| title | date | tags | ||
|---|---|---|---|---|
day13-HTTP框架修炼之道 |
2023-01-15 04:54:09 -0800 |
|

[TOC]
这是我参与「第三届青训营 - 后端场」笔记创作活动的的第13篇笔记。PC端阅读效果更佳,点击文末:阅读原文即可。


可尝试用Gin框架写一个 hello Golang程序,达到以下效果
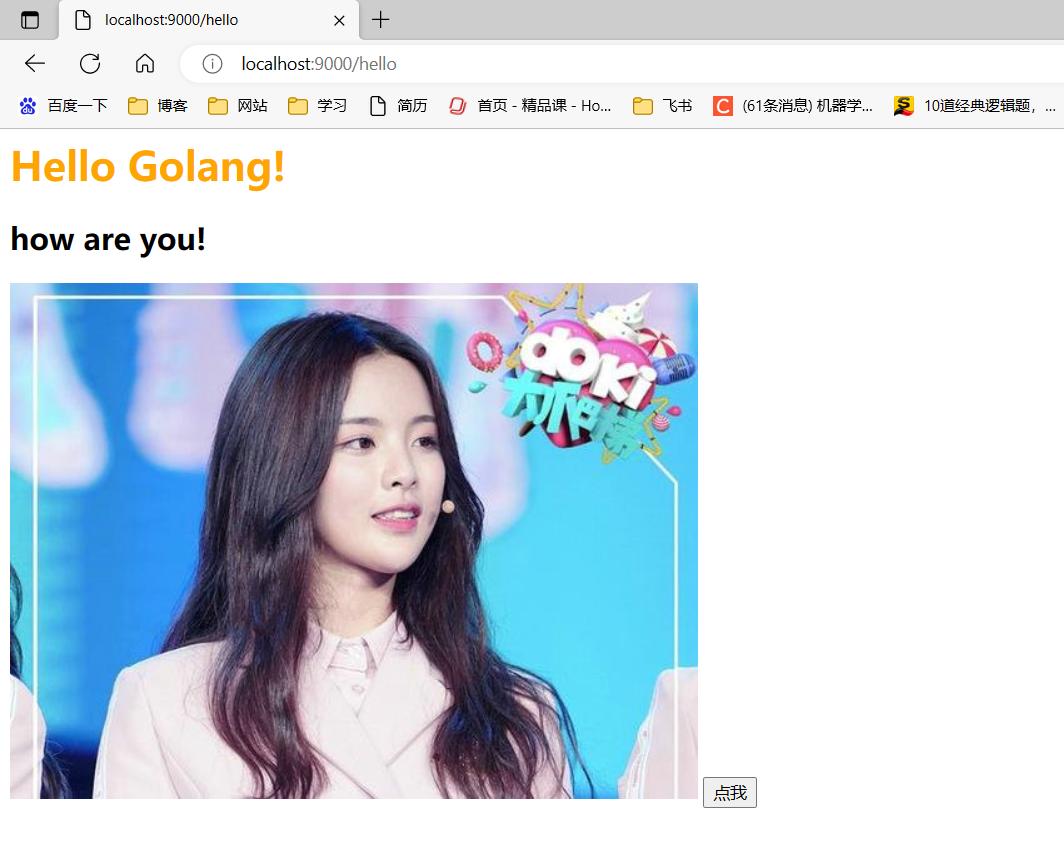
-
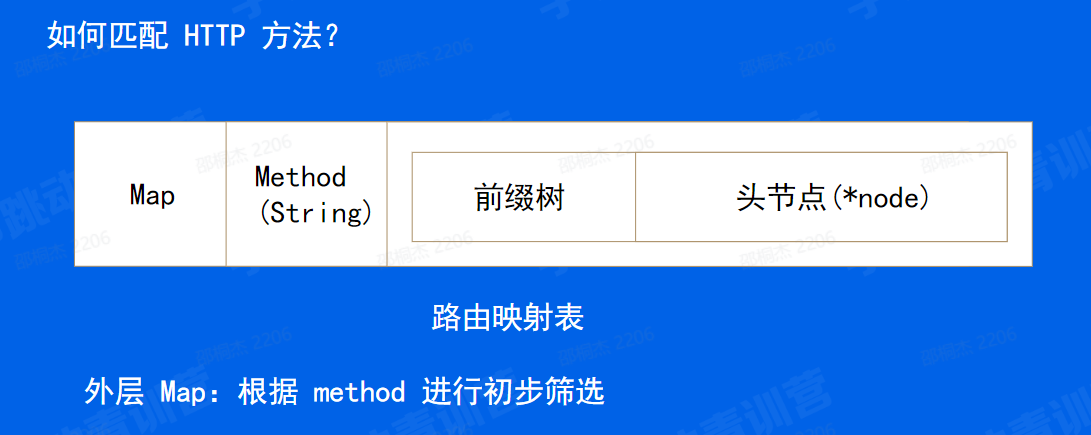
框架路由:根据请求的 URI 选择对应的处理函数。
-
首先匹配 HTTP 方法
-
静态路由: 精确匹配注册的路由,如:/a/b/c、/a/b/d
-
参数路由:
-
命名参数:形如 **
:name**这类叫做命名参数,命名参数只匹配单个路径段:Pattern: /user/:user /user/gordon match(user = gordon) /user/you match(user = you) /user/gordon/profile no match /user/ no match
-
通配参数:形如 **
action**这类叫做通配参数,就像名字所暗示的那样,它们匹配所有内容。因此,它们必须始终位于模式的末尾:Pattern: /src/*filepath /src/ match(filepath = "") /src/somefile.go match(filepath = somefile.go) /src/subdir/somefile.go match(filepath = subdie/somefile.go)
-
-
路由修复:如果只注册了 /a/b,但是访问的 URI 是 /a/b/,那可以提供自动重定向到 /a/b 能力;同样,如果只注册了 /a/b/,但是访问的 URI 是 /a/b,那可以提供自动重定向到 /a/b/ 能力
-
冲突路由:同时注册 /a/b 和 /:id/b,并设定优先级。比如:当请求 URI 为 /a/b 时,优先匹配静态路由 /a/b
-
-
什么是框架中间件,可参考 gin,kratos
- sync.Pool用法
-
C10K Problem
-
Select,Poll,Epoll
-
Epoll ET、LT 区别
-
字节跳动自研网络库 netpoll,netpoll-examples
-
SIMD 是什么,可参考维基百科
-
Improving performance with SIMD intrinsics in three use cases
HTTP背景
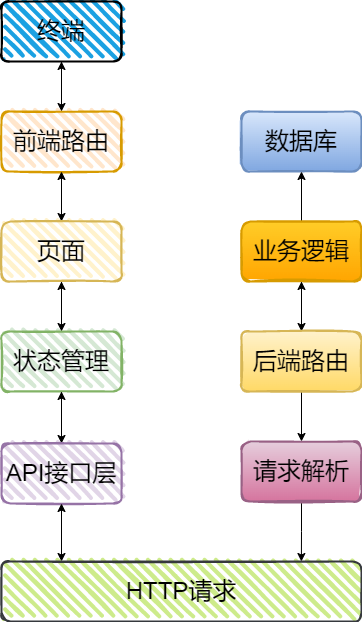
提到 HTTP 协议,大家都非常熟悉了。
HTTP 协议是当今使用最为广泛的协议之一,HTTP是客户端与服务端通信的基础协议。像这一张图就是一个前后端分离的一个流程图了,前后端之间通过 HTTP 请求进行通信。那 HTTP 框架负责的就是对 HTTP 请求的解析、根据对应的路由选择对应的后端逻辑了,也就是图上标出来的这些。
HTTP 在企业实际业务场景中也使用广泛,在字节跳动内部的 HTTP 服务达上万个。这里主要讲HTTP 框架的设计与实现,知道 HTTP 框架为什么要这么做。

- HTTP协议是什么
- 协议里有什么
- 请求流程
- 不足与展望
我们第一个大规模使用的 http 协议版本,它其实是0.9,是从1991年开始的大规模使用。现在到今年的话已经 30 多年过去了。那这么这样一款 30 岁的一个协议,它依然能够这么生机盎然,持续地去迭代,甚至还有一些更新的版本。
HTTP:超文本传输协议(Hypertext Transfer Protocol)
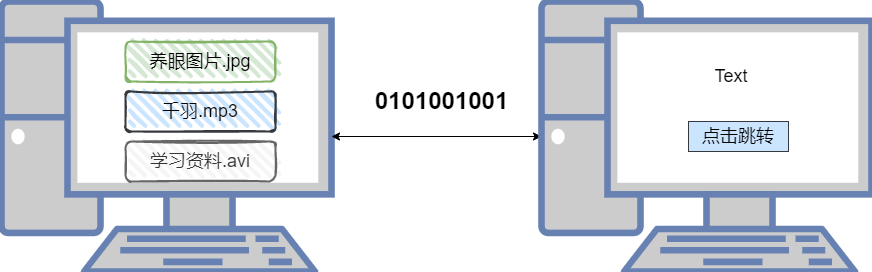
HTTP 协议的话,它就是 hypertext transfer protocol,翻译过来就是超文本传输协议。
text 我理解你加上 hypertext ,hypertext 那超文本到底超在哪里?
可以看到在我们的前辈最早的时候,大家和 PC 交互,其实基本上就是通过 text 没有额外的一些花里胡哨的东西。大家每个人跟自己的电脑对话,就是通过text。然后直到后来我们。村里通网了之后,我们两台 PC 之间,想去互相去分享点什么东西。我们就把两台 PC 通过网线连起来,通过在网线上传输 01 把我们这个 text 进行一个交流和分享对吧。 有了网络之后,其实大家就发现 text 已经没有办法满足我们大家对于这个传输的一个需求了。逐渐地我们有了一些图片以及音乐以及视频,甚至于还有一些超链接的这种需求。那这些资源其实他们就是针对我们 text 这种文本的类型资源的一个扩充,所以叫做 hypertext 然后传输这类资源的这种协议,我们就叫做 hypertext transfer protocol 那非常简单,能很好理解这个协议的一个本质,它就是想传输这类超文本。
那现在知道我们协我们知道协议是什么了之后,我们可以来思考一下为啥需要协议。

