(Retour vers la page principale)
- Chapitre I: Introduction
 |
|---|
| Apprentissage automatique |
- Certaines tâches sont difficiles à programmer manuellement: Reconnaissance de formes, Traduction par machine, Reconnaissance de la parole, Aide à la décision, etc.
- Les données sont disponibles, qui peuvent être utilisé pour estimer la fonction de notre tâche.
-
Santé:
- Watson santé de IBM: https://www.ibm.com/watson/health/
- Projet Hanover de Microsoft: https://hanover.azurewebsites.net
- DeepMind santé de Google: https://deepmind.com/applied/deepmind-health/
-
Finance : Prévention de fraude, management de risques, prédiction des investissements, etc.
-
Domaine légal : cas de CaseText https://casetext.com
-
Traduction: Google translate https://translate.google.com/ ...TODO: Add more
Lorsqu'on se dispose d'un ensemble de données avec les résultats attendus, on peut entrainer un système sur ces données pour inférer la fonction utilisée pour avoir ces résultats. En résumé:
- Source d'apprentissage: des données annotées (nous avons les résultats attendus)
- Retour d'information: direct; à partir des résultats attendues.
- Fonction: prédire les future résultats
Etant donné un ensemble de données annotées (avec les résultats attendues):
- On divise cet ensemble en 2 parties: données d'entrainement et données de test (évaluation). On peut avoir les données de validation comme troisième partie.
- On fait entrainer notre système sur les données d'apprentissage pour avoir un modèle
- Si on utilise des données de validation, on teste la performance de notre modèle. Si la performance dépasse un certain seuil, on passe vers l'étape suivante. Sinon, on change les paramètres de l'algorithme d'apprentissage ou on on récupère plus de données d'entrainement, et on refaire l'étape précédente.
- On utilise les données de test (évaluation) afin de décider la performance du modèle et le comparer avec un système de base. Si on n'a pas utilisé des données de validation, on peut faire l'étape précédente ici. Mais, il faut faire attention: si on valide plusieurs fois sur les données de test, le système va être adapté aux données de test. Or, l'intérêt des données de test est d'évaluer le modèle sur des nouvelles données qu'il n'a pas rencontré.
 |
|---|
| Apprentissage supervisé |
Selon le type d'annotation, on peut remarquer deux types des algorithmes d'apprentissage automatique: classement et régression.
Lorsque le résultat attendu est une classe (groupe).
| Par exemple: |
|---|
| Classer un animal comme: chat, chien, vache ou autre en se basant sur le poids, la longueur et le type de nourriture. |
Supposant, on veut évaluer un système de classification des courriers indésirables: indésirable ou non. Un résulat obtenu par un un système de classification binaire peut être:
- Vrai positif (True positive): Le modèle prédit correctement la classe positive. Le modèle prédit correctement qu'un message est indésirable.
- Vrai négatif (True negative): Le modèle prédit correctement la classe négative. Le modèle prédit correctement qu'un message est désirable.
- Faux positif (False positive): Le modèle prédit incorrectement la classe positive. Le modèle prédit incorrectement qu'un message est indésirable.
- Faux négatif (False negative): Le modèle prédit incorrectement la classe négative. Le modèle prédit incorrectement qu'un message est désirable.
La matrice de confusion d'un système de classification binaire est:
| classe réelle positive | classe réelle négative | |
|---|---|---|
| classe prédite positive | vrai positif (VP) | faux positif (FP) |
| classe prédite négative | faux négatif (FN) | vrai négtif (VN) |
La justesse d'un modèle de classification est la proportion de ces prédictions correctes. C'est le nombre des prédictions correctes divisé par le nombre total des prédictions. En terme de classification binaire et en utilisant les 4 types des résulats, on peut l'écrire sous forme:
La justesse seule n'ai pas suffisante comme mesure de performance, surtout pour les ensembles de données avec des classes imbalancées. Revenant au système de classification des courriels.
