Table of Contents
Digital Stethoscope aims at producing an electronics based amplifying stethoscope, which can store/ transmit the sound waveform captured to another device. Some of the advantages and motivation to switch from mechanically to electronically based amplifying are :
- Better amplification, and a more flexible range of amplification
- Noise reduction capabilities
- Ability to store and transmit sound captures in order to analyse them on a later date
We have used the following technologies and software for our project



The main goals we have set out for this project are
- Make a microphone - amplification module that can detect frequencies from 50Hz to 20kHz
- Transmit the sound clip to an associated laptop wirelessly
- Be able to detect the disease by using an associated Deep Learning model

The microcontroller that we are using in our project is the ESP32. The ESP32 is a high-performance microcontroller board that is widely used in Internet of Things (IoT) applications. Espressif Systems manufactures it, and it is the successor to the ESP8266. The ESP32 is built around a dual-core Tensilica LX6 processor that operates at up to 240 MHz, providing plenty of processing power for IoT applications.
The ESP32 microcontroller board has the following key features:
- Wi-Fi and Bluetooth connectivity: The ESP32 includes Wi-Fi and Bluetooth connectivity, making it simple to connect to the internet and other devices.
- Low power consumption: The ESP32 is energy-efficient, with multiple power modes that allow it to operate on very little power.
- Large Memory: The ESP32 comes up with up to 520 KB of SRAM and 4MB of flash memory, which is enough to run complex applications.
- GPIO pins: The ESP32 has a large number of GPIO pins, which makes it easy to interface with other devices and sensors.
- Development tools: There are many development tools available for it including Arduino IDE, ESP-IDF, and MicroPython.
Overall, the ESP32 is a powerful and versatile microcontroller board that is well-suited for a wide range of IoT applications. Its built-in Wi-Fi and Bluetooth capabilities, low power consumption, and large memory make it a popular choice among developers.
In this project, the esp32 is used to transmit the data collected from the microphone to the ML model over the in-built Wi-Fi.
Heart and lung sounds can provide important diagnostic information to healthcare professionals. Let's look closer at the different types of sounds that can be heard with a stethoscope.
The heart produces two main sounds, which are commonly referred to as "lub" and "dub." The first sound (lub) is caused by the closure of the mitral and tricuspid valves, which occurs when the ventricles contract and push blood out of the heart. The second sound (dub) is caused by the closure of the aortic and pulmonic valves, which occurs when the ventricles relax and fill with blood.
In addition to these two main sounds, there are also some abnormal heart sounds that can be indicative of various conditions, such as:
- Murmurs: Abnormal whooshing or swishing sounds caused by turbulent blood flow through the heart
- Gallops: Extra heart sounds that occur in addition to the lub-dub sounds and can indicate heart failure or other conditions.
- Clicks: High-pitched sounds are caused by the opening or closing of heart valves and can indicate valve problems.
The lungs produce various sounds that can be heard with a stethoscope. The most common lung sounds are:
- Bronchial sounds: Loud, high-pitched sounds can be heard over the trachea and larger airways.
- Vesicular sounds: Softer, lower-pitched sounds can be heard over the smaller airways and lung tissue.
- Crackles: Sounds caused by the opening of small airways that have been closed due to inflammation or fluid buildup.
- Wheezes: High-pitched sounds caused by narrowed airways, often due to asthma or chronic obstructive pulmonary disease (COPD).
Digital stethoscopes can amplify and filter these sounds, making them easier to hear and interpret and allowing for more accurate diagnosis and treatment.
In this project, we are utilizing an analog microphone to capture the subtle sounds of the heart and lungs. To ensure high-quality recordings, we have designed an RC low pass filter with a cut-off frequency of 4 kHz, which effectively reduces any high-frequency noise that may interfere with the recordings.
It is worth noting that heart sounds typically fall within the frequency range of 5-600 Hz, while the frequency range of healthy lung sounds can extend up to 1000 Hz. In certain abnormal cases, lung sounds may even appear at frequencies above 2000 Hz. By capturing these sounds within the appropriate frequency range, we can detect any anomalies that may be indicative of underlying medical conditions. Our approach provides a unique opportunity to identify and monitor heart and lung health using a non-invasive, low-cost method.