协议在网线上传输的都是一些01数据流,需要一定的规则才能让对方理解。那首先,我们需要协议给我们明确一个信息的边界,我们需要明确的知道信息从什么时候开始以及到什么时候结束,我们不能一直接收对吧?
那这就是我们协议的第一个要素,我们需要明确的边界。有了明确的边界之后,其实非常容易想到,我们需要用元数据进行消息的描述。我们描述这个消息它是什么类型的,包括我们刚刚看到的以图片对吧,音频视频以及超链接等等,就可以把它塞到这样的一个消息对应的地方,我们就进行一个传输了,这就是我们为什么需要协议。
一个常见的POST请求在协议层究竟做了什么?
那我们知道为什么需要协议之后,我们可以来看一下 HTTP 协议具体是什么样子的,这里我以一个常见的 post 请求举例
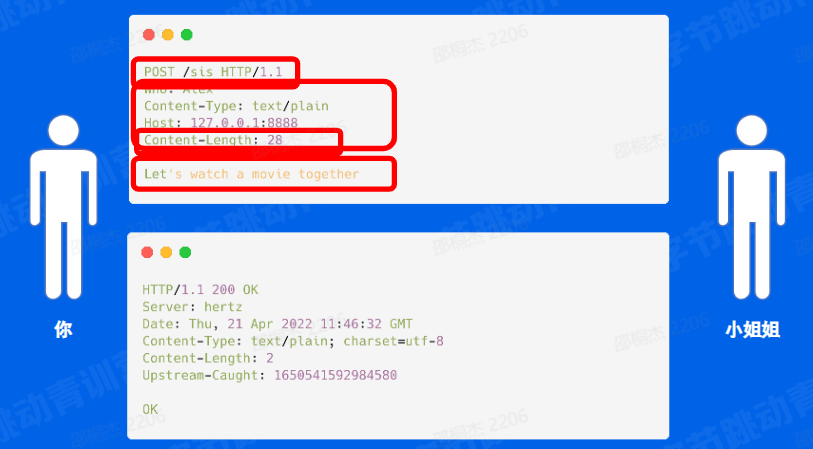
比如我和小姐姐去看电影,我们把它转换成了一个我们真实的一个 http 协议。
你们可以看到这个协议里面的第一行是从 post 开始打头,然后一个空格之后接上的 URL 然后接接下来又是一个空格,然后接上一个 HTTP 1.1,这看着像是一个 HD 当前版本的一个描述。这就是我们协议里面的一个 firstnine,也就是请求行。
那除了除开 firstnine 之后,我们剩下往后看有 5 行都是以冒号风格的一个 KV 对这个就是我们的一个协议的源数据,对应到刚刚我们看到的源数据的 1 描述。然后之后在一个大空行之后,我们可以看到我们真实的一个想说的话,也就是 body部分: lets watch a movie totogether tonight 那之后这个协议结束了。
那我们可以看到那我们的协议的开始,那其实就是我们的这个 post 这一行开始,只要我们对端检测到这一行的内容之后,我们就可以开始接收我们的协议了。
那协议的结束就是我们这个 Let's watch a movie together tonight 最后我们再加上一个换行之后就结束掉了我们的这个协议。
然后同时我们可以看到源数据里面有一个叫做 content Length的一个描述,这个是协议的关键的一个 header 它描述的是我们的 body 到底有多少个字节。所以我们的 server 端就是我们的小姐姐端就能根据这个字节来指定自去接收多少个字节的数据,这样就能拿到我们完整的一个消息了。
OK 这是我们请求的一个真实的场景。那我们小姐姐肯定会给我们一个回复对吧?那回复其实可以看到非常类似,我们的回复其实也是有一个 first line.first line 的话它是由我们的一个 http 1.1 是一个版本开始,然后一个空格,然后 200 是一个状态码,然后最后是一些源数据,最后是小姐姐回复的一个 OK . 这就是小姐姐响应的完整的协议了。
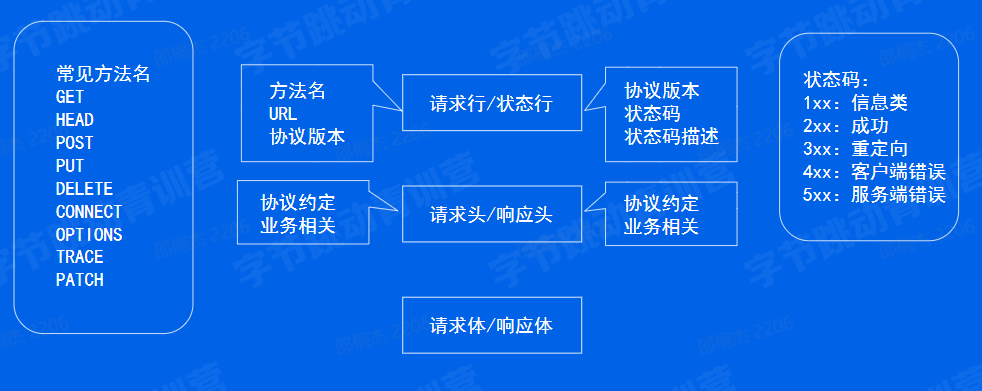
那我们既然看到协议里面有什么了之后,首先是一个请求行,状态行,就是我们对应的 first line. 然后之后就是一些元数据请求头响应头。最后就是一个再再往后的话就是一个请求体响应体。
那针针对我们的请求行。其实刚刚我们也看到了,它是由方法名、 URL 和协议版本组成。
我们常见的方法名就 get,get 就是我们 htp 0.9 里面唯一的一个方法。然后之后我们在 1.0 里面扩充了 header 和 post
然后 1.1 里面又陆陆续续扩充了 5 个,然后从 put 开始到 trace 然后最终到一个patch。patch的话其实它是在 1.1 之后额外新增的一个方法名。但是它因为使用得比较广泛,我们把它列在了这里。
patch 的话其实它的语义跟我们的 put 其实是非常类似的。这里又可以引出八股文: patch 和 put具体有什么区别吗?
-
**patch 的话就是我们的部分更新以及我们的 **
-
put 它的语义是完整地更新,
-
还有一个比较细微的一个区别在这里了(PUT 是幂等的,而 PATCH 不是幂等的)
那状态行的话其实刚刚也看到了,也是一个比较经典的三段式,就是我们的协议版本状态码以状态码描述。 然后接下来是我们的请求头响应头其实也是一个非常清晰的一个划分。我们主要是分为协议约定的相关的。比如说我们刚刚看到的 content 就是我们指定我们的 body 有多少字节,然后以及业务相关的,那就是我们自己定义的需要传输传递的一些源数据了。
最后是响应体…..

那我们把刚刚的那个 demo 用一个例子展示出来,大概是这样的一个场景。
我们在地址栏输入小姐姐的 URI 和请求路径,选择好请求方法。之后呢将我们想说的话,也就是 “小姐姐,咱们一起去看电影吧”,填到 body 当中点发送就可以了。 然后最后我们收到了一个小姐姐的 response 就是 OK 那一个简单的这样的一个回复。那实现一个这样的功能需要几行代码呢,我们一起来看一下。
代码:https://github.com/nateshao/gin-demo/tree/main/http-demo
package main
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
)
func main() {
hertz := server.New()
hertz.POST("/sys", func(c context.Context, ctx *app.RequestContext) {
ctx.Data(200, "text/plain;charset=utf-8", []byte("ok"))
})
hertz.Spin()
}
实现这样的一个功能仅仅需要5行代码,核心呢就是三行。
我们将对应的路由注册到 server 上,选择对应的方法,正如图上所示。接下来实现我们的业务逻辑,回复一个 OK。
那这短短5行代码实现这样的一个功能,其背后肯定隐含了大量的处理,那下面我就来说一下这背后经过了哪些的处理流程。

