalar data (b, num_envs, *shape)
+ pack_shape = [-1, num_envs] + shape[1:]
+ return batch_tensor.view(pack_shape)
+
+
+def venv_unpack(batch_tensor):
+ '''
+ Unpack a sampled vec env batch tensor
+ e.g. for a state with original shape (4, ), vec env should return vec state with shape (num_envs, 4) to store in memory
+ When sampled with batch_size b, we should get shape (b, num_envs, 4). But we need to unpack the num_envs dimension to get (b * num_envs, 4) for passing to a network. This method does that.
+ '''
+ shape = list(batch_tensor.shape)
+ if len(shape) < 3: # scalar data (b, num_envs,)
+ return batch_tensor.view(-1)
+ else: # non-scalar data (b, num_envs, *shape)
+ unpack_shape = [-1] + shape[2:]
+ return batch_tensor.view(unpack_shape)
# Policy Gradient calc
@@ -15,57 +56,29 @@
def calc_returns(rewards, dones, gamma):
'''
- Calculate the simple returns (full rollout) for advantage
- i.e. sum discounted rewards up till termination
+ Calculate the simple returns (full rollout) i.e. sum discounted rewards up till termination
'''
- is_tensor = torch.is_tensor(rewards)
- if is_tensor:
- assert not torch.isnan(rewards).any()
- else:
- assert not np.any(np.isnan(rewards))
- # handle epi-end, to not sum past current episode
- not_dones = 1 - dones
T = len(rewards)
- if is_tensor:
- rets = torch.empty(T, dtype=torch.float32, device=rewards.device)
- else:
- rets = np.empty(T, dtype='float32')
- future_ret = 0.0
+ rets = torch.zeros_like(rewards)
+ future_ret = torch.tensor(0.0, dtype=rewards.dtype)
+ not_dones = 1 - dones
for t in reversed(range(T)):
- future_ret = rewards[t] + gamma * future_ret * not_dones[t]
- rets[t] = future_ret
+ rets[t] = future_ret = rewards[t] + gamma * future_ret * not_dones[t]
return rets
-def calc_nstep_returns(rewards, dones, gamma, n, next_v_preds):
+def calc_nstep_returns(rewards, dones, next_v_pred, gamma, n):
'''
- Calculate the n-step returns for advantage
- see n-step return in: http://www-anw.cs.umass.edu/~barto/courses/cs687/Chapter%207.pdf
- i.e. for each timestep t:
- sum discounted rewards up till step n (0 to n-1 that is),
- then add v_pred for n as final term
+ Calculate the n-step returns for advantage. Ref: http://www-anw.cs.umass.edu/~barto/courses/cs687/Chapter%207.pdf
+ Also see Algorithm S3 from A3C paper https://arxiv.org/pdf/1602.01783.pdf for the calculation used below
+ R^(n)_t = r_{t} + gamma r_{t+1} + ... + gamma^(n-1) r_{t+n-1} + gamma^(n) V(s_{t+n})
'''
- rets = rewards.clone() # prevent mutation
- next_v_preds = next_v_preds.clone() # prevent mutation
- nstep_rets = torch.zeros_like(rets) + rets
- cur_gamma = gamma
+ rets = torch.zeros_like(rewards)
+ future_ret = next_v_pred
not_dones = 1 - dones
- for i in range(1, n):
- # TODO shifting is expensive. rewrite
- # Shift returns by one and zero last element of each episode
- rets[:-1] = rets[1:]
- rets *= not_dones
- # Also shift V(s_t+1) so final terms use V(s_t+n)
- next_v_preds[:-1] = next_v_preds[1:]
- next_v_preds *= not_dones
- # Accumulate return
- nstep_rets += cur_gamma * rets
- # Update current gamma
- cur_gamma *= cur_gamma
- # Add final terms. Note no next state if epi is done
- final_terms = cur_gamma * next_v_preds * not_dones
- nstep_rets += final_terms
- return nstep_rets
+ for t in reversed(range(n)):
+ rets[t] = future_ret = rewards[t] + gamma * future_ret * not_dones[t]
+ return rets
def calc_gaes(rewards, dones, v_preds, gamma, lam):
@@ -78,16 +91,14 @@ def calc_gaes(rewards, dones, v_preds, gamma, lam):
NOTE any standardization is done outside of this method
'''
T = len(rewards)
- assert not torch.isnan(rewards).any()
assert T + 1 == len(v_preds) # v_preds includes states and 1 last next_state
- gaes = torch.empty(T, dtype=torch.float32, device=v_preds.device)
- future_gae = 0.0 # this will autocast to tensor below
+ gaes = torch.zeros_like(rewards)
+ future_gae = torch.tensor(0.0, dtype=rewards.dtype)
# to multiply with not_dones to handle episode boundary (last state has no V(s'))
not_dones = 1 - dones
for t in reversed(range(T)):
delta = rewards[t] + gamma * v_preds[t + 1] * not_dones[t] - v_preds[t]
gaes[t] = future_gae = delta + gamma * lam * not_dones[t] * future_gae
- assert not torch.isnan(gaes).any(), f'GAE has nan: {gaes}'
return gaes
@@ -96,23 +107,6 @@ def calc_q_value_logits(state_value, raw_advantages):
return state_value + raw_advantages - mean_adv
-def standardize(v):
- '''Method to standardize a rank-1 np array'''
- assert len(v) > 1, 'Cannot standardize vector of size 1'
- v_std = (v - v.mean()) / (v.std() + 1e-08)
- return v_std
-
-
-def normalize(v):
- '''Method to normalize a rank-1 np array'''
- v_min = v.min()
- v_max = v.max()
- v_range = v_max - v_min
- v_range += 1e-08 # division guard
- v_norm = (v - v_min) / v_range
- return v_norm
-
-
# generic variable decay methods
def no_decay(start_val, end_val, start_step, end_step, step):
@@ -159,35 +153,3 @@ def periodic_decay(start_val, end_val, start_step, end_step, step, frequency=60.
val = end_val * 0.5 * unit * (1 + np.cos(x) * (1 - x / x_freq))
val = max(val, end_val)
return val
-
-
-# misc math methods
-
-def is_outlier(points, thres=3.5):
- '''
- Detects outliers using MAD modified_z_score method, generalized to work on points.
- From https://stackoverflow.com/a/22357811/3865298
- @example
-
- is_outlier([1, 1, 1])
- # => array([False, False, False], dtype=bool)
- is_outlier([1, 1, 2])
- # => array([False, False, True], dtype=bool)
- is_outlier([[1, 1], [1, 1], [1, 2]])
- # => array([False, False, True], dtype=bool)
- '''
- points = np.array(points)
- if len(points.shape) == 1:
- points = points[:, None]
- median = np.median(points, axis=0)
- diff = np.sum((points - median)**2, axis=-1)
- diff = np.sqrt(diff)
- med_abs_deviation = np.median(diff)
- with np.errstate(divide='ignore', invalid='ignore'):
- modified_z_score = 0.6745 * diff / med_abs_deviation
- return modified_z_score > thres
-
-
-def to_one_hot(data, max_val):
- '''Convert an int list of data into one-hot vectors'''
- return np.eye(max_val)[np.array(data)]
diff --git a/slm_lab/lib/optimizer.py b/slm_lab/lib/optimizer.py
new file mode 100644
index 000000000..fecb379d8
--- /dev/null
+++ b/slm_lab/lib/optimizer.py
@@ -0,0 +1,102 @@
+# Custom PyTorch optimizer classes, to be registered in net_util.py
+import math
+import torch
+
+
+class GlobalAdam(torch.optim.Adam):
+ '''
+ Global Adam algorithm with shared states for Hogwild.
+ Adapted from https://github.com/ikostrikov/pytorch-a3c/blob/master/my_optim.py (MIT)
+ '''
+
+ def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0):
+ super().__init__(params, lr, betas, eps, weight_decay)
+
+ for group in self.param_groups:
+ for p in group['params']:
+ state = self.state[p]
+ state['step'] = torch.zeros(1)
+ state['exp_avg'] = p.data.new().resize_as_(p.data).zero_()
+ state['exp_avg_sq'] = p.data.new().resize_as_(p.data).zero_()
+
+ def share_memory(self):
+ for group in self.param_groups:
+ for p in group['params']:
+ state = self.state[p]
+ state['step'].share_memory_()
+ state['exp_avg'].share_memory_()
+ state['exp_avg_sq'].share_memory_()
+
+ def step(self, closure=None):
+ loss = None
+ if closure is not None:
+ loss = closure()
+
+ for group in self.param_groups:
+ for p in group['params']:
+ if p.grad is None:
+ continue
+ grad = p.grad.data
+ state = self.state[p]
+ exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
+ beta1, beta2 = group['betas']
+ state['step'] += 1
+ if group['weight_decay'] != 0:
+ grad = grad.add(group['weight_decay'], p.data)
+
+ # Decay the first and second moment running average coefficient
+ exp_avg.mul_(beta1).add_(1 - beta1, grad)
+ exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
+ denom = exp_avg_sq.sqrt().add_(group['eps'])
+ bias_correction1 = 1 - beta1 ** state['step'].item()
+ bias_correction2 = 1 - beta2 ** state['step'].item()
+ step_size = group['lr'] * math.sqrt(
+ bias_correction2) / bias_correction1
+ p.data.addcdiv_(-step_size, exp_avg, denom)
+ return loss
+
+
+class GlobalRMSprop(torch.optim.RMSprop):
+ '''
+ Global RMSprop algorithm with shared states for Hogwild.
+ Adapted from https://github.com/jingweiz/pytorch-rl/blob/master/optims/sharedRMSprop.py (MIT)
+ '''
+
+ def __init__(self, params, lr=1e-2, alpha=0.99, eps=1e-8, weight_decay=0):
+ super().__init__(params, lr=lr, alpha=alpha, eps=eps, weight_decay=weight_decay, momentum=0, centered=False)
+
+ # State initialisation (must be done before step, else will not be shared between threads)
+ for group in self.param_groups:
+ for p in group['params']:
+ state = self.state[p]
+ state['step'] = p.data.new().resize_(1).zero_()
+ state['square_avg'] = p.data.new().resize_as_(p.data).zero_()
+
+ def share_memory(self):
+ for group in self.param_groups:
+ for p in group['params']:
+ state = self.state[p]
+ state['step'].share_memory_()
+ state['square_avg'].share_memory_()
+
+ def step(self, closure=None):
+ loss = None
+ if closure is not None:
+ loss = closure()
+
+ for group in self.param_groups:
+ for p in group['params']:
+ if p.grad is None:
+ continue
+ grad = p.grad.data
+ state = self.state[p]
+ square_avg = state['square_avg']
+ alpha = group['alpha']
+ state['step'] += 1
+ if group['weight_decay'] != 0:
+ grad = grad.add(group['weight_decay'], p.data)
+
+ square_avg.mul_(alpha).addcmul_(1 - alpha, grad, grad)
+ avg = square_avg.sqrt().add_(group['eps'])
+ p.data.addcdiv_(-group['lr'], grad, avg)
+ return loss
diff --git a/slm_lab/lib/util.py b/slm_lab/lib/util.py
index c7a5dc3d0..81b28cf35 100644
--- a/slm_lab/lib/util.py
+++ b/slm_lab/lib/util.py
@@ -1,6 +1,8 @@
+from collections import deque
from contextlib import contextmanager
from datetime import datetime
from importlib import reload
+from pprint import pformat
from slm_lab import ROOT_DIR, EVAL_MODES
import cv2
import json
@@ -8,10 +10,12 @@
import operator
import os
import pandas as pd
+import pickle
import pydash as ps
import regex as re
import subprocess
import sys
+import time
import torch
import torch.multiprocessing as mp
import ujson
@@ -20,7 +24,6 @@
NUM_CPUS = mp.cpu_count()
FILE_TS_FORMAT = '%Y_%m_%d_%H%M%S'
RE_FILE_TS = re.compile(r'(\d{4}_\d{2}_\d{2}_\d{6})')
-SPACE_PATH = ['agent', 'agent_space', 'aeb_space', 'env_space', 'env']
class LabJsonEncoder(json.JSONEncoder):
@@ -35,6 +38,22 @@ def default(self, obj):
return str(obj)
+def batch_get(arr, idxs):
+ '''Get multi-idxs from an array depending if it's a python list or np.array'''
+ if isinstance(arr, (list, deque)):
+ return np.array(operator.itemgetter(*idxs)(arr))
+ else:
+ return arr[idxs]
+
+
+def calc_srs_mean_std(sr_list):
+ '''Given a list of series, calculate their mean and std'''
+ cat_df = pd.DataFrame(dict(enumerate(sr_list)))
+ mean_sr = cat_df.mean(axis=1)
+ std_sr = cat_df.std(axis=1)
+ return mean_sr, std_sr
+
+
def calc_ts_diff(ts2, ts1):
'''
Calculate the time from tss ts1 to ts2
@@ -93,21 +112,6 @@ def concat_batches(batches):
return concat_batch
-def cond_multiget(arr, idxs):
- '''Get multi-idxs from an array depending if it's a python list or np.array'''
- if isinstance(arr, list):
- return np.array(operator.itemgetter(*idxs)(arr))
- else:
- return arr[idxs]
-
-
-def count_nonan(arr):
- try:
- return np.count_nonzero(~np.isnan(arr))
- except Exception:
- return len(filter_nonan(arr))
-
-
def downcast_float32(df):
'''Downcast any float64 col to float32 to allow safer pandas comparison'''
for col in df.columns:
@@ -116,6 +120,14 @@ def downcast_float32(df):
return df
+def epi_done(done):
+ '''
+ General method to check if episode is done for both single and vectorized env
+ Only return True for singleton done since vectorized env does not have a natural episode boundary
+ '''
+ return np.isscalar(done) and done
+
+
def find_ckpt(prepath):
'''Find the ckpt-lorem-ipsum in a string and return lorem-ipsum'''
if 'ckpt' in prepath:
@@ -126,6 +138,14 @@ def find_ckpt(prepath):
return ckpt
+def frame_mod(frame, frequency, num_envs):
+ '''
+ Generic mod for (frame % frequency == 0) for when num_envs is 1 or more,
+ since frame will increase multiple ticks for vector env, use the remainder'''
+ remainder = num_envs or 1
+ return (frame % frequency < remainder)
+
+
def flatten_dict(obj, delim='.'):
'''Missing pydash method to flatten dict'''
nobj = {}
@@ -144,48 +164,6 @@ def flatten_dict(obj, delim='.'):
return nobj
-def filter_nonan(arr):
- '''Filter to np array with no nan'''
- try:
- return arr[~np.isnan(arr)]
- except Exception:
- mixed_type = []
- for v in arr:
- if not gen_isnan(v):
- mixed_type.append(v)
- return np.array(mixed_type, dtype=arr.dtype)
-
-
-def fix_multi_index_dtype(df):
- '''Restore aeb multi_index dtype from string to int, when read from file'''
- df.columns = pd.MultiIndex.from_tuples([(int(x[0]), int(x[1]), int(x[2]), x[3]) for x in df.columns])
- return df
-
-
-def nanflatten(arr):
- '''Flatten np array while ignoring nan, like np.nansum etc.'''
- flat_arr = arr.reshape(-1)
- return filter_nonan(flat_arr)
-
-
-def gen_isnan(v):
- '''Check isnan for general type (np.isnan is only operable on np type)'''
- try:
- return np.isnan(v).all()
- except Exception:
- return v is None
-
-
-def get_df_aeb_list(session_df):
- '''Get the aeb list for session_df for iterating.'''
- aeb_list = sorted(ps.uniq([(a, e, b) for a, e, b, col in session_df.columns.tolist()]))
- return aeb_list
-
-
-def get_aeb_shape(aeb_list):
- return np.amax(aeb_list, axis=0) + 1
-
-
def get_class_name(obj, lower=False):
'''Get the class name of an object'''
class_name = obj.__class__.__name__
@@ -228,19 +206,20 @@ def get_lab_mode():
return os.environ.get('lab_mode')
-def get_prepath(spec, info_space, unit='experiment'):
+def get_prepath(spec, unit='experiment'):
spec_name = spec['name']
- predir = f'data/{spec_name}_{info_space.experiment_ts}'
+ meta_spec = spec['meta']
+ predir = f'data/{spec_name}_{meta_spec["experiment_ts"]}'
prename = f'{spec_name}'
- trial_index = info_space.get('trial')
- session_index = info_space.get('session')
+ trial_index = meta_spec['trial']
+ session_index = meta_spec['session']
t_str = '' if trial_index is None else f'_t{trial_index}'
s_str = '' if session_index is None else f'_s{session_index}'
if unit == 'trial':
prename += t_str
elif unit == 'session':
prename += f'{t_str}{s_str}'
- ckpt = ps.get(info_space, 'ckpt')
+ ckpt = meta_spec['ckpt']
if ckpt is not None:
prename += f'_ckpt-{ckpt}'
prepath = f'{predir}/{prename}'
@@ -263,14 +242,12 @@ def get_ts(pattern=FILE_TS_FORMAT):
return ts
-def guard_data_a(cls, data_a, data_name):
- '''Guard data_a in case if it scalar, create a data_a and fill.'''
- if np.isscalar(data_a):
- new_data_a, = s_get(cls, 'aeb_space').init_data_s([data_name], a=cls.a)
- for eb, body in ndenumerate_nonan(cls.body_a):
- new_data_a[eb] = data_a
- data_a = new_data_a
- return data_a
+def insert_folder(prepath, folder):
+ '''Insert a folder into prepath'''
+ split_path = prepath.split('/')
+ prename = split_path.pop()
+ split_path += [folder, prename]
+ return '/'.join(split_path)
def in_eval_lab_modes():
@@ -294,7 +271,11 @@ def ctx_lab_mode(lab_mode):
Creates context to run method with a specific lab_mode
@example
with util.ctx_lab_mode('eval'):
- run_eval()
+ foo()
+
+ @util.ctx_lab_mode('eval')
+ def foo():
+ ...
'''
prev_lab_mode = os.environ.get('lab_mode')
os.environ['lab_mode'] = lab_mode
@@ -312,24 +293,14 @@ def monkey_patch(base_cls, extend_cls):
setattr(base_cls, fn, getattr(extend_cls, fn))
-def ndenumerate_nonan(arr):
- '''Generic ndenumerate for np.ndenumerate with only not gen_isnan values'''
- return (idx_v for idx_v in np.ndenumerate(arr) if not gen_isnan(idx_v[1]))
-
-
-def nonan_all(v):
- '''Generic np.all that also returns false if array is all np.nan'''
- return bool(np.all(v) and ~np.all(np.isnan(v)))
-
-
-def parallelize_fn(fn, args, num_cpus=NUM_CPUS):
+def parallelize(fn, args, num_cpus=NUM_CPUS):
'''
Parallelize a method fn, args and return results with order preserved per args.
- fn should take only a single arg.
+ args should be a list of tuples.
@returns {list} results Order preserved output from fn.
'''
pool = mp.Pool(num_cpus, maxtasksperchild=1)
- results = pool.map(fn, args)
+ results = pool.starmap(fn, args)
pool.close()
pool.join()
return results
@@ -352,7 +323,7 @@ def prepath_split(prepath):
if ckpt is not None: # separate ckpt
tail = tail.replace(f'_ckpt-{ckpt}', '')
if '/' in tail: # tail = prefolder/prename
- prefolder, prename = tail.split('/')
+ prefolder, prename = tail.split('/', 1)
else:
prefolder, prename = tail, None
predir = f'data/{prefolder}'
@@ -381,43 +352,28 @@ def prepath_to_idxs(prepath):
def prepath_to_spec(prepath):
- '''Create spec from prepath such that it returns the same prepath with info_space'''
- predir, _, prename, _, _, _ = prepath_split(prepath)
+ '''
+ Given a prepath, read the correct spec recover the meta_spec that will return the same prepath for eval lab modes
+ example: data/a2c_cartpole_2018_06_13_220436/a2c_cartpole_t0_s0
+ '''
+ predir, _, prename, _, experiment_ts, ckpt = prepath_split(prepath)
sidx_res = re.search('_s\d+', prename)
if sidx_res: # replace the _s0 if any
prename = prename.replace(sidx_res[0], '')
spec_path = f'{predir}/{prename}_spec.json'
# read the spec of prepath
spec = read(spec_path)
- return spec
-
-
-def prepath_to_info_space(prepath):
- '''Create info_space from prepath such that it returns the same prepath with spec'''
- from slm_lab.experiment.monitor import InfoSpace
- _, _, _, _, experiment_ts, ckpt = prepath_split(prepath)
+ # recover meta_spec
trial_index, session_index = prepath_to_idxs(prepath)
- # create info_space for prepath
- info_space = InfoSpace()
- info_space.experiment_ts = experiment_ts
- info_space.ckpt = ckpt
- info_space.set('experiment', 0)
- info_space.set('trial', trial_index)
- info_space.set('session', session_index)
- return info_space
-
-
-def prepath_to_spec_info_space(prepath):
- '''
- Given a prepath, read the correct spec and craete the info_space that will return the same prepath
- This is used for lab_mode: enjoy
- example: data/a2c_cartpole_2018_06_13_220436/a2c_cartpole_t0_s0
- '''
- spec = prepath_to_spec(prepath)
- info_space = prepath_to_info_space(prepath)
- check_prepath = get_prepath(spec, info_space, unit='session')
+ meta_spec = spec['meta']
+ meta_spec['experiment_ts'] = experiment_ts
+ meta_spec['ckpt'] = ckpt
+ meta_spec['experiment'] = 0
+ meta_spec['trial'] = trial_index
+ meta_spec['session'] = session_index
+ check_prepath = get_prepath(spec, unit='session')
assert check_prepath in prepath, f'{check_prepath}, {prepath}'
- return spec, info_space
+ return spec
def read(data_path, **kwargs):
@@ -452,6 +408,8 @@ def read(data_path, **kwargs):
ext = get_file_ext(data_path)
if ext == '.csv':
data = read_as_df(data_path, **kwargs)
+ elif ext == '.pkl':
+ data = read_as_pickle(data_path, **kwargs)
else:
data = read_as_plain(data_path, **kwargs)
return data
@@ -464,6 +422,13 @@ def read_as_df(data_path, **kwargs):
return data
+def read_as_pickle(data_path, **kwargs):
+ '''Submethod to read data as pickle'''
+ with open(data_path, 'rb') as f:
+ data = pickle.load(f)
+ return data
+
+
def read_as_plain(data_path, **kwargs):
'''Submethod to read data as plain type'''
open_file = open(data_path, 'r')
@@ -496,32 +461,6 @@ def run_cmd_wait(proc):
return output
-def s_get(cls, attr_path):
- '''
- Method to get attribute across space via inferring agent <-> env paths.
- @example
- self.agent.agent_space.aeb_space.clock
- # equivalently
- util.s_get(self, 'aeb_space.clock')
- '''
- from_class_name = get_class_name(cls, lower=True)
- from_idx = ps.find_index(SPACE_PATH, lambda s: from_class_name in (s, s.replace('_', '')))
- from_idx = max(from_idx, 0)
- attr_path = attr_path.split('.')
- to_idx = SPACE_PATH.index(attr_path[0])
- assert -1 not in (from_idx, to_idx)
- if from_idx < to_idx:
- path_link = SPACE_PATH[from_idx: to_idx]
- else:
- path_link = ps.reverse(SPACE_PATH[to_idx: from_idx])
-
- res = cls
- for attr in path_link + attr_path:
- if not (get_class_name(res, lower=True) in (attr, attr.replace('_', ''))):
- res = getattr(res, attr)
- return res
-
-
def self_desc(cls):
'''Method to get self description, used at init.'''
desc_list = [f'{get_class_name(cls)}:']
@@ -529,7 +468,7 @@ def self_desc(cls):
if k == 'spec':
desc_v = v['name']
elif ps.is_dict(v) or ps.is_dict(ps.head(v)):
- desc_v = to_json(v)
+ desc_v = pformat(v)
else:
desc_v = v
desc_list.append(f'- {k} = {desc_v}')
@@ -537,24 +476,6 @@ def self_desc(cls):
return desc
-def session_df_to_data(session_df):
- '''
- Convert a multi_index session_df (df) with column levels (a,e,b,col) to session_data[aeb] = aeb_df
- @example
-
- session_df = util.read(filepath, header=[0, 1, 2, 3])
- session_data = util.session_df_to_data(session_df)
- '''
- session_data = {}
- fix_multi_index_dtype(session_df)
- aeb_list = get_df_aeb_list(session_df)
- for aeb in aeb_list:
- aeb_df = session_df.loc[:, aeb]
- aeb_df.reset_index(inplace=True, drop=True) # guard for eval append-row
- session_data[aeb] = aeb_df
- return session_data
-
-
def set_attr(obj, attr_dict, keys=None):
'''Set attribute of an object from a dict'''
if keys is not None:
@@ -564,25 +485,46 @@ def set_attr(obj, attr_dict, keys=None):
return obj
-def set_rand_seed(random_seed, env_space):
- '''Set all the module random seeds'''
- torch.cuda.manual_seed_all(random_seed)
- torch.manual_seed(random_seed)
- np.random.seed(random_seed)
- envs = env_space.envs if hasattr(env_space, 'envs') else [env_space]
- for env in envs:
- try:
- env.u_env.seed(random_seed)
- except Exception as e:
- pass
+def set_cuda_id(spec):
+ '''Use trial and session id to hash and modulo cuda device count for a cuda_id to maximize device usage. Sets the net_spec for the base Net class to pick up.'''
+ # Don't trigger any cuda call if not using GPU. Otherwise will break multiprocessing on machines with CUDA.
+ # see issues https://github.com/pytorch/pytorch/issues/334 https://github.com/pytorch/pytorch/issues/3491 https://github.com/pytorch/pytorch/issues/9996
+ for agent_spec in spec['agent']:
+ if not agent_spec['net'].get('gpu'):
+ return
+ meta_spec = spec['meta']
+ trial_idx = meta_spec['trial'] or 0
+ session_idx = meta_spec['session'] or 0
+ if meta_spec['distributed'] == 'shared': # shared hogwild uses only global networks, offset them to idx 0
+ session_idx = 0
+ job_idx = trial_idx * meta_spec['max_session'] + session_idx
+ job_idx += meta_spec['cuda_offset']
+ device_count = torch.cuda.device_count()
+ cuda_id = None if not device_count else job_idx % device_count
+
+ for agent_spec in spec['agent']:
+ agent_spec['net']['cuda_id'] = cuda_id
-def set_logger(spec, info_space, logger, unit=None):
- '''Set the logger for a lab unit give its spec and info_space'''
- os.environ['PREPATH'] = get_prepath(spec, info_space, unit=unit)
+def set_logger(spec, logger, unit=None):
+ '''Set the logger for a lab unit give its spec'''
+ os.environ['LOG_PREPATH'] = insert_folder(get_prepath(spec, unit=unit), 'log')
reload(logger) # to set session-specific logger
+def set_random_seed(spec):
+ '''Generate and set random seed for relevant modules, and record it in spec.meta.random_seed'''
+ torch.set_num_threads(1) # prevent multithread slowdown, set again for hogwild
+ trial = spec['meta']['trial']
+ session = spec['meta']['session']
+ random_seed = int(1e5 * (trial or 0) + 1e3 * (session or 0) + time.time())
+ torch.cuda.manual_seed_all(random_seed)
+ torch.manual_seed(random_seed)
+ np.random.seed(random_seed)
+ spec['meta']['random_seed'] = random_seed
+ return random_seed
+
+
def _sizeof(obj, seen=None):
'''Recursively finds size of objects'''
size = sys.getsizeof(obj)
@@ -634,6 +576,21 @@ def smart_path(data_path, as_dir=False):
return os.path.normpath(data_path)
+def split_minibatch(batch, mb_size):
+ '''Split a batch into minibatches of mb_size or smaller, without replacement'''
+ size = len(batch['rewards'])
+ assert mb_size < size, f'Minibatch size {mb_size} must be < batch size {size}'
+ idxs = np.arange(size)
+ np.random.shuffle(idxs)
+ chunks = int(size / mb_size)
+ nested_idxs = np.array_split(idxs, chunks)
+ mini_batches = []
+ for minibatch_idxs in nested_idxs:
+ minibatch = {k: v[minibatch_idxs] for k, v in batch.items()}
+ mini_batches.append(minibatch)
+ return mini_batches
+
+
def to_json(d, indent=2):
'''Shorthand method for stringify JSON with indent'''
return json.dumps(d, indent=indent, cls=LabJsonEncoder)
@@ -650,31 +607,10 @@ def to_torch_batch(batch, device, is_episodic):
batch[k] = np.concatenate(batch[k])
elif ps.is_list(batch[k]):
batch[k] = np.array(batch[k])
- batch[k] = torch.from_numpy(batch[k].astype('float32')).to(device)
+ batch[k] = torch.from_numpy(batch[k].astype(np.float32)).to(device)
return batch
-def try_set_cuda_id(spec, info_space):
- '''Use trial and session id to hash and modulo cuda device count for a cuda_id to maximize device usage. Sets the net_spec for the base Net class to pick up.'''
- # Don't trigger any cuda call if not using GPU. Otherwise will break multiprocessing on machines with CUDA.
- # see issues https://github.com/pytorch/pytorch/issues/334 https://github.com/pytorch/pytorch/issues/3491 https://github.com/pytorch/pytorch/issues/9996
- for agent_spec in spec['agent']:
- if not agent_spec['net'].get('gpu'):
- return
- trial_idx = info_space.get('trial') or 0
- session_idx = info_space.get('session') or 0
- job_idx = trial_idx * spec['meta']['max_session'] + session_idx
- job_idx += int(os.environ.get('CUDA_ID_OFFSET', 0))
- device_count = torch.cuda.device_count()
- if device_count == 0:
- cuda_id = None
- else:
- cuda_id = job_idx % device_count
-
- for agent_spec in spec['agent']:
- agent_spec['net']['cuda_id'] = cuda_id
-
-
def write(data, data_path):
'''
Universal data writing method with smart data parsing
@@ -702,6 +638,8 @@ def write(data, data_path):
ext = get_file_ext(data_path)
if ext == '.csv':
write_as_df(data, data_path)
+ elif ext == '.pkl':
+ write_as_pickle(data, data_path)
else:
write_as_plain(data, data_path)
return data_path
@@ -711,7 +649,14 @@ def write_as_df(data, data_path):
'''Submethod to write data as DataFrame'''
df = cast_df(data)
ext = get_file_ext(data_path)
- df.to_csv(data_path)
+ df.to_csv(data_path, index=False)
+ return data_path
+
+
+def write_as_pickle(data, data_path):
+ '''Submethod to write data as pickle'''
+ with open(data_path, 'wb') as f:
+ pickle.dump(data, f)
return data_path
@@ -729,7 +674,26 @@ def write_as_plain(data, data_path):
return data_path
-# Atari image transformation
+# Atari image preprocessing
+
+
+def to_opencv_image(im):
+ '''Convert to OpenCV image shape h,w,c'''
+ shape = im.shape
+ if len(shape) == 3 and shape[0] < shape[-1]:
+ return im.transpose(1, 2, 0)
+ else:
+ return im
+
+
+def to_pytorch_image(im):
+ '''Convert to PyTorch image shape c,h,w'''
+ shape = im.shape
+ if len(shape) == 3 and shape[-1] < shape[0]:
+ return im.transpose(2, 0, 1)
+ else:
+ return im
+
def grayscale_image(im):
return cv2.cvtColor(im, cv2.COLOR_RGB2GRAY)
@@ -739,68 +703,35 @@ def resize_image(im, w_h):
return cv2.resize(im, w_h, interpolation=cv2.INTER_AREA)
-def crop_image(im):
- '''Crop away the unused top-bottom game borders of Atari'''
- return im[18:102, :]
-
-
def normalize_image(im):
'''Normalizing image by dividing max value 255'''
# NOTE: beware in its application, may cause loss to be 255 times lower due to smaller input values
return np.divide(im, 255.0)
-def nature_transform_image(im):
+def preprocess_image(im):
'''
- Image preprocessing from the paper "Playing Atari with Deep Reinforcement Learning, 2013, Mnih et al"
- Takes an RGB image and converts it to grayscale, downsizes to 110 x 84 and crops to square 84 x 84 without the game border
- '''
- im = grayscale_image(im)
- im = resize_image(im, (84, 110))
- im = crop_image(im)
- return im
-
-
-def openai_transform_image(im):
- '''
- Image transformation using OpenAI's baselines method: greyscale, resize
- Instead of cropping as done in nature_transform_image(), this resizes and stretches the image.
+ Image preprocessing using OpenAI Baselines method: grayscale, resize
+ This resize uses stretching instead of cropping
'''
+ im = to_opencv_image(im)
im = grayscale_image(im)
im = resize_image(im, (84, 84))
+ im = np.expand_dims(im, 0)
return im
-def transform_image(im, method='openai'):
- '''Apply image transformation using nature or openai method'''
- if method == 'nature':
- return nature_transform_image(im)
- elif method == 'openai':
- return openai_transform_image(im)
- else:
- raise ValueError('method must be one of: nature, openai')
-
-
-def debug_image(im, is_chw=True):
+def debug_image(im):
'''
Renders an image for debugging; pauses process until key press
Handles tensor/numpy and conventions among libraries
'''
if torch.is_tensor(im): # if PyTorch tensor, get numpy
im = im.cpu().numpy()
- if is_chw: # pytorch c,h,w convention
- im = np.transpose(im)
+ im = to_opencv_image(im)
im = im.astype(np.uint8) # typecast guard
if im.shape[0] == 3: # RGB image
# accommodate from RGB (numpy) to BGR (cv2)
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
cv2.imshow('debug image', im)
cv2.waitKey(0)
-
-
-def mpl_debug_image(im):
- '''Uses matplotlib to plot image with bigger size, axes, and false color on greyscaled images'''
- import matplotlib.pyplot as plt
- plt.figure()
- plt.imshow(im)
- plt.show()
diff --git a/slm_lab/lib/viz.py b/slm_lab/lib/viz.py
index cc2fa2043..f0154414a 100644
--- a/slm_lab/lib/viz.py
+++ b/slm_lab/lib/viz.py
@@ -1,31 +1,21 @@
-'''
-The data visualization module
-TODO pie, swarm, box plots
-'''
-from plotly import (
- graph_objs as go,
- offline as py,
- tools,
-)
+# The data visualization module
+# Defines plotting methods for analysis
+from plotly import graph_objs as go, io as pio, tools
+from plotly.offline import init_notebook_mode, iplot
from slm_lab.lib import logger, util
import colorlover as cl
import os
-import plotly
-import plotly.io as pio
import pydash as ps
-import sys
+logger = logger.get_logger(__name__)
-PLOT_FILEDIR = util.smart_path('data')
-os.makedirs(PLOT_FILEDIR, exist_ok=True)
+# warn orca failure only once
+orca_warn_once = ps.once(lambda e: logger.warning(f'Failed to generate graph. Run retro-analysis to generate graphs later.'))
if util.is_jupyter():
- py.init_notebook_mode(connected=True)
-logger = logger.get_logger(__name__)
+ init_notebook_mode(connected=True)
-def create_label(
- y_col, x_col,
- title=None, y_title=None, x_title=None, legend_name=None):
+def create_label(y_col, x_col, title=None, y_title=None, x_title=None, legend_name=None):
'''Create label dict for go.Layout with smart resolution'''
legend_name = legend_name or y_col
y_col_list, x_col_list, legend_name_list = ps.map_(
@@ -45,9 +35,7 @@ def create_label(
return label
-def create_layout(
- title, y_title, x_title, x_type=None,
- width=500, height=350, layout_kwargs=None):
+def create_layout(title, y_title, x_title, x_type=None, width=500, height=500, layout_kwargs=None):
'''simplified method to generate Layout'''
layout = go.Layout(
title=title,
@@ -61,12 +49,12 @@ def create_layout(
return layout
-def get_palette(aeb_count):
- '''Get the suitable palette to plot for some number of aeb graphs, where each aeb is a color.'''