The output of the analog microphone is initially fed into an RC low-pass filter with a cut-off frequency of 4 kHz to eliminate high-frequency noise that could potentially disrupt the recordings. The filtered signal is then amplified using a two-stage non-inverting configuration of operational amplifiers, which boosts the signal to a level that can be detected by the microcontroller.
It is important to note that we have utilized a single supply for the operational amplifiers, with the supply voltages being +Vcc and Gnd, in contrast to the conventional method of using +Vcc and -Vcc. The amplified signal is then directed towards a second-order Butterworth filter, which further removes any unwanted noise, ensuring that the signal being processed is clear and accurate.
The output from the Butterworth filter is then fed to the analog pin of an ESP32 microcontroller, which collects data at a rate of 8000 samples per second. This sampling rate is sufficient, as the frequency range of heart and lung sounds fall below 4kHz, and according to the Nyquist theorem, we need to sample the signal at least twice the maximum frequency to reconstruct it accurately.
The collected data is then transmitted via a WiFi-based communication channel to a server, where it is stored for further analysis. In this case, we are using a laptop as our server to store the recorded data. The stored data is then processed using a Machine Learning (ML) model, which enables us to classify the different heart and lung sounds accurately.
Overall, this approach provides a non-invasive, convenient, and low-cost method for monitoring and diagnosing medical conditions related to heart and lung sounds. The ML model enhances the accuracy of the analysis, allowing for more precise detection and diagnosis of potential medical issues.
Link to the dataset
This dataset is a collection of respiratory sound recordings. The dataset consists of a total of 920 annotated respiratory sound recordings (4.2 GB) in WAV format, collected from 126 patients. The recordings were collected from different clinical environments, including emergency departments, hospital wards, and outpatient clinics. The patients were suffering from various respiratory disorders, including asthma, chronic obstructive pulmonary disease.
The respiratory sound recordings were collected using digital stethoscopes.
- Crackles (also called rales): Discontinuous sounds heard during inhalation or exhalation. They can be fine, medium, or coarse and may have different qualities, such as moist, dry, or bubbling.
- Wheezes: Continuous, high-pitched sounds heard during exhalation or inhalation. They can be musical, whistling, or hissing in nature.
- Other abnormal sounds: Sounds that do not fit into the categories of crackles or wheezes, such as stridor or pleural rubs.
The dataset is organized into folders for each patient, with each folder containing one or more respiratory sound recordings in WAV format. Each recording is labeled with the presence or absence of crackles and wheezes, as well as the overall quality of the recording. The annotations are provided in text files with the same name as the corresponding recording.
CNN
A Convolutional neural network (CNN) is a neural network that has one or more convolutional layers and are used mainly for image processing, classification, segmentation and also for other auto correlated data. A convolution is essentially sliding a filter over the input. One helpful way to think about convolutions is this quote from Dr Prasad Samarakoon: “A convolution can be thought as “looking at a function’s surroundings to make better/accurate predictions of its outcome.”

The architecture of the model used here is as follows :
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d (Conv2D) | (None, 39, 861, 16) | 80 |
| max_pooling2d (MaxPooling2D ) | (None, 19, 430, 16) | 0 |
| dropout (Dropout) | (None, 19, 430, 16) | 0 |
| conv2d_1 (Conv2D) | (None, 18, 429, 32) | 2080 |
| max_pooling2d_1 (MaxPooling2D) | (None, 9, 214, 32) | 0 |
| dropout_1 (Dropout) | (None, 9, 214, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 8, 213, 64) | 8256 |
| max_pooling2d_2 (MaxPooling 2D) | (None, 4, 106, 64) | 0 |
| conv2d_3 (Conv2D) | (None, 3, 105, 128) | 32896 |
| max_pooling2d_3 (MaxPooling 2D) | (None, 1, 52, 128) | 0 |
| dropout_3 (Dropout) | (None, 1, 52, 128) | 0 |
| global_average_pooling2d (G lobalAveragePooling2D) | (None, 128) | 0 |
| dense (Dense) | (None, 6) | 774 |
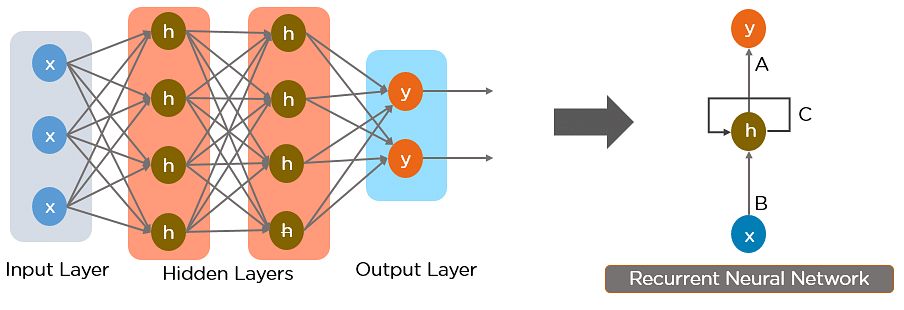
Recurrent Neural Network is a generalization of feedforward neural network that has an internal memory. RNN is recurrent in nature as it performs the same function for every input of data while the output of the current input depends on the past one computation. After producing the output, it is copied and sent back into the recurrent network. For making a decision, it considers the current input and the output that it has learned from the previous input. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. In other neural networks, all the inputs are independent of each other. But in RNN, all the inputs are related to each other.
