This project is designed to implement an agent capable of interacting with a graph database like Neo4j through a semantic layer using OpenAI function calling. The semantic layer equips the agent with a suite of robust tools, allowing it to interact with the graph database based on the user's intent. Read more in the blog post.
To start the project, run the following command:
docker-compose up
Open http://localhost:8501 in your browser to interact with the agent.
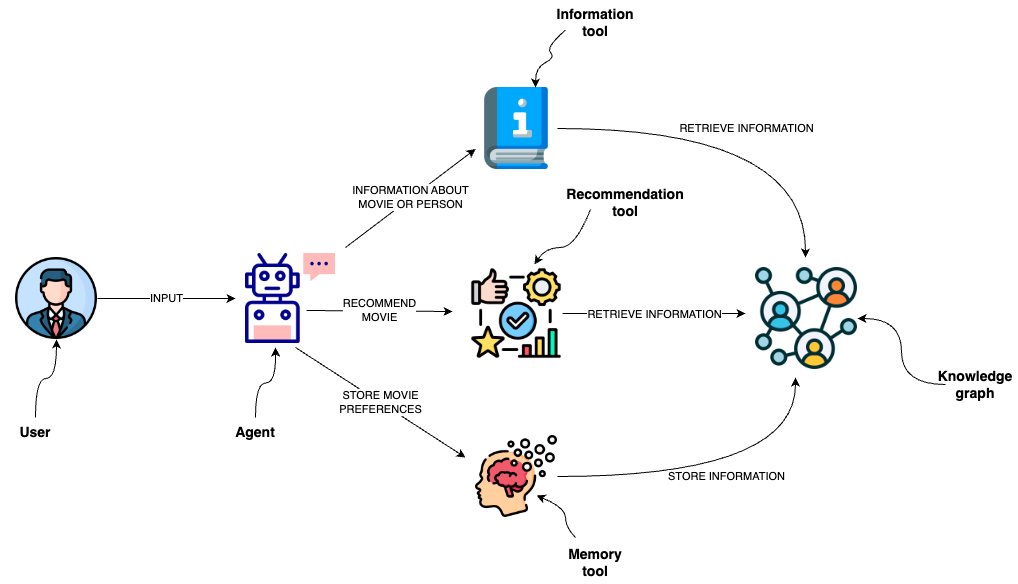
The agent utilizes several tools to interact with the Neo4j graph database effectively:
- Information tool:
- Retrieves data about movies or individuals, ensuring the agent has access to the latest and most relevant information.
- Recommendation Tool:
- Provides movie recommendations based upon user preferences and input.
- Memory Tool:
- Stores information about user preferences in the knowledge graph, allowing for a personalized experience over multiple interactions.
You need to define the following environment variables in the .env file.
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
NEO4J_URI=<YOUR_NEO4J_URI>
NEO4J_USERNAME=<YOUR_NEO4J_USERNAME>
NEO4J_PASSWORD=<YOUR_NEO4J_PASSWORD>
This project contains the following services wrapped as docker containers
- Neo4j:
- Neo4j, a graph database, is used to store the information about actors, movies, and their ratings.
- API:
- Uses LangChain's
neo4j-semantic-layertemplate to implement the OpenAI LLM and function calling capabilities.
- Uses LangChain's
- UI:
- Simple streamlit chat user interface. Available on
localhost:8501.
- Simple streamlit chat user interface. Available on
If you want to populate the DB with an example movie dataset, you can run ingest.py.
The script imports information about movies and their rating by users.
To run within the api docker container (recommended) do the following:
# access container shell
docker exec -it <container id for llm-movieagent-api> bash
# run script
python ingest.pyAdditionally, the script creates two fulltext indices, which are used to map information from user input to the database.
The dataset is based on the MovieLens dataset, which is also available as the Recommendation project in Neo4j Sandbox.
Contributions are welcomed!