 Image taken from researchgate.net.
Image taken from researchgate.net.
This was a final project submission for the Machine Learning class at Clemson University. I got permission from Dr. Razi to publish it here.
The purpose of this project is to recreate a model seen in the paper "Actuator Trajectory Planning for UAVs with Overhead Manipulator using Reinforcement Learning" which was written by Hazim Alzorgan, Abolfazl Razi and Ata Jahangir Moshayed. The paper describes an application of reinforcement learning on a virtual drone, where various kinematics are taken into account in simulating it. In addition the drone has a two arm actuator on top with a tip known as an end effector. Its goal is to detect a viable base path and to follow a target path with the tip of the end effector.
This project utilizes methods from the paper such as inverse kinematic equations, and Q-Learning formulas to recreate a more bare-bones version of what was presented in the paper.
To run my program you will need to install the required libraries including Gym. On installing Gym,
place the PathEvn file into the python3.11 > site-packages > gym > envs > classic_control folder.
A common error I've encountered on new installs is the custom environment not registering with Gym,
I fixed this by duplicating my working Gym folder and replacing the broken one. I have provided this working
Gym folder in the repo.
Here's an explanation of the files:
- /gym/ - You can use your own install of gym, but this one is here incase you encounter errors.
- base_path.npy - These are the base path coordinates the drone body follows.
- ee_path.npy - These are the coordinates of the target path the end effector should follow.
- PathEnv.py - This is the custom environment used to model the arm and world.
- q-table.csv - This is a table containing the q-values of after a 10,000 episode run in Q mode.
- README.md - See README for more details.
- TestRunQ.py - This is the Q-Learning algorithm which tests and renders the program.
- TestRunSARSA.py - This is a modified version of TestRunQ.py which implements SARSA.
Note: There is a commented section of code near the bottom of TestRunQ.py and TestRunSARSA.py which allow for rendering the simulation in pygame. There is also a section of code toward the bottom of TestRunQ.py and TestRunSARSA.py which can be uncommented to see the statstics of a run after a certain episode.
The main library used to enable reinforcement learning was OpenAI's Gym. This allowed for a custom environment to be created and used on top of existing libraries in Gym to create a custom reinforcement learning project.
To create a graphical representation of the environment, I used PyGame to render and grab the data from my environment. Other packages like, numpy, and pandas were used as well.
One of the biggest challenges I faced early on was figuring out how the kinematic equations would fit. I learned after a while that a confusion with what functions returned degrees and radians led me to go in circles for a couple hours. Getting the inverse kinematic equations to function was a hassle early on. Another challenge was figuring out how the observation and action space would work. A specific challenge with the action space was deciding whether it should be a discrete set from the get-go, or if it should be continous and quantized later. The process of sorting out where those functions belonged also took until now to realize fully.

These equations taken from the paper listed above, derive the inverse kinematics of the two arm actuator. These two equations show the respective angles of the root and middle joint of the arm.
The basis of the Q Learning algorithm follows this pseudocode.

A subtle difference exists between Q-Learning and SARSA but it can make a big impact.
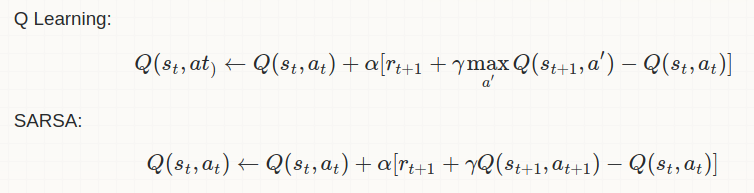
In Q-learning, the Q-value of the current state-action pair is updated based on the maximum Q-value of the next state. But in SARSA, the Q-value of the current state-action pair is updated based on the Q-value of the next state and the action taken in that state.
Q-learning follows an off-policy approach. It learns the optimal policy while following a different, exploratory policy (usually epsilon-greedy). This means that Q-learning estimates the value of the best action even if the agent does not necessarily choose that action during exploration. Whereas SARSA follows an on-policy approach. It learns the value of the policy it is currently using. This means that SARSA estimates the value of the action that the agent would actually take in the next state.
Delving into reinforcement learning was quite the learning curve. OpenAI Gym stood out as the most approachable library for me to grasp, making it the natural choice to start with. Creating a custom environment, though, turned out to be a laborious task, as at first it was incredibly unstable. Pygame posed its own set of challenges. As figuring out the scaling and coordinates of objects was not a straightforward as it could have been. When I first started working on the visuals for this project I had planned on using PyBullet. However given the 2D nature of the sim, and the challenging logistics of creating and rigging a model, I found it impractical given time constraints.
When I began work on creating the custom environment I imagined a 1 dimensional version of the gridworld problem that is always used in reinforcement learning examples. The two most important things to set up were the observation space and the action space. I knew that each state was a discrete location on a path, and that the next position was guaranteed, but I didn't know at first how I would keep track of the angle values of each position.
This is where Gym's spaces came in handy. As I could define the observation space as a tuple, where the first value is a discrete space of integers from 0 to 99, and the second value could be the angular measurements as another tuple this time defined as a Box space between the upper and lower limits.

For the action space, I defined it as a continuous Box space going between -3 degrees and positive 3 degrees. I decided to have my actions represent different values of torque movements that could be made. With this case, both arms would be moving at once, unless a random action was selected otherwise with a 0.
This project tested both Q-Learning and SARSA, and those details will be discussed below in findings.
Here's the result of a 1000 episode run, the line stabilizes as the episodes increase.
