应用场景:
- 数据清洗【实时ETL】
- 数据报表
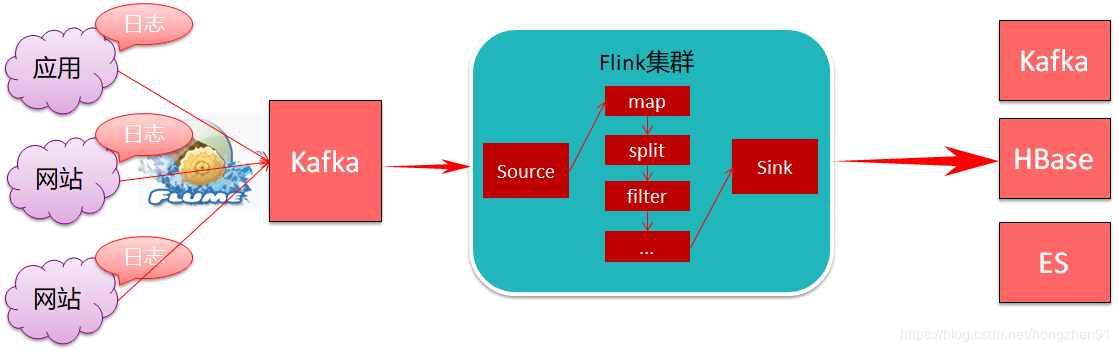
针对算法产生的日志数据进行清洗拆分
- 算法产生的日志数据是嵌套大JSON格式(json嵌套json),需要拆分打平
- 针对算法中的国家字段进行大区转换
- 最后把不同类型的日志数据分别进行存储
启动redis:
- 先从一个终端启动redis服务
./redis-server
./redis-cli
127.0.0.1:6379> hset areas AREA_US US
(integer) 1
127.0.0.1:6379> hset areas AREA_CT TW,HK
(integer) 1
127.0.0.1:6379> hset areas AREA_AR PK,SA,KW
(integer) 1
127.0.0.1:6379> hset areas AREA_IN IN
(integer) 1
127.0.0.1:6379>启动kafka:
./kafka-server-start.sh -daemon ../config/server.propertieskafka创建topc:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic allData监控kafka topic:
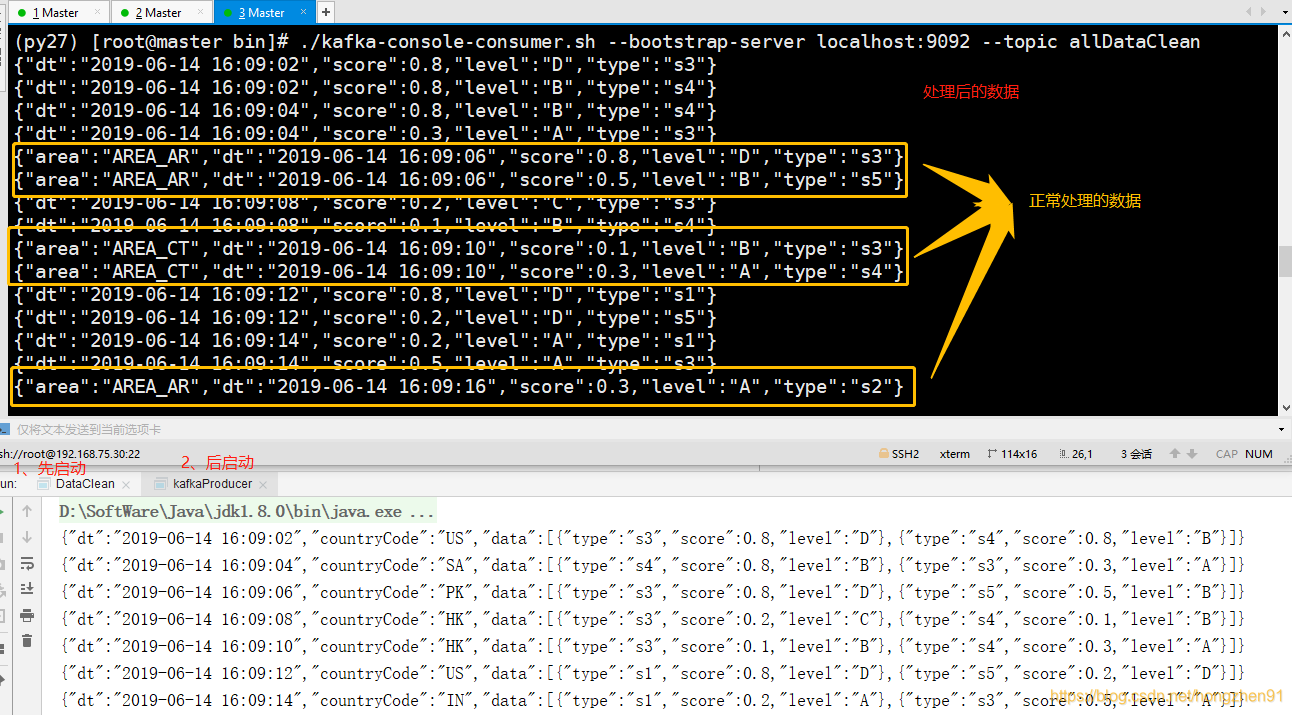
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic allDataClean
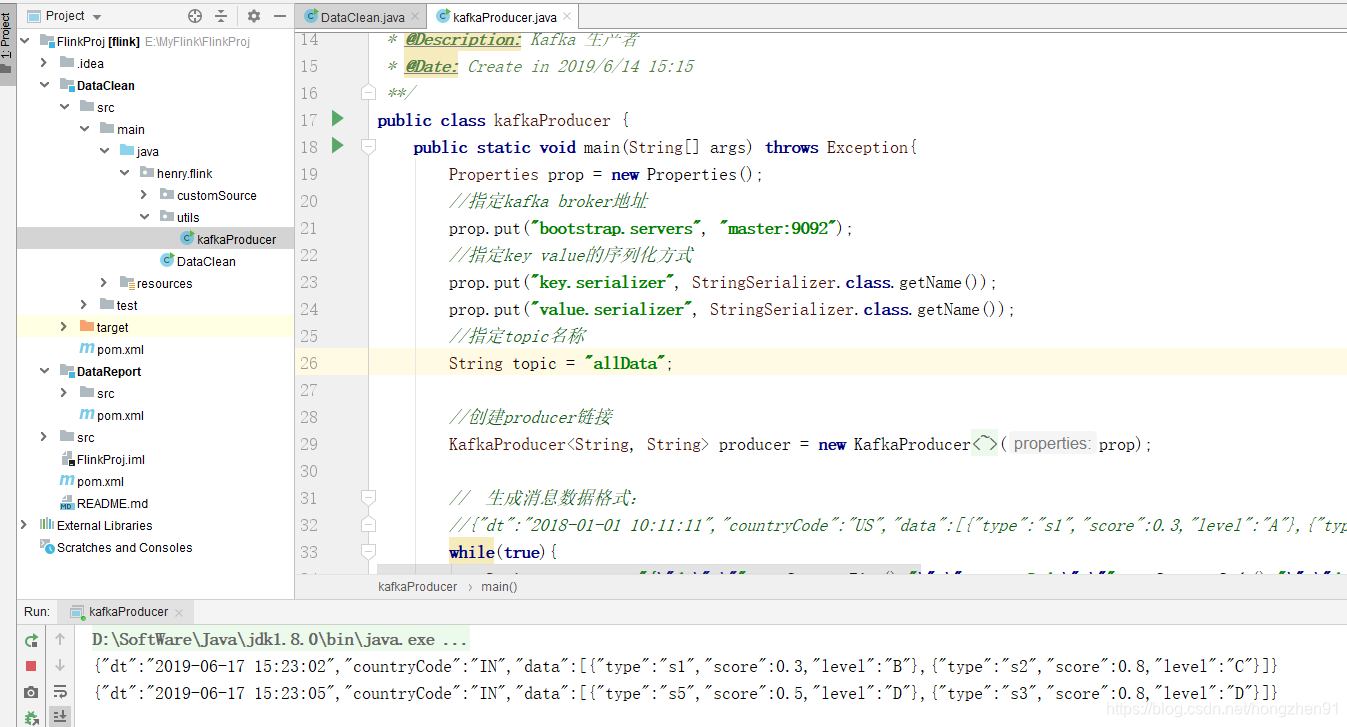
先启动 DataClean 程序,再启动生产者程序,kafka生产者产生数据如下:

最后终端观察处理输出的数据:
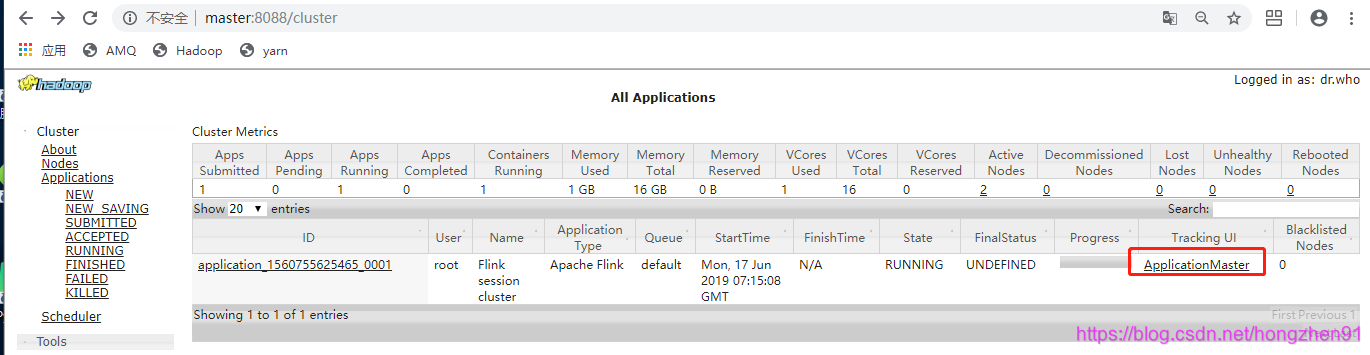
向yarn提交任务:
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c henry.flink.DataClean /root/flinkCode/DataClean-1.0-SNAPSHOT-jar-with-dependencies.jar通过 yarn UI 查看任务,并进入Flink job:
启动kafka生产者:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic allDataClean最终终端输出结果, 同IDEA中运行结果:
