I trained the model with this dataset of about 80,000 images depicting the american alphabet in sign language.
The computer trained the model for about 24h and I got pretty accurate results.
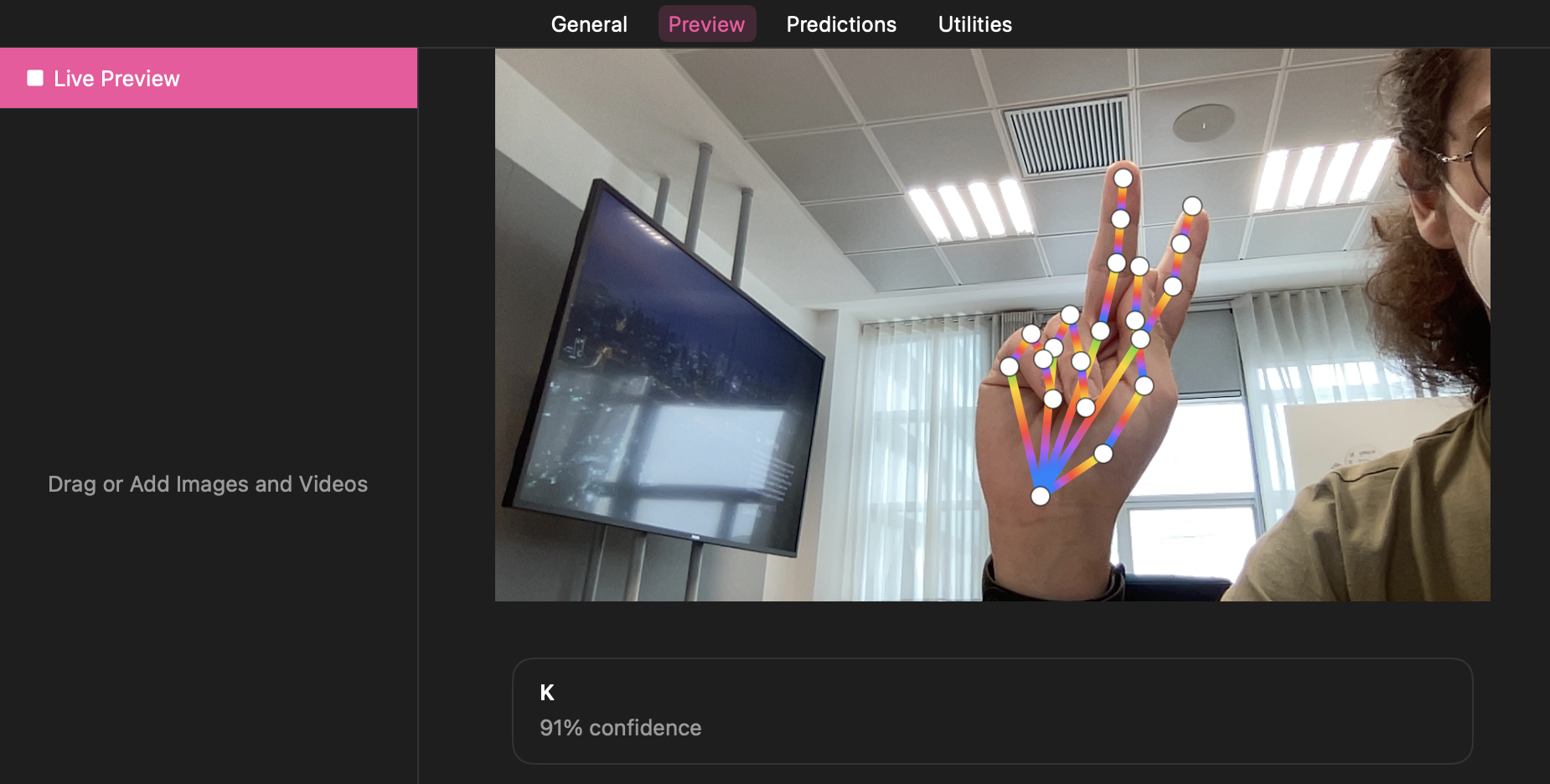

Once the model had finished training I implemented it in Swift, creating a project that received in UIImage processes it with the model and shows the result on screen. available on GitHub.