我们看一下那一次完整的请求发生了什么呢?
首先在业务层,我们业务方的使用框架提供的 API 完成业务逻辑,也就是刚刚的那个小哥哥他想和小姐姐去看电影,那这个就是它的一个业务逻辑。那它的这个逻业务逻辑想要传递给小姐姐,其实还是有很多工作要去做的。
完成了我们的业务逻辑之后,会进入到一些服务服务治理的逻辑。也就是大家经常说的比如熔断、限流等等。
服务治理层,是依托于中间件层的。它对每个请求可以有一些先处理逻辑和后处理逻辑,是和请求级别绑定的。比如说我要打一个计时,在进入业务层之前,我记录一下当前的时间,在业务层执行完毕之后,我们再记录一下业务执行完毕的时间,那这样的话就可以记录整个的业务逻辑的耗时。
对于 client 来说,之后就可以进入一个协议的编解码。协议的编解码层就是刚刚上文里说的协议里有什么编译成一个小姐姐能够看懂的一个协议,
最后是通过传输层传输给小姐姐。那小姐姐这边,她其实处理逻辑也大概如此,但是会多一个路由层,它是根据 URI 选择对应的执行的 handler,比如说我这个好像比如说我这个地方有很多个小姐姐,那我要根据小姐姐的名字去选择我想要约的哪一个?
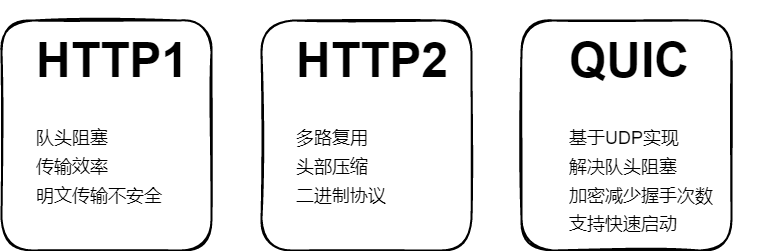
HTTP1:
-
首先对于 http1来说,因为它是基于 TCP 。基于 TCP 的都会有一个这头阻塞的问题,后续的分片必须要等待前面的分片的到来才能继续发送后面的数据,否则的话会一直等待。
-
第二个是他的传输效率很低,就像刚刚我只想传输Let's watch a movie together 但是这里面的无用的信息其实非常的多,存在很多重复的头部什么的。
-
除此之外,http1也不支持多路复用,这个请求没结束之前是不能再发送其他请求的。最后是他的明文传输不安全,也能看到刚刚我和小姐姐的沟通完全就是明文沟通,想隐藏也不行。
HTTP2:
- HTTP2 解决了HTTP1一部分,但没有完全解决。
- 比如说可以多路复用... 二进制协议解析起来更加高效。
- 但是由于 HTTP2 还是基于 tcp 的并没有解决对头阻塞的问题,而且握手的开销也没有优化。
于是出现了 QUIC 在 UDP 就基础上解决得上刚刚才说的两个问题。
- 专注性
- 扩展性
- 复用性
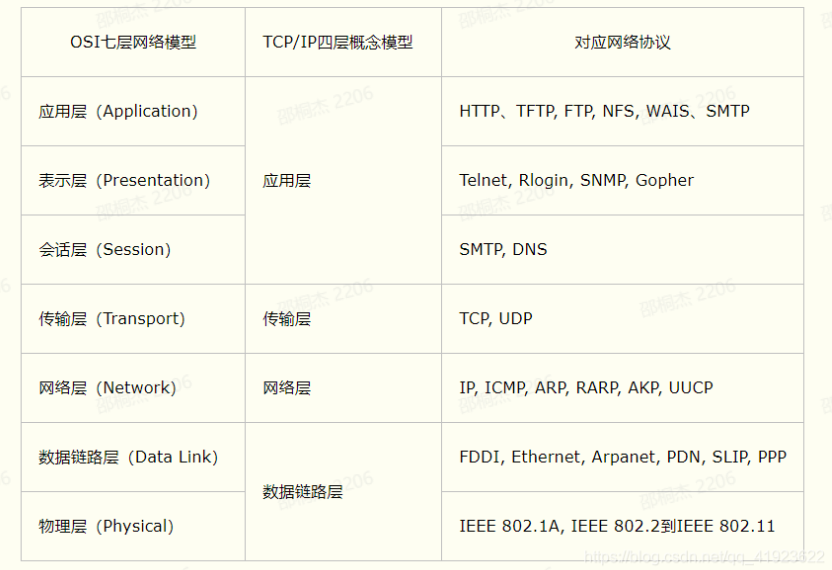
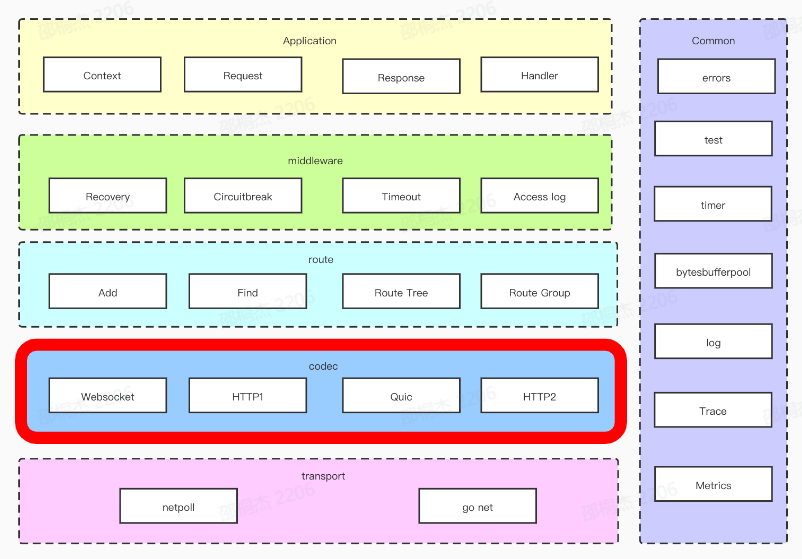
HTTP框架聚焦于第四层之上。分层的设计可以简化系统设计,让不同的人专注做某一层次的事情。
想象一下,我写一个程序还要关心物理设备是否正常,关注网络是否堵塞,TCP是在否超时重传,那这是一件多么痛苦的事情。而有了分层的设计,大家只需要使用下一层提供给上层的接口,专注特定层的开发就可以了,至于这个接口底层是如何实现的我是不用关心的。分层架构可以让我们更容易做横向扩展。
如果系统没有分层,那相关的扩展就会变得不太容易,比如某些Go的 HTTP 框架,到现在也没有支持 h2,那肯定不是它不想支持。最后,分层之后可以做到很高的复用。比如,我们在设计模块A的时候,发现这一模块具有一定的通用性,那么我们可以把它抽取独立出来,在设计系统B的时候使用起来,减少工作量。
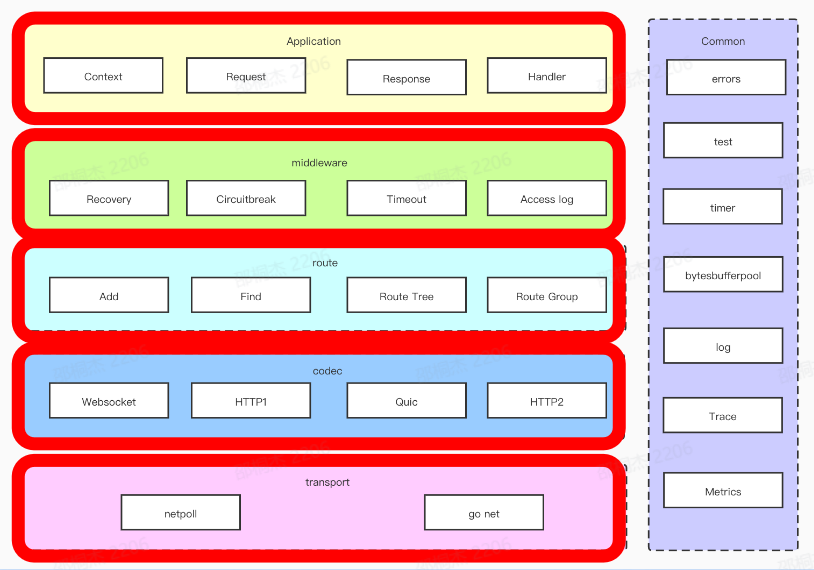
HTTP 框架的设计采用分层设计。在进行分层设计时,我们需要考虑高内聚低耦合,复用性、扩展性等等。 这个是我们进行的一个分层实践。这个架构的话其实从整体上来看的话,我们从上往下总共分为了五层,层与层之前使用接口解耦。
-
那我们从上开始的话就是应用层,这一层的话其实就是跟用户直接打交道的一层,这一层会对请求进行一个抽象,包括像 request response context 等等。这一层也会提供一些丰富的易用的API 。
-
然后下一层就是中间件层,可以对请求有一些预处理和后处理的逻辑,像我们可以打一些 accesslog,打一些耗时的点。其他中间件比如 Reacovery 中间件用于捕获 Panic。
-
之后是我们的路由层,路由层的话就是我们会有一个原生的路由实现来提供大家类似于跟注册、路由寻址的一些操作。这一块的话在我们下一部分会具体进行详细地展开。
-
然后再往下的话就是我们的协议层。我们知道现在 http1.1 已经不能够满足我们所有的需求了,我们需要支持H2、Quic 等等,甚至是在 TLS 握手之后的 ALPN 协商升级操作,那这些都需要能够很方便的支持。
-
最后一层的话就是我们的网络层,不同的网络库使用的场景并不相同。那我们也需要一个灵活替换网络库的能力。 Common 层主要放一些公共逻辑,这一部分可能每一层都会使用。

一个切实可行的复杂系统势必是从一个切实可行的简单系统发展而来的。从头开始设计的复杂系统根本不切实可行,无法修修补补让它切实可行。你必须由一个切实可行的简单系统重新开始。 ---盖尔定律
接口设计时考虑的点:设计之前可以参考一下业界成熟的方案,做好充分的调研,结合自己的场景,先设计出一版可以使用的接口,之后如果有需求/瓶颈再慢慢优化,也是OK的。
易用性首先是体现在我们要提供一些合理的 api。
列了一些在设计 api 时需要考虑的点。
- 可理解性:使用主流的概念,如 ctx.Body(), ctx.GetBody(),不要用 ctx.BodyA()
- 简单性:常用的 API 放到上层,误用/低频 API 放到下层,如 ctx.Request.Header.Peek(key)/ctx.GetHeader(key)
- 可见性:最小暴露原则,不需要暴露的 API 不暴露,可以抽象为接口。
- 冗余性:不需要冗余或能通过其他 API 组合得到的 API 。
- 兼容性:尽量避免 break change,做好版本管理。
中间件需求:
- 配合Handler 实现一个完整的请求处理生命周期
- 拥有预处理逻辑与后处理逻辑
- 可以注册多中间件
- 对上层模块用户逻辑模块易用
洋葱模型
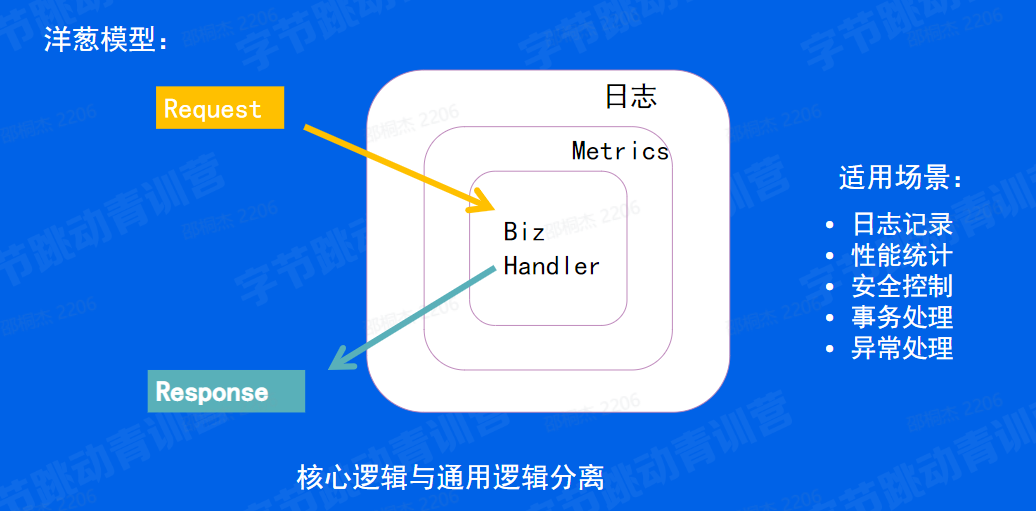
洋葱模型是一个中间件的典型模型。如上图,我们有请求过来。
首先我们先一层首先经过一个日志的日志中间件的预处理之后经过 metrics 中间件的预处理,在处理完了之后我们再进行执行一个真正的业务逻辑。
那最后我们再退出业务逻辑之后,我们会有一个后处理。首先经过一个 metric 中间件的后处理,最后是经过一个日志中间件的后处理。然后再将真正的响应再将一个完整的响应返回给用户。那这个逻这这个的中间件的核心它是能够将核心逻辑与通用逻辑分离。那它的适用的场景包括说像日志记录、性能统计、安全控制、事务处理、像异和异常处理等等。
我们来举个具体点例子,比如说我们想打印出来每个请求的 request 和 response 那平时如果没有中间件,我们需要怎么办呢?
举个栗子:打印每个请求的request和response
| 没加中间件之前 | 加中间件之后 |
|---|---|
 |
 |
| 需要在每一个业务逻辑的代码当中去加上头和尾加上两句话去打印出来我们的一个 request 和 response 那我们有了中间件之后, | 既然要实现预处理和后处理,那这个就很像调用了一个函数。路由上可以注册多 Handler,同时也可以满足请求级别有效,只需要将 Middleware 设计为和业务和 Handler 相同即可。那这样是不是第5行的代码不就不用区分是中间件还是业务逻辑了,统一为直接调用下一个处理函数,我们抽象为 Next() 方法。 对服务治理易用 |
-
既然要实现预处理和后处理,那这个就很像调用了一个函数
-
路由上可以注册多Middleware,同时也可以满足请求级别有效,只需要将Middleware 设计为和业务和Handler 相同即可。

-
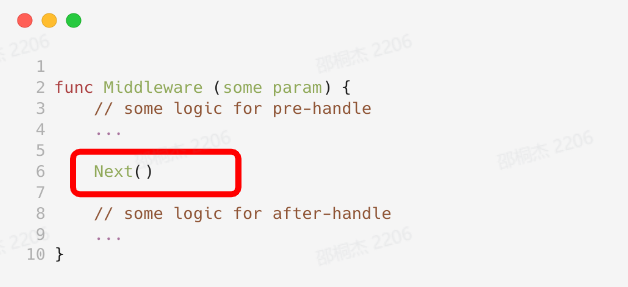
用户如果不主动调用下一个处理函数怎么办?
func Middleware( some param) { // some logic ... }
如果用户只有预处理逻辑,没有后处理逻辑怎么办呢?比如只想完成一些初始化。考虑到用户真正希望执行的是业务逻辑,那我们可以主动帮用户调用一下之后的中间件。
func (ctx *RequestContext) Next() { ctx.index++ for ctx.index < int8(len(ctx.handlers)) { ctx.handlers[ctx.index]() ctx.index++ } }
核心:在任何场景下index保证递增
-
出现异常想停止怎么办?
func (ctx *RequestContext) Abort() { ctx.index = IndexMax }
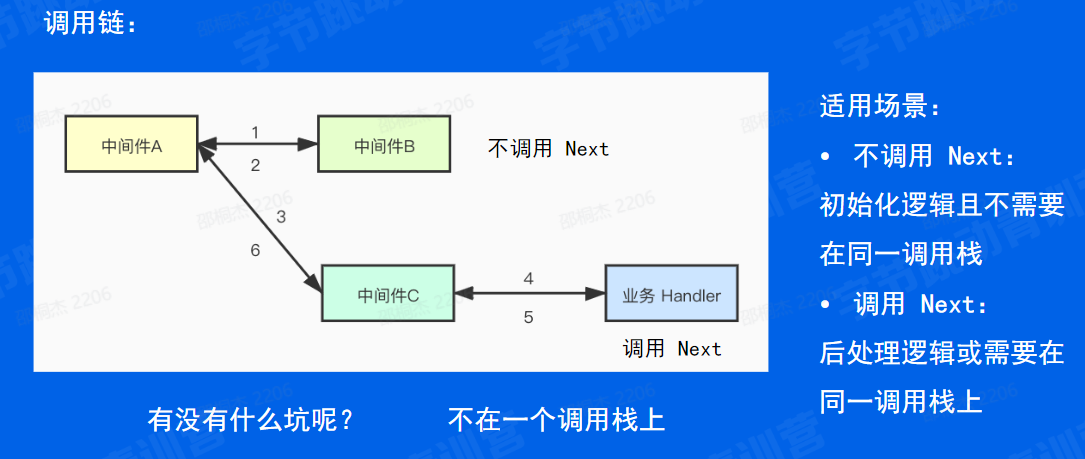
最后讲一下调用 Next 和 不调用 Next 的适用场景。我们看一下这张图,这是一个一次注册了 ABC三个中间件和最后一个业务 handler 的调用链图,其中 B 中间件中不调用 next 对,中间件 C 调用 next 。那我们的调用顺序就是首先中间件A去调用中间件B,返回了之后中间件A去调用中间件C,然后中间件C去调用业务Handler,最后返回,也就是按照图上的标号调用。
那我们可以想一下,这会不会有什么坑呢?
思考:有没有其他实现中间件的方式?
- 既然要实现预处理和后处理,那这个就很像调用了一个函数。路由上可以注册多 Handler,同时也可以满足请求级别有效,只需要将 Middleware 设计为和业务和 Handler 相同即可。
- 那这样是不是第5行的代码不就不用区分是中间件还是业务逻辑了,统一为直接调用下一个处理函数。 对服务治理易用

框架路由实际上就是为URL匹配对应的处理函数(Hand lers)
-
静态路由: /a/b/c、 /a/b/d
-
参数路由: /a/: id/c (/a/b/c, /a/d/c)、 /*all
-
路由修复: /a/b <-> /a/b/
-
冲突路由以及优先级: /a/b、/: id/c
-
匹配HTTP方法
-
多处理函数:方便添加中间件
-
…
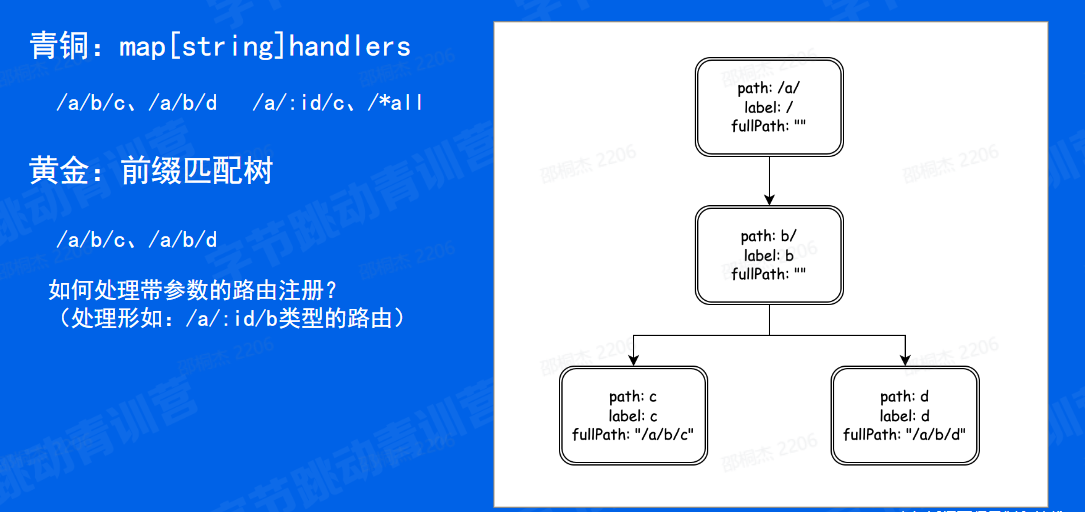


