Lesson: Add pages to a bibliographic work
- Set up Models to represent relationships between different types of objects
- Create and modify relationships between objects
Now that we have created a model for BibliographicWorks, we will create a model for pages in the bibliographic resource.
Next we're going to add a model for our pages. Open app/models/page_file_set.rb and add this content:
class PageFileSet < ActiveFedora::Base
include Hydra::Works::FileSetBehavior
property :page_number, predicate: ::RDF::URI.new('http://opaquenamespace.org/hydra/pageNumber'), multiple: false do |index|
index.as :stored_searchable
index.type :integer
end
property :text, predicate: ::RDF::URI.new('http://opaquenamespace.org/hydra/pageText'), multiple: false do |index|
index.as :stored_searchable
end
end
This is very similar to how our RDF-based BibliographicFileSet class looks, we're just adding different attributes defined by different predicates. I.E. a bibliographic resource has an author and a title, while a Page has a page_number and text.
NOTE: We are adding the text property here to hold the text of the page. In the next lesson, we will see how to attach a file that could be a pdf, jpg, or some other format to serve as the text for the page.
ASIDE #1: It's generally best practice to use well-known RDF predicates when defining metadata terms, e.g. using DC.title for your title term. In some cases, however, RDF ontologies don't exist to express the concepts we want to track. Surprisingly, page numbers are in this group; therefore, we have used a predicate registry created by the community to define our page number predicate: http://opaquenamespace.org/hydra/pageNumber.
ASIDE #2: We are explicitly assigning a type for the page number index. This lets us control our indexing and searching to use integer sorting (e.g. 1,2,3,4,...9,10,11) instead of the default lexical sorting use for strings (e.g. '1','10','11','2','21','27','5','6','60'). By default, Hydra and Active Fedora assume all metadata are text values. You can find additional information on the available indexing options in the Solrizer ReadME and in the solrizer code that defines the default indexing strategies
Pre-PCDM and Hydra-Works, you had to explicitly define a relationship between the bibliographic resource and it's page. In Hydra-Works, any file set can be a member of any generic work. To add a page to a work, you simply create an instance of the PageFileSet file set and add it as a member of the BibliographicWork instance.
Start the rails console and let's create a page.
pf1 = PageFileSet.new("page-1")
=> #<PageFileSet id: "page-1", page_number: nil, text: nil, head_id: nil, tail_id: nil>
pf1.page_number = 1
=> 1
pf1.text = "Once upon a midnight dreary..."
=> "Once upon a midnight dreary..."
pf1.save
=> trueAnd add it to the bibliographic resource work we created previously.
bw = BibliographicWork.find("work-1")
=> #<BibliographicWork id: "work-1", title: "The Raven", author: "Poe, Edgar Allan", abstract: "A lonely man tries to ease his 'sorrow for the lost Lenore', by distracting his mind with old books of 'forgotten lore'.">
bw.members << pf1
=> [#<BibliographicFileSet id: "fileset-1", head: [], tail: [], title: "The Raven pdf">,
#<BibliographicWork id: "work-2", head: [], tail: [], title: "Work 2", author: nil, abstract: nil>,
#<BibliographicFileSet id: "fileset-2", head: [], tail: [], title: "File Set 2">,
#<PageFileSet id: "page-1", head: [], tail: [], page_number: 1, text: "Once upon a midnight dreary...">]For fun, let's create another page so we can have more than one page to play around with.
pf2 = PageFileSet.new("page-2")
=> #<PageFileSet id: "page-2", page_number: nil, text: nil, head_id: nil, tail_id: nil>
pf2.page_number = 2
=> 2
pf2.text = "The End"
=> "The End"
pf2.save
=> true
bw.members << pf2
=> [#<BibliographicFileSet id: "fileset-1", head: [], tail: [], title: "The Raven pdf">,
#<BibliographicWork id: "work-2", head: [], tail: [], title: "Work 2", author: nil, abstract: nil>,
#<BibliographicFileSet id: "fileset-2", head: [], tail: [], title: "File Set 2">,
#<PageFileSet id: "page-1", head: [], tail: [], page_number: 1, text: "Once upon a midnight dreary...">,
#<PageFileSet id: "page-2", head: [], tail: [], page_number: 2, text: "The End">]There are two more pages for The Raven. You can add those now if you want.
Now that we have pages, how can we get a list of all pages?
bw.file_sets
=> [#<BibliographicFileSet id: "fileset-1", head: [], tail: [], title: "The Raven pdf">,
#<BibliographicFileSet id: "fileset-2", head: [], tail: [], title: "File Set 2">,
#<PageFileSet id: "page-1", head: [], tail: [], page_number: 1, text: "Once upon a midnight dreary...">,
#<PageFileSet id: "page-2", head: [], tail: [], page_number: 2, text: "The End">]Hmmm, that returns the bibliographic resource file and all the page files. Can I make it just return page files?
 Warning: At the last update (12-20-2015), this section on filtering does not seem to be working.
Warning: At the last update (12-20-2015), this section on filtering does not seem to be working.
Let's add a filter to the BibliographicWork that understands pages. Add the filters_association line between the include of WorkBehavior and the property statements.
filters_association :members, as: :pages, condition: :page?
such that BibliographicWork model at app/models/bibliographic_work.rb now looks like...
class BibliographicWork < ActiveFedora::Base
include Hydra::Works::WorkBehavior
filters_association :members, as: :pages, condition: :page?
property :title, predicate: ::RDF::DC.title, multiple: false do |index|
index.as :stored_searchable
end
property :author, predicate: ::RDF::DC.creator, multiple: false do |index|
index.as :stored_searchable
end
property :abstract, predicate: ::RDF::DC.abstract, multiple: false do |index|
index.as :stored_searchable
end
endFor the filter to find pages, we need to define the condition method page? in each of file set class that should be treated as a page..
Add the following method to the end of app/models/page_file_set.rb to identify this model as a page.
def page?
true
endAt this time, it is also necessary to add the same method to all file sets that can be members of BibliographicWork. So also add this method to app/models/bibliographic_file_set.rb. NOTE: In bibliographic_file_set.rb, the method returns false to identify that this class is NOT a page.
def page?
false
endRestart rails console. Now, we can request just pages to be returned.
bw = BibliographicWork.find("work-1")
=> #<BibliographicWork id: "work-1", title: "The Raven", author: "Poe, Edgar Allan", abstract: "A lonely man tries to ease his 'sorrow for the lost Lenore', by distracting his mind with old books of 'forgotten lore'.">
bw.pages
=> [#<PageFileSet id: "page-1", page_number: 1, text: "Once upon a midnight dreary...", head_id: nil, tail_id: nil>, #<PageFileSet id: "page-2", page_number: 2, text: "The End", head_id: nil, tail_id: nil>]NOTE: At the 12-20-2015 update, bw.pages threw an error "(Object doesn't support #inspect)". ### TODO Look into this error to determine if filters are still supported.
You can side-step the "Object doesn't support #inspect" error by issuing bw.pages.to_s in the console. This shows that pages is in fact an ActiveFedora::Associations::CollectionProxy object:
bw.pages.to_s
=> "#<ActiveFedora::Associations::CollectionProxy:0x007f7ff22557c8>" However, at this moment, you must also declare a page? method in the BibliographicWork class and have it return false in order to be able to access bw.pages correctly. After you add the method to BibliographicWork you can access the pages collection:
bw.pages[0]
=> #<PageFileSet id: "page-1", head: [], tail: [], page_number: 1, text: "the first page">Let's look at the RDF that active-fedora uses to represent these relationships. View the page file in Fedora at: http://127.0.0.1:8983/fedora/rest/dev/page-1
The page file has the following properties in Fedora...
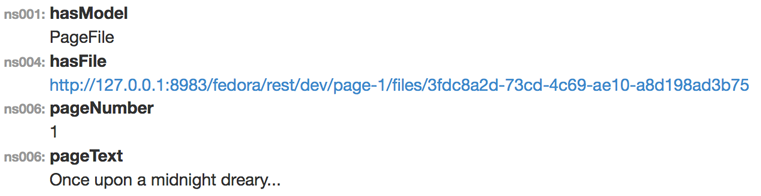
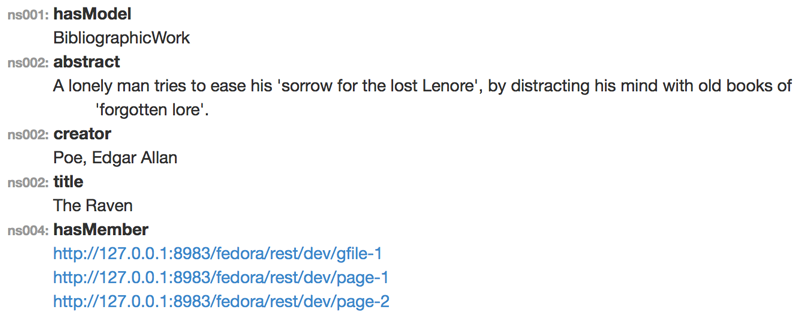
View the update bibliographic work in Fedora at: http://127.0.0.1:8983/fedora/rest/dev/work-1 The updated bibliographic resource work with two pages has the following properties in Fedora...
Now that we've added page relationships, it's a great time to commit to git:
git add .
git commit -m "Created a page file model with relationship to the bibliographic resource work model"
Go on to BONUS Lesson: Add attached files or explore other [Dive into Hydra-Works](Dive into Hydra-Works#Bonus) tutorial bonus lessons.