- (good) review on voting, bagging, boosting stacking, cascading methodologies
- How to combine several sklearn algorithms into a voting ensemble
- Stacking api, MLXTEND
- Machine learning Mastery on
- stacking neural nets - really good
- Stacked Generalization Ensemble
- Multi-Class Classification Problem
- Multilayer Perceptron Model
- Train and Save Sub-Models
- Separate Stacking Model
- Integrated Stacking Model
- How to Combine Predictions for Ensemble Learning
- Plurality Voting.
- Majority Voting.
- Unanimous Voting.
- Weighted Voting.
- Essence of Stacking Ensembles for Machine Learning
- Voting Ensembles
- Weighted Average
- Blending Ensemble
- Super Learner Ensemble
- Dynamic Ensemble Selection (DES) for Classification in Python - Dynamic Ensemble Selection algorithms operate much like DCS algorithms, except predictions are made using votes from multiple classifier models instead of a single best model. In effect, each region of the input feature space is owned by a subset of models that perform best in that region.
- k-Nearest Neighbor Oracle (KNORA) With Scikit-Learn
- KNORA-Eliminate (KNORA-E)
- KNORA-Union (KNORA-U)
- Hyperparameter Tuning for KNORA
- Explore k in k-Nearest Neighbor
- Explore Algorithms for Classifier Pool
- k-Nearest Neighbor Oracle (KNORA) With Scikit-Learn
- A Gentle Introduction to Mixture of Experts Ensembles
- Mixture of Experts
- Subtasks
- Expert Models
- Gating Model
- Pooling Method
- Relationship With Other Techniques
- Mixture of Experts and Decision Trees
- Mixture of Experts and Stacking
- Mixture of Experts
- Strong Learners vs. Weak Learners in Ensemble Learning - Weak learners are models that perform slightly better than random guessing. Strong learners are models that have arbitrarily good accuracy.
Weak and strong learners are tools from computational learning theory and provide the basis for the development of the boosting class of ensemble methods.
- stacking neural nets - really good
- Vidhya on trees, bagging boosting, gbm, xgb
- Parallel grad boost treest
- A comprehensive guide to ensembles read! (samuel jefroykin)
- Basic Ensemble Techniques
- 2.1 Max Voting
- 2.2 Averaging
- 2.3 Weighted Average
- Advanced Ensemble Techniques
- 3.1 Stacking
- 3.2 Blending
- 3.3 Bagging
- 3.4 Boosting
- Algorithms based on Bagging and Boosting
- 4.1 Bagging meta-estimator
- 4.2 Random Forest
- 4.3 AdaBoost
- 4.4 GBM
- 4.5 XGB
- 4.6 Light GBM
- 4.7 CatBoost
- Kaggler guide to stacking
- Blending vs stacking
- Kaggle ensemble guide
- bagging (random sample selection, multi classifier training), random forest (random feature selection for each tree, multi tree training), boosting(creating stumps, each new stump tries to fix the previous error, at last combining results using new data, each model is assigned a skill weight and accounted for in the end), voting(majority vote, any set of algorithms within weka, results combined via mean or some other way), stacking(same as voting but combining predictions using a meta model is used).