Supposant qu'on a 20 données de test: 3 indésirables et 17 désirables. Le modèle qu'on a entrainé a pu détecter toutes les 17 classes désirables et seulement 1 classe indésirable.
| indésirable (réel) | désirable (réel) | Total (prédit) | |
|---|---|---|---|
| indésirable (modèle) | 1 | 1 | 2 |
| désirable (modèle) | 2 | 16 | 18 |
| Total (réel) | 3 | 17 |
Dans ce cas, la justesse est (1 + 16)/20 = 85%. Le problème est que ce modèle puisse bien détecter les couriers désirables contrairement aux courriers indésirables. Or, notre but est de détecter les courrier indésirables afin de les filtrer.
La précision est la proportion des prédictions positives correctes par rapport aux prédictions postives (correctes ou non).
La précision de notre modèle précédent est 1/(1 + 1) = 50%. En d'autre termes, parmi les prédictions qu'il puisse prédire correctement, les couriers indésirables forment 50%.
Le rappel est la proportion des prédictions positives correctes par rapport aux prédictions correctes (négatives et positives).
Le rapperl de notre modèle précédent est 1/(1 + 2) = 33%. En d'autre termes, il peut prédire seulement 33% des couriers indésirables.
C'est la moyenne harmonique entre le rappel et la précision.
Le F1 mesure de notre modèle précédent est (2 * 50 * 33)/(50 + 33) = 3300/83 = 40 %.
C'est un coéfficient pour mesurer de qualité en tenant compte des données imbalancées. Cette mesure est connue, aussi, sous le nom: coefficient Phi. Un modèle peut avoir des coefficients allant de -1 jusqu'à +1:
- -1: les prédictions sont totalement irronnées.
- 0: la performance du modèle est comparable avec un système aléatoire (random).
- 1: les prédictions sont parfaites.
Pour un système de classification binaire, sa formule exprimé en terme de la matrice de confusion est:
Le CCM de notre modèle précédent est (1 * 16 - 1 * 2)/rac((1 + 1)(1 + 2)(16 + 1)(16 + 2)) = 14/rac(2 * 3 * 17 * 18) = 14/rac(1836) = 0.33. En d'autre termes, la qualité de notre modèle est un peu plus que le système aléatoire, mais reste toujours mauvaise.
Supposant, on a entrainer un modèle pour détecter à partir d'une image donnée s'il s'agit d'un chat, un chien ou une vache. Dans le cas de la justesse, c'est le nombre des classes correctement détectées divisé par le nombre des examples. Mais, comment calculer la précision et le rappel?
Ces deux métriques sont calculés par rapport une classe donnée. Le rappel (précision) du modèle est la moyenne arithmétique des rappels (précisions) de toutes les classes.
Supposant les données de test sont 60 examples uniformément distribuées sur les classes (20 par classe). Voici la matrice de confusion:
| chat (réel) | chien (réel) | vache (réel) | Total (prédit) | |
|---|---|---|---|---|
| chat(modèle) | 10 | 5 | 0 | 15 |
| chien(modèle) | 8 | 13 | 3 | 24 |
| vache(modèle) | 2 | 2 | 17 | 21 |
| Total (réel) | 20 | 20 | 20 |
La justesse est (10 + 13 + 17)/60 = 67%.
Le rappel de la classe "chat" est 10/20 = 50%. Donc, on peut confirmer que notre modèle peut détecter 50% des "chat" de l'ensemble de données.
La précision de la classe "chat" est 10/15 = 67%. Donc, on peut confirmer que 67% des données marquées comme "chat" par notre modèle sont réelement de la classe "chat".
De la même façon:
Rappel(chien) = 13/20 = 65%.
Précision(chien) = 13/24 = 54%
Rappel(vache) = 17/20 = 85%
Précision(vache) = 17/21 = 81%
Rappel = (50 + 65 + 85)/3 = 67%
Précision = (67 + 54 + 81)/3 = 67%
Lorsque le résultat attendu est une valeur.
| Par exemple: |
|---|
| Estimer le prix d'une maison à partir de sa surface, nombre de chambre et l'emplacement. |
Lorsque nous disposons d'un ensemble de données non annotées (sans savoir les résulats attendus). En résumé:
- Source d'apprentissage: des données non annotées
- Retour d'information: pas de retour; on dispose seulement des données en entrée.
