- Installed kubectl binary using curl: https://kubernetes.io/docs/tasks/tools/install-kubectl/
- Have secure boot disabled and virtualization enabled from bios
- Installed virtualBox and minikube: https://kubernetes.io/docs/tasks/tools/install-minikube/
- Installed kubectl completion for fish shell: https://github.com/evanlucas/fish-kubectl-completions
minikube versionminikube start- Now I have a running Kubernetes clster. Minikube started a virtual machine and a Kubernetes cluster is now running in that VM.
minikube dashboard- shows gui
- The cluster can be interacted with using the kubectl CLI. This is the main approach used for managing Kubernetes and the applications running on top of the cluster.
kubectl cluster-info- shows links
kubectl cluster-info dump- further diagnose in terminal
kubectl get nodes- This command shows all nodes that can be used to host our applications. Now we have only one node, and we can see that it’s status is ready (it is ready to accept applications for deployment).
- Before: applications were installed directly onto specific machines as packages deeply integrated into the host. Now: make the applications containerized. Deploy them into a cluster of machines.
- Master coordinates the cluster - schedules applications, maintains desired state, scales app and rolls out new updates.
- Nodes are the workers that run applications. It's a VM or a physical computer that serves as a worker machine in a Kubernetes cluster. It has a kubelet, that manages the node and communicates with master. Each node has docker/rkt too. A cluster has at least three nodes.
- To deploy an application, you tell the master the start app containers. The master schedules the containers to run on the nodes. The nodes communicates with the master using k8s api, which the master exposes. Users can also communicate withe master using the api.
- A k8s cluster can be deployed on either physical or vm. We can use minikube to make a k8s cluster on local machine, which has only one node.

minikube versionensure that minikube is installedminikube start- minikube created a virtual machine and a k8s cluster is running in that vm.kubectl version- it provides an interface to manage k8s. This command checks if kubectl is installed properly.kubectl cluster-info- shows the cluster detailskubectl get nodes- shows all the nodes that can be used to host apps. Now in our local machine, we have only one node and we can it's status ready and it's role is master
- Now you can deploy apps on top of the cluster. You need to create a Deployment Configuration. This instructs how to create and update instances of your app. Then Master schedules the instances onto individual Nodes.
- Once instances of the app are created, a Kubernetes Deployment Controller continuously monitors these instances. If a Node containing an instances goes down, the Deployment controller replaces it. This provides a self-healing mechanism.
- Before: scripts were used to start the app, but doesn't help to recover. Now: Controller keeps them running.

- kubectl is a command line interface that communicates with the cluster using the k8s api.
- To deploy, you need to specify the container image and number of replicas to run. You can change the info by updating the Deployment.
kubectl run <deployment-name> --image=<image-name> --port=<8080-or-something-else>kubectl runcommand creates a new Deployment. It need deployment name and app image location (if the image aren't hosted on DockerHub, needs to include full repo url). Also needs specific port to run- this command searched for a Node where an instance of the app could be run
- scheduled the app to run on that Node
- configured the cluster to reschedule the instance on a new node when needed
- Q: fahim couldn't run the deployment because he didn't have
EXPOSEin his Dockerfile. After adding the line, deployment ran. And--portvalue inkubectl runcommand doesn't have to matchEXPOSEvalue. Why? kubectl run busyboxkube --image=busyboxpods doesn't run because the os container have nothing to do - it will be inRunningstatus as long as it has something to do - Shudipta added a infinite loop and it ran and you can runkubectl exec -it <pod-name> shand run various comamnds on sh.
kubectl get deploymentsshows the deployments, their instances and state.kubectl proxycreates a proxy - so far kubectl were communicating with k8s cluster using api, but after proxy command we can communicate with k8s api too (through browser or curl)
- A pod represents one or more containers and has some shared storage as Volumes, networking as a unique cluster IP address, information about each container such as image version or which ports to use.
- A pod models an application-specific "logical host" and can contain different application which are relatively tightly coupled.
- The contains in same Pod share an IP address and port space - co-located/co-scheduled/runs-in-same-context
- Pods are atomic unit on K8s platform. A deployment creates Pods with containers inside them. Each pod is tied to its Node, where it is scheduled. When a Node fails, identical pods are scheduled on other available Nodes in the cluster.

- One node is either one physical machine (laptop) or virtual machine (I can create more than one node in my laptop with VM). A node can have multiple pods and k8s master automatically handles scheduling the pods across the Nodes in the cluster, based on the resources available on each Node.
- One node has kubelet - a process responsible for communicating with the Master. It manages pods and containers.
- Node contains container runtime too (Docker/rkt) which pulls the container image, unpacks the container and runs the pp.

kubectl get podslists pods.kubectl describe podsshows details (yaml?)kubectl proxy- As pods are running in an isolated, private network - we need to proxy access to them so we can interact with them.kubectl proxy --port=3456adds a port- default is 8001
curl localhost:8001from browser
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')- QJenny
curl http://localhost:<mentioned-or-default-port>/api/v1/namespaces/default/pods/$POD_NAME/proxy/(from my laptop)- QJenny - shows yaml-like things
kubectl logs <pod-name>- Anything that the application would normally send to STDOUT becomes logs for the container within the Pod (ommitted name of container as we have only one container now).-fflag continues to watchkubectl exec <pod-name> <command>- we can execute commands directly on the container once the Pod is up and running. (here we ommitted the container name as there's only one container in our pod)kubectl exec -it <pod-name> bash- lets us use the bash inside the container(again, we have one container)- we can use
curl localhost:8080to from inside the container (after accessing bash of the pod)- as we used
4321in our dockerfile - we would uselocalhost:4321 --target-portis4321
- as we used
- Pods are mortal. They have a lifecycle. If a node dies, pods running on that node are lost too.
- Replication Controller creates new pods when that happens (by rescheduling the pod on available nodes).
- Pods have unique IP across a K8s cluster.
- Front-end shouldn't care about backend replicas or if a pod is lost and created.
- A service in K8s defines a logical set of Pods and a policy by to access them. Service is defined using YAML.
- The set of Pods targeted by a Service is usually determined by a
LabelSelector - Unique IP addresses are not exposed to outside cluster with a Service. Services can be exposed in different ways by specifying a type in the ServiceSpec.
ClusterIP(default) exposes the service on an internal IP in the cluster. This makes the Service onlu reachable from within the cluster.NodePortexposes the Service on the same port of each selected Node in the cluster using NAT. Makes a service accessible from outside the cluster using<NodeIP>:<NodePort. Superset of ClusterIP.LoadBalancercreates an external load balancer in the current cloud (if supported) and assigns a fixed, external IP to the Service. Superset of NodePort.ExternalNameexposes the service using an arbitrary name (specified byexternalNamein the spec) by returning aCNAMErecord with the name. No proxy is used. This type requires v1.7 or higher ofkube-dns
- A service created without selector will also not create the corresponding Endpoints object. This allows users to manually map a Service to specific endpoints. Another possibility why there maybe no selector is you are strictly using
type:ExternalName
- Service routes traffic for a set of pods and allows pods to die and replicate in k8s without impacting the app (services exposes pods through a common port(in case of node port) - so an application sees the service - if a node/pod is down service is recreating those pods internally - application is not harmed)
- Labels are key/value pairs attached to objects. It can attached to objects at creation or later on.
- A Service can be created at time of deployment by using
--exposein kubectl. - A Service is created by default when minikube starts the cluster.


kubectl get serviceskubectl expose deployment/<deployment-name> --type="NodePort" --port 4321created a new service and exposed it as NodePort type. minikube doesn't support LoadBalancer yet.- when we are mentioning
--portand not mentioning--target-port, target-port takes the --port by default - my
EXPOSEin Dockerfile is4321, we can access the service only if--target-portis4321 - services works on pods - a service can have pods from multiple nodes
- when we are mentioning
kubectl describe services/<service-name>shows detailsexport NODE_PORT=$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')curl $(minikube ip):$NODE_PORTminikube ipshows the node-ip- browse
192.168.99.100:30250
kubectl describe deploymentshows name of the label among many other infoskubectl get pods -l run=<pod-label>kubectl get pods -l run=booklistkube2
kubectl get services -l run=<service-label>kubectl get services -l run=booklistkube2
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')- QJenny
kubectl label pod <pod-name> app=<varialbe-name>applies a new label (pinned the application version to the pod)kubectl describe pods <pod-name>- if we use
-lflag,use <pod-label> - otherwise, use
<pod-name> - same for
kubectl get pods
- if we use
kubectl describe pods -l app=<app-label-namekubectl delete service -l run=<label-name>orapp=<label-namedeletes a service- or
kubectl delete service <service-name
- or
kubectl label pod <pod-name> app=v2 --overwriteoverwrites a label namekubectl label service <service-name> app=<label-namewe can add service label too! (:D starting to get the label-things)kubectl edit service <service-name> -o yamlyou can edit details of the service-o yamlcan be ommitted- used
--port=8080- later saw that--target-portgot the same from this comamnd and edited target-port(only) to4321and it worked
kubectl get service <service-name> -o yamlshows the yamlkubectl get deployment <deployment-name> -o yamlkubectl edit deployment <deployment-name> -o yaml-o yamlcan be ommitted
kubectl get pod <pod-name> -o yamlkubectl edit pod <pod-name> -o yaml-o yamlcan be ommitted
kubectl exec -it <pod-name> sh- thenwget localhost:4321(--target-port)kubectl exec -it <pod-name> wget localhost:4321
- Scaling is accomplished by changing the number of replicas in a Deployment.
- Scaling will increase the number of Pods to the new desired state - schedules them to nodes with available resources. Scaling to zero will terminate all pods.
- Services have an intergrated load balancer that will distribute network traffic to all pods of an exposed deployment. Services will monitor continuously the running pods using endpoints, to ensure the traffic is sent only to available pods.
kubectl get deploycommand has- DESIRED shows the configured number of replicas
- CURRENT shows how many replicas are running now
- UP-TO-DATE shows the number of replicas that were updated to match the desired state
- AVAILABLE state shows the number of replicas AVAILABLE to the users
kubectl scale deploy/booklistkube2 --replicas=4makes the number of pods to 4kubectl get pods -o widewill also show IP and NODEkubectl get deploy booklistkube2will now show the scaling up eventkubectl describe services <service-name>shows 4 endpoints asIP:4321(4 different IP and one common port).- creating replicas will automatically be added to the service
- open
kubectl get pods -w,kubectl get deploy -w,kubectl get replicaset -win 3 pane and scale/edit a deployment in another pane and see the changes :D- replicaset name + different extension = different pod name
- scaling up/down doesn't change the replicaset name - because old pods are useful. but updating deployment replaces every pod - so new replicaset name and pod name.
- Rolling updates allow deployments' update to take place with zero downtime by incrementally updating pods instances with new ones.
- By default, the max no of pods that can be unavailable during the update and the max no of new pods that can be created, is one. Both options can be configured to either number or percentage. Updates are versioned and can be reverted back to previous version.
- Similar to application Scaling, if a deployment is exposed publicly, the Service will load-balance the traffic only to available Pods during the update.
kubectl set image deploy/booklistkube2 <container-name>=<new-image-name>changes imagekubectl rollout status deploy/booklistkube2shows rollout statuskubectl rollout undo deploy/booklistkube2reverts back to previous versionkubectl get eventskubectl config view
- https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
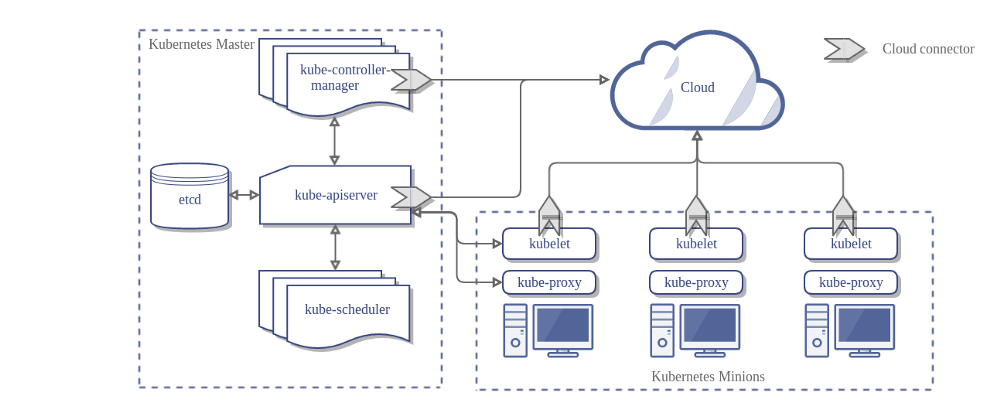
- K8s Master is collection of these process: kube-apiserver, kube-controller, kube-scheduler
- Each non-master node has two processes:
- kubelet, which communicates with the K8s Master
- kube-proxy, a network proxy which reflects K8s networking services on each node
- Various parts of the K8s Control Plane, such as the K8s Master and kubelet processes, govern how K8s communicates with your cluster.
- Open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation.
- A container platform/a microservices platform/a portable cloud platform and a lot more.
- [Google's Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across a number of clusters each with up to tens of thousands of machines.]
- Continuous Integration, Delivery, and Deployment (CI/CD)
- Kubernetes is not a mere orchestration system. In fact, it eliminates the need for orchestration. The technical definition of orchestration is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes is comprised of a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C. Centralized control is also not required.
- why containers?
- The Old Way to deploy applications was to install the applications on a host using the operating-system package manager. This had the disadvantage of entangling the applications’ executables, configuration, libraries, and lifecycles with each other and with the host OS. One could build immutable virtual-machine images in order to achieve predictable rollouts and rollbacks, but VMs are heavyweight and non-portable.
- The New Way is to deploy containers based on operating-system-level virtualization rather than hardware virtualization. These containers are isolated from each other and from the host: they have their own filesystems, they can’t see each others’ processes, and their computational resource usage can be bounded. They are easier to build than VMs, and because they are decoupled from the underlying infrastructure and from the host filesystem, they are portable across clouds and OS distributions.
- Containers are small and fast. So one-to-one application-to-image relation if built.
- The name Kubernetes originates from Greek, meaning helmsman or pilot, and is the root of governor and cybernetic. K8s is an abbreviation derived by replacing the 8 letters
ubernetewith8
- Master components provide the cluster's control plane - makes global decisions, e.g. scheduling, detecting, responding
- Master components can be run on any machine in the cluster - usually set up scripts start all master components on the same machine and do not run user containers on this machine.
kube-apiserverexposes k8s api - front end for k8s control plane. designed to scale horizontally, that is - it scales by deploying more instances (QJenny - vertical scaling is creating new replicas with increased resources?)etcdis key value store used as k8s' backing store for all cluster data.kube-schedulerschedules newly created pods to nodes based on individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interface and deadlines.kube-controller managerruns controllers. Logically, each controller is a seperate process, but to reduce complexity, they are all compiled into a single binary and run in a single processNode Controlleris responsible for noticing and responding when nodes go downReplication Controlleris responsible for maintaining correct number of podsEndpoints Controllerpopulates the Endpoints object (joins Services and Pods)Service Account & Token Controllerscreate default accounts and API access tokens for new namespaces.
cloud-controller-managerruns controllers that interact with the underlying cloud providers. It runs cloud-provider-specific controller loops only, must disable these controller loops in the kube-controller-manager by setting--cloud-providerflag toexternal. It allows cloud vendors code and k8s core to evolve independent of each other. In prior releases, the core k8s code was dependent upon cloud-provider-specific code for functionality. In future releases, code specific to cloud vendors should be maintained by the cloud vendor themselves, and linked to cloud-controller-manager while running k8s. These controllers have cloud provider dependencies:Node Controllerfor checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding.Route Controllerfor setting up routes in the underlying cloud infrastructureService Controllerfor creating, updating and deleting cloud provider load balancersVolume Controllerfor creating, attaching and mounting volumes, and interacting with the cloud provider to orchestrate volumes
kubeletruns on each in the cluster, takes a set of PodSpecs and ensures that the containers are running and healthy.kube-proxyenables k8s service abstraction by maintaining network rules on the host and performing connection forwardingContainer Runtimeis the software that is responsible for running containers, e.g. Docker, rkt, runc, any OCI runtime-spec implementation
- Addons are pods and services that implement cluster features. They may be managed by Deployments, ReplicationControllers. Namespaced addon objects are created in
kube-systemnamespace.- UJenny
DNS- all k8s clusters should have cluster DNS, as many examples rely on it. Cluster DNS is DNS server, in addition to the other DNS server(s) in your environment, which serves DNS records for k8s services. Containers started by k8s automatically include this DNS server in their DNS searches- UJenny
Web UI(Dashboard)Container Resource Monitoringrecords generic time-series metrics about containers in a central database and provides a UI for browsing that data- UJenny
Cluster-level Loggingis responsible for saving container logs to central log store with search/browsing interface- UJenny
- https://kubernetes.io/docs/concepts/overview/kubernetes-api/
- UJenny
- API continuously changes
- to make it easier to eliminate fields or restructure resource representation, k8s supports multiple API versions, each at a different API path, such as
/api/v1or/apis/extensions/v1beta1 - Alpha: e.g,
v1alpha1. may be buggy. - Beta: e.g,
v2beta3. code is well tested - Stable: e.g,
v1. will appear in released software.