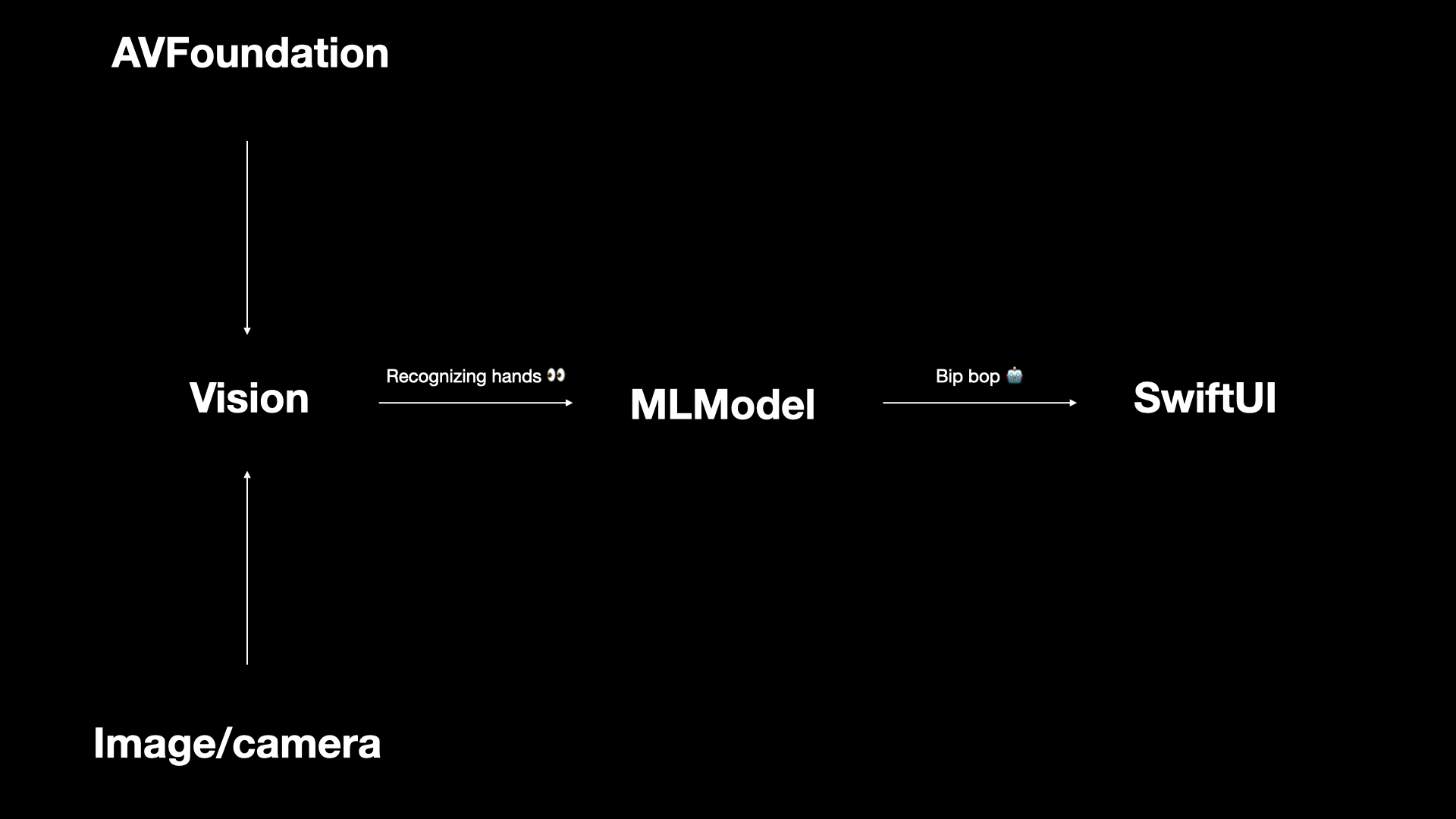
I used AVFoundation as the first framework to start recording in real time and receive frames from the camera. After that, the frames I was receiving from the camera were processed using the model created with machine learning and using the vision framework. Then the whole UI is built using SwiftUI.