LSTM
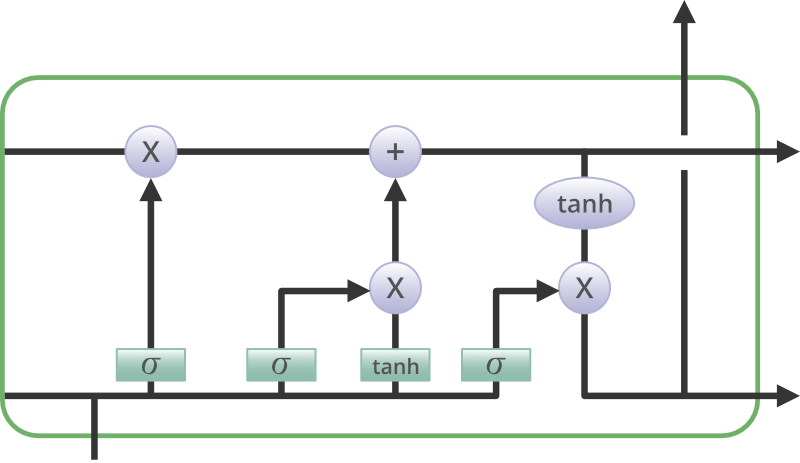
Long Short-Term Memory (LSTM) networks are a modified version of recurrent neural networks, which makes it easier to remember past data in memory. The vanishing gradient problem of RNN is resolved here. LSTM is well-suited to classify, process and predict time series given time lags of unknown duration. It trains the model by using back-propagation. In an LSTM network, three gates are present: Input gate — discover which value from input should be used to modify the memory. Sigmoid function decides which values to let through 0,1. and tanh function gives weightage to the values which are passed deciding their level of importance ranging from-1 to 1. Forget gate — discover what details to be discarded from the block. It is decided by the sigmoid function. it looks at the previous state(ht-1) and the content input(Xt) and outputs a number between 0(omit this)and 1(keep this)for each number in the cell state. Output gate— the input and the memory of the block is used to decide the output. Sigmoid function decides which values to let through 0,1. and tanh function gives weightage to the values which are passed deciding their level of importance ranging from-1 to 1 and multiplied with output of Sigmoid There were multiple architectures used that are explained in detail in the Heart-Model folder
Tried couple of architecture but one given here is as :
| Layer (type) | Output Shape | Param # |
|---|---|---|
| LSTM | (None, 30, 256) | 264192 |
| LSTM | (None, 30,128) | 197120 |
| LSTM | (None, 64) | 49408 |
| Dense | (None,3) | 195 |
Speech Recognition is a supervised learning task. In the speech recognition problem input will be the audio signal and we have to predict the text from the audio signal. We can’t take the raw audio signal as input to our model because there will be a lot of noise in the audio signal. It is observed that extracting features from the audio signal and using it as input to the base model will produce much better performance than directly considering raw audio signal as input. MFCC is the widely used technique for extracting the features from the audio signal.



This gave accuracies of :
- model train data score : 74 %
- model test data score : 76 %
- model validation data score : 79 %
- model unlabeled data score : 74 %