- Fonction: rechercher les structures cachées dans les données.
Selon le type de structure que l'algorithme va découvrir, on peut avoir: le regroupement et la réduction de dimension.
L'algorithme de regroupement sert à assigner les échantillons similaires dans le même groupe. Donc, le résultat est un ensemble de groupes contenants les échantillons.
| Par exemple: |
|---|
| Regrouper les plantes similaires en se basant sur la couleur, la taille, etc. |
L'algorithme de réduction de dimension a comme but d'apprendre comment représenter des données en entrée avec moins de valeurs.
| Par exemple: |
|---|
| Représenter des individus sur un graphe de deux dimensions en utilisant la taille, le poids, l'age, la couleur des cheveux, la texture des cheveux et la couleur des yeux |
- Source d'apprentissage: le processus de décision
- Retour d'information: un système de récompense
- Fonction: recherche des structures cachées dans les données.
 |
|---|
| Apprentissage par renforcement [ Wikimedia ] |
{kind=link}
- Pour des tâches complexes, on a besoin d'une grande quantité de données
- Dans le cas de l'apprentissage supervisé, l'annotation de données est une tâche fastidieuse; qui prend beaucoup de temps.
- Le traitement automatique de langages naturels (TALN) reste un défit
- Les données d'entrainement sont souvent biaisées
Les outils suivants sont conçus pour l'apprentissage approfondi qui est basé le réseau de neurones.
- Outil: nom et lien de l'outil (ordre alphabétique)
- Licence: la licence de l'outil. Ici, on ne s'intéresse que par les outils open sources.
- écrit en: le langage de programmation utilisé pour écrire cet outil.
- interfaces: les langages de programmation qu'on puisse utiliser pour utiliser cet outil (API).
| Outil | Licence | écrit en | interfaces |
|---|---|---|---|
| Caffe | BSD | C++ | C++, MATLAB, Python |
| Deeplearning4j | Apache 2.0 | C++, Java | Java, Scala, Clojure, Python, Kotlin |
| Keras | MIT | Python | Python, R |
| Microsoft Cognitive Toolkit | MIT | C++ | Python, C++ |
| MXNet (Apache) | Apache 2.0 | C++ | C++, Clojure, Java, Julia, Perl, Python, R, Scala |
| TensorFlow | Apache 2.0 | C++, Python | Python (Keras), C/C++, Java, Go, JavaScript, R, Julia, Swift |
| Theano | BSD | Python | Python |
| Torch | BSD | C, Lua | C, Lua, LuaJIT |
Pour une comparaison plus détaillée, veuillez consulter cette page en Wikipédia
La liste suivante contient les outils avec plusieurs algorithmes d'apprentissage automatique.
| Outil | Licence | écrit en | interfaces |
|---|---|---|---|
| Data Analytics Acceleration Library(Intel) | Apache 2.0 | C++, Python, Java | C++, Python, Java |
| Encog | C#, Java | C#, Java | |
| Java Statistical Analysis Tool (JSAT) | GPL 3 | Java | Java |
| MLLib(Apache Spark) | Apache 2.0 | - | Java, R, Python, Scala |
| ScalaNLP Breeze | Apache 2.0 | Scala | Scala |
| Scikit-learn | BSD | Python | Python |
| Shogun | - | C++ | C++, C#, Java, Lua, Octave, Python, R, Ruby |
Ce sont des logiciels visuels qui peuvent être utilisés par des non informaticiens.
Apprentissage automatique comme un service (MLaaS: Machine Learning as a Service):
- Amazon Machine Learning
- BigML
- DataRobot
- Deepai enterprise machine learning
- Deepcognition
- FloydHub
- IBM Watson Machine Learning
- Google Cloud Machine Learning Engine
- Microsoft Azure Machine Learning studio
- MLJAR
- Open ML
- ParallelDots
- VALOHAI
- Vize: Traitement d'images
- Kaggle: télécarger les données, faire des compétitions avec des prix.