- K8s objects represent the state of a cluster. They can describe
- what containerized applications are running on which nodes
- available resources
- policies areound how those applications behave (restart, upgrade, fault-tolerance)
- Objects represents the cluster's desired state
kubectlis used to create/modify/delete the objects through api calls. alternatively, client-go can be used- Every k8s object has two field - the object spec is provided, it describes desired state. The object status describes the actual status of the object. k8s control plane actively manages actual state to match the desired state
- deployment is an object. spec can have no of replicas to make. it one fails, k8s replaces the instance.
- k8s api is used (either directly or via kubectl) to create an object. that API request must have some information as JSON in the request body. I provide the information to kubectl in a
.yamlfile. kubectl convert the info to JSON
kind:
metadata:
name:
labels:
app:
spec:
replicas:
template:
metadata:
name:
labels:
app:
spec:
containers:
- name:
image:
imagePullPolicy: IfNotPresent
ports:
- containerPort:
restartPolicy: Always
selector:
matchLabels:
app:
- Deployment struct
apiVersiondefines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. +optionalkindKind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. Cannot be updated. +optionalmetadataStandard object metadata. +optionalnameName must be unique within a namespace. Cannot be updated. +optionallabelsMap of string keys and values that can be used to organize and categorize (scope and select) objects. May match selectors of replication controllers and services. +optionaluidUID is the unique in time and space value for this object. It is typically generated by the server on successful creation of a resource and is not allowed to change on PUT operations. +optional
specSpecification of the desired behavior of the Deployment. +optionalreplicasNumber of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1. +optionaltemplateTemplate describes the pods that will be created.metadataStandard object's metadata. +optionalnamesamelabelssameappsame
specSpecification of the desired behavior of the pod. +optionalcontainersList of containers belonging to the pod. Containers cannot currently be added or removed. There must be at least one container in a Pod. Cannot be updated.nameName of the container specified as a DNS_LABEL. Each container in a pod must have a unique name (DNS_LABEL). Cannot be updated.imageDocker image name. This field is optional to allow higher level config management to default or override container images in workload controllers like Deployments and StatefulSets. +optional (QJenny)imagePullPolicyImage pull policy. One of Always, Never, IfNotPresent. Defaults to Always if :latest tag is specified, or IfNotPresent otherwise. Cannot be updated. +optional- Always means that kubelet always attempts to pull the latest image. Container will fail If the pull fails.
- Never means that kubelet never pulls an image, but only uses a local image. Container will fail if the image isn't present
- IfNotPresent means that kubelet pulls if the image isn't present on disk. Container will fail if the image isn't present and the pull fails.
portsList of ports to expose from the container. Exposing a port here gives the system additional information about the network connections a container uses, but is primarily informational. Not specifying a port here DOES NOT prevent that port from being exposed. Any port which is listening on the default "0.0.0.0" address inside a container will be accessible from the network. Cannot be updated. +optionalcontainerPortNumber of port to expose on the pod's IP address. This must be a valid port number, 0 < x < 65536.restartPolicyRestart policy for all containers within the pod. One of Always, OnFailure, Never. Default to Always. +optional
selectorLabel selector for pods. Existing ReplicaSets whose pods are selected by this will be the ones affected by this deployment. It must match the pod template's labels. (Selector selects the pods that will be controlled. if the matchLabels is a subset of a pod, then that pod will be selected and will be controlled.)matchLabelsmatchLabels is a map of {key,value} pairs. A single {key,value} in the matchLabels map is equivalent to an element of matchExpressions, whose key field is "key", the operator is "In", and the values array contains only "value". The requirements are ANDed. +optional. type: map[string]stringappis a key
- QJenny - what is +optional? (Nahid: +optional thakle user empty dite parbe, na dile nil hobe. +optional na thakle na dile empty hobe??? :/ )
apiVersion,kind,metadatais required.
- All objects in the Kubernetes REST API are unambiguously identified by a Name and a UID. For non-unique user-provided attributes, Kubernetes provides labels and annotations.
- name is included in the url
/api/v1/pods/<name> - max length 253. consists of lowercase alphanumeric, '-' and '.' (certain resources have more specific restrictions)
- A Kubernetes systems-generated string to uniquely identify objects.
- Every object created over the whole lifetime of a Kubernetes cluster has a distinct UID. It is intended to distinguish between historical occurrences of similar entities.
- Namespaces are intended for use in environments with many users spread across multiple teams, or projects. For clusters with a few to tens of users, you should not need to create or think about namespaces at all. Start using namespaces when you need the features they provide. Namespaces provide a scope for names. Names of resources need to be unique within a namespace, but not across namespaces.
- It is not necessary to use multiple namespaces just to separate slightly different resources, such as different versions of the same software: use labels to distinguish resources within the same namespace.
kubectl get namespacesto view namespaces in a clusterdefaultthe default namespace for objects with no other namespacekube-systemfor objects created by k8s systemkube-publicis crated automatically and readable by all users(including not authenticated). mostly reserved for cluster usage, in case some resources should be visible and readable publicly
kubectl create ns <new_namespace_namecreates a namespacekubectl --namespace=<non-default-namespace> run <deployment-name> --image=<image-name>kubectl get deploy --namespace=<new-namespace>if not mentioned, kubectl uses default namespaces. so you won't see the deployment created in previous comamnd if you don't mention this namespace namekubectl get deploy --all-namespacesshows all deployments under al namespaces- similar
--namespaceflag for all deloy/pod/service/container commands kubectl delete ns <new-namespace>deletes a namespacekubectl config viewshows the file~/.kube/config- clusters: here we have only minikube cluster, with its certificates and server. minikube cluster is running in that ip:port.
192.168.99.100(minikube ip) comes from here - users: kubectl communicates with k8s api, as a user(name: minikube (UJenny)). that user is defined here with its certificates and stuff
- context: configurations - we have one context. a context has cluster/user/namespace/name
- UJenny
- clusters: here we have only minikube cluster, with its certificates and server. minikube cluster is running in that ip:port.
kubectl config current-contextshows current-context field of the config filekubectl config set-context $(kubectl config current-context) --namespace=<ns>sets a ns as default, any changes you make/create objects will be done to this namespace- most k8s resources (pods, services, replication controllers etc.) are in some namespaces. low-level resources (nodes, persistentVolumes) are not in namespace.
kubectl api-resourcesshows all--namespaced=trueshows which are in some namespace--namespaced=falseshows which are not in a namespace
- When you create a Service, it creates a corresponding DNS entry. This entry is of the form ..svc.cluster.local, which means that if a container just uses , it will resolve to the service which is local to a namespace.
- This is useful for using the same configuration across multiple namespaces such as Development, Staging and Production. If you want to reach across namespaces, you need to use the fully qualified domain name (FQDN).
- to specify identifying attributes of objects - meaningful and relevant (but do not directly imply semantics to the core system). used to organize and seelect subsets of objects. can be attached at creation/added/modified.
- key can be anything, but have to be unique (within a object). e.g,
release,environment,tier,partition,track - Labels are key/value pairs. Valid label keys have two segments: an optional prefix and name, separated by a slash (/). The name segment is required and must be 63 characters or less, beginning and ending with an alphanumeric character ([a-z0-9A-Z]) with dashes (-), underscores (
_), dots (.), and alphanumerics between. The prefix is optional. If specified, the prefix must be a DNS subdomain: a series of DNS labels separated by dots (.), not longer than 253 characters in total, followed by a slash (/). If the prefix is omitted, the label Key is presumed to be private to the user. Automated system components (e.g. kube-scheduler, kube-controller-manager, kube-apiserver, kubectl, or other third-party automation) which add labels to end-user objects must specify a prefix. The kubernetes.io/ prefix is reserved for Kubernetes core components. - many objects can have same labels
- via a label selector, the client/user can identify a set of objects. the label selector is the core grouping primitive in k8s
- current, the API supports two types of selectors: equality-based and set-based. A label selector can be made of multiple requirements, which are comma-separated - acts as a logical AND(&&).
- An empty label selector selects every object in the collection
- A null label selector (which is only possible for optional selector fields) selects no objects (UJenny)
- The label selectors of two controllers must not overlap within a namespace, otherwise they will fight with each other.
- equality or inequality based requirements allow filtering by label keys and values. matching objects must satisfy ALL of the specified label constraints, though they may have additional labels as well.
- three kinds of operator are admitted
=,==,!=. first two are synonyms.environment = productionselects all resources with key equalenvironmentand value equal toproductiontier != frontendselects all resources with key equal totierand value distinct fromfrontendand all resources with no labels with thetierkey.environment=production, tier!=frontendselects resources inproductionexcludingfrontend- usually, pods are scheduled to nodes, based on various criteria. If we want to limit the nodes a pod can be assigned to
kind: Pod metadata: name: cuda-test spec: containers: - name: cuda-test image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 nodeSelector: accelerator: nvidia-tesla-p100 - Pod Struct
kind,metadatasamespec(podSpec) samecontainerssamename,imagesameresourcesCompute Resources required by this container. Cannot be updated. +optionallimitsLimits describes the maximum amount of compute resources allowed. +optional (this is of type ResourceList. ResourceList is a set of (resource name, quantity) pairs.)nvidia.com/gpuis resource name, whose quantity is1nodeSelectorNodeSelector is a selector which must be true for the pod to fit on a node. Selector which must match a node's labels for the pod to be scheduled on that node. +optionalaccelerator: nvidia-tesla-p100is a node label
- set-based label requirements allow one key with multiple values.
- three kinds of operators are supported:
in,notinandexists(only key needs to be mentioned) environment in (production, qa)selects all resources with key equal toenvironmentand value equal toproductionORqa. (of course OR, it cannot be AND, can it? a resource cannot have multiple values for one key)tier notin (frontend, backend)selects all resources with key equal totierand values other thanfrontendandbackendand all resources with no labels with thetierkeypartitionselects all resources including a label with keypartition, no values are checked!partitionselects all resources without the keypartition; no values are checked- comma acts like a AND
- so
partition, environment notin (qa)means the keypartitionhave to exist andenvironmenthave to be other thanqa(UJenny, will the resources with noenvironmentbe selected?)
- so
- Set-based requirements can be mixed with equality-based requirements. For example:
partition in (customerA, customerB), environment!=qa
- LIST and WATCH both are allowed to use using labels
- in URL:
- equality-based:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - set-baed:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
- equality-based:
- both selector style can be used to list or watch via REST client. e.g, targeting
apiserverwithkubectlkubectl get pods -l environment=production, tier=frontendkubectl get pods -l 'environment in (production), tier in (frontend)'
- set-based requirements are more expressive - they can implement OR operator
kubectl get pods -l 'environment in (production, qa)'selectsqaorproductionkubectl get pods -l 'environment, environment notin(frontend)'selects resources which hasenvironmentand it cannot befrontend(if i wroteenvironment notin(frontend)only, it would select the resources which doesn't haveenvironmentkey also)
servicesandreplicationcontrollersalso use label selectors to select other resources aspods- only equality-based requirements are supported (UJenny: is this restriction for deploy/pods too?)
- newer resources, such as
job,deployment,replicaset,daemon setsupport set-baed requirements
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
matchExpressionsis a list of label selector requirements. The requirements are ANDed. +optionalkeyis the label key that the selector applies to. type: stringoperatorrepresents a key's relationship to a set of values. Valid operators are In, NotIn, Exists and DoesNotExist.valuesis an array of string values. If the operator is In or NotIn, the values array must be non-empty. If the operator is Exists or DoesNotExist, the values array must be empty. This array is replaced during a strategic merge patch. +optional (UJenny: merge patch?)
- All of the requirements, from both matchLabels and matchExpressions are ANDed together – they must all be satisfied in order to match.
- to attach arbitrary non-identifying metadata to objects. Clients such as tools and libraries can retrieve this metadata.
- labels are used to identify and select objects. annotations are not.
- can include characters not permitted by labels
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
- Instead of using annotations, you could store this type of information in an external database or directory, but that would make it much harder to produce shared client libraries and tools for deployment, management, introspection, and the like. (UJenny: examples are given)
- select k8s objects based on the value of one or more fields.
kubectl get pods --field-selector status.phase=Runningselects all pods for which the value ofstatus.phaseisRunningmetadata.name=my-service,metadata.namespace!=default,status.phase=Pending- using unsupported fields gives error
kubectl get ingress --field-selector foo.bar=bazgives errorError from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"(UJenny: what the f is ingress) - supported operator are
=,==,!=(first two are same).kubectl get services --field-selector metadata.namespace!=default kubectl get pods --field-selector metadata.namespace=default,status.phase=RunningANDed- multiple resource types can also be selected
kubectl get statefulsets,services --field-selector metadata.namespace!=default
- multiple resource is also allowed for labels too:
kubectl get pod,deploy -l run=booklistkube2also works
- A Kubernetes object should be managed using only one technique. Mixing and matching techniques for the same object results in undefined behavior.
Management techniques Operates on Recommended environment Supported writers Learning curve
Imperative commands Live objects Development projects 1+ Lowest
Imperative object configuration Individual files Production projects 1 Moderate
Declarative object configuration Directories of files Production projects 1+ Highest
kubectl run nginx --image nginxkubectl create deployment nginx --image nginx- simple, easy to learn, single step
- doesn't record changes, doesn't provide template
kubectl create -f nginx.yamlkubectl delete -f <name>.yaml -f <name>.yamlkubectl replace -f <name>.yaml- Warning: The imperative replace command replaces the existing spec with the newly provided one, dropping all changes to the object missing from the configuration file. This approach should not be used with resource types whose specs are updated independently of the configuration file. Services of type LoadBalancer, for example, have their externalIPs field updated independently from the configuration by the cluster. (UJenny)
- compared with imperative commands:
- can be stored, provides template
- must learn, additional step writing YAML
- compated with declarative object config:
- simpler and easier to learn, more mature
- works best on files, not directories. updates to live objects must be reflected in config file or they will be lost in next replacement
- When using declarative object configuration, a user operates on object configuration files stored locally, however the user does not define the operations to be taken on the files. Create, update, and delete operations are automatically detected per-object by kubectl. This enables working on directories, where different operations might be needed for different objects. UJenny
- Note: Declarative object configuration retains changes made by other writers, even if the changes are not merged back to the object configuration file. This is possible by using the patch API operation to write only observed differences, instead of using the replace API operation to replace the entire object configuration. UJenny
kubectl diff -f configs/to see what changes are going to be madekubectl apply -f configs/process all object configuration files in the configs directorykubectl diff -R -f configs/,kubectl apply -R -f configs/recursively processs directories- changes made directly to live objects are retained, even if they are not merged. has better support for operating on directories and automatically detecting opeartion types (create, patch, delete) per-object
- harder to debug and understand results, partial updates using diffs create complex merge and patch operations.