比如自定义路由:自定义路由:ANY + /*all,正则路由:NoRoute�在对上层易用方面,多处理函数。如果要是没有参数路由和路由修复,那直接一个 map 处理就行。青铜段位:map。
思考:如何查找路由?
刚刚我们讲了路由树的构建规则,应该如何查找路由呢。
查找路由的时候需要考虑到优先级匹配的问题,回溯的问题,因为静态路径已经走到一个子树,那怎么回溯到另一颗子树。
再比如路由修正,/a/b -> /a/b/
- 明确需求:考虑清楚要解决什么问题、有哪些需求
- 业界调研:业界都有哪些解决方案可供参考
- 方案权衡:思考不同方案的取舍
- 方案评审:相关同学对不同方案做评审
- 确定开发:确定最合适的方案进行开发
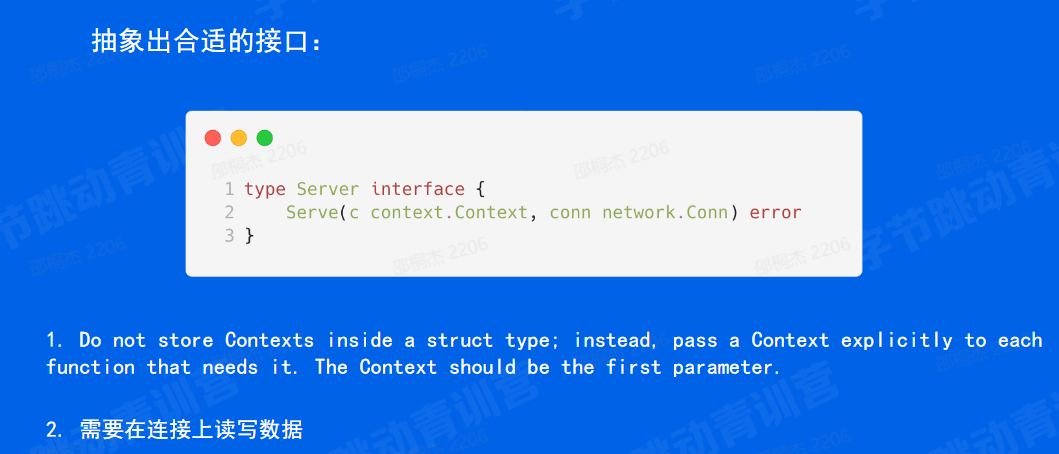
第一个是对协议的扩展,对 h1h2 QUIC 等等。
首先他其实要实现一个 serve 的一个接口。他这个 server 的接口他要传入一个标准的context 这也是和 Golang 的设计思想相吻合的。
第二个,再一个是肯定要把连接传进来,因为我们要往连接上读其他的应该是不再需要了。数据、写数据对吧?那其他的还有没有呢?那我们的返回值是一个 error。那也说只要是任何的一个协议,只要实现了这样的一个 serve 的接口,就可以注册到我们的框架当中来。