- if aeb_count <= 8:
- palette = cl.scales[str(max(3, aeb_count))]['qual']['Set2']
+def get_palette(size):
+ '''Get the suitable palette of a certain size'''
+ if size <= 8:
+ palette = cl.scales[str(max(3, size))]['qual']['Set2']
else:
- palette = cl.interp(cl.scales['8']['qual']['Set2'], aeb_count)
+ palette = cl.interp(cl.scales['8']['qual']['Set2'], size)
return palette
@@ -76,162 +64,168 @@ def lower_opacity(rgb, opacity):
def plot(*args, **kwargs):
if util.is_jupyter():
- return py.iplot(*args, **kwargs)
- else:
- kwargs.update({'auto_open': ps.get(kwargs, 'auto_open', False)})
- return py.plot(*args, **kwargs)
+ return iplot(*args, **kwargs)
-def plot_go(
- df, y_col=None, x_col='index', y2_col=None,
- title=None, y_title=None, x_title=None, x_type=None,
- legend_name=None, width=500, height=350, draw=True,
- save=False, filename=None,
- trace_class='Scatter', trace_kwargs=None, layout_kwargs=None):
- '''
- Quickly plot from df using trace_class, e.g. go.Scatter
- 1. create_label() to auto-resolve labels
- 2. create_layout() with go.Layout() and update(layout_kwargs)
- 3. spread and create go.() and update(trace_kwargs)
- 4. Create the figure and plot accordingly
- @returns figure
- '''
- df = df.copy()
- if x_col == 'index':
- df['index'] = df.index.tolist()
-
- label = create_label(y_col, x_col, title, y_title, x_title, legend_name)
- layout = create_layout(
- x_type=x_type, width=width, height=height, layout_kwargs=layout_kwargs,
- **ps.pick(label, ['title', 'y_title', 'x_title']))
- y_col_list, x_col_list = label['y_col_list'], label['x_col_list']
-
- if y2_col is not None:
- label2 = create_label(y2_col, x_col, title, y_title, x_title, legend_name)
- layout.update(dict(yaxis2=dict(
- rangemode='tozero', title=label2['y_title'],
- side='right', overlaying='y1', anchor='x1',
- )))
- y2_col_list, x_col_list = label2['y_col_list'], label2['x_col_list']
- label2_legend_name_list = label2['legend_name_list']
- else:
- y2_col_list = []
- label2_legend_name_list = []
-
- combo_y_col_list = y_col_list + y2_col_list
- combo_legend_name_list = label['legend_name_list'] + label2_legend_name_list
- y_col_num, x_col_num = len(combo_y_col_list), len(x_col_list)
- trace_num = max(y_col_num, x_col_num)
- data = []
- for idx in range(trace_num):
- y_c = ps.get(combo_y_col_list, idx % y_col_num)
- x_c = ps.get(x_col_list, idx % x_col_num)
- df_y, df_x = ps.get(df, y_c), ps.get(df, x_c)
- trace = ps.get(go, trace_class)(y=df_y, x=df_x, name=combo_legend_name_list[idx])
- trace.update(trace_kwargs)
- if idx >= len(y_col_list):
- trace.update(dict(yaxis='y2', xaxis='x1'))
- data.append(trace)
-
- figure = go.Figure(data=data, layout=layout)
- if draw:
- plot(figure)
- if save:
- save_image(figure, filename=filename)
- return figure
-
-
-def plot_area(
- *args, fill='tonexty', stack=False,
- trace_kwargs=None, layout_kwargs=None,
- **kwargs):
- '''Plot area from df'''
- if stack:
- df, y_col = args[:2]
- stack_df = stack_cumsum(df, y_col)
- args = (stack_df,) + args[1:]
- trace_kwargs = ps.merge(dict(fill=fill, mode='lines', line=dict(width=1)), trace_kwargs)
- layout_kwargs = ps.merge(dict(), layout_kwargs)
- return plot_go(
- *args, trace_class='Scatter',
- trace_kwargs=trace_kwargs, layout_kwargs=layout_kwargs,
- **kwargs)
-
-
-def plot_bar(
- *args, barmode='stack', orientation='v',
- trace_kwargs=None, layout_kwargs=None,
- **kwargs):
- '''Plot bar chart from df'''
- trace_kwargs = ps.merge(dict(orientation=orientation), trace_kwargs)
- layout_kwargs = ps.merge(dict(barmode=barmode), layout_kwargs)
- return plot_go(
- *args, trace_class='Bar',
- trace_kwargs=trace_kwargs, layout_kwargs=layout_kwargs,
- **kwargs)
-
-
-def plot_line(
- *args,
- trace_kwargs=None, layout_kwargs=None,
- **kwargs):
- '''Plot line from df'''
- trace_kwargs = ps.merge(dict(mode='lines', line=dict(width=1)), trace_kwargs)
- layout_kwargs = ps.merge(dict(), layout_kwargs)
- return plot_go(
- *args, trace_class='Scatter',
- trace_kwargs=trace_kwargs, layout_kwargs=layout_kwargs,
- **kwargs)
-
-
-def plot_scatter(
- *args,
- trace_kwargs=None, layout_kwargs=None,
- **kwargs):
- '''Plot scatter from df'''
- trace_kwargs = ps.merge(dict(mode='markers'), trace_kwargs)
- layout_kwargs = ps.merge(dict(), layout_kwargs)
- return plot_go(
- *args, trace_class='Scatter',
- trace_kwargs=trace_kwargs, layout_kwargs=layout_kwargs,
- **kwargs)
-
-
-def plot_histogram(
- *args, barmode='overlay', xbins=None, histnorm='count', orientation='v',
- trace_kwargs=None, layout_kwargs=None,
- **kwargs):
- '''Plot histogram from df'''
- trace_kwargs = ps.merge(dict(orientation=orientation, xbins={}, histnorm=histnorm), trace_kwargs)
- layout_kwargs = ps.merge(dict(barmode=barmode), layout_kwargs)
- return plot_go(
- *args, trace_class='Histogram',
- trace_kwargs=trace_kwargs, layout_kwargs=layout_kwargs,
- **kwargs)
-
-
-def save_image(figure, filepath=None):
+def plot_sr(sr, time_sr, title, y_title, x_title):
+ '''Plot a series'''
+ x = time_sr.tolist()
+ color = get_palette(1)[0]
+ main_trace = go.Scatter(
+ x=x, y=sr, mode='lines', showlegend=False,
+ line={'color': color, 'width': 1},
+ )
+ data = [main_trace]
+ layout = create_layout(title=title, y_title=y_title, x_title=x_title)
+ fig = go.Figure(data, layout)
+ plot(fig)
+ return fig
+
+
+def plot_mean_sr(sr_list, time_sr, title, y_title, x_title):
+ '''Plot a list of series using its mean, with error bar using std'''
+ mean_sr, std_sr = util.calc_srs_mean_std(sr_list)
+ max_sr = mean_sr + std_sr
+ min_sr = mean_sr - std_sr
+ max_y = max_sr.tolist()
+ min_y = min_sr.tolist()
+ x = time_sr.tolist()
+ color = get_palette(1)[0]
+ main_trace = go.Scatter(
+ x=x, y=mean_sr, mode='lines', showlegend=False,
+ line={'color': color, 'width': 1},
+ )
+ envelope_trace = go.Scatter(
+ x=x + x[::-1], y=max_y + min_y[::-1], showlegend=False,
+ line={'color': 'rgba(0, 0, 0, 0)'},
+ fill='tozerox', fillcolor=lower_opacity(color, 0.2),
+ )
+ data = [main_trace, envelope_trace]
+ layout = create_layout(title=title, y_title=y_title, x_title=x_title)
+ fig = go.Figure(data, layout)
+ return fig
+
+
+def save_image(figure, filepath):
if os.environ['PY_ENV'] == 'test':
return
- if filepath is None:
- filepath = f'{PLOT_FILEDIR}/{ps.get(figure, "layout.title")}.png'
filepath = util.smart_path(filepath)
try:
pio.write_image(figure, filepath)
- logger.info(f'Graph saved to {filepath}')
except Exception as e:
- logger.warn(
- f'{e}\nFailed to generate graph. Fix the issue and run retro-analysis to generate graphs.')
-
-
-def stack_cumsum(df, y_col):
- '''Submethod to cumsum over y columns for stacked area plot'''
- y_col_list = util.cast_list(y_col)
- stack_df = df.copy()
- for idx in range(len(y_col_list)):
- col = y_col_list[idx]
- presum_idx = idx - 1
- if presum_idx > -1:
- presum_col = y_col_list[presum_idx]
- stack_df[col] += stack_df[presum_col]
- return stack_df
+ orca_warn_once(e)
+
+
+# analysis plot methods
+
+def plot_session(session_spec, session_metrics, session_df, df_mode='eval'):
+ '''
+ Plot the session graphs:
+ - mean_returns, strengths, sample_efficiencies, training_efficiencies, stabilities (with error bar)
+ - additional plots from session_df: losses, exploration variable, entropy
+ '''
+ meta_spec = session_spec['meta']
+ prepath = meta_spec['prepath']
+ graph_prepath = meta_spec['graph_prepath']
+ title = f'session graph: {session_spec["name"]} t{meta_spec["trial"]} s{meta_spec["session"]}'
+
+ local_metrics = session_metrics['local']
+ name_time_pairs = [
+ ('mean_returns', 'frames'),
+ ('strengths', 'frames'),
+ ('sample_efficiencies', 'frames'),
+ ('training_efficiencies', 'opt_steps'),
+ ('stabilities', 'frames')
+ ]
+ for name, time in name_time_pairs:
+ fig = plot_sr(
+ local_metrics[name], local_metrics[time], title, name, time)
+ save_image(fig, f'{graph_prepath}_session_graph_{df_mode}_{name}_vs_{time}.png')
+ if name in ('mean_returns',): # save important graphs in prepath directly
+ save_image(fig, f'{prepath}_session_graph_{df_mode}_{name}_vs_{time}.png')
+
+ if df_mode == 'eval':
+ return
+ # training plots from session_df
+ name_time_pairs = [
+ ('loss', 'frame'),
+ ('explore_var', 'frame'),
+ ('entropy', 'frame'),
+ ]
+ for name, time in name_time_pairs:
+ fig = plot_sr(
+ session_df[name], session_df[time], title, name, time)
+ save_image(fig, f'{graph_prepath}_session_graph_{df_mode}_{name}_vs_{time}.png')
+
+
+def plot_trial(trial_spec, trial_metrics):
+ '''
+ Plot the trial graphs:
+ - mean_returns, strengths, sample_efficiencies, training_efficiencies, stabilities (with error bar)
+ - consistencies (no error bar)
+ '''
+ meta_spec = trial_spec['meta']
+ prepath = meta_spec['prepath']
+ graph_prepath = meta_spec['graph_prepath']
+ title = f'trial graph: {trial_spec["name"]} t{meta_spec["trial"]} {meta_spec["max_session"]} sessions'
+
+ local_metrics = trial_metrics['local']
+ name_time_pairs = [
+ ('mean_returns', 'frames'),
+ ('strengths', 'frames'),
+ ('sample_efficiencies', 'frames'),
+ ('training_efficiencies', 'opt_steps'),
+ ('stabilities', 'frames'),
+ ('consistencies', 'frames'),
+ ]
+ for name, time in name_time_pairs:
+ if name == 'consistencies':
+ fig = plot_sr(
+ local_metrics[name], local_metrics[time], title, name, time)
+ else:
+ fig = plot_mean_sr(
+ local_metrics[name], local_metrics[time], title, name, time)
+ save_image(fig, f'{graph_prepath}_trial_graph_{name}_vs_{time}.png')
+ if name in ('mean_returns',): # save important graphs in prepath directly
+ save_image(fig, f'{prepath}_trial_graph_{name}_vs_{time}.png')
+
+
+def plot_experiment(experiment_spec, experiment_df, metrics_cols):
+ '''
+ Plot the metrics vs. specs parameters of an experiment, where each point is a trial.
+ ref colors: https://plot.ly/python/heatmaps-contours-and-2dhistograms-tutorial/#plotlys-predefined-color-scales
+ '''
+ y_cols = metrics_cols
+ x_cols = ps.difference(experiment_df.columns.tolist(), y_cols)
+ fig = tools.make_subplots(rows=len(y_cols), cols=len(x_cols), shared_xaxes=True, shared_yaxes=True, print_grid=False)
+ strength_sr = experiment_df['strength']
+ min_strength = strength_sr.values.min()
+ max_strength = strength_sr.values.max()
+ for row_idx, y in enumerate(y_cols):
+ for col_idx, x in enumerate(x_cols):
+ x_sr = experiment_df[x]
+ guard_cat_x = x_sr.astype(str) if x_sr.dtype == 'object' else x_sr
+ trace = go.Scatter(
+ y=experiment_df[y], yaxis=f'y{row_idx+1}',
+ x=guard_cat_x, xaxis=f'x{col_idx+1}',
+ showlegend=False, mode='markers',
+ marker={
+ 'symbol': 'circle-open-dot', 'color': experiment_df['strength'], 'opacity': 0.5,
+ # dump first quarter of colorscale that is too bright
+ 'cmin': min_strength - 0.50 * (max_strength - min_strength), 'cmax': max_strength,
+ 'colorscale': 'YlGnBu', 'reversescale': True
+ },
+ )
+ fig.add_trace(trace, row_idx + 1, col_idx + 1)
+ fig.layout[f'xaxis{col_idx+1}'].update(title='
'.join(ps.chunk(x, 20)), zerolinewidth=1, categoryarray=sorted(guard_cat_x.unique()))
+ fig.layout[f'yaxis{row_idx+1}'].update(title=y, rangemode='tozero')
+ fig.layout.update(
+ title=f'experiment graph: {experiment_spec["name"]}',
+ width=100 + 300 * len(x_cols), height=200 + 300 * len(y_cols))
+ plot(fig)
+ graph_prepath = experiment_spec['meta']['graph_prepath']
+ save_image(fig, f'{graph_prepath}_experiment_graph.png')
+ # save important graphs in prepath directly
+ prepath = experiment_spec['meta']['prepath']
+ save_image(fig, f'{prepath}_experiment_graph.png')
+ return fig
diff --git a/slm_lab/spec/__init__.py b/slm_lab/spec/__init__.py
index 6bf7be66c..e69de29bb 100644
--- a/slm_lab/spec/__init__.py
+++ b/slm_lab/spec/__init__.py
@@ -1,5 +0,0 @@
-'''
-The spec module
-Handles the Lab experiment spec: reading, writing(evolution), validation and default setting
-Expands the spec and params into consumable inputs in info space for lab units.
-'''
diff --git a/slm_lab/spec/_fitness_std.json b/slm_lab/spec/_fitness_std.json
deleted file mode 100644
index 182bebc5d..000000000
--- a/slm_lab/spec/_fitness_std.json
+++ /dev/null
@@ -1,97 +0,0 @@
-{
- "template": {
- "rand_epi_reward": 0,
- "std_epi_reward": 1,
- "std_timestep": 1000000
- },
- "Acrobot-v1": {
- "rand_epi_reward": -500,
- "std_epi_reward": -50,
- "std_timestep": 200000
- },
- "CartPole-v0": {
- "rand_epi_reward": 22,
- "std_epi_reward": 195,
- "std_timestep": 50000
- },
- "MountainCar-v0": {
- "rand_epi_reward": -200,
- "std_epi_reward": -110,
- "std_timestep": 200000
- },
- "MountainCarContinuous-v0": {
- "rand_epi_reward": -33,
- "std_epi_reward": 90,
- "std_timestep": 200000
- },
- "Pendulum-v0": {
- "rand_epi_reward": -1200,
- "std_epi_reward": -130,
- "std_timestep": 200000
- },
- "BipedalWalker-v2": {
- "rand_epi_reward": -100,
- "std_epi_reward": 300 ,
- "std_timestep": 200000
- },
- "BipedalWalkerHardcore-v2": {
- "rand_epi_reward": -100,
- "std_epi_reward": 300,
- "std_timestep": 200000
- },
- "CarRacing-v0": {
- "rand_epi_reward": -100,
- "std_epi_reward": 900,
- "std_timestep": 200000
- },
- "LunarLander-v2": {
- "rand_epi_reward": -250,
- "std_epi_reward": 200,
- "std_timestep": 300000
- },
- "LunarLanderContinuous-v2": {
- "rand_epi_reward": -250,
- "std_epi_reward": 200,
- "std_timestep": 300000
- },
- "BeamRiderNoFrameskip-v4": {
- "rand_epi_reward": 363.9,
- "std_epi_reward": 6846,
- "std_timestep": 10000000
- },
- "BreakoutNoFrameskip-v4": {
- "rand_epi_reward": 1.7,
- "std_epi_reward": 401.2,
- "std_timestep": 10000000
- },
- "EnduroNoFrameskip-v4": {
- "rand_epi_reward": 0,
- "std_epi_reward": 301.8,
- "std_timestep": 10000000
- },
- "MsPacmanNoFrameskip-v4": {
- "rand_epi_reward": 307.3,
- "std_epi_reward": 2311,
- "std_timestep": 10000000
- },
- "PongNoFrameskip-v4": {
- "rand_epi_reward": -20.7,
- "std_epi_reward": 18.9,
- "std_timestep": 10000000
- },
- "QbertNoFrameskip-v4": {
- "rand_epi_reward": 163.9,
- "std_epi_reward": 10596,
- "std_timestep": 10000000
- },
- "SeaquestNoFrameskip-v4": {
- "rand_epi_reward": 68.4,
- "std_epi_reward": 5286,
- "std_timestep": 10000000
- },
- "SpaceInvadersNoFrameskip-v4": {
- "rand_epi_reward": 148,
- "std_epi_reward": 1976,
- "std_timestep": 10000000
- },
-}
diff --git a/slm_lab/spec/_random_baseline.json b/slm_lab/spec/_random_baseline.json
new file mode 100644
index 000000000..13c07bf81
--- /dev/null
+++ b/slm_lab/spec/_random_baseline.json
@@ -0,0 +1,3102 @@
+{
+ "Copy-v0": {
+ "mean": -0.20500000000000002,
+ "std": 0.587771213994016
+ },
+ "RepeatCopy-v0": {
+ "mean": -0.18,
+ "std": 0.5455272678794341
+ },
+ "ReversedAddition-v0": {
+ "mean": -0.115,
+ "std": 0.67769831045975
+ },
+ "ReversedAddition3-v0": {
+ "mean": -0.06,
+ "std": 0.7819207120929841
+ },
+ "DuplicatedInput-v0": {
+ "mean": -0.195,
+ "std": 0.6200604809210141
+ },
+ "Reverse-v0": {
+ "mean": 0.26,
+ "std": 1.049952379872535
+ },
+ "CartPole-v0": {
+ "mean": 21.86,
+ "std": 10.718227465397439
+ },
+ "CartPole-v1": {
+ "mean": 22.64,
+ "std": 13.65834543420249
+ },
+ "MountainCar-v0": {
+ "mean": -200.0,
+ "std": 0.0
+ },
+ "MountainCarContinuous-v0": {
+ "mean": -33.304518895110284,
+ "std": 1.022343508110212
+ },
+ "Pendulum-v0": {
+ "mean": -1206.5607939097736,
+ "std": 289.6515888782244
+ },
+ "Acrobot-v1": {
+ "mean": -499.58,
+ "std": 2.94
+ },
+ "LunarLander-v2": {
+ "mean": -162.2394118221398,
+ "std": 97.54473995307002
+ },
+ "LunarLanderContinuous-v2": {
+ "mean": -188.2473711551503,
+ "std": 112.75910737272488
+ },
+ "BipedalWalker-v2": {
+ "mean": -98.31056339884668,
+ "std": 13.899485794318384
+ },
+ "BipedalWalkerHardcore-v2": {
+ "mean": -108.32967609699128,
+ "std": 12.116284033395456
+ },
+ "Blackjack-v0": {
+ "mean": -0.42,
+ "std": 0.8623224454924041
+ },
+ "KellyCoinflip-v0": {
+ "mean": 30.0,
+ "std": 81.24038404635961
+ },
+ "KellyCoinflipGeneralized-v0": {
+ "mean": 62717.09,
+ "std": 328657.14334869076
+ },
+ "FrozenLake-v0": {
+ "mean": 0.02,
+ "std": 0.13999999999999901
+ },
+ "FrozenLake8x8-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "CliffWalking-v0": {
+ "mean": -67125.59,
+ "std": 68747.06277974282
+ },
+ "NChain-v0": {
+ "mean": 1318.2,
+ "std": 75.81741224811091
+ },
+ "Roulette-v0": {
+ "mean": -0.73,
+ "std": 7.41869934692059
+ },
+ "Taxi-v2": {
+ "mean": -771.68,
+ "std": 99.3736262798133
+ },
+ "GuessingGame-v0": {
+ "mean": 0.13,
+ "std": 0.336303434416004
+ },
+ "HotterColder-v0": {
+ "mean": 81.12035574448731,
+ "std": 10.84244638829641
+ },
+ "Adventure-v0": {
+ "mean": -0.47,
+ "std": 0.49909918853871116
+ },
+ "Adventure-v4": {
+ "mean": -0.86,
+ "std": 0.346987031457949
+ },
+ "AdventureDeterministic-v0": {
+ "mean": -0.89,
+ "std": 0.31288975694324034
+ },
+ "AdventureDeterministic-v4": {
+ "mean": -0.9,
+ "std": 0.29999999999999905
+ },
+ "AdventureNoFrameskip-v0": {
+ "mean": -0.96,
+ "std": 0.19595917942265428
+ },
+ "AdventureNoFrameskip-v4": {
+ "mean": -0.89,
+ "std": 0.31288975694324
+ },
+ "Adventure-ram-v0": {
+ "mean": -0.52,
+ "std": 0.4995998398718718
+ },
+ "Adventure-ram-v4": {
+ "mean": -0.87,
+ "std": 0.336303434416004
+ },
+ "Adventure-ramDeterministic-v0": {
+ "mean": -0.87,
+ "std": 0.33630343441600474
+ },
+ "Adventure-ramDeterministic-v4": {
+ "mean": -0.89,
+ "std": 0.31288975694324
+ },
+ "Adventure-ramNoFrameskip-v0": {
+ "mean": -0.94,
+ "std": 0.23748684174075835
+ },
+ "Adventure-ramNoFrameskip-v4": {
+ "mean": -0.85,
+ "std": 0.35707142142714204
+ },
+ "AirRaid-v0": {
+ "mean": 560.25,
+ "std": 356.98555643050884
+ },
+ "AirRaid-v4": {
+ "mean": 544.0,
+ "std": 397.8397918760767
+ },
+ "AirRaidDeterministic-v0": {
+ "mean": 554.5,
+ "std": 411.7854417047791
+ },
+ "AirRaidDeterministic-v4": {
+ "mean": 575.25,
+ "std": 356.43188339428895
+ },
+ "AirRaidNoFrameskip-v0": {
+ "mean": 511.0,
+ "std": 322.8258044208982
+ },
+ "AirRaidNoFrameskip-v4": {
+ "mean": 486.0,
+ "std": 243.34440614076175
+ },
+ "AirRaid-ram-v0": {
+ "mean": 661.75,
+ "std": 483.05609146350696
+ },
+ "AirRaid-ram-v4": {
+ "mean": 631.25,
+ "std": 420.13948576633453
+ },
+ "AirRaid-ramDeterministic-v0": {
+ "mean": 574.5,
+ "std": 382.39344921167253
+ },
+ "AirRaid-ramDeterministic-v4": {
+ "mean": 604.25,
+ "std": 363.6285020457005
+ },
+ "AirRaid-ramNoFrameskip-v0": {
+ "mean": 531.0,
+ "std": 318.867527352661
+ },
+ "AirRaid-ramNoFrameskip-v4": {
+ "mean": 531.0,
+ "std": 316.34870001313425
+ },
+ "Alien-v0": {
+ "mean": 189.4,
+ "std": 123.06762368714205
+ },
+ "Alien-v4": {
+ "mean": 159.7,
+ "std": 43.09187858518122
+ },
+ "AlienDeterministic-v0": {
+ "mean": 200.2,
+ "std": 84.22564929996088
+ },
+ "AlienDeterministic-v4": {
+ "mean": 193.7,
+ "std": 65.33995714721583
+ },
+ "AlienNoFrameskip-v0": {
+ "mean": 119.7,
+ "std": 35.48112174100475
+ },
+ "AlienNoFrameskip-v4": {
+ "mean": 97.0,
+ "std": 30.44667469527666
+ },
+ "Alien-ram-v0": {
+ "mean": 168.7,
+ "std": 53.34144729944998
+ },
+ "Alien-ram-v4": {
+ "mean": 180.5,
+ "std": 164.53798953433216
+ },
+ "Alien-ramDeterministic-v0": {
+ "mean": 202.1,
+ "std": 111.94011792025232
+ },
+ "Alien-ramDeterministic-v4": {
+ "mean": 202.5,
+ "std": 82.21161718394791
+ },
+ "Alien-ramNoFrameskip-v0": {
+ "mean": 117.0,
+ "std": 29.8496231131986
+ },
+ "Alien-ramNoFrameskip-v4": {
+ "mean": 101.9,
+ "std": 32.30154795052398
+ },
+ "Amidar-v0": {
+ "mean": 2.76,
+ "std": 3.1084401232772687
+ },
+ "Amidar-v4": {
+ "mean": 2.0,
+ "std": 2.690724809414742
+ },
+ "AmidarDeterministic-v0": {
+ "mean": 4.95,
+ "std": 10.864966635935888
+ },
+ "AmidarDeterministic-v4": {
+ "mean": 2.86,
+ "std": 2.905236651290218
+ },
+ "AmidarNoFrameskip-v0": {
+ "mean": 2.11,
+ "std": 3.3163081883323207
+ },
+ "AmidarNoFrameskip-v4": {
+ "mean": 1.8,
+ "std": 2.603843313258307
+ },
+ "Amidar-ram-v0": {
+ "mean": 1.73,
+ "std": 2.5878755766071904
+ },
+ "Amidar-ram-v4": {
+ "mean": 2.12,
+ "std": 3.007590397643934
+ },
+ "Amidar-ramDeterministic-v0": {
+ "mean": 3.36,
+ "std": 4.107359248957899
+ },
+ "Amidar-ramDeterministic-v4": {
+ "mean": 2.5,
+ "std": 2.787471972953271
+ },
+ "Amidar-ramNoFrameskip-v0": {
+ "mean": 2.07,
+ "std": 5.9485376354193145
+ },
+ "Amidar-ramNoFrameskip-v4": {
+ "mean": 1.8399999999999999,
+ "std": 2.6747710182368882
+ },
+ "Assault-v0": {
+ "mean": 238.14,
+ "std": 77.05712426505417
+ },
+ "Assault-v4": {
+ "mean": 266.28,
+ "std": 80.23429192059963
+ },
+ "AssaultDeterministic-v0": {
+ "mean": 229.53,
+ "std": 65.6232359762912
+ },
+ "AssaultDeterministic-v4": {
+ "mean": 249.9,
+ "std": 64.00695274733832
+ },
+ "AssaultNoFrameskip-v0": {
+ "mean": 304.08,
+ "std": 98.56497146552623
+ },
+ "AssaultNoFrameskip-v4": {
+ "mean": 308.28,
+ "std": 87.69254016163518
+ },
+ "Assault-ram-v0": {
+ "mean": 265.44,
+ "std": 88.67472244106547
+ },
+ "Assault-ram-v4": {
+ "mean": 258.3,
+ "std": 73.79939024138342
+ },
+ "Assault-ramDeterministic-v0": {
+ "mean": 247.38,
+ "std": 75.16592046931906
+ },
+ "Assault-ramDeterministic-v4": {
+ "mean": 234.36,
+ "std": 73.69294674526186
+ },
+ "Assault-ramNoFrameskip-v0": {
+ "mean": 290.64,
+ "std": 71.81385938661144
+ },
+ "Assault-ramNoFrameskip-v4": {
+ "mean": 309.75,
+ "std": 88.31867016661879
+ },
+ "Asterix-v0": {
+ "mean": 257.0,
+ "std": 145.2618325645109
+ },
+ "Asterix-v4": {
+ "mean": 298.5,
+ "std": 161.470585556627
+ },
+ "AsterixDeterministic-v0": {
+ "mean": 281.0,
+ "std": 162.29294500994183
+ },
+ "AsterixDeterministic-v4": {
+ "mean": 265.0,
+ "std": 140.26760139105536
+ },
+ "AsterixNoFrameskip-v0": {
+ "mean": 301.5,
+ "std": 149.90913914768507
+ },
+ "AsterixNoFrameskip-v4": {
+ "mean": 307.5,
+ "std": 145.15078366994786
+ },
+ "Asterix-ram-v0": {
+ "mean": 285.0,
+ "std": 141.86260959111107
+ },
+ "Asterix-ram-v4": {
+ "mean": 269.5,
+ "std": 132.8335424506928
+ },
+ "Asterix-ramDeterministic-v0": {
+ "mean": 246.0,
+ "std": 111.28342194594845
+ },
+ "Asterix-ramDeterministic-v4": {
+ "mean": 277.5,
+ "std": 123.16147936753602
+ },
+ "Asterix-ramNoFrameskip-v0": {
+ "mean": 296.0,
+ "std": 130.13070352534024
+ },
+ "Asterix-ramNoFrameskip-v4": {
+ "mean": 270.5,
+ "std": 141.61479442487638
+ },
+ "Asteroids-v0": {
+ "mean": 929.8,
+ "std": 465.47390904324595
+ },
+ "Asteroids-v4": {
+ "mean": 1039.0,
+ "std": 490.23973727147006
+ },
+ "AsteroidsDeterministic-v0": {
+ "mean": 912.7,
+ "std": 422.603490283741
+ },
+ "AsteroidsDeterministic-v4": {
+ "mean": 812.8,
+ "std": 379.8317522272197
+ },
+ "AsteroidsNoFrameskip-v0": {
+ "mean": 1373.5,
+ "std": 694.8847026665646
+ },
+ "AsteroidsNoFrameskip-v4": {
+ "mean": 1331.9,
+ "std": 604.5902662134084
+ },
+ "Asteroids-ram-v0": {
+ "mean": 928.4,
+ "std": 439.2031876022759
+ },
+ "Asteroids-ram-v4": {
+ "mean": 1009.0,
+ "std": 492.58806319276556
+ },
+ "Asteroids-ramDeterministic-v0": {
+ "mean": 851.5,
+ "std": 376.0462072671389
+ },
+ "Asteroids-ramDeterministic-v4": {
+ "mean": 783.7,
+ "std": 394.3999366125709
+ },
+ "Asteroids-ramNoFrameskip-v0": {
+ "mean": 1206.6,
+ "std": 522.691534272366
+ },
+ "Asteroids-ramNoFrameskip-v4": {
+ "mean": 1357.2,
+ "std": 695.5991374347728
+ },
+ "Atlantis-v0": {
+ "mean": 19077.0,
+ "std": 5852.860070085394
+ },
+ "Atlantis-v4": {
+ "mean": 19380.0,
+ "std": 7122.120470758691
+ },
+ "AtlantisDeterministic-v0": {
+ "mean": 17337.0,
+ "std": 6206.410476273705
+ },
+ "AtlantisDeterministic-v4": {
+ "mean": 18407.0,
+ "std": 6456.396130969661
+ },
+ "AtlantisNoFrameskip-v0": {
+ "mean": 28462.0,
+ "std": 7652.591456493676
+ },
+ "AtlantisNoFrameskip-v4": {
+ "mean": 29473.0,
+ "std": 9613.998699812686
+ },
+ "Atlantis-ram-v0": {
+ "mean": 19455.0,
+ "std": 6486.68443813941
+ },
+ "Atlantis-ram-v4": {
+ "mean": 20766.0,
+ "std": 8152.63417552879
+ },
+ "Atlantis-ramDeterministic-v0": {
+ "mean": 17287.0,
+ "std": 6654.737485430962
+ },
+ "Atlantis-ramDeterministic-v4": {
+ "mean": 17278.0,
+ "std": 6321.274871416366
+ },
+ "Atlantis-ramNoFrameskip-v0": {
+ "mean": 29006.0,
+ "std": 8897.188544703322
+ },
+ "Atlantis-ramNoFrameskip-v4": {
+ "mean": 30905.0,
+ "std": 10442.65651067773
+ },
+ "BankHeist-v0": {
+ "mean": 15.3,
+ "std": 10.339729203417273
+ },
+ "BankHeist-v4": {
+ "mean": 14.6,
+ "std": 9.531002045955084
+ },
+ "BankHeistDeterministic-v0": {
+ "mean": 14.5,
+ "std": 10.136567466356647
+ },
+ "BankHeistDeterministic-v4": {
+ "mean": 15.2,
+ "std": 10.047885349664377
+ },
+ "BankHeistNoFrameskip-v0": {
+ "mean": 15.8,
+ "std": 10.505236789335115
+ },
+ "BankHeistNoFrameskip-v4": {
+ "mean": 13.4,
+ "std": 9.189124006128115
+ },
+ "BankHeist-ram-v0": {
+ "mean": 15.7,
+ "std": 8.972736483370054
+ },
+ "BankHeist-ram-v4": {
+ "mean": 13.6,
+ "std": 9.221713506718801
+ },
+ "BankHeist-ramDeterministic-v0": {
+ "mean": 14.5,
+ "std": 8.874119674649425
+ },
+ "BankHeist-ramDeterministic-v4": {
+ "mean": 13.6,
+ "std": 10.248902380255164
+ },
+ "BankHeist-ramNoFrameskip-v0": {
+ "mean": 14.1,
+ "std": 10.591978096654088
+ },
+ "BankHeist-ramNoFrameskip-v4": {
+ "mean": 15.8,
+ "std": 10.31309846748299
+ },
+ "BattleZone-v0": {
+ "mean": 2890.0,
+ "std": 3177.7193079313975
+ },
+ "BattleZone-v4": {
+ "mean": 3270.0,
+ "std": 3282.849372115632
+ },
+ "BattleZoneDeterministic-v0": {
+ "mean": 3030.0,
+ "std": 2662.536384727916
+ },
+ "BattleZoneDeterministic-v4": {
+ "mean": 3480.0,
+ "std": 3528.399070400059
+ },
+ "BattleZoneNoFrameskip-v0": {
+ "mean": 3160.0,
+ "std": 3692.478842187183
+ },
+ "BattleZoneNoFrameskip-v4": {
+ "mean": 3080.0,
+ "std": 3107.02429987279
+ },
+ "BattleZone-ram-v0": {
+ "mean": 2930.0,
+ "std": 3024.0866389705175
+ },
+ "BattleZone-ram-v4": {
+ "mean": 2990.0,
+ "std": 3363.0194766013474
+ },
+ "BattleZone-ramDeterministic-v0": {
+ "mean": 3120.0,
+ "std": 3037.3672810511407
+ },
+ "BattleZone-ramDeterministic-v4": {
+ "mean": 3680.0,
+ "std": 3717.203249756462
+ },
+ "BattleZone-ramNoFrameskip-v0": {
+ "mean": 3110.0,
+ "std": 2999.649979580951
+ },
+ "BattleZone-ramNoFrameskip-v4": {
+ "mean": 2980.0,
+ "std": 3152.7131173007165
+ },
+ "BeamRider-v0": {
+ "mean": 364.56,
+ "std": 144.2187449674972
+ },
+ "BeamRider-v4": {
+ "mean": 378.08,
+ "std": 149.30182048454736
+ },
+ "BeamRiderDeterministic-v0": {
+ "mean": 355.6,
+ "std": 139.87823275978292
+ },
+ "BeamRiderDeterministic-v4": {
+ "mean": 361.04,
+ "std": 157.83902685964583
+ },
+ "BeamRiderNoFrameskip-v0": {
+ "mean": 328.52,
+ "std": 150.49959999946842
+ },
+ "BeamRiderNoFrameskip-v4": {
+ "mean": 355.52,
+ "std": 124.24527999083105
+ },
+ "BeamRider-ram-v0": {
+ "mean": 374.48,
+ "std": 153.07700545803735
+ },
+ "BeamRider-ram-v4": {
+ "mean": 345.16,
+ "std": 145.04652494975534
+ },
+ "BeamRider-ramDeterministic-v0": {
+ "mean": 374.48,
+ "std": 139.720612652536
+ },
+ "BeamRider-ramDeterministic-v4": {
+ "mean": 388.32,
+ "std": 147.1496435605605
+ },
+ "BeamRider-ramNoFrameskip-v0": {
+ "mean": 371.52,
+ "std": 146.0183878831704
+ },
+ "BeamRider-ramNoFrameskip-v4": {
+ "mean": 343.24,
+ "std": 126.2653650056103
+ },
+ "Berzerk-v0": {
+ "mean": 163.3,
+ "std": 107.07992342171335
+ },
+ "Berzerk-v4": {
+ "mean": 174.5,
+ "std": 120.31105518612992
+ },
+ "BerzerkDeterministic-v0": {
+ "mean": 149.5,
+ "std": 135.73779871502262
+ },
+ "BerzerkDeterministic-v4": {
+ "mean": 161.1,
+ "std": 105.16553617987216
+ },
+ "BerzerkNoFrameskip-v0": {
+ "mean": 216.3,
+ "std": 158.61056080854138
+ },
+ "BerzerkNoFrameskip-v4": {
+ "mean": 212.1,
+ "std": 126.95113233051525
+ },
+ "Berzerk-ram-v0": {
+ "mean": 155.0,
+ "std": 116.081867662439
+ },
+ "Berzerk-ram-v4": {
+ "mean": 175.5,
+ "std": 124.19641701756134
+ },
+ "Berzerk-ramDeterministic-v0": {
+ "mean": 147.0,
+ "std": 98.18859404228171
+ },
+ "Berzerk-ramDeterministic-v4": {
+ "mean": 165.5,
+ "std": 113.51101268158962
+ },
+ "Berzerk-ramNoFrameskip-v0": {
+ "mean": 204.2,
+ "std": 130.9059204161523
+ },
+ "Berzerk-ramNoFrameskip-v4": {
+ "mean": 248.6,
+ "std": 164.8879619620547
+ },
+ "Bowling-v0": {
+ "mean": 24.92,
+ "std": 5.864605698595601
+ },
+ "Bowling-v4": {
+ "mean": 23.6,
+ "std": 5.396295025292817
+ },
+ "BowlingDeterministic-v0": {
+ "mean": 23.45,
+ "std": 5.6042394666894815
+ },
+ "BowlingDeterministic-v4": {
+ "mean": 24.16,
+ "std": 5.984513346964814
+ },
+ "BowlingNoFrameskip-v0": {
+ "mean": 24.39,
+ "std": 5.507985112543424
+ },
+ "BowlingNoFrameskip-v4": {
+ "mean": 24.14,
+ "std": 6.308755820286596
+ },
+ "Bowling-ram-v0": {
+ "mean": 24.02,
+ "std": 5.102901135628634
+ },
+ "Bowling-ram-v4": {
+ "mean": 23.63,
+ "std": 5.518432748525617
+ },
+ "Bowling-ramDeterministic-v0": {
+ "mean": 22.67,
+ "std": 6.0844966924142545
+ },
+ "Bowling-ramDeterministic-v4": {
+ "mean": 23.56,
+ "std": 5.613056208519562
+ },
+ "Bowling-ramNoFrameskip-v0": {
+ "mean": 24.41,
+ "std": 5.482873334302006
+ },
+ "Bowling-ramNoFrameskip-v4": {
+ "mean": 23.33,
+ "std": 5.144035380904761
+ },
+ "Boxing-v0": {
+ "mean": 0.94,
+ "std": 4.632105352860619
+ },
+ "Boxing-v4": {
+ "mean": 0.74,
+ "std": 5.574262283029029
+ },
+ "BoxingDeterministic-v0": {
+ "mean": 0.68,
+ "std": 4.93534193344291
+ },
+ "BoxingDeterministic-v4": {
+ "mean": -0.09,
+ "std": 4.870513319969468
+ },
+ "BoxingNoFrameskip-v0": {
+ "mean": 0.25,
+ "std": 5.82129710631574
+ },
+ "BoxingNoFrameskip-v4": {
+ "mean": -0.91,
+ "std": 6.06315924250716
+ },
+ "Boxing-ram-v0": {
+ "mean": 0.99,
+ "std": 4.92644902541374
+ },
+ "Boxing-ram-v4": {
+ "mean": 0.42,
+ "std": 6.601787636693566
+ },
+ "Boxing-ramDeterministic-v0": {
+ "mean": 0.1,
+ "std": 5.771481612203231
+ },
+ "Boxing-ramDeterministic-v4": {
+ "mean": 1.03,
+ "std": 4.869199112790521
+ },
+ "Boxing-ramNoFrameskip-v0": {
+ "mean": -0.78,
+ "std": 4.879713106320903
+ },
+ "Boxing-ramNoFrameskip-v4": {
+ "mean": -1.87,
+ "std": 6.186525680864826
+ },
+ "Breakout-v0": {
+ "mean": 1.3,
+ "std": 1.2288205727444508
+ },
+ "Breakout-v4": {
+ "mean": 1.25,
+ "std": 1.291317157014496
+ },
+ "BreakoutDeterministic-v0": {
+ "mean": 1.54,
+ "std": 1.5389606882568507
+ },
+ "BreakoutDeterministic-v4": {
+ "mean": 0.78,
+ "std": 1.063766891757776
+ },
+ "BreakoutNoFrameskip-v0": {
+ "mean": 1.4,
+ "std": 1.3038404810405297
+ },
+ "BreakoutNoFrameskip-v4": {
+ "mean": 1.26,
+ "std": 1.300922749435953
+ },
+ "Breakout-ram-v0": {
+ "mean": 1.22,
+ "std": 1.100727032465361
+ },
+ "Breakout-ram-v4": {
+ "mean": 0.9500000000000001,
+ "std": 1.098863048791795
+ },
+ "Breakout-ramDeterministic-v0": {
+ "mean": 1.08,
+ "std": 1.1373653766490344
+ },
+ "Breakout-ramDeterministic-v4": {
+ "mean": 1.09,
+ "std": 1.123343224486621
+ },
+ "Breakout-ramNoFrameskip-v0": {
+ "mean": 1.09,
+ "std": 1.1497391008398383
+ },
+ "Breakout-ramNoFrameskip-v4": {
+ "mean": 1.13,
+ "std": 1.230081298126266
+ },
+ "Carnival-v0": {
+ "mean": 672.4,
+ "std": 346.75386082926315
+ },
+ "Carnival-v4": {
+ "mean": 698.8,
+ "std": 406.82989074058946
+ },
+ "CarnivalDeterministic-v0": {
+ "mean": 752.0,
+ "std": 427.8130432794213
+ },
+ "CarnivalDeterministic-v4": {
+ "mean": 706.4,
+ "std": 337.6848234670904
+ },
+ "CarnivalNoFrameskip-v0": {
+ "mean": 827.2,
+ "std": 353.01580701152744
+ },
+ "CarnivalNoFrameskip-v4": {
+ "mean": 905.8,
+ "std": 434.45869769173686
+ },
+ "Carnival-ram-v0": {
+ "mean": 663.4,
+ "std": 367.7722664910991
+ },
+ "Carnival-ram-v4": {
+ "mean": 715.0,
+ "std": 351.3331752055305
+ },
+ "Carnival-ramDeterministic-v0": {
+ "mean": 648.4,
+ "std": 307.3132603712375
+ },
+ "Carnival-ramDeterministic-v4": {
+ "mean": 680.4,
+ "std": 406.39862204490805
+ },
+ "Carnival-ramNoFrameskip-v0": {
+ "mean": 860.0,
+ "std": 458.01310024932695
+ },
+ "Carnival-ramNoFrameskip-v4": {
+ "mean": 881.6,
+ "std": 483.137081996404
+ },
+ "Centipede-v0": {
+ "mean": 2186.17,
+ "std": 1197.3362439598995
+ },
+ "Centipede-v4": {
+ "mean": 2044.22,
+ "std": 1212.348444796297
+ },
+ "CentipedeDeterministic-v0": {
+ "mean": 2043.84,
+ "std": 1035.485284492252
+ },
+ "CentipedeDeterministic-v4": {
+ "mean": 2138.13,
+ "std": 1240.4113322200826
+ },
+ "CentipedeNoFrameskip-v0": {
+ "mean": 2684.98,
+ "std": 1673.0911390596748
+ },
+ "CentipedeNoFrameskip-v4": {
+ "mean": 2888.81,
+ "std": 1502.9192905475663
+ },
+ "Centipede-ram-v0": {
+ "mean": 2397.95,
+ "std": 1301.5617954980087
+ },
+ "Centipede-ram-v4": {
+ "mean": 2363.71,
+ "std": 1091.5232686021861
+ },
+ "Centipede-ramDeterministic-v0": {
+ "mean": 2131.45,
+ "std": 1157.177967081987
+ },
+ "Centipede-ramDeterministic-v4": {
+ "mean": 2341.76,
+ "std": 1349.6452061190007
+ },
+ "Centipede-ramNoFrameskip-v0": {
+ "mean": 2862.6,
+ "std": 1534.7243270372694
+ },
+ "Centipede-ramNoFrameskip-v4": {
+ "mean": 3087.73,
+ "std": 1940.5136168293175
+ },
+ "ChopperCommand-v0": {
+ "mean": 786.0,
+ "std": 313.3751745113196
+ },
+ "ChopperCommand-v4": {
+ "mean": 765.0,
+ "std": 335.37292675468007
+ },
+ "ChopperCommandDeterministic-v0": {
+ "mean": 812.0,
+ "std": 371.0202150826825
+ },
+ "ChopperCommandDeterministic-v4": {
+ "mean": 759.0,
+ "std": 295.6670424649998
+ },
+ "ChopperCommandNoFrameskip-v0": {
+ "mean": 778.0,
+ "std": 247.21650430341418
+ },
+ "ChopperCommandNoFrameskip-v4": {
+ "mean": 735.0,
+ "std": 257.05057868053905
+ },
+ "ChopperCommand-ram-v0": {
+ "mean": 800.0,
+ "std": 297.3213749463701
+ },
+ "ChopperCommand-ram-v4": {
+ "mean": 828.0,
+ "std": 356.9537785204129
+ },
+ "ChopperCommand-ramDeterministic-v0": {
+ "mean": 766.0,
+ "std": 288.17355881482257
+ },
+ "ChopperCommand-ramDeterministic-v4": {
+ "mean": 788.0,
+ "std": 314.41374015777365
+ },
+ "ChopperCommand-ramNoFrameskip-v0": {
+ "mean": 771.0,
+ "std": 259.728704613102
+ },
+ "ChopperCommand-ramNoFrameskip-v4": {
+ "mean": 725.0,
+ "std": 259.37424698685874
+ },
+ "CrazyClimber-v0": {
+ "mean": 7845.0,
+ "std": 2291.216925565975
+ },
+ "CrazyClimber-v4": {
+ "mean": 7567.0,
+ "std": 2290.9410730090813
+ },
+ "CrazyClimberDeterministic-v0": {
+ "mean": 8292.0,
+ "std": 2387.8726934240026
+ },
+ "CrazyClimberDeterministic-v4": {
+ "mean": 7582.0,
+ "std": 2327.7190552126344
+ },
+ "CrazyClimberNoFrameskip-v0": {
+ "mean": 4423.0,
+ "std": 1173.8700950275545
+ },
+ "CrazyClimberNoFrameskip-v4": {
+ "mean": 2452.0,
+ "std": 728.214254186225
+ },
+ "CrazyClimber-ram-v0": {
+ "mean": 7876.0,
+ "std": 2158.708873377788
+ },
+ "CrazyClimber-ram-v4": {
+ "mean": 8113.0,
+ "std": 2494.780751889833
+ },
+ "CrazyClimber-ramDeterministic-v0": {
+ "mean": 8184.0,
+ "std": 2247.7864667267663
+ },
+ "CrazyClimber-ramDeterministic-v4": {
+ "mean": 7734.0,
+ "std": 2372.68708429915
+ },
+ "CrazyClimber-ramNoFrameskip-v0": {
+ "mean": 4343.0,
+ "std": 1135.7160736733456
+ },
+ "CrazyClimber-ramNoFrameskip-v4": {
+ "mean": 2375.0,
+ "std": 616.0154218848745
+ },
+ "Defender-v0": {
+ "mean": 444210.0,
+ "std": 198079.17608875496
+ },
+ "Defender-v4": {
+ "mean": 468910.0,
+ "std": 180036.91288177544
+ },
+ "DefenderDeterministic-v0": {
+ "mean": 393410.0,
+ "std": 163832.0481468751
+ },
+ "DefenderDeterministic-v4": {
+ "mean": 432710.0,
+ "std": 196237.63655323614
+ },
+ "DefenderNoFrameskip-v0": {
+ "mean": 523960.0,
+ "std": 203904.7510481303
+ },
+ "DefenderNoFrameskip-v4": {
+ "mean": 546810.0,
+ "std": 244397.74958047384
+ },
+ "Defender-ram-v0": {
+ "mean": 460360.0,
+ "std": 233276.93306454454
+ },
+ "Defender-ram-v4": {
+ "mean": 479360.0,
+ "std": 215603.403266275
+ },
+ "Defender-ramDeterministic-v0": {
+ "mean": 394160.0,
+ "std": 162320.7549883871
+ },
+ "Defender-ramDeterministic-v4": {
+ "mean": 424610.0,
+ "std": 206381.53987215037
+ },
+ "Defender-ramNoFrameskip-v0": {
+ "mean": 526010.0,
+ "std": 224937.76917183117
+ },
+ "Defender-ramNoFrameskip-v4": {
+ "mean": 555760.0,
+ "std": 211419.4586597932
+ },
+ "DemonAttack-v0": {
+ "mean": 185.6,
+ "std": 158.8431301630637
+ },
+ "DemonAttack-v4": {
+ "mean": 191.8,
+ "std": 99.11992736074819
+ },
+ "DemonAttackDeterministic-v0": {
+ "mean": 171.6,
+ "std": 100.15208435174976
+ },
+ "DemonAttackDeterministic-v4": {
+ "mean": 183.9,
+ "std": 106.9896723987881
+ },
+ "DemonAttackNoFrameskip-v0": {
+ "mean": 265.95,
+ "std": 171.3165126308611
+ },
+ "DemonAttackNoFrameskip-v4": {
+ "mean": 346.9,
+ "std": 342.2760435671768
+ },
+ "DemonAttack-ram-v0": {
+ "mean": 195.1,
+ "std": 89.64089468540573
+ },
+ "DemonAttack-ram-v4": {
+ "mean": 174.85,
+ "std": 90.04292032136672
+ },
+ "DemonAttack-ramDeterministic-v0": {
+ "mean": 174.45,
+ "std": 99.06536983224764
+ },
+ "DemonAttack-ramDeterministic-v4": {
+ "mean": 183.0,
+ "std": 119.04200939164292
+ },
+ "DemonAttack-ramNoFrameskip-v0": {
+ "mean": 277.25,
+ "std": 232.00255925312547
+ },
+ "DemonAttack-ramNoFrameskip-v4": {
+ "mean": 292.4,
+ "std": 213.73871900055917
+ },
+ "DoubleDunk-v0": {
+ "mean": -18.84,
+ "std": 3.443021928480851
+ },
+ "DoubleDunk-v4": {
+ "mean": -18.02,
+ "std": 3.181131874034775
+ },
+ "DoubleDunkDeterministic-v0": {
+ "mean": -18.1,
+ "std": 2.971531591620725
+ },
+ "DoubleDunkDeterministic-v4": {