- UJenny: the whole thing
run: create a new deploy to run containers in one or more podsexpose: create a new service to load balance traffic across podsautoscale: create a new autoscaler object to automatically horizontally scale a controller, such as a deployment.create: driven by object typecreate <objecttype> [<subtype>] <instancename>kubectl create service nodeport <name>
scalehorizontally scale a controller to add or removeannotateadd or remove an annotationlabeladd or remove a labelsetset/edit an aspect (env, image, resources, selector etc) of an objecteditdirectly edit the config filepatchdirectly modify specific fields of a live object by using a patch string (UJenny)deletedeletes an objectgetdescribelogsprints the stdout and stderr for a container running in a podkubectl create service clusterip <name> --clusterip="None" -o yaml --dry-run | kubectl set selector --local -f - 'environment=qa' -o yaml | kubectl create -f -createcommand cannot take every fields as flags. used create + set to do this (usingsetcommand to modify objects before creation)kubectl create service -o yaml --dry-runcommand creates the config file for the service, but prints it to stdout as YAML instread sending it to k8s API--dry-runif it is true, only print the object that would be sent, without sending it.
kubectl set selector --local -f - -o -yamlreads the config file from stdin, write the updated configuration to stdout as YAMLkubectl create -f -command creates the object using the config provided via stdin- UJenny:
--local
kubectl create service clusterip <name> --clusterip="None" -o yaml --dry-run > /tmp/srv.yaml
kubectl create --edit -f /tmp/srv.yaml
- `kubectl create service` creates the config for the service and saves it to `/tmp/srv.yaml`
- `kubectl create --edit` open the config file for editiog before creating
kubectl create -f <filename/url>creates an object from a config filekubectl replace -f <filename/url>- Warning: Updating objects with the replace command drops all parts of the spec not specified in the configuration file. This should not be used with objects whose specs are partially managed by the cluster, such as Services of type LoadBalancer, where the externalIPs field is managed independently from the configuration file. Independently managed fields must be copied to the configuration file to prevent replace from dropping them. UJenny
kubectl delete -f <filename/url>UJenny - how does this work?- ever if changes are made to live config file of the object -
delete <object-config>.yamlalso works too
- ever if changes are made to live config file of the object -
kubectl get -f <filename/url> -o yamlshow objects.-o yamlshows the yaml file- limitation: created a deployment from a yaml file. edited the
kubectl edit deploy <name>(note that, this is not the yaml file from which I created the object. this is calledlive configuration). thenkubectl replace -f <object-config>.yamlcreates the object from scratch. the edit is gone. works for every kind of object. kubectl applyif multiple writers are needed.kubectl create -f <url> --editedits the config file from the url, then create the object.kubectl get deploy <name> -o yaml --export > <filename>.yamlexports the live object config file to local config file- then remove the status field (interestingly, the status field is automatically after exporting, although
kubectl get deploy <name> -o yamlhas the status field) - then run
kubectl replace -f <filename>.yaml - this solves the
replaceproblem
- then remove the status field (interestingly, the status field is automatically after exporting, although
- Warning: Updating selectors on controllers is strongly discouraged. (UJenny: because it would affect a lot?)
- The recommended approach is to define a single, immutable PodTemplate label used only by the controller selector with no other semantic meaning. (significant labels. doesn't have to be changed again)
object config filedefines the config for k8s object.live object config/live configvalues an object, as observed by k8s cluster. this is typically stored inetcddeclaration config writer/declarative writera person or software component that makes updates to a live object.
- worker machine in k8s, previously knows as
minion - maybe vm or physical machine
- each node contains the services necessary to run pods
- the services on a node include docker, kubelet, kube-proxy
- a node's status contains - addresses, condition, capacity, info
- Node is a top-level resource in the k8s REST API.
- usage of these fields depends on your cloud provider or bare metal config
HostNamethe hostname as reported by the node's kernel. can be overridden via the kubelet--hostname-overrideparameterExternalIPavailable from outside the clusterInternalIPwithin the cluster
- describes the status of all running nodes
OutOfDiskTrueif there is insufficient free space on the node for adding new pods, otherwiseFalseReadyTrueif the node is healthy and ready to accept pods,Falseif the node is not healthy and is not accepting pods andUnknownif the node controller has not heard from the node in the lastnode-monitor-grace-period(default is 40 seconds)MemoryPressureTrueif pressure exists on the node memory - that is, if the node memory is low; otherwiseFalsePIDPressureTrueif pressure exists on the processes - that is, if there are too many processes on the node, otherwiseFalseDiskPressureTrueif pressure exists on the disk size - that is, if the disk capacity is low; otherwiseFalseNetworkUnavailableTrueif the network for the node is not correctly configured, otherwiseFalse
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
- if the status of the
Readycondition remainsUnknownorFalsefor longer thanpod-eviction-timeout(default 5m), an argument is passed tokube-controller-managerand all the pods on the node are scheduled for deletion by Node Controller. if apiserver cannot communicate with kubelet on the node, the deletion decision cannot happen until the communication is established again. in the meantime, the pods on the node continues to run, inTerminatingorUnknownstate. - prior to version 1.5, node controller force deletes the pods from the apiserver. from 1.5, if k8s cannot deduce if the node has permanently left the cluster, admin needs to delete the node by hand. then all pods will be deleted with the node.
- in version 1.12,
TaintNodesByConditionfeature is promoted to beta,so node lifecycle controller automatically creates taints that represent conditions. Similarly the scheduler ignores conditions when considering a Node; instead it looks at the Node’s taints and a Pod’s tolerations. users can choose between the old scheduling model and a new, more flexible scheduling model. A Pod that does not have any tolerations gets scheduled according to the old model. But a Pod that tolerates the taints of a particular Node can be scheduled on that Node. Enabling this feature creates a small delay between the time when a condition is observed and when a taint is created. This delay is usually less than one second, but it can increase the number of Pods that are successfully scheduled but rejected by the kubelet. (UJenny)
- describes the resources available on the node: cpu, memory, max no of pods that can be scheduled
- general information about the node, such as kernel version, k8s (kubelet, kube-proxy) version, docker version, os name. these info are gathered by kubelet
- unlike pods and services, a node is not inherently created by k8s. it is created by cloud providers, e.g, google compute engine or it exists in your pool of physical or vm. so when k8s creates a node, it creates an object that represents the node. then k8s checks whether the node is valid or not.
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
- k8s creates a node object internally (the representation) and validates the node by health checking based on `metadata.name`. if it is valid, it is eligible to run a pod. otherwise, it is ignored for any cluster until it becomes valid. k8s keeps the object for the invalid node and keeps checking. to stop this process, you have to explicitly delete this node.
- there are 3 components that interact with the k8s node interface: node controller, kubelet, kubectl
- k8s master component which manages varioud aspects of nodes
- first role is assigning a CIDR block to a node when it is registered (if CIDR assignment is turned on) (UJenny)
- second is keeping the node controller's internal list of nodes up to date with the cloud provider's list of available machines. when a node is unhealthy, the node controller asks the cloud provider if the vm for that node is still available. if not, the node controller deletes the node from its list of nodes.
- third is monitoring the nodes' health. the node controller is responsible for updating the NodeReady condition of NodeStatus to ConditionUnknown when a node becomes unreachable and then later evicting all the pods from the node if the node continues to be unreachable(
--node-monitor-grace-periodis 40s andpod-eviction-timeoutis 5m by defautl). the node controller checks the state of each node every--node-monitor-periodseconds (default 5s) (QJenny where are these flags???) - prior to 1.13, NodeStatus is the heartbeat of a node. from 1.13, node lease feature is introduced. when this feature is enabled, each node has an associated
Leaseobject inkube-node-leasenamespace. both NodeStatus and node lease are treated as heartbeats. Node leases are updated frequently and NodeStatus is reported from node to master only when there is some change or some time(default 1 minute) has passed, which is longer than default timeout of 40 seconds for unreachable nodes. Since node lease is much more lightweight than NodeStatus, this feature makes node heartbeat cheaper. - Node controller limits the eviction rate to
--node-eviction-rate(default 0.1) per second, meaning it won't evict pods from more than 1 node per 10 seconds.- If your cluster spans multiple cloud provider availability zones (otherwise its one zone), node eviction behavior changes when a node in a given availability becomes unhealthy.
- Node controller checks the percentage of unhealthy nodes (
NodeReadyisFalseorConditionUnknown). If the fraction is at least--unhealthy-zone-threshold(default 0.55) then the eviction rate is reduced - if the cluster is small (less than or equal to--large-cluster-size-threshold, default 50 nodes), then evictions are stopped, otherwise the eviction rate is reduced to--secondary-node-eviction-rate(default 0.01) per second. - This is done because one availability zone might become partitioned from the master while the others remain connected.
- Key reason for spreading the nodes across availability zone is that workload can be shifted to healthy zones when one entire zone goes down.
- Therefore if all nodes in a zone are unhealthy then node controller evicts at the normal rate
--node-eviction-rate - Corner case is, if all zones are completely unhealthy, node controller thinks there's some problem with master connectivity and stops all evictions until some connectivity is restored.
- Starting in Kubernetes 1.6, the NodeController is also responsible for evicting pods that are running on nodes with NoExecute taints, when the pods do not tolerate the taints. Additionally, as an alpha feature that is disabled by default, the NodeController is responsible for adding taints corresponding to node problems like node unreachable or not ready. See this documentation for details about NoExecute taints and the alpha feature. Starting in version 1.8, the node controller can be made responsible for creating taints that represent Node conditions. This is an alpha feature of version 1.8. (UJenny)
- When the kubelet flag
--register-nodeis true (the default), the kubelet will attempt to register itself with the API server. --kubeconfigpath to credentials to authenticate itself to the apiserver--cloud-providerhow to talk to a cloud provider to read metadata about itself--register-nodeautomatically register with the API server--register-with-taintsregister the node with the given list of taints (comma separated =:) No-op ifregister-nodeis false--node-ipip address of the node--node-labelslabels to add when registering the node in the cluster--node-status-update-frequencyspecifies how often kubelet posts node status to master
Manual Node Administration (UJenny)
- Number of cpus and amount of memory
- Normally nodes register themselves and report their capacity when creating node object
- K8s scheduler ensures that there are enough resources for all thepods on a node. The sum of the requests of containers on the node must be no greater than the node capacity. (It includes all containers started by the kubelet, not the ones started directly by dockers nor any process running outside of the containers)
- If you want to explicitly reserve resources for non-pod processes, you can create a placeholder pod.
apiVersion: v1
kind: Pod
metadata:
name: resource-reserver
spec:
containers:
- name: sleep-forever
image: k8s.gcr.io/pause:0.8.0
resources:
requests:
cpu: 100m
memory: 100Mi
- set the cpu and memory values to the amount of resources you want to reserve. Place the file in the manifest directory (`--config=DIR` flag of kubelet). do this on every kubelet you want to reserve resources. QJenny
- communication paths between the master (really the apiserver) and the k8s cluster.
- to allow users to customize their installatin to run the cluster on an untrusted network or on fully public IPs on a cloud provider
- all communicatin paths from the cluster to master terminate at the apiserver (
kube-apiserver, which exposes k8s api. it is designed to expose remote services) - in a typical deployment, the apiserver is configured to listen for remote connections on a secure https port (443) with one or more forms of client authentication enable, which is necessary if annonymous requests of service account tokens are allowed (UJenny)
- nodes should be provisioned with the public root certificate for the cluster such that they can connect securely to the apiserver along with valid client credentials. for example, on a default GKE(Google Kubernetes Engine) deployment, the client credentials provided to the kubelet are in the form of a client certificate.
- pods that wish to connect to the apiserver can do so securely by taking a 'service account' so that k8s will automatically inject the public root certificate and a valid bearer token into the pod when it is instactiated.
- the
kubernetesservice (in all namespaces) is configured with a virtual IP address that is redirected (viakube-proxy) to the https endpoint on the apiserver - the master components also communicate with the cluster apiserver over the secure port
- so, the default operating mode for connections from the cluster (nodes and pods running on the nodes) to the master is secured by default and can run over untrusted and/or public network
- two primary communication paths from the master(apiserver) to the cluster
- from the apiserver to the kubelet process
- from the apiserver to any node, pod or service through the apiserver's proxy functionality
- used for
- fetching logs for pods
- attaching (through kubectl) tp running pods
- providing the kubelet's port-forwarding functionality
- these connecions terminate at the kubelet's https endpoint.
- by default, apiserver doesn't verify the kubelet's serving certificate, which makes the connection subject to man-in-the-middle attacks, and unsafe to run over untrusted and/or public networks
- to verify this connection, use the
--kubelet-certificate-authorityflag to provide the apiserver with a root certificate bundle to use to verify the kubelet's serving certificate - if that is not possible, use
SSH tunnelingbetweent the apiserver and kubelet if required to avoid connecting over an untrusted or public network - finally, kubelet authentication and/or authorization shouldb be enabled to secure the kubelet API
- these are default to plain http connections and are therefore neither authenticated nor encrypted.
- they can be run over a secure https connection by prefixing
https:to the node, pod or service name in the API URL, but they will not validate the certificate provided by the https endpoint nor provide client credentials - so while the connection will be encrypted, it will not provide any guarantees of integrity. - these connections are not currently safe to run over untrusted and/or public networks.
