| 课程名称: | 操作系统 |
|---|---|
| 任课教师: | 翟高寿 |
| 小组成员: | 胡栩贤、魏振杰 |
| 成员学号: | 20231159、20241068 |
| 专业年级: | 计算机科学与技术 |
| 学院名称: | 詹天佑学院 |
| 提交时间: | 2022年12月18日 |
[TOC]
基于龙芯LoongArch64的操作系统的构建:要求实现启动初始化、进程管理、内存管理、显示器与键盘驱动、文件系统、系统调用及命令解释器等主要模块,并在QEMU虚拟机或龙芯处理器计算机上测试验证。
Mini Kernel:Mini Kernel是一个研究系统装载和中断处理的微内核,其本身基于loongarch,且代码只有500行左右。麻雀虽小,五脏俱全,其实现了基本的键盘中断和时钟中断,同时简单实现了输出函数,为我们的开头工作提供了极大的便利。
Linux 0.11:Linux 0.11作为最早一批相对完整的操作系统,其思想历经三十多年仍熠熠生辉。是现有许多操作系统只是的基础。我们从中学习了许多数据结构、代码规范、管理算法。
linux-loongarch-v2022:linux-loongarch-v2022作为较新的基于loongarch的linux操作系统,与龙芯架构的底层逻辑更为贴近,是代码实现细节学习的基础。
龙芯官方文档:龙芯官方文档包括《龙芯架构参考手册》、《龙芯处理器寄存器使用手册》、《龙芯处理器数据手册》等文件,为我们的实际考证提供了莫大的帮助。

为了保证在学习开发过程中有足够的成就感推动我们攻克难关,我们会在核心工作(如中断管理、内存管理、进程管理、文件管理、标准库实现)遇到阻碍时转而尝试开发一些简单的、可视化的、有意思的模块(如shell、vim、图形界面之类),以免长期困于同一个挫折中而丧失了推进工作的动力。
-
底层和上层结合,核心模块与直观模块相结合
-
开发步骤:确定核心概念,定义模块行为,设计数据结构,确定模块方法,进行开发优化,系统联调测试
Satori:佛教禅宗用语,指心灵之顿悟、开悟;期盼在设计学习的过程中有所顿悟。

开源地址:
SatoriOS: 开悟操作系统,仅供个人学习使用(暂时停止更新)。 (github.com)
SatoriOS: 开悟操作系统,仅供个人学习使用。 (gitee.com)
Echo:指回声,灵感来源于一款名为《Dark Echo》的解密游戏,寓意在黑暗中通过努力,获得反馈,不断探索。

开源地址:
EchoOS: my first OS (github.com)
台式计算机
【处理器:Intel(R) Core(TM) i7-10750H CPU @ 2.60GHz 2.59 GHz;内存:16GB,15.8GB可用】
【处理器:AMD Ryzen 7 4800U with Radeon Graphics @ 1.80 GHz;内存:16GB,15.4GB可用】
Windows 10 21H2
系统类型:基于x64的处理器,64位操作系统
| 平台需求 | 具体平台 |
|---|---|
| 虚拟机平台: | VMware Workstation 16 Pro V16.2.4 |
| 虚拟机系统环境: | Ubuntu20.04 |
| 交叉编译工具: | loongarch64-clfs-2021-12-18-cross-tools-gcc-full |
| 自制操作系统运行平台: | QEMU 6.2.50 |
为了验证环境配置已经就绪,我们实现了对Mini Linux系统的编译运行,并将编译过程记录如下。
这是一个攀登到巨人肩膀上的工作。
创建一个shell脚本,用于设置交叉编译器的路径和环境。
env.sh:
CC_PREFIX=/opt/cross-tools
export PATH=$CC_PREFIX/bin:$PATH
export LD_LIBRARY_PATH=$CC_PREFIX/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$CC_PREFIX/loongarch64-unknown-linux-gnu/lib/:$LD_LIBRARY_PATH
export ARCH=loongarch
export CROSS_COMPILE=loongarch64-unknown-linux-gnu-
export LC_ALL=C; export LANG=C; export LANGUAGE=C交叉编译过程中需要的配置文件
cp arch/loongarch/configs/loongson3_defconfig_qemu .config其内容大体如下:
……
CONFIG_CRASH_CORE=y
CONFIG_GENERIC_ENTRY=y
CONFIG_HAVE_64BIT_ALIGNED_ACCESS=y
CONFIG_ARCH_USE_BUILTIN_BSWAP=y
CONFIG_HAVE_IOREMAP_PROT=y
CONFIG_HAVE_NMI=y
CONFIG_TRACE_IRQFLAGS_SUPPORT=y
CONFIG_HAVE_ARCH_TRACEHOOK=y
CONFIG_HAVE_DMA_CONTIGUOUS=y
……sudo apt install make
sudo apt install make-doc
sudo apt install make-guile
sudo apt install gcc
sudo apt install flex
sudo apt install bison
sudo apt install libssl-devmake clean
source env.sh
make
自此,我们的平台基础和开发环境正式测试完成。
项目的文件结构如下图所示:(以SatoriOS为例)
学习Linux的源文件组织方式,将头文件和C文件分开管理。iuclude文件夹用于存放所有的头文件,而kernel文件夹用于存放所有的C文件,以及记录参考资料的md文件。
所有的编译中间产生文件均被放置在build文件夹中,该文件夹会被动态创建和删除。
tools文件夹用于放置一些辅助开发的工具,一般用python语言实现,其中包含一个查看内存分布的小工具。
output文件夹用于放置一些中间产物(主要是由tools内的工具产生的),暂时并未启用。



为了方便IDE定位头文件所在位置,可在VSCode中做如下配置:
{
"configurations": [
{
...
"includePath": [
"${workspaceFolder}/include/**",
],
...
}
],
...
}本系统通过编写多级Makefile文件实现对源代码的编译和链接,详细编译过程如下。
在kernel文件夹中添加负责内核总体编译的Makefile文件,其主要功能是
- 定义基本编译/链接指令参数,并将其
export至工作空间
export TOOLPREFIX := loongarch64-unknown-linux-gnu-
export CC = $(TOOLPREFIX)gcc
export LD = $(TOOLPREFIX)ld
export CFLAGS = -Wall -O2 -g3 \
-march=loongarch64 -mabi=lp64s \
-ffreestanding -fno-common \
-nostdlib \
-I../include \ # 告知gcc头文件的相对路径
-fno-stack-protector \
-fno-pie -no-pie
export LDFLAGS = -z max-page-size=4096- 遍历
kernel文件夹,确定需要编译链接的中间目标文件,这里默认将每个子文件夹的名字作为目标文件的文件名
TGTDIR := ../build/ # 编译目标输出文件夹
TARGET := $(TGTDIR)kernel
SOURCE := $(wildcard *.c)
# 遍历所有的文件夹,并将文件夹的名字作为中间目标产物的名字
SUBOBJS = $(filter %.o, $(patsubst ./%, %.o, $(shell find -maxdepth 1 -type d)))
OBJECTS = $(patsubst %.c, $(TGTDIR)%.o, $(SOURCE))
OBJECTS += $(patsubst %.o, $(TGTDIR)%.o, $(SUBOBJS))- 遍历并进入到每一个子文件夹中执行
make指令,递归地完成编译,并将所有中间产物最终链接为内核
$(TARGET): $(OBJECTS) ld.script # 根据链接脚本进行链接
@echo Linking $(TARGET)
$(ECHOPRE)$(LD) $(LDFLAGS) -T ld.script -o $(TARGET) $(OBJECTS)
$(TGTDIR)%.o : %.c
@echo Compiling $<
$(ECHOPRE)$(CC) $(CFLAGS) -c -o $@ $<
$(TGTDIR)%.o : # 递归地执行编译
@echo -------------------------- == $(subst .o,,$@) == ------------------------------
@mkdir -p $(subst .o,,$@)
@(cd $(subst $(TGTDIR),,$(subst .o,,$@)); make) # 进入到子文件夹并执行`make`指令每一个子文件夹中的Makefile文件内容类似如下
SECNME := mm # 该模块名称
TGTDIR := ../../build/ # 目标产物文件夹
INCDIR := ../../include # 头文件目录
SUBDIR := $(TGTDIR)$(SECNME)/
TARGET := $(TGTDIR)$(SECNME).o
SOURCE := $(wildcard *.c)
OBJECTS := $(patsubst %.c, $(SUBDIR)%.o, $(SOURCE))
CFLAGS += -I../../include
all: $(TARGET)
$(TARGET): $(OBJECTS)
@echo Linking $(TARGET)
$(ECHOPRE)$(LD) -r -o $(TARGET) $(OBJECTS)
$(SUBDIR)%.o : %.c
@echo Compiling $<
$(ECHOPRE)$(CC) $(CFLAGS) -c -o $@ $<基本参数设置如下:
MEM="4G"
CPUS="1"
BIOS="/opt/SatoriVenv/loongarch_bios_0310.bin"
#BIOS="/opt/SatoriVenv/loongarch_bios_0310_debug.bin"
KERNEL="./build/kernel"
INITRD="/opt/SatoriVenv/busybox-rootfs.img"
USE_GRAPHIC="yes"
DEBUG=''
QEMU="qemu-system-loongarch64"由于键盘驱动需要QEMU启动可视化设备,因此可设置相关参数如下:
if [ $USE_GRAPHIC = "no" ] ; then
# run without graphic
CMDLINE="root=/dev/ram console=ttyS0,115200 rdinit=/init"
GRAPHIC="-vga none -nographic"
else
# run with graphic
CMDLINE="root=/dev/ram console=tty0 rdinit=/init"
GRAPHIC="-vga virtio -serial stdio"启动命令(借助QEMU)
$QEMU -m $MEM -smp $CPUS -bios $BIOS -kernel $KERNEL -append "$CMDLINE" $GRAPHIC $DEBUGBIOS(Basic Input Output System,基本输入输出系统)诞生于1975年的CP/M计算机。UEFI,全称Unified Extensible Firmware Interface,即“统一的可扩展固件接口”,是一种详细描述全新类型接口的标准,这种接口用于操作系统自动从预启动的操作环境,加载到一种操作系统上。是适用于电脑的标准固件接口,旨在代替BIOS(基本输入/输出系统)。
UEFI是BIOS的一种升级替代方案。UEFI本身已经相当于一个微型操作系统,相比BIOS具有更强大的功能支持,能为操作系统提供更多的便利(当然,由于其权限极大,不得不让人质疑其安全性)。首先,UEFI已具备文件系统的支持,它能够直接读取FAT分区中的文件。其次,可开发出直接在UEFI下运行的应用程序,这类程序文件通常以efi结尾。
相比之下,基于BIOS要完成这些工作将会复杂许多。因为BIOS下启动操作系统之前,必须从硬盘上指定扇区读取系统启动代码(包含在主引导记录中),然后从活动分区中引导启动操作系统。对扇区的操作远比不上对分区中文件的操作更直观更简单,所以在BIOS下引导安装系统,我们不得不使用一些工具对设备进行配置以达到启动要求。而在UEFI下,这些统统都不需要,不再需要主引导记录,不再需要活动分区,不需要任何工具,只要复制安装文件到一个FAT32(主)分区/U盘中,然后从这个分区/U盘启动即可。