+ "mean": -17.58,
+ "std": 3.050180322538325
+ },
+ "DoubleDunkNoFrameskip-v0": {
+ "mean": -17.46,
+ "std": 3.3088366535687435
+ },
+ "DoubleDunkNoFrameskip-v4": {
+ "mean": -16.48,
+ "std": 3.087005021051958
+ },
+ "DoubleDunk-ram-v0": {
+ "mean": -18.0,
+ "std": 3.4525353003264136
+ },
+ "DoubleDunk-ram-v4": {
+ "mean": -18.58,
+ "std": 2.997265420345686
+ },
+ "DoubleDunk-ramDeterministic-v0": {
+ "mean": -18.36,
+ "std": 3.128961489056713
+ },
+ "DoubleDunk-ramDeterministic-v4": {
+ "mean": -18.54,
+ "std": 3.380591664191344
+ },
+ "DoubleDunk-ramNoFrameskip-v0": {
+ "mean": -16.86,
+ "std": 4.052209273964019
+ },
+ "DoubleDunk-ramNoFrameskip-v4": {
+ "mean": -15.52,
+ "std": 4.186836514601448
+ },
+ "ElevatorAction-v0": {
+ "mean": 2445.0,
+ "std": 4941.48510065547
+ },
+ "ElevatorAction-v4": {
+ "mean": 7416.0,
+ "std": 22090.820355975917
+ },
+ "ElevatorActionDeterministic-v0": {
+ "mean": 6735.0,
+ "std": 22196.046382182572
+ },
+ "ElevatorActionDeterministic-v4": {
+ "mean": 8090.0,
+ "std": 24540.205785608236
+ },
+ "ElevatorActionNoFrameskip-v0": {
+ "mean": 13570.0,
+ "std": 29204.073346024867
+ },
+ "ElevatorActionNoFrameskip-v4": {
+ "mean": 9851.0,
+ "std": 24973.768217872126
+ },
+ "ElevatorAction-ram-v0": {
+ "mean": 1927.0,
+ "std": 4442.000787933293
+ },
+ "ElevatorAction-ram-v4": {
+ "mean": 9796.0,
+ "std": 25460.038963049527
+ },
+ "ElevatorAction-ramDeterministic-v0": {
+ "mean": 5310.0,
+ "std": 16981.251426205312
+ },
+ "ElevatorAction-ramDeterministic-v4": {
+ "mean": 5708.0,
+ "std": 19307.95007244425
+ },
+ "ElevatorAction-ramNoFrameskip-v0": {
+ "mean": 14346.0,
+ "std": 28769.742508406292
+ },
+ "ElevatorAction-ramNoFrameskip-v4": {
+ "mean": 10942.0,
+ "std": 24785.02443008681
+ },
+ "Enduro-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "EnduroDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "EnduroDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "EnduroNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "EnduroNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ram-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ram-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ramDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ramDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ramNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Enduro-ramNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "FishingDerby-v0": {
+ "mean": -94.01,
+ "std": 3.1858907702556283
+ },
+ "FishingDerby-v4": {
+ "mean": -93.84,
+ "std": 3.557302348690648
+ },
+ "FishingDerbyDeterministic-v0": {
+ "mean": -93.16,
+ "std": 3.306720429670461
+ },
+ "FishingDerbyDeterministic-v4": {
+ "mean": -92.91,
+ "std": 3.400279400284629
+ },
+ "FishingDerbyNoFrameskip-v0": {
+ "mean": -93.46,
+ "std": 3.3568437556728794
+ },
+ "FishingDerbyNoFrameskip-v4": {
+ "mean": -93.96,
+ "std": 2.863284826907724
+ },
+ "FishingDerby-ram-v0": {
+ "mean": -94.08,
+ "std": 3.5712182795231104
+ },
+ "FishingDerby-ram-v4": {
+ "mean": -94.06,
+ "std": 3.1042551441529422
+ },
+ "FishingDerby-ramDeterministic-v0": {
+ "mean": -93.38,
+ "std": 3.7276802437977423
+ },
+ "FishingDerby-ramDeterministic-v4": {
+ "mean": -93.82,
+ "std": 2.885758132623037
+ },
+ "FishingDerby-ramNoFrameskip-v0": {
+ "mean": -93.38,
+ "std": 3.3069018733551796
+ },
+ "FishingDerby-ramNoFrameskip-v4": {
+ "mean": -94.06,
+ "std": 3.025954394897583
+ },
+ "Freeway-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "FreewayDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "FreewayDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "FreewayNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "FreewayNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ram-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ram-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ramDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ramDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ramNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Freeway-ramNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Frostbite-v0": {
+ "mean": 76.3,
+ "std": 44.624096629511726
+ },
+ "Frostbite-v4": {
+ "mean": 70.1,
+ "std": 44.64291657138902
+ },
+ "FrostbiteDeterministic-v0": {
+ "mean": 74.1,
+ "std": 37.552496588109825
+ },
+ "FrostbiteDeterministic-v4": {
+ "mean": 71.6,
+ "std": 41.272751301554884
+ },
+ "FrostbiteNoFrameskip-v0": {
+ "mean": 65.3,
+ "std": 37.66842178801761
+ },
+ "FrostbiteNoFrameskip-v4": {
+ "mean": 68.0,
+ "std": 37.013511046643494
+ },
+ "Frostbite-ram-v0": {
+ "mean": 64.5,
+ "std": 37.077621282924824
+ },
+ "Frostbite-ram-v4": {
+ "mean": 74.8,
+ "std": 42.88309690309225
+ },
+ "Frostbite-ramDeterministic-v0": {
+ "mean": 70.6,
+ "std": 38.87981481437379
+ },
+ "Frostbite-ramDeterministic-v4": {
+ "mean": 73.8,
+ "std": 37.03457843691487
+ },
+ "Frostbite-ramNoFrameskip-v0": {
+ "mean": 71.2,
+ "std": 40.700859941775185
+ },
+ "Frostbite-ramNoFrameskip-v4": {
+ "mean": 63.2,
+ "std": 40.14673087562672
+ },
+ "Gopher-v0": {
+ "mean": 257.8,
+ "std": 231.9637040573374
+ },
+ "Gopher-v4": {
+ "mean": 280.2,
+ "std": 217.66938232098698
+ },
+ "GopherDeterministic-v0": {
+ "mean": 240.2,
+ "std": 198.72584129901173
+ },
+ "GopherDeterministic-v4": {
+ "mean": 274.0,
+ "std": 180.43281298034458
+ },
+ "GopherNoFrameskip-v0": {
+ "mean": 261.2,
+ "std": 219.74203057221442
+ },
+ "GopherNoFrameskip-v4": {
+ "mean": 276.6,
+ "std": 241.56249708926256
+ },
+ "Gopher-ram-v0": {
+ "mean": 317.0,
+ "std": 298.2666592162121
+ },
+ "Gopher-ram-v4": {
+ "mean": 324.0,
+ "std": 246.57656011875906
+ },
+ "Gopher-ramDeterministic-v0": {
+ "mean": 294.4,
+ "std": 231.70809221949935
+ },
+ "Gopher-ramDeterministic-v4": {
+ "mean": 292.4,
+ "std": 275.67778292782316
+ },
+ "Gopher-ramNoFrameskip-v0": {
+ "mean": 296.0,
+ "std": 251.42792207708357
+ },
+ "Gopher-ramNoFrameskip-v4": {
+ "mean": 264.4,
+ "std": 235.1948979038449
+ },
+ "Gravitar-v0": {
+ "mean": 226.0,
+ "std": 229.83472322519066
+ },
+ "Gravitar-v4": {
+ "mean": 254.5,
+ "std": 275.5988933214355
+ },
+ "GravitarDeterministic-v0": {
+ "mean": 207.0,
+ "std": 227.81790974372493
+ },
+ "GravitarDeterministic-v4": {
+ "mean": 197.5,
+ "std": 233.5995505132662
+ },
+ "GravitarNoFrameskip-v0": {
+ "mean": 213.0,
+ "std": 221.31651542530665
+ },
+ "GravitarNoFrameskip-v4": {
+ "mean": 219.0,
+ "std": 203.07387818230094
+ },
+ "Gravitar-ram-v0": {
+ "mean": 218.0,
+ "std": 213.48536249588636
+ },
+ "Gravitar-ram-v4": {
+ "mean": 215.5,
+ "std": 260.25900560787517
+ },
+ "Gravitar-ramDeterministic-v0": {
+ "mean": 235.5,
+ "std": 302.18330529663615
+ },
+ "Gravitar-ramDeterministic-v4": {
+ "mean": 187.5,
+ "std": 197.53164303473
+ },
+ "Gravitar-ramNoFrameskip-v0": {
+ "mean": 251.0,
+ "std": 221.13118278524175
+ },
+ "Gravitar-ramNoFrameskip-v4": {
+ "mean": 238.5,
+ "std": 212.11494525374678
+ },
+ "Hero-v0": {
+ "mean": 684.15,
+ "std": 977.0987808302699
+ },
+ "Hero-v4": {
+ "mean": 674.6,
+ "std": 982.5043714915471
+ },
+ "HeroDeterministic-v0": {
+ "mean": 553.6,
+ "std": 897.4901336505043
+ },
+ "HeroDeterministic-v4": {
+ "mean": 358.45,
+ "std": 774.7495385606887
+ },
+ "HeroNoFrameskip-v0": {
+ "mean": 585.75,
+ "std": 911.1246827410615
+ },
+ "HeroNoFrameskip-v4": {
+ "mean": 706.05,
+ "std": 1041.4065716616158
+ },
+ "Hero-ram-v0": {
+ "mean": 657.45,
+ "std": 1026.4868472123742
+ },
+ "Hero-ram-v4": {
+ "mean": 365.05,
+ "std": 777.6305340584306
+ },
+ "Hero-ramDeterministic-v0": {
+ "mean": 637.7,
+ "std": 998.7200358458822
+ },
+ "Hero-ramDeterministic-v4": {
+ "mean": 444.35,
+ "std": 886.6001508571945
+ },
+ "Hero-ramNoFrameskip-v0": {
+ "mean": 622.95,
+ "std": 939.7505240754059
+ },
+ "Hero-ramNoFrameskip-v4": {
+ "mean": 589.1,
+ "std": 956.9478512437344
+ },
+ "IceHockey-v0": {
+ "mean": -10.02,
+ "std": 3.8574084564640025
+ },
+ "IceHockey-v4": {
+ "mean": -9.1,
+ "std": 3.04138126514911
+ },
+ "IceHockeyDeterministic-v0": {
+ "mean": -9.85,
+ "std": 3.766629793329841
+ },
+ "IceHockeyDeterministic-v4": {
+ "mean": -9.92,
+ "std": 3.195872337875842
+ },
+ "IceHockeyNoFrameskip-v0": {
+ "mean": -9.84,
+ "std": 3.2240347392669326
+ },
+ "IceHockeyNoFrameskip-v4": {
+ "mean": -9.87,
+ "std": 3.291367496953204
+ },
+ "IceHockey-ram-v0": {
+ "mean": -9.56,
+ "std": 2.8820825803574746
+ },
+ "IceHockey-ram-v4": {
+ "mean": -9.63,
+ "std": 3.242391093005283
+ },
+ "IceHockey-ramDeterministic-v0": {
+ "mean": -10.18,
+ "std": 2.9711277320236498
+ },
+ "IceHockey-ramDeterministic-v4": {
+ "mean": -9.21,
+ "std": 3.397925837919362
+ },
+ "IceHockey-ramNoFrameskip-v0": {
+ "mean": -9.54,
+ "std": 3.0835693603355185
+ },
+ "IceHockey-ramNoFrameskip-v4": {
+ "mean": -9.73,
+ "std": 3.078489889539999
+ },
+ "Jamesbond-v0": {
+ "mean": 28.5,
+ "std": 38.89408695418881
+ },
+ "Jamesbond-v4": {
+ "mean": 27.0,
+ "std": 42.67317658670374
+ },
+ "JamesbondDeterministic-v0": {
+ "mean": 25.5,
+ "std": 38.40247387864485
+ },
+ "JamesbondDeterministic-v4": {
+ "mean": 24.5,
+ "std": 40.923709509280805
+ },
+ "JamesbondNoFrameskip-v0": {
+ "mean": 26.0,
+ "std": 46.08687448721165
+ },
+ "JamesbondNoFrameskip-v4": {
+ "mean": 13.0,
+ "std": 32.109188716004645
+ },
+ "Jamesbond-ram-v0": {
+ "mean": 27.5,
+ "std": 40.85033659592048
+ },
+ "Jamesbond-ram-v4": {
+ "mean": 22.5,
+ "std": 40.85033659592048
+ },
+ "Jamesbond-ramDeterministic-v0": {
+ "mean": 27.5,
+ "std": 41.4578098794425
+ },
+ "Jamesbond-ramDeterministic-v4": {
+ "mean": 33.5,
+ "std": 41.26439142893059
+ },
+ "Jamesbond-ramNoFrameskip-v0": {
+ "mean": 21.5,
+ "std": 35.53519382246282
+ },
+ "Jamesbond-ramNoFrameskip-v4": {
+ "mean": 17.5,
+ "std": 36.31459761583488
+ },
+ "JourneyEscape-v0": {
+ "mean": -19837.0,
+ "std": 9045.580744208743
+ },
+ "JourneyEscape-v4": {
+ "mean": -19883.0,
+ "std": 8821.191019357873
+ },
+ "JourneyEscapeDeterministic-v0": {
+ "mean": -20106.0,
+ "std": 9864.16565148822
+ },
+ "JourneyEscapeDeterministic-v4": {
+ "mean": -19837.0,
+ "std": 9668.46063238611
+ },
+ "JourneyEscapeNoFrameskip-v0": {
+ "mean": -18266.0,
+ "std": 8820.342623730668
+ },
+ "JourneyEscapeNoFrameskip-v4": {
+ "mean": -18095.0,
+ "std": 8619.401081281692
+ },
+ "JourneyEscape-ram-v0": {
+ "mean": -17751.0,
+ "std": 8017.549438575355
+ },
+ "JourneyEscape-ram-v4": {
+ "mean": -20971.0,
+ "std": 8665.278933767799
+ },
+ "JourneyEscape-ramDeterministic-v0": {
+ "mean": -19895.0,
+ "std": 7372.277463579352
+ },
+ "JourneyEscape-ramDeterministic-v4": {
+ "mean": -20386.0,
+ "std": 8165.6600468057695
+ },
+ "JourneyEscape-ramNoFrameskip-v0": {
+ "mean": -21149.0,
+ "std": 9679.591881892542
+ },
+ "JourneyEscape-ramNoFrameskip-v4": {
+ "mean": -17903.0,
+ "std": 8056.009620153144
+ },
+ "Kangaroo-v0": {
+ "mean": 48.0,
+ "std": 85.41662601625049
+ },
+ "Kangaroo-v4": {
+ "mean": 36.0,
+ "std": 81.87795796183488
+ },
+ "KangarooDeterministic-v0": {
+ "mean": 56.0,
+ "std": 113.4195750300626
+ },
+ "KangarooDeterministic-v4": {
+ "mean": 42.0,
+ "std": 95.05787710652916
+ },
+ "KangarooNoFrameskip-v0": {
+ "mean": 40.0,
+ "std": 97.97958971132712
+ },
+ "KangarooNoFrameskip-v4": {
+ "mean": 54.0,
+ "std": 105.28057750601485
+ },
+ "Kangaroo-ram-v0": {
+ "mean": 38.0,
+ "std": 88.06815542521599
+ },
+ "Kangaroo-ram-v4": {
+ "mean": 34.0,
+ "std": 75.1265598839718
+ },
+ "Kangaroo-ramDeterministic-v0": {
+ "mean": 54.0,
+ "std": 105.28057750601485
+ },
+ "Kangaroo-ramDeterministic-v4": {
+ "mean": 42.0,
+ "std": 103.1309846748299
+ },
+ "Kangaroo-ramNoFrameskip-v0": {
+ "mean": 44.0,
+ "std": 87.54427451295716
+ },
+ "Kangaroo-ramNoFrameskip-v4": {
+ "mean": 52.0,
+ "std": 100.47885349664377
+ },
+ "Krull-v0": {
+ "mean": 1613.54,
+ "std": 519.0163662159412
+ },
+ "Krull-v4": {
+ "mean": 1626.82,
+ "std": 453.75057862222064
+ },
+ "KrullDeterministic-v0": {
+ "mean": 1536.95,
+ "std": 450.01383034302404
+ },
+ "KrullDeterministic-v4": {
+ "mean": 1616.23,
+ "std": 502.34352499061833
+ },
+ "KrullNoFrameskip-v0": {
+ "mean": 1774.06,
+ "std": 526.0717027174147
+ },
+ "KrullNoFrameskip-v4": {
+ "mean": 1747.82,
+ "std": 616.8337276770783
+ },
+ "Krull-ram-v0": {
+ "mean": 1583.18,
+ "std": 533.3634291925159
+ },
+ "Krull-ram-v4": {
+ "mean": 1502.41,
+ "std": 554.0690226858021
+ },
+ "Krull-ramDeterministic-v0": {
+ "mean": 1634.61,
+ "std": 583.1619825571622
+ },
+ "Krull-ramDeterministic-v4": {
+ "mean": 1564.52,
+ "std": 422.66536361523634
+ },
+ "Krull-ramNoFrameskip-v0": {
+ "mean": 1643.43,
+ "std": 556.5235889879242
+ },
+ "Krull-ramNoFrameskip-v4": {
+ "mean": 1717.34,
+ "std": 617.5327719238875
+ },
+ "KungFuMaster-v0": {
+ "mean": 602.0,
+ "std": 416.40845332437715
+ },
+ "KungFuMaster-v4": {
+ "mean": 680.0,
+ "std": 363.04269721342695
+ },
+ "KungFuMasterDeterministic-v0": {
+ "mean": 538.0,
+ "std": 366.546040764322
+ },
+ "KungFuMasterDeterministic-v4": {
+ "mean": 562.0,
+ "std": 394.6593467789658
+ },
+ "KungFuMasterNoFrameskip-v0": {
+ "mean": 914.0,
+ "std": 459.13396737771427
+ },
+ "KungFuMasterNoFrameskip-v4": {
+ "mean": 865.0,
+ "std": 466.12766491595414
+ },
+ "KungFuMaster-ram-v0": {
+ "mean": 600.0,
+ "std": 430.34869582700026
+ },
+ "KungFuMaster-ram-v4": {
+ "mean": 536.0,
+ "std": 327.87802610117075
+ },
+ "KungFuMaster-ramDeterministic-v0": {
+ "mean": 581.0,
+ "std": 380.18285074421755
+ },
+ "KungFuMaster-ramDeterministic-v4": {
+ "mean": 569.0,
+ "std": 429.3471788657752
+ },
+ "KungFuMaster-ramNoFrameskip-v0": {
+ "mean": 861.0,
+ "std": 462.3624119670629
+ },
+ "KungFuMaster-ramNoFrameskip-v4": {
+ "mean": 862.0,
+ "std": 454.9241695052045
+ },
+ "MontezumaRevenge-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevengeDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevengeDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevengeNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevengeNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-ram-v0": {
+ "mean": 1.0,
+ "std": 9.9498743710662
+ },
+ "MontezumaRevenge-ram-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-ramDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-ramDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-ramNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MontezumaRevenge-ramNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "MsPacman-v0": {
+ "mean": 231.3,
+ "std": 119.27828804941826
+ },
+ "MsPacman-v4": {
+ "mean": 209.3,
+ "std": 73.82756937621609
+ },
+ "MsPacmanDeterministic-v0": {
+ "mean": 276.0,
+ "std": 165.2815779208318
+ },
+ "MsPacmanDeterministic-v4": {
+ "mean": 252.2,
+ "std": 89.42684160809884
+ },
+ "MsPacmanNoFrameskip-v0": {
+ "mean": 188.3,
+ "std": 124.90040031961465
+ },
+ "MsPacmanNoFrameskip-v4": {
+ "mean": 170.7,
+ "std": 51.96643147263433
+ },
+ "MsPacman-ram-v0": {
+ "mean": 220.8,
+ "std": 60.690691213727334
+ },
+ "MsPacman-ram-v4": {
+ "mean": 198.1,
+ "std": 72.89300377951233
+ },
+ "MsPacman-ramDeterministic-v0": {
+ "mean": 256.1,
+ "std": 107.23707381311743
+ },
+ "MsPacman-ramDeterministic-v4": {
+ "mean": 229.5,
+ "std": 88.53671554784489
+ },
+ "MsPacman-ramNoFrameskip-v0": {
+ "mean": 178.0,
+ "std": 68.89121859859934
+ },
+ "MsPacman-ramNoFrameskip-v4": {
+ "mean": 171.7,
+ "std": 49.43794089563197
+ },
+ "NameThisGame-v0": {
+ "mean": 2303.1,
+ "std": 865.9569215613442
+ },
+ "NameThisGame-v4": {
+ "mean": 2377.0,
+ "std": 858.9580897808694
+ },
+ "NameThisGameDeterministic-v0": {
+ "mean": 2342.7,
+ "std": 972.5254289734538
+ },
+ "NameThisGameDeterministic-v4": {
+ "mean": 2482.6,
+ "std": 911.3875355741927
+ },
+ "NameThisGameNoFrameskip-v0": {
+ "mean": 2174.3,
+ "std": 844.3462026917631
+ },
+ "NameThisGameNoFrameskip-v4": {
+ "mean": 2088.3,
+ "std": 749.8493915447287
+ },
+ "NameThisGame-ram-v0": {
+ "mean": 2417.5,
+ "std": 831.1081457909073
+ },
+ "NameThisGame-ram-v4": {
+ "mean": 2318.6,
+ "std": 935.9978846129941
+ },
+ "NameThisGame-ramDeterministic-v0": {
+ "mean": 2436.9,
+ "std": 955.716166024202
+ },
+ "NameThisGame-ramDeterministic-v4": {
+ "mean": 2288.6,
+ "std": 885.8453815423997
+ },
+ "NameThisGame-ramNoFrameskip-v0": {
+ "mean": 2182.8,
+ "std": 810.9661891842347
+ },
+ "NameThisGame-ramNoFrameskip-v4": {
+ "mean": 2027.4,
+ "std": 754.3349653834163
+ },
+ "Phoenix-v0": {
+ "mean": 999.3,
+ "std": 706.0456854906771
+ },
+ "Phoenix-v4": {
+ "mean": 979.2,
+ "std": 659.5220693805478
+ },
+ "PhoenixDeterministic-v0": {
+ "mean": 797.0,
+ "std": 601.0765342283793
+ },
+ "PhoenixDeterministic-v4": {
+ "mean": 1047.4,
+ "std": 757.2062070532702
+ },
+ "PhoenixNoFrameskip-v0": {
+ "mean": 1260.4,
+ "std": 782.757842503031
+ },
+ "PhoenixNoFrameskip-v4": {
+ "mean": 1324.4,
+ "std": 945.6863327763598
+ },
+ "Phoenix-ram-v0": {
+ "mean": 991.7,
+ "std": 767.3070506648561
+ },
+ "Phoenix-ram-v4": {
+ "mean": 1062.7,
+ "std": 762.4130835708422
+ },
+ "Phoenix-ramDeterministic-v0": {
+ "mean": 973.6,
+ "std": 839.6779382596638
+ },
+ "Phoenix-ramDeterministic-v4": {
+ "mean": 860.1,
+ "std": 569.2003074489683
+ },
+ "Phoenix-ramNoFrameskip-v0": {
+ "mean": 1337.8,
+ "std": 867.9211715357565
+ },
+ "Phoenix-ramNoFrameskip-v4": {
+ "mean": 1326.7,
+ "std": 969.0016047458332
+ },
+ "Pitfall-v0": {
+ "mean": -301.74,
+ "std": 429.85310560702015
+ },
+ "Pitfall-v4": {
+ "mean": -233.34,
+ "std": 372.5010931527585
+ },
+ "PitfallDeterministic-v0": {
+ "mean": -161.25,
+ "std": 227.7623487321818
+ },
+ "PitfallDeterministic-v4": {
+ "mean": -277.21,
+ "std": 376.4866344241187
+ },
+ "PitfallNoFrameskip-v0": {
+ "mean": -301.71,
+ "std": 458.9449704485277
+ },
+ "PitfallNoFrameskip-v4": {
+ "mean": -301.45,
+ "std": 483.9251672521279
+ },
+ "Pitfall-ram-v0": {
+ "mean": -252.96,
+ "std": 384.76311985428123
+ },
+ "Pitfall-ram-v4": {
+ "mean": -285.46,
+ "std": 484.7930160388039
+ },
+ "Pitfall-ramDeterministic-v0": {
+ "mean": -227.82,
+ "std": 349.0667666793847
+ },
+ "Pitfall-ramDeterministic-v4": {
+ "mean": -188.4,
+ "std": 312.61250774721094
+ },
+ "Pitfall-ramNoFrameskip-v0": {
+ "mean": -350.32,
+ "std": 516.989978239424
+ },
+ "Pitfall-ramNoFrameskip-v4": {
+ "mean": -327.05,
+ "std": 482.0183891720315
+ },
+ "Pong-v0": {
+ "mean": -20.34,
+ "std": 0.7901898506055365
+ },
+ "Pong-v4": {
+ "mean": -20.25,
+ "std": 0.898610037780571
+ },
+ "PongDeterministic-v0": {
+ "mean": -20.37,
+ "std": 0.7701298591796062
+ },
+ "PongDeterministic-v4": {
+ "mean": -20.51,
+ "std": 0.65566759871142
+ },
+ "PongNoFrameskip-v0": {
+ "mean": -20.43,
+ "std": 0.7906326580656784
+ },
+ "PongNoFrameskip-v4": {
+ "mean": -20.4,
+ "std": 0.7483314773547881
+ },
+ "Pong-ram-v0": {
+ "mean": -20.21,
+ "std": 0.9412226091632095
+ },
+ "Pong-ram-v4": {
+ "mean": -20.27,
+ "std": 0.8701149349367591
+ },
+ "Pong-ramDeterministic-v0": {
+ "mean": -20.26,
+ "std": 0.8901685233707155
+ },
+ "Pong-ramDeterministic-v4": {
+ "mean": -20.49,
+ "std": 0.714072825417688
+ },
+ "Pong-ramNoFrameskip-v0": {
+ "mean": -20.45,
+ "std": 0.7794228634059948
+ },
+ "Pong-ramNoFrameskip-v4": {
+ "mean": -20.56,
+ "std": 0.6374950980203691
+ },
+ "Pooyan-v0": {
+ "mean": 503.4,
+ "std": 255.61091525989258
+ },
+ "Pooyan-v4": {
+ "mean": 441.35,
+ "std": 220.02369758732806
+ },
+ "PooyanDeterministic-v0": {
+ "mean": 394.4,
+ "std": 196.24637576271311
+ },
+ "PooyanDeterministic-v4": {
+ "mean": 386.3,
+ "std": 224.78391846393288
+ },
+ "PooyanNoFrameskip-v0": {
+ "mean": 487.55,
+ "std": 226.572830454139
+ },
+ "PooyanNoFrameskip-v4": {
+ "mean": 515.4,
+ "std": 246.94197699054732
+ },
+ "Pooyan-ram-v0": {
+ "mean": 436.0,
+ "std": 220.30773931026573
+ },
+ "Pooyan-ram-v4": {
+ "mean": 420.25,
+ "std": 213.211602639256
+ },
+ "Pooyan-ramDeterministic-v0": {
+ "mean": 418.1,
+ "std": 243.85628964617663
+ },
+ "Pooyan-ramDeterministic-v4": {
+ "mean": 397.95,
+ "std": 189.71438400922585
+ },
+ "Pooyan-ramNoFrameskip-v0": {
+ "mean": 464.8,
+ "std": 218.44784274512762
+ },
+ "Pooyan-ramNoFrameskip-v4": {
+ "mean": 517.6,
+ "std": 224.26377326710616
+ },
+ "PrivateEye-v0": {
+ "mean": 16.7,
+ "std": 215.99562495569205
+ },
+ "PrivateEye-v4": {
+ "mean": -4.61,
+ "std": 256.8467985005848
+ },
+ "PrivateEyeDeterministic-v0": {
+ "mean": -4.66,
+ "std": 267.4156023869961
+ },
+ "PrivateEyeDeterministic-v4": {
+ "mean": 7.28,
+ "std": 233.89185877238222
+ },
+ "PrivateEyeNoFrameskip-v0": {
+ "mean": -289.33,
+ "std": 459.7834719734933
+ },
+ "PrivateEyeNoFrameskip-v4": {
+ "mean": -731.71,
+ "std": 402.21283656790473
+ },
+ "PrivateEye-ram-v0": {
+ "mean": -17.66,
+ "std": 289.710518276434
+ },
+ "PrivateEye-ram-v4": {
+ "mean": -11.03,
+ "std": 271.6145229916839
+ },
+ "PrivateEye-ramDeterministic-v0": {
+ "mean": 28.16,
+ "std": 190.62658366555277
+ },
+ "PrivateEye-ramDeterministic-v4": {
+ "mean": 52.9,
+ "std": 159.13374877756132
+ },
+ "PrivateEye-ramNoFrameskip-v0": {
+ "mean": -292.0,
+ "std": 457.13682853167717
+ },
+ "PrivateEye-ramNoFrameskip-v4": {
+ "mean": -779.92,
+ "std": 382.7165447168439
+ },
+ "Qbert-v0": {
+ "mean": 158.75,
+ "std": 164.36905882799232
+ },
+ "Qbert-v4": {
+ "mean": 143.75,
+ "std": 122.28935971702526
+ },
+ "QbertDeterministic-v0": {
+ "mean": 165.75,
+ "std": 152.9156221581039
+ },
+ "QbertDeterministic-v4": {
+ "mean": 147.25,
+ "std": 130.18712493945014
+ },
+ "QbertNoFrameskip-v0": {
+ "mean": 155.75,
+ "std": 140.52824449198815
+ },
+ "QbertNoFrameskip-v4": {
+ "mean": 157.25,
+ "std": 135.56801798359376
+ },
+ "Qbert-ram-v0": {
+ "mean": 162.5,
+ "std": 128.76820259675912
+ },
+ "Qbert-ram-v4": {
+ "mean": 182.25,
+ "std": 156.73604403582476
+ },
+ "Qbert-ramDeterministic-v0": {
+ "mean": 141.75,
+ "std": 126.34550842827774
+ },
+ "Qbert-ramDeterministic-v4": {
+ "mean": 154.0,
+ "std": 136.73514544549255
+ },
+ "Qbert-ramNoFrameskip-v0": {
+ "mean": 178.5,
+ "std": 185.3382043724391
+ },
+ "Qbert-ramNoFrameskip-v4": {
+ "mean": 181.25,
+ "std": 157.13747961578105
+ },
+ "Riverraid-v0": {
+ "mean": 1558.4,
+ "std": 317.9204932054554
+ },
+ "Riverraid-v4": {
+ "mean": 1496.8,
+ "std": 265.8190361881556
+ },
+ "RiverraidDeterministic-v0": {
+ "mean": 1510.4,
+ "std": 386.71674388368547
+ },
+ "RiverraidDeterministic-v4": {
+ "mean": 1516.7,
+ "std": 328.6702146529254
+ },
+ "RiverraidNoFrameskip-v0": {
+ "mean": 1549.4,
+ "std": 361.49362373353136
+ },
+ "RiverraidNoFrameskip-v4": {
+ "mean": 1554.0,
+ "std": 308.2823381252971
+ },
+ "Riverraid-ram-v0": {
+ "mean": 1521.1,
+ "std": 320.13089510386214
+ },
+ "Riverraid-ram-v4": {
+ "mean": 1496.4,
+ "std": 328.321549703945
+ },
+ "Riverraid-ramDeterministic-v0": {
+ "mean": 1487.5,
+ "std": 345.48335705211616
+ },
+ "Riverraid-ramDeterministic-v4": {
+ "mean": 1554.8,
+ "std": 344.56488503618584
+ },
+ "Riverraid-ramNoFrameskip-v0": {
+ "mean": 1537.0,
+ "std": 328.3641271515511
+ },
+ "Riverraid-ramNoFrameskip-v4": {
+ "mean": 1623.7,
+ "std": 363.173939042988
+ },
+ "RoadRunner-v0": {
+ "mean": 25.0,
+ "std": 125.19984025548915
+ },
+ "RoadRunner-v4": {
+ "mean": 12.0,
+ "std": 43.08131845707603
+ },
+ "RoadRunnerDeterministic-v0": {
+ "mean": 11.0,
+ "std": 48.774993593028796
+ },
+ "RoadRunnerDeterministic-v4": {
+ "mean": 19.0,
+ "std": 73.06846104852626
+ },
+ "RoadRunnerNoFrameskip-v0": {
+ "mean": 39.0,
+ "std": 167.26924403487928
+ },
+ "RoadRunnerNoFrameskip-v4": {
+ "mean": 35.0,
+ "std": 65.3834841531101
+ },
+ "RoadRunner-ram-v0": {
+ "mean": 27.0,
+ "std": 85.85452812752511
+ },
+ "RoadRunner-ram-v4": {
+ "mean": 9.0,
+ "std": 44.93328387732194
+ },
+ "RoadRunner-ramDeterministic-v0": {
+ "mean": 41.0,
+ "std": 234.98723369579037
+ },
+ "RoadRunner-ramDeterministic-v4": {
+ "mean": 21.0,
+ "std": 125.13592609638529
+ },
+ "RoadRunner-ramNoFrameskip-v0": {
+ "mean": 41.0,
+ "std": 67.96322535018479
+ },
+ "RoadRunner-ramNoFrameskip-v4": {
+ "mean": 52.0,
+ "std": 139.62807740565648
+ },
+ "Robotank-v0": {
+ "mean": 2.01,
+ "std": 1.6155184926208674
+ },
+ "Robotank-v4": {
+ "mean": 2.05,
+ "std": 1.499166435056495
+ },
+ "RobotankDeterministic-v0": {
+ "mean": 1.93,
+ "std": 1.8560980577544928
+ },
+ "RobotankDeterministic-v4": {
+ "mean": 2.19,
+ "std": 1.553673067282818
+ },
+ "RobotankNoFrameskip-v0": {
+ "mean": 1.69,
+ "std": 1.4049555153100044
+ },
+ "RobotankNoFrameskip-v4": {
+ "mean": 1.78,
+ "std": 1.507182802449656
+ },
+ "Robotank-ram-v0": {
+ "mean": 1.99,
+ "std": 1.4594176920950355
+ },
+ "Robotank-ram-v4": {
+ "mean": 2.09,
+ "std": 1.7151967817133982
+ },
+ "Robotank-ramDeterministic-v0": {
+ "mean": 2.3,
+ "std": 1.6093476939431082
+ },
+ "Robotank-ramDeterministic-v4": {
+ "mean": 2.05,
+ "std": 1.465435088975284
+ },
+ "Robotank-ramNoFrameskip-v0": {
+ "mean": 1.87,
+ "std": 1.3758997056471813
+ },
+ "Robotank-ramNoFrameskip-v4": {
+ "mean": 1.79,
+ "std": 1.498632710172842
+ },
+ "Seaquest-v0": {
+ "mean": 82.4,
+ "std": 63.00984050130584
+ },
+ "Seaquest-v4": {
+ "mean": 86.6,
+ "std": 60.003666554636474
+ },
+ "SeaquestDeterministic-v0": {
+ "mean": 73.8,
+ "std": 53.79182093961869
+ },
+ "SeaquestDeterministic-v4": {
+ "mean": 80.0,
+ "std": 61.44916598294886
+ },
+ "SeaquestNoFrameskip-v0": {
+ "mean": 109.4,
+ "std": 72.41298226147022
+ },
+ "SeaquestNoFrameskip-v4": {
+ "mean": 106.0,
+ "std": 73.62064927722385
+ },
+ "Seaquest-ram-v0": {
+ "mean": 86.0,
+ "std": 61.155539405682624
+ },
+ "Seaquest-ram-v4": {
+ "mean": 87.4,
+ "std": 67.3887230922207
+ },
+ "Seaquest-ramDeterministic-v0": {
+ "mean": 80.8,
+ "std": 62.091545318183215
+ },
+ "Seaquest-ramDeterministic-v4": {
+ "mean": 86.0,
+ "std": 64.52906321960671
+ },
+ "Seaquest-ramNoFrameskip-v0": {
+ "mean": 99.4,
+ "std": 66.54051397457042
+ },
+ "Seaquest-ramNoFrameskip-v4": {
+ "mean": 117.2,
+ "std": 84.47579534991073
+ },
+ "Skiing-v0": {
+ "mean": -16619.23,
+ "std": 1903.7348074508698
+ },
+ "Skiing-v4": {
+ "mean": -16589.53,
+ "std": 2141.852013818882
+ },
+ "SkiingDeterministic-v0": {
+ "mean": -16467.99,
+ "std": 1825.6421965708396
+ },
+ "SkiingDeterministic-v4": {
+ "mean": -16151.98,
+ "std": 1809.29986447797
+ },
+ "SkiingNoFrameskip-v0": {
+ "mean": -17027.31,
+ "std": 1700.3016243890377
+ },
+ "SkiingNoFrameskip-v4": {
+ "mean": -17361.61,
+ "std": 1558.4333472753976
+ },
+ "Skiing-ram-v0": {
+ "mean": -16377.97,
+ "std": 1702.6937860637183
+ },
+ "Skiing-ram-v4": {
+ "mean": -16492.75,
+ "std": 1829.4789278644344
+ },
+ "Skiing-ramDeterministic-v0": {
+ "mean": -16737.99,
+ "std": 1985.5401657735358
+ },
+ "Skiing-ramDeterministic-v4": {
+ "mean": -16054.45,
+ "std": 1804.8648446628906
+ },
+ "Skiing-ramNoFrameskip-v0": {
+ "mean": -16744.35,
+ "std": 1820.8162146411153
+ },
+ "Skiing-ramNoFrameskip-v4": {
+ "mean": -17190.47,
+ "std": 1795.4087526521641
+ },
+ "Solaris-v0": {
+ "mean": 2298.0,
+ "std": 1273.8398643471635
+ },
+ "Solaris-v4": {
+ "mean": 2404.6,
+ "std": 1798.1387154499512
+ },
+ "SolarisDeterministic-v0": {
+ "mean": 2435.0,
+ "std": 1358.1704605829123
+ },
+ "SolarisDeterministic-v4": {
+ "mean": 2244.4,
+ "std": 1373.4353424897731
+ },
+ "SolarisNoFrameskip-v0": {
+ "mean": 2210.4,
+ "std": 1219.421108559303
+ },
+ "SolarisNoFrameskip-v4": {
+ "mean": 2097.2,
+ "std": 1579.0250662988224
+ },
+ "Solaris-ram-v0": {
+ "mean": 2166.4,
+ "std": 1391.4506962160033
+ },
+ "Solaris-ram-v4": {
+ "mean": 2199.0,
+ "std": 1228.8185382716197
+ },
+ "Solaris-ramDeterministic-v0": {
+ "mean": 2452.6,
+ "std": 2132.738436845925
+ },
+ "Solaris-ramDeterministic-v4": {
+ "mean": 2353.0,
+ "std": 1441.1311529489603
+ },
+ "Solaris-ramNoFrameskip-v0": {
+ "mean": 2341.0,
+ "std": 1571.601412572539
+ },
+ "Solaris-ramNoFrameskip-v4": {
+ "mean": 2133.2,
+ "std": 905.6013250873696
+ },
+ "SpaceInvaders-v0": {
+ "mean": 143.1,
+ "std": 78.06657415309064
+ },
+ "SpaceInvaders-v4": {
+ "mean": 167.25,
+ "std": 114.0644006690957
+ },
+ "SpaceInvadersDeterministic-v0": {
+ "mean": 192.0,
+ "std": 118.47995611072785
+ },
+ "SpaceInvadersDeterministic-v4": {
+ "mean": 160.65,
+ "std": 118.64580692127305
+ },
+ "SpaceInvadersNoFrameskip-v0": {
+ "mean": 161.75,
+ "std": 101.1888704354387
+ },
+ "SpaceInvadersNoFrameskip-v4": {
+ "mean": 164.1,
+ "std": 101.58341400051486
+ },
+ "SpaceInvaders-ram-v0": {
+ "mean": 132.55,
+ "std": 79.81383025516315
+ },
+ "SpaceInvaders-ram-v4": {
+ "mean": 143.35,
+ "std": 99.87505944929396
+ },
+ "SpaceInvaders-ramDeterministic-v0": {
+ "mean": 156.9,
+ "std": 111.07155351393986
+ },
+ "SpaceInvaders-ramDeterministic-v4": {
+ "mean": 156.55,
+ "std": 98.79700147271676
+ },
+ "SpaceInvaders-ramNoFrameskip-v0": {
+ "mean": 160.15,
+ "std": 94.7165640212946
+ },
+ "SpaceInvaders-ramNoFrameskip-v4": {
+ "mean": 153.05,
+ "std": 98.01758770751297
+ },
+ "StarGunner-v0": {
+ "mean": 752.0,
+ "std": 430.92458736999447
+ },
+ "StarGunner-v4": {
+ "mean": 670.0,
+ "std": 356.2302626111375
+ },
+ "StarGunnerDeterministic-v0": {
+ "mean": 670.0,
+ "std": 308.3828789021855
+ },
+ "StarGunnerDeterministic-v4": {
+ "mean": 638.0,
+ "std": 348.9355241301751
+ },
+ "StarGunnerNoFrameskip-v0": {
+ "mean": 655.0,
+ "std": 357.8756767370479
+ },
+ "StarGunnerNoFrameskip-v4": {
+ "mean": 645.0,
+ "std": 361.76649927819466
+ },
+ "StarGunner-ram-v0": {
+ "mean": 687.0,
+ "std": 322.38331222319806
+ },
+ "StarGunner-ram-v4": {
+ "mean": 740.0,
+ "std": 409.38978980917443
+ },
+ "StarGunner-ramDeterministic-v0": {
+ "mean": 691.0,
+ "std": 383.4305673782412
+ },
+ "StarGunner-ramDeterministic-v4": {
+ "mean": 620.0,
+ "std": 342.92856398964494
+ },
+ "StarGunner-ramNoFrameskip-v0": {
+ "mean": 720.0,
+ "std": 461.30250378683183
+ },
+ "StarGunner-ramNoFrameskip-v4": {
+ "mean": 606.0,
+ "std": 337.28919342309206
+ },
+ "Tennis-v0": {
+ "mean": -23.92,
+ "std": 0.2712931993250107
+ },
+ "Tennis-v4": {
+ "mean": -23.94,
+ "std": 0.23748684174075801
+ },
+ "TennisDeterministic-v0": {
+ "mean": -23.9,
+ "std": 0.29999999999999993
+ },
+ "TennisDeterministic-v4": {
+ "mean": -23.86,
+ "std": 0.374699879903903
+ },
+ "TennisNoFrameskip-v0": {
+ "mean": -23.96,
+ "std": 0.19595917942265423
+ },
+ "TennisNoFrameskip-v4": {
+ "mean": -24.0,
+ "std": 0.0
+ },
+ "Tennis-ram-v0": {
+ "mean": -23.95,
+ "std": 0.21794494717703372
+ },
+ "Tennis-ram-v4": {
+ "mean": -23.95,
+ "std": 0.21794494717703303
+ },
+ "Tennis-ramDeterministic-v0": {
+ "mean": -23.95,
+ "std": 0.21794494717703372
+ },
+ "Tennis-ramDeterministic-v4": {
+ "mean": -23.92,
+ "std": 0.30594117081556704
+ },
+ "Tennis-ramNoFrameskip-v0": {
+ "mean": -24.0,
+ "std": 0.0
+ },
+ "Tennis-ramNoFrameskip-v4": {
+ "mean": -24.0,
+ "std": 0.0
+ },
+ "TimePilot-v0": {
+ "mean": 3485.0,
+ "std": 1855.6602598536188
+ },
+ "TimePilot-v4": {
+ "mean": 3354.0,
+ "std": 2021.6537784694985
+ },
+ "TimePilotDeterministic-v0": {
+ "mean": 3186.0,
+ "std": 1823.7883649151838
+ },
+ "TimePilotDeterministic-v4": {
+ "mean": 3391.0,
+ "std": 1976.8204268471125
+ },
+ "TimePilotNoFrameskip-v0": {
+ "mean": 3499.0,
+ "std": 1984.867501875125
+ },
+ "TimePilotNoFrameskip-v4": {
+ "mean": 3151.0,
+ "std": 1685.1406469490908
+ },
+ "TimePilot-ram-v0": {
+ "mean": 3275.0,
+ "std": 1859.751327462895
+ },
+ "TimePilot-ram-v4": {
+ "mean": 3673.0,
+ "std": 1802.046336807131
+ },
+ "TimePilot-ramDeterministic-v0": {
+ "mean": 2983.0,
+ "std": 1910.1337649494603
+ },
+ "TimePilot-ramDeterministic-v4": {
+ "mean": 3258.0,
+ "std": 1856.727228216358
+ },
+ "TimePilot-ramNoFrameskip-v0": {
+ "mean": 3493.0,
+ "std": 1838.3827131476187
+ },
+ "TimePilot-ramNoFrameskip-v4": {
+ "mean": 3138.0,
+ "std": 1667.080082059647
+ },
+ "Tutankham-v0": {
+ "mean": 12.14,
+ "std": 14.872135018214431
+ },
+ "Tutankham-v4": {
+ "mean": 12.29,
+ "std": 16.264252211522056
+ },
+ "TutankhamDeterministic-v0": {
+ "mean": 7.3,
+ "std": 10.79490620616965
+ },
+ "TutankhamDeterministic-v4": {
+ "mean": 9.27,
+ "std": 12.357876031098547
+ },
+ "TutankhamNoFrameskip-v0": {
+ "mean": 14.48,
+ "std": 15.391867982801827
+ },
+ "TutankhamNoFrameskip-v4": {
+ "mean": 15.45,
+ "std": 19.062725408503372
+ },
+ "Tutankham-ram-v0": {
+ "mean": 13.36,
+ "std": 17.799730335035978
+ },
+ "Tutankham-ram-v4": {
+ "mean": 10.3,
+ "std": 14.234113952051953
+ },
+ "Tutankham-ramDeterministic-v0": {
+ "mean": 10.01,
+ "std": 14.960945825715699
+ },
+ "Tutankham-ramDeterministic-v4": {
+ "mean": 11.26,
+ "std": 15.502657836642076
+ },
+ "Tutankham-ramNoFrameskip-v0": {
+ "mean": 14.18,
+ "std": 16.87387329571963
+ },
+ "Tutankham-ramNoFrameskip-v4": {
+ "mean": 15.26,
+ "std": 19.253893112822666
+ },
+ "UpNDown-v0": {
+ "mean": 382.4,
+ "std": 407.77719406558276
+ },
+ "UpNDown-v4": {
+ "mean": 451.0,
+ "std": 438.0011415510238
+ },
+ "UpNDownDeterministic-v0": {
+ "mean": 600.7,
+ "std": 505.64464794952585
+ },
+ "UpNDownDeterministic-v4": {
+ "mean": 360.8,
+ "std": 355.498748239709
+ },
+ "UpNDownNoFrameskip-v0": {
+ "mean": 200.0,
+ "std": 193.98969044771425
+ },
+ "UpNDownNoFrameskip-v4": {
+ "mean": 125.2,
+ "std": 83.9461732302313
+ },
+ "UpNDown-ram-v0": {
+ "mean": 421.0,
+ "std": 490.4090129677472
+ },
+ "UpNDown-ram-v4": {
+ "mean": 382.3,
+ "std": 424.5700295593178
+ },
+ "UpNDown-ramDeterministic-v0": {
+ "mean": 619.1,
+ "std": 571.1638906653676
+ },
+ "UpNDown-ramDeterministic-v4": {
+ "mean": 498.3,
+ "std": 491.22103985883996
+ },
+ "UpNDown-ramNoFrameskip-v0": {
+ "mean": 147.0,
+ "std": 154.27572718998928
+ },
+ "UpNDown-ramNoFrameskip-v4": {
+ "mean": 119.8,
+ "std": 44.29401765475785
+ },
+ "Venture-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "VentureDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "VentureDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "VentureNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "VentureNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ram-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ram-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ramDeterministic-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ramDeterministic-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ramNoFrameskip-v0": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Venture-ramNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "VideoPinball-v0": {
+ "mean": 21367.92,
+ "std": 17556.126217181285
+ },
+ "VideoPinball-v4": {
+ "mean": 23952.26,
+ "std": 27080.712190272985
+ },
+ "VideoPinballDeterministic-v0": {
+ "mean": 20766.83,
+ "std": 16057.55676499697
+ },
+ "VideoPinballDeterministic-v4": {
+ "mean": 27449.96,
+ "std": 22889.760570578277
+ },
+ "VideoPinballNoFrameskip-v0": {
+ "mean": 31742.53,
+ "std": 39491.826383051724
+ },
+ "VideoPinballNoFrameskip-v4": {
+ "mean": 25365.15,
+ "std": 22216.58844349195
+ },
+ "VideoPinball-ram-v0": {
+ "mean": 27251.43,
+ "std": 21868.144384128707
+ },
+ "VideoPinball-ram-v4": {
+ "mean": 22449.74,
+ "std": 21474.35637481133
+ },
+ "VideoPinball-ramDeterministic-v0": {
+ "mean": 22851.29,
+ "std": 21145.883776420884
+ },
+ "VideoPinball-ramDeterministic-v4": {
+ "mean": 22138.97,
+ "std": 20308.8014483647
+ },
+ "VideoPinball-ramNoFrameskip-v0": {
+ "mean": 28336.62,
+ "std": 26998.936443415696
+ },
+ "VideoPinball-ramNoFrameskip-v4": {
+ "mean": 34272.72,
+ "std": 38923.28963155093
+ },
+ "WizardOfWor-v0": {
+ "mean": 643.0,
+ "std": 525.7860781724826
+ },
+ "WizardOfWor-v4": {
+ "mean": 695.0,
+ "std": 576.0859310901457
+ },
+ "WizardOfWorDeterministic-v0": {
+ "mean": 631.0,
+ "std": 551.4879871765114
+ },
+ "WizardOfWorDeterministic-v4": {
+ "mean": 621.0,
+ "std": 540.9796669007071
+ },
+ "WizardOfWorNoFrameskip-v0": {
+ "mean": 763.0,
+ "std": 647.0942744299319
+ },
+ "WizardOfWorNoFrameskip-v4": {
+ "mean": 784.0,
+ "std": 684.3566321736058
+ },
+ "WizardOfWor-ram-v0": {
+ "mean": 700.0,
+ "std": 582.5804665451803
+ },
+ "WizardOfWor-ram-v4": {
+ "mean": 706.0,
+ "std": 593.939390847248
+ },
+ "WizardOfWor-ramDeterministic-v0": {
+ "mean": 597.0,
+ "std": 416.7625223073687
+ },
+ "WizardOfWor-ramDeterministic-v4": {
+ "mean": 638.0,
+ "std": 526.6459911553491
+ },
+ "WizardOfWor-ramNoFrameskip-v0": {
+ "mean": 792.0,
+ "std": 573.3550383488401
+ },
+ "WizardOfWor-ramNoFrameskip-v4": {
+ "mean": 724.0,
+ "std": 569.0553575883457
+ },
+ "YarsRevenge-v0": {
+ "mean": 3235.71,
+ "std": 825.9027218141372
+ },
+ "YarsRevenge-v4": {
+ "mean": 3241.86,
+ "std": 750.8401829950233
+ },
+ "YarsRevengeDeterministic-v0": {
+ "mean": 3043.24,
+ "std": 778.5125062579277
+ },
+ "YarsRevengeDeterministic-v4": {
+ "mean": 3244.79,
+ "std": 812.750789541296
+ },
+ "YarsRevengeNoFrameskip-v0": {
+ "mean": 3241.93,
+ "std": 692.6291252178182
+ },
+ "YarsRevengeNoFrameskip-v4": {
+ "mean": 3369.27,
+ "std": 612.8237243286196
+ },
+ "YarsRevenge-ram-v0": {
+ "mean": 3169.72,
+ "std": 722.7541640142933
+ },
+ "YarsRevenge-ram-v4": {
+ "mean": 3275.35,
+ "std": 989.2559362975791
+ },
+ "YarsRevenge-ramDeterministic-v0": {
+ "mean": 3228.85,
+ "std": 728.1094200049881
+ },
+ "YarsRevenge-ramDeterministic-v4": {
+ "mean": 3158.92,
+ "std": 733.5002478527188
+ },
+ "YarsRevenge-ramNoFrameskip-v0": {
+ "mean": 3232.65,
+ "std": 627.814692007124
+ },
+ "YarsRevenge-ramNoFrameskip-v4": {
+ "mean": 3246.76,
+ "std": 689.4990372727143
+ },
+ "Zaxxon-v0": {
+ "mean": 73.0,
+ "std": 345.50108538179734
+ },
+ "Zaxxon-v4": {
+ "mean": 12.0,
+ "std": 84.0
+ },
+ "ZaxxonDeterministic-v0": {
+ "mean": 40.0,
+ "std": 269.81475126464085
+ },
+ "ZaxxonDeterministic-v4": {
+ "mean": 6.0,
+ "std": 34.11744421846396
+ },
+ "ZaxxonNoFrameskip-v0": {
+ "mean": 2.0,
+ "std": 19.8997487421324
+ },
+ "ZaxxonNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "Zaxxon-ram-v0": {
+ "mean": 8.0,
+ "std": 48.33218389437829
+ },
+ "Zaxxon-ram-v4": {
+ "mean": 14.0,
+ "std": 86.04649905719582
+ },
+ "Zaxxon-ramDeterministic-v0": {
+ "mean": 26.0,
+ "std": 134.62540622037136
+ },
+ "Zaxxon-ramDeterministic-v4": {
+ "mean": 18.0,
+ "std": 144.48529336925608
+ },
+ "Zaxxon-ramNoFrameskip-v0": {
+ "mean": 7.0,
+ "std": 69.6491205974634
+ },
+ "Zaxxon-ramNoFrameskip-v4": {
+ "mean": 0.0,
+ "std": 0.0
+ },
+ "CubeCrash-v0": {
+ "mean": -0.6465000000000001,
+ "std": 0.7812033986101181
+ },
+ "CubeCrashSparse-v0": {
+ "mean": -0.68,
+ "std": 0.7332121111929341
+ },
+ "CubeCrashScreenBecomesBlack-v0": {
+ "mean": -0.62,
+ "std": 0.7846018098373211
+ },
+ "MemorizeDigits-v0": {
+ "mean": -18.39,
+ "std": 3.733349702345067
+ }
+}
diff --git a/slm_lab/spec/base.json b/slm_lab/spec/base.json
index 100e70a65..faf012465 100644
--- a/slm_lab/spec/base.json
+++ b/slm_lab/spec/base.json
@@ -13,7 +13,7 @@
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
"unity": {
"gridSize": 6,
"numObstacles": 2,
@@ -27,14 +27,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 4,
- "num_gpus": 0
- }
},
"search": {
"agent": [{
@@ -63,7 +58,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -72,7 +67,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -96,7 +90,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": 10,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
@@ -105,7 +99,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -126,7 +119,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": 10,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
@@ -135,7 +128,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -156,7 +148,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": 10,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
@@ -165,7 +157,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -190,7 +181,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": 10,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
@@ -199,7 +190,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch",
@@ -220,7 +210,7 @@
"env": [{
"name": "3dball",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -229,7 +219,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -258,7 +247,7 @@
"env": [{
"name": "tennis",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -267,7 +256,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -287,11 +275,11 @@
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}, {
"name": "3dball",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -300,7 +288,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -329,11 +316,11 @@
"env": [{
"name": "tennis",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}, {
"name": "tennis",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -342,7 +329,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -371,11 +357,11 @@
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}, {
"name": "3dball",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "outer",
@@ -384,7 +370,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -413,11 +398,11 @@
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}, {
"name": "3dball",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "inner",
@@ -426,7 +411,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -446,11 +430,11 @@
"env": [{
"name": "gridworld",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}, {
"name": "3dball",
"max_t": 20,
- "max_tick": 3,
+ "max_frame": 3,
}],
"body": {
"product": "custom",
@@ -473,7 +457,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/benchmark/ddqn_lunar.json b/slm_lab/spec/benchmark/ddqn_lunar.json
index 7cd45d84e..8aa9f5f37 100644
--- a/slm_lab/spec/benchmark/ddqn_lunar.json
+++ b/slm_lab/spec/benchmark/ddqn_lunar.json
@@ -14,18 +14,16 @@
"end_step": 14000
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -57,8 +55,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000
+ "max_frame": 250000
}],
"body": {
"product": "outer",
@@ -67,13 +67,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 62,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 62
- }
},
}
}
diff --git a/slm_lab/spec/benchmark/dqn_lunar.json b/slm_lab/spec/benchmark/dqn_lunar.json
index 9cf5b9a06..27926c010 100644
--- a/slm_lab/spec/benchmark/dqn_lunar.json
+++ b/slm_lab/spec/benchmark/dqn_lunar.json
@@ -14,18 +14,16 @@
"end_step": 12000
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": false
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -56,8 +54,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000
+ "max_frame": 250000
}],
"body": {
"product": "outer",
@@ -66,13 +66,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 62,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 62
- }
},
}
}
diff --git a/slm_lab/spec/demo.json b/slm_lab/spec/demo.json
index 79e415432..305b66f64 100644
--- a/slm_lab/spec/demo.json
+++ b/slm_lab/spec/demo.json
@@ -11,14 +11,13 @@
"start_val": 1.0,
"end_val": 0.1,
"start_step": 0,
- "end_step": 800,
+ "end_step": 1000,
},
"gamma": 0.99,
- "training_batch_epoch": 10,
- "training_epoch": 4,
- "training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": false
+ "training_batch_iter": 8,
+ "training_iter": 4,
+ "training_frequency": 4,
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -36,7 +35,7 @@
},
"optim_spec": {
"name": "Adam",
- "lr": 0.002
+ "lr": 0.02
},
"lr_scheduler_spec": {
"name": "StepLR",
@@ -52,7 +51,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 30000
+ "max_frame": 10000
}],
"body": {
"product": "outer",
@@ -60,15 +59,10 @@
},
"meta": {
"distributed": false,
- "eval_frequency": 5000,
- "max_tick_unit": "total_t",
+ "eval_frequency": 2000,
"max_trial": 4,
- "max_session": 1,
+ "max_session": 2,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 4,
- "num_gpus": 0
- }
},
"search": {
"agent": [{
diff --git a/slm_lab/spec/experimental/a2c.json b/slm_lab/spec/experimental/a2c.json
index 9ba83a57a..a8b0d7510 100644
--- a/slm_lab/spec/experimental/a2c.json
+++ b/slm_lab/spec/experimental/a2c.json
@@ -20,8 +20,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -52,7 +50,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -61,7 +59,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -104,8 +101,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -136,7 +131,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -145,7 +140,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -188,12 +182,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicyConcatReplay",
- "concat_len": 4
+ "name": "OnPolicyReplay"
},
"net": {
"type": "MLPNet",
@@ -220,8 +211,10 @@
}],
"env": [{
"name": "CartPole-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -230,7 +223,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -273,11 +265,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -309,7 +299,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -318,7 +308,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -361,11 +350,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -397,7 +384,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -406,7 +393,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -449,8 +435,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -481,7 +465,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -490,7 +474,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -533,8 +516,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -565,7 +546,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -574,7 +555,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -617,11 +597,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -653,7 +631,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -662,7 +640,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -705,11 +682,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -741,7 +716,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -750,7 +725,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -793,12 +767,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.5,
"training_frequency": 1,
- "training_epoch": 1,
- "normalize_state": false
},
"memory": {
- "name": "OnPolicyAtariReplay",
- "stack_len": 4
+ "name": "OnPolicyReplay",
},
"net": {
"type": "ConvNet",
@@ -831,8 +802,11 @@
}],
"env": [{
"name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 10000000,
+ "max_frame": 10000000,
}],
"body": {
"product": "outer",
@@ -841,13 +815,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
- "max_session": 1,
+ "max_session": 4,
"max_trial": 1,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16,
- }
}
},
}
diff --git a/slm_lab/spec/experimental/a2c/a2c_atari.json b/slm_lab/spec/experimental/a2c/a2c_atari.json
new file mode 100644
index 000000000..670c725d5
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_atari.json
@@ -0,0 +1,172 @@
+{
+ "a2c_atari": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay"
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1,
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "a2c_atari_full": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay"
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1,
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a2c/a2c_cont.json b/slm_lab/spec/experimental/a2c/a2c_cont.json
new file mode 100644
index 000000000..884d92753
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_cont.json
@@ -0,0 +1,78 @@
+{
+ "a2c_cont": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.0,
+ "end_val": 0.0,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 2048
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "MLPNet",
+ "shared": false,
+ "hid_layers": [64, 64],
+ "hid_layers_activation": "tanh",
+ "init_fn": "orthogonal_",
+ "normalize": false,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e6
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e6
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 20000,
+ "eval_frequency": 20000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "RoboschoolAnt-v1", "BipedalWalker-v2", "RoboschoolHalfCheetah-v1", "RoboschoolHopper-v1", "RoboschoolInvertedPendulum-v1", "Pendulum-v0"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a2c/a2c_gae_atari.json b/slm_lab/spec/experimental/a2c/a2c_gae_atari.json
new file mode 100644
index 000000000..0ec7667a6
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_gae_atari.json
@@ -0,0 +1,172 @@
+{
+ "a2c_gae_atari": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "a2c_gae_atari_full": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a2c/a2c_gae_cont.json b/slm_lab/spec/experimental/a2c/a2c_gae_cont.json
new file mode 100644
index 000000000..a682e9cf3
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_gae_cont.json
@@ -0,0 +1,78 @@
+{
+ "a2c_gae_cont": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.0,
+ "end_val": 0.0,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 2048
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "MLPNet",
+ "shared": false,
+ "hid_layers": [64, 64],
+ "hid_layers_activation": "tanh",
+ "init_fn": "orthogonal_",
+ "normalize": false,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e6
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e6
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 20000,
+ "eval_frequency": 20000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "RoboschoolAnt-v1", "BipedalWalker-v2", "RoboschoolHalfCheetah-v1", "RoboschoolHopper-v1", "RoboschoolInvertedPendulum-v1", "Pendulum-v0"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a2c/a2c_gae_cont_hard.json b/slm_lab/spec/experimental/a2c/a2c_gae_cont_hard.json
new file mode 100644
index 000000000..16f46b505
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_gae_cont_hard.json
@@ -0,0 +1,78 @@
+{
+ "a2c_gae_cont_hard": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.0,
+ "end_val": 0.0,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 2048
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "MLPNet",
+ "shared": false,
+ "hid_layers": [64, 64],
+ "hid_layers_activation": "tanh",
+ "init_fn": "orthogonal_",
+ "normalize": false,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e6
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "num_envs": 32,
+ "max_t": null,
+ "max_frame": 5e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 20000,
+ "eval_frequency": 20000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "RoboschoolHumanoid-v1"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/ppo_enduro.json b/slm_lab/spec/experimental/a2c/a2c_gae_pong.json
similarity index 52%
rename from slm_lab/spec/experimental/ppo_enduro.json
rename to slm_lab/spec/experimental/a2c/a2c_gae_pong.json
index 95e373886..2032de2ef 100644
--- a/slm_lab/spec/experimental/ppo_enduro.json
+++ b/slm_lab/spec/experimental/a2c/a2c_gae_pong.json
@@ -1,21 +1,15 @@
{
- "ppo_shared_enduro": {
+ "a2c_gae_pong": {
"agent": [{
- "name": "PPO",
+ "name": "A2C",
"algorithm": {
- "name": "PPO",
+ "name": "ActorCritic",
"action_pdtype": "default",
"action_policy": "default",
"explore_var_spec": null,
"gamma": 0.99,
"lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
+ "num_step_returns": null,
"entropy_coef_spec": {
"name": "no_decay",
"start_val": 0.01,
@@ -23,13 +17,11 @@
"start_step": 0,
"end_step": 0
},
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
},
"memory": {
- "name": "OnPolicyAtariReplay"
+ "name": "OnPolicyBatchReplay",
},
"net": {
"type": "ConvNet",
@@ -37,29 +29,42 @@
"conv_hid_layers": [
[32, 8, 4, 0, 1],
[64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
+ [32, 3, 1, 0, 1]
],
- "fc_hid_layers": [256],
+ "fc_hid_layers": [512],
"hid_layers_activation": "relu",
- "init_fn": null,
+ "init_fn": "orthogonal_",
+ "normalize": true,
"batch_norm": false,
- "clip_grad_val": 1.0,
+ "clip_grad_val": 0.5,
"use_same_optim": false,
"loss_spec": {
- "name": "SmoothL1Loss"
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
},
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
},
"lr_scheduler_spec": null,
"gpu": true
}
}],
"env": [{
- "name": "EnduroNoFrameskip-v4",
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
"max_t": null,
- "max_tick": 10000000
+ "max_frame": 1e7
}],
"body": {
"product": "outer",
@@ -67,14 +72,10 @@
},
"meta": {
"distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
"max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
+ "max_trial": 1,
}
}
}
diff --git a/slm_lab/spec/experimental/a2c/a2c_pong.json b/slm_lab/spec/experimental/a2c/a2c_pong.json
new file mode 100644
index 000000000..733636c19
--- /dev/null
+++ b/slm_lab/spec/experimental/a2c/a2c_pong.json
@@ -0,0 +1,82 @@
+{
+ "a2c_pong": {
+ "agent": [{
+ "name": "A2C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay"
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1,
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a3c.json b/slm_lab/spec/experimental/a3c/a3c.json
similarity index 92%
rename from slm_lab/spec/experimental/a3c.json
rename to slm_lab/spec/experimental/a3c/a3c.json
index e17d98d06..1a7582baf 100644
--- a/slm_lab/spec/experimental/a3c.json
+++ b/slm_lab/spec/experimental/a3c/a3c.json
@@ -20,8 +20,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.96,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -52,16 +50,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -104,8 +101,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -136,16 +131,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -188,8 +182,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.08,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -220,16 +212,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 400,
+ "max_frame": 400,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -272,11 +263,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -308,16 +297,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -360,11 +348,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -396,16 +382,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -448,8 +433,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -480,16 +463,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -532,8 +514,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -564,16 +544,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -616,11 +595,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -652,16 +629,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -704,11 +680,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -740,16 +714,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -792,8 +765,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
},
"memory": {
"name": "OnPolicyReplay"
@@ -829,16 +800,15 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -865,8 +835,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
},
"memory": {
"name": "OnPolicyReplay"
@@ -902,16 +870,15 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1,
+ "max_frame": 1,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/a3c/a3c_atari.json b/slm_lab/spec/experimental/a3c/a3c_atari.json
new file mode 100644
index 000000000..623ba8ea1
--- /dev/null
+++ b/slm_lab/spec/experimental/a3c/a3c_atari.json
@@ -0,0 +1,326 @@
+{
+ "a3c_atari": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "gpu_a3c_atari": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "a3c_atari_full": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ },
+ "gpu_a3c_atari_full": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a3c/a3c_gae_atari.json b/slm_lab/spec/experimental/a3c/a3c_gae_atari.json
new file mode 100644
index 000000000..42ef6cb68
--- /dev/null
+++ b/slm_lab/spec/experimental/a3c/a3c_gae_atari.json
@@ -0,0 +1,326 @@
+{
+ "a3c_gae_atari": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "gpu_a3c_gae_atari": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "a3c_gae_atari_full": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ },
+ "gpu_a3c_gae_atari_full": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a3c/a3c_gae_pong.json b/slm_lab/spec/experimental/a3c/a3c_gae_pong.json
new file mode 100644
index 000000000..1bec5e98f
--- /dev/null
+++ b/slm_lab/spec/experimental/a3c/a3c_gae_pong.json
@@ -0,0 +1,152 @@
+{
+ "a3c_gae_pong": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ }
+ },
+ "gpu_a3c_gae_pong": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "num_step_returns": null,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 32
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/a3c/a3c_pong.json b/slm_lab/spec/experimental/a3c/a3c_pong.json
new file mode 100644
index 000000000..58366bacd
--- /dev/null
+++ b/slm_lab/spec/experimental/a3c/a3c_pong.json
@@ -0,0 +1,152 @@
+{
+ "a3c_pong": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": false
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "synced",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ }
+ },
+ "gpu_a3c_pong": {
+ "agent": [{
+ "name": "A3C",
+ "algorithm": {
+ "name": "ActorCritic",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": null,
+ "num_step_returns": 5,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 5
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "critic_optim_spec": {
+ "name": "GlobalAdam",
+ "lr": 1e-4
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": "shared",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 16,
+ "max_trial": 1,
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/cartpole.json b/slm_lab/spec/experimental/cartpole.json
index 4019d434c..3da74c800 100644
--- a/slm_lab/spec/experimental/cartpole.json
+++ b/slm_lab/spec/experimental/cartpole.json
@@ -15,8 +15,7 @@
"start_step": 0,
"end_step": 2000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -44,7 +43,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -53,13 +52,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -94,11 +89,10 @@
"start_step": 0,
"end_step": 2000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -127,7 +121,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -136,13 +130,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -181,9 +171,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": false
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -214,7 +202,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -223,13 +211,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -268,9 +252,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -301,7 +283,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -310,13 +292,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -358,9 +336,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -391,7 +367,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -400,13 +376,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 23,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -448,12 +420,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -485,7 +455,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -494,13 +464,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -542,9 +508,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -575,7 +539,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -584,13 +548,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -630,9 +590,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -663,7 +621,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -672,13 +630,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -721,9 +675,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -754,22 +706,18 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 23,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -808,12 +756,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -845,7 +791,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -854,13 +800,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -909,8 +851,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -941,7 +882,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -950,13 +891,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1006,13 +943,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 8,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -1043,7 +979,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1052,13 +988,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1103,13 +1035,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -1140,7 +1070,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1149,13 +1079,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1194,8 +1120,7 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
"name": "OnPolicyBatchReplay"
@@ -1223,7 +1148,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1232,13 +1157,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1271,11 +1192,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
- "name": "OnPolicySeqBatchReplay"
+ "name": "OnPolicyBatchReplay"
},
"net": {
"type": "RecurrentNet",
@@ -1304,7 +1224,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1313,13 +1233,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1353,18 +1269,16 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 10000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -1390,8 +1304,10 @@
}],
"env": [{
"name": "CartPole-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1400,13 +1316,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1417,7 +1329,6 @@
},
},
"memory": {
- "name__choice": ["Replay", "ConcatReplay"],
"batch_size__choice": [32, 64, 128],
"use_cer__choice": [false, true],
},
@@ -1445,11 +1356,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 10,
- "training_epoch": 4,
+ "training_batch_iter": 10,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -1483,22 +1393,18 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 23,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
@@ -1532,18 +1438,16 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 10000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -1569,8 +1473,10 @@
}],
"env": [{
"name": "CartPole-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1579,13 +1485,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1596,7 +1498,6 @@
},
},
"memory": {
- "name__choice": ["Replay", "ConcatReplay"],
"batch_size__choice": [32, 64, 128],
"use_cer__choice": [false, true],
},
@@ -1624,14 +1525,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": false,
@@ -1665,7 +1565,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1674,13 +1574,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1718,14 +1614,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": false,
@@ -1759,7 +1654,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1768,13 +1663,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1812,18 +1703,16 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 10000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -1849,8 +1738,10 @@
}],
"env": [{
"name": "CartPole-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1859,13 +1750,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1876,7 +1763,6 @@
},
},
"memory": {
- "name__choice": ["Replay", "ConcatReplay"],
"batch_size__choice": [32, 64, 128],
"use_cer__choice": [false, true],
},
@@ -1904,18 +1790,16 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 10000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -1941,8 +1825,10 @@
}],
"env": [{
"name": "CartPole-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -1951,13 +1837,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -1968,7 +1850,6 @@
},
},
"memory": {
- "name__choice": ["Replay", "ConcatReplay"],
"batch_size__choice": [32, 64, 128],
"use_cer__choice": [false, true],
},
@@ -1996,14 +1877,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": false,
@@ -2037,7 +1917,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -2046,13 +1926,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -2090,14 +1966,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 128,
- "normalize_state": true
+ "training_start_step": 128
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": false,
@@ -2131,7 +2006,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -2140,13 +2015,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 64,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
},
"search": {
"agent": [{
@@ -2184,11 +2055,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 10,
- "training_epoch": 4,
+ "training_batch_iter": 10,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -2222,7 +2092,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 40000,
+ "max_frame": 40000,
}],
"body": {
"product": "outer",
@@ -2231,13 +2101,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
diff --git a/slm_lab/spec/experimental/ddqn.json b/slm_lab/spec/experimental/ddqn.json
index 9019b65d5..3cef079ad 100644
--- a/slm_lab/spec/experimental/ddqn.json
+++ b/slm_lab/spec/experimental/ddqn.json
@@ -14,11 +14,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 10,
- "training_epoch": 4,
+ "training_batch_iter": 10,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -52,7 +51,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 400,
+ "max_frame": 400,
}],
"body": {
"product": "outer",
@@ -61,7 +60,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -97,11 +95,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 10,
- "normalize_state": true
+ "training_start_step": 10
},
"memory": {
"name": "Replay",
@@ -135,7 +132,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -144,7 +141,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -186,14 +182,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 10,
- "normalize_state": true
+ "training_start_step": 10
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -228,7 +223,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -237,7 +232,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -279,14 +273,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 10,
- "normalize_state": true
+ "training_start_step": 10
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -321,7 +314,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -330,7 +323,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -372,17 +364,15 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 100,
- "training_start_step": 100,
- "normalize_state": false
+ "training_start_step": 100
},
"memory": {
- "name": "AtariReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 250000,
- "stack_len": 4,
"use_cer": true
},
"net": {
@@ -420,8 +410,11 @@
}],
"env": [{
"name": "BreakoutDeterministic-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 50000,
+ "max_frame": 50000,
}],
"body": {
"product": "outer",
@@ -430,7 +423,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -451,17 +443,15 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 100,
- "training_start_step": 100,
- "normalize_state": false
+ "training_start_step": 100
},
"memory": {
- "name": "AtariReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 250000,
- "stack_len": 4,
"use_cer": true
},
"net": {
@@ -499,8 +489,11 @@
}],
"env": [{
"name": "BreakoutDeterministic-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 50000,
+ "max_frame": 50000,
}],
"body": {
"product": "outer",
@@ -509,7 +502,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/ddqn_beamrider.json b/slm_lab/spec/experimental/ddqn_beamrider.json
deleted file mode 100644
index d8f92f8dc..000000000
--- a/slm_lab/spec/experimental/ddqn_beamrider.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_beamrider": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false,
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BeamRiderNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_breakout.json b/slm_lab/spec/experimental/ddqn_breakout.json
deleted file mode 100644
index 4b239e86c..000000000
--- a/slm_lab/spec/experimental/ddqn_breakout.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_breakout": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BreakoutNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_enduro.json b/slm_lab/spec/experimental/ddqn_enduro.json
deleted file mode 100644
index 866a8bb4f..000000000
--- a/slm_lab/spec/experimental/ddqn_enduro.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_enduro": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "EnduroNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_mspacman.json b/slm_lab/spec/experimental/ddqn_mspacman.json
deleted file mode 100644
index c20c468a7..000000000
--- a/slm_lab/spec/experimental/ddqn_mspacman.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_mspacman": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "MsPacmanNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_beamrider.json b/slm_lab/spec/experimental/ddqn_per_beamrider.json
deleted file mode 100644
index 021273b9c..000000000
--- a/slm_lab/spec/experimental/ddqn_per_beamrider.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_beamrider": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false,
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BeamRiderNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_breakout.json b/slm_lab/spec/experimental/ddqn_per_breakout.json
deleted file mode 100644
index e22eefc22..000000000
--- a/slm_lab/spec/experimental/ddqn_per_breakout.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_breakout": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BreakoutNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_enduro.json b/slm_lab/spec/experimental/ddqn_per_enduro.json
deleted file mode 100644
index ebc5eda04..000000000
--- a/slm_lab/spec/experimental/ddqn_per_enduro.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_enduro": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "EnduroNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_mspacman.json b/slm_lab/spec/experimental/ddqn_per_mspacman.json
deleted file mode 100644
index 28880c4c3..000000000
--- a/slm_lab/spec/experimental/ddqn_per_mspacman.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_mspacman": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "MsPacmanNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_pong.json b/slm_lab/spec/experimental/ddqn_per_pong.json
deleted file mode 100644
index 5e8be5c08..000000000
--- a/slm_lab/spec/experimental/ddqn_per_pong.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_pong": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "PongNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_qbert.json b/slm_lab/spec/experimental/ddqn_per_qbert.json
deleted file mode 100644
index a54171076..000000000
--- a/slm_lab/spec/experimental/ddqn_per_qbert.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_qbert": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "QbertNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_seaquest.json b/slm_lab/spec/experimental/ddqn_per_seaquest.json
deleted file mode 100644
index f0d94089d..000000000
--- a/slm_lab/spec/experimental/ddqn_per_seaquest.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_seaquest": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SeaquestNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_per_spaceinvaders.json b/slm_lab/spec/experimental/ddqn_per_spaceinvaders.json
deleted file mode 100644
index adc1cf003..000000000
--- a/slm_lab/spec/experimental/ddqn_per_spaceinvaders.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "ddqn_per_spaceinvaders": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SpaceInvadersNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_pong.json b/slm_lab/spec/experimental/ddqn_pong.json
deleted file mode 100644
index 2f8c196f7..000000000
--- a/slm_lab/spec/experimental/ddqn_pong.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_pong": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "PongNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_qbert.json b/slm_lab/spec/experimental/ddqn_qbert.json
deleted file mode 100644
index 60e4cae0a..000000000
--- a/slm_lab/spec/experimental/ddqn_qbert.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_qbert": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "QbertNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_seaquest.json b/slm_lab/spec/experimental/ddqn_seaquest.json
deleted file mode 100644
index d189648e3..000000000
--- a/slm_lab/spec/experimental/ddqn_seaquest.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_seaquest": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SeaquestNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ddqn_spaceinvaders.json b/slm_lab/spec/experimental/ddqn_spaceinvaders.json
deleted file mode 100644
index 4a9be0064..000000000
--- a/slm_lab/spec/experimental/ddqn_spaceinvaders.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "ddqn_spaceinvaders": {
- "agent": [{
- "name": "DoubleDQN",
- "algorithm": {
- "name": "DoubleDQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SpaceInvadersNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn.json b/slm_lab/spec/experimental/dqn.json
index 585c90ec4..ddc502857 100644
--- a/slm_lab/spec/experimental/dqn.json
+++ b/slm_lab/spec/experimental/dqn.json
@@ -14,11 +14,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -49,7 +48,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250
+ "max_frame": 250
}],
"body": {
"product": "outer",
@@ -58,7 +57,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -100,11 +98,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -138,7 +135,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 100,
+ "max_frame": 100,
}],
"body": {
"product": "outer",
@@ -147,7 +144,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 2,
"max_trial": 16,
"search": "RandomSearch"
@@ -182,11 +178,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -220,7 +215,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -229,7 +224,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -271,14 +265,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -313,7 +306,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -322,7 +315,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -364,14 +356,13 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -406,7 +397,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -415,7 +406,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -457,17 +447,15 @@