- this concept was originally created to allow cloud specific vendor code and k8s core to evolve independent of one another. (UJenny - vendor code)
- it runs alongside other master components such as the k8s controller manager, the api server, and scheduler. it can also be started as k8s addon, in which case it runs on top of k8s
- CCM's design is based on a plugin mechanism that allows new cloud providers to integrate with k8s by using plugins
- there are plans for migrating cloud providers from the old model to the new ccm model
- here k8s and cloud provider are integrated with 3 different components - kubelet, k8s controller manager, k8s api server
- here, single point of integration with cloud
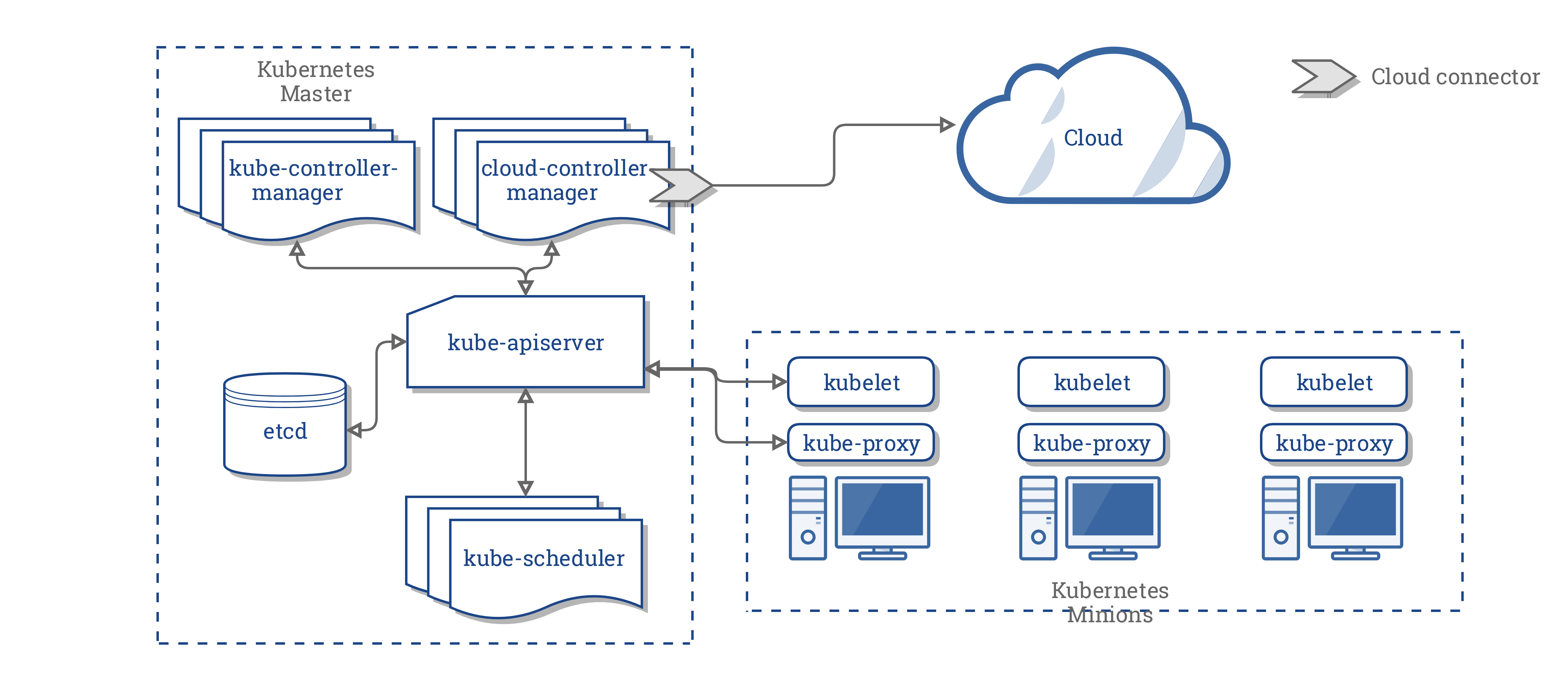
- CCM breaks away cloud dependent controller loops from kcm - Node controller, volume controller, router controller, service controller
- from 1.9, due to the complexity involved and due to the existing efforts to abstract away vendor specific volume logic, volume controller is not moved to ccm. instead ccm runs another controller called PersistentVolumeLabels controller. this controller is responsible for setting the zone and region labels on PersistentVolumes created in GCP and AWS clouds (UJenny is volumed controller still in or not? if in, who controls it?)
- the original plan to support volumes using CCM was to use Flex volumes to support pluggable volumes. However, a competing effort known as CSI is being planned to replace Flex. Considering these dynamics, we decided to have an intermediate stop gap measure until CSI becomes ready (UJenny)
- majority of ccm's functions are derived from the kcm
node controlleris responsible for initializing a node by obtaining information about the nodes running in the cluster from the cloud provider. does the following functions- intialize a node with cloud specific zone/region labels
- initialize a node with cloud specific instance details, e. g, type and size
- obtain the node's network addresses and hostname
- if a node becomes unresponsive, check the cloud to see if the node has been deleted form the cloud. if deleted, delete the k8s node object
route controlleris responsible for configuring routes in the cloud appropriately so that containers on different nodes can communicate with each other. route controller is only applicable for Google Compute Engine clusters (QJenny nodes can communicate with each other??? why and how do they do that?)service controlleris responsible for listening to service create, update and delete events. Based on the current state of services, it configures cloud load balancers (such as ELB(Elastic Load Balancing) or Google LB) to reflect the state of the services in k8s.PersistentVolumeLabels controllerapplies labels on AWS EBS(Amazon Web Services, Elastic Block Store)/GCE PD(Google Compute Engine Persistent Disk) volumes when they are created. removes the need for users to manually set the labels on these volumes.- these labels are essential for the scheduling of pods as these volumes are constrained to work only within the region/zone that they are in. (pods need to be attached to volumes only in same region/zone - because otherwise they would be connected to remote network connection.) (shudipta said if they are in different network - they should use NFS (network file system) volume type)
- this controller was created for ccm. it was done to move the PV labelling logic in the k8s api server to the CCM (before it was an admission controller). it doesn't run on the KCM.
- node controller contains the cloud-dependent functionality of the kubelet. before CCM, the kubelet was responsible for initializing a node with cloud-specific details such as IP addresses, region/zone labels and instance type information
- now, this initialization operation is moved to CCM
- kubelet initializes a node without cloud-specific information.
- and adds a taint to the newly created node that makes the node unschedulable until the CCM initializes the node with cloud-specific information. kubelet then removes the taint. (UJenny - again. what's taint?)
- the PersistentVolumeLabels controller moves the cloud-dependent functionality of the K8s API server to CCM
- CCM uses Go interfaces to allow implementations from any cloud to be plugged in.
- it uses the CloudProvider Interface defined here (UJenny)
- the implementations of four shared controllers above and shared cloudprovider interface (and some other things) will stayRather than specifying the current desired state of all replicas, pod templates are like cookie cutters. Once a cookie has been cut, the cookie has no relationship to the cutter. There is no “quantum entanglement”. Subsequent changes to the template or even switching to a new template has no direct effect on the pods already created. Similarly, pods created by a replication controller may subsequently be updated directly. This is in deliberate contrast to pods, which do specify the current desired state of all containers belonging to the pod. This approach radically simplifies system semantics and increases the flexibility of the primitive.
- in k8s core.
- implementation specific to cloud providers will be built outside of the core and implement interfaces defined in the core
- node controller only works with node objects. requires full access to
Get,List,Create,Update,Patch,Watch,Delete(v1/Node) - route controller listens to Node object creation and configures routes appropriately. requires
Getaccess to Node objects (v1/Node) - service controller listens to service object create, update and delete events and then configures endpoints for those services appropriately. (v1/Service)
- To access services, it requires
ListandWatchaccess. - To update services, it requires
PatchandUpdateaccess. - To set up endpoints for the services, it requires access to
Create,List,Get,Watch,Update
- To access services, it requires
- PersistentVolumeLabels controller listens on PersistentVolume (PV) create events and then updates them. requires access to get and update PVs through v1/PersistentVolume:
Get,List,Watch,Updateaccess - others: the implementation of the core CCM requires access to create events and to ensure secure operation, it requires access to create ServiceAccounts through v1/Event:
Create,Patch,Updateand v1/ServiceAccount:Create - kind: ClusterRole UJenny
- cloud providers implement CCM to integrate with k8s - so that cluster can be hosted on these cloud providers? (UJenny)
Containers (UJenny)
- default pull policy is
IfNotPresentwhich causes the kubelet to skip pulling. - to always force a pull, one of these can be done
- set the imagePullPolicy to
Always - omit the imagePullPolicy and use
:latestas tag (not best practice) - omit imagePullPolicy and the tag for the image (UJenny - omit both? test)
- enable the
AlwaysPullImagesadmission controller (UJenny)
- set the imagePullPolicy to
- smallest deployable object
- a pod represents a running process on your cluster
- a pod encapsulates
- one or multiple containers
- storage resources
- a unique network IP
- options that govern how the container(s) should run.
- two ways:
- pods that run a single container: most common use case, a pod just wraps around a container. kubernetes manages the pods rather than the containers
- pods that run multiple containers that need to work together: tightly coupled containers and need to share resources. these co-located containers might form a single cohesive unit of service - one container serving files from a shared volume to the public, another container refreshes or updates those files.
- replication: horizontal scaling (multiple instances)
- the containers in a pod are automatically co-located and co-scheduled on the same physical or virtual machine in the cluster.
- they can share resources and dependencies, communicate with one another, and coordinate when and how they are terminated.
- it's a advanced use case. only use when they are tightly coupled. for example, one container acts as a web server for files in a shared volume and another one updates those files from a remote source.
- pods provide two kinds of shared resources for their containers: networking and storage.
- networking: each container in a pod shares the network namespace, including the IP address and network ports. they communicate with one another using
localhost. (QJenny how???) - when containers in a pod communicate with entities outside the Pod, they must coordinate how they use the shared network resources (such as ports)
- storage: a pod can specify a set of shared storage volumes. All containers in the pod can access the shared volumes. Volumes also allow persistent data in a Pod to survive in case one of the containers within needs to be restarted
- networking: each container in a pod shares the network namespace, including the IP address and network ports. they communicate with one another using
- you'll rarely create individual pods directly
- pods can be created directly by me or indirectly by Controller
- pod remains in the scheduled Node until the process is terminated, pod object is deleted, pod is evicted for lack of resources or Node fails
- the pod itself doesn't run, but it is an environment the containers run in and persists until it is deleted
- pods don't self-heal. if a pod is scheduled to a node that fails or if scheduling operation itself fails, the pod is deleted. and pods don't survive evictiion due to lack of resources or Node maintenance
- k8s uses a higher-level abstraction, called a controller, that handles the work of managing the relatively disposable Pod instances.
- although it is possible to use Pod directly, it's far more common to manage pods using a Controller
- A controller can create and manage multiple pods, handling replication and rollout and providing self-healing capabilities at cluster scope. for example, if a Node fails, the controller might automatically replace the Pod by scheduling an identical replacement on a different Node
- some examples of controller - deployment, StatefulSet, DaemonSet
- pod templates are pod specifications which are included in other objects such as Replication Controllers, Jobs, DaemonSets.
- controllers use pod templates to make actual pods.

apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
- rather than specifying the current desired state of all replicas, pod templates are like cookie cutters. once a cookie has been cut, the cookie has no relationship to the cutter.
- subsequent changes to the template or even switching to a new template has no direct effect on the pods already created.
- changes to the template doesn't affect the pods already created
- Similarly, pods created by a replication controller may subsequently be updated directly. this is in deliberate contrast to pods, which do specify the current desired state of all containers belonging to the pod. (after creating pods with controller, the pods can be updated separately with
kubectl edit pod <name>. it will affect only the specific pod) - a pod models an application-specific "logical host". [before: same physical/virtual machine] = [now: same logical host]
- the shared context of a pod is a set of Linux namespaces, cgroups, and other aspects of isolation (same things that isolate Docker container)
cgroups(control groups) is a Linux kernel feature that limits, accounts for and isolates the resource usage(CPU, memory, disk I/O, network etc) of a collection of processes.
- within a pod's context, the individual applications may have further sub-isolations applied.
- as mentioned before, containers in same pod share an IP address and port space and can find each other via
localhost. they can also communicate using standard inter-process communications likeSystemV semaphoresorPOSIXshared memory. (UJenny: what?) - containers in different pods have distinct IP addresses and cannot communicate by IPC (interprocess communication) without special configuration (UJenny)
- containers in different pods communicate usually with each other via pod ip addresses.
- applications within a pod also have access to shared volumes, which are defined as part of a pod and are made available to be mounted into each applicaion's filesystem.
- pods are of "short life". after pods are created, they are assigned a unique ID (UID), scheduled to nodes where they remain until termination or deletion.
- a pod is defined by UID
- If a node dies, pods are scheduled for deletion after a timeout period. they are not rescheduled, instead it is replaced by an identical pod, if desired with same name but with a new UID
- when something is said to have same lifetime as a pod, such as a volume, it exists as long as that specific pod (with that UID) exists. if the pod is deleted, volume is also destroyed. even if an identical pod is replaced, volume will be created anew.
- pods are unit of deployment, horizontal scaling, replication
- colocation (coscheduling), shared fate(e.g, termination), coordinated replication, resource sharing, dependency management are handled automatically in a pod
- applications in a pod must decide which one will use which port (one container is exposed in one port)
- each pod has an IP address in a flat shared networking space that can communicate with other physical machines and pods across the network
- the hostname is set to the pod's name for the application containers within the pod
- volumes enable data to survive container restarts and to be shared among the applicatiions within the pods
- uses of pods UJenny
- individual pods are not intended to run multiple instances of the same application
- why not just run multiple programs in a single container?
- transparency: helps the infrastructure to manage them, for example, process management and resoruce monitoring.
- decoupling software dependencies: they maybe be versioned, rebuilt, redeployed independently. k8s may even support live updates of individual containers someday.
- ease of use. users don't need to run their process managers (because infrastructure manages them?)
- efficiency: infrastructure takes on more responsibility, containers can be light weight
- Why not support affinity-based co-scheduling of containers? That approach would provide co-location, but would not provide most of the benefits of pods, such as resource sharing, IPC, guaranteed fate sharing, and simplified management. UJenny
- controllers (such as deployement) provides self-healing, replication, rollout management wiht a cluster scope, that's why pods should use controllers, even for singletons
- pod is exposed as a primitive in order to facilitate : UJenny
- as pods represent running processes on nodes in the cluster, it is important to allow those processes to gracefully terminate instead of being killed with a KILL signal
- when a user requests for deletion of a pod
- the system records the intended grace period before the pod is forcefully killed
- a TERM signal is sent to main processes of containers of the pod
- once the grace period is over, KILL signal is sent to those processes (of containers)
- then pod is deleted from API server
- if kubelet or container manager is restarted while waiting for processes to terminate, termination will be tried again with full grace period.
- an example flow -
- user sends commands to delete a pod with grace period of 30s
- the pod in the API server is updated with the last-alive-time and grace period
kubectl get podswill showTerminatingfor the pod. when the kubelet sees theTerminatingmark, it begins the process (the following subpoints happen simulaneously with this step)- if the pod has defined a
preStop hook, it is invoked inside of the pod. preStopis called immediately before a container is terminated. it must complete before the call to delete the container can be sent. of typeHandler- if the
preStophook is still running after grace period expires, 2nd step again - API server is updated with 2 second of grace period again. - the processes are sent TERM signal
- pod is removed from endpoints list for service, are no longer part of the set of running pods for replication controllers
- pods that shutdown slowly cannot continue to serve traffic as load balancers (like the service proxy) remove them from their rotations (UJenny)
- when the grace perios expires, running processes are killed with SIGKILL
- kubelet will finish deleting the pod on the API server by setting grace period to 0s (immediate deletion).
- default grace period is 30s.
kubectl deletehas--grace-period=<second>- to force delete set
--grace-periodto 0 along with--force - force deletion of a pod: doesn't wait for kubelet confirmation from the node. the pod is deleted from the apiserver immediately and a new pod is created with the same name. on the node, pods that are set to terminate will be given a small grace period before being killed.
- using
privilegedflag on theSecurityContextof the container (not pod) spec enables priviledge mode. it allows the containers to use linux capabilities like manipulating the network stack and accessing devices. all processes in a container get same privileges usually. with privileged mode, it is easier to write network and volume plugins as separate pods that don't need to be compiled in kubelet - privileged mode is enabled from k8s v1.1. If the master is v1.1 or higher, but node is below, privileged pods will be created (accepted in apiserver) but will be in pending state. if master is below v1.1, pods won't be created.
- pod's status field is a
PodStatusobject, which has aphasefield. (current condition of the pod)PendingThe Pod has been accepted by the Kubernetes system, but one or more of the Container images has not been created. This includes time before being scheduled as well as time spent downloading images over the network, which could take a while.RunningThe Pod has been bound to a node, and all of the Containers have been created. At least one Container is still running, or is in the process of starting or restarting.SucceededAll Containers in the Pod have terminated in success, and will not be restarted.FailedAll Containers in the Pod have terminated, and at least one Container has terminated in failure. That is, the Container either exited with non-zero status or was terminated by the system.UnknownFor some reason the state of the Pod could not be obtained, typically due to an error in communicating with the host of the Pod.
