SQLoogleBot.exe has a new command line argument; -s for schedule.
It accepts a cron expression (e.g. -s "0/20 * 4-23 ? * MON-SAT *").
Use nssm to make it a service and just let it run.
Note: What follows is an article I posted to CodeProject back in May of 2013.
One day, it dawned on me, that I should be able to perform sub-second searches on my company's entire SQL catalog in one place. I needed Google for SQL. Something like this:
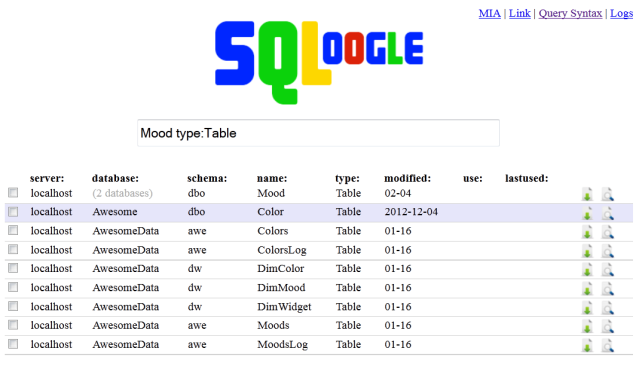
SQLoogle crawls, indexes, and searches your T-SQL based objects. Here are some of it's features:
- Crawls nearly all SQL based database objects at lightning-fast speeds (e.g tables, indexes, stored procedures, etc.)
- Crawls SQL Agent Job Steps
- Crawls Reporting Services Commands
- Crawls Ad Hoc Queries (filtered and condensed)
- Crawls Prepared Statements
- Captures usage statistics (execution, seek, scan counts, and last used date)
- Performs multi-field searches with Lucene.NET.
- Provides a web-based, single-page AJAX search interface.
- Provides downloads, formatted viewing, and comparing of SQL definitions.
If you're like me, you look up SQL-based objects on a daily basis. When dealing with many SQL Servers and databases, it can be a pain. Most people use SQL Server Management Studio for this. However, this means a lot of clicking, scrolling, right-clicking, carpal tunnel syndrome, etc.
Navigating (or browsing) to find something has it's place. However, when there's a significant amount to browse, a search feature can be a great help. This is especially true when you're in a hurry, or you're not sure where to start looking (which for me, is pretty much all the time). Given a few words, search engines return instant results. We take this ability for granted today. So, this is what SQLoogle tries to provide.
Here's the basic game plan for SQLoogle:
- Extract SQL from SQL Servers.
- Transform, and aggregate SQL.
- Load SQL into Lucene.NET.
- Search SQL!
Here is a diagram I made with draw.io

SQLoogle's configuration uses .NET 2.0's configuration API. There is a great article about this on the 4GuysFromRolla site. Here is an example of a sqloogleBot section in App.Config:
<sqloogleBot searchIndexPath="c:\Sqloogle\SearchIndex\"
<servers>
<add name="localhost"
connectionString="Server=localhost;Database=master;Trusted_Connection=True;" />
</servers>
<skips>
<add name="master"></add>
<add name="model"></add>
<add name="tempdb"></add>
<add name="msdb"></add>
<add name="SharePoint" operator="StartsWith"></add>
</skips>
</sqloogleBot>There are 2 collections: servers, and skips. In the servers element, add names and connection strings for each server you want to crawl. I only have one above, but you can add as many as you want. In the skips element, add any databases you're not interested in. Maybe you won't need this, but I found there are some database objects I just don't care about. For convenience, the skip element has an operator attribute supporting equals, startsWith, and endsWith. This allows you to filter out several databases with one entry. So for the example above, SQLoogle crawls the local SQL Server, and it skips over the databases: master, model, tempdb, msdb, and any database starting with SharePoint.

SQLoogle is about 75% ETL. When you realize your program is mostly ETL, you need to find an ETL tool. For Microsoft shops, you might think SQL Server Integration Services (SSIS). For a Java shops, you might think Talend. But, if you don't want to take a dependency like SSIS or Talend, and you'd rather not use a GUI tool to drag-n-drop and right-click your ETL solution, you need to find an alternative.
For SQLoogle, I chose a developer friendly ETL framework called Rhino ETL. It was created in .NET by Ayende. It's open source, and easy to include in your project with NuGet.
Rhino ETL is developer friendly because it's code. You stay within Visual Studio and compose ETL processes in beautiful object oriented C#. You may use any logging framework and/or unit-testing framework you want. You can refactor it with ReSharper, and Resharper really makes it shine by high-lighting what methods you need to implement. It comes with a lot of nice operations (components), and of course you can build a reusable library of your own operations that do all kinds of amazing things; afterall, you get the whole .NET framework to work with.
Rhino ETL lets us register operations, and/or partial processes into a multi-threaded data pipeline.
- An
Operationis a single extract, transform, or load. An operation is roughly equivalent to the components you use in GUI-based ETL tools. - A
PartialProcessOperationis comprised of multiple operations.
