The Captcha image consists of four characters that are either a string of letters or a combination of letters with numbers. In some of the combinations, the captcha characters contain all letters but they are not aligned cleanly. Some of the letters are joined together or diagonally aligned, therefore correctly separating them in order to make them easily recognised as letters is one of the tasks at hand. In the instances of Captcha characters that contain both numbers and letters, the position of the number is not guaranteed and the letters are slanted.
The expected outcome is to correctly identify each of the Captcha characters from the image. We are doing this inorder to measure the efficiency of the neural networks to correctly identify the Captcha characters. The label variable is the letter or number from the image of the separated Captcha characters.
def read_image(image_file_path):
"""Read in an image file."""
bgr_img = cv2.imread(image_file_path)
b,g,r = cv2.split(bgr_img) # get b,g,r
rgb_img = cv2.merge([r,g,b]) # switch it to rgb
return rgb_img
images = []
labels = []
for image_file_path in imutils.paths.list_images(image_file_Path):
image_file = read_image(image_file_path)
label = image_file_path.split('/')[7]
images.append(image_file)
labels.append(label)
for label in labels:
labelHere = label.split('.')[0]
newLabels.append(labelHere)
images = np.array(images)
#images4Plot = np.array(images, dtype="float") / 255.0
labels = np.array(newLabels)
A dataset of 9,955 of unique CAPTCHA images each with its label as the filename was used for this research. However, machine learning classification requires a one-to-many relationship between a label and in this context the CAPTCHA images. Therefore, uniqueness of the CAPTCHA images is problematic for a machine learning process.
some_digit = images[300]
#Some_digit_image = some_digit.reshape(24, 72, 3)
plt.imshow(some_digit, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
plt.show()

def pureBlackWhiteConversionThreshold(image):
# Add some extra padding around the image
imagePadded = cv2.copyMakeBorder(image, 8, 8, 8, 8, cv2.BORDER_REPLICATE)
gray = cv2.cvtColor(imagePadded, cv2.COLOR_RGB2GRAY)
# threshold the image (convert it to pure black and white)
imagethresholded = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
return imagethresholded
def pureBlackWhiteConversionOGImage(image):
# Add some extra padding around the image
imagePadded = cv2.copyMakeBorder(image, 8, 8, 8, 8, cv2.BORDER_REPLICATE)
gray = cv2.cvtColor(imagePadded, cv2.COLOR_RGB2GRAY)
padded_ThreshImage300 = pureBlackWhiteConversionThreshold(images[300])
some_digit = padded_ThreshImage300
plt.imshow(some_digit, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
plt.show()
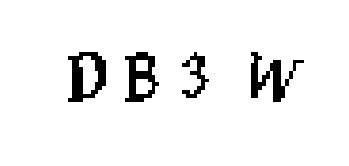
To deal with the uniqueness problem of the dataset, the solution was to separate the CAPTCHA images into the individual 4 characters that make up the CHAPTCHA image. This was to make each character into its own image. The resulting dataset has 39,754 images with one character per image. The new dataset satisfies the one-to-many relationship between the images and the following 32 characters labels {'2', '3', '4','5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q','R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'}
def regionsOfLetters(image):
# find the contours (continuous blobs of pixels) the image
contours = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Hack for compatibility with different OpenCV versions
contours = contours[0] if imutils.is_cv2() else contours[1]
letter_image_regions = []
# Now we can loop through each of the four contours and extract the letter
# inside of each one
for contour in contours:
# Get the rectangle that contains the contour
(x, y, w, h) = cv2.boundingRect(contour)
# Compare the width and height of the contour to detect letters that
# are conjoined into one chunk
if w / h > 1.25:
# This contour is too wide to be a single letter!
# Split it in half into two letter regions!
half_width = int(w / 2)
letter_image_regions.append((x, y, half_width, h))
letter_image_regions.append((x + half_width, y, half_width, h))
else:
# This is a normal letter by itself
letter_image_regions.append((x, y, w, h))
# If we found more or less than 4 letters in the captcha, our letter extraction
# didn't work correcly. Skip the image instead of saving bad training data!
#if len(letter_image_regions) != 4:
# continue
# Sort the detected letter images based on the x coordinate to make sure
# we are processing them from left-to-right so we match the right image
# with the right letter
letter_image_regions = sorted(letter_image_regions, key=lambda x: x[0])
return letter_image_regions
letter_image_regions = regionsOfLetters(padded_ThreshImage300)
letter_image_regions
def extractLetters(letter_image_regions, image):
# Save out each letter as a single image
letter_images =[]
for letter_bounding_box in letter_image_regions:
# Grab the coordinates of the letter in the image
x, y, w, h = letter_bounding_box
# Extract the letter from the original image with a 2-pixel margin around the edge
letter_image = image[y - 2:y + h + 2, x - 2:x + w + 2]
#image_file1 = read_image(letter_image)
letter_images.append(letter_image)
return letter_images
grayScaleImage = pureBlackWhiteConversionOGImage(images[300])
letter_image_List = extractLetters(letter_image_regions,grayScaleImage)
checkImage = letter_image_List[3]
some_digit = checkImage
#Some_digit_image = some_digit.reshape(24, 72, 3)
plt.imshow(some_digit, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
plt.show()
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = mpl.cm.binary, **options)
plt.axis("off")
index, = np.where(labels == 'F')
plt.figure(figsize=(15, 15))
example_images = np.r_[images[[14,39,51,39702,39752]],
images[[7,56,61,39703,39714]],
images[[45, 198, 352,39705, 39719]],
images[[2, 12, 52, 39698, 39712]],
images[[3, 26, 87, 39612, 39619]]]
example_images
plot_digits(example_images, images_per_row=5)
#save_fig("more_digits_plot")
#plt.show()

images3DTo2D = images.reshape(39754, 28 * 28)
X, y = images3DTo2D, labels
The image data was split into training and test set data, with the training set having 80% of the data and the remaining 20% was kept for the evaluation of model performance on the test set. The data was then fit to the random forest model.
from sklearn.model_selection import train_test_split
(X_train, X_test, y_train, y_test) = train_test_split(
X, y, test_size=0.2, random_state=11
)
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=10, random_state=42)
forest_clf.fit(X_train, y_train)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
y_train_pred = cross_val_predict(clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

# precision recall curve
precision = dict()
recall = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_trainBinarize[:, i],
y_score[:, i])
plt.plot(recall[i], precision[i], lw=2)
plt.xlabel("recall")
plt.ylabel("precision")
#plt.legend(loc="upper left")
plt.title("precision vs. recall curve")
plt.show()

# roc curve
fpr = dict()
tpr = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_trainBinarize[:, i],
(y_score[:, i]))
plt.plot(fpr[i], tpr[i], lw=2)
plt.xlabel("false positive rate")
plt.ylabel("true positive rate")
plt.title("ROC curve")
plt.show()

The random forest model did very well predicting the individual characters from the CAPTCHA images with an accuracy score, precision score, recall score and f1 score, all of 97.956%. The precision vs recall and ROC curves shows that the model is predicting most characters correctly.
X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
y_test_pred = cross_val_predict(clf, X_test_scaled, y_test, cv=3)
conf_mx = confusion_matrix(y_test, y_test_pred)
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

# precision recall curve
precision = dict()
recall = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_testBinarize[:, i],
y_scoretest[:, i])
plt.plot(recall[i], precision[i], lw=2)
plt.xlabel("recall")
plt.ylabel("precision")
#plt.legend(loc="upper left")
plt.title("precision vs. recall curve")
plt.show()

# roc curve
fpr = dict()
tpr = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_testBinarize[:, i],
(y_scoretest[:, i]))
plt.plot(fpr[i], tpr[i], lw=2)
plt.xlabel("false positive rate")
plt.ylabel("true positive rate")
plt.title("ROC curve")
plt.show()

The model's performance on the test is not that much different from the training set which shows that the model didn't overfit on the training set. All the performance metrics are above 97% and the precision vs recall and ROC curves confirm the performance of the model. The confusion matrix shows that the model is confusing some Ms for Ws and vice-versa.