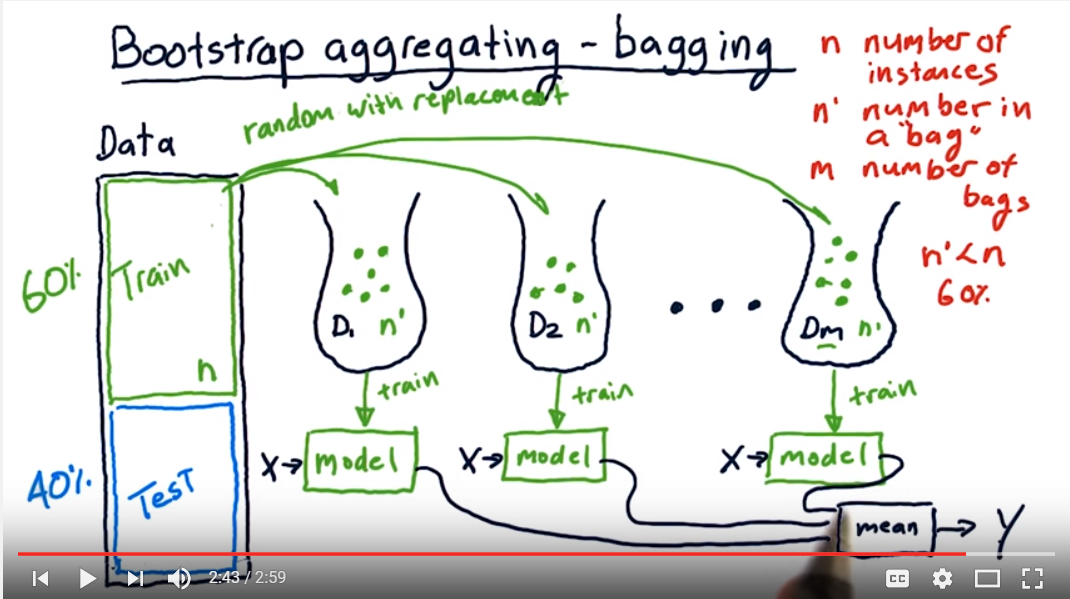
Bagging - best example so far, create m bags, put n’<n samples (60% of n) in each bag - with replacement which means that the same sample can be selected twice or more, query from the test (x) each of the m models, calculate mean, this is the classification.
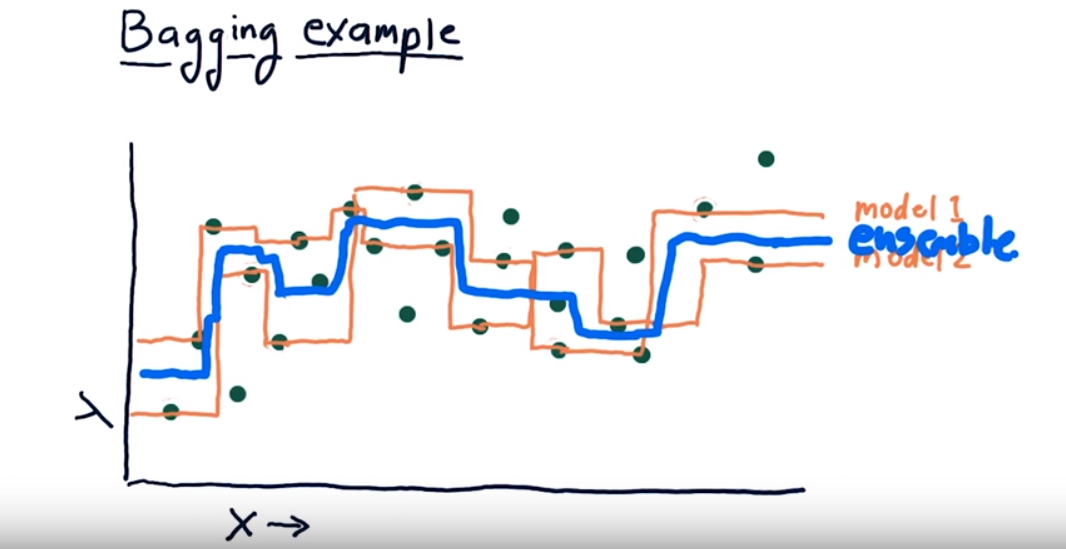
Overfitting - not an issue with bagging, as the mean of the models actually averages or smoothes the “curves”. Even if all of them are overfitted.