BIO和NIO


那有了 epoll 之后,C10K的问题就可以解决了吗?
我们在这里设想一个场景,就比如说你打客服电话,然后比如说,我去打一个客服电话,客服跟我说问我身份证号是多少,那这时候我忘了身份证号多少,我就必须说你等一下,我去找一下这个身份证,但我又没找着,那这个客服是不是占线,那占线的话他就什么都做不了,然后并在这里占住了,他等不下去了,就等到了超时。那这种编程模型在互联网界就叫 block io,简称 bio
我们可以看下面这段代码,这段代码是go一个经典的connection处理,我们在一个 go function 里面维护一个 listener 那它 listener 每次 accept 获取一个连接之后,我们会开一个 goroutine 去单独处理它。这 goroutine 行为应该是先去读取数据,读取完之后然后处理业务逻辑,然后再把这个response写回去。这是一个比较经典的 go 的写法,那它就是一种 block io 编程模型。
因为假如说你在读数据的时候读到了一半,它就读在这里了,它啥也干不了。那有没有解决这种办法的方式也比较简单,我们在中间引入一种通知的机制,就是当他数据有一半的时候,我让客服小姐姐也去干别的事情。那当它后续把整个包都已经发完的时候,我们再去通知他去处理,这样的话就不会阻塞。是在互联网界就是non block IO 的一种编程模式,它就是非阻塞的。
我们可以看一下刚才那段伪代码改成这段伪代码之后是什么样子,就是上面我们在第一个go function里面还是维护这个连接, accept 但是每次我们拿到这个连接之后,我们把它加到一个监听器里面,比如说 add 这个链接,然后我们在另外一个部分里面去轮询这个 monitor 就是监听器,我们搜索可读的连接数。因为这里 monitor 它已经知道有数据了,但我们这个服务方式去执行的时候可能是 read 这时候就能拿到完整的数据并处理,然后再返回,这个时候整个流程是没有阻塞的。
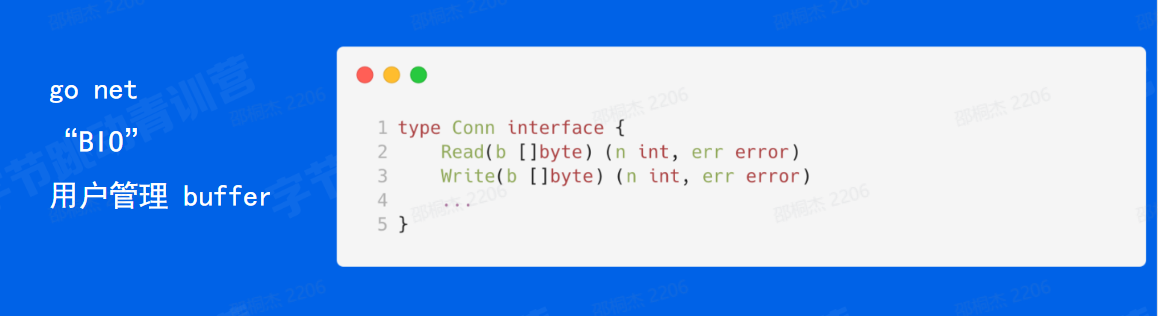
在用户态来看。 那 go net 呢是由用户管理的 buffer,这两个接口都是传入 buffer,进行读或者写,那它本身是不管理buffer的。
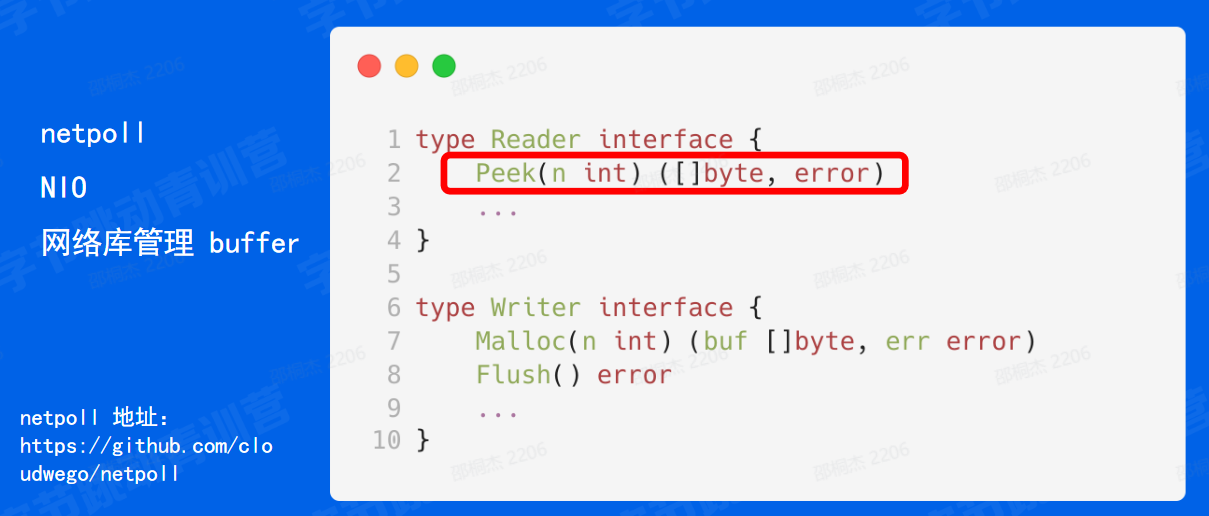
netpoll是字节内部自研的网络库,目前已经开源。netpoll:https://github.com/cloudwego/netpoll
type Conn interface {
net.Conn
Reader
Writer
}
-
首先我们希望能够存下全部的 header 那如果要是说我们因为 http它的头部它是没有 length 是不知道长度的,所以我们需要存下全部的 header 才能够进行一个解析。
-
那第二个是我们希望能够减少系统调用的次数,系统调用户涉及到内核态和用户态的切换,这部分的开销还是比较大的。
-
第三是我们希望能够复用内存,能也是提高一下资源的使用率。
-
最后是我们希望能够多次读,这部分主要体现在对 header 的处理,对于一个超大的 header 我可能第一次读不完,但是我并不知道这个 header 是不是完整的,所以说我们在那只有解析的时候发现解析失败了,那我们才知道说当前这个 header 是不足够的,那下一次我们希望说还能够从头地进行一个解析。
下面我给大家举两个例子,
- 一种是我 header 有100字节,整个 request 有150字节,那我一次把所有的数据全读了出来,那针对这种场景,对于 body 的50个字节,希望不需要将它拷贝到另一个 buffer 中;
- 第二个场景是我 header 超大,比如说100字节,可是第一次读只有50字节。那我希望接下来到来的数据不会再分配一个新的,大的 buffer,然后将之前读的数据拷贝进去。
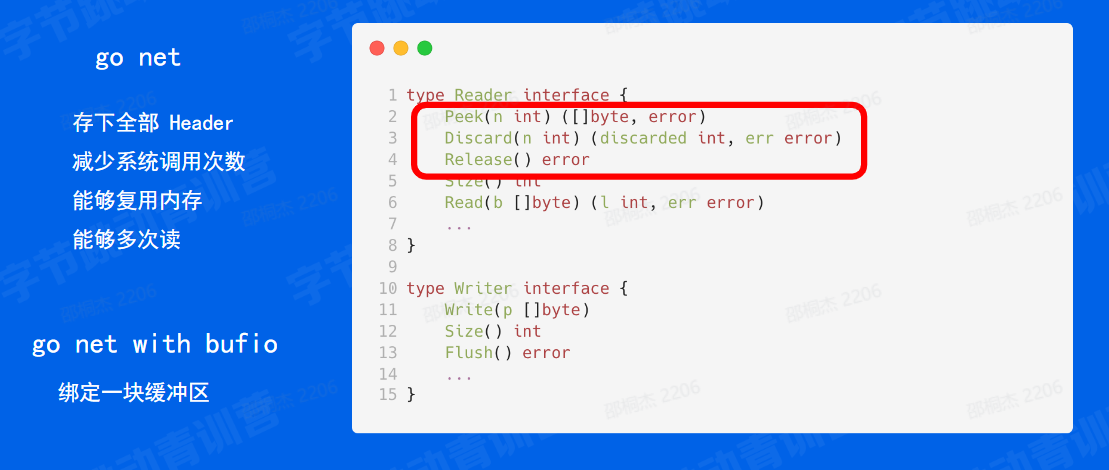
那基于此,我们可以对勾在勾标准库的接口上面封装一层 buffer 说也就是用一块用一个常用的一种优化手段。就是绑定在这个连接上面,绑定一块缓冲区。
那根据我们在内部的一个调研,也发现大部分的包都是在 4k 以下的,所以我们可以绑定一块大小为 4k 左右的一个缓冲区,这样对内存的压力也不是很大。那这个还那我们再设计接那我们这个再设计接口。
首先需要一个我在读的时候让读指针不动,我下次还能够在这里进行读,也就是 Peek;以及说我们既然就能够让读指针不动,那我们就需要一个接口,让读指针进行一个移动,也就是 Discard。最后呢我们还需要回收这块内存,希望下一次请求能够复用之前的空间,也就是 Release 接口。
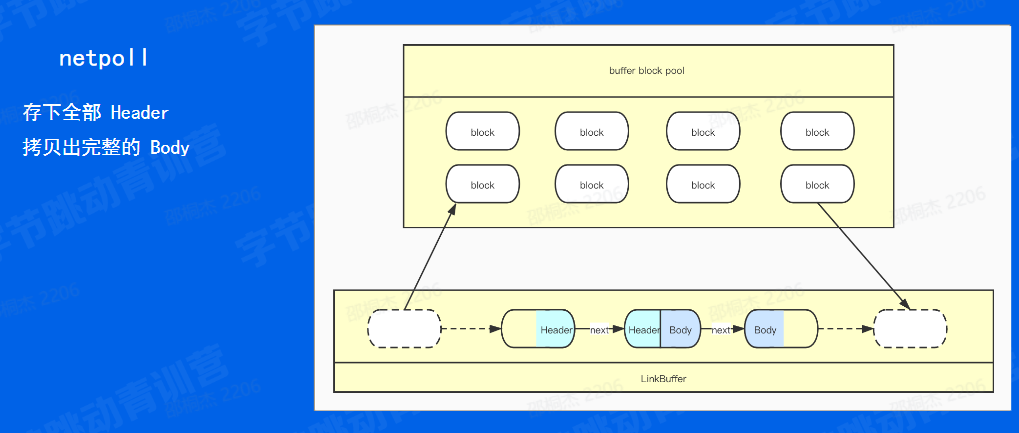
ET 会被动刷数据。 复习一下之前讲到的 linkbuffer。通过查找尾部("/r/n/r/n") ,判断Header的完整性 对于 netpoll 我们是希望能够存下全部的 header
那第二个我们是希望能够拷贝出完整的 body 那对于 netpull 这种网络库管理底层,由于 netpoll 为了减少锁的竞争,采用了一个链表的设计方式,实现一个无锁化。那这样一个链表带来的问题就是它可能会存在一个跨节点的问题。
那比如说那比如说像下面的这张图,我们的 header 可能分布在两个节点当中,我们的 body 也可能分配在两个节点当中。那这样的话如果我们要进行一个使用,我们效我们就需要再分配一块足够大的 buffer 然后将两部分的 header 拼到一起,返回给框架来进行一个解析。那既然如此,我们为什么不将这个足够大的 buffer 直接分配到下层的底层的节点当中呢?也就是像下面这样一种情况,那我们可以根据 D 此请求当中的最大值来分配一个足够大的 buffer 来保证说所有的 header 和 body 都分配到同一个节点上。
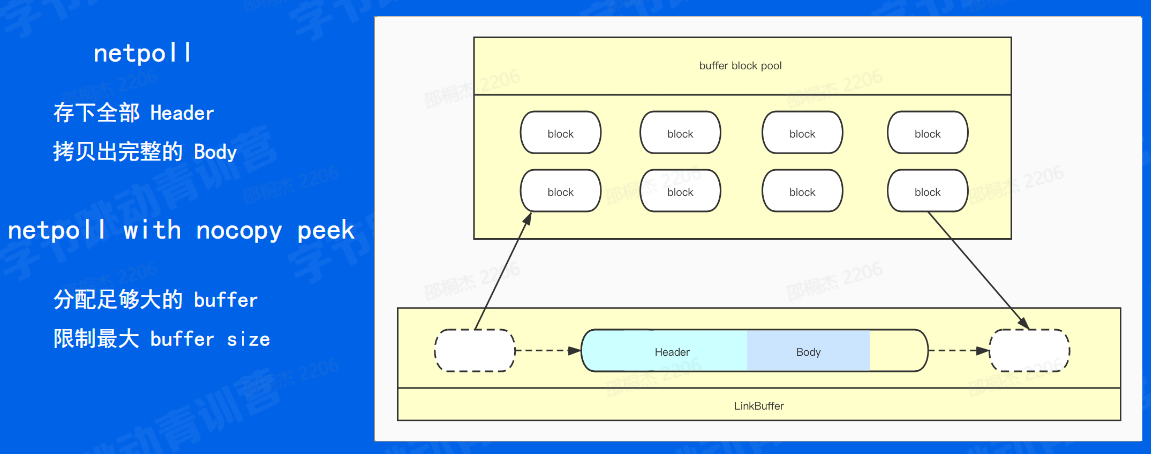
ET 会被动刷数据。 复习一下之前讲到的 linkbuffer。通过查找尾部("/r/n/r/n") ,判断Header的完整性 计算历次最大的包大小分配时,分配足够大的 buffer
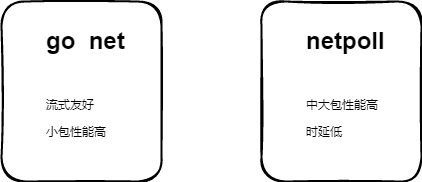
用户管理 buffer,超大包友好;
小包场景(4k)以下不涉及到内存分配与回收,性能高 中大包场景(4k以上)减少系统调用次数;时延低
找到Header Line 边界:\r\n
先找到\n再看它前一个是不是\r
func index(b []byte, c byte) int {
for i := 0; i < len(b); i++ {
if b[i] == c {
return i
}
}
return -1
}说到了针对协议的所做的网络库的优化,那我们现在视线从底层移动到上层。刚刚也说了,http协议需要找到边界才能够判断它是完整的。
那我们现在来看看上面讲的知识,我们需要找到的一个边界就是\r\n,每一个headerline的结束是\r\n,如果连续两个 \r\n\r\n 的话就说明 header 读完了。
然后字符串匹配算法有很多种,比如kmp,bm。这些算法也是可以了。快不快呢?当然不是最快了。这些算法针对的是任何两个字符串,没有其他条件了,至少需要进行一次预处理。
那我们来看一下针对我们的http协议,他每次只需要匹配两个字符,并且都是\n的前面都是\r,杀鸡焉用宰牛刀,针对这种有特征的数据,那我们只需要找到 \n,再去判断\r就OK了,起来这样的复杂度其实是只要扫一遍就ok了。
具体的代码我也在下面写了出来。咱们现在思考一个问题,这个找到边界能不能更快呢?可能有一些同学说,那我这个算法再快,也要是O(n)的吧。这个算法的复杂度,我是没有想出来一个更好的解决办法。不过咱们上过一门课,叫计算机体系结构。这门课里面讲了simd。大家在刚听到这门课中讲SIMD的时候,反应跟我当时是一样的,一脸懵逼,完全不知道有什么用。在这里,SIMD就可以派上用场。
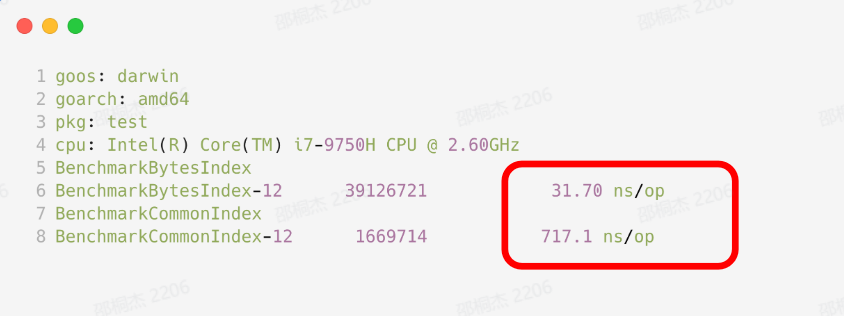
SIMD(Single Instruction Multiple Data)指令集,指单指令多数据流技术,可用一组指令对多组数据通进行并行操作。对于咱们的这个场景之前,咱们之前来说是一个一个进行相比。那咱们这次呢咱们可以多个相比,比如每次比16个。那自然效率就高了。那可能有一些同学说,那我不会写汇编,那怎么办呢?或者说这个汇编的难度太高了,那怎么办呢?不要急,咱们go语言呢,他官方已经为我们支持了SIMD技术,我们只要调用 bytes.Index() 函数,在满足条件的情况下,会自动使用 SIMD 指令集进行加速。
这里我也把相关代码链接贴了出来,感兴趣的同学可以看一看。什么,有的同学说例子太少? 这里有一个使用 SIMD 加速的 json 解析库 sonic,也可以了解一下,编解码速度已经能够达到和pb是同一个数量级的了
Sonic:https://github.com/bytedance/sonic
switch s.Key[0] | 0x20 {
case 'h':
if utils.CaseInsensitiveCompare(s.Key, bytestr.StrHost) {
h. SetHostBytes(s.Value )
continue
}
...
}针对协议相关的Headers 快速解析:
- 通过
Headerkey首字母快速筛除掉完全不可能的key - 解析对应
value到独立字段 - 使用
byte slice管理对应header存储,方便复用
请求体中同样处理的Key:
User-Agent、Content-Type、Content-Length、 Connection、Transfer-Encoding
再一个例子的话是说我们的 header 解析。
header 解析:那这个这里面的话其实大家可以看到我们针对我们图上的这个 header 其实也就是是叫做 host 的一个 header,我们在解析这个 host 这个 header 的时候,我们首先是对它的首字母进行的一个筛选,我们通过首字母直接筛选掉那种首字母,不为 H 的这一类 header 然后如果为 H 我们才会进入到我们真正的一个解析过程当中。这就已经筛掉了 25/26 了对吧?如果通过字母来判断的话,应该是分成筛掉了 26 个字母里面的其他 25 个字母的可能性。通过这个来进行一个加速。然后同时我们针对这种 协议中的高频关键 header,像 host 这种,我们直接额外把它开辟的一块成员变量我们来直接把它存储了。
内存存储:那我们之后再需要用到这个 host 的时候,我们直接通过点 host 就能拿到它对应的一个 value 了。这就是我们针对于我们的特异化的这些 header 做了一个特异化的操作。 然后我们同时在管理的时候,我们可以看到我们是通过 byte slice 的方式来管理的,我们通过 append 操作去把这个 slice 给它填充起来。然后这个的目的其实就是为了我们更方便地去进行一个内存的管理。因为我们的整体的这个 header 的话,其实它会去做一个完整的复用,就包括我们请求结束之后,下一个请求来的时候,我们其实用的内存空间,一就是这个同一块内存空间,不会去额外地去做更多的一些内存分配了。

