-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create CVPR 2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法.md
- Loading branch information
Showing
1 changed file
with
103 additions
and
0 deletions.
There are no files selected for viewing
103 changes: 103 additions & 0 deletions
103
docs/academic/科研及竞赛分享/CVPR 2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,103 @@ | ||
| ## CVPR'2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法 | ||
|
|
||
| ### 摘要 | ||
|
|
||
| 以情境为中心的问题驱动任务完成(AQTC)被提出,从视频中获取知识,为用户提供全面系统的指导。然而,现有的方法忽视了时空视觉和语言信号的一致性,以及人与物体之间关键的交互信息。为了解决这些局限性,我们建议将大规模预训练的视觉语言和视频语言模型结合起来,以提供稳定可靠的多模态数据,并促进有效的时空视觉-文本对齐。此外,我们还提出了一个新颖的手-物-交互(HOI)聚合模块,该模块有助于捕捉人-物交互信息,从而进一步增强理解所呈现场景的能力。我们的方法在CVPR'2023 AQTC挑战赛1中获得了第一名,Recall@1得分为78.7%。 | ||
|
|
||
| 文章链接:https://arxiv.org/abs/2306.13380 | ||
|
|
||
| 代码链接:https://github.com/tomchen-ctj/CVPR23-LOVEU-AQTC。 | ||
|
|
||
| ### 引言 | ||
|
|
||
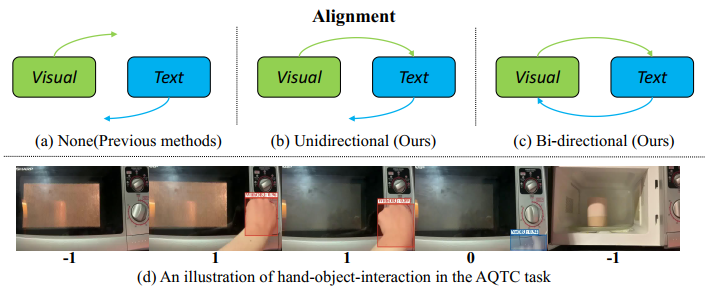
| 以情境为中心的问题驱动任务完成(AQTC)方法旨在通过一系列动作解决用户提出的一系列问题。虽然AQTC与传统的视觉问题解答(VQA)方法类似,但AQTC不仅需要清晰地理解静态图像,还需要理解人与物体在空间和时间上的交互变化,这是一项需要严格的多模态理解和对齐能力的任务。此外,AQTC中以任务为导向的问题需要多模态和多步骤的答案,与VQA相比更具挑战性,类似于智能助手的设置。 | ||
|
|
||
|  | ||
|
|
||
|
|
||
| 然而,现有的方法主要依靠在单一模态上预先训练的模型来提取特征,例如ViT、XL-Net和BERT。此外,它们通常通过时间平均池获得视频级特征,然后使用交叉注意或基于统计的问题函数接地等技术进行上下文接地。如上图(a)所示,这些简单的方法没有考虑视觉和文本的时空一致性,而这对于多源上下文接地至关重要。此外,如上图(d)所示,在视频的某些部分,手和物体之间没有互动,帧只是物体的插图。在这些情况下汇集帧级特征可能会分散模型对人-物交互所提供的关键信息的注意力。 | ||
|
|
||
| 为了解决上述问题,我们提出利用视觉语言预训练模型来提取对齐良好的特征,如上图(b)(c)所示,同时利用自我中心-视频语言预训练模型来提高对长格式时间线索的理解。此外,我们还引入了以交互为中心的时间聚合模块。它弥补了之前以功能为中心的方法只关注问题的基础而忽略人与物体之间交互的缺陷,有助于提取大量教学视频中与交互相关的上下文信息。 | ||