- Registry of Open Data on AWS
- UC Irvine Machine Learning Repository
- Visual data: Des données sur le traitement d'images.
- COCO un ensemble de données de détection, de segmentation et d'annotation des images.
- COIL-100 des images de 100 objets différents prises sous tous les angles dans une rotation de 360.
- ImageNet des images organisées selon la hiérarchie de WordNet
- Indoor Scene Recognition reconnaissance de scènes d'intérieur
- Labelled Faces in the Wild: reconnaissance faciale sans contraintes
- LabelMe Images annotées
- LSUN des images concernant un défi pour la classification de la scène.
- Open Images Dataset de Google
- Stanford Dogs Dataset la reconnaissance des races de chiens.
- VisualGenome une base pour connecter les images au langage
- Large Movie Review Dataset critiques des films -Multi-Domain Sentiment Dataset commentaires sur les produits d'Amazon
- Sentiment140 des Tweets avec des émoticônes filtrées.
- Stanford Sentiment Treebank critiques de films
- Amazon Reviews
- Enron Email Dataset
- Google Books Ngrams
- Gutenberg eBooks List Liste annotée de livres électroniques du projet Gutenberg.
- Hansards text chunks of Canadian Parliament texte aligné: Français-Anglais
- HotspotQA Dataset Question-Réponse (réponse automatique)