这就是header 解析的一个特异化处理的一个优化,我们可以看我们整体的一个取舍。那我们取部分的话我们说我们针对我们的协议的核心字段我们进行了一个加速。然后我们同时我们采用 byte slice 而不是 map 来存储我们的 header 然后我们可以高效地去管理内存,方便我们每一次请求之间去复用这块内存。
取和舍
取:以及我们额外把这些 KV 我们把它解析到特定的成员变量中,保证我们去读取的时候是第一时间去读到的。
舍:那我们有取,那肯定就有些舍对吧。我们舍掉了是什么呢?
- 其实舍掉了就是对于普通的这些 header 我们没有做额外的特殊处理,因为那这种处理的话也是一个需要消耗计算资源的操作,可能会对性能造成影响。那我们对于普通的 header 的话是需要在真正使用的时候才知道是否存在对应的 key 这个时候是就去进行一次真正的一个解析。
- 然后第二个的话就是大家可能感到疑惑,说我们为啥没有一个类似于
map的结构来存储这类的 KV 那其实就是刚刚提到的我们因为 map 本身它在内存管理这一块的话没有一个比较非常好的一个实践方式,它内部的一些内存是通过自己的一些算法来维护的。所以我们没法是通过像我们的byte slice这样的一个方式来高效地去管理这块存储这就是我们舍掉的一些东西。
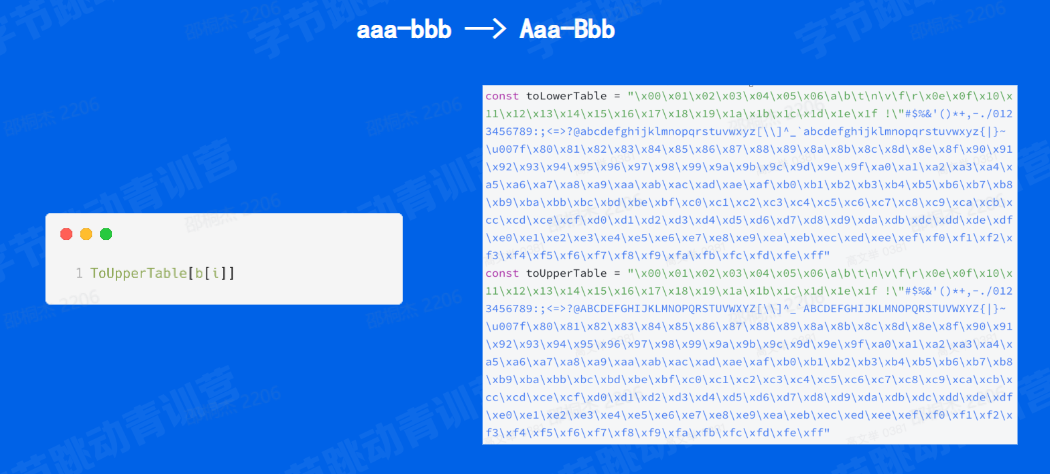
刚刚提到 header key 规范化,它是一个什么概念呢?可以看到我们这里提到了是一个问号,问号,我们转换成 A 小写小写杠 B 大写 B 小写这一类。
转换的话其实就是我们所谓的 header key 的一个规范化,其实它就是想把我们的 key 转换成这种类似于手这么大写的一个字符串,然后包括有一个中划线之后有一个接着首字母也会大写,这样就是我们的一个规范化。
那我们在处理这类需求的时候,我们也是用了一个非常取巧的方式,可以看到我们的实现在我们左边,然后右边的话是我们的自己定义的两张表。这两张表一个叫做 to lower table 顾名思义就是把字母转成小写 table ,第二个表就是把 to upper table 那就是把字母转成大写 table
那这两张表怎么用呢?其实是非常简单。我们可以看到左边我们直接把我们的对应的字母传递到我们的这个表里面来。这个表其实它就是一个 byte 数组,那我们的字母其实也是可以理解为是一个 byte
那我们把 byte 传递到我们的这个表表格里面来,然后查询到对应的返回,就是我们想要的一个大写或者小写了,那相当于我们直接是查表的方式,这个时间复杂度非常的低,应该是个 big o1 的一个查询方式。 这就是我们在做 header key 的规范化的时候做的一个优化。
取和舍

