A hash function takes an arbitrary-length message input to produce a fixed-length output. This project aims at implementing an hardware accelerator peripheral for SHA256 hashing algorithm with AXI4 interfacing with PicoRV32 CPU. The project focuses on multiple implementations of the accelerator with gradual improvements through spatial pre-computation techniques and pipelining. The SHA256 accelerators are implemented using Verilog and synthesized using Yosys Open Synthesis Suite. The optimized designs are then compared with a base-line C implementation in software. Hash functions are used to securely store passwords, to quickly store and retrive data, and also to check if a file/message is corrupted.
The SHA family of hash function algorithms are used during data transmission to produce an indecipherable message digest. A hash function is a one-way deterministic function which is practically infeasible to invert a hash value to its message input. Therefore, it becomes an essential tool for embedded security in e-mail, internet banking, and other applications. The strong motivation behind this project is that these applications especially on the server-side require high-throughput low-latent encryption devices.
- The hashing is deterministic (i.e the data is scrambled deterministically)
- Irrespective of the size of input, the output of the hashing process is always 256-bits long.
- The original data cannot be retrived from the scrambled data as it is a one-way function.
The general architecture of the SHA256 hashing algorithm consists of following modules:
-
Padding and Parsing: that ensures that the input message has length of multiples of 512 bits.
-
Message Expansion: that decomposes the input message into 16 blocks of 32 bits each and further expands it into 64 blocks
{W} -
Block Compression: that iterates 64 times on 8 - 32 bit variables
{a,b,c,d,e,f,g,h}using {W} values obtained from previous stage and constants{K} -
Hash Value Computation: that utilizes the 8 variables to generate a concatenated 256 bit output
RotR(A, n)denotes the circular right shift of n bits of the binary word A.ShR(A, n)denotes the right shift of n bits of the binary word A.A||Bdenotes the concatenation of the binary words A and B.
We use the following functions in our algorithm:
- Ch(X, Y, Z) = (X ∧ Y ) ⊕ (X ∧ Z),
- Maj(X, Y, Z) = (X ∧ Y ) ⊕ (X ∧ Z) ⊕ (Y ∧ Z)
- Σ_0(X) = RotR(X, 2) ⊕ RotR(X, 13) ⊕ RotR(X, 22),
- Σ_1(X) = RotR(X, 6) ⊕ RotR(X, 11) ⊕ RotR(X, 25),
- σ_0(X) = RotR(X, 7) ⊕ RotR(X, 18) ⊕ ShR(X, 3),
- σ_1(X) = RotR(X, 17) ⊕ RotR(X, 19) ⊕ ShR(X, 10),
64 binary words of K[i] are given by the first 4 bytes of the fractional parts of the cube roots of the first 64 prime numbers:
0x428a2f98 0x71374491 0xb5c0fbcf 0xe9b5dba5 0x3956c25b 0x59f111f1 0x923f82a4 0xab1c5ed5
0xd807aa98 0x12835b01 0x243185be 0x550c7dc3 0x72be5d74 0x80deb1fe 0x9bdc06a7 0xc19bf174
0xe49b69c1 0xefbe4786 0x0fc19dc6 0x240ca1cc 0x2de92c6f 0x4a7484aa 0x5cb0a9dc 0x76f988da
0x983e5152 0xa831c66d 0xb00327c8 0xbf597fc7 0xc6e00bf3 0xd5a79147 0x06ca6351 0x14292967
0x27b70a85 0x2e1b2138 0x4d2c6dfc 0x53380d13 0x650a7354 0x766a0abb 0x81c2c92e 0x92722c85
0xa2bfe8a1 0xa81a664b 0xc24b8b70 0xc76c51a3 0xd192e819 0xd6990624 0xf40e3585 0x106aa070
0x19a4c116 0x1e376c08 0x2748774c 0x34b0bcb5 0x391c0cb3 0x4ed8aa4a 0x5b9cca4f 0x682e6ff3
0x748f82ee 0x78a5636f 0x84c87814 0x8cc70208 0x90befffa 0xa4506ceb 0xbef9a3f7 0xc67178f2
This step is to make the the padded message become 512 bits. This step can be done in software becuase as per our analysis the bottleneck is not in this step. Therefore this step needs to be implemented in software.
- The input message is converted to bits
1is appended to this message- Now,
0's are appended till 448^th bit (= 512-64) - Then the length of the input message is calculated and is appended to the end of this 448 bit long value in 64 bits format to make the entire input into 512 bits.
This new 512 bit padded input is used for further processing from here on. However for our use case we assume that we have the padded message ready, as we faced some problem while implementing the code for pre-processing.
For each block M ∈ {0, 1} 512 , 64 words of 32 bits each are constructed as follows:
-
The first 16 are obtained by splitting M in 32-bit blocks Message = W1||W2|| · · · ||W15||W16
-
The remaining 48 are obtained with the formula: Wi = σ_1(Wi−2) + Wi−7 + σ_0(Wi−15) + Wi−16, where 17 ≤ i ≤ 64.
First, eight variables are set to their initial values, given by the first 32 bits of the fractional part of the square roots of the first 8 prime numbers:
H1(0) = 0x6a09e667
H2(0) = 0xbb67ae85
H3(0)= 0x3c6ef372
H4(0) = 0xa54ff53a
H5(0) = 0x510e527f
H6(0) = 0x9b05688c
H7(0) = 0x1f83d9ab
H8(0) = 0x5be0cd19
Next, the blocks M(1) , M(2), . . . , M(N) are processed one at a time:
For t = 1 to N construct the 64 blocks Wi from M(t) , as explained above
Now set:
(a, b, c, d, e, f, g, h) = (H 1 (t−1) , H 2 (t−1) , H 3 (t−1) , H 4 (t−1) , H 5 (t−1) , H 6 (t−1) , H 7 (t−1) , H 8 (t−1) )
Do 64 rounds consisting of:
T1 = h + Σ_1(e) + Ch(e, f, g) + Ki + Wi
T2 = Σ_0(a) + M aj(a, b, c)
h = g
g = f
f = e
e = d + T1
d = c
c = b
b = a
a = T1 + T2
Now computing the new value of Hj(t) as follows:
H1(t) = H1(t-1) + a
H2(t) = H2(t-1) + b
H3(t) = H3(t-1) + c
H4(t) = H4(t-1) + d
H5(t) = H5(t-1) + e
H6(t) = H6(t-1) + f
H7(t) = H7(t-1) + g
H8(t) = H8(t-1) + h
The hash of the message is the concatenation of the variables Hi after the last block has been processed as follows:
H = H1(N) || H2(N) || H3(N) || H4(N) || H5(N) || H6(N) || H7(N) || H8(N) .
There are three main directories. Namely:
- SHACORE
- SHACORE_UNROLLED
- SHACORE_UNROLLED_PIPELINED
As their names suggest each of these folders contain a different implementation of the SHA256 Peripheral.
To move into this folder use $ cd SHACORE
This folder contains the implementation of the original un-optimsed (without any spatial optimisation or pipelining) verilog code. The sha256_core.vfile contains the verilog implementation of the accelerator.
To execute and see the peripheral inaction use the $ make command.
To run the Yosys synthesis and also to execute the generated file simultaneously, use the '$ ./run.sh' command. If the $ ./run.sh didn't work, use chmod +x run.sh followed by $ ./run.sh. Once this is done, you will be able to see the synthesis results in the command prompt. To view the complete file, use $ ./run.sh > output.log. This will store the entire output in the output.log file.
To move into this folder use $ cd SHACORE_UNROLLED
This folder contains the implementation of the original spatially optimised verilog code. The sha256_unrolled.vfile contains the verilog implementation of the accelerator. Further details about unrolling (which is a form of spacial optimisation) is given in the following section.
To execute and see the peripheral inaction use the $ make command.
To run the Yosys synthesis and also to execute the generated file simultaneously, use the '$ ./run.sh' command. If the $ ./run.sh didn't work, use chmod +x run.sh followed by $ ./run.sh. Once this is done, you will be able to see the synthesis results in the command prompt. To view the complete file, use $ ./run.sh > output.log. This will store the entire output in the output.log file.
To move into this folder use $ cd SHACORE_UNROLLED_PIPELINED
This folder contains the implementation of the optimised verilog code, which contains both unrolling and pipelining. The sha256_unrolled_pipelined.vfile contains the verilog implementation of the accelerator. Further details about this unrolled and pipelined accelerator architecture is given in the following section.
To execute and see the peripheral inaction use the $ make command.
To run the Yosys synthesis and also to execute the generated file simultaneously, use the '$ ./run.sh' command. If the $ ./run.sh didn't work, use chmod +x run.sh followed by $ ./run.sh. Once this is done, you will be able to see the synthesis results in the command prompt. To view the complete file, use $ ./run.sh > output.log. This will store the entire output in the output.log file.
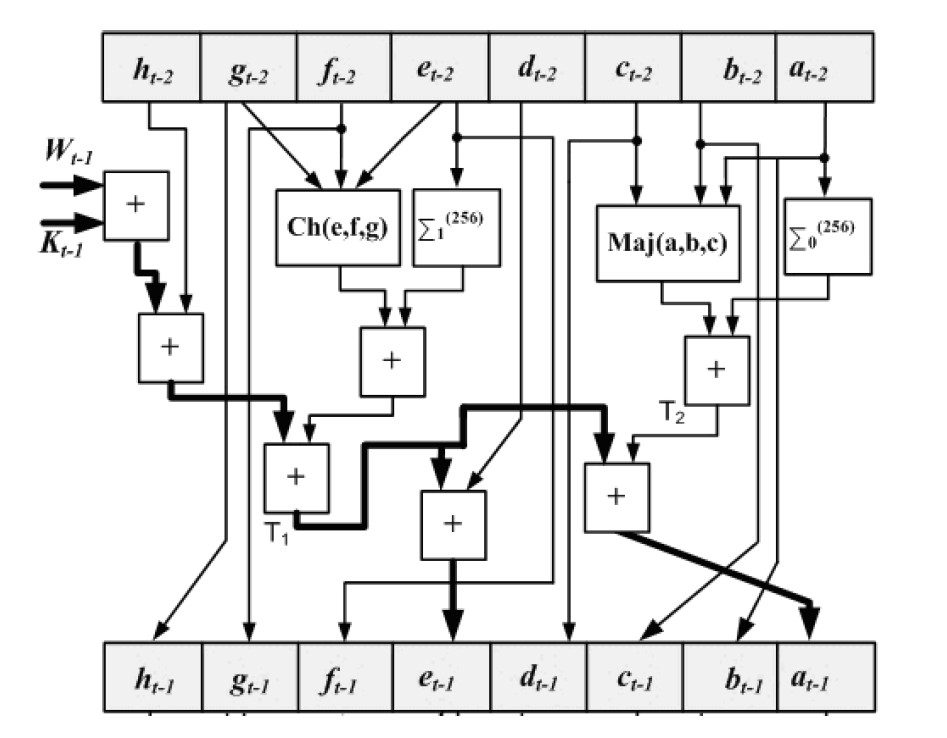
The diagram above shows the implementation of the most primitive implementation of the SHA256 accelerator peripheral.

The diagram above shows the implementation of the SHA256 accelerator peripheral with Unrolling & Pipelining.
=== design hierarchy ===
overall 1
hash_output 1
compression_algorithm_stage1 1
S0 1
S1 1
compression_algorithm_stage2 1
S0 1
S1 1
w_new_calc 2
s0 1
s1 1
Number of wires: 15910
Number of wire bits: 26608
Number of public wires: 297
Number of public wire bits: 9791
Number of memories: 0
Number of memory bits: 0
Number of processes: 0
Number of cells: 20460
FDRE 2799
LUT1 22
LUT2 1157
LUT3 1433
LUT4 307
LUT5 1758
LUT6 9609
MUXCY 720
MUXF7 1755
MUXF8 154
XORCY 746
Estimated number of LCs: 13107
Hashed Value in hex: E2547202 08FF3334 31F723CB E00B9C1D 45FC65B7 AC165015 1A3D8EB0 CBD885A3
Software Calculation completed in 26657 cycles.
Instruction counter ..5275
CPI: 5.05
Hardware Calculation Completed in 531 cycles.
Instruction counter ..127
CPI: 4.18
Total Cycle counter (Including Hardware & Software) .......... 57027
Total Instruction counter (Including Hardware & Software) .... 10413
CPI: 5.47
DONE
=== design hierarchy ===
overall 1
hash_output 1
compression_algorithm_stage1 1
S0 1
S1 1
compression_algorithm_stage2 1
S0 1
S1 1
w_new_calc 2
s0 1
s1 1
Number of wires: 15564
Number of wire bits: 25983
Number of public wires: 286
Number of public wire bits: 9501
Number of memories: 0
Number of memory bits: 0
Number of processes: 0
Number of cells: 19835
FDRE 2509
LUT1 22
LUT2 1618
LUT3 945
LUT4 387
LUT5 1524
LUT6 9607
MUXCY 720
MUXF7 1601
MUXF8 156
XORCY 746
Estimated number of LCs: 12606
Hashed Value in hex: E2547202 08FF3334 31F723CB E00B9C1D 45FC65B7 AC165015 1A3D8EB0 CBD885A3
Software Calculation completed in 26657 cycles.
Instruction counter ..5275
CPI: 5.05
Hardware Calculation Completed in 531 cycles.
Instruction counter ..127
CPI: 4.18
Total Cycle counter (Including Hardware & Software) .......... 57027
Total Instruction counter (Including Hardware & Software) .... 10413
CPI: 5.47
DONE
=== design hierarchy ===
overall 1
hash_output 1
compression_algorithm 1
S0 1
S1 1
w_new_calc 1
s0 1
s1 1
Number of wires: 8759
Number of wire bits: 17086
Number of public wires: 227
Number of public wire bits: 7763
Number of memories: 0
Number of memory bits: 0
Number of processes: 0
Number of cells: 12187
FDRE 2409
LUT1 16
LUT2 911
LUT3 2178
LUT4 225
LUT5 596
LUT6 4256
MUXCY 411
MUXF7 682
MUXF8 81
XORCY 422
Estimated number of LCs: 7255
Hashed Value in hex: E2547202 08FF3334 31F723CB E00B9C1D 45FC65B7 AC165015 1A3D8EB0 CBD885A3
Software Calculation completed in 26657 cycles.
Instruction counter ..5275
CPI: 5.05
Hardware Calculation Completed in 561 cycles.
Instruction counter ..134
CPI: 4.18
Total Cycle counter (Including Hardware & Software) .......... 57057
Total Instruction counter (Including Hardware & Software) .... 10420
CPI: 5.47
DONE
- Tried interfacing with MicroBlaze in Vivado, but failed.
- Implementation of Padder Parser block was not done.
https://drive.google.com/drive/u/0/folders/1jZgz0kw_Lrw6K0A1S5sV644tq6n1V_5n