- PodStatus has a
PodConditionarray (current service state of the pod)- Details UJenny
conditions: - lastProbeTime: null lastTransitionTime: 2018-12-11T08:54:48Z status: "True" type: Initialized - lastProbeTime: null lastTransitionTime: 2018-12-12T04:01:42Z status: "True" type: Ready - lastProbeTime: null lastTransitionTime: 2018-12-11T08:54:48Z status: "True" type: PodScheduled
- A probe is a diagnostic performed periodically by kubelet on a container. container struct has two member of this type (liveness and readiness)
- to perform a diagnostic, kubelet calls a Handler
- Probe struct - Probe describes a health check to be performed against a container to determine whether it is alive or ready to receive traffic.
HandlerThe action taken to determine the health of a container. 3 types of handlers-ExecActionExecutes a specified command inside the Container. The diagnostic is considered successful if the command exits with a status code of 0. takes a command as an element of this structTCPSocketActionPerforms a TCP check against the Container’s IP address on a specified port. The diagnostic is considered successful if the port is open. takes the port as element. takes host name to connect to, default to pod ip. (UJenny - host name???)HTTPGetActionPerforms an HTTP Get request against the Container’s IP address on a specified port and path. The diagnostic is considered successful if the response has a status code greater than or equal to 200 and less than 400. takes path, port, host (default to pod ip) as element of this structInitialDelaySecondsof typeint32- Number of seconds after the container has started before liveness probes are initiated.
- each probe has one of three results:
- success: the container passed the diagnostic
- failure: failed the diagnostic
- unknown: the diagnostic itself failed, so no action should be taken
- the kubelet can optionally perform and react to two kinds of probes on running containers:
livenessProbeIndicates whether the Container is running. If the liveness probe fails, the kubelet kills the Container, and the Container is subjected to its restart policy. If a Container does not provide a liveness probe, the default state is Success. (UJenny what does it mean by "doesn't provide liveness probe"?)readinessProbeIndicates whether the Container is ready to service requests. If the readiness probe fails, the endpoints controller (UJenny there's a endpoints controller?) removes the Pod’s IP address from the endpoints of all Services that match the Pod. The default state of readiness before the initial delay is Failure. If a Container does not provide a readiness probe, the default state is Success.
- when should we use which probe?
- if process in container is able to crash on its own whenever it becomes unhealthy - probes aren't needed - kubelet will take care of it with pod's
restartPolicy - if container needs to be killed and restarted if a probe failt - liveness probe + restartPolicy of Always or OnFailure
- if container needs to send traffic only when a probe succeeds - readiness probe. in previous case, readiness or liveness if fine. but readiness in the spec means that the pod will start without receiving any traffic and starts receiving traffic only after readiness probe starts succeeding
- if container works on loading large data, configuration files or migrations during startup - readiness (UJenny why?)
- If you want your Container to be able to take itself down for maintenance, you can specify a readiness probe that checks an endpoint specific to readiness that is different from the liveness probe. UJenny
- if you want to avoid requests when pod is deleted, no need of readiness probe. on deletion, pod automatically put itself into an unready state, remains in that state while it waits for the containers to stop (UJenny then what happens?)
- if process in container is able to crash on its own whenever it becomes unhealthy - probes aren't needed - kubelet will take care of it with pod's
- PodStatus has a member - a list of
ContainerStatusUJenny - PodSpec has a new member from v1.11 -
ReadinessGate- If specified, all readiness gates will be evaluated for pod readiness. A pod is ready when all its containers are ready AND all conditions specified in the readiness gates have status equal to "True". +optional. contains a list of PodConditionType
Kind: Pod ... spec: readinessGates: - conditionType: "www.example.com/feature-1" status: conditions: - type: Ready # this is a builtin PodCondition status: "True" lastProbeTime: null lastTransitionTime: 2018-01-01T00:00:00Z - type: "www.example.com/feature-1" # an extra PodCondition status: "False" lastProbeTime: null lastTransitionTime: 2018-01-01T00:00:00Z containerStatuses: - containerID: docker://abcd... ready: true ...
to be ready, all the containers of the pod must be ready and readiness gates must be true. mentional the conditions in readinessGates and if that condition doesn't exist in status.conditions - it will be considered false.
The new Pod conditions must comply with Kubernetes label key format. Since the kubectl patch command still doesn’t support patching object status, the new Pod conditions have to be injected through the PATCH action using one of the KubeClient libraries. (UJenny, https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#pod-readiness-gate)
restartPolicy of a pod means restart of all containers of the pod. UJenny https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
Pods with a phase of Succeeded or Failed for more than some duration (determined by terminated-pod-gc-threshold in the master) will expire and be automatically destroyed.
3 types of controllers are available - 1. job - for pods that expected to terminate- with restartpolicy onFailure or never (ex. batch computations) 2. ReplicationController, ReplicaSet, or Deployment - for Pods that are not expected to terminate, for example, web servers. restartpolicy always 3. Use a DaemonSet for Pods that need to run one per machine, because they provide a machine-specific system service.
If a node dies or is disconnected from the rest of the cluster, Kubernetes applies a policy for setting the phase of all Pods on the lost node to Failed.
UJenny pod examples - https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#examples
all init containes must complete before app containers are started. podStatus has status.initContainerStatuses diff from regular - resources. don't support readinessProbe because they must run to completion before they can be ready run one after another ex-
- if something cannot be run in app container for security reasons, it is included in init
- for setup. there is no need to make an image FROM another image just to use a tool like sed, awk, python, or dig during setup. QJenny
- application image builder and deployer roles
- uses linux namespaces, so has access to secrets that app container cant have
- block or delay the startup of app containers until some pre-conditions are met
exaples: UJenny https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#examples
apiVersion: v1
kind: Pod
metadata:
name: initonservice
labels:
app: initonservice
spec:
containers:
- name: initonservice
image: busybox
command:
- sh
- -c
- while true; do echo app is running; sleep 1; done
imagePullPolicy: IfNotPresent
initContainers:
- name: init-myservice
image: ubuntu
command:
- sh
- -c
- "apt-get update; apt-get install dnsutils -y; until nslookup myservice; do echo waiting for myservice; sleep 2; done"
- name: init-mydb
image: ubuntu
command:
- sh
- -c
- "apt-get update; apt-get install dnsutils -y; until nslookup mydb; do echo waiting for mydb; sleep 2; done"
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
---
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
until command in busybox doesn't work. so used ubuntu and installed dnsutils (which includes nslookup).
nslookup <service-name>.default.svc.cluster.local this command works
if your /etc/resolve.conf contains
search default.svc.cluster.local svc.cluster.local cluster.local
mentioning only <service-name> will work
kubectl logs <pod-name> -c <container-name>to see logs of a container inside a pod
detailed behavior: UJenny https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#detailed-behavior
if the Pod restartPolicy is set to Always, the Init Containers use RestartPolicy OnFailure.
k8s struct - https://github.com/kubernetes/kubernetes/blob/master/pkg/apis/settings/types.go#L29 it is an api resource. used to injecting additional runtime requirements into a pod at creation time. label selector is used to select pods for podPreset by using pod template, we don't have to explicitly provide all the info to pod template. authors of pod template don't need to know all details of a service hes consuming
- the PodPreset (admission controller) applies Pod Presets to incoming pod creating requests.
- when a pod creation occurs, the system retrieves all
PodPresetsavaialable for use, selects the pod that has labels matched with selector of PodPresets. then it attempts to merge the resources defined by podPreset with the pod and document the error if merge error happens. finally, annotate the resulting pod specifying it has been modified by a PodPreset. the annotation is of the formpodpreset.admission.kubernetes.io/podpreset-<pod-preset name>: "<resource version>" - PodPreset has the following field -
selector,Env,EnvFrom,Volumes,VolumeMounts - changes in env, envfrom, volumemounts, k8s modifies all container spec
- changes in volume, k8s modifies the pod spec
- no resource definition from PodPreset will be applied to initContainers
- to disable pod preset to specific pod, annotate the podSpec as
podpreset.admission.kubernetes.io/exclude: "true" - to enable podPreset: https://kubernetes.io/docs/concepts/workloads/pods/podpreset/#enable-pod-preset
Pods do not disappear until someone (a person or a controller) destroys them, or there is an unavoidable hardware or system software error.
https://kubernetes.io/docs/concepts/workloads/pods/disruptions/
- diff with replicationController - it supports set-based selector requirement, while replicatonController suppoprt only equality-based selector requirements
rolling-updatedoesn't support replicaset, but supports replication controllers and deployment. for rolling-update, deployment is recommended- deployment + rollout is recommended"
- if the labels of the replicaset is empty, it is defaulted to the pods it manages
replicasdefault to 1containers.portslists the ports to expose FROM THE CONTAINER. keeping it empty doesn't prevent a port to be exposed. so in our book app, we exposed 4321. we could leave this field. UJenny - if we didn't expose the port in Dockerfile, would exposing the port in this field make it work???containers.commandoverwrites entrypoint of docker image.resourcescpu, memory, storage, ephemeral-storage- after pods are created, changing
containers.envdidn't change podscontainers.env. but through deployment, it did. - so replicaset's job is to control only replicas
- if you deploy a pod, then change the
replicasinreplicasetconfig under that deploy, it will only changeCURRENT, that means it will create/terminte the pods, but as deploy controlsDESIRED, so no of pods won't change ultimately. finally, config of replicaset will be restored as before - but if you create pod by replicaset, it will control
DESIREDtoo - you should not normally create any pods whose labels match this selector, either directly, with another ReplicaSet, or with another controller such as a Deployment. If you do so, the ReplicaSet thinks that it created the other pods.
- metadata.labels do not affect the behavior of the ReplicaSet.
kubectl delete replicaset <name>will the delete the rs and its podskubectl delete replicaset <name> --cascade=falsewill delete only the replicaset, but not the pods (you can create a new replicaset to control these pods by matchingselectors)- you can isolate a pod from a rs by changing its labels. (these pods will be replaced to meet the
replicasdemand) - spec.template is required
- pod restart policy should be
Always(default) - selector must match with
spec.template.metadata.labels - selectors should selected carefully, overlap could select unwanted pods. it doesn't care if the pods are created/deleted by it or others. so rs can be easily replaced
- isolating pods from a replicaset: change pod labels
- you can isolate a pod from a rc by changing its labels. (these pods will be replaced to meet the
replicasdemand) - spec.template is required
- pod restart policy should be
Always(default) - selector must match with
spec.template.metadata.labels - selectors should selected carefully, overlap could select unwanted pods. it doesn't care if the pods are created/deleted by it or others. so rc can be easily replaced
metadata.labelsdefaults tospec.template.metadata.labels- no rc is created after a deployment
- even if you need a bare pod, rs/rc/deploy are recommended - to keep one instance running
containerslist of containers belonging to the pod. cannot be currently added or removedkubectl rollout status deploy <name>kubectl get pods --show-labels- deployment creates pods and automatically make labels with
pod-template-hash-value - replicaset name = deploy-name + pod-template-hash-value (UJenny - k8s said this should match, in my pc, doesn't match)
- don't change pod-template-hash label (it is generated by hashing PodTemplate)
- deleting a deploy, deletes the corresponding replicaset
- updating podTemplate of a deploy, creates a new replicaset, but don't destroy the old one - just makes replicas = 0
deploymentspec.revisionHistoryLimitnumber of old replicasets to allow rollback - defaults to 10. if 0, all replicaset with 0 replica will be deleted
spec:
progressDeadlineSeconds: 600
replicas: 5
revisionHistoryLimit: 2
selector:
matchLabels:
run: booklistkube2
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
...
spec.strategyhastype. if this is =RollingUpdate,spec.strategy.rollingUpdatewill havemaxSurgeandmaxUnavailable. value can be percentage or absolute number- if maxSurge is 30%, total no of old + new pods do not exceed 130% of desired no of pods, default 25%, rounds up
- if maxUnavailable is 30%, total no of old + new pods is at least 70% of desired no of pods, default 25%. rounds down
- rollout is triggered iff pod template is changed
Rollover (aka multiple updates in-flight)if you update again in middle of a previous update, deployment will stop scaling up previous and start killing those updates (in other words, it will be "old") and start new updates- in
apps/v1, selector labels cannot be changed - selector addition: pod labels must be updated too - otherwise validation error
- selector removal: doesn't require pod labels to be changed (no new replicaset created, still not recommended) -h new revision is created if pod template is changed
- added a bad image, then scaled up. deployment created new pods from old replicaset too (and bad image pods too, maxSurge matched = total bad/good/old/new pods
CURRENT) - this happened because of
Proportional Scaling. new/old - two version are running. after new scaling, bigger proportion will go to most replicas and lower proportiont to replicaset with less replica. (that's why maxUnavailable didn't match I guess) 0-replicaset are not scaled up. - if you add a bad image, replicas - maxUnavailable = old replicas
kubectl set image deploy <name> <container-name>=<new-image> --record=true
--record=true to kubectl comamnds (create/edit) will record the command in Deployment annotation kubernetes.io/change-cause, you can modify this manually too, --record=true overwrites manual change
kubectl rollout history deploy <name> will show history with change-cause.
kubectl rollout history deploy <name> --revision=<revision-no> will datailed change in that revision
kubectl rollout undo deploy <name> does back to previous revision
- rolling back will bring that revision to top
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 kubectl edit deploy booklist4 --record=true
6 kubectl edit deploy booklist4 --record=true
7 changing to bad image
kubectl rollout undo deploy <name> --to-revision=2 goes back to revision-2
kubectl scale deploy <name> --replicas=10
kubectl autoscale deploy <name> --min=10 --max=15 --cpu-percent=80 based on cpu utilization of your existing pods (this command auto-changes replicas in live-config of deploy, creates a hpa object) //UJenny cpu utilization?
kubectl rollout pause deploy <name> to pause a deploy. (this doesn't disable the pods). notice that, it only pauses "rollout" changes. if you scale, it will continue to scale based on last state before pause.
///now change as much as you want
kubectl rollout resume deploy <name> now it will be counted as one rollout (change cause will the last annotation, because all the changes will be counted as one change, the last state before resume)
//you cannot rollback a paused deploy
deployspec.MinReadySeconds min number of seconds after pods are considered available from being ready. default 0s. (its ready after container probes (readiness/liveness) are passed)
deployspec.progressDeadlineSeconds max time in seconds, for which deployment progressing time should remain. after that, it will be considered failed. default 600s.
minReadySeconds must be greater than progressDeadlineSeconds, otherwise, even if they are valid, they won't be ready before progressDeadline
kubectl patch deploy booklist4 -p '{"spec":{"replicas":17}}' patch command by json
kubectl patch deploy booklist4 -p $'spec:\n replicas: 18' patch by yaml
kubectl patch deploy booklist4 -p $(cat patch.yaml)
rollout pause will pause a deploy in middle of a rollout, and will stop counting against progressDeadline. status.conditions.type = Progressing will have status unknown in middle of pause + rollout. but it will continue to "work" and create/terminate pods. status is False if progress failed
echo $? will show exit code of last command. so this command after rollout status will show 0 if rollout is succeeded, 1 otherwise
failed rollouts don't enter into rollout history
//pod template conditions are exact as wrote in rc/rs
-
created a bare pod
-
created a deployment with same label
-
doesn't effect on the pod
-
replicaset has a
pod-template-hash -
added this label to the bare pod
-
this pod is not controlled by the deployment
-
a controller controls pods only by selectors. internal spec doesn't matter.
-
changed spec of the bare pod - doesn't matter
-
spec.selectorand.metadata.labelsdefaults tospec.template.metadata.labelsfor rs/rc. but not deployment. you have to mention explicitly (apps/v1). selector is immutable
- pods with consistent identity - network and storage
- guarantess a given network will always map to the same storage identitiy
- ordered and graceful deployment/scaling
- ordered and automated rolling updates
- limitations: need to create a headless service, PersistentVolume provisioner, deleting/scaling doesn't delete the volumes (for data safety)
serviceNameis the service that govern the statefulset. it must exist before the statefulset. responsible for network identity of the set- pods has dns/hostname like :
pod-specific-string.serviceName.default.svc.cluster.local,pod-specific-stringis managed by statefulset controller.cluster.localis the cluster-domain - like deployment, gotta mention
spec.selector
spec.volumeClaimTemplates.spec.accessModes will can have values ReadWriteOnce, ReadOnlyMany, ReadWriteMany
-
ordinal indexfor n replicas, each pod will the receive integer ordinal - 0 to n-1 -
stable network idhostname of each pod - stateful_name-ordinal_index, e.g, book-0, book-1 etc. -
the headless service controls the domain of the pods.