- Jeopardy Les questions de Jeopardy format Json
- SMS Spam Collection in English
- UCI's Spambase filtrage du courrier électronique indésirable
- Wikipedia Links data
- Yelp Reviews
- Baidu Apolloscapes
- Berkeley DeepDrive BDD100k
- Bosch Small Traffic Lights Dataset
- Cityscapes dataset
- Comma.ai
- CSSAD Dataset
- KUL Belgium Traffic Sign Dataset
- LaRa Traffic Light Recognition
- LISA datasets
- MIT AGE Lab
- Oxford's Robotic Car
- WPI datasets
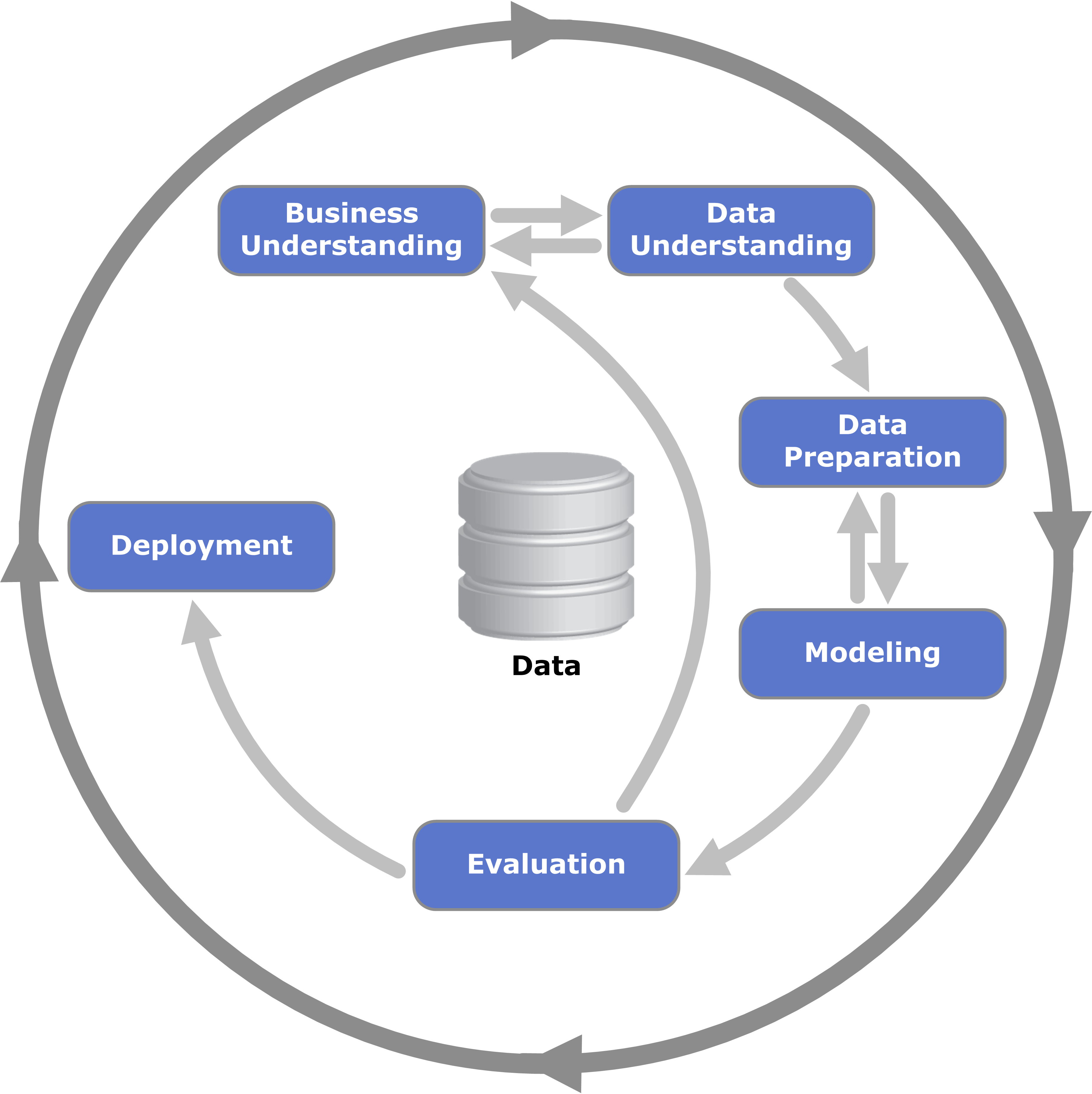 |
|---|
| CRISP-DM [ Wikimedia ] |
{kind=link}
 |
|---|
| ASUM-DM [ Source ] |
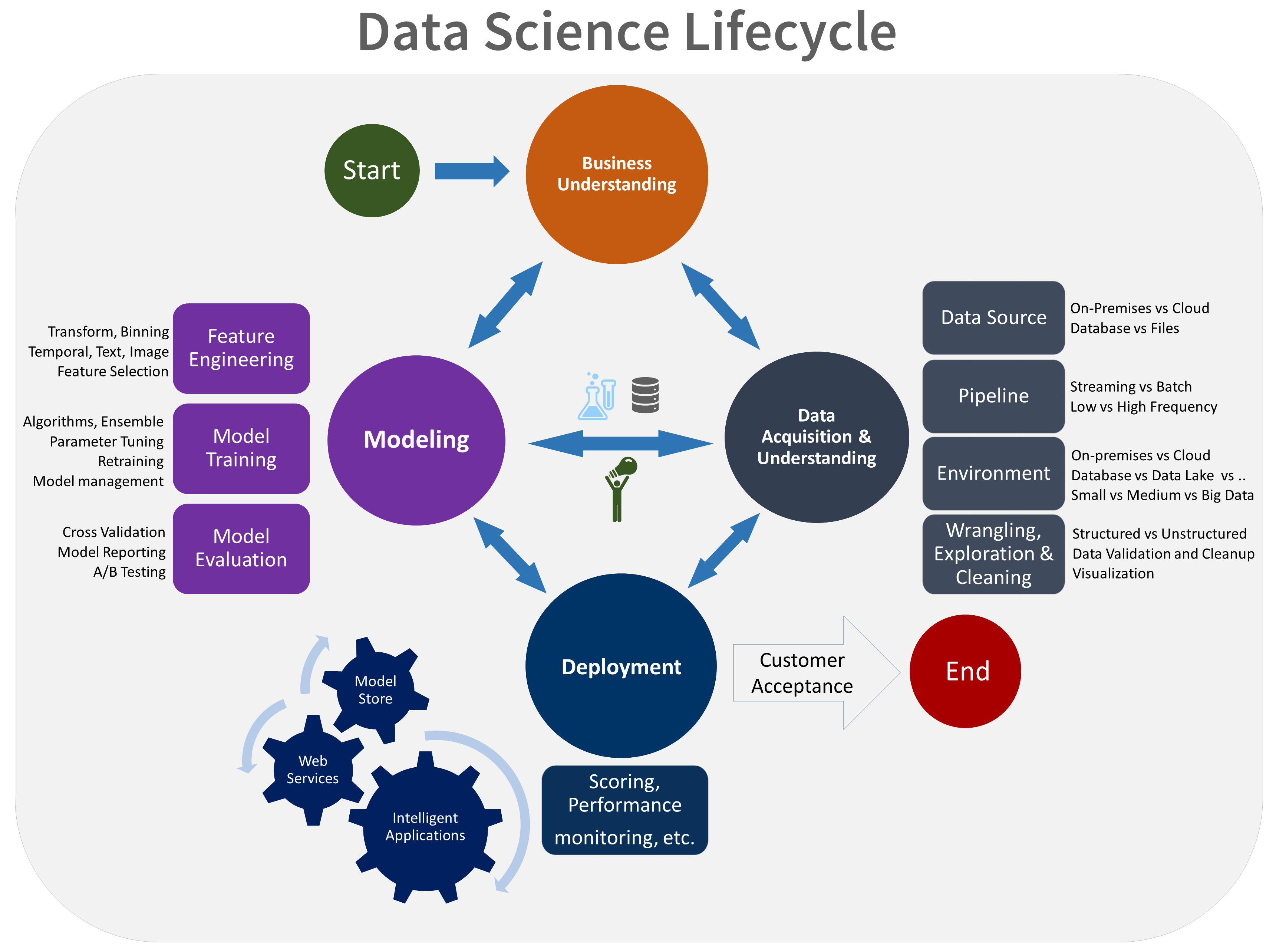 |
|---|
| TDSP [ Source ] |
Ici, on va utiliser l'outil scikit-learn pour l'évaluation. On va créer une liste des résulats attendus et une autre qu'on suppose être la liste des résulatats générés par notre modèle.
Consulter le fichier codes/eval/classer1.py
On a entrainé un modèle pour classer les emails comme indésirables ou non. Ensuite, on a testé ce modèle avec 20 examples qui a donné la matrice de confusion suivante:
| indésirable (réel) | désirable (réel) | Total (prédit) | |
|---|---|---|---|
| indésirable (modèle) | 1 | 1 | 2 |
| désirable (modèle) | 2 | 16 | 18 |
| Total (réel) | 3 | 17 |