|
|
||
| 这项工作的贡献可归纳为四个方面: | ||
|
|
||
| - 我们指出,现有方法受限于时空视觉语言错位和缺少 | ||
| 人-物交互信息。 | ||
| - 我们证明,通过简单地结合视觉语言和视频语言基础模型,对时空视觉语言信息进行对齐可以实现显著的改进。 | ||
| - 我们扩展了以功能为中心的方法,引入了新颖的以交互为中心的时空聚合模块,以更好地理解任务场景。 | ||
| - 我们在2023年AQTC测试集上取得了78.7%的Recall@1得分,夺得了CVPR'2023年AQTC挑战赛的冠军。 | ||
|
|
||
| ### 方法 | ||
|
|
||
|  | ||
|
|
||
|
|
||
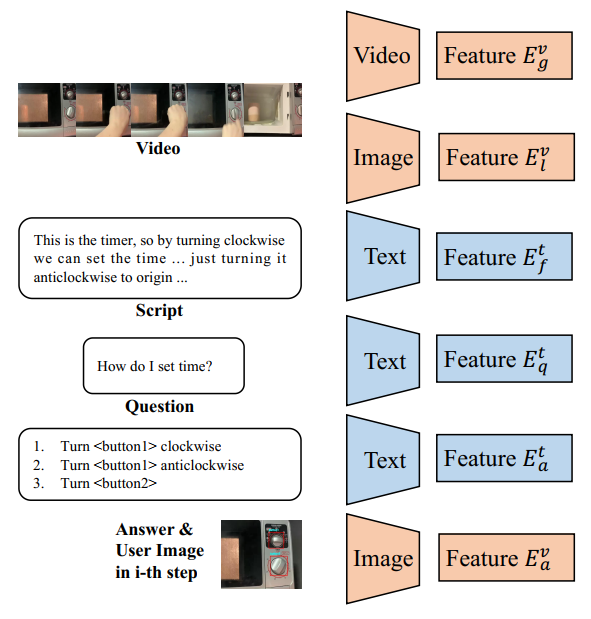
| 在本节中,我们将介绍所提出的以功能-交互为中心的框架的技术细节。在接下来的小节中,我们将介绍2.1节中的多模态对齐特征提取,2.2节中的功能交互特征聚合,2.3节中的上下文对应与多步回答。我们的方法流程如上图所示。 | ||
|
|
||
| #### 2.1 多模态对齐特征提取 | ||
|
|
||
| AQTC基准包含多源数据。我们采用基准方法如下:根据预定义模式将脚本S分割为文本功能段落$f_t$,然后通过对齐的脚本时间戳将对应的视频V分割为视觉功能片段$f_v$。通过实施这种方法,我们将指令视频和脚本分割为一组函数$\{f_1, f_2, ..., f_n\}$。每个函数f不仅包含文本描述$f_t$,还包含视觉指导$f_v$。 | ||
|
|
||
| 我们观察到文本和视觉编码器之间的对齐对最终结果有很大影响。因此,我们采用视觉语言预训练模型进行特征提取。特征对齐的效果将在第3.3节中进行彻底讨论。 | ||
|
|
||
|  | ||
|
|
||
|
|
||
| 我们以每秒1帧的速率对功能片段进行解码,并使用两个模型变量提取全局和局部剪辑特征。在局部变量中,我们使用图像编码器为每个功能剪辑提取帧级特征,表示为$E_v^l = \{[E_1]_v^l, [E_2]_v^l, ..., [E_n]_v^l\}$。另一方面,全局变量使用视频模型提取功能级特征$E_v^g = \{[E_1]_v^g, [E_2]_v^g, ..., [E_n]_v^g\}$,如上图所示。 | ||
|
|
||
| 对于全局变量,我们采用来自EgoVLP [8]的视频编码器,它在大规模自拍数据集Ego4D 上进行了预训练。选择此编码器使模型能够捕获长时间的手部物体交互,这对AQTC任务至关重要。 | ||
|
|
||
| 为确保域对齐,我们采用与视频相同的编码器对按钮图像进行编码,得到$E_v^a$。具体来说,在使用视频模型时,我们沿时间维对按钮图像进行填充。类似地,我们通过相同的文本编码器将功能段落、问题和候选答案编码为$E_t^f$、$E_t^q$和$E_t^a$。这确保了文本组件在特征空间中对齐。 | ||
|
|
||
| #### 2.2 功能交互特征聚合 | ||
|
|
||
| 我们现在来解释功能交互特征聚合的技术细节。 | ||
|
|
||
| 功能中心问题对应。考虑到相应函数与给定问题之间的语义相似性相对较低。我们提出使用基于统计的TF-IDF模型来计算特定问题Q与函数集$\{f_1, f_2, ..., f_n\}$之间的相似度分数。与使用交叉注意力相比,这种选择在小样本数据设置中已经证明了卓越的效果。 | ||