"end_step": 17500,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 5,
+ "training_batch_iter": 8,
+ "training_iter": 5,
"training_frequency": 50,
- "training_start_step": 100,
- "normalize_state": true
+ "training_start_step": 100
},
"memory": {
- "name": "ConcatReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "concat_len": 4,
"use_cer": true
},
"net": {
@@ -495,8 +483,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 600,
+ "max_frame": 600,
}],
"body": {
"product": "outer",
@@ -505,7 +495,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -526,17 +515,15 @@
"end_step": 210000,
},
"gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
+ "training_batch_iter": 1,
+ "training_iter": 1,
"training_frequency": 1,
- "training_start_step": 10000,
- "normalize_state": false
+ "training_start_step": 10000
},
"memory": {
- "name": "AtariReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "stack_len": 4,
"use_cer": false
},
"net": {
@@ -566,8 +553,11 @@
}],
"env": [{
"name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 10000000,
+ "max_frame": 10000000,
}],
"body": {
"product": "outer",
@@ -576,13 +566,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 1,
"max_trial": 16,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 16,
- }
},
"search": {
"agent": [{
diff --git a/slm_lab/spec/experimental/dqn/ddqn_atari.json b/slm_lab/spec/experimental/dqn/ddqn_atari.json
new file mode 100644
index 000000000..df4317449
--- /dev/null
+++ b/slm_lab/spec/experimental/dqn/ddqn_atari.json
@@ -0,0 +1,154 @@
+{
+ "ddqn_atari": {
+ "agent": [{
+ "name": "DoubleDQN",
+ "algorithm": {
+ "name": "DoubleDQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "Replay",
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false,
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 1e-4,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "ddqn_atari_full": {
+ "agent": [{
+ "name": "DoubleDQN",
+ "algorithm": {
+ "name": "DoubleDQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "Replay",
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false,
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 1e-4,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/dqn/ddqn_per_atari.json b/slm_lab/spec/experimental/dqn/ddqn_per_atari.json
new file mode 100644
index 000000000..30348ec39
--- /dev/null
+++ b/slm_lab/spec/experimental/dqn/ddqn_per_atari.json
@@ -0,0 +1,158 @@
+{
+ "ddqn_per_atari": {
+ "agent": [{
+ "name": "DoubleDQN",
+ "algorithm": {
+ "name": "DoubleDQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "PrioritizedReplay",
+ "alpha": 0.6,
+ "epsilon": 0.0001,
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false,
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-5,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "ddqn_per_atari_full": {
+ "agent": [{
+ "name": "DoubleDQN",
+ "algorithm": {
+ "name": "DoubleDQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "PrioritizedReplay",
+ "alpha": 0.6,
+ "epsilon": 0.0001,
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false,
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-5,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/dqn/dqn_atari.json b/slm_lab/spec/experimental/dqn/dqn_atari.json
new file mode 100644
index 000000000..060a77051
--- /dev/null
+++ b/slm_lab/spec/experimental/dqn/dqn_atari.json
@@ -0,0 +1,154 @@
+{
+ "dqn_atari": {
+ "agent": [{
+ "name": "DQN",
+ "algorithm": {
+ "name": "DQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "Replay",
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 1e-4,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "dqn_atari_full": {
+ "agent": [{
+ "name": "DQN",
+ "algorithm": {
+ "name": "DQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "Replay",
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 1e-4,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/dqn/dqn_per_atari.json b/slm_lab/spec/experimental/dqn/dqn_per_atari.json
new file mode 100644
index 000000000..9673b2ff8
--- /dev/null
+++ b/slm_lab/spec/experimental/dqn/dqn_per_atari.json
@@ -0,0 +1,158 @@
+{
+ "dqn_per_atari": {
+ "agent": [{
+ "name": "DQN",
+ "algorithm": {
+ "name": "DQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "PrioritizedReplay",
+ "alpha": 0.6,
+ "epsilon": 0.0001,
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-5,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "dqn_per_atari_full": {
+ "agent": [{
+ "name": "DQN",
+ "algorithm": {
+ "name": "DQN",
+ "action_pdtype": "Argmax",
+ "action_policy": "epsilon_greedy",
+ "explore_var_spec": {
+ "name": "linear_decay",
+ "start_val": 1.0,
+ "end_val": 0.01,
+ "start_step": 10000,
+ "end_step": 1000000
+ },
+ "gamma": 0.99,
+ "training_batch_iter": 1,
+ "training_iter": 1,
+ "training_frequency": 4,
+ "training_start_step": 10000
+ },
+ "memory": {
+ "name": "PrioritizedReplay",
+ "alpha": 0.6,
+ "epsilon": 0.0001,
+ "batch_size": 32,
+ "max_size": 200000,
+ "use_cer": false
+ },
+ "net": {
+ "type": "ConvNet",
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [64, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [256],
+ "hid_layers_activation": "relu",
+ "init_fn": null,
+ "batch_norm": false,
+ "clip_grad_val": 10.0,
+ "loss_spec": {
+ "name": "SmoothL1Loss"
+ },
+ "optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-5,
+ },
+ "lr_scheduler_spec": null,
+ "update_type": "replace",
+ "update_frequency": 1000,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "max_t": null,
+ "max_frame": 10000000
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "eval_frequency": 10000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/dqn_pong.json b/slm_lab/spec/experimental/dqn/dqn_pong.json
similarity index 79%
rename from slm_lab/spec/experimental/dqn_pong.json
rename to slm_lab/spec/experimental/dqn/dqn_pong.json
index 161761a1b..135814c5b 100644
--- a/slm_lab/spec/experimental/dqn_pong.json
+++ b/slm_lab/spec/experimental/dqn/dqn_pong.json
@@ -14,17 +14,15 @@
"end_step": 1000000
},
"gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
+ "training_batch_iter": 1,
+ "training_iter": 1,
"training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
+ "training_start_step": 10000
},
"memory": {
- "name": "AtariReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 200000,
- "stack_len": 4,
"use_cer": false
},
"net": {
@@ -54,8 +52,11 @@
}],
"env": [{
"name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 10000000
+ "max_frame": 10000000
}],
"body": {
"product": "outer",
@@ -64,13 +65,8 @@
"meta": {
"distributed": false,
"eval_frequency": 10000,
- "max_tick_unit": "total_t",
"max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
+ "max_trial": 1,
}
}
}
diff --git a/slm_lab/spec/experimental/lunar_dqn.json b/slm_lab/spec/experimental/dqn/lunar_dqn.json
similarity index 81%
rename from slm_lab/spec/experimental/lunar_dqn.json
rename to slm_lab/spec/experimental/dqn/lunar_dqn.json
index 0a29aa9bf..ec0b06cd5 100644
--- a/slm_lab/spec/experimental/lunar_dqn.json
+++ b/slm_lab/spec/experimental/dqn/lunar_dqn.json
@@ -14,18 +14,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -51,8 +49,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -61,26 +61,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"polyak_coef__choice": [0, 0.9, 0.95, 0.99, 0.995, 0.999],
"lr_scheduler_spec": {
@@ -113,18 +105,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -150,8 +140,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -160,26 +152,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"polyak_coef__choice": [0, 0.9, 0.95, 0.99, 0.995, 0.999],
"lr_scheduler_spec": {
@@ -212,18 +196,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -249,8 +231,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -259,26 +243,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"update_frequency__choice": [0, 200, 500, 800, 1000, 1500],
"lr_scheduler_spec": {
@@ -311,18 +287,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -348,8 +322,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -358,26 +334,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"update_frequency__choice": [0, 200, 500, 800, 1000, 1500],
"lr_scheduler_spec": {
@@ -410,18 +378,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -447,8 +413,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -457,26 +425,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"polyak_coef__choice": [0, 0.9, 0.95, 0.99, 0.995, 0.999],
"lr_scheduler_spec": {
@@ -509,18 +469,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -546,8 +504,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -556,26 +516,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"polyak_coef__choice": [0, 0.9, 0.95, 0.99, 0.995, 0.999],
"lr_scheduler_spec": {
@@ -608,18 +560,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -645,8 +595,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -655,26 +607,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"update_frequency__choice": [0, 200, 500, 800, 1000, 1500],
"lr_scheduler_spec": {
@@ -707,18 +651,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "MLPNet",
@@ -744,8 +686,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -754,26 +698,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"update_frequency__choice": [0, 200, 500, 800, 1000, 1500],
"lr_scheduler_spec": {
@@ -806,14 +742,13 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
@@ -846,8 +781,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -856,19 +793,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
@@ -905,18 +837,16 @@
"end_step": 10000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
"use_cer": false,
- "concat_len": 4
},
"net": {
"type": "DuelingMLPNet",
@@ -942,8 +872,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 250000,
+ "max_frame": 250000,
}],
"body": {
"product": "outer",
@@ -952,26 +884,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
- "training_batch_epoch__choice": [1, 2, 3],
+ "training_batch_iter__choice": [1, 2, 3],
"explore_var_spec": {
"end_step__choice": [8000, 10000, 12000, 14000]
},
},
- "memory": {
- "name__choice": ["Replay", "ConcatReplay"],
- },
"net": {
"polyak_coef__choice": [0, 0.9, 0.95, 0.99, 0.995, 0.999],
"lr_scheduler_spec": {
diff --git a/slm_lab/spec/experimental/dqn_beamrider.json b/slm_lab/spec/experimental/dqn_beamrider.json
deleted file mode 100644
index e37125c3e..000000000
--- a/slm_lab/spec/experimental/dqn_beamrider.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_beamrider": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BeamRiderNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_breakout.json b/slm_lab/spec/experimental/dqn_breakout.json
deleted file mode 100644
index fbea7d923..000000000
--- a/slm_lab/spec/experimental/dqn_breakout.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_breakout": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BreakoutNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_enduro.json b/slm_lab/spec/experimental/dqn_enduro.json
deleted file mode 100644
index 99c8bd2a9..000000000
--- a/slm_lab/spec/experimental/dqn_enduro.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_enduro": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "EnduroNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_mspacman.json b/slm_lab/spec/experimental/dqn_mspacman.json
deleted file mode 100644
index 9574024f0..000000000
--- a/slm_lab/spec/experimental/dqn_mspacman.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_mspacman": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "MsPacmanNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_beamrider.json b/slm_lab/spec/experimental/dqn_per_beamrider.json
deleted file mode 100644
index 935857d69..000000000
--- a/slm_lab/spec/experimental/dqn_per_beamrider.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_beamrider": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BeamRiderNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_breakout.json b/slm_lab/spec/experimental/dqn_per_breakout.json
deleted file mode 100644
index b3ed18671..000000000
--- a/slm_lab/spec/experimental/dqn_per_breakout.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_breakout": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BreakoutNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_enduro.json b/slm_lab/spec/experimental/dqn_per_enduro.json
deleted file mode 100644
index c624dd24f..000000000
--- a/slm_lab/spec/experimental/dqn_per_enduro.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_enduro": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "EnduroNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_mspacman.json b/slm_lab/spec/experimental/dqn_per_mspacman.json
deleted file mode 100644
index 966c60617..000000000
--- a/slm_lab/spec/experimental/dqn_per_mspacman.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_mspacman": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "MsPacmanNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_pong.json b/slm_lab/spec/experimental/dqn_per_pong.json
deleted file mode 100644
index eee7d1a0f..000000000
--- a/slm_lab/spec/experimental/dqn_per_pong.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_pong": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "PongNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_qbert.json b/slm_lab/spec/experimental/dqn_per_qbert.json
deleted file mode 100644
index 450fa852e..000000000
--- a/slm_lab/spec/experimental/dqn_per_qbert.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_qbert": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "QbertNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_seaquest.json b/slm_lab/spec/experimental/dqn_per_seaquest.json
deleted file mode 100644
index 37b3a1b04..000000000
--- a/slm_lab/spec/experimental/dqn_per_seaquest.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_seaquest": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SeaquestNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_per_spaceinvaders.json b/slm_lab/spec/experimental/dqn_per_spaceinvaders.json
deleted file mode 100644
index e5ee582ed..000000000
--- a/slm_lab/spec/experimental/dqn_per_spaceinvaders.json
+++ /dev/null
@@ -1,78 +0,0 @@
-{
- "dqn_per_spaceinvaders": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariPrioritizedReplay",
- "alpha": 0.6,
- "epsilon": 0.0001,
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-5,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SpaceInvadersNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_qbert.json b/slm_lab/spec/experimental/dqn_qbert.json
deleted file mode 100644
index 3d7867e85..000000000
--- a/slm_lab/spec/experimental/dqn_qbert.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_qbert": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "QbertNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_seaquest.json b/slm_lab/spec/experimental/dqn_seaquest.json
deleted file mode 100644
index bbcdff203..000000000
--- a/slm_lab/spec/experimental/dqn_seaquest.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_seaquest": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SeaquestNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dqn_spaceinvaders.json b/slm_lab/spec/experimental/dqn_spaceinvaders.json
deleted file mode 100644
index bcc47566a..000000000
--- a/slm_lab/spec/experimental/dqn_spaceinvaders.json
+++ /dev/null
@@ -1,76 +0,0 @@
-{
- "dqn_spaceinvaders": {
- "agent": [{
- "name": "DQN",
- "algorithm": {
- "name": "DQN",
- "action_pdtype": "Argmax",
- "action_policy": "epsilon_greedy",
- "explore_var_spec": {
- "name": "linear_decay",
- "start_val": 1.0,
- "end_val": 0.01,
- "start_step": 10000,
- "end_step": 1000000
- },
- "gamma": 0.99,
- "training_batch_epoch": 1,
- "training_epoch": 1,
- "training_frequency": 4,
- "training_start_step": 10000,
- "normalize_state": false
- },
- "memory": {
- "name": "AtariReplay",
- "batch_size": 32,
- "max_size": 200000,
- "stack_len": 4,
- "use_cer": false
- },
- "net": {
- "type": "ConvNet",
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 10.0,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 1e-4,
- },
- "lr_scheduler_spec": null,
- "update_type": "replace",
- "update_frequency": 1000,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SpaceInvadersNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 16,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 16
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/dueling_dqn.json b/slm_lab/spec/experimental/dueling_dqn.json
index 9c100c59d..7e9efebbf 100644
--- a/slm_lab/spec/experimental/dueling_dqn.json
+++ b/slm_lab/spec/experimental/dueling_dqn.json
@@ -14,11 +14,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -52,7 +51,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -61,7 +60,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 100,
"search": "RandomSearch"
@@ -103,11 +101,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 8,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -141,7 +138,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -150,7 +147,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -192,17 +188,15 @@
"end_step": 17500,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 5,
+ "training_batch_iter": 8,
+ "training_iter": 5,
"training_frequency": 50,
- "training_start_step": 100,
- "normalize_state": true
+ "training_start_step": 100
},
"memory": {
- "name": "ConcatReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "concat_len": 4,
"use_cer": true
},
"net": {
@@ -230,8 +224,10 @@
}],
"env": [{
"name": "LunarLander-v2",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 600,
+ "max_frame": 600,
}],
"body": {
"product": "outer",
@@ -240,7 +236,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -261,17 +256,15 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 100,
- "training_start_step": 100,
- "normalize_state": false
+ "training_start_step": 100
},
"memory": {
- "name": "AtariReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 250000,
- "stack_len": 4,
"use_cer": true
},
"net": {
@@ -309,8 +302,11 @@
}],
"env": [{
"name": "BreakoutDeterministic-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"max_t": null,
- "max_tick": 50000,
+ "max_frame": 50000,
}],
"body": {
"product": "outer",
@@ -319,7 +315,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/hydra_dqn.json b/slm_lab/spec/experimental/hydra_dqn.json
index c6906d68c..1806886d6 100644
--- a/slm_lab/spec/experimental/hydra_dqn.json
+++ b/slm_lab/spec/experimental/hydra_dqn.json
@@ -14,11 +14,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 10,
- "normalize_state": true
+ "training_start_step": 10
},
"memory": {
"name": "Replay",
@@ -56,11 +55,11 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}, {
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 1000
+ "max_frame": 1000
}],
"body": {
"product": "outer",
@@ -69,7 +68,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -111,11 +109,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_batch_epoch": 8,
- "training_epoch": 4,
+ "training_batch_iter": 8,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 10,
- "normalize_state": true
+ "training_start_step": 10
},
"memory": {
"name": "Replay",
@@ -156,11 +153,11 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}, {
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 1000
+ "max_frame": 1000
}],
"body": {
"product": "outer",
@@ -169,7 +166,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -211,11 +207,10 @@
"end_step": 15000,
},
"gamma": 0.99,
- "training_batch_epoch": 4,
- "training_epoch": 4,
+ "training_batch_iter": 4,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -256,12 +251,12 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 300,
+ "max_frame": 300,
"reward_scale": 1,
}, {
"name": "2DBall",
"max_t": 1000,
- "max_tick": 300,
+ "max_frame": 300,
"reward_scale": 10,
}],
"body": {
@@ -271,7 +266,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 40,
"search": "RandomSearch"
@@ -307,11 +301,10 @@
"end_step": 15000,
},
"gamma": 0.99,
- "training_batch_epoch": 4,
- "training_epoch": 4,
+ "training_batch_iter": 4,
+ "training_iter": 4,
"training_frequency": 32,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
@@ -352,12 +345,12 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 300,
+ "max_frame": 300,
"reward_scale": 1,
}, {
"name": "2DBall",
"max_t": 1000,
- "max_tick": 300,
+ "max_frame": 300,
"reward_scale": 10,
}],
"body": {
@@ -367,7 +360,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 40,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/gridworld.json b/slm_lab/spec/experimental/misc/gridworld.json
similarity index 85%
rename from slm_lab/spec/experimental/gridworld.json
rename to slm_lab/spec/experimental/misc/gridworld.json
index af80d6d7c..b9dc45586 100644
--- a/slm_lab/spec/experimental/gridworld.json
+++ b/slm_lab/spec/experimental/misc/gridworld.json
@@ -14,8 +14,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -46,7 +44,7 @@
"env": [{
"name": "gridworld",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -55,20 +53,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [1, 2, 3],
- "training_epoch__choice": [1, 2, 3, 4],
"lam__uniform": [0.9, 0.99]
},
"net": {
@@ -99,11 +91,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -135,7 +125,7 @@
"env": [{
"name": "gridworld",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -144,20 +134,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [1, 2, 3],
- "training_epoch__choice": [1, 2, 3, 4],
"lam__uniform": [0.9, 0.99]
},
"net": {
@@ -188,8 +172,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -220,7 +202,7 @@
"env": [{
"name": "gridworld",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -229,20 +211,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [1, 2, 3],
- "training_epoch__choice": [1, 2, 3, 4],
"num_step_returns__choice": [1, 2, 3, 5, 10]
},
"net": {
@@ -273,11 +249,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -309,7 +283,7 @@
"env": [{
"name": "gridworld",
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -318,20 +292,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [1, 2, 3],
- "training_epoch__choice": [1, 2, 3, 4],
"num_step_returns__choice": [1, 2, 3, 5, 10]
},
"net": {
@@ -362,18 +330,16 @@
"end_step": 2000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -400,8 +366,10 @@
}],
"env": [{
"name": "gridworld",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -410,18 +378,13 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [30000, 40000, 50000]
}
@@ -430,7 +393,7 @@
"max_size__choice": [10000, 50000, 100000],
},
"net": {
- "training_epoch__choice": [1, 2, 3, 4],
+ "training_iter__choice": [1, 2, 3, 4],
"lr_decay_frequency__choice": [30000, 40000, 50000, 60000, 70000],
"polyak_coef__choice": [0, 0.9, 0.99, 0.999],
"lr__uniform": [0.001, 0.01],
@@ -454,18 +417,16 @@
"end_step": 2000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "RecurrentNet",
@@ -496,8 +457,10 @@
}],
"env": [{
"name": "gridworld",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -506,18 +469,13 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [30000, 40000, 50000]
}
@@ -528,7 +486,7 @@
"net": {
"rnn_hidden_size__choice": [32, 64],
"seq_len__choice": [2, 3, 4, 5, 6],
- "training_epoch__choice": [1, 2, 3, 4],
+ "training_iter__choice": [1, 2, 3, 4],
"lr_decay_frequency__choice": [30000, 40000, 50000, 60000, 70000],
"lr__uniform": [0.001, 0.01],
"polyak_coef__choice": [0, 0.9, 0.99, 0.999],
@@ -552,18 +510,16 @@
"end_step": 2000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -590,8 +546,10 @@
}],
"env": [{
"name": "gridworld",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -600,18 +558,13 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [30000, 40000, 50000]
}
@@ -620,7 +573,7 @@
"max_size__choice": [10000, 50000, 100000],
},
"net": {
- "training_epoch__choice": [1, 2, 3, 4],
+ "training_iter__choice": [1, 2, 3, 4],
"lr_decay_frequency__choice": [30000, 40000, 50000, 60000, 70000],
"lr__uniform": [0.001, 0.01],
"polyak_coef__choice": [0, 0.9, 0.99, 0.999],
@@ -644,18 +597,16 @@
"end_step": 2000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "RecurrentNet",
@@ -686,8 +637,10 @@
}],
"env": [{
"name": "gridworld",
+ "frame_op": "concat",
+ "frame_op_len": 4,
"max_t": null,
- "max_tick": 1000,
+ "max_frame": 1000,
}],
"body": {
"product": "outer",
@@ -696,18 +649,13 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [30000, 40000, 50000]
}
@@ -718,7 +666,7 @@
"net": {
"rnn_hidden_size__choice": [32, 64],
"seq_len__choice": [2, 3, 4, 5, 6],
- "training_epoch__choice": [1, 2, 3, 4],
+ "training_iter__choice": [1, 2, 3, 4],
"lr_decay_frequency__choice": [30000, 40000, 50000, 60000, 70000],
"lr__uniform": [0.001, 0.01],
"polyak_coef__choice": [0, 0.9, 0.99, 0.999],
diff --git a/slm_lab/spec/experimental/lunar_pg.json b/slm_lab/spec/experimental/misc/lunar_pg.json
similarity index 90%
rename from slm_lab/spec/experimental/lunar_pg.json
rename to slm_lab/spec/experimental/misc/lunar_pg.json
index cf6fafb10..b5989ba0d 100644
--- a/slm_lab/spec/experimental/lunar_pg.json
+++ b/slm_lab/spec/experimental/misc/lunar_pg.json
@@ -15,8 +15,7 @@
"start_step": 30000,
"end_step": 40000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -44,7 +43,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -53,13 +52,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -104,11 +99,10 @@
"start_step": 30000,
"end_step": 40000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -137,7 +131,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -146,13 +140,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -203,9 +193,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 3,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 3
},
"memory": {
"name": "OnPolicyReplay"
@@ -236,7 +224,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -245,13 +233,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95,
- }
},
"search": {
"agent": [{
@@ -300,12 +284,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 3,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 3
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -337,7 +319,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -346,13 +328,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -403,9 +381,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -436,7 +412,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -445,13 +421,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -501,12 +473,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -538,7 +508,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -547,13 +517,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -611,8 +577,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -643,7 +608,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -652,13 +617,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -707,11 +668,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -743,7 +703,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -752,13 +712,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -802,9 +758,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": false
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -835,7 +789,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -844,18 +798,13 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 1.0],
},
@@ -892,13 +841,11 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 50000,
"use_cer": false
@@ -929,7 +876,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -938,19 +885,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
"algorithm": {
"training_frequency__choice": [1, 2],
- "training_epoch__choice": [4, 6, 8],
"entropy_coef__uniform": [0.04, 0.09],
"lam__uniform": [0.9, 1.0]
},
@@ -990,12 +932,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -1027,7 +967,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1036,13 +976,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1083,9 +1019,7 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": false
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -1116,7 +1050,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1125,19 +1059,15 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
"algorithm": {
"training_frequency__choice": [2, 3, 4],
- "training_batch_epoch_choice": [4, 6, 8, 10],
+ "training_batch_iter_choice": [4, 6, 8, 10],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 0.05],
},
@@ -1173,13 +1103,11 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 50000,
"use_cer": true
@@ -1210,7 +1138,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1219,19 +1147,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
"algorithm": {
"training_frequency__choice": [1, 2, 3],
- "training_epoch__choice": [4, 6, 8],
"entropy_coef__uniform": [0.01, 0.1],
"num_step_returns__choice": [1, 4, 5]
},
@@ -1271,12 +1194,10 @@
},
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
- "training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -1308,7 +1229,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1317,13 +1238,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1370,8 +1287,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -1402,7 +1318,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1411,13 +1327,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1463,11 +1375,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -1499,7 +1410,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1508,13 +1419,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1558,13 +1465,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -1595,7 +1500,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1604,13 +1509,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1654,13 +1555,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -1691,7 +1590,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1700,13 +1599,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1753,13 +1648,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -1794,7 +1687,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1803,13 +1696,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1854,13 +1743,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -1895,7 +1782,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -1904,13 +1791,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -1963,9 +1846,8 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -1996,7 +1878,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -2005,13 +1887,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -2061,9 +1939,8 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -2094,7 +1971,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -2103,13 +1980,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -2162,13 +2035,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -2203,7 +2075,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -2212,13 +2084,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
@@ -2269,13 +2137,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 10000,
"use_cer": true
@@ -2310,7 +2177,7 @@
"env": [{
"name": "LunarLander-v2",
"max_t": null,
- "max_tick": 400000,
+ "max_frame": 400000,
}],
"body": {
"product": "outer",
@@ -2319,13 +2186,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 2,
"max_trial": 95,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 91,
- }
},
"search": {
"agent": [{
diff --git a/slm_lab/spec/experimental/mountain_car.json b/slm_lab/spec/experimental/misc/mountain_car.json
similarity index 84%
rename from slm_lab/spec/experimental/mountain_car.json
rename to slm_lab/spec/experimental/misc/mountain_car.json
index ebee27e7d..5c378cf9b 100644
--- a/slm_lab/spec/experimental/mountain_car.json
+++ b/slm_lab/spec/experimental/misc/mountain_car.json
@@ -20,8 +20,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -52,7 +50,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 2600,
+ "max_frame": 2600,
}],
"body": {
"product": "outer",
@@ -61,24 +59,17 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 4, 8],
"lam__uniform": [0.9, 0.99]
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
"hid_layers__choice": [[100], [200], [400], [200, 100]],
"actor_optim_spec": {
@@ -112,11 +103,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -153,7 +142,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 2600,
+ "max_frame": 2600,
}],
"body": {
"product": "outer",
@@ -162,24 +151,17 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 4, 8],
"lam__uniform": [0.9, 0.99],
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
"hid_layers__choice": [[], [100], [200]],
@@ -216,8 +198,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -248,7 +228,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 2600,
+ "max_frame": 2600,
}],
"body": {
"product": "outer",
@@ -257,24 +237,17 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 4, 8],
"num_step_returns__choice": [2, 4, 8]
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
"hid_layers__choice": [[100], [200], [400], [200, 100]],
@@ -309,11 +282,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -345,7 +316,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 2600,
+ "max_frame": 2600,
}],
"body": {
"product": "outer",
@@ -354,24 +325,17 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 4, 8],
"lam__uniform": [0.9, 0.99],
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
"hid_layers__choice": [[], [100], [200]],
@@ -402,18 +366,16 @@
"end_step": 80000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": false
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -436,13 +398,12 @@
"update_frequency": 200,
"polyak_coef": 0.8,
"gpu": false,
- "training_epoch": 2
}
}],
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 1400,
+ "max_frame": 1400,
}],
"body": {
"product": "outer",
@@ -451,24 +412,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [20000, 40000, 80000]
}
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"polyak_coef__uniform": [0.8, 1.0],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
@@ -495,18 +450,16 @@
"end_step": 40000,
},
"gamma": 0.999,
- "training_batch_epoch": 3,
- "training_epoch": 4,
+ "training_batch_iter": 3,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "RecurrentNet",
@@ -538,7 +491,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 1400,
+ "max_frame": 1400,
}],
"body": {
"product": "outer",
@@ -547,24 +500,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [20000, 40000, 80000]
}
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"polyak_coef__uniform": [0.8, 1.0],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
@@ -593,18 +540,16 @@
"end_step": 40000,
},
"gamma": 0.999,
- "training_batch_epoch": 4,
- "training_epoch": 4,
+ "training_batch_iter": 4,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": false
+ "training_start_step": 32
},
"memory": {
"name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "MLPNet",
@@ -627,13 +572,12 @@
"update_frequency": 200,
"polyak_coef": 0.8,
"gpu": false,
- "training_epoch": 8
}
}],
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 1400,
+ "max_frame": 1400,
}],
"body": {
"product": "outer",
@@ -642,24 +586,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [20000, 40000, 80000]
}
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"polyak_coef__uniform": [0.8, 1.0],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
@@ -686,18 +624,16 @@
"end_step": 40000,
},
"gamma": 0.999,
- "training_batch_epoch": 4,
- "training_epoch": 4,
+ "training_batch_iter": 4,
+ "training_iter": 4,
"training_frequency": 4,
- "training_start_step": 32,
- "normalize_state": true
+ "training_start_step": 32
},
"memory": {
- "name": "SeqReplay",
+ "name": "Replay",
"batch_size": 32,
"max_size": 100000,
- "use_cer": false,
- "concat_len": 4,
+ "use_cer": false
},
"net": {
"type": "RecurrentNet",
@@ -729,7 +665,7 @@
"env": [{
"name": "MountainCar-v0",
"max_t": null,
- "max_tick": 1400,
+ "max_frame": 1400,
}],
"body": {
"product": "outer",
@@ -738,24 +674,18 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 200,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"explore_var_spec": {
"end_step__choice": [20000, 40000, 80000]
}
},
"net": {
- "training_epoch__choice": [2, 4, 8],
"lr_decay_frequency__choice": [5000, 10000, 50000, 10000],
"polyak_coef__uniform": [0.8, 1.0],
"hid_layers_activation__choice": ["relu", "selu", "sigmoid"],
diff --git a/slm_lab/spec/experimental/pendulum.json b/slm_lab/spec/experimental/misc/pendulum.json
similarity index 88%
rename from slm_lab/spec/experimental/pendulum.json
rename to slm_lab/spec/experimental/misc/pendulum.json
index 5904c22d0..a154759ec 100644
--- a/slm_lab/spec/experimental/pendulum.json
+++ b/slm_lab/spec/experimental/misc/pendulum.json
@@ -20,8 +20,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -52,7 +50,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500000,
+ "max_frame": 500000,
}],
"body": {
"product": "outer",
@@ -61,20 +59,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 190,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 3, 4],
"lam__uniform": [0.95, 0.99],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 0.05],
@@ -113,11 +105,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -149,7 +139,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500000,
+ "max_frame": 500000,
}],
"body": {
"product": "outer",
@@ -158,20 +148,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 190,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 3, 4],
"lam__uniform": [0.95, 0.99],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 0.05],
@@ -211,8 +195,6 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
"name": "OnPolicyReplay"
@@ -243,7 +225,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500000,
+ "max_frame": 500000,
}],
"body": {
"product": "outer",
@@ -252,20 +234,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 190,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 3, 4],
"num_step_returns__choice": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 0.05],
@@ -304,11 +280,9 @@
"policy_loss_coef": 1.0,
"val_loss_coef": 0.01,
"training_frequency": 1,
- "training_epoch": 4,
- "normalize_state": true
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -340,7 +314,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500000,
+ "max_frame": 500000,
}],
"body": {
"product": "outer",
@@ -349,20 +323,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 190,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
"algorithm": {
- "normalize_state__choice": [true, false],
"training_frequency__choice": [2, 4, 8],
- "training_epoch__choice": [2, 3, 4],
"num_step_returns__choice": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"entropy_coef_spec": {
"start_val__uniform": [0.001, 0.05],
@@ -404,13 +372,11 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 10,
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 64,
"max_size": 100000,
"use_cer": true
@@ -441,7 +407,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500000,
+ "max_frame": 500000,
}],
"body": {
"product": "outer",
@@ -450,13 +416,9 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "total_t",
"max_session": 4,
"max_trial": 190,
"search": "RandomSearch",
- "resources": {
- "num_cpus": 95
- }
},
"search": {
"agent": [{
diff --git a/slm_lab/spec/experimental/ppo.json b/slm_lab/spec/experimental/ppo.json
index 7b208c31a..81ca1cab2 100644
--- a/slm_lab/spec/experimental/ppo.json
+++ b/slm_lab/spec/experimental/ppo.json
@@ -25,8 +25,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -57,7 +56,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -66,7 +65,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -117,8 +115,7 @@
},
"val_loss_coef": 0.85,
"training_frequency": 4,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -149,7 +146,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -158,8 +155,7 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
- "max_session": 1,
+ "max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
@@ -209,11 +205,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -245,7 +240,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -254,7 +249,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -305,11 +299,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -341,7 +334,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -350,7 +343,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -401,8 +393,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -433,7 +424,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -442,7 +433,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -493,8 +483,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -525,7 +514,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -534,7 +523,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -585,11 +573,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -621,7 +608,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -630,7 +617,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -681,11 +667,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -717,7 +702,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -726,7 +711,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -777,8 +761,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -814,7 +797,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -823,8 +806,7 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
- "max_session": 1,
+ "max_session": 4,
"max_trial": 1,
"search": "RandomSearch"
}
@@ -855,8 +837,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -892,86 +873,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 1000,
- "max_tick_unit": "epi",
- "max_session": 1,
- "max_trial": 1,
- "search": "RandomSearch"
- }
- },
- "ppo_conv_separate_vizdoom": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 1.0,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.01,
- "start_step": 100000,
- "end_step": 100000,
- },
- "entropy_coef_spec": {
- "name": "linear_decay",
- "start_val": 0.01,
- "end_val": 0.001,
- "start_step": 100000,
- "end_step": 100000,
- },
- "val_loss_coef": 0.1,
- "training_frequency": 5,
- "training_epoch": 8,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyImageReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": false,
- "conv_hid_layers": [
- [16, 5, 2, 0, 1],
- [32, 5, 2, 0, 2],
- [32, 5, 2, 0, 2]
- ],
- "fc_hid_layers": [128, 64],
- "hid_layers_activation": "relu",
- "batch_norm": false,
- "clip_grad_val": null,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 0.01
- },
- "lr_scheduler_spec": {
- "name": "StepLR",
- "step_size": 2000,
- "gamma": 0.9,
- },
- "gpu": true
- }
- }],
- "env": [{
- "name": "vizdoom-v0",
- "cfg_name": "take_cover",
- "max_t": null,
- "max_tick": 100
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -980,8 +882,7 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
- "max_session": 1,
+ "max_session": 4,
"max_trial": 1,
"search": "RandomSearch"
}
diff --git a/slm_lab/spec/experimental/dppo.json b/slm_lab/spec/experimental/ppo/dppo.json
similarity index 92%
rename from slm_lab/spec/experimental/dppo.json
rename to slm_lab/spec/experimental/ppo/dppo.json
index c20db4200..d95e838e8 100644
--- a/slm_lab/spec/experimental/dppo.json
+++ b/slm_lab/spec/experimental/ppo/dppo.json
@@ -25,8 +25,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -57,16 +56,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -117,8 +115,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -149,16 +146,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -209,11 +205,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -245,16 +240,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -305,11 +299,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -341,16 +334,15 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -401,8 +393,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -433,16 +424,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -493,8 +483,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -525,16 +514,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -585,11 +573,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -621,16 +608,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -681,11 +667,10 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": true
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -717,16 +702,15 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -777,8 +761,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -814,16 +797,15 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -855,8 +837,7 @@
},
"val_loss_coef": 0.1,
"training_frequency": 1,
- "training_epoch": 8,
- "normalize_state": false
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay"
@@ -892,16 +873,15 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
- "distributed": true,
+ "distributed": "synced",
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/ppo/ppo_atari.json b/slm_lab/spec/experimental/ppo/ppo_atari.json
new file mode 100644
index 000000000..20c42f1ae
--- /dev/null
+++ b/slm_lab/spec/experimental/ppo/ppo_atari.json
@@ -0,0 +1,186 @@
+{
+ "ppo_atari": {
+ "agent": [{
+ "name": "PPO",
+ "algorithm": {
+ "name": "PPO",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "clip_eps_spec": {
+ "name": "no_decay",
+ "start_val": 0.10,
+ "end_val": 0.10,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 128,
+ "minibatch_size": 32,
+ "training_epoch": 4
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e7
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "BeamRiderNoFrameskip-v4", "BreakoutNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "PongNoFrameskip-v4", "QbertNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4"
+ ]
+ }
+ },
+ "ppo_atari_full": {
+ "agent": [{
+ "name": "PPO",
+ "algorithm": {
+ "name": "PPO",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "clip_eps_spec": {
+ "name": "no_decay",
+ "start_val": 0.10,
+ "end_val": 0.10,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 128,
+ "minibatch_size": 32,
+ "training_epoch": 4
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e7
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "AdventureNoFrameskip-v4", "AirRaidNoFrameskip-v4", "AlienNoFrameskip-v4", "AmidarNoFrameskip-v4", "AssaultNoFrameskip-v4", "AsterixNoFrameskip-v4", "AsteroidsNoFrameskip-v4", "AtlantisNoFrameskip-v4", "BankHeistNoFrameskip-v4", "BattleZoneNoFrameskip-v4", "BeamRiderNoFrameskip-v4", "BerzerkNoFrameskip-v4", "BowlingNoFrameskip-v4", "BoxingNoFrameskip-v4", "BreakoutNoFrameskip-v4", "CarnivalNoFrameskip-v4", "CentipedeNoFrameskip-v4", "ChopperCommandNoFrameskip-v4", "CrazyClimberNoFrameskip-v4", "DefenderNoFrameskip-v4", "DemonAttackNoFrameskip-v4", "DoubleDunkNoFrameskip-v4", "ElevatorActionNoFrameskip-v4", "FishingDerbyNoFrameskip-v4", "FreewayNoFrameskip-v4", "FrostbiteNoFrameskip-v4", "GopherNoFrameskip-v4", "GravitarNoFrameskip-v4", "HeroNoFrameskip-v4", "IceHockeyNoFrameskip-v4", "JamesbondNoFrameskip-v4", "JourneyEscapeNoFrameskip-v4", "KangarooNoFrameskip-v4", "KrullNoFrameskip-v4", "KungFuMasterNoFrameskip-v4", "MontezumaRevengeNoFrameskip-v4", "MsPacmanNoFrameskip-v4", "NameThisGameNoFrameskip-v4", "PhoenixNoFrameskip-v4", "PitfallNoFrameskip-v4", "PongNoFrameskip-v4", "PooyanNoFrameskip-v4", "PrivateEyeNoFrameskip-v4", "QbertNoFrameskip-v4", "RiverraidNoFrameskip-v4", "RoadRunnerNoFrameskip-v4", "RobotankNoFrameskip-v4", "SeaquestNoFrameskip-v4", "SkiingNoFrameskip-v4", "SolarisNoFrameskip-v4", "SpaceInvadersNoFrameskip-v4", "StarGunnerNoFrameskip-v4", "TennisNoFrameskip-v4", "TimePilotNoFrameskip-v4", "TutankhamNoFrameskip-v4", "UpNDownNoFrameskip-v4", "VentureNoFrameskip-v4", "VideoPinballNoFrameskip-v4", "WizardOfWorNoFrameskip-v4", "YarsRevengeNoFrameskip-v4", "ZaxxonNoFrameskip-v4"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/ppo/ppo_cont.json b/slm_lab/spec/experimental/ppo/ppo_cont.json
new file mode 100644
index 000000000..df5f233cd
--- /dev/null
+++ b/slm_lab/spec/experimental/ppo/ppo_cont.json
@@ -0,0 +1,86 @@
+{
+ "ppo_cont": {
+ "agent": [{
+ "name": "PPO",
+ "algorithm": {
+ "name": "PPO",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "clip_eps_spec": {
+ "name": "no_decay",
+ "start_val": 0.20,
+ "end_val": 0.20,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.0,
+ "end_val": 0.0,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 2048,
+ "minibatch_size": 64,
+ "training_epoch": 10
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "MLPNet",
+ "shared": false,
+ "hid_layers": [64, 64],
+ "hid_layers_activation": "tanh",
+ "init_fn": "orthogonal_",
+ "normalize": false,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e6
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "num_envs": 8,
+ "max_t": null,
+ "max_frame": 1e6
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 20000,
+ "eval_frequency": 20000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "RoboschoolAnt-v1", "BipedalWalker-v2", "RoboschoolHalfCheetah-v1", "RoboschoolHopper-v1", "RoboschoolInvertedPendulum-v1", "Pendulum-v0"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/ppo/ppo_cont_hard.json b/slm_lab/spec/experimental/ppo/ppo_cont_hard.json
new file mode 100644
index 000000000..e00da2dc8
--- /dev/null
+++ b/slm_lab/spec/experimental/ppo/ppo_cont_hard.json
@@ -0,0 +1,86 @@
+{
+ "ppo_cont_hard": {
+ "agent": [{
+ "name": "PPO",
+ "algorithm": {
+ "name": "PPO",
+ "action_pdtype": "default",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "lam": 0.95,
+ "clip_eps_spec": {
+ "name": "no_decay",
+ "start_val": 0.20,
+ "end_val": 0.20,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.0,
+ "end_val": 0.0,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "val_loss_coef": 0.5,
+ "training_frequency": 2048,
+ "minibatch_size": 64,
+ "training_epoch": 10
+ },
+ "memory": {
+ "name": "OnPolicyBatchReplay",
+ },
+ "net": {
+ "type": "MLPNet",
+ "shared": false,
+ "hid_layers": [64, 64],
+ "hid_layers_activation": "tanh",
+ "init_fn": "orthogonal_",
+ "normalize": false,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 3e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e6
+ },
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "${env}",
+ "num_envs": 32,
+ "max_t": null,
+ "max_frame": 5e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 20000,
+ "eval_frequency": 20000,
+ "max_session": 4,
+ "max_trial": 1,
+ "param_spec_process": 4
+ },
+ "spec_params": {
+ "env": [
+ "RoboschoolHumanoid-v1"
+ ]
+ }
+ }
+}
diff --git a/slm_lab/spec/experimental/ppo_pong.json b/slm_lab/spec/experimental/ppo/ppo_pong.json
similarity index 54%
rename from slm_lab/spec/experimental/ppo_pong.json
rename to slm_lab/spec/experimental/ppo/ppo_pong.json
index dcd66f7dd..73cc5bd4b 100644
--- a/slm_lab/spec/experimental/ppo_pong.json
+++ b/slm_lab/spec/experimental/ppo/ppo_pong.json
@@ -1,5 +1,5 @@
{
- "ppo_shared_pong": {
+ "ppo_pong": {
"agent": [{
"name": "PPO",
"algorithm": {
@@ -10,11 +10,11 @@
"gamma": 0.99,
"lam": 0.95,
"clip_eps_spec": {
- "name": "linear_decay",
+ "name": "no_decay",
"start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
+ "end_val": 0.10,
+ "start_step": 0,
+ "end_step": 0
},
"entropy_coef_spec": {
"name": "no_decay",
@@ -23,13 +23,13 @@
"start_step": 0,
"end_step": 0
},
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
+ "val_loss_coef": 0.5,
+ "training_frequency": 128,
+ "minibatch_size": 32,
+ "training_epoch": 4
},
"memory": {
- "name": "OnPolicyAtariReplay"
+ "name": "OnPolicyBatchReplay",
},
"net": {
"type": "ConvNet",
@@ -37,29 +37,41 @@
"conv_hid_layers": [
[32, 8, 4, 0, 1],
[64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
+ [32, 3, 1, 0, 1]
],
- "fc_hid_layers": [256],
+ "fc_hid_layers": [512],
"hid_layers_activation": "relu",
- "init_fn": null,
+ "init_fn": "orthogonal_",
+ "normalize": true,
"batch_norm": false,
- "clip_grad_val": 1.0,
+ "clip_grad_val": 0.5,
"use_same_optim": false,
"loss_spec": {
- "name": "SmoothL1Loss"
+ "name": "MSELoss"
},
- "optim_spec": {
+ "actor_optim_spec": {
"name": "Adam",
- "lr": 2.5e-4
+ "lr": 2.5e-4,
+ },
+ "critic_optim_spec": {
+ "name": "Adam",
+ "lr": 2.5e-4,
+ },
+ "lr_scheduler_spec": {
+ "name": "LinearToZero",
+ "total_t": 1e7
},
- "lr_scheduler_spec": null,
"gpu": true
}
}],
"env": [{
"name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 8,
"max_t": null,
- "max_tick": 10000000
+ "max_frame": 1e7
}],
"body": {
"product": "outer",
@@ -67,14 +79,10 @@
},
"meta": {
"distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
"max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
+ "max_trial": 1,
}
}
}
diff --git a/slm_lab/spec/experimental/ppo_beamrider.json b/slm_lab/spec/experimental/ppo_beamrider.json
deleted file mode 100644
index f7d694993..000000000
--- a/slm_lab/spec/experimental/ppo_beamrider.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_beamrider": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BeamRiderNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ppo_breakout.json b/slm_lab/spec/experimental/ppo_breakout.json
deleted file mode 100644
index 0cc1095c0..000000000
--- a/slm_lab/spec/experimental/ppo_breakout.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_breakout": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "BreakoutNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ppo_mspacman.json b/slm_lab/spec/experimental/ppo_mspacman.json
deleted file mode 100644
index fd420325f..000000000
--- a/slm_lab/spec/experimental/ppo_mspacman.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_mspacman": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "MsPacmanNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ppo_qbert.json b/slm_lab/spec/experimental/ppo_qbert.json
deleted file mode 100644
index dc4c29d82..000000000
--- a/slm_lab/spec/experimental/ppo_qbert.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_qbert": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "QbertNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ppo_seaquest.json b/slm_lab/spec/experimental/ppo_seaquest.json
deleted file mode 100644
index 802defd57..000000000
--- a/slm_lab/spec/experimental/ppo_seaquest.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_seaquest": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SeaquestNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/ppo_sil.json b/slm_lab/spec/experimental/ppo_sil.json
index cbed8362f..438ec05e4 100644
--- a/slm_lab/spec/experimental/ppo_sil.json
+++ b/slm_lab/spec/experimental/ppo_sil.json
@@ -27,13 +27,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 4,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 4,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -64,7 +64,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -73,7 +73,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -128,13 +127,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4,
+ "training_epoch": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -165,7 +164,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 400,
+ "max_frame": 400,
}],
"body": {
"product": "outer",
@@ -174,7 +173,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -229,13 +227,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -270,7 +268,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -279,7 +277,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -334,13 +331,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -375,7 +372,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -384,7 +381,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -439,13 +435,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 4,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 4,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -476,7 +472,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -485,7 +481,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -540,13 +535,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -577,7 +572,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -586,7 +581,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -641,13 +635,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -682,7 +676,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -691,7 +685,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -746,13 +739,13 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 8,
+ "training_epoch": 8
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -787,7 +780,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -796,7 +789,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/ppo_spaceinvaders.json b/slm_lab/spec/experimental/ppo_spaceinvaders.json
deleted file mode 100644
index c05801bdc..000000000
--- a/slm_lab/spec/experimental/ppo_spaceinvaders.json
+++ /dev/null
@@ -1,80 +0,0 @@
-{
- "ppo_shared_spaceinvaders": {
- "agent": [{
- "name": "PPO",
- "algorithm": {
- "name": "PPO",
- "action_pdtype": "default",
- "action_policy": "default",
- "explore_var_spec": null,
- "gamma": 0.99,
- "lam": 0.95,
- "clip_eps_spec": {
- "name": "linear_decay",
- "start_val": 0.10,
- "end_val": 0.0,
- "start_step": 10000,
- "end_step": 10000000
- },
- "entropy_coef_spec": {
- "name": "no_decay",
- "start_val": 0.01,
- "end_val": 0.01,
- "start_step": 0,
- "end_step": 0
- },
- "val_loss_coef": 1.0,
- "training_frequency": 1,
- "training_epoch": 3,
- "normalize_state": false
- },
- "memory": {
- "name": "OnPolicyAtariReplay"
- },
- "net": {
- "type": "ConvNet",
- "shared": true,
- "conv_hid_layers": [
- [32, 8, 4, 0, 1],
- [64, 4, 2, 0, 1],
- [64, 3, 1, 0, 1]
- ],
- "fc_hid_layers": [256],
- "hid_layers_activation": "relu",
- "init_fn": null,
- "batch_norm": false,
- "clip_grad_val": 1.0,
- "use_same_optim": false,
- "loss_spec": {
- "name": "SmoothL1Loss"
- },
- "optim_spec": {
- "name": "Adam",
- "lr": 2.5e-4
- },
- "lr_scheduler_spec": null,
- "gpu": true
- }
- }],
- "env": [{
- "name": "SpaceInvadersNoFrameskip-v4",
- "max_t": null,
- "max_tick": 10000000
- }],
- "body": {
- "product": "outer",
- "num": 1
- },
- "meta": {
- "distributed": false,
- "eval_frequency": 10000,
- "max_tick_unit": "total_t",
- "max_session": 4,
- "max_trial": 12,
- "search": "RandomSearch",
- "resources": {
- "num_cpus": 12
- }
- }
- }
-}
diff --git a/slm_lab/spec/experimental/reinforce.json b/slm_lab/spec/experimental/reinforce.json
index 369d063aa..018f2a97b 100644
--- a/slm_lab/spec/experimental/reinforce.json
+++ b/slm_lab/spec/experimental/reinforce.json
@@ -15,8 +15,7 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -44,7 +43,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 400,
+ "max_frame": 400,
}],
"body": {
"product": "outer",
@@ -53,7 +52,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -88,11 +86,10 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -121,7 +118,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -130,7 +127,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -165,8 +161,7 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -194,7 +189,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -203,7 +198,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -238,11 +232,10 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": true
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicySeqReplay"
+ "name": "OnPolicyReplay"
},
"net": {
"type": "RecurrentNet",
@@ -271,7 +264,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -280,7 +273,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -315,8 +307,7 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": false
+ "training_frequency": 1
},
"memory": {
"name": "OnPolicyReplay"
@@ -350,7 +341,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -359,7 +350,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -370,7 +360,7 @@
"name": "Reinforce",
"algorithm": {
"name": "Reinforce",
- "action_pdtype": "default",
+ "action_pdtype": "MultiCategorical",
"action_policy": "default",
"explore_var_spec": null,
"gamma": 0.99,
@@ -381,12 +371,10 @@
"start_step": 1000,
"end_step": 5000,
},
- "training_frequency": 1,
- "normalize_state": false
+ "training_frequency": 1
},
"memory": {
- "name": "OnPolicyAtariReplay",
- "stack_len": 4
+ "name": "OnPolicyReplay",
},
"net": {
"type": "ConvNet",
@@ -417,9 +405,12 @@
}],
"env": [{
"name": "vizdoom-v0",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
"cfg_name": "basic",
- "max_t": null,
- "max_tick": 100
+ "max_t": 400000,
+ "max_frame": 100
}],
"body": {
"product": "outer",
@@ -428,7 +419,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/reinforce/reinforce_pong.json b/slm_lab/spec/experimental/reinforce/reinforce_pong.json
new file mode 100644
index 000000000..0145e355b
--- /dev/null
+++ b/slm_lab/spec/experimental/reinforce/reinforce_pong.json
@@ -0,0 +1,78 @@
+{
+ "reinforce_pong": {
+ "agent": [{
+ "name": "Reinforce",
+ "algorithm": {
+ "name": "Reinforce",
+ "action_pdtype": "Categorical",
+ "action_policy": "default",
+ "explore_var_spec": null,
+ "gamma": 0.99,
+ "entropy_coef_spec": {
+ "name": "no_decay",
+ "start_val": 0.01,
+ "end_val": 0.01,
+ "start_step": 0,
+ "end_step": 0
+ },
+ "training_frequency": 1
+ },
+ "memory": {
+ "name": "OnPolicyReplay",
+ },
+ "net": {
+ "type": "ConvNet",
+ "shared": true,
+ "conv_hid_layers": [
+ [32, 8, 4, 0, 1],
+ [64, 4, 2, 0, 1],
+ [32, 3, 1, 0, 1]
+ ],
+ "fc_hid_layers": [512],
+ "hid_layers_activation": "relu",
+ "init_fn": "orthogonal_",
+ "normalize": true,
+ "batch_norm": false,
+ "clip_grad_val": 0.5,
+ "use_same_optim": false,
+ "loss_spec": {
+ "name": "MSELoss"
+ },
+ "actor_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "critic_optim_spec": {
+ "name": "RMSprop",
+ "lr": 7e-4,
+ "alpha": 0.99,
+ "eps": 1e-5
+ },
+ "lr_scheduler_spec": null,
+ "gpu": true
+ }
+ }],
+ "env": [{
+ "name": "PongNoFrameskip-v4",
+ "frame_op": "concat",
+ "frame_op_len": 4,
+ "reward_scale": "sign",
+ "num_envs": 16,
+ "max_t": null,
+ "max_frame": 1e7
+ }],
+ "body": {
+ "product": "outer",
+ "num": 1
+ },
+ "meta": {
+ "distributed": false,
+ "log_frequency": 50000,
+ "eval_frequency": 50000,
+ "max_session": 1,
+ "max_trial": 1,
+ },
+ }
+}
diff --git a/slm_lab/spec/experimental/sarsa.json b/slm_lab/spec/experimental/sarsa.json
index 89b738e66..375038b51 100644
--- a/slm_lab/spec/experimental/sarsa.json
+++ b/slm_lab/spec/experimental/sarsa.json
@@ -14,8 +14,7 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
"name": "OnPolicyBatchReplay"
@@ -43,7 +42,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -52,7 +51,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -94,8 +92,7 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
"name": "OnPolicyBatchReplay"
@@ -123,7 +120,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -132,7 +129,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -174,11 +170,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
- "name": "OnPolicySeqBatchReplay"
+ "name": "OnPolicyBatchReplay"
},
"net": {
"type": "RecurrentNet",
@@ -207,7 +202,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -216,7 +211,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -258,11 +252,10 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 20,
- "normalize_state": true
+ "training_frequency": 20
},
"memory": {
- "name": "OnPolicySeqBatchReplay"
+ "name": "OnPolicyBatchReplay"
},
"net": {
"type": "RecurrentNet",
@@ -291,7 +284,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 250,
+ "max_frame": 250,
}],
"body": {
"product": "outer",
@@ -300,7 +293,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -342,8 +334,7 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 100,
- "normalize_state": false
+ "training_frequency": 100
},
"memory": {
"name": "OnPolicyBatchReplay"
@@ -377,7 +368,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -386,7 +377,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -407,8 +397,7 @@
"end_step": 2000,
},
"gamma": 0.99,
- "training_frequency": 100,
- "normalize_state": false
+ "training_frequency": 100
},
"memory": {
"name": "OnPolicyBatchReplay"
@@ -442,7 +431,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -451,7 +440,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/experimental/sil.json b/slm_lab/spec/experimental/sil.json
index 187f5192f..e5c4451c3 100644
--- a/slm_lab/spec/experimental/sil.json
+++ b/slm_lab/spec/experimental/sil.json
@@ -18,17 +18,16 @@
"end_step": 5000,
},
"policy_loss_coef": 1.0,
- "val_loss_coef": 0.69,
- "sil_policy_loss_coef": 0.59,
- "sil_val_loss_coef": 0.17,
+ "val_loss_coef": 0.5,
+ "sil_policy_loss_coef": 0.5,
+ "sil_val_loss_coef": 0.5,
"training_frequency": 1,
- "training_batch_epoch": 10,
- "training_epoch": 8,
- "normalize_state": true
+ "training_batch_iter": 4,
+ "training_iter": 8
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -37,7 +36,7 @@
"type": "MLPNet",
"shared": true,
"hid_layers": [64],
- "hid_layers_activation": "tanh",
+ "hid_layers_activation": "relu",
"clip_grad_val": null,
"use_same_optim": false,
"actor_optim_spec": {
@@ -59,7 +58,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 400,
+ "max_frame": 400,
}],
"body": {
"product": "outer",
@@ -68,15 +67,14 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
- "max_session": 4,
+ "max_session": 1,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -118,13 +116,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -155,7 +152,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -164,7 +161,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -172,7 +168,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -214,13 +210,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -255,7 +250,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -264,7 +259,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -272,7 +266,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -314,13 +308,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -355,7 +348,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -364,7 +357,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -372,7 +364,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -414,13 +406,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 4,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 4,
+ "training_iter": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -451,7 +442,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -460,7 +451,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -468,7 +458,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -510,13 +500,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -547,7 +536,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -556,7 +545,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -564,7 +552,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -606,13 +594,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -647,7 +634,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -656,7 +643,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -664,7 +650,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -706,13 +692,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": true
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
- "name": "OnPolicySeqReplay",
- "sil_replay_name": "SILSeqReplay",
+ "name": "OnPolicyReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -747,7 +732,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 500,
+ "max_frame": 500,
}],
"body": {
"product": "outer",
@@ -756,7 +741,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
@@ -764,7 +748,7 @@
"search": {
"agent": [{
"algorithm": {
- "training_epoch__choice": [1, 4, 8, 16]
+ "training_iter__choice": [1, 4, 8, 16]
},
"net": {
"hid_layers__choice": [
@@ -806,13 +790,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": false
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -848,7 +831,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -857,7 +840,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
@@ -886,13 +868,12 @@
"sil_policy_loss_coef": 1.0,
"sil_val_loss_coef": 0.1,
"training_frequency": 1,
- "training_batch_epoch": 8,
- "training_epoch": 4,
- "normalize_state": false
+ "training_batch_iter": 8,
+ "training_iter": 4
},
"memory": {
"name": "OnPolicyReplay",
- "sil_replay_name": "SILReplay",
+ "sil_replay_name": "Replay",
"batch_size": 32,
"max_size": 10000,
"use_cer": true
@@ -928,7 +909,7 @@
"env": [{
"name": "Breakout-v0",
"max_t": null,
- "max_tick": 1
+ "max_frame": 1
}],
"body": {
"product": "outer",
@@ -937,7 +918,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/random.json b/slm_lab/spec/random.json
index ac18daf79..6acc5f10f 100644
--- a/slm_lab/spec/random.json
+++ b/slm_lab/spec/random.json
@@ -13,7 +13,7 @@
"env": [{
"name": "CartPole-v0",
"max_t": null,
- "max_tick": 100
+ "max_frame": 100
}],
"body": {
"product": "outer",
@@ -22,7 +22,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 5,
"max_trial": 1,
"search": "RandomSearch"
@@ -42,7 +41,7 @@
"env": [{
"name": "Pendulum-v0",
"max_t": null,
- "max_tick": 100
+ "max_frame": 100
}],
"body": {
"product": "outer",
@@ -51,7 +50,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 5,
"max_trial": 1,
"search": "RandomSearch"
@@ -71,7 +69,7 @@
"env": [{
"name": "2DBall",
"max_t": 1000,
- "max_tick": 100
+ "max_frame": 100
}],
"body": {
"product": "outer",
@@ -80,7 +78,6 @@
"meta": {
"distributed": false,
"eval_frequency": 1000,
- "max_tick_unit": "epi",
"max_session": 5,
"max_trial": 1,
"search": "RandomSearch"
diff --git a/slm_lab/spec/random_baseline.py b/slm_lab/spec/random_baseline.py
new file mode 100644
index 000000000..2efaf0952
--- /dev/null
+++ b/slm_lab/spec/random_baseline.py
@@ -0,0 +1,133 @@
+# Module to generate random baselines
+# Run as: python slm_lab/spec/random_baseline.py
+from slm_lab.lib import logger, util
+import gym
+import numpy as np
+import pydash as ps
+
+
+FILEPATH = 'slm_lab/spec/_random_baseline.json'
+NUM_EVAL = 100
+# extra envs to include
+INCLUDE_ENVS = [
+ 'vizdoom-v0',
+]
+EXCLUDE_ENVS = [
+ 'CarRacing-v0', # window bug
+ 'Reacher-v2', # exclude mujoco
+ 'Pusher-v2',
+ 'Thrower-v2',
+ 'Striker-v2',
+ 'InvertedPendulum-v2',
+ 'InvertedDoublePendulum-v2',
+ 'HalfCheetah-v3',
+ 'Hopper-v3',
+ 'Swimmer-v3',
+ 'Walker2d-v3',
+ 'Ant-v3',
+ 'Humanoid-v3',
+ 'HumanoidStandup-v2',
+ 'FetchSlide-v1',
+ 'FetchPickAndPlace-v1',
+ 'FetchReach-v1',
+ 'FetchPush-v1',
+ 'HandReach-v0',
+ 'HandManipulateBlockRotateZ-v0',
+ 'HandManipulateBlockRotateParallel-v0',
+ 'HandManipulateBlockRotateXYZ-v0',
+ 'HandManipulateBlockFull-v0',
+ 'HandManipulateBlock-v0',
+ 'HandManipulateBlockTouchSensors-v0',
+ 'HandManipulateEggRotate-v0',
+ 'HandManipulateEggFull-v0',
+ 'HandManipulateEgg-v0',
+ 'HandManipulateEggTouchSensors-v0',
+ 'HandManipulatePenRotate-v0',
+ 'HandManipulatePenFull-v0',
+ 'HandManipulatePen-v0',
+ 'HandManipulatePenTouchSensors-v0',
+ 'FetchSlideDense-v1',
+ 'FetchPickAndPlaceDense-v1',
+ 'FetchReachDense-v1',
+ 'FetchPushDense-v1',
+ 'HandReachDense-v0',
+ 'HandManipulateBlockRotateZDense-v0',
+ 'HandManipulateBlockRotateParallelDense-v0',
+ 'HandManipulateBlockRotateXYZDense-v0',
+ 'HandManipulateBlockFullDense-v0',
+ 'HandManipulateBlockDense-v0',
+ 'HandManipulateBlockTouchSensorsDense-v0',
+ 'HandManipulateEggRotateDense-v0',
+ 'HandManipulateEggFullDense-v0',
+ 'HandManipulateEggDense-v0',
+ 'HandManipulateEggTouchSensorsDense-v0',
+ 'HandManipulatePenRotateDense-v0',
+ 'HandManipulatePenFullDense-v0',
+ 'HandManipulatePenDense-v0',
+ 'HandManipulatePenTouchSensorsDense-v0',
+]
+
+
+def enum_envs():
+ '''Enumerate all the env names of the latest version'''
+ envs = [es.id for es in gym.envs.registration.registry.all()]
+ envs += INCLUDE_ENVS
+ envs = ps.difference(envs, EXCLUDE_ENVS)
+ return envs
+
+
+def gen_random_return(env_name, seed):
+ '''Generate a single-episode random policy return for an environment'''
+ # TODO generalize for unity too once it has a gym wrapper
+ env = gym.make(env_name)
+ env.seed(seed)
+ env.reset()
+ done = False
+ total_reward = 0
+ while not done:
+ _, reward, done, _ = env.step(env.action_space.sample())
+ total_reward += reward
+ return total_reward
+
+
+def gen_random_baseline(env_name, num_eval=NUM_EVAL):
+ '''Generate the random baseline for an environment by averaging over num_eval episodes'''
+ returns = util.parallelize(gen_random_return, [(env_name, i) for i in range(num_eval)])
+ mean_rand_ret = np.mean(returns)
+ std_rand_ret = np.std(returns)
+ return {'mean': mean_rand_ret, 'std': std_rand_ret}
+
+
+def get_random_baseline(env_name):
+ '''Get a single random baseline for env; if does not exist in file, generate live and update the file'''
+ random_baseline = util.read(FILEPATH)
+ if env_name in random_baseline:
+ baseline = random_baseline[env_name]
+ else:
+ try:
+ logger.info(f'Generating random baseline for {env_name}')
+ baseline = gen_random_baseline(env_name, NUM_EVAL)
+ except Exception as e:
+ logger.warning(f'Cannot start env: {env_name}, skipping random baseline generation')
+ baseline = None
+ # update immediately
+ logger.info(f'Updating new random baseline in {FILEPATH}')
+ random_baseline[env_name] = baseline
+ util.write(random_baseline, FILEPATH)
+ return baseline
+
+
+def main():
+ '''
+ Main method to generate all random baselines and write to file.