-
the domain takes the form
service-name.namespace.svc.cluster.local(so this is the service domain) wherecluster.localis cluster domain -
now each pod gets its matching dns subdomain as
podname.service-domain -
another example of pod dns :
web-0.nginx.jennyns.svc.kube.local -
statefulset adds a label to each pod -
statefulset.kubernetes.io/pod-name(helps to attach service) -
there's another label i can see -
controller-revision-hashUJenny -
pods are created 0 to n-1, deleted n-1 to 0
-
after web-1 is created, if web-0 is failed, web-2 won't be launched before web-0 is relaunched
-
all predecessors of a pod must ready before scaling operation of a pod and all successors must be completely shutdown before termination
-
stateful pods should not be force deleted. so
pod.spec.terminationPeriodSecondsmust not be 0. it is the difference between termination signal to processes in the pods and the kill signal. so it must be longer than expected cleanup time of processes. defualts to 30s. -
if scaled down from 3 to 1, web-0 will remain. if web-0 fails after web-2 is terminated, web-1 won't terminate before web-0 is relaunched
-
relax ordering policy by
spec.podManagementPolicy. can beOrderedReadyorParallel. at most one pod is changed in first one
updateStrategy:
rollingUpdate:
partition: 0
type: RollingUpdate
-
spec.UpdateStrategycan be oftype-RollingUpdateandOnDelete. default is first one. -
rollingupdate updates the pod according to ordering constraints. terminates and creates the pod right after termination in decreasing order
-
onDelete will happen only when we delete pods manually (legacy behavior - difficult to replace), and then replace that pod with new pod that reflects the update
-
rollingupdate.partitionupdate (by changingspec.template) will happen to those >= to the ordinal. even if the non-update pods are deleted they will created by previous template. can be > #replicas, in that case, no update will happen. useful to stage an update, previous version, roll out canary (canary release) -
experiment: did a bad image update, last pod got stuck while creating, corrected the mistake, still stuck (i guess for ordering constraints), manually deleted the pod,
-
deleting a random pod (rollingupdate strategy) will create that pod again. no problem with ordering constraint
-
doesn't start en event before finishing one? unlike deployment? made a bad image to web-0, scaled down. didn't scaled down - got stuck in ImagePullBackOff
- service defines a logical set of pod and a policy to access them
- For Kubernetes-native applications, Kubernetes offers a simple Endpoints API that is updated whenever the set of Pods in a Service changes. For non-native applications, Kubernetes offers a virtual-IP-based bridge to Services which redirects to the backend Pods.
- service, pods are REST objects. they can be POSTed to apiserver to create new instances
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
- selector selects pods. if not mentioned, its assumed external process is managing its endpoints which k8s will not modify. ignored if service.type is ExternalName
- selector are evaluated constantly and will be POSTed to
Endpointsobject named like the service
kubectl get endpoints shows all endpoints with their pod-ip
apiVersion: apps/v1
kind: Deployment
metadata:
name: booklist5
labels:
app: booklist5
spec:
replicas: 2
template:
metadata:
name: booklist5
labels:
app: booklist5
spec:
containers:
- name: booklist51
image: kfoozminus/booklistgo
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
- name: booklist52
image: kfoozminus/booklist:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 4321
name: exposed
- containerPort: 80
name: ashi
restartPolicy: Always
selector:
matchLabels:
app: booklist5
---
apiVersion: v1
kind: Service
metadata:
name: booklist5
spec:
selector:
app: booklist5
ports:
- targetPort: exposed
port: 1234
name: exposeds
- targetPort: 8080
port: 5050
name: exposeds2
- targetPort: ashi
port: 50
name: ashis
type: NodePort
- this deployment has one pod. the pod has 2 containers. one container exposed 8080 to the pod
container.ports.containerPort(optional field, this doesn't preventEXPOSE 8080in the Dockerfile), which gets mapped to 5050service.spec.ports.portin the service with the nameexposeds2. other container has 2 ports exposed, with the nameexposedandashi. these two gets mapped to 1234 and 50, by mentioning the names inservice.spec.ports.targetPort(this field can be string or int32). the service will have a clusterID, determined by master. total 3 ports and the deploy has 2 replicas - so total 6 endpoints. so you can access this service by clusterIP:port, from inside the cluster. and by minikube-ip:nodePort, from outside the cluster. and access a specific pod with podIP:targetPort from inside the cluster - if targetPort is string/name, this name can have different ports in different pods, that are managed by that service - so if you change port in a pod, you don't break anything
minikube ssh enter your minikube cluster
service.ports.name must be included if there's more than one port
- services without selectors
- Real life example
- https://github.com/appscode/service-broker/blob/master/hack/dev/service_for_locally_run.yaml#L10
kind: Service
apiVersion: v1
metadata:
name: myendpointservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 8080
---
kind: Endpoints
apiVersion: v1
metadata:
name: myendpoint
subsets:
- addresses:
- ip: 10.0.2.2
ports:
- port: 8080
-
usually when we use selectors, service creates some
Endpointsobject. here we are using no selector, but manually creating endpoints -
used when cluster needs to access something on your local machine
-
subsets.addressesare used to access a specific endpoint byipandportfrom inside a cluster. final addresses can be found by cartesian product ofipandport. -
when controlling pods,
ipcontains all pod-ip's andportcontains all the exposed port from the containers in a pod. so. cartesian product, right? -
10.0.2.2gets the host machine from the VM. we can access this ip inside the cluster (as pod-ip) -
ran a go server (which is running on localhost:8080 in my pc), now enterd
minikube sshand accesses this go server by10.0.2.2- how does this work? where do we get this ip? -
endpoint live-config file for previous service example
subsets:
- addresses:
- ip: 172.17.0.38
nodeName: minikube
targetRef:
kind: Pod
name: booklist5-db76c94f5-qm7js
namespace: default
resourceVersion: "478338"
uid: 908f99de-02b9-11e9-8af4-080027893a7d
- ip: 172.17.0.45
nodeName: minikube
targetRef:
kind: Pod
name: booklist5-db76c94f5-hgll5
namespace: default
resourceVersion: "478301"
uid: 8f49deca-02b9-11e9-8af4-080027893a7d
ports:
- name: exposeds2
port: 8080
protocol: TCP
- name: ashis
port: 80
protocol: TCP
- name: exposeds
port: 4321
protocol: TCP
-
note that,
subsetsis an array. we think like - same things are in same set (as cartesian product thing is going on) -
nodeNamein which node the pod is -
ports.namemust be included if there's more than one port -
theory how it works(kube-proxy, userspace, proxy-mode) https://kubernetes.io/docs/concepts/services-networking/service/#virtual-ips-and-service-proxies
-
clusterIPis usually assigned by master. users can mention too.Noneas value will create headless service. -
route -nshows routing table in any machine -
each node has
kube-proxy. responsible for implementing virtual ip. -
proxy-mode:userspacekube-proxy watches master for change inserviceandendpoints. opens a port in local node(minikube?). any connections toproxy portwill be proxied to one of the pods. pod is selected uponSessionAffinity. then with iptables, clusterIP (virtaul ip) and port to proxy-port which proxies the backend pod. chooses backend with round-robin -
proxy-mode:iptableswatches master. installs iptable, clusterIP and port to service'sbackend sets. each endpoint, install iptable, selects a pod. chooses backend by random. doesn't switch between userspace and kernelspace. so faster. but cannot automaticallt retry another pod if one pod is down. so depends on workingreadiness probes -
proxy-mode:ipvsipvs not just round-robin. has least connection, destination hashing, source hashing, shortest expected delay, never queue -
with any proxy-model, any traffic is routed from service-ip:port to backend without client knowing anything about k8s/service/pods.
-
spec.SessionAffinitycan be clientIP or None. default is none. UJenny what's this? -
spec.sessionAffinityConfig.clientIP.timeoutSecondsis 10800 (3 hours) by default if sessionAffinity is clientIP. UJenny -
must be within
service-cluster-ip-range. apiserver return 442 if it is invalid -
why not round-robin dns? https://kubernetes.io/docs/concepts/services-networking/service/#why-not-use-round-robin-dns UJenny
-
discovers services in 2 ways - env and dns
-
enter a pod
kubectl execandenv- you will see ALL the service ip and port -
dns: if enabled, services can be discovered from any pod from dns record
<service-name>.ns. also supportsDNS SRV'. -
if you want to query for port named http with tcp protocol : then you can do DNS SRV (service) query for
_http._tcp.service-name.nsQJenny -
dns server is the only way to access
ExternalName -
headless service -
spec.clusterIPisNone(typeisClusterIPby default) -
kube-proxy doesn't handle these services, no load-balancing or proxying done
-
headless with selectors: creates endpoints records in api, modifies dns config to return addresses that points to pods backing the service
-
without selectors: QJenny https://kubernetes.io/docs/concepts/services-networking/service/#without-selectors
-ClusterIP is for inside the cluster
-
NodePortmaster will allocate anodePortin the--service-node-port-range(default: 30000 ~ 32767). if you try to hit that nodeip:nodeport from outside, it will be proxied to the service. here, nodeip = any-node-ip, nodeport is same (service.spec.ports.nodePort) -
NodePortalso createsClusterIP -
a specific ip can be set by
--nodeport-addressesflag in kube-proxy QJenny -
loadBalancerwe cannot add loadBalancer in minikube, as we don't have any. It createsNodePortandClusterIPtoo. created a loadBalancer type service and test the nodePort -
QJenny - what's the difference betweeen
spec.externalIPandspec.loadBalancerIP -
https://kubernetes.io/docs/concepts/services-networking/service/#loadbalancer
-
loadBalancerIPis only for typeLoadBalancer,externalIPcan be for others? -
if loadBalancerIP is added, sanjid vai said, outsiders can hit
loadBalancerIP:port(service.spec.ports.port) -
UJenny ExternalName https://kubernetes.io/docs/concepts/services-networking/service/#externalname
-
UJenny ExternalIP https://kubernetes.io/docs/concepts/services-networking/service/#external-ips
-
UJenny can I test externalIP with my localhost/realip? do I put ip of the master node here in real life?
-
UJenny we never hit an address with any port. does that mean they always listen to port 80?
-
UJenny https://kubernetes.io/docs/concepts/services-networking/service/#shortcomings
-
UJenny ip-vip, userspace-iptables-ipvs https://kubernetes.io/docs/concepts/services-networking/service/#the-gory-details-of-virtual-ips
-
services get dns name
-
kubedns server return A record
-
a pod in
foonamespace will lookupsvc1bysvc1and a pod in another ns will look up this bysvc.foo -
A record: normal (not headless) services are assigned DNS A record for a name (resolves to
ClusterIP). headless services are also assigned similarlysvcname.ns.svc.cluster.local, but resolves to set of IPs of the pods. (enter a pod and usenslookupto check services. you'll get one ip for normal service and multiple ip's for headless service) clients have to consume the set or select using round robin -
SRV record: for normal service,
_port-name._protocol.myservice.ns.svc.cluster.localwould resolve into port number and domain namemyservice.ns.svc.cluster.localand for headless service, it would resolve into (for each pod) port number and pod domainauto-generated-name-for-pod.myservice.ns.svc.cluster.localUJenny -
pod domain:
pod-ip-address.ns.pod.cluster.local1.2.3.4 would get DNS A record1-2-3-4.default.pod.cluster.local(with port 80) -
you can't change any field in the pod spec other than image/activeDeadlineSeconds/tolerations
-
pod.spec.hostnamegets thepod.spec.nameif not specified.pod.spec.namegets system-defined-value if not specified. you can check hostname by entering the pod and shell commandhostname -
QJenny - experiment: https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#pod-s-hostname-and-subdomain-fields
- sleep = 1, 5, 20, 3600
- at first, created it without the port. nslookup doesn't get the service.
- deleted. again, created without port. nslookup gets it. then configured and deleted the port. nslookup now gets the service.
-
put
pod.spec.subdomainas it's service'sname, then the pod will get dng A record with the namepod-hostname.subdomain.ns.svc.cluster.local(FQDN - fully qualified domain name) -
so pod gets 2 A record? one in
pod.cluster.local, another insvc.cluster.local(if subdomain is specified) -
UJenny DNS policy https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#pod-s-dns-policy
-
if a node dies, pod dies too. new pods are created with new ip. service solves the problem. new pods are linked to that service.
kubectl exec <pod-name> -- echo hi prints hi in your terminal
- pods only gets env of those services, which was created before the pod.
BOOKLISTKUBE2_PORT_4321_TCP_PORT=4321
BOOKLISTKUBE2_PORT_4321_TCP_PROTO=tcp
BOOKLISTKUBE2_SERVICE_HOST=10.104.123.160
BOOKLISTKUBE2_PORT_4321_TCP=tcp://10.104.123.160:4321
QJenny CoreDNS cluster addon, kube-dns
- if container crashes, every data is lost
- k8s volume has same lifetime as pod. if container crashes, volume outlives.
- docker is at the root of the filesystem hierarchy. volumes cannot mount into other volumes
awsEBScontents of an ebs volume are preserved when the pod dies, just merely unmountedcephfsdata is preserved. unmounted when pod dies
ConfigMap (Object)
ConfigMapobject holds config data for pods to consumekubectl create configmap <config-name> --from-file=<file-name>adds files asConfigMap.data
data:
game.properties: |-
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
|-leaves the trailing newline- you can use
--from-filemultiple times to mention multiple files --from-env-fileto bring from a env-file (containsVAR=VALformat. strings in the value can be attached too)- multiple
--from-env-fileuses only last one
allowed: '"true"'
enemies: aliens
lives: "3"
-
here file-name is the key-name
-
to change the key-name, you can mention
--from-file=<key-name>=<file-name> -
--from-literal=<key>=<value> -
containers can consume data from config
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
valueFromcan be used ifvalueis not used- in the above code, you can also attach command to echo the env.
containers:
- name: test-container
image: k8s.gcr.io/busybox
command: [ "/bin/sh", "-c", "ls /etc/config/" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
containers.volumeMounts.namemust matchvolumes.name.containers.volumeMount.mountPathcontainers.volumeMount.readOnlycontainers.volumeMount.subPathvolumes.configMap.namecan locate an object (LocalObjectReference) (in same namespace)volumes.configMap.itemsif not specified, takes all, else takes the specified ones. key = filename, value = content
volumeMounts:
- name: game-config-volume-mount
mountPath: /home/jenny
volumes:
- name: game-config-volume-mount
configMap:
name: game-config
items:
- key: game.properties
path: game-folder/game-file
-
pathmentions the relative path in the container volume where this key/file should be saved -
change the configmap, takes time to affect (kubelet sync period + ttl of configmaps cache in kubelet)
-
A container using a ConfigMap as a subPath volume will not receive ConfigMap updates.