龙芯之前定义了一个启动规范,定义了固件和内核的交互接口,但是在推动相关补丁进入上游社区时,内核的维护者们提出了不同意见。社区倾向于采用EFI标准提供的启动功能,即编译内核时生成一个kernel.efi这样的EFI模块,它可以不用任何grub之类的装载器实现启动。因为还没有最终定论,导致龙芯开源版本的内核和BIOS互相没有直接支持。因此我们不得不从github.com/loongson fork了相应的软件,进行了一点修改。这里对目前的启动约定做一个简单的说明:
- UEFI bios装载内核时,会把从内核elf文件获取的入口点地址(可以用readelf -h或者-l vmlinux看到)抹去高32位使用。比如vmlinux链接的地址是0x9000000001034804,实际bios跳转的地址将是0x1034804,代码装载的位置也是物理内存0x1034804。BIOS这么做是因为它逻辑上相当于用物理地址去访问内存,高的虚拟地址空间没有映射不能直接用。
- 内核启动入口代码需要做两件事:(参见arch/loongarch/kernel/head.S)
- 设置一个直接地址映射窗口(参见loongarch体系结构手册,5.2.1节),把内核用到的64地址抹去高位映射到物理内存。目前linux内核是设置0x8000xxxx-xxxxxxxx和0x9000xxxx-xxxxxxxx地址抹去最高的8和9为其物理地址,前者用于uncache访问(即不通过高速缓存去load/store),后者用于cache访问。
- 做个代码自跳转,使得后续代码执行的PC和链接用的虚拟地址匹配。BIOS刚跳转到内核时,用的地址是抹去了高32位的地址(相当于物理地址),步骤1使得链接时的高地址可以访问到同样的物理内存,这里则换回到原始的虚拟地址。
我们这里使用链接脚本(ld.script)设置内核入口:
OUTPUT_ARCH( "loongarch" )
ENTRY( kernel_entry )
SECTIONS
{
. = 0x92000000;
.text : {
*(.text .text.*)
PROVIDE(etext = .);
}
.rodata : {
. = ALIGN(16);
*(.srodata .srodata.*)
. = ALIGN(16);
*(.rodata .rodata.*)
}
.data : {
. = ALIGN(16);
*(.sdata .sdata.*)
. = ALIGN(16);
*(.data .data.*)
}
.bss : {
. = ALIGN(16);
*(.sbss .sbss.*)
. = ALIGN(16);
*(.bss .bss.*)
}
PROVIDE(end = .);
}通过上述步骤,我们成功完成了内核装载并启动,同时设置了内核入口,就相当于给我们的操作系统“程序”设置了一个“main”函数,但是在这样的命令行窗口,没有输出,我们无法看到任何东西,也就无法做任何有意义的交互,甚至无法进行基本的调试工作。因此,摆在我们面前亟待解决的第一个问题就是——实现printf。
作为一个从0开始实现的操作系统,一开始并没有标准的输入输出库供我们使用,经过研究,想要在命令行窗口实现输出,我们决定通过串口实现输出与通信。
对于串口的通信,龙芯3A5000提供了两块UART(Universal Asynchronous Receiver Transmitter)控制器进行控制,分别为UART0和UART1从《龙芯3A5000_3B5000处理器寄存器使用手册》中我们可以找到UART0控制器的物理地址为0x1FE00100,在输出过程中,涉及到的两个重要寄存器如下图:


其中DAT寄存器,负责输入数据的传输,是我们向命令行窗口输出的端口,接收8位宽的 ascii码;LSR寄存器则负责在传输前后检测输出状态,其第5个标志位代表当前串口是否为空,即是否能够传输数据,防止对前面传入但未处理的数据造成直接覆盖。


具体实现和管理代码如下:
static const unsigned long uart_base = 0x1fe001e0;
#define UART0_THR (uart_base + 0)
#define UART0_LSR (uart_base + 5)
#define LSR_TX_IDLE (1 << 5)
static char io_readb()
{
return *(volatile char*)UART0_LSR;
}
static void io_writeb(char c)
{
while ((io_readb() & LSR_TX_IDLE) == 0){
asm volatile("nop\n" : : : );
}
*(char*)UART0_THR = c;
}在此基础上,我们进一步封装出putc(输出单个字符)和puts(输出字符串):
void putc(char c)
{
// wait for Transmit Holding Empty to be set in LSR.
while ((io_readb() & LSR_TX_IDLE) == 0);
io_writeb(c);
}
void puts(char *str)
{
while (*str != 0)
{
putc(*str);
str++;
}
}格式化输出函数设计实现如下:
void printf(const char *fmt, ...)
{
va_list ap;
int i, c, n;
char *s;
if (fmt == 0)
{
intr_on();
return;
}
va_start(ap, fmt);
for (i = 0; (c = fmt[i] & 0xff) != 0; i++)
{
if (c != '%')
{
putc(c);
continue;
}
c = fmt[++i] & 0xff;
if (c == 0)
break;
switch (c)
{
case 'd': // 打印10进制整数
print_int(va_arg(ap, int), 10, 1);
break;
case 'x': // 打印16进制整数
print_int(va_arg(ap, int), 16, 1);
break;
case 'P': // 打印64位地址
print_ptr(va_arg(ap, unsigned long));
break;
case 'p': // 打印32位地址
print_ptr_short(va_arg(ap, unsigned long));
break;
case 's': // 打印字符串
if ((s = va_arg(ap, char *)) == 0)
s = "(null)";
for (; *s; s++)
putc(*s);
break;
case 'c': // 打印字符
putc((char)(va_arg(ap, int)));
break;
case 'O': // 打印字符串(16位左对齐)
n = 16;
if ((s = va_arg(ap, char *)) == 0)
s = "(null) ";
for (; n; s++, n--)
putc(*s ? *s : ' ');
break;
case 'o': // 打印字符串(8位左对齐)
n = 8;
if ((s = va_arg(ap, char *)) == 0)
s = "(null) ";
for (; n; s++, n--)
putc(*s ? *s : ' ');
break;
case '%':
putc('%');
break;
default:
putc('%');
putc(c);
break;
}
}
}在此基础上,我们了解到可以通过ANSI控制码实现对串口窗口的多样化控制,我们将相关方法进行了封装,其中一些示例如下:
static inline void cursor_move_to(sint x, sint y); // 光标位置移动到
static inline void clear_screen(); // 清屏
static inline void set_cursor_style(sint style); // 设置光标样式
static inline void set_cursor_color(sint color); // 设置光标(字体)颜色
static inline void set_cursor_background_color(sint color); // 设置光标(字体)背景颜色
void save_cursor_style(); // 保存光标样式
void restore_cursor_style(); // 恢复光标样式
void save_cursor_color(); // 保存光标(字体)颜色
void restore_cursor_color(); // 恢复光标(字体)颜色在以上输出控制模块的基础上,我们统一了内核信息输出的标准格式,定义了四种输出类型,其实现如下:
#define pr_info(src, fmt, ...) \
{ \
save_cursor_color(); \
set_cursor_color(ANSI_GREEN); \
printf("[" #src "] | INFO | "); \
printf(fmt, ##__VA_ARGS__); \
put_char('\n'); \
restore_cursor_color(); \
}
#define pr_warn(src, fmt, ...) \
{ \
save_cursor_color(); \
set_cursor_color(ANSI_YELLOW); \
printf("[" #src "] | WARN | "); \
printf(fmt, ##__VA_ARGS__); \
put_char('\n'); \
restore_cursor_color(); \
}
#define pr_error(src, fmt, ...) \
{ \
save_cursor_color(); \
set_cursor_color(ANSI_RED); \
printf("[" #src "] | ERROR | "); \
printf(fmt, ##__VA_ARGS__); \
put_char('\n'); \
restore_cursor_color(); \
die(); \
}
#ifdef CONFIG_DEBUG
#define pr_debug(src, fmt, ...) \
{ \
save_cursor_color(); \
set_cursor_color(ANSI_BLUE); \
printf("[" #src "] | DEBUG | "); \
printf(fmt, ##__VA_ARGS__); \
put_char('\n'); \
restore_cursor_color(); \
}
#else
#define pr_debug(src, fmt, ...) \
{ \
}
#endif /* !CONFIG_DEBUG */内核各模块在使用上述基本模块时,可以进行封装,例如:
#define mm_info(fmt, ...) pr_info(MM, fmt, ##__VA_ARGS__)
#define mm_warn(fmt, ...) pr_warn(MM, fmt, ##__VA_ARGS__)
#define mm_error(fmt, ...) pr_error(MM, fmt, ##__VA_ARGS__)
#define mm_debug(fmt, ...) pr_debug(MM, fmt, ##__VA_ARGS__)(1)为了实现中断处理,首先是对中断的初始化,为各个中断相关的芯片写入控制方式,同时为CPU设置中断入口、中断使能等中断基本信息;
(2)当接收到中断后,CPU会自动跳转到设置的中断入口处运行;
(3)当前我们使用的是单个中断,在进入中断后,各个中断统一进入trap_entry函数进行现场保护,而后进入中断处理函数trap_handle;
(4)在trap_handle函数中,我们通过读取例外配置寄存器获取当前中断状态并和配置的中断配置寄存器以及各中断设备进行比较,确定触发中断的设备并进入对应设备的中断处理函数。

对于中断过程的初始化可以分为四部分:
void trap_init(void)
{
/*CPU控制状态寄存器设置*/
unsigned int ecfg = ( 0U << CSR_ECFG_VS_SHIFT ) | HWI_VEC | TI_VEC;
unsigned long tcfg = 0x0a000000UL | CSR_TCFG_EN | CSR_TCFG_PER;
w_csr_ecfg(ecfg);
w_csr_tcfg(tcfg);
w_csr_eentry((unsigned long)trap_entry);
/*拓展io中断初始化*/
extioi_init();
/*桥片初始化*/
ls7a_intc_init();
/*键鼠控制芯片初始化*/
i8042_init();
}首先是对控制状态寄存器的设置,不同于8086简单基础的架构,龙芯对CPU本身设置了大量的可配置内容,其通过控制状态寄存器进行设置。所有的控制状态寄存器需要通过龙芯的csrwr/csrrd指令进行控制。
ecfg个tcfg分别为例外配置寄存器和时钟配置寄存器,这样我们就实现了对于中断的基础配置和一个十分重要的中断源——时钟中断源:


同时我们还需要向eentry控制状态寄存器中写入我们编写的中断入口函数地址。
对CPU的控制状态寄存器配置完成后,我们需要对CPU的IO端口的控制状态进行配置:
void extioi_init(void)
{
iocsr_writeq((0x1UL << UART0_IRQ) | (0x1UL << KEYBOARD_IRQ) |
(0x1UL << MOUSE_IRQ) | (0x1UL << DISK_IRQ),
LOONGARCH_IOCSR_EXTIOI_EN_BASE);
/* extioi[31:0] map to cpu irq pin INT1, other to INT0 */
iocsr_writeq(0x01UL,LOONGARCH_IOCSR_EXTIOI_MAP_BASE);
/* extioi IRQ 0-7 route to core 0, use node type 0 */
iocsr_writeq(0x0UL,LOONGARCH_IOCSR_EXTIOI_ROUTE_BASE);
/* nodetype0 set to 1, always trigger at node 0 */
iocsr_writeq(0x1,LOONGARCH_IOCSR_EXRIOI_NODETYPE_BASE);
}这里分别对拓展IO中断使能寄存器、中断路由寄存器、中断目标处理器核路由寄存器地址和中断目标结点映射方式寄存器进行了配置。
对CPU的配置完成后,我们还需要对桥片芯片进行配置,配置其中断使能寄存器、中断向量寄存器等:
void ls7a_intc_init(void)
{
/* enable uart0/keyboard/mouse */
*(volatile unsigned long*)(LS7A_INT_MASK_REG) = ~((0x1UL << UART0_IRQ) | (0x1UL << KEYBOARD_IRQ) |
(0x1UL << MOUSE_IRQ));
*(volatile unsigned long*)(LS7A_INT_EDGE_REG) = (0x1UL << (UART0_IRQ | KEYBOARD_IRQ | MOUSE_IRQ));
/* route to the same irq in extioi */
*(volatile unsigned char*)(LS7A_INT_HTMSI_VEC_REG + UART0_IRQ) = UART0_IRQ;
*(volatile unsigned char*)(LS7A_INT_HTMSI_VEC_REG + KEYBOARD_IRQ) = KEYBOARD_IRQ;
*(volatile unsigned char*)(LS7A_INT_HTMSI_VEC_REG + MOUSE_IRQ) = MOUSE_IRQ;
*(volatile unsigned long*)(LS7A_INT_POL_REG) = 0x0UL;
}自此,中断还不能够正常运行,我们还需要对外围设备进行配置。我们知道不同设备都会有不同的控制状态和输入输出端口,对应设备控制芯片的控制寄存器、数据寄存器和状态寄存器(i8042的控制寄存器和状态寄存器共用一个端口),这里我们最直接涉及到的就是对键鼠进行控制的i8042芯片,我们需要在其控制端口写入我们需要的控制方式:
void i8042_init(void)
{
unsigned char data;
/* disable device */
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0xAD;
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0xA7;
/* flush */
data = *(volatile unsigned char*)(LS7A_I8042_DATA);
/* self test */
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0xAA;
data = *(volatile unsigned char*)(LS7A_I8042_DATA);
/* set config byte, enable device and interrupt*/
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0x20;
data = *(volatile unsigned char*)(LS7A_I8042_DATA);
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0x60;
*(volatile unsigned char*)(LS7A_I8042_DATA) = 0x07;
/* test */
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0xAB;
data = *(volatile unsigned char*)(LS7A_I8042_DATA);
/* enable first port */
*(volatile unsigned char*)(LS7A_I8042_COMMAND) = 0xAE;
/* reset device */
*(volatile unsigned char*)(LS7A_I8042_DATA) = 0xFF;
data = *(volatile unsigned char*)(LS7A_I8042_DATA);
}这样我们就是完整实现了键鼠中断以及时钟中断并将中断定向到我们设置的中断入口处。
在操作系统的运行过程中,因为处于命令行状态下,我们最主要的交互方式就是通过键盘实现输入,下图为设计的键盘驱动处理过程。

当我们通过中断进入键盘的中断处理程序后,会先通过状态端口判断i8042的数据端口是否有未读的数据,如果有,则可以通过数据端口读取数据。
此时我们读取到的数据为键盘扫描码,我们需要通过键盘扫描码映射到键盘按键表,其中包含了每一个按键的ascii码(若没有则为0)。然后外部的应用可以通过注册键盘的回调,在键盘中断的过程中接收键盘驱动分发的键盘数据。
首先将键盘扫描码映射为键号:
const unsigned int keymap[] = {
...
/* 28 */ KEY_RESERVED, KEY_SPACE, KEY_V, KEY_F, KEY_T, KEY_R, KEY_5, KEY_F6,
/* 30 */ KEY_RESERVED, KEY_N, KEY_B, KEY_H, KEY_G, KEY_Y, KEY_6, KEY_F7,
/* 38 */ KEY_RESERVED, KEY_RIGHTALT, KEY_M, KEY_J, KEY_U, KEY_7, KEY_8, KEY_F8,
/* 40 */ KEY_RESERVED, KEY_COMMA, KEY_K, KEY_I, KEY_O, KEY_0, KEY_9, KEY_F9,
...
};进一步将键号映射为ASCII码:
const char kbd_US[128] =
{
0, 27, '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '-', '=', '\b',
'\t', /* <-- Tab */
'q', 'w', 'e', 'r', 't', 'y', 'u', 'i', 'o', 'p', '[', ']', '\n',
0, /* <-- control key */
'a', 's', 'd', 'f', 'g', 'h', 'j', 'k', 'l', ';', '\'', '`', 0, '\\', 'z', 'x', 'c', 'v', 'b', 'n', 'm', ',', '.', '/', 0,
...
};若同时按下shift,则使用另一个表完成映射:
const char kbd_US_shift[128] =
{
0, 27, '!', '@', '#', '$', '%', '^', '&', '*', '(', ')', '_', '+', 0,
0, /* <-- Tab */
'Q', 'W', 'E', 'R', 'T', 'Y', 'U', 'I', 'O', 'P', '{', '}', '\n',
0, /* <-- control key */
'A', 'S', 'D', 'F', 'G', 'H', 'J', 'K', 'L', ':', '\"', '~', 0, '|', 'Z', 'X', 'C', 'V', 'B', 'N', 'M', '<', '>', '?', 0,
...
};至此,完成了从键盘扫描码到ASCII的转换。
我们设计的键盘驱动采用了事件注册与分发的机制,键盘事件的数据结构如下:
typedef struct kbd_event {
char key; // ASCII
int state; // 键盘是否按下?
int key_no; // 键号,用于判断特殊按键是否按下
} kbd_event;上层应用可以通过注册事件回调函数的方式来获取键盘按下的信息:
int register_kbd_cbk(void (*cbk_func)(kbd_event));
void unregister_kbd_cbk(int cbk_id);当键盘中断发生时,键盘驱动会完成键盘信息的解析,并向注册了键盘事件的应用程序逐一分发键盘事件(即依次调用其注册的键盘回调)。键盘驱动处理中断的核心函数实现如下:
void handle_kbd_irq(void)
{
while (kbd_has_data()) // while 用于稳定键盘中断,具体原理不详
{
kbd_event e;
unsigned char code = kbd_read_byte();
e.key_no = keymap[(unsigned int)code];
e.state = KEY_STATE_DOWN;
if (code == 0xF0 && kbd_has_data()) // 处理由于键盘抬起准备的二次数据
{
e.key_no = keymap[(unsigned int)kbd_read_byte()];
e.state = KEY_STATE_UP;
}
... // 一些特殊按键的判断
else
{
... // 根据特殊按键的状态进行进一步转换
invoke_kbd_cbk(e); // 完成键盘事件生成后,调用注册的回调函数
}
}
}键盘驱动的最直接应用是gets函数的实现(是的没错,相比于puts函数,gets函数的实现要绕更大的弯子)。
stdin的实现基于标准缓冲区库的实现,有关标准缓冲区库的讨论,请参见本章5.2小节。
在有了标准缓冲区的基础上,stdin会动态地向键盘驱动注册回调函数,相关代码如下:
void stdin_kbd_cbk(kbd_event e)
{
if (stdin_enabled && e.state == KEY_STATE_DOWN)
{
if (e.key == '\b')
{
if (std_buffer_empty(stdin_buffer))
return;
std_buffer_pop(stdin_buffer);
putc('\b');
putc(' ');
putc('\b');
}
else
{
std_buffer_put(stdin_buffer, e.key);
putc(e.key);
if (e.key == '\n')
putc('\r');
}
}
}此时,便可借助便准缓冲区的相关方法实现gets函数:
char getc()
{
stdin_enable();
byte c = 0;
c = std_buffer_wait_char(stdin_buffer);
stdin_disable();
return c;
}
int gets(char *str, int size)
{
stdin_enable();
int n = std_buffer_wait_line(stdin_buffer, str, size);
stdin_disable();
return n;
}由于时间原因,鼠标驱动并未完全实现,在此不便介绍。
为了方便内核部分功能的实现,我们首先实现了string.h:
#ifndef _SYSTEM_LIB_STRING_H_
#define _SYSTEM_LIB_STRING_H_
int strcmp(const char *str1, const char *str2);
int strcpy(char *dst, const char *src);
int strlen(const char *str);
int strncmp(const char *str1, const char *str2, int n);
int strncpy(char *dst, const char *src, int n);
void split(char *str, char *delim, char result[][100], int *result_len);
void memset(void *ptr, char c, unsigned long size);
int memcmp(void *ptr1, void *ptr2, unsigned long size);
void memcpy(void *ptr1, void *ptr2, unsigned long size);
#endif /* !_SYSTEM_LIB_STRING_H_ */以上这些函数的功能人尽皆知,在此便不赘述。
为了方便标准输入模块的开发,我们首先设计实现了标准字符输入缓冲区数据结构及其相关操作函数。缓冲区由顺序队列实现,并提供了自旋等待数据的API。
typedef struct std_buffer
{
byte *data; // 数据
int size; // 已装入数据大小(单位:字节)
int capacity; // 缓冲区容量(单位:字节)
int head; // 缓冲区头
int tail; // 缓冲区尾
int peek; // 访问指针
} std_buffer;
std_buffer *std_buffer_create(int capacity);
void std_buffer_destroy(std_buffer *buffer);
void std_buffer_clear(std_buffer *buffer);
void std_buffer_put(std_buffer *buffer, const byte data);
void std_buffer_puts(std_buffer *buffer, const char *data);
byte std_buffer_pop(std_buffer *buffer);
byte std_buffer_get(std_buffer *buffer);
int std_buffer_gets(std_buffer *buffer, char *data, int size);
byte std_buffer_peek(std_buffer *buffer);
void std_buffer_back(std_buffer *buffer);
char std_buffer_wait_char(std_buffer *buffer);
int std_buffer_wait_line(std_buffer *buffer, char *data, int size);
static inline int std_buffer_full(std_buffer *buffer)
{
return buffer->size == buffer->capacity;
}
static inline int std_buffer_full_p(std_buffer *buffer)
{
return buffer->peek == buffer->head;
}
static inline int std_buffer_empty(std_buffer *buffer)
{
return buffer->size == 0;
}
static inline int std_buffer_empty_p(std_buffer *buffer)
{
return buffer->peek == buffer->tail;
}为了支持建议文本编辑器vim的设计实现,我们利用二维双向链表设计了可编辑的文本数据结构,其核心数据结构定义与相关操作函数设计与实现如下。
核心数据结构:
typedef struct text_cursor // 光标位置
{
int x;
int y;
} text_cursor;
typedef struct text_char // 字符结点
{
char ch;
struct text_char *next;
struct text_char *prev;
} text_char;
typedef struct text_line // 行节点
{
int nr_chars;
text_char *fst_char;
text_char *lst_char;
struct text_line *next;
struct text_line *prev;
} text_line;
typedef struct text_buffer // 可编辑文本缓冲
{
int nr_lines;
text_line *fst_line;
text_line *lst_line;
text_line *cur_line;
text_char *cur_char;
text_cursor cursor;
} text_buffer;相关操作函数:
text_buffer *text_buffer_create();
int text_buffer_count_lines(text_buffer *buffer);
int text_buffer_count_chars(text_buffer *buffer);
void text_buffer_load_text(text_buffer *buffer, char *str);
void text_buffer_save_text(text_buffer *buffer, char *str, int size);
void text_buffer_save_line(text_line *line, char *str, int size);
void text_buffer_clear(text_buffer *buffer);
void text_buffer_destroy(text_buffer *buffer);
void text_buffer_free_line(text_line *line);
void text_buffer_write_char(text_buffer *buffer, char c);
void text_buffer_insert_line(text_buffer *buffer);
void text_buffer_insert_char(text_buffer *buffer, char c);
void text_buffer_insert_string(text_buffer *buffer, char *str);
void text_buffer_split_line(text_buffer *buffer);
void text_buffer_merge_line(text_buffer *buffer);
static inline void text_buffer_newline(text_buffer *buffer)
{
text_buffer_split_line(buffer);
}
void text_buffer_delete_char(text_buffer *buffer);
void text_buffer_delete_line(text_buffer *buffer);
void text_buffer_backspace(text_buffer *buffer);
void text_buffer_cursor_up(text_buffer *buffer);
void text_buffer_cursor_down(text_buffer *buffer);
void text_buffer_cursor_prev(text_buffer *buffer);
void text_buffer_cursor_next(text_buffer *buffer);
void text_buffer_cursor_move_to(text_buffer *buffer, int x, int y);
void text_buffer_cursor_to_line(text_buffer *buffer, int line);
void text_buffer_cursor_to_col(text_buffer *buffer, int col);
void text_buffer_cursor_home(text_buffer *buffer);
void text_buffer_cursor_end(text_buffer *buffer);
void text_buffer_cursor_line_home(text_buffer *buffer);
void text_buffer_cursor_line_end(text_buffer *buffer);
void text_buffer_print_info(text_buffer *buffer);
void text_buffer_print_line(text_line *line);
void text_buffer_print_text(text_buffer *buffer);
void text_buffer_relocate_cursor(text_buffer *buffer);函数详细实现过程不再赘述,感兴趣的同学可以参考源码。
核心常量及数据结构定义如下:(shell.h)
#define SHELL_BUFFER_SIZE 256 // shell命令输入缓冲区大小
#define SHELL_CMD_MAX 64 // 最大支持内置命令的数量
#define CMD_PARAM_MAX 8 // 每条命令最大支持的参数数量
#define NAME_LEN_MAX 16 // 命令或参数名最大长度
#define DESC_LEN_MAX 64 // 命令或参数描述信息最大长度
typedef struct {
char sign;
char name[NAME_LEN_MAX];
char desc[DESC_LEN_MAX];
} cmd_param; // 命令参数定义数据结构,sign代表该命令的缩写
typedef struct {
char sign;
char param[DESC_LEN_MAX];
} param_unit; // 从命令中解析得到的参数数据结构,由参数缩写和参数附加值组成
typedef struct {
char cmd[NAME_LEN_MAX]; // 命令名
char desc[DESC_LEN_MAX]; // 命令描述信息
cmd_param params[CMD_PARAM_MAX]; // 命令附带的参数定义
void (*func)(); // 命令的执行函数
} shell_cmd; //命令定义数据结构
extern char input_buff[SHELL_BUFFER_SIZE]; // 输入缓冲区
extern shell_cmd shell_cmds[SHELL_CMD_MAX]; // 内置命令
extern param_unit param_buff[CMD_PARAM_MAX];// 参数缓冲区
extern int shell_exit_flag; // shell退出标志在cmd.c中定义内置命令如下:(截取部分)
shell_cmd shell_cmds[SHELL_CMD_MAX] = {
...
{
.cmd = "info",
.desc = "show the information of SatoriOS",
.params = {
{
.sign = 'c',
.name = "cpu",
.desc = "show cpu information",
},
{
.sign = 'm',
.name = "memory",
.desc = "show memory information",
},
{
.sign = 'b',
.name = "boot",
.desc = "show boot information",
}
},
.func = show_satori_info
}
...
};该命令对应的实现在impl.c中,也可直接调用内核其他部分的函数。shell的主函数如下。
注意:由于我们并未进入保护模式,所以此处并不涉及内核态到用户态的切换。
void entry_shell()
{
puts("Entering Shell...");
shell_exit_flag = 0;
while (!shell_exit_flag)
{
printf("SatoriOS:%s $ ", shell_path);
int n = gets(input_buff, SHELL_BUFFER_SIZE);
if (n == SHELL_BUFFER_SIZE)
{
puts("\n\rInput overflowed!");
continue;
}
if (input_buff[0] == 0)
continue;
parse_command();
}
puts("Exiting Shell...");
}此处,为方便起见,shell直接使用的我们实现的gets方法获取键盘输入并进行解析。解析过程在parser.c中实现,其中重要函数的含义如下:
void parse_command(); // 解析输入缓冲区中的命令,并将格式化的参数存入参数缓冲区,而后调用命令执行函数
void parse_params(int cmd_id); // 由parse_command调用,负责解析命令参数
int has_param(int cmd_id); // 由命令执行函数调用,判断参数缓冲区中是否含有某个参数
char *get_param(char sign); // 由命令执行函数调用,获取某个参数的附加值对于每一个命令,可以参照如下格式进行实现,其余不多赘述。
void show_about_info(int cmd_id)
{
if (!has_param(cmd_id))
{
puts("Satori OS is a simple OS written by C.");
print_info();
}
else
{
if (get_param('v') != 0)
puts(VERSION);
if (get_param('a') != 0)
puts(AUTHOR);
if (get_param('c') != 0)
puts(COPYRIGHT);
if (get_param('l') != 0)
puts(LOGO);
if (get_param('o') != 0)
puts(ORIGIN);
}
}SatoriOS Shell实际运行截图如下:

在设计内存管理系统时,我们着重参考了Linux相关的设计理念和设计思路,但由于Linux的内存管理系统过于庞大复杂,我们并未完全遵循Linux的实现方式,而是混入了大量的自己的理解和思考。在实现上,我们以根据现有需求自行实现代码为主,以参考Linux相关概念命名为辅,设计了一个简易可用的内存管理系统。
由于时间原因,这个系统尚有诸多等待完善的部分。同时,由于资料和时间的双重匮乏,我们目前并未对龙芯的硬件架构有透彻的研究,因此并未针对龙芯的相关控制寄存器进行设置,也并未启用硬件的MMU,无法对地址进行翻译转换,从而无法真正意义上进入保护模式,对内存进行段页式的管理。对于这个问题,一方面我们只能使系统仍然在内核态运行,另一方面我们提出了vpu的概念,希望以模拟硬件逻辑的方式来虚拟地实现段页式的内存管理,该想法将在本章第10小节进行详细讨论和阐述。
下面先对内存分配系统整体的设计思路进行介绍。
研究Linux内核可以发现,Linux中重要的内存分配接口主要由kmalloc、vmalloc、malloc等组成。其中kmalloc用于内核空间动态内存分配,其本质是分配大小不定的连续物理内存,依靠slab系统实现。在Linux中,slab系统是以对象为单位的,在buddy system基础上分配较小连续物理内存的系统。Linux底层所使用的页分配器是buddy system。在Linux系统中,vmalloc负责分配虚拟连续,但物理上并不一定连续的内存空间,而malloc则是用于在用户空间进行连续内存分配的接口。

在我们设计的操作系统中,我们模仿Linux设计了最简单的Buddy System和Slab Allocator,并在此基础上实现了kmalloc函数。由于时间原因,我们并未实现vmalloc和malloc两个分配器。
在我们实践的过程中,我们发现内存管理实际上存在鸡生蛋蛋生鸡的问题,也就是说,内存管理系统的搭建是为了能够动态的申请和释放内存,而内存管理系统本身在一定程度上也依赖于动态的内存申请和释放。对此,Linux的解决方案是设计了一个boot_cache的过程,而我们则采用了更为简单的方式,即在内核空间划分出一段内存用于临时的内核数据结构的动态内存申请,而管理这片内存的分配器是基于位示图原理的Bit Allocator。
我们设计的连续物理内存分配器主要由底层的页分配器Buddy System、上层的对象分配器Slab Allocator以及初始化阶段的临时分配器Bit Allocator三个部分组成。
位分配器的实现非常简单,其针对位示图进行位的分配操作。其中负责分配的函数主要有alloc_bits和alloc_aligned_bits两个函数,前者负责忠实的分配内核需要的内存大小,保证内存的利用率,后者则在内核需求的基础上考虑了内存对齐以及分配性能等因素,可以相对快速地分配大块的内存。两个函数的实现如下:
int alloc_bits(byte *bitmap, int map_size, int size, int *last)
{
int last_i = *last / 8;
int i = last_i, j = *last % 8, k = 0;
while (k < size)
{
if (j == 8)
{
j = 0;
i = (i + 1) % map_size;
if (i == last_i)
return -1;
}
if ((bitmap[i] & (1 << j)) == 0)
k++;
else
k = 0;
j++;
}
*last = i * 8 + j;
for (int l = 0; l < size; l++)
set_bit(bitmap, *last - l - 1, 1);
return *last - size;
}int alloc_aligned_bits(byte *bitmap, int map_size, int size, int *last)
{
int last_i = (*last + 7) / 8 % map_size;
size = (size + 7) / 8;
int i = last_i, k = 0;
while (k < size)
{
if (bitmap[i] == 0)
k++;
else
k = 0;
i = (i + 1) % map_size;
if (i == last_i)
return -1;
}
*last = i * 8;
for (int l = 0; l < size; l++)
bitmap[i - l - 1] = 0xFF;
return *last - size * 8;
}此外,分别有两个函数负责内存的释放,并与上述两个函数一一匹配,一般不可混用。由于释放函数地实现较为简单,在此便不做展示。
系统启动之初的位分配器内存分配情况:

在我们实现的系统中,伙伴系统是建立在树结构地基础上实现的。使用树实现的优点是代码结构简单,可靠性强,但缺点是内存分配效率相对较低。后续我们会择机对其进行优化改进。我们目前实现的伙伴系统的数据结构及方法的定义如下:
#define ALLOCATED 1
#define FREE 0
typedef struct buddy_node
{
struct buddy_node *left;
struct buddy_node *right;
int order;
int state;
void* start;
} buddy_node;
void init_buddy();
int split_buddy(buddy_node *node);
void merge_buddy(buddy_node *node);
buddy_node *alloc_buddy(buddy_node *root, int order);
void free_buddy(void* start, int order);
void *buddy_alloc(int size);
void buddy_free(void *addr, int size);
void* buddy_realloc(void* addr, int old_size, int new_size);
void* buddy_calloc(int size);除去一些基本的树结构操作,我们的伙伴系统几个核心的方法实现如下:
buddy_node *alloc_buddy(buddy_node *root, int order)
{
if (order > root->order)
return NULL;
if (order == root->order)
{
root->state = ALLOCATED;
return root;
}
else
{
if (root->left == NULL)
{
if (split_buddy(root) == -1)
return NULL;
}
void *ret = alloc_buddy(root->left, order);
if (ret == NULL)
ret = alloc_buddy(root->right, order);
return ret;
}
return NULL;
}
void free_buddy(void *start, int order)
{
buddy_node *root = &buddy_root;
buddy_node *node = root;
while (node->order != order)
{
if (node->left == NULL)
{
mm_error("free_buddy: invalid operation. (start: %p, order: %d)", start, order);
return;
}
root = node;
if (start < node->right->start)
node = node->left;
else
node = node->right;
}
node->state = FREE;
if (root->left->state == FREE && root->right->state == FREE)
merge_buddy(root);
}
void *buddy_alloc(int size)
{
int order = 0;
while ((1 << order) < size)
order++;
buddy_node *node = alloc_buddy(&buddy_root, order);
if (node == NULL)
return NULL;
set_dead_beef(node->start + (1 << order) - 1);
return (void *)node->start;
}
void buddy_free(void *addr, int size)
{
int order = 0;
while ((1 << order) < size)
order++;
if (!check_dead_beef(addr + (1 << order) - 1))
{
mm_error("buddy_free: Dead beef check failure. (addr: %p, size: %d)", addr, size);
}
free_buddy(addr, order);
}由于时间原因,我们自己的Slab分配器尚未完全实现,下面附上Linux的具体实现示意图,感兴趣的同学可以深入了解。

由于时间原因,本功能还处于实验开发阶段,在此不便展示。
由于时间原因,本功能还处于实验开发阶段,在此不便展示。
进程控制块的设计比较常规,根据龙芯的架构做了相应的调整,这其中也借鉴了Linux的设计思路。
- 进程标识符:内/外部、父/子进程、用户标识符
- 处理器状态信息:通用、PC、PSW、用户栈指针寄存器、龙芯控制寄存器
- 进程调度信息:进程状态、进程优先级、事件及其它
- 进程控制信息:程序和数据地址、进程同步通信机制、资源清单、链接指针
struct loongarch_fpu {
unsigned int fcsr;
unsigned int vcsr;
unsigned long int fcc; /* 8x8 */
union fpureg fpr[NUM_FPU_REGS];
};
struct thread_struct {
/* 保存主要的处理器寄存器 */
unsigned long reg01, reg02, reg03, reg22; /* ra tp sp fp */
unsigned long reg04, reg05, reg06, reg07; /* a0-a3 */
unsigned long reg23, reg24, reg25, reg26; /* s0-s3 */
unsigned long reg27, reg28, reg29, reg30, reg31; /* s4-s8 */
/* 保存控制状态寄存器 */
unsigned long csr_prmd;
unsigned long csr_crmd;
unsigned long csr_euen;
unsigned long csr_ecfg;
unsigned long csr_badvaddr; //Last user fault
/* 保存特权级寄存器 */
unsigned long scr0;
unsigned long scr1;
unsigned long scr2;
unsigned long scr3;
/* 保存标志寄存器 */
unsigned long eflags;
/* 其他与进程相关的内容 */
unsigned long trap_nr;
unsigned long error_code;
struct loongarch_fpu fpu FPU_ALIGN;
};
struct task_struct
{
long state; /* -1 不可运行, 0 可运行, >0 终止 */
long counter;
long priority;
long signal; /* 挂起信号位图 */
struct sigaction sigaction[32]; /* 信号的相关信息 */
long blocked; /* 屏蔽信号位图 */
/* 进程信息 */
int exit_code;
unsigned long start_code, end_code, end_data, brk, start_stack;
long pid, father, pgrp, session, leader;
unsigned short uid, euid, suid;
unsigned short gid, egid, sgid;
long utime, stime, cutime, cstime, start_time;
struct thread_struct tss;
};进程调度算法采用时间片轮转,在上述进程控制块的基础上,每当触发时钟中断达到指定的倒计时次数后,会进入进程调度算法,调度算法首先会判断现有各个进程的信号量,判断是否存在未被阻塞且可中断的进程,需要将其置为运行状态。
而后正式进入进程调度的部分,通过判断哪一个进程的计数器值大,则将其确定为下一个占用CPU的程序,调用switch_to切换进程。
void schedule (void)
{
int i, next, c;
struct task_struct **p;
/*通过信号量激活进程,略*/
/*调度*/
while (1)
{
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i)
{
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c)
break;
for (p = &LAST_TASK; p > &FIRST_TASK; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
switch_to (current, task[next]);
}VPU的想法阐述请参见本章第十小节。在VPU的基础上,进程切换将变得非常简单。在虚拟进程进行切换时,不再需要进行额外的现场保护,只需将CPU的执行权交由不同的VPU执行即可。
由于时间原因,本功能还处于实验开发阶段,在此不便展示。
由于资料和时间的双重匮乏,我们对龙芯架构的了解还很浅薄,尚不能完成对龙芯CPU的完全控制。对我们来说,龙芯CPU就像是一个黑盒子,我们无法在短期内摸清其关键操纵方法,而这样的盲人摸象可能会在很大程度上阻碍我们研发的进度。进行操作系统实验,一方面是希望对龙芯架构有一定的研究和理解,另一方面,我们也希望在实践的过程中更深入地理解课堂中学习到的知识,去进一步对操作系统这一非具体的概念感兴趣。因此,我们决定走一个折中的路线——既然操纵龙芯CPU存在一定的难度,那我们就用软件的方式构建一个虚拟的处理单元(Virtual Processor Unit, VPU),并在此基础上完成虚拟的指令执行、地址转换、段页管理及用户-内核态的转换,等相关的算法成熟之后再移植到真正的CPU上。我们必须承认,这个想法的工作量很大,我们投入了大量的时间也未能将其完全实现,下面我们仅就已经完成的工作作以简要介绍和展示。
经过综合考虑,我们最终确定VPU设计如下:
typedef struct vpu
{
u32 gpr[GENERAL_REGISTERS]; // General purpose registers
u32 scr[SYSCALL_REGISTERS]; // System call registers
segment_registers_t sgr; // Segment registers
segment_register_t *csr; // Current segment register
int ip; // Instruction pointer
int sp; // Stack pointer
int bp; // Base pointer
sint cpl; // Current privilege level
sint asid; // Address space identifier
vpu_flags_t flags; // Flags
vdt_entry_t gdtr; // Global descriptor table register
selector_t ldtr; // Local descriptor table register
} vpu_t;下面进行逐一介绍。
u32 gpr[GENERAL_REGISTERS]; // General purpose registers通用寄存器。每个寄存器占用32位空间,共计16个。
u32 scr[SYSCALL_REGISTERS]; // System call registers系统调用专用寄存器。用于系统调用参数传递,共8个。这样的设计可能并不规范,仅仅是为了方便。
segment_registers_t sgr; // Segment registers段寄存器组。其详细定义如下,本VPU设计共将应用程序划分成了四段,即代码段、数据段、栈段、堆段。
typedef struct segment_registers
{
segment_register_t cs; // Code segment
segment_register_t ds; // Data segment
segment_register_t ss; // Stack segment
segment_register_t hs; // Heap segment
} segment_registers_t;其中,每一个段寄存器由一个段选择子和一个段描述符组成。这里是参照了8086的经典设计,在设置段选择子时,VPU会自动将该选择子对应的段描述符填入段寄存器中。
typedef struct segment_register
{
selector_t selector;
virtual_descriptor_t descriptor;
} segment_register_t;其余有关分段设计将在10.2.2进行阐述。
segment_register_t *csr; // Current segment register当前段寄存器。用于标记CPU当前正处于工作的段。该设计暂时没有参考依据,仅仅是为了方便而设置。
int ip; // Instruction pointer
int sp; // Stack pointer
int bp; // Base pointer程序计数器、栈顶指针和栈底指针。
sint cpl; // Current privilege level
sint asid; // Address space identifier当前工作特权级、进程地址空间ID。
vpu_flags_t flags; // Flags标志寄存器,详细定义如下:
typedef struct vpu_flags
{
u8 cf : 1; // carry flag
u8 zf : 1; // zero flag
u8 of : 1; // overflow flag
u8 sf : 1; // sign flag
u8 pf : 1; // parity flag
u8 tf : 1; // trace flag
u8 rf : 1; // interrupt flag
} vpu_flags_t;以上定义参考了经典的CPU设计,并结合实际需求制定。
vdt_entry_t gdtr; // Global descriptor table register
selector_t ldtr; // Local descriptor table register全局描述符表寄存器、局部描述符表寄存器。根据8086经典设计,gdtr中保存的是全局描述符表的入口信息,而ldtr中保存的是其对应的局部描述符表在全局描述符表中的位置,即段选择子。
在VPU中,我们模拟了微处理器处理解析并运行指令的完整过程,并将其封装成一个循环,规定每一个循环都是一个原子操作,在执行循环的过程中不可被打断执行。(注意,此处的不可被中断是指,不可被同样是运行在VPU上的其他虚拟进程中断,而并非屏蔽了硬件意义上的中断。事实上,硬件中断后会恢复现场,并不影响虚拟进程的正常执行。)
void vpu_cycle()
{
logi_addr_t ip = cur_vpu->ip;
phys_addr_t *phys_ip = get_phys_addr(ip);
vpu_instr_t *instr = (vpu_instr_t *)phys_ip;
cur_vpu->ip += sizeof(vpu_instr_t);
vpu_exec_instr(*instr);
}那在什么情况下CPU会进入VPU Cycle中执行呢?答案是当内核代码在执行空操作时。我们暂时约定,当内核代码在执行空操作时,便会跳转到VPU并执行一个Cycle,这样便可利用CPU的空闲实现来执行VPU的相关任务。事实上,空操作函数已经被替换为如下操作:
void go_to_vpu_cycle()
{
if(vpu_exit_flag || !cur_vpu)
{
return;
}
if (vpu_switch_flag)
{
vpu_switch_flag = false;
cur_vpu = next_vpu;
}
vpu_cycle();
}从上面的代码中也可以看到,虚拟进程的切换是通过不通过VPU之间交换CPU的执行权来实现的,而且这个过程发生在一个VPU Cycle之外。
在建立了初步的VPU概念之后,我们就可以开始大展拳脚,开始模拟实现真正的段页式内存管理系统了。由于由软件模拟实现的虚拟执行单元的所有细节都是由我们决定的,VPU相对于龙芯的CPU来说,对于我们已经不再是一个黑盒子,其所有细节都可以被跟踪确定的。基于以上设计,我们设计了虚拟的段页式内存管理架构如下。
我们首先对地址类型进行了如下定义:
#define VADDR_OFT_ODR 12
#define VADDR_PGN_ODR 6
#define VADDR_PDN_ODR 14
typedef struct logi_addr
{
u32 oft : VADDR_OFT_ODR; // offset: 4k
u32 pgn : VADDR_PGN_ODR; // page number: 64 pages
u32 pdn : VADDR_PDN_ODR; // page directory number: 16k page tables
} logi_addr_t;
typedef addr phys_addr_t;可以看到,我们采用了两级分页结构,内存页的大小为4k,逻辑地址一共占用32位内存空间。处于一些实际的考虑,我们并没有按照课本上讲述的在逻辑地址中加入段号。在我们的虚拟VPU中,分段管理是由操作系统自动完成的,这便意味着,虚拟用户程序的每个段都认为自己拥有32位总计4G的内存空间。
经过对各类资料的学习和分析,我们最终确定的页表项数据结构如下所示:
typedef struct page
{
u32 present : 1; // Page present in memory
u32 rw : 1; // Read-only if clear, readwrite if set
u32 user : 1; // Supervisor level only if clear
u32 accessed : 1; // Has the page been accessed since last refresh?
u32 dirty : 1; // Has the page been written to since last refresh?
u32 unused : 7; // Amalgamation of unused and reserved bits
u32 frame : 20; // Frame address (shifted right 12 bits)
} page_t;其中物理页框号占20位,结合12位的页内偏移,我们的分页结构可以访问32位的地址空间。
在此基础上的页表和页目录数据结构则呼之欲出:
typedef struct page_table
{
int nr_pages;
page_t *pages;
} page_table_t;
typedef struct page_directory
{
int nr_tables;
page_table_t *tables;
} page_directory_t;以上是分页的数据结构。下面是分段的数据结构:
根据惯例,我们确定了16位的段选择子结构:
typedef struct selector
{
u16 rpl : 2; // Requested Privilege Level
u16 tbl : 1; // Table Indicator (0 = GDT, 1 = LDT)
u16 idx : 13; // Index
} selector_t;段选择子用于在描述符表中查找定位某个段的段描述符,而段描述符的数据结构如下:
typedef struct descriptor
{
u16 limit_low; // 段界限的低16位
u16 base_low; // 段基地址的低16位
u8 base_mid; // 段基地址的中8位
descriptor_attrs_t attrs; // 段属性
descriptor_flags_t flags; // 段标志
u8 base_high; // 段基地址的高8位
} descriptor_t;这里段描述符数据结构的设计参考了8086的经典设计,但原设计由于历史兼容原因过于复杂,结合实际的使用需求,我们实际使用的是自定义的虚拟描述符结构:
typedef struct virtual_descriptor
{
addr entry;
u32 limit;
descriptor_attrs_t attrs;
} attr_packed virtual_descriptor_t;上述两种描述符结构共用段属性结构,其详细定义如下:
typedef struct descriptor_attrs
{
u8 accessed : 1; // 表明该段是否被访问过,将选择子装入寄存器时,该位被置1
u8 writeable : 1; // 代码段:0表示只执行,1表示可读;数据段:0表示只读,1表示可读写
u8 direction : 1; // 代码段:0表示非一致码段,1表示一致码段;数据段:0表示向高位扩展,1表示向低位扩展
u8 executable : 1; // 表明该段是否可执行,如果该位为1,则表示该段是代码段,否则是数据段
u8 descriptor_type : 1; // 表明该段描述符是系统段(0)描述符还是存储段(代码或数据)描述符
u8 privilege_level : 2; // 表明该段的特权级别,0表示最高级别,3表示最低级别
u8 present : 1; // 表明该段是否存在内存中,如果该位为0,则表示该段不存在内存中
} descriptor_attrs_t;真实的地址转换依赖于地址变换机构(一般为MMU)才得以实现,为了全面支持分段分页以及保护模式的管理,我们设计了虚拟的地址变换机构,即Virtual Memory Management Unit, VMMU。其提供一个核心功能:
phys_addr_t get_phys_addr(logi_addr_t logi_addr)
{
virtual_descriptor_t *vdesc = cur_vpu->csr->descriptor;
page_directory_t *pdir = (page_directory_t *)(vdesc->entry);
if ((u32)logi_addr >= vdesc->limit)
{
vmmu_error("%x - Unhandled segment fault: Exceed seg limit.", logi_addr);
return nullptr;
}
if (logi_addr.pdn >= pdir->nr_tables)
{
vmmu_error("%x - Unhandled page fault: Exceed page directory limit.", logi_addr);
return nullptr;
}
page_table_t *ptable = (page_table_t *)(pdir->tables[logi_addr.pdn]);
if (logi_addr.pgn >= ptable->nr_pages)
{
vmmu_error("%x - Unhandled page fault: Exceed page table limit.", logi_addr);
return nullptr;
}
page_t *page = (page_t *)(ptable->pages[logi_addr.pgn]);
if (!page->present)
{
vmmu_error("%x - Unhandled page fault: Page not present.", logi_addr);
return nullptr;
}
return (page->frame << 12) + logi_addr.oft;
}由于时间原因,部分功能暂未实现。计划实现的函数如下:
void handle_page_fault(u32 error_code);
void handle_tlb_miss(logi_addr_t logi_addr, phys_addr_t phys_addr);为了尽可能模仿真实计算机的运行过程,同时提高虚拟执行单元的工作效率,减轻多级地址变换带来的性能消耗,我们也在尝试设计虚拟快表查找机构。不过经老师提醒,该实现目前并不能很好的起到加速所用,下面仅作简要展示:
#define VTLB_SIZE 64 // 2^VADDR_PGN_ODR(6)=64
typedef struct vtlb_entry
{
byte valid : 1;
byte ng : 1; // non global
byte asid : 6;
u16 tag : VADDR_PDN_ODR;
addr frame;
} vtlb_entry_t;
void flush_tlb();
void vtlb_insert(logi_addr_t logi_addr, phys_addr_t frame);
phys_addr_t *vtlb_lookup(logi_addr_t logi_addr);以上tlb表项的设计参考了知乎上的一篇讲解文章,其示意图如下:
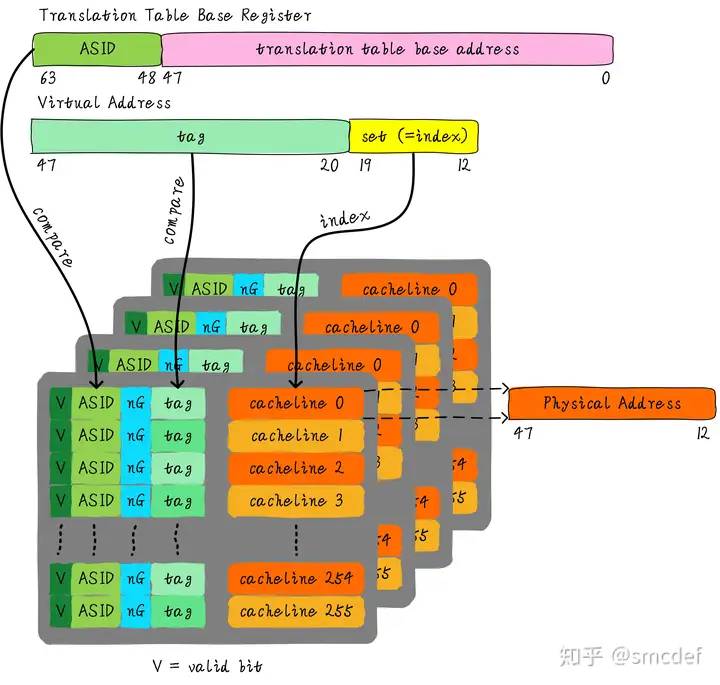
我们的虚拟tlb查找的过程如下。大致原理是,将虚拟地址中的页号作为表项索引以避免对整个快表的遍历,并将虚拟地址中的页目录号作为tag和表项进行对比以判断是否命中。表项中存储了实际的物理页框号,其结合虚拟地址中的业内偏移量即可计算出真实的物理地址。
#define get_vtlb_entry(logi_addr) (virtual_tlb + logi_addr.pgn)
#define get_vtlb_tag(logi_addr) logi_addr.pdn
phys_addr_t *vtlb_lookup(logi_addr_t logi_addr)
{
vtlb_entry_t *entry = get_vtlb_entry(logi_addr);
if (!entry->valid || (entry->ng && entry->asid != cur_vpu->asid))
{
return nullptr;
}
if (entry->tag == get_vtlb_tag(logi_addr))
{
return entry->frame << 12 + (logi_addr & 0xfff);
}
return nullptr;
}由于虚拟执行单元是由软件模拟的,所以其并不能执行机器指令。为了将以上虚拟硬件系统利用起来,我们设计了一套简易的模拟指令集,并在此基础上模拟实现了简单的系统调用。下面进行简要介绍。
经过研究商讨,我们最终确定的虚拟指令集如下。其中共包含算术指令7条,位操作指令6条,逻辑指令2条,分支控制指令10条,堆栈指令2条,内存指令2条,系统调用指令1条,其他指令2条总计32条虚拟机器指令。
typedef enum vpu_opcode
{
// Arithmetic
ADD,
SUB,
MUL,
DIV,
MOD,
INC,
DEC,
// Bitwise
AND,
OR,
XOR,
NOT,
SHL,
SHR,
// Logical
CMP,
TEST,
// Control
JMP,
JZ,
JNZ,
JG,
JGE,
JL,
JLE,
CALL,
RET,
LOOP,
// Stack
PUSH,
POP,
// Memory
MOV,
LEA,
// System
SYSCALL,
// Misc
NOP,
HALT
} vpu_opcode_t;虚拟指令数据结构如下(虚拟用,并未做压缩优化):
typedef enum vpu_operand_type
{
REGISTER,
SYSCALL_REG,
IMMEDIATE,
MEMORY,
} vpu_operand_type_t;
typedef struct vpu_operand
{
vpu_operand_type_t type;
union
{
u32 reg;
u32 imm;
u32 mem;
};
} vpu_operand_t;
typedef struct vpu_instr
{
vpu_opcode_t opcode;
vpu_operand_t operands[3];
} vpu_instr_t;由上可见,我们设计的指令采用了3操作数结构,其中第一个操作数默认为目标操作数。三个操作数均支持寄存器、立即数和内存单元三种类型。虚拟指令的执行实现如下。由于指令数较多,下面只列出几个典型代表。
#define _calc_op(op1, op2, op3, op) \
do \
{ \
vpu_switch_seg(SEG_DS); \
u32 op2_val = get_op_value(op2); \
u32 op3_val = get_op_value(op3); \
set_op_value(op1, op2_val op op3_val); \
} while (0)
void vpu_instr_add(vpu_operand_t *op1, vpu_operand_t *op2, vpu_operand_t *op3)
{
_calc_op(op1, op2, op3, +);
}
void vpu_instr_sub(vpu_operand_t *op1, vpu_operand_t *op2, vpu_operand_t *op3)
{
_calc_op(op1, op2, op3, -);
}
void vpu_instr_cmp(vpu_operand_t *op1, vpu_operand_t *op2)
{
vpu_switch_seg(SEG_DS);
u32 op1_val = get_op_value(op1);
u32 op2_val = get_op_value(op2);
if (op1_val == op2_val)
{
cur_vpu->flags.zf = 1;
}
else
{
cur_vpu->flags.zf = 0;
}
if (op1_val < op2_val)
{
cur_vpu->flags.cf = 1;
}
else
{
cur_vpu->flags.cf = 0;
}
}在我们设计的虚拟执行单元中,用户程序可通过syscall指令陷入内核态,调用系统提供的功能函数。该指令接受一个操作数作为系统调用号,用户可将需要的参数事先放置在系统调用寄存器中。
系统调用指令的实现如下:
void vpu_instr_syscall(vpu_operand_t *op1)
{
syscall_entry(get_op_value(op1), cur_vpu->scr);
}涉及到系统调用实现部分的数据和方法定义如下:
typedef void (*syscall_t)(void);
extern syscall_t syscall_table[SYSCALL_MAX];
void syscall_entry(int idx, u32* args);由于时间原因,系统调用的功能并未完全实现,因此系统调用表中仅仅存放了一些空白的占位符,大致如下:
syscall_t syscall_table[SYSCALL_NUM_MAX] = {
[SYSCALL_EXIT] = nullptr,
[SYSCALL_FORK] = nullptr,
[SYSCALL_READ] = nullptr,
[SYSCALL_WRITE] = nullptr,
[SYSCALL_OPEN] = nullptr,
[SYSCALL_CLOSE] = nullptr,
[SYSCALL_WAITPID] = nullptr,
[SYSCALL_CREAT] = nullptr,
[SYSCALL_LINK] = nullptr,
[SYSCALL_UNLINK] = nullptr,
[SYSCALL_EXECVE] = nullptr,
[SYSCALL_CHDIR] = nullptr,
[SYSCALL_TIME] = nullptr,
[SYSCALL_MKNOD] = nullptr,
[SYSCALL_CHMOD] = nullptr,
[SYSCALL_LSEEK] = nullptr,
[SYSCALL_GETPID] = nullptr,
}仅仅有虚拟指令并不足够,我们计划为该指令集实现一个配套的汇编器,不过该想法目前仅仅初具雏形,暂不便进行展示。
我们计划将汇编分为预处理、符号解析、指令翻译、可执行文件生成等数个阶段。
长期以来,我们试图为自己的操作系统构建一个图形化界面。但从零开始的像素级操作的难度可想而知,于是我们打算先从文本化的界面入手。经过前期规划思考,我们大致敲定了一个名为RTX(Rich Text Graphics)的可视化框架,并正在设计开发中。
在我们的设想中,该架构主要负责对虚拟显存的管理。用户应用程序可以向RTX申请一块特定大小的虚拟显存,并告诉RTX它想在这块虚拟显存上输出什么数据。RTX则在会判断该用户程序目前是否处于最顶层,若是,则在修改显存的同时将更改映射到真正的屏幕上,否则将只会修改显存。系统会向RTX申请一块保留显存用于展示系统的状态信息,以及完成不同应用间的切换等任务。RTX目前提供总计10种窗口尺寸,分别是上中下、左中右两两组合的9种尺寸以及全屏尺寸。
RTX相关的数据结构及方法暂时定义如下:
#define hit_align(cur_align, tgt_align) (cur_align & tgt_align)
extern char _rtx_buffer[RTX_BUFFER_LINES][RTX_MAX_WIDTH];
typedef enum rtx_align
{
rtx_align_lft = 1 << 0, // left
rtx_align_mid = 1 << 1, // middle (full width)
rtx_align_rgt = 1 << 2, // right
rtx_align_top = 1 << 3, // top
rtx_align_ctr = 1 << 4, // center (vertical)
rtx_align_btm = 1 << 5, // bottom
rtx_align_exp = 1 << 6, // expand (full width and height)
} rtx_align;
typedef struct rtx_char
{
char ch;
sint color;
sint style;
} rtx_char;
typedef struct rtx_line
{
rtx_char *line;
sint width;
bool blank;
struct rtx_line *next;
struct rtx_line *prev;
} rtx_line;
typedef struct rtx_buffer
{
sint prior;
sint width;
sint height;
bool active;
sint cursor_x;
sint cursor_y;
rtx_align align;
rtx_line *buf_line; // buffer line
rtx_line *pre_line; // previous line
rtx_line *cur_line; // current line
rtx_line *exs_line; // excessive line
} rtx_buffer;
void rtx_init();
rtx_buffer *rtx_create_buffer(rtx_align align);
void rtx_destroy_buffer(rtx_buffer *buffer);
void rtx_clear_buffer(rtx_buffer *buffer);
void rtx_clear_line(rtx_buffer *buffer, int line);
void rtx_clear_char(rtx_buffer *buffer, int x, int y);
void rtx_set_char(rtx_buffer *buffer, int x, int y, char c);
void rtx_set_string(rtx_buffer *buffer, int x, int y, char *str);
void rtx_append_char(rtx_buffer *buffer, char c);
void rtx_append_string(rtx_buffer *buffer, char *str);
void rtx_set_active(rtx_buffer *buffer);
void rtx_set_inactive(rtx_buffer *buffer);
void rtx_render_buffer(rtx_buffer *buffer);
void rtx_render_back(rtx_buffer *buffer);
void rtx_render_line(rtx_buffer *buffer, int line);
void rtx_set_cursor(rtx_buffer *buffer, int x, int y);
void rtx_move_cursor(rtx_buffer *buffer, int x, int y);
void rtx_hide_cursor(rtx_buffer *buffer);
void rtx_show_cursor(rtx_buffer *buffer);
void rtx_set_cursor_style(rtx_buffer *buffer, int style);
void rtx_save_cursor_style(rtx_buffer *buffer);
void rtx_restore_cursor_style(rtx_buffer *buffer);
void rtx_set_cursor_color(rtx_buffer *buffer, int color);
void rtx_save_cursor_color(rtx_buffer *buffer);
void rtx_restore_cursor_color(rtx_buffer *buffer);
void rtx_roll_up(rtx_buffer *buffer, int lines);
void rtx_roll_down(rtx_buffer *buffer, int lines);
void rtx_render_all();由于时间原因,相关函数仍在开发测试中,在此不便详细展示。
基于上述的可编辑文本数据结构、ANSI控制码,综合键盘驱动等已经实现的模块,我们设计了简易的vim应用,支持基础的文本编辑操作,其效果图如下:

以
SatoriOS为例。统计工具采用
VSCodeCounterDate : 2022-12-18
SatoriOSTotal : 140 files, 7279 codes, 456 comments, 1508 blanks, all 9243 linesEchoOSTotal : 82 files, 4263 codes, 960 comments, 827 blanks, all 6050 lines
SatoriOS
| language | files | code | comment | blank | total |
|---|---|---|---|---|---|
| C | 69 | 4,847 | 429 | 673 | 5,949 |
| Markdown | 15 | 1,219 | 0 | 466 | 1,685 |
| C++ | 36 | 726 | 14 | 247 | 987 |
| Makefile | 16 | 294 | 0 | 98 | 392 |
| Python | 1 | 112 | 0 | 16 | 128 |
| Shell Script | 2 | 65 | 13 | 7 | 85 |
| CSV | 1 | 16 | 0 | 1 | 17 |
EchoOS
| language | files | code | comment | blank | total |
|---|---|---|---|---|---|
| C | 46 | 3,183 | 844 | 538 | 4,565 |
| C++ | 19 | 703 | 103 | 144 | 950 |
| Makefile | 13 | 240 | 0 | 80 | 320 |
| Markdown | 2 | 70 | 0 | 57 | 127 |
| Shell Script | 2 | 67 | 13 | 8 | 88 |
SatoriOS
| path | files | code | comment | blank | total |
|---|---|---|---|---|---|
| . | 140 | 7,279 | 456 | 1,508 | 9,243 |
| include | 60 | 2,071 | 152 | 564 | 2,787 |
| include\app | 1 | 4 | 0 | 2 | 6 |
| include\arch | 3 | 211 | 17 | 49 | 277 |
| include\boot | 1 | 81 | 6 | 20 | 107 |
| include\config | 3 | 275 | 16 | 20 | 311 |
| include\drivers | 6 | 346 | 31 | 89 | 466 |
| include\fs | 6 | 56 | 1 | 22 | 79 |
| include\io | 5 | 118 | 0 | 38 | 156 |
| include\isp | 3 | 26 | 0 | 12 | 38 |
| include\lib | 4 | 132 | 0 | 45 | 177 |
| include\mm | 9 | 141 | 0 | 53 | 194 |
| include\sched | 2 | 19 | 0 | 6 | 25 |
| include\shell | 3 | 50 | 0 | 14 | 64 |
| include\sys | 1 | 36 | 0 | 13 | 49 |
| include\temp | 1 | 178 | 72 | 47 | 297 |
| include\vpu | 10 | 342 | 9 | 116 | 467 |
| kernel | 71 | 3,971 | 291 | 585 | 4,847 |
| kernel\app | 3 | 122 | 19 | 12 | 153 |
| kernel\boot | 2 | 161 | 16 | 36 | 213 |
| kernel\config | 4 | 189 | 6 | 24 | 219 |
| kernel\drivers | 5 | 239 | 5 | 36 | 280 |
| kernel\fs | 4 | 283 | 3 | 35 | 321 |
| kernel\io | 4 | 246 | 8 | 33 | 287 |
| kernel\isp | 4 | 19 | 0 | 8 | 27 |
| kernel\lib | 4 | 822 | 47 | 70 | 939 |
| kernel\mm | 13 | 504 | 127 | 126 | 757 |
| kernel\sched | 3 | 22 | 4 | 10 | 36 |
| kernel\shell | 6 | 514 | 12 | 31 | 557 |
| kernel\sys | 3 | 51 | 0 | 10 | 61 |
| kernel\trap | 8 | 295 | 40 | 80 | 415 |
| kernel\vpu | 5 | 438 | 0 | 56 | 494 |
| report | 1 | 1,009 | 0 | 325 | 1,334 |
| tools | 2 | 128 | 0 | 17 | 145 |
EchoOS
| path | files | code | comment | blank | total |
|---|---|---|---|---|---|
| . | 82 | 4,263 | 960 | 827 | 6,050 |
| include | 33 | 1,530 | 313 | 340 | 2,183 |
| include\app | 1 | 12 | 0 | 9 | 21 |
| include\arch | 2 | 170 | 16 | 46 | 232 |
| include\boot | 1 | 74 | 13 | 19 | 106 |
| include\config | 1 | 4 | 0 | 2 | 6 |
| include\drivers | 3 | 489 | 43 | 62 | 594 |
| include\fs | 1 | 27 | 1 | 7 | 35 |
| include\mm | 9 | 147 | 0 | 54 | 201 |
| include\sched | 3 | 204 | 132 | 45 | 381 |
| include\serial | 1 | 18 | 1 | 5 | 24 |
| include\shell | 1 | 11 | 0 | 5 | 16 |
| include\sysio | 2 | 49 | 0 | 8 | 57 |
| include\temp | 1 | 203 | 72 | 47 | 322 |
| include\utils | 3 | 27 | 0 | 7 | 34 |
| kernel | 45 | 2,653 | 634 | 474 | 3,761 |
| kernel\app | 4 | 303 | 62 | 27 | 392 |
| kernel\boot | 2 | 127 | 21 | 32 | 180 |
| kernel\config | 2 | 43 | 0 | 13 | 56 |
| kernel\drivers | 4 | 243 | 24 | 30 | 297 |
| kernel\fs | 2 | 221 | 3 | 24 | 248 |
| kernel\mm | 13 | 500 | 128 | 122 | 750 |
| kernel\sched | 4 | 361 | 274 | 80 | 715 |
| kernel\shell | 2 | 265 | 23 | 21 | 309 |
| kernel\sysio | 2 | 114 | 10 | 20 | 144 |
| kernel\trap | 5 | 247 | 40 | 63 | 350 |
| kernel\utils | 3 | 164 | 16 | 19 | 199 |
经历过了操作系统的磨练,我们无形之中收获了很多勇气和坚毅。我们经历了数次举步维艰思绪混乱和数次突破重围理清思路,并最终找到了一套架构设计方法:理清概念关系、设计数据结构、设计方法接口、实现完善方法、测试和联调。经此一役,我们历经从一头雾水到柳暗花明、从抵触硬件到得心应手、从一无所有到渐入佳境……相信这样的一段经历将会是我们大学生活中最为浓墨重彩的一笔!