+ Run as: python slm_lab/spec/random_baseline.py
+ '''
+ envs = enum_envs()
+ for idx, env_name in enumerate(envs):
+ logger.info(f'Generating random baseline for {env_name}: {idx + 1}/{len(envs)}')
+ get_random_baseline(env_name)
+ logger.info(f'Done, random baseline updated in {FILEPATH}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/slm_lab/spec/spec_util.py b/slm_lab/spec/spec_util.py
index 07f16ffaa..55661b20b 100644
--- a/slm_lab/spec/spec_util.py
+++ b/slm_lab/spec/spec_util.py
@@ -1,15 +1,14 @@
-'''
-The spec util
-Handles the Lab experiment spec: reading, writing(evolution), validation and default setting
-Expands the spec and params into consumable inputs in info space for lab units.
-'''
+# The spec module
+# Manages specification to run things in lab
from slm_lab.lib import logger, util
+from string import Template
import itertools
import json
import numpy as np
import os
import pydash as ps
+
SPEC_DIR = 'slm_lab/spec'
'''
All spec values are already param, inferred automatically.
@@ -27,20 +26,17 @@
}],
"env": [{
"name": str,
- "max_t": (type(None), int),
- "max_tick": int,
+ "max_t": (type(None), int, float),
+ "max_frame": (int, float),
}],
"body": {
"product": ["outer", "inner", "custom"],
"num": (int, list),
},
"meta": {
- "distributed": bool,
- "eval_frequency": int,
- "max_tick_unit": str,
+ "eval_frequency": (int, float),
"max_session": int,
"max_trial": (type(None), int),
- "search": str,
},
"name": str,
}
@@ -57,10 +53,13 @@ def check_comp_spec(comp_spec, comp_spec_format):
else:
v_type = spec_format_v
assert isinstance(comp_spec_v, v_type), f'Component spec {ps.pick(comp_spec, spec_k)} needs to be of type: {v_type}'
+ if isinstance(v_type, tuple) and int in v_type and isinstance(comp_spec_v, float):
+ # cast if it can be int
+ comp_spec[spec_k] = int(comp_spec_v)
def check_body_spec(spec):
- '''Base method to check body spec for AEB space resolution'''
+ '''Base method to check body spec for multi-agent multi-env'''
ae_product = ps.get(spec, 'body.product')
body_num = ps.get(spec, 'body.num')
if ae_product == 'outer':
@@ -69,10 +68,17 @@ def check_body_spec(spec):
agent_num = len(spec['agent'])
env_num = len(spec['env'])
assert agent_num == env_num, 'Agent and Env spec length must be equal for body `inner` product. Given {agent_num}, {env_num}'
- else: # custom AEB
+ else: # custom
assert ps.is_list(body_num)
+def check_compatibility(spec):
+ '''Check compatibility among spec setups'''
+ # TODO expand to be more comprehensive
+ if spec['meta'].get('distributed') == 'synced':
+ assert ps.get(spec, 'agent.0.net.gpu') == False, f'Distributed mode "synced" works with CPU only. Set gpu: false.'
+
+
def check(spec):
'''Check a single spec for validity'''
try:
@@ -84,7 +90,8 @@ def check(spec):
check_comp_spec(env_spec, SPEC_FORMAT['env'][0])
check_comp_spec(spec['body'], SPEC_FORMAT['body'])
check_comp_spec(spec['meta'], SPEC_FORMAT['meta'])
- check_body_spec(spec)
+ # check_body_spec(spec)
+ check_compatibility(spec)
except Exception as e:
logger.exception(f'spec {spec_name} fails spec check')
raise e
@@ -97,9 +104,10 @@ def check_all():
for spec_file in spec_files:
spec_dict = util.read(f'{SPEC_DIR}/{spec_file}')
for spec_name, spec in spec_dict.items():
+ # fill-in info at runtime
+ spec['name'] = spec_name
+ spec = extend_meta_spec(spec)
try:
- spec['name'] = spec_name
- spec['git_SHA'] = util.get_git_sha()
check(spec)
except Exception as e:
logger.exception(f'spec_file {spec_file} fails spec check')
@@ -108,6 +116,26 @@ def check_all():
return True
+def extend_meta_spec(spec):
+ '''Extend meta spec with information for lab functions'''
+ extended_meta_spec = {
+ # reset lab indices to -1 so that they tick to 0
+ 'experiment': -1,
+ 'trial': -1,
+ 'session': -1,
+ 'cuda_offset': int(os.environ.get('CUDA_OFFSET', 0)),
+ 'experiment_ts': util.get_ts(),
+ 'prepath': None,
+ # ckpt extends prepath, e.g. ckpt_str = ckpt-epi10-totalt1000
+ 'ckpt': None,
+ 'git_sha': util.get_git_sha(),
+ 'random_seed': None,
+ 'eval_model_prepath': None,
+ }
+ spec['meta'].update(extended_meta_spec)
+ return spec
+
+
def get(spec_file, spec_name):
'''
Get an experiment spec from spec_file, spec_name.
@@ -125,30 +153,39 @@ def get(spec_file, spec_name):
spec_dict = util.read(spec_file)
assert spec_name in spec_dict, f'spec_name {spec_name} is not in spec_file {spec_file}. Choose from:\n {ps.join(spec_dict.keys(), ",")}'
spec = spec_dict[spec_name]
+ # fill-in info at runtime
spec['name'] = spec_name
- spec['git_SHA'] = util.get_git_sha()
+ spec = extend_meta_spec(spec)
check(spec)
return spec
-def is_aeb_compact(aeb_list):
- '''
- Check if aeb space (aeb_list) is compact; uniq count must equal shape in each of a,e axes. For b, per unique a,e hash, uniq must equal shape.'''
- aeb_shape = util.get_aeb_shape(aeb_list)
- aeb_uniq = [len(np.unique(col)) for col in np.transpose(aeb_list)]
- ae_compact = np.array_equal(aeb_shape, aeb_uniq)
- b_compact = True
- for ae, ae_b_list in ps.group_by(aeb_list, lambda aeb: f'{aeb[0]}{aeb[1]}').items():
- b_shape = util.get_aeb_shape(ae_b_list)[2]
- b_uniq = [len(np.unique(col)) for col in np.transpose(ae_b_list)][2]
- b_compact = b_compact and np.array_equal(b_shape, b_uniq)
- aeb_compact = ae_compact and b_compact
- return aeb_compact
+def get_eval_spec(spec_file, prename):
+ '''Get spec for eval mode'''
+ predir, _, _, _, _, _ = util.prepath_split(spec_file)
+ prepath = f'{predir}/{prename}'
+ spec = util.prepath_to_spec(prepath)
+ spec['meta']['ckpt'] = 'eval'
+ spec['meta']['eval_model_prepath'] = util.insert_folder(prepath, 'model')
+ return spec
-def is_singleton(spec):
- '''Check if spec uses a singleton Session'''
- return len(spec['agent']) == 1 and len(spec['env']) == 1 and spec['body']['num'] == 1
+def get_param_specs(spec):
+ '''Return a list of specs with substituted spec_params'''
+ assert 'spec_params' in spec, 'Parametrized spec needs a spec_params key'
+ spec_params = spec.pop('spec_params')
+ spec_template = Template(json.dumps(spec))
+ keys = spec_params.keys()
+ specs = []
+ for idx, vals in enumerate(itertools.product(*spec_params.values())):
+ spec_str = spec_template.substitute(dict(zip(keys, vals)))
+ spec = json.loads(spec_str)
+ spec['name'] += f'_{"_".join(vals)}'
+ # offset to prevent parallel-run GPU competition, to mod in util.set_cuda_id
+ cuda_id_gap = int(spec['meta']['max_session'] / spec['meta']['param_spec_process'])
+ spec['meta']['cuda_offset'] += idx * cuda_id_gap
+ specs.append(spec)
+ return specs
def override_dev_spec(spec):
@@ -163,58 +200,65 @@ def override_enjoy_spec(spec):
def override_eval_spec(spec):
- for agent_spec in spec['agent']:
- if 'max_size' in agent_spec['memory']:
- agent_spec['memory']['max_size'] = 100
+ spec['meta']['max_session'] = 1
# evaluate by episode is set in env clock init in env/base.py
return spec
def override_test_spec(spec):
for agent_spec in spec['agent']:
- # covers episodic and timestep
- agent_spec['algorithm']['training_frequency'] = 1
+ # onpolicy freq is episodic
+ freq = 1 if agent_spec['memory']['name'] == 'OnPolicyReplay' else 8
+ agent_spec['algorithm']['training_frequency'] = freq
agent_spec['algorithm']['training_start_step'] = 1
- agent_spec['algorithm']['training_epoch'] = 1
- agent_spec['algorithm']['training_batch_epoch'] = 1
+ agent_spec['algorithm']['training_iter'] = 1
+ agent_spec['algorithm']['training_batch_iter'] = 1
for env_spec in spec['env']:
- env_spec['max_t'] = 20
- env_spec['max_tick'] = 3
- spec['meta']['eval_frequency'] = 1000
- spec['meta']['max_tick_unit'] = 'epi'
+ env_spec['max_frame'] = 40
+ env_spec['max_t'] = 12
+ spec['meta']['log_frequency'] = 10
+ spec['meta']['eval_frequency'] = 10
spec['meta']['max_session'] = 1
spec['meta']['max_trial'] = 2
return spec
-def resolve_aeb(spec):
- '''
- Resolve an experiment spec into the full list of points (coordinates) in AEB space.
- @param {dict} spec An experiment spec.
- @returns {list} aeb_list Resolved array of points in AEB space.
- @example
+def save(spec, unit='experiment'):
+ '''Save spec to proper path. Called at Experiment or Trial init.'''
+ prepath = util.get_prepath(spec, unit)
+ util.write(spec, f'{prepath}_spec.json')
- spec = spec_util.get('base.json', 'general_inner')
- aeb_list = spec_util.resolve_aeb(spec)
- # => [(0, 0, 0), (0, 0, 1), (1, 1, 0), (1, 1, 1)]
- '''
- agent_num = len(spec['agent']) if ps.is_list(spec['agent']) else 1
- env_num = len(spec['env']) if ps.is_list(spec['env']) else 1
- ae_product = ps.get(spec, 'body.product')
- body_num = ps.get(spec, 'body.num')
- body_num_list = body_num if ps.is_list(body_num) else [body_num] * env_num
- aeb_list = []
- if ae_product == 'outer':
- for e in range(env_num):
- sub_aeb_list = list(itertools.product(range(agent_num), [e], range(body_num_list[e])))
- aeb_list.extend(sub_aeb_list)
- elif ae_product == 'inner':
- for a, e in zip(range(agent_num), range(env_num)):
- sub_aeb_list = list(itertools.product([a], [e], range(body_num_list[e])))
- aeb_list.extend(sub_aeb_list)
- else: # custom AEB, body_num is a aeb_list
- aeb_list = [tuple(aeb) for aeb in body_num]
- aeb_list.sort()
- assert is_aeb_compact(aeb_list), 'Failed check: for a, e, uniq count == len (shape), and for each a,e hash, b uniq count == b len (shape)'
- return aeb_list
+def tick(spec, unit):
+ '''
+ Method to tick lab unit (experiment, trial, session) in meta spec to advance their indices
+ Reset lower lab indices to -1 so that they tick to 0
+ spec_util.tick(spec, 'session')
+ session = Session(spec)
+ '''
+ meta_spec = spec['meta']
+ if unit == 'experiment':
+ meta_spec['experiment_ts'] = util.get_ts()
+ meta_spec['experiment'] += 1
+ meta_spec['trial'] = -1
+ meta_spec['session'] = -1
+ elif unit == 'trial':
+ if meta_spec['experiment'] == -1:
+ meta_spec['experiment'] += 1
+ meta_spec['trial'] += 1
+ meta_spec['session'] = -1
+ elif unit == 'session':
+ if meta_spec['experiment'] == -1:
+ meta_spec['experiment'] += 1
+ if meta_spec['trial'] == -1:
+ meta_spec['trial'] += 1
+ meta_spec['session'] += 1
+ else:
+ raise ValueError(f'Unrecognized lab unit to tick: {unit}')
+ # set prepath since it is determined at this point
+ meta_spec['prepath'] = prepath = util.get_prepath(spec, unit)
+ for folder in ('graph', 'info', 'log', 'model'):
+ folder_prepath = util.insert_folder(prepath, folder)
+ os.makedirs(os.path.dirname(folder_prepath), exist_ok=True)
+ meta_spec[f'{folder}_prepath'] = folder_prepath
+ return spec
diff --git a/test/agent/algo/test_algo.py b/test/agent/algo/test_algo.py
deleted file mode 100644
index 8ccd6bd24..000000000
--- a/test/agent/algo/test_algo.py
+++ /dev/null
@@ -1,25 +0,0 @@
-from slm_lab.experiment.monitor import InfoSpace
-from slm_lab.experiment.control import Session, Trial, Experiment
-from slm_lab.lib import util
-from slm_lab.spec import spec_util
-from flaky import flaky
-import pytest
-import os
-import shutil
-
-
-def generic_algorithm_test(spec, algorithm_name):
- '''Need new InfoSpace() per trial otherwise session id doesn't tick correctly'''
- trial = Trial(spec, info_space=InfoSpace())
- trial_data = trial.run()
- folders = [x for x in os.listdir('data/') if x.startswith(algorithm_name)]
- assert len(folders) == 1
- path = 'data/' + folders[0]
- sess_data = util.read(path + '/' + algorithm_name + '_t0_s0_session_df.csv')
- rewards = sess_data['0.2'].replace("reward", -1).astype(float)
- print(f'rewards: {rewards}')
- maxr = rewards.max()
- # Delete test data folder and trial
- shutil.rmtree(path)
- del trial
- return maxr
diff --git a/test/agent/memory/test_onpolicy_memory.py b/test/agent/memory/test_onpolicy_memory.py
index 8ed781109..acaf4273e 100644
--- a/test/agent/memory/test_onpolicy_memory.py
+++ b/test/agent/memory/test_onpolicy_memory.py
@@ -5,7 +5,7 @@
def memory_init_util(memory):
- assert memory.true_size == 0
+ assert memory.size == 0
assert memory.seen_size == 0
return True
@@ -16,7 +16,7 @@ def memory_reset_util(memory, experiences):
e = experiences[i]
memory.add_experience(*e)
memory.reset()
- assert memory.true_size == 0
+ assert memory.size == 0
assert np.sum(memory.states) == 0
assert np.sum(memory.actions) == 0
assert np.sum(memory.rewards) == 0
@@ -45,7 +45,7 @@ def test_add_experience(self, test_on_policy_batch_memory):
experiences = test_on_policy_batch_memory[2]
exp = experiences[0]
memory.add_experience(*exp)
- assert memory.true_size == 1
+ assert memory.size == 1
assert len(memory.states) == 1
# Handle states and actions with multiple dimensions
assert np.array_equal(memory.states[-1], exp[0])
@@ -114,7 +114,7 @@ def test_add_experience(self, test_on_policy_episodic_memory):
experiences = test_on_policy_episodic_memory[2]
exp = experiences[0]
memory.add_experience(*exp)
- assert memory.true_size == 1
+ assert memory.size == 1
assert len(memory.states) == 0
# Handle states and actions with multiple dimensions
assert np.array_equal(memory.cur_epi_data['states'][-1], exp[0])
diff --git a/test/agent/memory/test_per_memory.py b/test/agent/memory/test_per_memory.py
index 5c4dc4548..342dbc5b7 100644
--- a/test/agent/memory/test_per_memory.py
+++ b/test/agent/memory/test_per_memory.py
@@ -2,7 +2,6 @@
from flaky import flaky
import numpy as np
import pytest
-import torch
@flaky
@@ -16,12 +15,13 @@ class TestPERMemory:
def test_prioritized_replay_memory_init(self, test_prioritized_replay_memory):
memory = test_prioritized_replay_memory[0]
- assert memory.true_size == 0
- assert memory.states.shape == (memory.max_size, memory.body.state_dim)
- assert memory.actions.shape == (memory.max_size,)
- assert memory.rewards.shape == (memory.max_size,)
- assert memory.dones.shape == (memory.max_size,)
- assert memory.priorities.shape == (memory.max_size,)
+ memory.reset()
+ assert memory.size == 0
+ assert len(memory.states) == memory.max_size
+ assert len(memory.actions) == memory.max_size
+ assert len(memory.rewards) == memory.max_size
+ assert len(memory.dones) == memory.max_size
+ assert len(memory.priorities) == memory.max_size
assert memory.tree.write == 0
assert memory.tree.total() == 0
assert memory.epsilon[0] == 0
@@ -34,12 +34,13 @@ def test_add_experience(self, test_prioritized_replay_memory):
experiences = test_prioritized_replay_memory[2]
exp = experiences[0]
memory.add_experience(*exp)
- assert memory.true_size == 1
+ assert memory.size == 1
assert memory.head == 0
# Handle states and actions with multiple dimensions
assert np.array_equal(memory.states[memory.head], exp[0])
assert memory.actions[memory.head] == exp[1]
assert memory.rewards[memory.head] == exp[2]
+ assert np.array_equal(memory.ns_buffer[0], exp[3])
assert memory.dones[memory.head] == exp[4]
assert memory.priorities[memory.head] == 1000
@@ -52,7 +53,7 @@ def test_wrap(self, test_prioritized_replay_memory):
for e in experiences:
memory.add_experience(*e)
num_added += 1
- assert memory.true_size == min(memory.max_size, num_added)
+ assert memory.size == min(memory.max_size, num_added)
assert memory.head == (num_added - 1) % memory.max_size
write = (num_added - 1) % memory.max_size + 1
if write == memory.max_size:
@@ -99,12 +100,13 @@ def test_reset(self, test_prioritized_replay_memory):
memory.add_experience(*e)
memory.reset()
assert memory.head == -1
- assert memory.true_size == 0
- assert np.sum(memory.states) == 0
- assert np.sum(memory.actions) == 0
- assert np.sum(memory.rewards) == 0
- assert np.sum(memory.dones) == 0
- assert np.sum(memory.priorities) == 0
+ assert memory.size == 0
+ assert memory.states[0] is None
+ assert memory.actions[0] is None
+ assert memory.rewards[0] is None
+ assert memory.dones[0] is None
+ assert memory.priorities[0] is None
+ assert len(memory.ns_buffer) == 0
assert memory.tree.write == 0
assert memory.tree.total() == 0
@@ -123,7 +125,7 @@ def test_update_priorities(self, test_prioritized_replay_memory):
memory.batch_idxs = np.asarray([0, 1, 2, 3]).astype(int)
memory.tree_idxs = [3, 4, 5, 6]
print(f'batch_size: {batch_size}, batch_idxs: {memory.batch_idxs}, tree_idxs: {memory.tree_idxs}')
- new_errors = torch.from_numpy(np.asarray([0, 10, 10, 20])).float().unsqueeze(dim=1)
+ new_errors = np.array([0, 10, 10, 20], dtype=np.float32)
print(f'new_errors: {new_errors}')
memory.update_priorities(new_errors)
memory.tree.print_tree()
@@ -133,7 +135,7 @@ def test_update_priorities(self, test_prioritized_replay_memory):
assert memory.priorities[2] == 10
assert memory.priorities[3] == 20
# Second update
- new_errors = torch.from_numpy(np.asarray([90, 0, 30, 0])).float().unsqueeze(dim=1)
+ new_errors = np.array([90, 0, 30, 0], dtype=np.float32)
# Manually change tree idxs and batch idxs
memory.batch_idxs = np.asarray([0, 1, 2, 3]).astype(int)
memory.tree_idxs = [3, 4, 5, 6]
diff --git a/test/agent/memory/test_replay_memory.py b/test/agent/memory/test_replay_memory.py
index f6161872b..4e647be97 100644
--- a/test/agent/memory/test_replay_memory.py
+++ b/test/agent/memory/test_replay_memory.py
@@ -1,10 +1,24 @@
-from collections import Counter
+from collections import deque
from copy import deepcopy
from flaky import flaky
+from slm_lab.agent.memory.replay import sample_next_states
import numpy as np
import pytest
+def test_sample_next_states():
+ # for each state, its next state is itself + 10
+ head = 1
+ max_size = 9
+ ns_idx_offset = 3
+ batch_idxs = np.arange(max_size)
+ states = [31, 32, 10, 11, 12, 20, 21, 22, 30]
+ ns_buffer = deque([40, 41, 42], maxlen=ns_idx_offset)
+ ns = sample_next_states(head, max_size, ns_idx_offset, batch_idxs, states, ns_buffer)
+ res = np.array([41, 42, 20, 21, 22, 30, 31, 32, 40])
+ assert np.array_equal(ns, res)
+
+
@flaky
class TestMemory:
'''
@@ -16,11 +30,12 @@ class TestMemory:
def test_memory_init(self, test_memory):
memory = test_memory[0]
- assert memory.true_size == 0
- assert memory.states.shape == (memory.max_size, memory.body.state_dim)
- assert memory.actions.shape == (memory.max_size,)
- assert memory.rewards.shape == (memory.max_size,)
- assert memory.dones.shape == (memory.max_size,)
+ memory.reset()
+ assert memory.size == 0
+ assert len(memory.states) == memory.max_size
+ assert len(memory.actions) == memory.max_size
+ assert len(memory.rewards) == memory.max_size
+ assert len(memory.dones) == memory.max_size
def test_add_experience(self, test_memory):
'''Adds an experience to the memory. Checks that memory size = 1, and checks that the experience values are equal to the experience added'''
@@ -29,12 +44,13 @@ def test_add_experience(self, test_memory):
experiences = test_memory[2]
exp = experiences[0]
memory.add_experience(*exp)
- assert memory.true_size == 1
+ assert memory.size == 1
assert memory.head == 0
# Handle states and actions with multiple dimensions
assert np.array_equal(memory.states[memory.head], exp[0])
assert memory.actions[memory.head] == exp[1]
assert memory.rewards[memory.head] == exp[2]
+ assert np.array_equal(memory.ns_buffer[0], exp[3])
assert memory.dones[memory.head] == exp[4]
def test_wrap(self, test_memory):
@@ -46,7 +62,7 @@ def test_wrap(self, test_memory):
for e in experiences:
memory.add_experience(*e)
num_added += 1
- assert memory.true_size == min(memory.max_size, num_added)
+ assert memory.size == min(memory.max_size, num_added)
assert memory.head == (num_added - 1) % memory.max_size
def test_sample(self, test_memory):
@@ -85,9 +101,13 @@ def test_sample_changes(self, test_memory):
def test_sample_next_states(self, test_memory):
memory = test_memory[0]
- idxs = np.array(range(memory.true_size))
- next_states = memory._sample_next_states(idxs)
- assert np.array_equal(next_states[len(next_states) - 1], memory.latest_next_state)
+ experiences = test_memory[2]
+ for e in experiences:
+ memory.add_experience(*e)
+ idxs = np.arange(memory.size) # for any self.head
+ next_states = sample_next_states(memory.head, memory.max_size, memory.ns_idx_offset, idxs, memory.states, memory.ns_buffer)
+ # check self.head actually samples from ns_buffer
+ assert np.array_equal(next_states[memory.head], memory.ns_buffer[0])
def test_reset(self, test_memory):
'''Tests memory reset. Adds 2 experiences, then resets the memory and checks if all appropriate values have been zeroed'''
@@ -99,11 +119,12 @@ def test_reset(self, test_memory):
memory.add_experience(*e)
memory.reset()
assert memory.head == -1
- assert memory.true_size == 0
- assert np.sum(memory.states) == 0
- assert np.sum(memory.actions) == 0
- assert np.sum(memory.rewards) == 0
- assert np.sum(memory.dones) == 0
+ assert memory.size == 0
+ assert memory.states[0] is None
+ assert memory.actions[0] is None
+ assert memory.rewards[0] is None
+ assert memory.dones[0] is None
+ assert len(memory.ns_buffer) == 0
@pytest.mark.skip(reason="Not implemented yet")
def test_sample_dist(self, test_memory):
diff --git a/test/agent/net/test_conv.py b/test/agent/net/test_conv.py
index 233a58a76..e2bb5c954 100644
--- a/test/agent/net/test_conv.py
+++ b/test/agent/net/test_conv.py
@@ -1,4 +1,5 @@
from copy import deepcopy
+from slm_lab.env.base import Clock
from slm_lab.agent.net import net_util
from slm_lab.agent.net.conv import ConvNet
import torch
@@ -35,6 +36,9 @@
out_dim = 3
batch_size = 16
net = ConvNet(net_spec, in_dim, out_dim)
+# init net optimizer and its lr scheduler
+optim = net_util.get_optim(net, net.optim_spec)
+lr_scheduler = net_util.get_lr_scheduler(optim, net.lr_scheduler_spec)
x = torch.rand((batch_size,) + in_dim)
@@ -52,14 +56,11 @@ def test_forward():
assert y.shape == (batch_size, out_dim)
-def test_wrap_eval():
- y = net.wrap_eval(x)
- assert y.shape == (batch_size, out_dim)
-
-
-def test_training_step():
+def test_train_step():
y = torch.rand((batch_size, out_dim))
- loss = net.training_step(x=x, y=y)
+ clock = Clock(100, 1)
+ loss = net.loss_fn(net.forward(x), y)
+ net.train_step(loss, optim, lr_scheduler, clock=clock)
assert loss != 0.0
diff --git a/test/agent/net/test_mlp.py b/test/agent/net/test_mlp.py
index 6c56a1218..3d703aa33 100644
--- a/test/agent/net/test_mlp.py
+++ b/test/agent/net/test_mlp.py
@@ -1,4 +1,5 @@
from copy import deepcopy
+from slm_lab.env.base import Clock
from slm_lab.agent.net import net_util
from slm_lab.agent.net.mlp import MLPNet
import torch
@@ -32,6 +33,9 @@
out_dim = 3
batch_size = 16
net = MLPNet(net_spec, in_dim, out_dim)
+# init net optimizer and its lr scheduler
+optim = net_util.get_optim(net, net.optim_spec)
+lr_scheduler = net_util.get_lr_scheduler(optim, net.lr_scheduler_spec)
x = torch.rand((batch_size, in_dim))
@@ -48,14 +52,11 @@ def test_forward():
assert y.shape == (batch_size, out_dim)
-def test_wrap_eval():
- y = net.wrap_eval(x)
- assert y.shape == (batch_size, out_dim)
-
-
-def test_training_step():
+def test_train_step():
y = torch.rand((batch_size, out_dim))
- loss = net.training_step(x=x, y=y)
+ clock = Clock(100, 1)
+ loss = net.loss_fn(net.forward(x), y)
+ net.train_step(loss, optim, lr_scheduler, clock=clock)
assert loss != 0.0
@@ -67,7 +68,6 @@ def test_no_lr_scheduler():
assert hasattr(net, 'model')
assert hasattr(net, 'model_tail')
assert not hasattr(net, 'model_tails')
- assert isinstance(net.lr_scheduler, net_util.NoOpLRScheduler)
y = net.forward(x)
assert y.shape == (batch_size, out_dim)
diff --git a/test/agent/net/test_recurrent.py b/test/agent/net/test_recurrent.py
index c2a86d3e4..cd46b233a 100644
--- a/test/agent/net/test_recurrent.py
+++ b/test/agent/net/test_recurrent.py
@@ -1,4 +1,5 @@
from copy import deepcopy
+from slm_lab.env.base import Clock
from slm_lab.agent.net import net_util
from slm_lab.agent.net.recurrent import RecurrentNet
import pytest
@@ -31,12 +32,16 @@
},
"gpu": True
}
-in_dim = 10
+state_dim = 10
out_dim = 3
batch_size = 16
seq_len = net_spec['seq_len']
+in_dim = (seq_len, state_dim)
net = RecurrentNet(net_spec, in_dim, out_dim)
-x = torch.rand((batch_size, seq_len, in_dim))
+# init net optimizer and its lr scheduler
+optim = net_util.get_optim(net, net.optim_spec)
+lr_scheduler = net_util.get_lr_scheduler(optim, net.lr_scheduler_spec)
+x = torch.rand((batch_size, seq_len, state_dim))
def test_init():
@@ -54,14 +59,11 @@ def test_forward():
assert y.shape == (batch_size, out_dim)
-def test_wrap_eval():
- y = net.wrap_eval(x)
- assert y.shape == (batch_size, out_dim)
-
-
-def test_training_step():
+def test_train_step():
y = torch.rand((batch_size, out_dim))
- loss = net.training_step(x=x, y=y)
+ clock = Clock(100, 1)
+ loss = net.loss_fn(net.forward(x), y)
+ net.train_step(loss, optim, lr_scheduler, clock=clock)
assert loss != 0.0
diff --git a/test/conftest.py b/test/conftest.py
index 16db8ce58..992049879 100644
--- a/test/conftest.py
+++ b/test/conftest.py
@@ -1,6 +1,4 @@
-from slm_lab.agent import AgentSpace
-from slm_lab.env import EnvSpace
-from slm_lab.experiment.monitor import AEBSpace, InfoSpace
+from slm_lab.experiment.control import make_agent_env
from slm_lab.lib import util
from slm_lab.spec import spec_util
from xvfbwrapper import Xvfb
@@ -9,12 +7,6 @@
import pytest
-spec = None
-aeb_space = None
-agent = None
-env = None
-
-
@pytest.fixture(scope='session', autouse=True)
def test_xvfb():
'''provide xvfb in test environment'''
@@ -29,40 +21,11 @@ def test_xvfb():
@pytest.fixture(scope='session')
def test_spec():
- global spec
spec = spec_util.get('base.json', 'base_case_openai')
spec = spec_util.override_test_spec(spec)
return spec
-@pytest.fixture(scope='session')
-def test_info_space():
- return InfoSpace()
-
-
-@pytest.fixture(scope='session')
-def test_aeb_space(test_spec):
- global aeb_space
- if aeb_space is None:
- aeb_space = AEBSpace(test_spec, InfoSpace())
- env_space = EnvSpace(test_spec, aeb_space)
- aeb_space.init_body_space()
- agent_space = AgentSpace(test_spec, aeb_space)
- return aeb_space
-
-
-@pytest.fixture(scope='session')
-def test_agent(test_aeb_space):
- agent = test_aeb_space.agent_space.agents[0]
- return agent
-
-
-@pytest.fixture(scope='session')
-def test_env(test_aeb_space):
- env = test_aeb_space.env_space.envs[0]
- return env
-
-
@pytest.fixture
def test_df():
data = pd.DataFrame({
@@ -122,15 +85,9 @@ def test_str():
),
])
def test_memory(request):
- memspec = spec_util.get('base.json', 'base_memory')
- memspec = spec_util.override_test_spec(memspec)
- aeb_mem_space = AEBSpace(memspec, InfoSpace())
- env_space = EnvSpace(memspec, aeb_mem_space)
- aeb_mem_space.init_body_space()
- agent_space = AgentSpace(memspec, aeb_mem_space)
- agent = agent_space.agents[0]
- body = agent.nanflat_body_a[0]
- res = (body.memory, ) + request.param
+ spec = spec_util.get('base.json', 'base_memory')
+ agent, env = make_agent_env(spec)
+ res = (agent.body.memory, ) + request.param
return res
@@ -150,15 +107,9 @@ def test_memory(request):
),
])
def test_on_policy_episodic_memory(request):
- memspec = spec_util.get('base.json', 'base_on_policy_memory')
- memspec = spec_util.override_test_spec(memspec)
- aeb_mem_space = AEBSpace(memspec, InfoSpace())
- env_space = EnvSpace(memspec, aeb_mem_space)
- aeb_mem_space.init_body_space()
- agent_space = AgentSpace(memspec, aeb_mem_space)
- agent = agent_space.agents[0]
- body = agent.nanflat_body_a[0]
- res = (body.memory, ) + request.param
+ spec = spec_util.get('base.json', 'base_on_policy_memory')
+ agent, env = make_agent_env(spec)
+ res = (agent.body.memory, ) + request.param
return res
@@ -178,15 +129,9 @@ def test_on_policy_episodic_memory(request):
),
])
def test_on_policy_batch_memory(request):
- memspec = spec_util.get('base.json', 'base_on_policy_batch_memory')
- memspec = spec_util.override_test_spec(memspec)
- aeb_mem_space = AEBSpace(memspec, InfoSpace())
- env_space = EnvSpace(memspec, aeb_mem_space)
- aeb_mem_space.init_body_space()
- agent_space = AgentSpace(memspec, aeb_mem_space)
- agent = agent_space.agents[0]
- body = agent.nanflat_body_a[0]
- res = (body.memory, ) + request.param
+ spec = spec_util.get('base.json', 'base_on_policy_batch_memory')
+ agent, env = make_agent_env(spec)
+ res = (agent.body.memory, ) + request.param
return res
@@ -206,13 +151,7 @@ def test_on_policy_batch_memory(request):
),
])
def test_prioritized_replay_memory(request):
- memspec = spec_util.get('base.json', 'base_prioritized_replay_memory')
- memspec = spec_util.override_test_spec(memspec)
- aeb_mem_space = AEBSpace(memspec, InfoSpace())
- env_space = EnvSpace(memspec, aeb_mem_space)
- aeb_mem_space.init_body_space()
- agent_space = AgentSpace(memspec, aeb_mem_space)
- agent = agent_space.agents[0]
- body = agent.nanflat_body_a[0]
- res = (body.memory, ) + request.param
+ spec = spec_util.get('base.json', 'base_prioritized_replay_memory')
+ agent, env = make_agent_env(spec)
+ res = (agent.body.memory, ) + request.param
return res
diff --git a/test/env/test_vec_env.py b/test/env/test_vec_env.py
new file mode 100644
index 000000000..e8dc58f0f
--- /dev/null
+++ b/test/env/test_vec_env.py
@@ -0,0 +1,80 @@
+from slm_lab.env.vec_env import make_gym_venv
+import numpy as np
+import pytest
+
+
+@pytest.mark.parametrize('name,state_shape,reward_scale', [
+ ('PongNoFrameskip-v4', (1, 84, 84), 'sign'),
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+@pytest.mark.parametrize('num_envs', (1, 4))
+def test_make_gym_venv_nostack(name, num_envs, state_shape, reward_scale):
+ seed = 0
+ frame_op = None
+ frame_op_len = None
+ venv = make_gym_venv(name, num_envs, seed, frame_op, frame_op_len, reward_scale)
+ venv.reset()
+ for i in range(5):
+ state, reward, done, info = venv.step([venv.action_space.sample()] * num_envs)
+
+ assert isinstance(state, np.ndarray)
+ assert state.shape == (num_envs,) + state_shape
+ assert isinstance(reward, np.ndarray)
+ assert reward.shape == (num_envs,)
+ assert isinstance(done, np.ndarray)
+ assert done.shape == (num_envs,)
+ assert len(info) == num_envs
+ venv.close()
+
+
+@pytest.mark.parametrize('name,state_shape, reward_scale', [
+ ('PongNoFrameskip-v4', (1, 84, 84), 'sign'),
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+@pytest.mark.parametrize('num_envs', (1, 4))
+def test_make_gym_concat(name, num_envs, state_shape, reward_scale):
+ seed = 0
+ frame_op = 'concat' # used for image, or for concat vector
+ frame_op_len = 4
+ venv = make_gym_venv(name, num_envs, seed, frame_op, frame_op_len, reward_scale)
+ venv.reset()
+ for i in range(5):
+ state, reward, done, info = venv.step([venv.action_space.sample()] * num_envs)
+
+ assert isinstance(state, np.ndarray)
+ stack_shape = (num_envs, frame_op_len * state_shape[0],) + state_shape[1:]
+ assert state.shape == stack_shape
+ assert isinstance(reward, np.ndarray)
+ assert reward.shape == (num_envs,)
+ assert isinstance(done, np.ndarray)
+ assert done.shape == (num_envs,)
+ assert len(info) == num_envs
+ venv.close()
+
+
+@pytest.mark.skip(reason='Not implemented yet')
+@pytest.mark.parametrize('name,state_shape,reward_scale', [
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+@pytest.mark.parametrize('num_envs', (1, 4))
+def test_make_gym_stack(name, num_envs, state_shape, reward_scale):
+ seed = 0
+ frame_op = 'stack' # used for rnn
+ frame_op_len = 4
+ venv = make_gym_venv(name, num_envs, seed, frame_op, frame_op_len, reward_scale)
+ venv.reset()
+ for i in range(5):
+ state, reward, done, info = venv.step([venv.action_space.sample()] * num_envs)
+
+ assert isinstance(state, np.ndarray)
+ stack_shape = (num_envs, frame_op_len,) + state_shape
+ assert state.shape == stack_shape
+ assert isinstance(reward, np.ndarray)
+ assert reward.shape == (num_envs,)
+ assert isinstance(done, np.ndarray)
+ assert done.shape == (num_envs,)
+ assert len(info) == num_envs
+ venv.close()
diff --git a/test/env/test_wrapper.py b/test/env/test_wrapper.py
new file mode 100644
index 000000000..6b237efef
--- /dev/null
+++ b/test/env/test_wrapper.py
@@ -0,0 +1,79 @@
+from slm_lab.env.wrapper import make_gym_env, LazyFrames
+import numpy as np
+import pytest
+
+
+@pytest.mark.parametrize('name,state_shape,reward_scale', [
+ ('PongNoFrameskip-v4', (1, 84, 84), 'sign'),
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+def test_make_gym_env_nostack(name, state_shape, reward_scale):
+ seed = 0
+ frame_op = None
+ frame_op_len = None
+ env = make_gym_env(name, seed, frame_op, frame_op_len, reward_scale)
+ env.reset()
+ for i in range(5):
+ state, reward, done, info = env.step(env.action_space.sample())
+
+ assert isinstance(state, np.ndarray)
+ assert state.shape == state_shape
+ assert state.shape == env.observation_space.shape
+ assert isinstance(reward, float)
+ assert isinstance(done, bool)
+ assert isinstance(info, dict)
+ env.close()
+
+
+@pytest.mark.parametrize('name,state_shape,reward_scale', [
+ ('PongNoFrameskip-v4', (1, 84, 84), 'sign'),
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+def test_make_gym_env_concat(name, state_shape, reward_scale):
+ seed = 0
+ frame_op = 'concat' # used for image, or for concat vector
+ frame_op_len = 4
+ env = make_gym_env(name, seed, frame_op, frame_op_len, reward_scale)
+ env.reset()
+ for i in range(5):
+ state, reward, done, info = env.step(env.action_space.sample())
+
+ assert isinstance(state, LazyFrames)
+ state = state.__array__() # realize data
+ assert isinstance(state, np.ndarray)
+ # concat multiplies first dim
+ stack_shape = (frame_op_len * state_shape[0],) + state_shape[1:]
+ assert state.shape == stack_shape
+ assert state.shape == env.observation_space.shape
+ assert isinstance(reward, float)
+ assert isinstance(done, bool)
+ assert isinstance(info, dict)
+ env.close()
+
+
+@pytest.mark.parametrize('name,state_shape, reward_scale', [
+ ('LunarLander-v2', (8,), None),
+ ('CartPole-v0', (4,), None),
+])
+def test_make_gym_env_stack(name, state_shape, reward_scale):
+ seed = 0
+ frame_op = 'stack' # used for rnn
+ frame_op_len = 4
+ env = make_gym_env(name, seed, frame_op, frame_op_len, reward_scale)
+ env.reset()
+ for i in range(5):
+ state, reward, done, info = env.step(env.action_space.sample())
+
+ assert isinstance(state, LazyFrames)
+ state = state.__array__() # realize data
+ assert isinstance(state, np.ndarray)
+ # stack creates new dim
+ stack_shape = (frame_op_len, ) + state_shape
+ assert state.shape == stack_shape
+ assert state.shape == env.observation_space.shape
+ assert isinstance(reward, float)
+ assert isinstance(done, bool)
+ assert isinstance(info, dict)
+ env.close()
diff --git a/test/experiment/test_control.py b/test/experiment/test_control.py
index 9046213db..34aa7a679 100644
--- a/test/experiment/test_control.py
+++ b/test/experiment/test_control.py
@@ -1,57 +1,59 @@
from copy import deepcopy
-from slm_lab.experiment.control import Session, Trial, Experiment
+from flaky import flaky
from slm_lab.experiment import analysis
-from slm_lab.lib import util
+from slm_lab.experiment.control import Session, Trial, Experiment
from slm_lab.spec import spec_util
import pandas as pd
import pytest
-def test_session(test_spec, test_info_space):
- test_info_space.tick('trial')
- test_info_space.tick('session')
- analysis.save_spec(test_spec, test_info_space, unit='trial')
- session = Session(test_spec, test_info_space)
- session_data = session.run()
- assert isinstance(session_data, pd.DataFrame)
-
+def test_session(test_spec):
+ spec_util.tick(test_spec, 'trial')
+ spec_util.tick(test_spec, 'session')
+ spec_util.save(test_spec, unit='trial')
+ session = Session(test_spec)
+ session_metrics = session.run()
+ assert isinstance(session_metrics, dict)
-def test_session_total_t(test_spec, test_info_space):
- test_info_space.tick('trial')
- test_info_space.tick('session')
- analysis.save_spec(test_spec, test_info_space, unit='trial')
- spec = deepcopy(test_spec)
- env_spec = spec['env'][0]
- env_spec['max_tick'] = 30
- spec['meta']['max_tick_unit'] = 'total_t'
- session = Session(spec, test_info_space)
- assert session.env.max_tick_unit == 'total_t'
- session_data = session.run()
- assert isinstance(session_data, pd.DataFrame)
+def test_trial(test_spec):
+ spec_util.tick(test_spec, 'trial')
+ spec_util.save(test_spec, unit='trial')
+ trial = Trial(test_spec)
+ trial_metrics = trial.run()
+ assert isinstance(trial_metrics, dict)
-def test_trial(test_spec, test_info_space):
- test_info_space.tick('trial')
- analysis.save_spec(test_spec, test_info_space, unit='trial')
- trial = Trial(test_spec, test_info_space)
- trial_data = trial.run()
- assert isinstance(trial_data, pd.DataFrame)
-
-def test_trial_demo(test_info_space):
+def test_trial_demo():
spec = spec_util.get('demo.json', 'dqn_cartpole')
- analysis.save_spec(spec, test_info_space, unit='experiment')
+ spec_util.save(spec, unit='experiment')
spec = spec_util.override_test_spec(spec)
- spec['meta']['eval_frequency'] = 1
- test_info_space.tick('trial')
- trial_data = Trial(spec, test_info_space).run()
- assert isinstance(trial_data, pd.DataFrame)
+ spec_util.tick(spec, 'trial')
+ trial_metrics = Trial(spec).run()
+ assert isinstance(trial_metrics, dict)
-def test_experiment(test_info_space):
+@pytest.mark.skip(reason="Unstable")
+@flaky
+def test_demo_performance():
+ spec = spec_util.get('demo.json', 'dqn_cartpole')
+ spec_util.save(spec, unit='experiment')
+ for env_spec in spec['env']:
+ env_spec['max_frame'] = 2000
+ spec_util.tick(spec, 'trial')
+ trial = Trial(spec)
+ spec_util.tick(spec, 'session')
+ session = Session(spec)
+ session.run()
+ last_reward = session.agent.body.train_df.iloc[-1]['total_reward']
+ assert last_reward > 50, f'last_reward is too low: {last_reward}'
+
+
+@pytest.mark.skip(reason="Cant run on CI")
+def test_experiment():
spec = spec_util.get('demo.json', 'dqn_cartpole')
- analysis.save_spec(spec, test_info_space, unit='experiment')
+ spec_util.save(spec, unit='experiment')
spec = spec_util.override_test_spec(spec)
- test_info_space.tick('experiment')
- experiment_data = Experiment(spec, test_info_space).run()
- assert isinstance(experiment_data, pd.DataFrame)
+ spec_util.tick(spec, 'experiment')
+ experiment_df = Experiment(spec).run()
+ assert isinstance(experiment_df, pd.DataFrame)
diff --git a/test/experiment/test_monitor.py b/test/experiment/test_monitor.py
index c4d79fd28..b68e192a0 100644
--- a/test/experiment/test_monitor.py
+++ b/test/experiment/test_monitor.py
@@ -1,5 +1,3 @@
-from slm_lab.experiment.monitor import AEBSpace
-import numpy as np
import pytest
# TODO add these tests
@@ -11,11 +9,3 @@ def test_clock():
def test_body():
return
-
-
-def test_data_space(test_spec):
- return
-
-
-def test_aeb_space(test_spec):
- return
diff --git a/test/fixture/lib/util/test_df.csv b/test/fixture/lib/util/test_df.csv
index b7df3426a..305661610 100644
--- a/test/fixture/lib/util/test_df.csv
+++ b/test/fixture/lib/util/test_df.csv
@@ -1,4 +1,4 @@
-,integer,letter,square
-0,1,a,1
-1,2,b,4
-2,3,c,9
+integer,letter,square
+1,a,1
+2,b,4
+3,c,9
diff --git a/test/lib/test_distribution.py b/test/lib/test_distribution.py
new file mode 100644
index 000000000..8932f900c
--- /dev/null
+++ b/test/lib/test_distribution.py
@@ -0,0 +1,47 @@
+from flaky import flaky
+from slm_lab.lib import distribution
+import pytest
+import torch
+
+
+@pytest.mark.parametrize('pdparam_type', [
+ 'probs', 'logits'
+])
+def test_argmax(pdparam_type):
+ pdparam = torch.tensor([1.1, 10.0, 2.1])
+ # test both probs or logits
+ pd = distribution.Argmax(**{pdparam_type: pdparam})
+ for _ in range(10):
+ assert pd.sample().item() == 1
+ assert torch.equal(pd.probs, torch.tensor([0., 1., 0.]))
+
+
+@flaky
+@pytest.mark.parametrize('pdparam_type', [
+ 'probs', 'logits'
+])
+def test_gumbel_categorical(pdparam_type):
+ pdparam = torch.tensor([1.1, 10.0, 2.1])
+ pd = distribution.GumbelCategorical(**{pdparam_type: pdparam})
+ for _ in range(10):
+ assert torch.is_tensor(pd.sample())
+
+
+@pytest.mark.parametrize('pdparam_type', [
+ 'probs', 'logits'
+])
+def test_multicategorical(pdparam_type):
+ pdparam0 = torch.tensor([10.0, 0.0, 0.0])
+ pdparam1 = torch.tensor([0.0, 10.0, 0.0])
+ pdparam2 = torch.tensor([0.0, 0.0, 10.0])
+ pdparams = [pdparam0, pdparam1, pdparam2]
+ # use a probs
+ pd = distribution.MultiCategorical(**{pdparam_type: pdparams})
+ assert isinstance(pd.probs, list)
+ # test probs only since if init from logits, probs will be close but not precise
+ if pdparam_type == 'probs':
+ assert torch.equal(pd.probs[0], torch.tensor([1., 0., 0.]))
+ assert torch.equal(pd.probs[1], torch.tensor([0., 1., 0.]))
+ assert torch.equal(pd.probs[2], torch.tensor([0., 0., 1.]))
+ for _ in range(10):
+ assert torch.equal(pd.sample(), torch.tensor([0, 1, 2]))
diff --git a/test/lib/test_logger.py b/test/lib/test_logger.py
index f30ede71c..50baf3d7e 100644
--- a/test/lib/test_logger.py
+++ b/test/lib/test_logger.py
@@ -7,4 +7,4 @@ def test_logger(test_str):
logger.error(test_str)
logger.exception(test_str)
logger.info(test_str)
- logger.warn(test_str)
+ logger.warning(test_str)
diff --git a/test/lib/test_math_util.py b/test/lib/test_math_util.py
index 64ba99d06..01ac9a11b 100644
--- a/test/lib/test_math_util.py
+++ b/test/lib/test_math_util.py
@@ -4,6 +4,33 @@
import torch
+@pytest.mark.parametrize('base_shape', [
+ [], # scalar
+ [2], # vector
+ [4, 84, 84], # image
+])
+def test_venv_pack(base_shape):
+ batch_size = 5
+ num_envs = 4
+ batch_arr = torch.zeros([batch_size, num_envs] + base_shape)
+ unpacked_arr = math_util.venv_unpack(batch_arr)
+ packed_arr = math_util.venv_pack(unpacked_arr, num_envs)
+ assert list(packed_arr.shape) == [batch_size, num_envs] + base_shape
+
+
+@pytest.mark.parametrize('base_shape', [
+ [], # scalar
+ [2], # vector
+ [4, 84, 84], # image
+])
+def test_venv_unpack(base_shape):
+ batch_size = 5
+ num_envs = 4
+ batch_arr = torch.zeros([batch_size, num_envs] + base_shape)
+ unpacked_arr = math_util.venv_unpack(batch_arr)
+ assert list(unpacked_arr.shape) == [batch_size * num_envs] + base_shape
+
+
def test_calc_gaes():
rewards = torch.tensor([1., 0., 1., 1., 0., 1., 1., 1.])
dones = torch.tensor([0., 0., 1., 1., 0., 0., 0., 0.])
@@ -17,15 +44,6 @@ def test_calc_gaes():
assert torch.allclose(gaes, res)
-@pytest.mark.parametrize('vec,res', [
- ([1, 1, 1], [False, False, False]),
- ([1, 1, 2], [False, False, True]),
- ([[1, 1], [1, 1], [1, 2]], [False, False, True]),
-])
-def test_is_outlier(vec, res):
- assert np.array_equal(math_util.is_outlier(vec), res)
-
-
@pytest.mark.parametrize('start_val, end_val, start_step, end_step, step, correct', [
(0.1, 0.0, 0, 100, 0, 0.1),
(0.1, 0.0, 0, 100, 50, 0.05),
diff --git a/test/lib/test_util.py b/test/lib/test_util.py
index 44ed665f3..e339613c2 100644
--- a/test/lib/test_util.py
+++ b/test/lib/test_util.py
@@ -1,5 +1,4 @@
from slm_lab.agent import Agent
-from slm_lab.env import Clock
from slm_lab.lib import util
import numpy as np
import os
@@ -31,18 +30,6 @@ def test_cast_list(test_list, test_str):
assert ps.is_list(util.cast_list(test_str))
-@pytest.mark.parametrize('arr,arr_len', [
- ([0, 1, 2], 3),
- ([0, 1, 2, None], 3),
- ([0, 1, 2, np.nan], 3),
- ([0, 1, 2, np.nan, np.nan], 3),
- ([0, 1, Clock()], 3),
- ([0, 1, Clock(), np.nan], 3),
-])
-def test_count_nonan(arr, arr_len):
- assert util.count_nonan(np.array(arr)) == arr_len
-
-
@pytest.mark.parametrize('d,flat_d', [
({'a': 1}, {'a': 1}),
({'a': {'b': 1}}, {'a.b': 1}),
@@ -77,44 +64,8 @@ def test_flatten_dict(d, flat_d):
assert util.flatten_dict(d) == flat_d
-@pytest.mark.parametrize('arr', [
- ([0, 1, 2]),
- ([0, 1, 2, None]),
- ([0, 1, 2, np.nan]),
- ([0, 1, 2, np.nan, np.nan]),
- ([0, 1, Clock()]),
- ([0, 1, Clock(), np.nan]),
-])
-def test_filter_nonan(arr):
- arr = np.array(arr)
- assert np.array_equal(util.filter_nonan(arr), arr[:3])
-
-
-@pytest.mark.parametrize('arr,res', [
- ([0, np.nan], [0]),
- ([[0, np.nan], [1, 2]], [0, 1, 2]),
- ([[[0], [np.nan]], [[1], [2]]], [0, 1, 2]),
-])
-def test_nanflatten(arr, res):
- arr = np.array(arr)
- res = np.array(res)
- assert np.array_equal(util.nanflatten(arr), res)
-
-
-@pytest.mark.parametrize('v,isnan', [
- (0, False),
- (1, False),
- (Clock(), False),
- (None, True),
- (np.nan, True),
-])
-def test_gen_isnan(v, isnan):
- assert util.gen_isnan(v) == isnan
-
-
def test_get_fn_list():
fn_list = util.get_fn_list(Agent)
- assert 'reset' in fn_list
assert 'act' in fn_list
assert 'update' in fn_list
@@ -125,35 +76,23 @@ def test_get_ts():
assert util.RE_FILE_TS.match(ts)
-def test_is_jupyter():
- assert not util.is_jupyter()
+def test_insert_folder():
+ assert util.insert_folder('data/dqn_pong_2018_12_02_082510/dqn_pong_t0_s0', 'model') == 'data/dqn_pong_2018_12_02_082510/model/dqn_pong_t0_s0'
-def test_ndenumerate_nonan():
- arr = np.full((2, 3), np.nan, dtype=object)
- np.fill_diagonal(arr, 1)
- for (a, b), body in util.ndenumerate_nonan(arr):
- assert a == b
- assert body == 1
-
-
-@pytest.mark.parametrize('v,isall', [
- ([1, 1], True),
- ([True, True], True),
- ([np.nan, 1], True),
- ([0, 1], False),
- ([False, True], False),
- ([np.nan, np.nan], False),
-])
-def test_nonan_all(v, isall):
- assert util.nonan_all(v) == isall
+def test_is_jupyter():
+ assert not util.is_jupyter()
-def test_s_get(test_agent):
- spec = util.s_get(test_agent, 'aeb_space.spec')
- assert ps.is_dict(spec)
- spec = util.s_get(test_agent, 'aeb_space').spec
- assert ps.is_dict(spec)
+def test_prepath_split():
+ prepath = 'data/dqn_pong_2018_12_02_082510/dqn_pong_t0_s0'
+ predir, prefolder, prename, spec_name, experiment_ts, ckpt = util.prepath_split(prepath)
+ assert predir == 'data/dqn_pong_2018_12_02_082510'
+ assert prefolder == 'dqn_pong_2018_12_02_082510'
+ assert prename == 'dqn_pong_t0_s0'
+ assert spec_name == 'dqn_pong'
+ assert experiment_ts == '2018_12_02_082510'
+ assert ckpt == None
def test_set_attr():
@@ -224,3 +163,19 @@ def test_read_file_not_found():
fake_rel_path = 'test/lib/test_util.py_fake'
with pytest.raises(FileNotFoundError) as excinfo:
util.read(fake_rel_path)
+
+
+def test_to_opencv_image():
+ im = np.zeros((80, 100, 3))
+ assert util.to_opencv_image(im).shape == (80, 100, 3)
+
+ im = np.zeros((3, 80, 100))
+ assert util.to_opencv_image(im).shape == (80, 100, 3)
+
+
+def test_to_pytorch_image():
+ im = np.zeros((80, 100, 3))
+ assert util.to_pytorch_image(im).shape == (3, 80, 100)
+
+ im = np.zeros((3, 80, 100))
+ assert util.to_pytorch_image(im).shape == (3, 80, 100)
diff --git a/test/spec/test_dist_spec.py b/test/spec/test_dist_spec.py
index f1a82f5da..dbc657ffa 100644
--- a/test/spec/test_dist_spec.py
+++ b/test/spec/test_dist_spec.py
@@ -2,11 +2,9 @@
from slm_lab.agent.net import net_util
from slm_lab.experiment import analysis
from slm_lab.experiment.control import Trial
-from slm_lab.experiment.monitor import InfoSpace
from slm_lab.lib import util
from slm_lab.spec import spec_util
import os
-import pandas as pd
import pydash as ps
import pytest
@@ -15,12 +13,11 @@
def run_trial_test_dist(spec_file, spec_name=False):
spec = spec_util.get(spec_file, spec_name)
spec = spec_util.override_test_spec(spec)
- info_space = InfoSpace()
- info_space.tick('trial')
- spec['meta']['distributed'] = True
+ spec_util.tick(spec, 'trial')
+ spec['meta']['distributed'] = 'synced'
spec['meta']['max_session'] = 2
- trial = Trial(spec, info_space)
+ trial = Trial(spec)
# manually run the logic to obtain global nets for testing to ensure global net gets updated
global_nets = trial.init_global_nets()
# only test first network
@@ -28,11 +25,10 @@ def run_trial_test_dist(spec_file, spec_name=False):
net = list(global_nets[0].values())[0]
else:
net = list(global_nets.values())[0]
- session_datas = trial.parallelize_sessions(global_nets)
- trial.session_data_dict = {data.index[0]: data for data in session_datas}
- trial_data = analysis.analyze_trial(trial)
+ session_metrics_list = trial.parallelize_sessions(global_nets)
+ trial_metrics = analysis.analyze_trial(spec, session_metrics_list)
trial.close()
- assert isinstance(trial_data, pd.DataFrame)
+ assert isinstance(trial_metrics, dict)
@pytest.mark.parametrize('spec_file,spec_name', [
@@ -188,11 +184,3 @@ def test_ddqn_dist(spec_file, spec_name):
])
def test_dueling_dqn_dist(spec_file, spec_name):
run_trial_test_dist(spec_file, spec_name)
-
-
-@pytest.mark.parametrize('spec_file,spec_name', [
- ('experimental/hydra_dqn.json', 'hydra_dqn_boltzmann_cartpole'),
- ('experimental/hydra_dqn.json', 'hydra_dqn_epsilon_greedy_cartpole'),
-])
-def test_hydra_dqn_dist(spec_file, spec_name):
- run_trial_test_dist(spec_file, spec_name)
diff --git a/test/spec/test_spec.py b/test/spec/test_spec.py
index 162cf5942..f5bcc0151 100644
--- a/test/spec/test_spec.py
+++ b/test/spec/test_spec.py
@@ -1,10 +1,8 @@
from flaky import flaky
from slm_lab.experiment.control import Trial
-from slm_lab.experiment.monitor import InfoSpace
from slm_lab.lib import util
from slm_lab.spec import spec_util
import os
-import pandas as pd
import pytest
import sys
@@ -13,11 +11,10 @@
def run_trial_test(spec_file, spec_name=False):
spec = spec_util.get(spec_file, spec_name)
spec = spec_util.override_test_spec(spec)
- info_space = InfoSpace()
- info_space.tick('trial')
- trial = Trial(spec, info_space)
- trial_data = trial.run()
- assert isinstance(trial_data, pd.DataFrame)
+ spec_util.tick(spec, 'trial')
+ trial = Trial(spec)
+ trial_metrics = trial.run()
+ assert isinstance(trial_metrics, dict)
@pytest.mark.parametrize('spec_file,spec_name', [
@@ -77,6 +74,8 @@ def test_ppo(spec_file, spec_name):
('experimental/ppo.json', 'ppo_mlp_separate_pendulum'),
('experimental/ppo.json', 'ppo_rnn_shared_pendulum'),
('experimental/ppo.json', 'ppo_rnn_separate_pendulum'),
+ # ('experimental/ppo_halfcheetah.json', 'ppo_halfcheetah'),
+ # ('experimental/ppo_invertedpendulum.json', 'ppo_invertedpendulum'),
])
def test_ppo_cont(spec_file, spec_name):
run_trial_test(spec_file, spec_name)
@@ -176,24 +175,17 @@ def test_dueling_dqn(spec_file, spec_name):
run_trial_test(spec_file, spec_name)
-@pytest.mark.parametrize('spec_file,spec_name', [
- ('experimental/hydra_dqn.json', 'hydra_dqn_boltzmann_cartpole'),
- ('experimental/hydra_dqn.json', 'hydra_dqn_epsilon_greedy_cartpole'),
- # ('experimental/hydra_dqn.json', 'hydra_dqn_epsilon_greedy_cartpole_2dball'),
-])
-def test_hydra_dqn(spec_file, spec_name):
- run_trial_test(spec_file, spec_name)
-
-
@flaky
@pytest.mark.parametrize('spec_file,spec_name', [
('experimental/dqn.json', 'dqn_pong'),
- # ('experimental/a2c.json', 'a2c_pong'),
+ ('experimental/a2c.json', 'a2c_pong'),
])
def test_atari(spec_file, spec_name):
run_trial_test(spec_file, spec_name)
+@flaky
+@pytest.mark.skip(reason='no baseline')
@pytest.mark.parametrize('spec_file,spec_name', [
('experimental/reinforce.json', 'reinforce_conv_vizdoom'),
])
@@ -202,20 +194,10 @@ def test_reinforce_vizdoom(spec_file, spec_name):
@pytest.mark.parametrize('spec_file,spec_name', [
- ('base.json', 'base_case_unity'),
+ # ('base.json', 'base_case_unity'),
('base.json', 'base_case_openai'),
('random.json', 'random_cartpole'),
('random.json', 'random_pendulum'),
- # ('base.json', 'multi_agent'),
- # ('base.json', 'multi_agent_multi_env'),
])
def test_base(spec_file, spec_name):
run_trial_test(spec_file, spec_name)
-
-
-@pytest.mark.parametrize('spec_file,spec_name', [
- ('base.json', 'multi_body'),
- ('base.json', 'multi_env'),
-])
-def test_base_multi(spec_file, spec_name):
- run_trial_test(spec_file, spec_name)
diff --git a/test/spec/test_spec_util.py b/test/spec/test_spec_util.py
index 45ee72d5b..fac8339a2 100644
--- a/test/spec/test_spec_util.py
+++ b/test/spec/test_spec_util.py
@@ -1,4 +1,3 @@
-
from slm_lab.spec import spec_util
import numpy as np
import pytest
@@ -16,81 +15,3 @@ def test_check_all():
def test_get():
spec = spec_util.get('base.json', 'base_case_openai')
assert spec is not None
-
-
-@pytest.mark.parametrize('aeb_list,is_compact', [
- ([(0, 0, 0), (0, 1, 0), (0, 1, 1)], True),
- ([(0, 0, 0), (0, 1, 0), (0, 1, 2)], False),
- ([(0, 0, 0), (0, 1, 1)], False),
-])
-def test_is_aeb_compact(aeb_list, is_compact):
- assert spec_util.is_aeb_compact(aeb_list) == is_compact
-
-
-@pytest.mark.parametrize('spec_name,aeb_list', [
- ('multi_agent', [(0, 0, 0),
- (0, 0, 1),
- (0, 0, 2),
- (0, 0, 3),
- (0, 0, 4),
- (0, 0, 5),
- (1, 0, 0),
- (1, 0, 1),
- (1, 0, 2),
- (1, 0, 3),
- (1, 0, 4),
- (1, 0, 5)]),
- ('multi_env', [(0, 0, 0),
- (0, 1, 0),
- (0, 1, 1),
- (0, 1, 2),
- (0, 1, 3),
- (0, 1, 4),
- (0, 1, 5),
- (0, 1, 6),
- (0, 1, 7),
- (0, 1, 8),
- (0, 1, 9),
- (0, 1, 10),
- (0, 1, 11)]),
- ('multi_agent_multi_env', [(0, 0, 0),
- (0, 1, 0),
- (0, 1, 1),
- (0, 1, 2),
- (0, 1, 3),
- (0, 1, 4),
- (0, 1, 5),
- (1, 0, 0),
- (1, 1, 0),
- (1, 1, 1),
- (1, 1, 2),
- (1, 1, 3),
- (1, 1, 4),
- (1, 1, 5)]),
- ('general_inner', [(0, 0, 0), (0, 0, 1), (1, 1, 0), (1, 1, 1)]),
- ('general_outer', [(0, 0, 0),
- (0, 0, 1),
- (0, 1, 0),
- (0, 1, 1),
- (1, 0, 0),
- (1, 0, 1),
- (1, 1, 0),
- (1, 1, 1)]),
- ('general_custom', [(0, 0, 0),
- (0, 1, 0),
- (0, 1, 1),
- (0, 1, 2),
- (0, 1, 3),
- (0, 1, 4),
- (0, 1, 5),
- (0, 1, 6),
- (0, 1, 7),
- (0, 1, 8),
- (0, 1, 9),
- (0, 1, 10),
- (0, 1, 11)]),
-])
-def test_resolve_aeb(spec_name, aeb_list):
- spec = spec_util.get('base.json', spec_name)
- resolved_aeb_list = spec_util.resolve_aeb(spec)
- assert resolved_aeb_list == aeb_list