We are building a dataset of software mentions in research publications. We have annotated thousands of mentions of software, mostly informal, in thousands of published academic papers. The effort has led to an annotated corpus suitable for training entity recognition algorithms. We expect this effort can fuel more development in text mining utilities leveraging machine learning techniques, either for enabling further analysis of software use and development in science, or for improving the visibility of software entities in existing scientific literature.
Visibility is important to the underacknowledged software work in science, which is critical for unleashing scientific progress. We hope our effort can help software work achieve its due credit on the honor wall of science, and thus facilitate more investment in quality software work for better science.
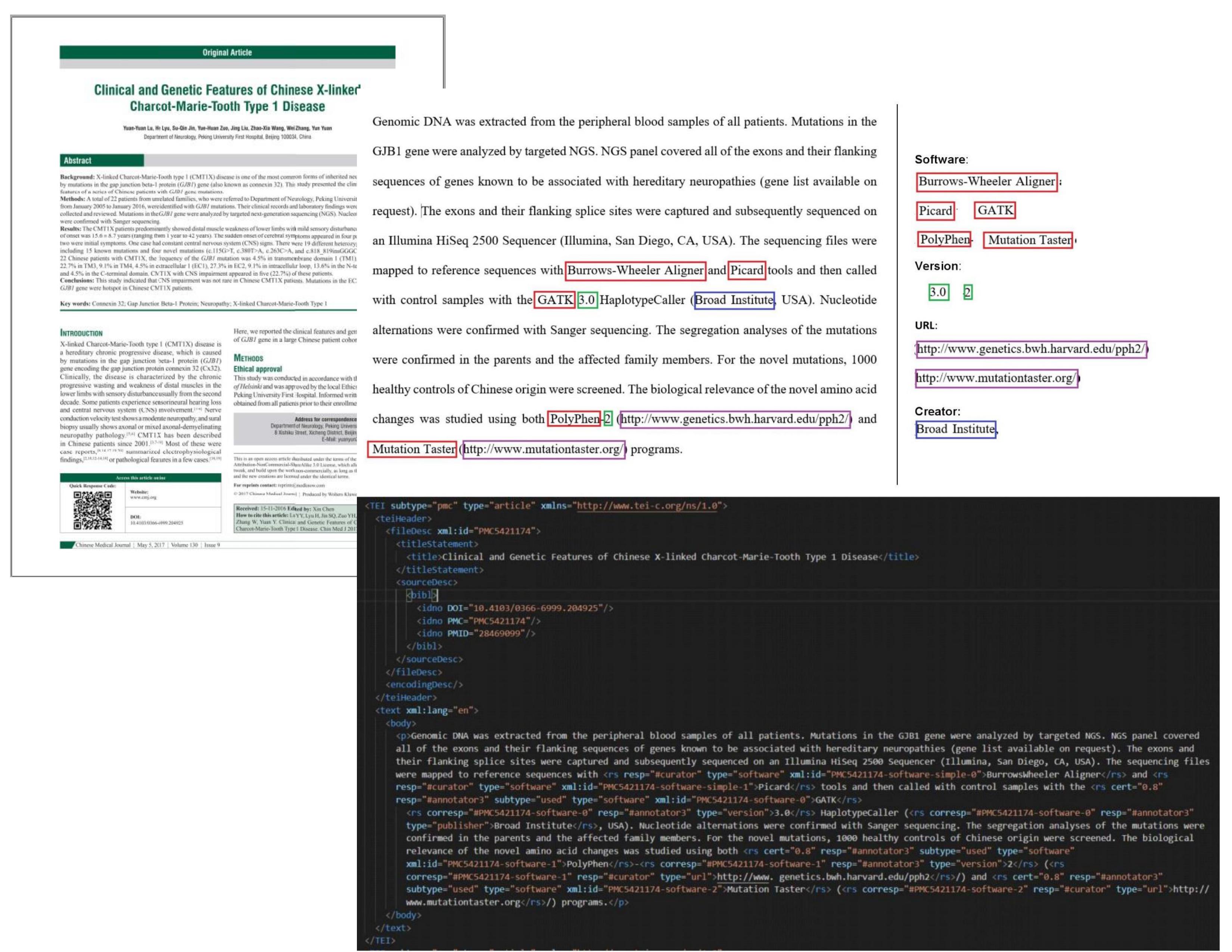
softcite-dataset: from manual annotation of PDF documents to a corpus for machine learning use
CiteAs.org helps find the requested citation for software (and will eventually use data from the knowledge base).
Thanks to the Sloan Foundation for funding.