On annote les courniers indésirables avec 1 et ceux désirables avec 0. Dans la classification binaire de scikit-learn, la classe positive est annotée par 1 par défaut. Cela peut être changé en utilisant l'option pos_label. La fonction str est juste pour transformer un nombre vers une chaîne de charactères.
#imortation des fonctions nécessaires
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import recall_score, f1_score, matthews_corrcoef
# créer une liste de 3 "1" suivis de 17 "0"
reel = [1] * 3 + [0] * 17
# créer une list [1, 0, 0, 1] concaténée avec 16 "0"
predit = [1, 0, 0, 1] + [0] * 16
print "La justesse: " + str(accuracy_score(reel, predit))
print "La précision: " + str(precision_score(reel, predit))
print "Le rappel: " + str(recall_score(reel, predit))
print "La mesure F1: " + str(f1_score(reel, predit))
print "corrélation de matthews: " + str(matthews_corrcoef(reel, predit))scikit-learn offre la possibilié de récupérer la matrice de confusion
#imortation des fonctions nécessaires
from sklearn.metrics import confusion_matrix
# récupérer et afficher la matrice de confusion
mat_conf = confusion_matrix(reel, predit)
print mat_conf
# récupérer le nombre des VN, FP, FN, TP
vn, fp, fn, vp = mat_conf.ravel()
print vn, fp, fn, vpCeci va afficher:
[[16 1]
[ 2 1]]
16 1 2 1
On peut, aussi, récupérer un rapport de classification.