-
used configMap to a container's volume. readOnly is false. but cannot create file there. sayd 'it's read only file system'. most probably cause the volume contains exactly what configmap contains
-
configmap is like secrets, but easier for strings (not sensitive info)
-
if you mention keys that don't exist, pods wont start. (except for
envFrom, pods will start, but will be added toInvalidVariableNamesin event log, and be skipped -kubectl get events) -
the pod (that is using configmap) must be in apiserver (pods created via the Kubelet’s –manifest-url flag, –config flag, or the Kubelet REST API are not allowed QJenny)
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
- empty tmp dir that share pod's lifetime
emptyDir.mediumcan be "" orMemory(tmpfs - RAM backed filesystem) (data lost if node is restarted)- safe accross container crashes, deleted if pod is deleted
- can write
- usually used to access to host's system agents or other privileged things, or Docker internals(
/var/lib/docker), running cAdvisor (QJenny) or - allows pods to check if a given hostPath exists before the pod is started
hostPath.type-""(backwards compatible = no checks will be performed), directoryorcreate, directory, fileorcreate, file, socket, chardevice, blockdevice (link QJenny last 3?)- host is
Node, your minikube, not your machine. enter tominikube sshand you'll see the files you created inside your pod - data is permanent
- used
Directory(which must exist) and put something which doesn't exist, pod remians inContainerCreatingmode - hostPath volume inside a pod give write permission to only root of the node (minikube). so if you want write from minikube, you either
sudo suorchmod -R 747 <directory>from minikube or pod (so initiallyfile's owneris both's root. changing permission changes from both filesystem) - if you use directoryorcreate - creates empty dir with 0755. fileorcreate produces 0644
- you CAN mount a volume more than one to your pod. even you can mount inside another mount (the same volume!)
volumeMounts:
- name: emptyvol
mountPath: /etc/empty
- name: hostpathvol
mountPath: /etc/kfoozminus
- name: hostpathvol
mountPath: /etc/kfoozminus/kfoozfolder
- name: hostpathvol2
mountPath: /etc/afifa
restartPolicy: Always
volumes:
- name: emptyvol
emptyDir: {}
- name: hostpathvol
hostPath:
path: /home/kfoozminus/jenny
type: DirectoryOrCreate
- name: hostpathvol2
hostPath:
path: /home/kfoozminus/afifa
type: FileOrCreate
-
pv is like node, pvc is like pod
-
pod requests resources, pvc requests size/access modes
-
create a pv from physical storage. not used yet.
-
cluster user creates a pvc, automatically bound to a pv
-
create a pod that uses the pvc
-
https://kubernetes.io/docs/tasks/configure-pod-container/configure-persistent-volume-storage/
-
UJenny Access Control https://kubernetes.io/docs/tasks/configure-pod-container/configure-persistent-volume-storage/#access-control
-
hostPath for testing and development in single node. in production, use gce persistent disk, nfs share, amazon ebs
-
after you create a pvc, if control plane finds a suitable pv with same storage class, with requirements (at least)
-
if storage class is empty, it means doesn't belong to any storage class (will show empty)
-
if storage class is not mentioned, it will belong to standard
-
readWriteOnce means the volume can be mounted as read-write by a single Node
-
if you try to delete a pv, that is used by a pvc, that will be in Terminating stage until you delete that pvc ( https://kubernetes.io/docs/concepts/storage/persistent-volumes/#storage-object-in-use-protection )
-
storage class: standard (default) or custome (even "" is a kind of storage class)
-
diff between "" and new storageclass, in case of empty one, you don't have to create the class to use pvc (but there must be pv of empty storage class, because empty one can't create a dynamic pv)
-
a storage class is responsible for creating dynamic pv
-
if you try to assign a pvc to standard, and no pv exists meeting that demand, that pvc create a pv from standard storageclass.
-
pvc and pv is ont-to-one mapping, so if pv uses 10gb, pvc uses 3gb - capacity of pvc is 10gb
-
access mode must match of pvc and pv
-
if you create a pvc (standard), if there's no pv, automatically one will be created, and if that pvc is deleted, that pv will be deleted automatically too (because default dynamic policy is delete)
-
even if there's a pv, which can meet the requirement, I can see by
kubectl get pv -wthat some intermediate pv is created and released -
pvc's are updated automatically, so pending ones will be bound if a suitable pv is created (A control loop watches over the pvc)
kind: PersistentVolume
apiVersion: v1
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
- now use a pod that will use the pvc, which will be actually used as a wrapper around a pv, that is owned by someone else (system)
- hostpath is maintained by pv, not pvc
kind: Pod
apiVersion: v1
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
-
volume has name and volumesource - not a resource(yaml)
-
persistent volume has meta/object data, spec, status (like a node)
-
persistent volume spec has persistent volume source, cap, accessmodes, storageclassname
-
pod.spec.volumes.volumesource/persistenvolumeclaim.readOnlyoverwritescontainers.volumeMounts.readOnly -
pod.spec.volumes.persitenvolumeclaim.claimNamemust match the pvc object -
if pvc finalizer contains
kubernetes.io/pvc-protectionor pv finalizer containskubernetes.io/pvc-protection, it won't be deleted till it is used (metadata.finalizers). this list must be empty to delete the object -
pvc get everything from pv (capacity, accessmodes)
-
pv has reclaiming policy
-
policy: dynamic pv gets policy from storage class (which defaults to delete).
-
otherwise default is
Retain -
Recycleif pvc deleted, data is lost, pv is available again. it is deprecated, use dynamic provisioning -
Deleteif pvc deleted, data not lost (I think that depends on type of volume, I used hostPath here). showedfailedbecause hostPath deleter supports only/tmpas mount path, I used/mnt/data, changed it to/tmp. then after pvc is deleted, pv is deleted automatically -
Retaindeleted pvc, pv is released, can't be used again. if create pvc again, new (dynamin or avaialble) pv is used -
UJenny https://kubernetes.io/docs/concepts/storage/persistent-volumes/#recycle
-
You can only expand a PVC if its storage class’s
allowVolumeExpansionfield is set to true. specify a larger volume for pvc, pv isn't created anew. instead, existing volume is resized -
statefulset.spec.volumeclaimtemplatesevery claim must have one mapping incontainers.volumemout. this takes precedence over with same name intemplate.spec.volumes -
pv has
mountOptionsashard,nfsvers=4.1,ro,softQJenny -
not every volume supports mountOptions - https://kubernetes.io/docs/concepts/storage/persistent-volumes/#mount-options
-
pv.volumeMode= raw/filesystem. filesystem is default. QJenny diff between raw device and block device -
pv.accessModesdifferent for different volume type https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes -
pvc.selectorselects the volume with this label. both matchlabel and matchexpressin are ANDed -
if pv doesn't mention storageClass, it belongs to "". if pvc doesn't mention, it goes to standard
-
default storage class shits https://kubernetes.io/docs/concepts/storage/persistent-volumes/#class-1 UJenny
-
pv binds are exclusive, pvc are namespace objects, mounting claims with
Manymodes (ROX, RWX) are possible within one namespace QJenny -
UJenny Raw block volume support https://kubernetes.io/docs/concepts/storage/persistent-volumes/#raw-block-volume-support
-
volumesnapshotcontent is like pv, volumesnapshot is like pvc
-
supported in only csi driver
-
An administrator can mark a specific StorageClass as default by adding the
storageclass.kubernetes.io/is-default-classannotation to it. -
k8s has default limits on the number of volumes that can be attached to a Node - aws ebs 39, google persistent disk 16, azure 16
-
can be changed by setting the value
KUBE_MAX_PD_VOLS -
dynamic volume limits https://kubernetes.io/docs/concepts/storage/storage-limits/#dynamic-volume-limits
- group related objects in same file
kubectl create -f /dir- don't write default values unnecessarily
- use annotations
- don't use bare pods
- create service before pods
- don't use environment variable for dns lookups (only for old software)
- don't specify
hostPortunless necessary. hostIP is 0.0.0.0 by default - avoid hostNetwork too
app: myapp, tier: frontend, phase: test, deployment: v3as labels. idientifies semantic attributes- use labels to debug. take a pod and remove its label (to remove it from a service, it will be replaces, so no problem) and debug the pod
- if imagePullPolicy is ommitted - if image tag is
latestor ommitted,Alwaysis applied - if image tag is present but notlatest,IfNotPresentis applied - to make sure to use same version of the image always : use digest
- avoid using latest, because it is always gonna be updated. will be problem to track down the releases
- The caching semantics of the underlying image provider make even
imagePullPolicy: Alwaysefficient. With Docker, for example, if the image already exists, the pull attempt is fast because all image layers are cached and no image download is needed. - use labels to
getanddeleteoperation instead of object names.
labels:
app: guestbook
tier: frontend
labels:
app: guestbook
tier: backend
role: master
labels:
app: guestbook
tier: backend
role: slave
kubectl get pods -Lappshows all pods with the labelappas keykubectl get pods -l appsame- cpu in units of cores, memory in units of bytes
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
-
cpu - 0.5, 0.1 (100m - one hundred millicpu/millicores) are allowed. precision finer than 1m is not allowed. so 100m might be preferrable format
-
You can express memory as a plain integer or as a fixed-point integer using one of these suffixes: E, P, T, G, M, K. You can also use the power-of-two equivalents: Ei, Pi, Ti, Gi, Mi, Ki.
-
64MiB - 2^26 bytes
-
pods are scheduled in node after capacity check
-
how resources are processed https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#how-pods-with-resource-limits-are-run
-
troubleshooting https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#troubleshooting
- My Pods are pending with event message failedScheduling
- My Container is terminated
-
ephemeral storage UJenny
-
extended resources UJenny
-
curl patch UJenny
kubernetes.io/hostname
failure-domain.beta.kubernetes.io/zone
failure-domain.beta.kubernetes.io/region
beta.kubernetes.io/instance-type
beta.kubernetes.io/os
beta.kubernetes.io/arch
node-restriction.kubernetes.io/- https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#node-isolation-restriction
- minikube has a
etcd-minikubepod where it keeps all the info. UJenny https://coreos.com/etcd/docs/latest/dev-guide/interacting_v3.html
- https://kubernetes.io/docs/tasks/run-application/update-api-object-kubectl-patch/#use-a-json-merge-patch-to-update-a-deployment
- https://erosb.github.io/post/json-patch-vs-merge-patch/
- https://kubernetes.io/docs/reference/kubectl/cheatsheet/#patching-resources
- 3 types
- strategic merge patch -
kubectl patch deploy <name> --patch "$(cat patch.yaml)"- depends on the patchStrategy in the k8s code
- can be
merge,retainKeys,replace(QJenny what is retainKeys? volume has merge,retainKeys both) - if not specified, default is
replace - this method is default to kubectl patch. so
--type strategiccan be ommitted. - if you add a container, new one will be added in
containers[0]
- json merge patch:
--type merge- partial elements are passed - those are replaced
kubectl patch deploy booklist4 --type merge -p "$(cat patch.yaml)"- you can also do
$(cat patch.json) - completely replaces existing list
- deletion is by
null(from here) - so it's not possible to change a value to null, by json patch - it is possible
- if you want to change a array/slice like containers, you have to mention the full list - as it replaces the whole
- json patch - above link + https://json8.github.io/patch/demos/apply/
- json patch has add, remove, replace, move, copy
kubectl patch pod valid-pod --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]'- (admission webhook use only this kinda patch, others don't work in here)
- https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
- aggregated API sits behind primary API
- https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/
- you can create custom resources in 2 ways - crd (under k8s api) or programming aggregation api
- use crd if your company uses that for small open-source project
- crd common features - https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/#common-features
- uses authN, authZ, auditing
- finalizers like can be removed after
metadata.deletionTimestampis set - UJenny: validation https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/#validation
apiVersionisapiextensions.k8s.io/v1beta1metadata.namemust beplural.groupcrd.spec.names.singulardefaults to lowercase ofkindscopehasClusterorNamespacelistKindis likeJennyList(kind isJenny)- plural/singular must be lowercase
- Operator, etcd cluster, etcd operator - https://coreos.com/blog/introducing-operators.html
-
https://blog.openshift.com/kubernetes-deep-dive-code-generation-customresources/
-
some code generators for building controllers
-
deepcopy-gen creates deepcopy method for every tyep
-
client-gen creates typed clientsets for customresources
-
informer-gen creates informers for customresources which offer event based interface to react on changes of cr on the server
-
lister-gen creates listers for cr which offer read-only caching layer for GET and LIST requests
-
generated code either goes to same directory as input files(deepcoy-gen) or pkg/client (client-, informer-, lister-gen)
-
global tags are in directly above /pkg/apis///doc.go
-
local tags are in directly above types
-
others must be separated from types or doc.go with at least one empty line
-
// +k8s:deepcopy-gen=package,register- you don't writeregisterhere after v1.8 -
// +groupName=example.commust be just above the package name -
if you want a type to not be deepcopied - you will write
// +k8s:deepcopy-gen=falseabove that type, abovetrueif you didn't mentionpackagein global tag -
crds must have to implement
runtime.Object interface, which hasDeepCopyObjectmethod - https://github.com/kubernetes/apimachinery/blob/7089aafd1ef57551192f6ec14c5ed1f49494ccd2/pkg/runtime/interfaces.go#L237 -
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Objectabove every top-level API types will implementruntime.Object interfaceby writing DeepCopyObject() method -
those who have metav1.TypeMeta embedded are top-level API types
-
// +k8s:deepcopy-gen:interfaces=example.com/pkg/apis/example.SomeInterfacewill also generateDeepCopySomeInterface() SomeInterfaceif the object has that interface as field (QJenny if a struct has an interface as a field?) -
// +genclientcreates a client for this type. should not use in list type. QJenny why? -
// +genclient:noStatussays the resulting client will not haveUpdateStatusmethod -
// +genclient:nonNamespacedfor cluster wide resources
// +genclient:noVerbs
// +genclient:onlyVerbs=create,delete
// +genclient:skipVerbs=get,list,create,update,patch,delete,deleteCollection,watch
// +genclient:method=Create,verb=create,result=k8s.io/apimachinery/pkg/apis/meta/v1.Status
- the last one will be create-only and will not return the API type itself, but a metav1.Status
- deepcopy-gen https://github.com/kubernetes/gengo/blob/master/examples/deepcopy-gen/main.go
- client-gen https://github.com/kubernetes/community/blob/master/contributors/devel/generating-clientset.md
- list-, informer-gen https://github.com/kubernetes/code-generator/blob/master/generate-groups.sh (yeah that's right :v)
- create a directory like
root
artifacts
*.yaml
pkg
apis
types.go
doc.go
register.go
client
-
Wrangling Kubernetes API internals: https://skillsmatter.com/skillscasts/10599-wrangling-kubernetes-api-internals#video
-
Extending the Kubernetes API: What the Docs Don't Tell You [I] - James Munnelly, Jetstack: https://www.youtube.com/watch?v=PYLFZVv68lM
-
client-, conversion-, deepcopy-, defaulter-, go-to-protobuf, informer-, lister-, openapi-, codec-
-
types.gooutsideapigroup/versionworks as intermediate something when conversioning versions/upgrading apiservers. this is called internal type/version. others are external versions. ex. - v1 to internal to v2
- https://kubernetes.io/docs/tasks/access-application-cluster/access-cluster/#accessing-the-api-from-a-pod
/var/run/secrets/kubernetes.io/serviceaccount/in a pod has ca.crt, token, namespace
- https://kubernetes.io/docs/tasks/access-application-cluster/access-cluster/#accessing-services-running-on-the-cluster
kubectl cluster-info,kubectl cluster-info dump
- used to hold password, OAuth tokens, ssh
- user and system both can create secret
- pod references the secret in 2 ways - volume or by kubelet when pulling images for the pod QJenny
- service account automatically create and attach secrets with API https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/ UJenny
kubectl create secret generic <name> --from-file=username.txt --from-file=password.txt= a secret with typeOpaque--from-fileautomatically encodes the dataecho -n "jenny" | base64to encodeecho -n <encoded> | base64 -dto decode- you cannot put non-encoded data in
.datafield in .yaml file - you CAN in
.stringDatafield
stringData:
password: 1234
gave error, 1234 was assumed as int. just wrap with ""
- stringData will be automatically encoded to base64
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |-
apiUrl: "https://my.api.com/api/v1"
username: {{username}}
password: {{password}}
- a field in stringData overwrites same field in data
- The keys of data and stringData must consist of alphanumeric characters, ‘-’, ‘_’ or ‘.’.
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
- inside pod, secrets will be saved as non-encoded
- if
.itemsis specified, only specified keys will be mounted to specified path (and filename - so username will be saved inmy-usernamefile) - default permission to files is 0644, but can be modified by
.volume.secret.defaultMode- but have to use decimal number as json/yaml doesn't support octal notation. so for 0400, you have to use 256 .volume.secret.items.modecan set permission to separate files- QJenny file permissin don't match inside the pod
- updates secrets and configmaps after every periodin sync, using the
ConfigMapAndSecretChangeDetectionStrategyfield inkubeletConfigurationinkubernetes/staging/src/k8s.io/kubelet/config/v1beta1/types.go - total time is kubelet sync period + cache propagation delay
- subPath doesn't receive secret updates
- can also get env
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
- UJenny imagePullRegistry, private image
- When deploying applications that interact with the secrets API, access should be limited using authorization policies such as RBAC.
- The ability to watch and list all secrets in a cluster should be reserved for only the most privileged, system-level components.
- On most Kubernetes-project-maintained distributions, communication between user to the apiserver, and from apiserver to the kubelets, is protected by SSL/TLS. Secrets are protected when transmitted over these channels.
- In the API server secret data is stored as plaintext in etcd
- anyone with root on any node can read any secret from the apiserver, by impersonating the kubelet.
kubectl proxy --port=8080 &curl http://localhost:8080/api/
$ APISERVER=$(kubectl config view --minify | grep server | cut -f 2- -d ":" | tr -d " ")
$ TOKEN=$(kubectl describe secret $(kubectl get secrets | grep "^default" | cut -f1 -d ' ') | grep -E '^token' | cut -f2 -d':' | tr -d " ")
$ curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
--insecureleaves it subject to MITM attackkubectl cluster-info
serviceaccount.automountServiceAccountToken: falseorpod.spec.automountServiceAccountToken: falseto opt out of automounting API credentials for a particular pod.pod.overwritesservice.- creating a service account will create a secret, which has
kubernetes.io/service-account-tokenas type. when the service-account is deleted, the secret is deleted too - you can use that service-account in pods now, but it has to be created before that pod
- you can create a secret manually -
secret.metadata.annotationssetting tokubernetes.io/service-account.name: <svcac-name>andsecret.typesettingkubernetes.io/service-account-token
kubectl create -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: build-robot-secret
annotations:
kubernetes.io/service-account.name: build-robot
type: kubernetes.io/service-account-token
now you can see that this secret contains ca.crt, token from that svcac (service-account)
https://kubernetes.io/docs/concepts/containers/images/#specifying-imagepullsecrets-on-a-podhttps://stackoverflow.com/questions/36232906/how-to-access-private-docker-hub-repository-from-kubernetes-on-vagrant
DOCKER_REGISTRY_SERVER=docker.io
DOCKER_USER=Type your dockerhub username, same as when you `docker login`
DOCKER_EMAIL=Type your dockerhub email, same as when you `docker login`
DOCKER_PASSWORD=Type your dockerhub pw, same as when you `docker login`
kubectl create secret docker-registry myregistrykey \
--docker-server=$DOCKER_REGISTRY_SERVER \
--docker-username=$DOCKER_USER \
--docker-password=$DOCKER_PASSWORD \
--docker-email=$DOCKER_EMAIL
-
this will create a secret with type
kubernetes.io/dockerconfigjson -
If you need access to multiple registries, you can create one secret for each registry. Kubelet will merge any imagePullSecrets into a single virtual .docker/config.json when pulling images for your Pods.
-
create a private repo in docker hub, create that secret, add this to default service account as
serviceaccount.imagePullSecrets, now createa a pod - which will haveimagePullSecretsautomatically - you can mention the private image and it will pull the image by using your docker credentials -
or you can add
pod.spec.imagePullSecretsto the pod with adding it to service account
- https://kubernetes.io/docs/concepts/storage/volumes/#projected
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-projected-volume-storage/
- allows secret, downwardAPI, configMap, serviceAccountToken
- multiple ^these into one directory
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
containers:
- name: container-test
image: busybox
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
.kube/confighas certificate presented by API server- TLS - Transport Layer Security - cryptographic protocol that provides end-to-end communications security over networks
- apiserver runs authN modules
- http req --> header/client certificate
- authN modules have client certificates, password, Plain/JWT(for svcac)/Bootstrap tokens.
- if multiple modules, only one have to be succeded
- rejected with 401 (Unauthorized)
- accepted/authenticated as a username
- request {username, action, the object to be modified}
- suppose you have a abac policy
kubernetes/pkg/apis/abac/v1beta1/types.go
{
"apiVersion": "abac.authorization.kubernetes.io/v1beta1",
"kind": "Policy",
"spec": {
"user": "bob",
"namespace": "projectCaribou",
"resource": "pods",
"readonly": true
}
}
- and you have
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "projectCaribou",
"verb": "get",
"group": "unicorn.example.org",
"resource": "pods"
}
}
}
- different authZ modules - RBAC, ABAC, webhook mode
- if multiple, each one must authorize
- rejected with 403 (Forbidden)
- modifies, rejects reqs
- addition to authZ modules, they can access objects that are being created/deleted/updated/connected(proxy), but not reads
- if multiple, each called in order
- if rejected, immediately rejected
- it can also set complex defaults for fields
- if passed, it is validated using validation routines - then written to object store
- QJenny https://kubernetes.io/docs/reference/access-authn-authz/controlling-access/#api-server-ports-and-ips
- localhost port 8080, no TLS, no authN/Z, only admission control
- secure port 6443, TLS, authN/Z, admission control
- how to change api-server port?
- users can be 2 types -
- service account - created manually by k8s or through API call
- normal users - they're not objects or cannot be created by calling API
- request are from ^them or annonymous user
- all of them must authenticate
- k8s uses client certificate, bearer tokens, authenticating proxy or HTTP basic auth
- request has username(string), uid(string), groups(set of strings), extra fields(map of strings, additional information)
- these values are opaque to authN, reserved for authZ
- should have at least 2 authN method - one for svcac, at least one for user authN
- multiple authN module - no order - first one to authenticate short-circuits evaluation
- The
system:authenticatedgroup is included in the list of groups for all authenticated users.
- by passing
--client-ca-file=SOMEFILEto apiserver openssl req -new -key jbeda.pem -out jbeda-csr.pem -subj "/CN=jbeda/O=app1/O=app2"- that will create a CSR (certificate signing request) for the username
CNand for the groupsO
- apiserver reads tokens from a file
--token-auth-file=SOMEFILE - lasts indefinitely, cannot be changed without restarting API server
- The token file is a csv file with a minimum of 3 columns: token, user name, user uid, followed by optional group names.
token,user,uid,"group1,group2,group3"if you have more than one groupAuthorization: Bearer 31ada4fd-adec-460c-809a-9e56ceb75269if it is used in HTTP req header
- dynamically managed bearer token
- stored in secrets in
kube-systemnamespace - has expiration, deleted by TokenCleaner controller
- tokens are of the form [a-z0-9]{6}.[a-z0-9]{16} - {token-id}.{token-secret}
Authorization: Bearer 781292.db7bc3a58fc5f07e- must enable the Bootstrap Token Authenticator with the
--enable-bootstrap-token-authflag on the API Server and TokenCleaner controller via the--controllersflag on the Controller Manager - authenticates as
system:bootstrap:<token-id>(like username for x509 cert) and included insystem:bootstrapersgroups
- basic auth is enabled by passing
--basic-auth-file=SOMEFILEto apiserver - lasts indefinitely, cannot be changed without restarting apiserver
- basic auth file is a csv file with a minimum of 3 columns: password, user name, user id
Authorization: Basic <base64-encoded-user:password>if used in HTTP client req header
.minikubehas every key--service-account-key-filecontains PEM encoded key for signing bearer tokens, if unspecified, api server's TLS private key is used--service-account-lookupprovokes deleted tokens- svcac tokens are automatically loaded into pods
- these tokens can be used outside the cluster too, e.g, in case for long standing jobs that wish to talk to k8s api
- svcac-secrets contain public ca of api-server and a signed json web token (signed by apiserver private key)
- both are base64 encoded (including namespace too), because secrets are always base64 encoded
- authenticated as the username
system:serviceaccount:(NAMESPACE):(SERVICEACCOUNT)and assigned to the groupssystem:serviceaccountsandsystem:serviceaccounts:(NAMESPACE)
apiVersion: v1
data:
ca.crt: (APISERVER'S CA BASE64 ENCODED)
namespace: ZGVmYXVsdA==
token: (BEARER TOKEN BASE64 ENCODED)
kind: Secret
metadata:
# ...
type: kubernetes.io/service-account-token
--authentication-token-webhook-config-fileis a config file which describes how to access remote webhook service--authentication-token-webhook-cache-ttlhow long to cache authN decision. defaults 2 mins- config file is in the kubeconfig format (like
kubectl config view) - clusters are remote service and users are API server webhook
# Kubernetes API version
apiVersion: v1
# kind of the API object
kind: Config
# clusters refers to the remote service.
clusters:
- name: name-of-remote-authn-service
cluster:
certificate-authority: /path/to/ca.pem # CA for verifying the remote service.
server: https://authn.example.com/authenticate # URL of remote service to query. Must use 'https'.
# users refers to the API server's webhook configuration.
users:
- name: name-of-api-server
user:
client-certificate: /path/to/cert.pem # cert for the webhook plugin to use
client-key: /path/to/key.pem # key matching the cert
# kubeconfig files require a context. Provide one for the API server.
current-context: webhook
contexts:
- context:
cluster: name-of-remote-authn-service
user: name-of-api-sever
name: webhook
-
simple bearer token that is used to create new clusters or join new nodes to an existing cluster
-
can support kubeadm
-
can also be used in other contexts for users that wish to start clusters without kubeadm
-
also built to work with kubelet tls bootstrapping, via RBAC
-
secrets in
kube-system -
secrets of type
bootstrap.kubernetes.io/token -
secret name must be
bootstrap-token-<token id> -
read by Bootstrap authenticator
-
these tokens are also used to create a signature for a specific ConfigMap, used by BootstrapSigner controller
-
[a-z0-9]{6}\.[a-z0-9]{16} -
token-id can be public, to refer a token. token-secret should be only shared to trusted parties
-
Bootstrap token authN can be enabled by
--enable-bootstrap-token-auth -
--controllers=*,tokencleaner -
to use with
kubeadm, see - https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-token/
--controllers=*,bootstrapsigner- HS256, by signed by token-secret
- user account: for human, non-namespaced
- service account: for processes like pods, namespaced
-
it adds default svcac to pod
-
adds imagePullSecrets to pod
-
adds volume to the pod which contains a token for API access (default token secret as volume)
-
adds volumeSource to each container at
/var/run/secrets/kubernetes.io/serviceaccount -
BoundServiceAccountTokenVolumeto migrate svcac to projected volume
- creates secret automatically after svcac creation
- deletes that secret after svcac deletion
- ensures svcac referenced in the secret exists
- removes secret from svcac if needed
- pass
--service-account-private-key-fileto token controller to sign generated service account tokens - pass corresponding public key by
--service-account-key-fileto kube-apiserver, to verify the tokens during authentication
- https://kubernetes.io/docs/reference/access-authn-authz/authorization/
- req attributes - https://kubernetes.io/docs/reference/access-authn-authz/authorization/#review-your-request-attributes
- verbs - post, get, put, patch, delete, use, bind, impersonate
-
Node AuthZ
-
ABAC - attribute based access control
-
RBAC - role based access control - start apiserver
--authorization-mode=RBACto enable -
Webhook - A WebHook is an HTTP callback: an HTTP POST that occurs when something happens; a simple event-notification via HTTP POST. A web application implementing WebHooks will POST a message to a URL when certain things happen.
-
kubectl auth can-i create deployments --namespace devchecks if current user can perform a action, usesSelfSubjectAccessReview -
kubectl auth can-i list secrets --namespace dev --as daveuser impersonation -
SelfSubjectAccessReview is part of the authorization.k8s.io API group
-
SubjectAccessReview
-
LocalSubjectAccessReview
-
SelfSubjectRulesReview
kubectl create -f - -o yaml << EOF
apiVersion: authorization.k8s.io/v1
kind: SelfSubjectAccessReview
spec:
resourceAttributes:
group: apps
resource: deployments
verb: create
namespace: dev
EOF
returns the response in status field
--authorization-mode= ABAC, RBAC, Webhook, Node, AlwaysDeny, AlwaysAllow
-
3 CA (self-signed)
-
serving CA: signs serving certs. main and addon apiserver. could be same or different. in real setup, addon apiserver CA shouldn't be self signed
-
client CA: signs client certs. same or different maybe used in case of main and addon. using same CA ensures that identity trust works same way for both
-
requestHeader CA: signs proxy client certs. these clients are effectively trusted to pretend as anyone else. this ca MUST sign aggregator's proxy client cert, if any
-
.crt = public cert, .key = private key
-
apiserver.pem = public cert, apiserver-key.pem = private key
-
3 client authentication:
-
client cert authN: default admin user of a cluster/off-cluster non-human clients.--client-ca-fileto apiserver while creating, or change args in/etc/kubernetes/kube-apiserver. creates aConfigMapinkube-systemns nameextension-apiserver-authentication, populated with a client-ca and requestheader-client-ca. addon apiserver can use this ca file too (that way it can authenticate clients who are authenticated by main apiserver). pass--client-ca-fileto addon server if you use different ca file
-
- diff between VolumeSource & PersistentVolumeSource
- statefulset.volumeclaimtemplates https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#components
- nfs https://kubernetes.io/docs/concepts/storage/persistent-volumes/#persistent-volumes
- local
pv.volumeMode,mountOptions
Generationincreases if anything is changed in configcontainers.commandoverwrites entrypointcontaienrs.argsarguments to entrypoint- LocalObjectReference (
.name) can locate an object in the same namespace
deployment = k8s/api/apps/v1/ pod, container, service, endpoint = k8s/api/core/v1/
- resource model https://github.com/kubernetes/community/blob/master/contributors/design-proposals/scheduling/resources.md
- resource QoS https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/resource-qos.md
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/#deleting-a-replicaset-and-its-pods https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/#working-with-replicationcontrollers
ClusterIPby this, any object can access a serviceNodePorte.g,1234:31562/TCP, an object in the cluster will access the service byClusterIP:1234and from outside the cluster,minikubeip:31562.- you CAN access any pod from anywhere, even if you DONT have service. with exposed port.
- services create engpoints.
kubectl get endpointsshowspod-ip:service-targetport. but you actually access a pod bypod-ip:container-exposed-ip. service-targetport and container-exposed-ip have to match. even if they match, you can access the pod by pod-ip.
hostnamectlinside minikube to see your node's (vm) os and stuff
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
- make list of all the ports/ip
- you need get, create, patch permissin for
kubectl apply(dipta vai) - https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/#deployment-and-scaling-guarantees - If a user were to scale the deployed example by patching the StatefulSet such that replicas=1, web-2 would be terminated first. web-1 would not be terminated until web-2 is fully shutdown and deleted. If web-0 were to fail after web-2 has been terminated and is completely shutdown, but prior to web-1’s termination, web-1 would not be terminated until web-0 is Running and Ready. - Can I do that experiment? can web-0 communicate with web-2 so that after web-2 is terminated, web-0 will fail in its will?
- YAML https://github.com/helm/helm/blob/master/docs/chart_template_guide/yaml_techniques.md#scalars-and-collections
--
minikube startcommand initializeskubeadm, kubelet, certs, cluster, kubeconfig- Kubernetes is microservices platform --