同样这一块它也是有取舍的。
取:那取的话是利用了一个空间换时间的方式,我们把对应需要转换的这些字符我们能把它存起来了。然后通过这个带来一些高效的转换效率。然后对于原生的我们那 Golang net hdp 内部的实现,其实说它是针对于这种需求的话,它首先去判断是否是一个字母,然后针对字母的话,它再去做一个额外的字母的一个转换。就是针对他在ascii码表里面定义的一个是差值去进行加或者减这样差,这样完成它整个的一个规范化。那我们相比它们规原生库的实现的话,我们这种取巧的方式我们带来了近 40 倍的提升。
舍:那同样我们的舍的话,其实刚刚也可以看到我们有一些额外的内存开销。那其实我们目前的一些部署的一些场景的话,我们的内存资源其实相对来说比较充足。针对刚刚的开销已经算是可以忽略不计了,所以这个也是舍得非常小。然后第二点的话就是我们舍掉了一个我们叫做变更,我们没法去快速地去变更,因为我们每次要变更这个列表还是一个硬编码的列表,然后我们得需要去改我们的框架代码。
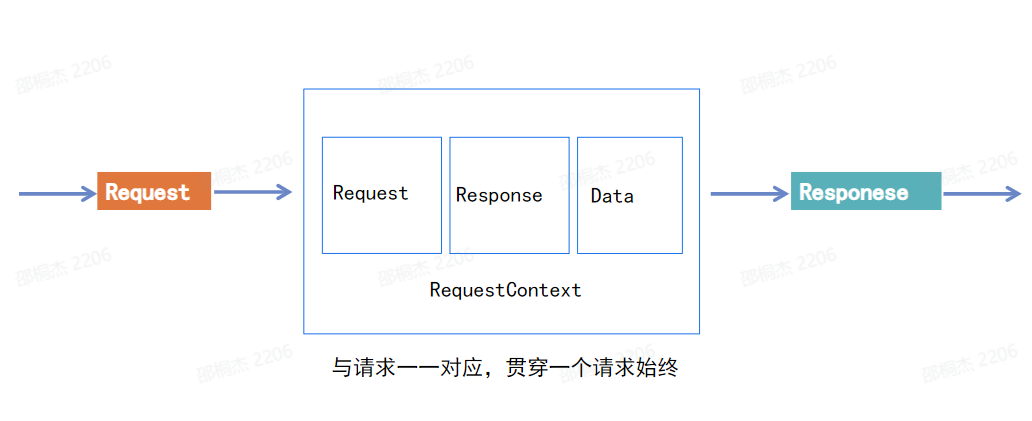
这是我们的一个热点资源池化设计,这个也是我们在做 Golang 开发过程中一个比较熟悉的手段。
首先的话其实我们可以看到背景其实我们一个请求请求进来之后,我们有一个叫做 requestContext 的一个资源,是需要去贯穿这个请求的一个完整生命周期,包括这个请求需要的资源像 Request、Response、conn 等等,直到我们的一个响应回包给我们的 client 那这一块的话其实就伴随着说我们与请求是一一对应的。在高并发场景的话,那这块内存的分配以及释放对 GC 是一个非常大的一个压力。

对于我们的这个这种场景的话,我们有一个叫做 context request context 池,我们把这个 request 放到池子里了。
然后我们请求来的时候,我们池子里取出来一个,我们做一些初始化,然后把它进行一个 response 的一个返回,之后我们处理完又把它放回去。按这个看起来是一个比较有意思的一个做法,就是我们这大家就共用一个池子里的资源,那这样的话就可以明显地减少我们整个 GC 或者是一个 runtime 的一个压力。
取和舍

取和舍
取:可以看到我们有了一些内存分配的一个次数减少了,然后我们的复用能力也提高了,机制压力相应的就降低了,那性能就得到了提升。
舍:那舍掉的话其实就是我们再额外放回这个 request 刚才是到池子里之前的话,我们需要做一些复杂的 reset 操作,因为这个这块内存直接会被下一个请求去复用。那我们不做这类似 reset 初始化操作的话,那可能会有一些额外存在的值会对下一个请求造成一些影响。第二点的话说我们超出了一个请求生命周期的这个 request context 它就变得不再可靠。那我们既然都把它放回池子里,那里面的数据不保证在一些请求生命周期之外也是可靠了。那等这两个问题的话其实带来的就是我们在一旦出现这种类似于数据不一致的问题的时候,我们的定位难度也非常的大,这就是我们在这个设计里面舍掉了一个东西。那其实针对这个问题的话,其实我们内部已经在做一些更优化的一些设计,来避免这种数据不一致造成的一些问题。包括我们刚刚提到的在我们的应用层有一个专门的 context 模块,这一块的话这块设计的话之后也会有我们的一个更新之后,我们会以一个新的 feature 提供给大家。
目的:
- 追求性能
- 追求易用,减少误用
- 打通内部生态
- 文档建设、用户群建设
性能:我们刚刚做了那么多都是为了什么,都是为了性能,为了能够支持更多的 feature。这个也是和我刚进字节跳动的时候,包括说很多刚进字节跳动的想法,包括说跟可能跟很多同学的想法都是一样的,性能就是王道,性能高就是牛逼。一个框架好不好完全就等于一个框架的性能好不好。确实性能是属于一个非常非常重要的。我在刚来的时候也做了一些关于性能优化方面的一些实践,当然现在也在做嗷。但是我后面慢慢地发现,除了追求性能之外,还有其他很多的工作也是要做的这部分工作的,这部分的一些优先级甚至要远大于提高性能方面的优先级。
追求易用,减少误用:我们就来说一下进来之后的第二个在做的东西,就是我们要对一个框架要追求易用,减少误用这几个字。就是我们在设计框架的时候,如果追求性能,因为往往性能和易用性它两个是一个矛盾的东西。我不能说我小孩子全做选择题,我全都要什么,性能又高,可扩展性又强,还非常的好用。那这个框架设计出来。确实非常有难度的。那所以说我们在设计当中就会有面临着非常多的取舍,那我们舍掉了就可能是一些追求好用的一些东西。比如说我在刚刚讲到对于 header 的优化的时候,那我们其实就舍掉了一个非常好用的 map 的这样的一个结构。那再比如说我们刚刚对于 requestcontext 进行池化的时候,那我们就抛弃我们就舍弃了它不能够在请求生命周期之外的一个不能再请求生命周期之外使用的这样的一个功能。那这样的话我们减少了应用性之后,我们发现很多业务,很多在使用方,很多做业务的同学在使用的时候就不能够正确地使用框架。
先别说性能怎么样,你可能说他连写出来正确的代码都是一件非常困难的一个事情。而且说因为你的问题,很多时候它并不是说不能通过编译这种简单地说我修一下语法错误,而很多的错误它都是一些在高并发或者说或者是并发问题,或者说数据不一致问题。那这样问题又非常非常的难查。那导致说我可能线上造成了一些很造成了一些很大影响之后我才发现说这个地方原来是有 bug 的,但是这个 bug 我还不知道是为啥。那所以说那再进来的。所以说之后我们又做了很多对于易用性和减少误用这两方面的一个工作,这两个看起来是亮点,其实就是一点,核心是说让业务方能够快速的去写出来正确的代码。
打通内部的生态:那在这个前提之下我们再去做一些性能的优化。那下一步,第三个是我们打通内部的生态,其实一个框架好不好用?除了说刚刚的一些API ,还有一些相关的一些使用之外,还有框架毕竟是它只做了一部分,但像但是它像它的生态其实有很多,比如说我们内部的生态,比如说像我们的 log trace metrics mesh 等等,这部分逻辑是每个微服务体系下都需要的逻辑,但是接入起来又很麻烦。如果要是说每一个业务的同学都去做这样的一套生态的话,那这样对于每个业务的同学肯定也是开销非常大了。而且最关键的就是很多同学他可能不太了解你内部,他也不知道他去他也不太了解实现。那这样的话打通内部生态对他来说其实也是不是很容易的一件事情。
那除了内部生态,其实还有一些像外部生态,对于 HTTP 来说,常见的像 CORS,就是跨域,还有说像 session 那像这些基础的功能,一个 HTTP 框架也应该是有的。但是由于我们采用了为了追求性能的一些优化,那我们其实那我们就改变了它之前的我们就没有采用原生库的这样的一个数据结构,导致说现在开源社区的一些生态是不能够直接地使用的。那这样的话如果用户想要使用这些能力的话,那他就需要去自己实现这样一套能力。那对他来说肯定也是不太能够上手用的一些简单的中间件。还好比如说让大家写一个什么加密算法,针对你的数据结构写一个加密算法,那这个的开销可就太大了。所以说我们也在一段时间也在努力地打通内外部的种种生态。
文档建设和用户群建设:那第四点就是关于文档建设和用户群建设,这部分主要还是为了说想尽量地减少一些双方的成本,我也不想让很多的业务同学都问一些很多重复的问题。我们可以让另外首先对于这些问题,如果每个人问如果每个人问一个,那 100 个人就问我 100 个,每天回复 100 个问题。那我也不是客服对吧,我还是有一些自己手上的开发的工作要做。那第二点就是我可能在某些时候也不会及时地回复消息,比如说我可能去开一些会或者什么的。那这个时候如果要是说没有一些良好的辅助的措施的话,让所有的用户阻塞在你这里肯定是不太好的。所以我们也在逐步地加强文档的建设,把常见的问题甚至说很多基础的用法都沟都进行了,一些文档都写到了文档当中。甚至说我们在追求我的一个目标,就是把每一个成让每一个服务端开发工程师变成一个 CV 工程师,就是 ctrl C ctrl V 的工程师直接的代码从你的文档当中复制粘贴出来,代码就可以用的这样的一些工作。再有就是用户群的建设可能有一些同学,他的可能有一些用户他的那个找文档可能不太理解,或者说文档可能有一些没有覆盖到的点。那用户群就是一个很好的反馈,很及时地反馈,说能够找到哪些点是他现在所欠缺的或者说不太清楚的。那这个时候他们这个时候我们在用户群里进行一个回复之后,一个是因为用户群有很多人,那其他的人也可以看到,也可以知道说我有没有这个问题,以及说我们后院加群的人,或者说之后我可以通过一个搜索聊天记录去搜索到一个对应的解决方案。这个是我们进来之后当然做了一些除了追求性能之外的很多的一些努力。
字节内部HTTP框架:Hertz
1万 + 服务3千万 + QPS
GitHub:https://github.com/cloudwego/hertz
目前已经开源,有时间可以研究一波
参考文献: