The core API application for Huey Books, written in Python. Responsible for the REST API (implemented as a Python FastAPI server using Pydantic models), implements most business logic, as well as the database models and an internal task server.
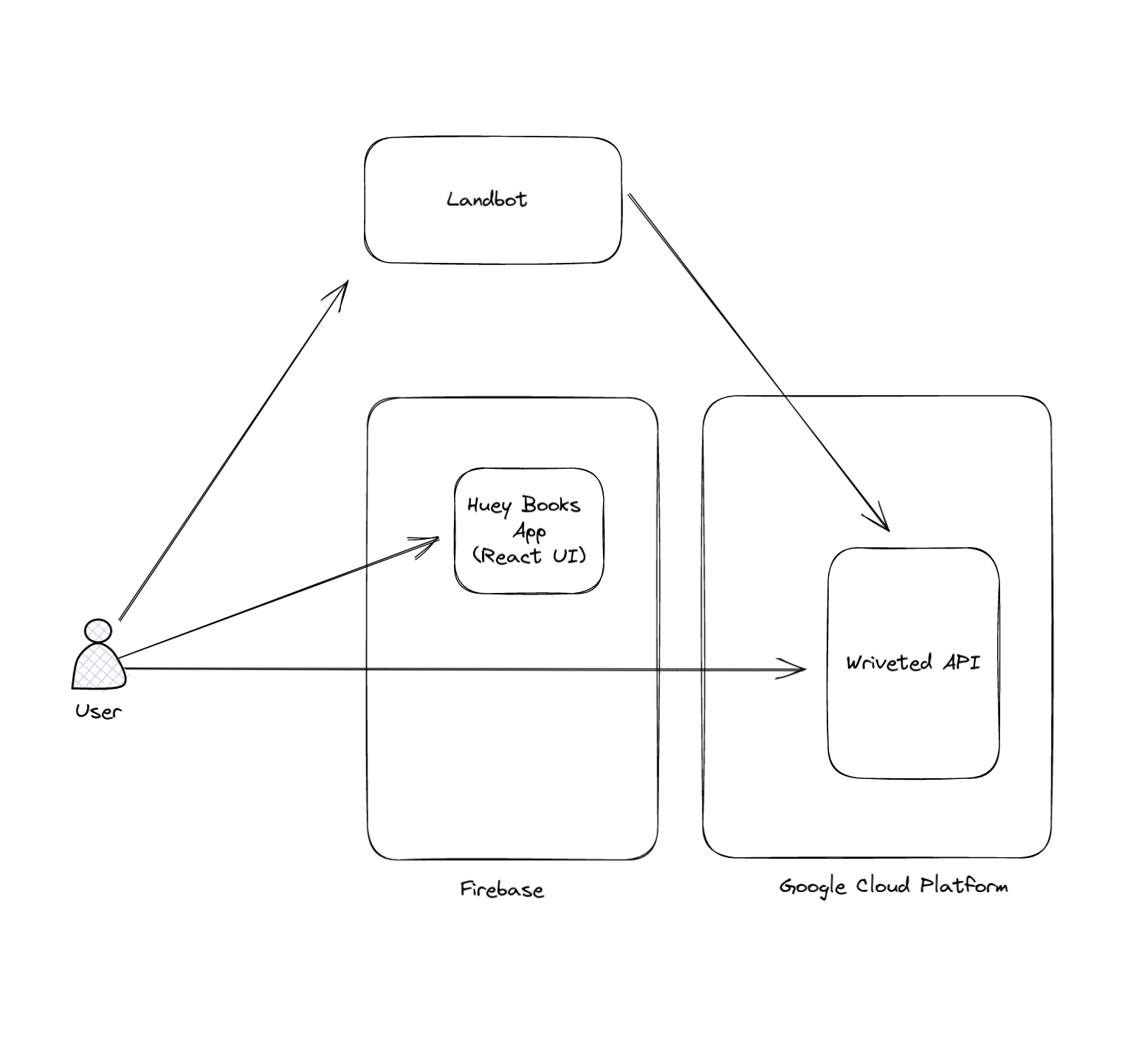
This repository implements a REST API to add, edit, and remove information about Users, Books, Schools and Library Collections for Wriveted.
The API is designed for use by multiple users:
- Library Management Systems. In particular see the section on updating and setting Schools collections.
- Wriveted Staff either directly via scripts or via an admin UI.
- End users via Huey the Bookbot, Huey Books, or other Wriveted applications.
A single docker image contains the implementation of two separate Python FastAPI server applications. The image is deployed as two services in GCP Cloud Run and is backed by a Postgresql database hosted in Cloud SQL. Background tasks such as log processing, emailing, and book labelling is carried out by the "internal" application, with Google Cloud Tasks providing task queuing and retries between these services.

The public facing API (with a few minor exceptions) is documented using OpenAPI at https://api.wriveted.com/v1/docs
Wriveted makes extensive use of a Postgresql database hosted in Cloud SQL. The database is the source of truth for all our book, collection and user data.
We use the Python library SqlAlchemy for defining the database schema (all tables, views, functions). Alembic is used for schema migrations.
The best starting point would be to read through the SqlAlchemy models at https://github.com/Wriveted/wriveted-api/tree/main/app/models. All modifications to the database structure requires a new alembic migration.