Mastery on using all the boosting algorithms: Gradient Boosting with Scikit-Learn, XGBoost, LightGBM, and CatBoost\
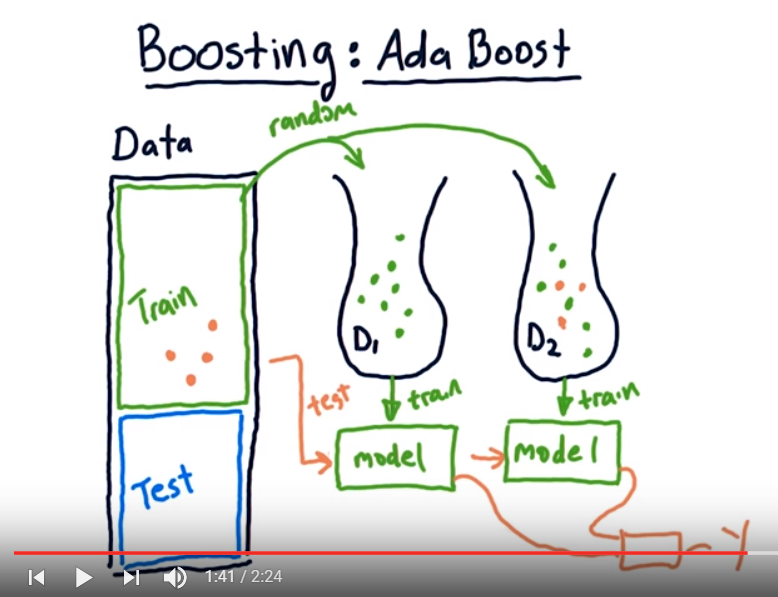
Adaboost: similar to bagging, create a system that chooses from samples that were modelled poorly before.
- create bag_1 with n’ features <n with replacement, create the model_1, test on ALL train.
- Create bag_2 with n’ features with replacement, but add a bias for selecting from the samples that were wrongly classified by the model_1. Create a model_2. Average results from model_1 and model_2. I.e., who was classified correctly or not.
- Create bag_3 with n’ features with replacement, but add a bias for selecting from the samples that were wrongly classified by the model_1+2. Create a model_3. Average results from model_1, 2 & 3 I.e., who was classified correctly or not. Iterate onward.
- Create bag_m with n’ features with replacement, but add a bias for selecting from the samples that were wrongly classified by the previous steps.
- What is XGBOOST? XGBoost is an optimized distributed gradient boosting system designed to be highly efficient, flexible and portable #2nd link
- Does it cause overfitting?
- Authors Youtube lecture.
- GIT here
- How to use XGB tutorial on medium (comparison to GBC)
- How to code tutorial, short and makes sense, with info about the parameters.
- Threads
- Rounds
- Tree height
- Loss function
- Error
- Cross fold.
- Beautiful Video Class about XGBOOST - mostly practical in jupyter but with some insight about the theory.
- Machine learning mastery - slides, video, lots of info.
R Installation in Weka, then XGBOOST in weka through R
Parameters for weka mlr class.xgboost.
- https://cran.r-project.org/web/packages/xgboost/xgboost.pdf
- Here is an example configuration for multi-class classification:
- weka.classifiers.mlr.MLRClassifier -learner “nrounds = 10, max_depth = 2, eta = 0.5, nthread = 2”
- classif.xgboost -params "nrounds = 1000, max_depth = 4, eta = 0.05, nthread = 5, objective = \"multi:softprob\"
Copy: nrounds = 10, max_depth = 2, eta = 0.5, nthread = 2\
Special case of random forest using XGBOOST:\
#Random Forest™ - 1000 trees
bst <- xgboost(data = train$data, label = train$label, max_depth = 4, num_parallel_tree = 1000, subsample = 0.5, colsample_bytree =0.5, nrounds = 1, objective = "binary:logistic")
#Boosting - 3 rounds
bst <- xgboost(data = train$data, label = train$label, max_depth = 4, nrounds = 3, objective = "binary:logistic")
RF1000: - max_depth = 4, num_parallel_tree = 1000, subsample = 0.5, colsample_bytree =0.5, nrounds = 1, nthread = 2
XG: nrounds = 10, max_depth = 4, eta = 0.5, nthread = 2