|
|
||
| 交互中心时序聚合。为了更好地捕获长视频中的手部物体交互信息,我们利用现成的HOI检测器HI-RCNN,它提供交互状态。交互中心聚合模块的流程如上图所示。 | ||
|
|
||
| 首先,我们对视觉功能剪辑$f_v$应用HI-RCNN并在帧级生成HOI状态$S_v$。接着,我们为每个功能剪辑计算一个softmax分数。最后,我们在当前局部剪辑内进行加权组合以获得聚合视频特征$E_v^f$。 | ||
|
|
||
| #### 2.3 上下文对应与多步回答 | ||
|
|
||
| 给定步数和候选答案,多步QA任务可以有效地形式化为一个分类问题。我们的目标是基于提供的历史步骤准确预测每个步骤的正确操作以及相应的按钮。 | ||
|
|
||
| 与基线方法一致,我们采用MLP进行上下文对应。为了利用历史步骤的信息并进行预测,我们使用GRU及两层MLP作为预测头,后接softmax激活。这种架构使我们能够有效捕获步骤间的依赖性,并预测每个答案的最终分数。 | ||
|
|
||
|
|
||
| $ | ||
| \hat{y}_i = \text{HEAD}(\text{GRU} (\text{MLP}([E_f, E_t^q, E_a]))) | ||
| $ | ||
|
|
||
|
|
||
| 其中,$E_f = \{E_t^f, E_v^f\}$是加权函数集,$E_t^q$表示问题的嵌入,$E_a = \{E_t^a, E_v^a\}$表示候选答案的嵌入。我们使用交叉熵(CE)和softmax激活来计算损失。 | ||
|
|
||
| $ | ||
| L = -\sum_{i=1}^N y_i \log \hat{y}_i | ||
| $ | ||
|
|
||
| ### 实验 | ||
|
|
||
| #### 3.1 实验设置 | ||
|
|
||
| 2023年AQTC挑战赛通过增加100组额外的QA对来扩展测试集,与去年相比。我们的模型在训练集上进行训练,使用2022年的训练和测试数据。评估指标Recall@1和Recall@3保持不变。 | ||
|
|
||
| 所有实验都在单个NVIDIA GeForce RTX 3090 GPU上进行。为确保公平比较,我们使用相同的参数设置训练模型,包括Adam优化器[6],学习率为$1\times10^{-4}$,训练100个epoch。我们报告在测试集上表现最佳的epoch对应的评估指标。 | ||
|
|
||
| #### 3.2 实验结果 | ||
|
|
||
| 我们在挑战赛中获得的最佳表现是通过组合所有模型的分类分数实现的,这可以看作是并行模型集成。如第2.1节所讨论的,我们采用各种良好对齐的特征提取器以确保使用可靠的多模态信息,包括CLIP、BLIP和EgoVLP 。 | ||
|
|
||
| #### 3.4 可视化结果 | ||
|
|
||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
||
| 上图直观地表示了我们方法的定性结果。通过改进的交互上下文理解和特征对齐,我们的方法相对于基线方法展示了正确的预测。 | ||
|
|
||
| ### 结论 | ||
|
|
||
| 本文介绍了一种具有时空视觉语言对齐的功能交互中心方法来解决AQTC任务。我们的实验结果展示了我们提出的方法在本次比赛中的排名第一的表现。展望未来,我们期待在AQTC领域中研究大语言模型(LLM)的上下文推理能力。 |