We deploy two instances of the database, one for development and one for production. A nightly job creates a snapshot of production and tests the backup/restore process by restoring the backup from production to development.
Our user models use joined-table inheritance which are worth reading up on before modifying the schema of any user tables.
A scrubbed dataset of labelled book data (that neatly fits on a free Supabase instance) is available from Google Cloud.
User Authentication is carried out with Google Identity Platform - via the Firebase API. Google SSO login as well as password-less email "magic link" login is used.
Users and login methods can be configured via Firebase Console, or GCP. Our user interface applications first require user’s to authenticate using Firebase, then the firebase token is exchanged for a Wriveted token (JWT) by calling /v1/auth/firebase (docs).
The API implements RBAC + row level access control on resources. Each user or service account
is linked to roles (e.g. "admin", "lms", or "student") and principals (e.g. user-xyz,
school-1). Endpoints have access control lists that specify what permissions are required for
different principals to access the resource at that endpoint. For example to access a school
the access control list could look like this:
from fastapi_permissions import Allow, Deny
class School:
id = ...
...
def __acl__(self):
return [
(Allow, "role:admin", "create"),
(Allow, "role:admin", "read"),
(Allow, "role:admin", "update"),
(Allow, "role:admin", "delete"),
(Allow, "role:admin", "batch"),
(Allow, "role:lms", "batch"),
(Allow, "role:lms", "update"),
(Deny, "role:student", "update"),
(Deny, "role:student", "delete"),
(Allow, f"school:{self.id}", "read"),
(Allow, f"school:{self.id}", "update"),
]Install poetry, then install dependencies with:
poetry installAdd a new dependency e.g. pydantic with:
poetry add pydanticUpdate the lock file and install the latest compatible versions of our dependencies every so often with:
poetry updateModify or add an SQLAlchemy ORM model in the app.models package.
Add an import for any new models to app.models.__init__.py.
Set the environment variable SQLALCHEMY_DATABASE_URI with the appropriate database path:
For example to connect to the docker-compose database:
// Terminal
export SQLALCHEMY_DATABASE_URI=postgresql://postgres:password@localhost/postgres
// Powershell
$Env:SQLALCHEMY_DATABASE_URI = "postgresql://postgres:password@localhost/postgres"Apply all migrations:
poetry run alembic upgrade headTo create a new migration:
poetry run alembic revision --autogenerate -m "Create first tables"Open the generated file in alembic/versions and review it — is it empty?
You may have to manually tweak the migration.
You can use docker-compose to bring up an API and postgresql database locally.
You can also run your own database, or proxy to a Cloud SQL instance.
Note, you will have to manually apply the migrations.
Running the app using uvicorn directly (without docker) is particularly handy for
debugging.
In scripts there are Python scripts that will connect directly to the
database outside of the FastAPI application. For example get_auth_token.py
can be run to generate an auth token for any user.
The following GCP services are used: Cloud Build + Cloud SQL + Cloud Run
Build the Docker image using Cloud Build:
gcloud builds submit --tag gcr.io/wriveted-api/wriveted-apiThen to deploy (or alternatively use the Google Console):
gcloud run deploy wriveted-api \
--image gcr.io/wriveted-api/wriveted-api \
--add-cloudsql-instances=wriveted \
--platform managed \
--set-env-vars="POSTGRESQL_DATABASE_SOCKET_PATH=/cloudsql" \
--set-secrets=POSTGRESQL_PASSWORD=wriveted-api-cloud-sql-password:latest,SECRET_KEY=wriveted-api-secret-key:latest
This will probably fail the first few times for a new GCP project - you'll have
to follow the permission errors to add appropriate permissions.
At a minimum you'll have to add the secrets to Secret Manager, then attach
the roles/secretmanager.secretAccessor role to the service account used by
Cloud Run for those secrets.
You will be prompted to allow unauthenticated invocations: respond y. We
implement our own authentication in the FastAPI app.
Note you will have to configure the Cloud SQL database manually (orchestrating with Terraform is left as an exercise for the reader 👋).
Use a public IP address for the Cloud SQL instance (don't worry about the private VPC method it is way more expensive). Smallest instance with shared CPU is fine.
Create a cloudrun user, then once you have a connection
reduce the rights with:
ALTER ROLE cloudrun with NOCREATEDB NOCREATEROLE;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO cloudrun;
GRANT USAGE, SELECT ON ALL SEQUENCES IN SCHEMA public to cloudrun;
alter default privileges in schema public grant SELECT, INSERT, UPDATE, DELETE on tables to cloudrun;
alter default privileges in schema public grant USAGE, SELECT on sequences to cloudrun;
Manually apply database migrations.
Login to GCP:
gcloud --project wriveted-api auth application-default loginStart the Cloud SQL proxy.
cloud_sql_proxy -instances=wriveted-api:australia-southeast1:wriveted=tcp:5432Set the environment variable SQLALCHEMY_DATABASE_URI with the proxied database path (otherwise it will create a local sqlite database):
Export the DevOps credentials for the production database. Note the actual password can be found in Secret Manager:
export SQLALCHEMY_DATABASE_URI=postgresql://postgres:password@localhost/postgresThen apply all migrations with:
poetry run alembic upgrade headProduction logs are available in Cloud Run:
Install pre-commit hooks with:
poetry run pre-commit installOr run manually with:
poetry run pre-commit run --all-files