-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create 单节点8xA800跑起来HuggingFace DeepSeek V2踩坑.md
- Loading branch information
Showing
1 changed file
with
86 additions
and
0 deletions.
There are no files selected for viewing
86 changes: 86 additions & 0 deletions
86
docs/academic/算法科普/Transformer/单节点8xA800跑起来HuggingFace DeepSeek V2踩坑.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,86 @@ | ||
| # 0x0. 背景 | ||
| 尝试跑起来HuggingFace上release的DeepSeek V2,踩了几个坑,这里给出解决的方法。HuggingFace提供的开源DeepSeek V2 repo链接为:https://huggingface.co/deepseek-ai/DeepSeek-V2 | ||
|
|
||
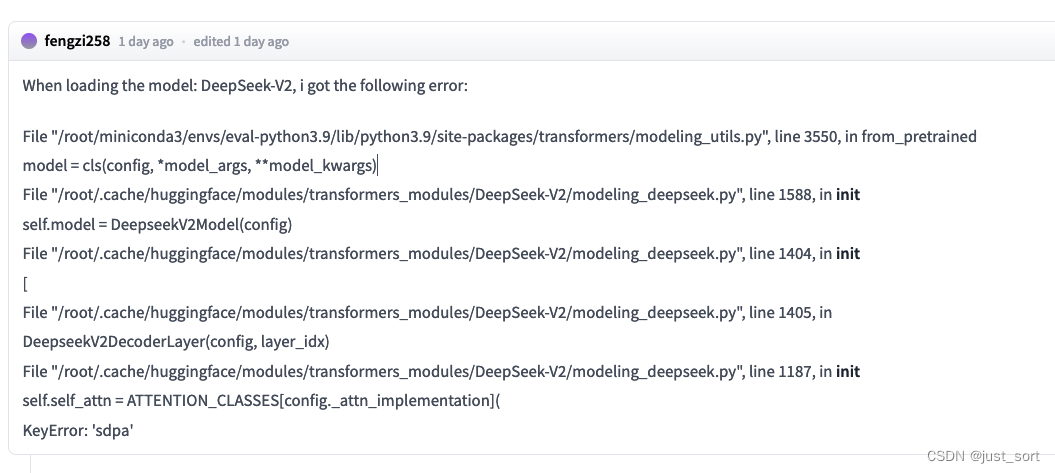
| # 0x1. 报错1: KeyError: 'sdpa' | ||
|
|
||
| 这个问题社区也有人反馈了。https://huggingface.co/deepseek-ai/DeepSeek-V2/discussions/3 | ||
|
|
||
|  | ||
|
|
||
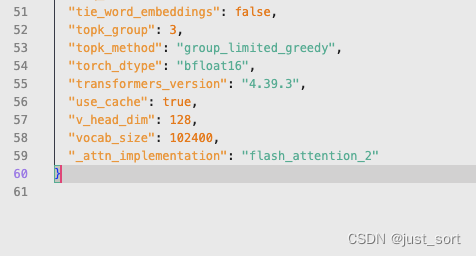
| 解决方法很简单,在工程里面的`config.json`最后加一句`"_attn_implementation": "flash_attention_2"`即可: | ||
|
|
||
|  | ||
|
|
||
| # 0x2. 报错2: 初始化阶段卡死 | ||
| 已经给accelerate提了一个pr解决这个问题。https://github.com/huggingface/accelerate/pull/2756 | ||
|
|
||
| ### 背景 | ||
| 当我尝试使用 transformers 库进行 deepseek-v2 模型推理时: | ||
|
|
||
| ```python | ||
| import torch | ||
| from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig | ||
|
|
||
| model_name = "deepseek-ai/DeepSeek-V2" | ||
| tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) | ||
| # `max_memory` should be set based on your devices | ||
| max_memory = {i: "75GB" for i in range(8)} | ||
| # `device_map` cannot be set to `auto` | ||
| model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager") | ||
| model.generation_config = GenerationConfig.from_pretrained(model_name) | ||
| model.generation_config.pad_token_id = model.generation_config.eos_token_id | ||
|
|
||
| text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is" | ||
| inputs = tokenizer(text, return_tensors="pt") | ||
| outputs = model.generate(**inputs.to(model.device), max_new_tokens=100) | ||
|
|
||
| result = tokenizer.decode(outputs[0], skip_special_tokens=True) | ||
| print(result) | ||
|
|
||
| ``` | ||
|
|
||
|
|
||
|
|
||
| 我发现程序卡住了... | ||
|
|
||
| ### 解决 | ||
| 根据栈信息,卡在 **这里**(https://github.com/huggingface/accelerate/blob/main/src/accelerate/utils/modeling.py#L1041) . | ||
|
|
||
|  | ||
|
|
||
|
|
||
| 对于 DeepSeek V2,module_sizes 的长度为68185,而这里的代码复杂度为 O(N^2)(其中 N = module_sizes),需要非常长的时间来执行,给人一种卡住的错觉。这个 PR 优化了代码,使其复杂度变为 O(N),从而可以快速到达加载大模型的阶段。在一台8xA800机器上,经过这种优化后,推理结果也是正常的。 | ||
|
|
||
| # 0x3. 单节点A800推理需要限制一下输出长度 | ||
| 由于模型的参数量有236B,用bf16来存储单节点8卡A800每张卡都已经占用了大约60G,如果输出长度太长,用HuggingFace直接推理的话KV Cache就顶不住了,如果你想在单节点跑通并且做一些调试的话,输入的prompt设短一点,然后`max_new_tokens`可以设置为64。实测是可以正常跑通的。我跑通的脚本为: | ||
|
|
||
| ```python | ||
| import torch | ||
| from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig | ||
|
|
||
| model_name = "/mnt/data/zhaoliang/models/DeepSeek-V2/" | ||
| tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) | ||
| # `max_memory` should be set based on your devices | ||
| max_memory = {i: "75GB" for i in range(8)} | ||
| model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto", torch_dtype=torch.bfloat16, max_memory=max_memory) | ||
| model.generation_config = GenerationConfig.from_pretrained(model_name) | ||
| model.generation_config.pad_token_id = model.generation_config.eos_token_id | ||
|
|
||
| text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is" | ||
| inputs = tokenizer(text, return_tensors="pt") | ||
| outputs = model.generate(**inputs.to(model.device), max_new_tokens=100) | ||
|
|
||
| result = tokenizer.decode(outputs[0], skip_special_tokens=True) | ||
| print(result) | ||
|
|
||
| ``` | ||
|
|
||
|
|
||
|  | ||
| # 0x4. VLLM | ||
| 如果想在单节点8卡A100/A800上加速推理并且输出更长长度的文本,目前可以使用vllm的实现,具体见这个pr:https://github.com/vllm-project/vllm/pull/4650 | ||
|
|
||
|
|
||
| > deepseek-v2的开源,技术报告,模型架构创新都很好,respect。但个人感觉上传开源代码的时候还是顺手做一下测试吧。 | ||
|
|