from sklearn.metrics import classification_report
noms_classes = ["desirable", "indesirable"]
print(classification_report(reel, predit, target_names=noms_classes))Ceci va afficher:
precision recall f1-score support
desirable 0.89 0.94 0.91 17
indesirable 0.50 0.33 0.40 3
micro avg 0.85 0.85 0.85 20
macro avg 0.69 0.64 0.66 20
weighted avg 0.83 0.85 0.84 20
Consulter le fichier codes/eval/classer2.py
Reprenons l'exemple des classification des animaux en chat, chien ou vache. Supposant notre test a donné la matrice de confusion suivante:
| chat (réel) | chien (réel) | vache (réel) | Total (prédit) | |
|---|---|---|---|---|
| chat(modèle) | 10 | 5 | 0 | 15 |
| chien(modèle) | 8 | 13 | 3 | 24 |
| vache(modèle) | 2 | 2 | 17 | 21 |
| Total (réel) | 20 | 20 | 20 |
On crée les deux listes:
- reel: la liste des résulats attendus avec 60 éléments
- predit: la liste des résultats générés par le système
On attribut à chaque classe un numéro: chat(0), chien(1) et vache(2)
# 20 chats, 20 chiens et 20 vaches
reel = [0] * 20 + [1] * 20 + [2] * 20
# les 20 chats sont prédites comme 10 chats, 8 chiens et 2 vaches
predit = [0] * 10 + [1] * 8 + [2] * 2
# les 20 chiens sont prédites comme 5 chats, 13 chiens et 2 vaches
predit += [0] * 5 + [1] * 13 + [2] * 2
# les 20 vaches sont prédites comme 0 chats, 3 chiens et 17 vaches
predit += [1] * 3 + [2] * 17La justesse est calculée comme dans la clasification binaire
print "La justesse: ", accuracy_score(reel, predit)La présion, le rappel et le f1-score dans le cas muti-classes peuvent être calculés selons plusieurs méthodes, celle qu'on décrit précédement s'appelle "macro"
print "La précision: ", precision_score(reel, predit, average="macro")
print "Le rappel: " , recall_score(reel, predit, average="macro")
print "La mesure F1: " , f1_score(reel, predit, average="macro")On peut sélectionner les classes qu'on veut prendre en considération. Supposant, on veut calculer la précision pour les classes: chat et chien et ignorer la classe vache. On peut, même, ajouter des classes qui ne sont pas présentes dans les données de test.
print "La précision (chat, chien): ", precision_score(reel, predit, labels=[0, 1], average="macro")- https://www.kdnuggets.com/2017/11/3-different-types-machine-learning.html
- https://www.techleer.com/articles/203-machine-learning-algorithm-backbone-of-emerging-technologies/
- https://www.wired.com/story/greedy-brittle-opaque-and-shallow-the-downsides-to-deep-learning/
- https://data-flair.training/blogs/advantages-and-disadvantages-of-machine-learning/
- https://towardsdatascience.com/coding-deep-learning-for-beginners-types-of-machine-learning-b9e651e1ed9d
- https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef
- https://docs.microsoft.com/fr-fr/azure/machine-learning/team-data-science-process/overview
- https://www.ibm.com/support/knowledgecenter/en/SSEPGG_9.5.0/com.ibm.im.easy.doc/c_dm_process.html
- ftp://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/18.0/en/ModelerCRISPDM.pdf
- https://medium.com/datadriveninvestor/the-50-best-public-datasets-for-machine-learning-d80e9f030279
- https://developers.google.com/machine-learning/crash-course/prereqs-and-prework?hl=fr
- https://towardsdatascience.com/supervised-machine-learning-classification-5e685fe18a6d
- http://text-analytics101.rxnlp.com/2014/10/computing-precision-and-recall-for.html
- https://scikit-learn.org/stable/modules/generated/sklearn.metrics.matthews_corrcoef.html
- https://en.wikipedia.org/wiki/Matthews_correlation_coefficient