Both implement the same interface, so they are interchangeable in the pipeline. SQLoogle uses and/or implements many Rhino ETL's operations including:
- The
InputCommandOperation - The
AbstractOperation - The
JoinOperation, including a Left Join, and a Full Outer Join. - The
AbstractAggregationOperation
Here is the main SQLoogle process that is executed from a Console application.
public class SqloogleProcess : SqloogleEtlProcess {
protected override void Initialize() {
var config = (SqloogleBotConfiguration)ConfigurationManager.GetSection("sqloogleBot");
if (!Directory.Exists(config.SearchIndexPath))
Directory.CreateDirectory(config.SearchIndexPath);
Register(new ParallelUnionAllOperation(config.ServerCrawlProcesses()));
Register(new SqloogleAggregate());
Register(new SqloogleTransform());
Register(new SqloogleCompare().Right(new LuceneExtract(config.SearchIndexPath)));
RegisterLast(new LuceneLoad(config.SearchIndexPath));
}
}The SqloogleProcess implements SqloogleEtlProcess,
which implements Rhino ETL's main EtlProcess
and adds a bit more logging. Line 10 registers
a ServerCrawlProcess for each server defined
in the configuration. The ParallelUnionAllOperation
executes each server process in parallel.
Rhino ETL doesn't come with a ParallelUnionAllOperation,
and, at the time, I wasn't exactly sure how to create
one. So, I emailed Ayende to ask him. Because he
knows how important SQLoogle is, he sent me a link
to a blog post.
He had pasted a prototype on his blog. One of his
readers posted another one here.
Another suggested that it might be done with parallel
LINQ, which is a good point. Needless to say, a big
thanks goes out to these developers for helping me
with the parallel programming bit.
Now let's examine what the ServerCrawlProcess
does.
public class ServerCrawlProcess : PartialProcessOperation {
public ServerCrawlProcess(string connectionString, string server) {
var union = new ParallelUnionAllOperation(
new DefinitionProcess(connectionString),
new CachedSqlProcess(connectionString),
new SqlAgentJobExtract(connectionString),
new ReportingServicesProcess(connectionString)
);
Register(union);
RegisterLast(new AppendToRowOperation("server", server));
}
}The ServerCrawlProcess is a PartialProcessOperation, which, as I mentioned before, is made up of multiple operations. Given the connection strings and server names from configuration, it gathers SQL objects from different parts of SQL Server in parallel. The first process is the DefinitionProcess.
public class DefinitionProcess : PartialProcessOperation {
public DefinitionProcess(string connectionString) {
Register(new DatabaseExtract(connectionString));
Register(new DatabaseFilter());
Register(new DefinitionExtract());
Register(new CachedObjectStatsJoin().Right(new CachedObjectStatsExtract(connectionString)));
Register(new TableStatsJoin().Right(new TableStatsExtract(connectionString)));
RegisterLast(new IndexStatsJoin().Right(new IndexStatsExtract(connectionString)));
}
}The DefinitionProcess is another PartialProcessOperation. It is responsible for gathering the SQL definitions from the appropriate databases and adding the usage statistics to them. Let's take a look at our first single operation; the DatabaseExtract.
The DatabaseExtract is an InputOperation. The InputOperation inherits from Rhino ETL's provided InputCommandOperation, which requires an implementation of two methods; the PrepareCommand, and CreateRowFromReader methods:
protected override void PrepareCommand(IDbCommand cmd) {
cmd.CommandText = @"/* SQLoogle */
USE master;
SELECT
database_id AS databaseid
,[Name] AS [database]
,Compatibility_Level AS compatibilitylevel
FROM sys.databases WITH (NOLOCK)
WHERE [state] = 0
AND [user_access] = 0
AND [is_in_standby] = 0
AND compatibility_level >= 80
ORDER BY [name] ASC;
";
}
protected override Row CreateRowFromReader(IDataReader reader) {
var row = Row.FromReader(reader);
row["connectionstring"] = GetDatabaseSpecificConnectionString(row);
return row;
}PrepareCommand let's you setup the database
SQL (or stored procedure) command. As you can
see in the WHERE clause, this SQL query avoids
extracting databases that are inaccessible, or
incompatible. The CreateRowFromReader method
provides an opportunity to capture the query's results and pass them on in the form of Rhino ETL's Row objects. The Row is much like a dictionary, only it doesn't throw an error when trying to access a key that doesn't exist, and it provides some helpful methods. There is a convenient FromReader method on it if you want all the columns returned from the query. This method refers to ADO.NET's IDataReader object. I used it here to put databaseid, database, and compatibilitylevel in the row variable. Then, I added one more key called "connectionstring." The connectionstring is a database specific connection string for each database. This is used later in the pipeline by the libraries responsible for extracting the SQL definitions.
The next operation is the DatabaseFilter, which
introduces the AbstractOperation. Rhino ETL's
AbstractOperaton is very useful. The Execute
method gives us an opportunity to transform or
filter rows as they pass through the pipeline.
It takes and returns an IEnumerable of Row.
This makes it very easy to operate on the rows
with LINQ, or a ForEach loop that yields
results as they are available. Once we're done
manipulating the rows, they are passed on to
the next operation in the pipeline.
The purpose of the DatabaseFilter is to filter
out the skips defined in the configuration.
Here is the DatabaseFilter's Execute implementation:
public override IEnumerable<Row> Execute(IEnumerable<Row> rows) {
return rows.Where(row => !_config.Skips.Match(row["database"].ToString()));
}In this case, I added a Match method to
the SkipElementCollection (Skips) in order to check
each "database" being passed through. If there is
no matching skip, the database gets to pass though,
otherwise, well, it's skipped!
A word of advice... I have found that it is tempting
to add a lot of transformation and/or filtering to
an AbstractOperation. Afterall, you're there,
you could just add it quickly. You will see evidence
of this my code. But, I would recommend that you
try and limit each operation to a single
responsibility. This will help make more manageable
code in the long run.
Next up, is the DefinitionExtract is another
AbstractOperation. It adapts the Open DB Diff project
libraries responsible for generating T-SQL definitions.
This is the 3rd (and fastest) SQL generation
library I've used. It uses the "connectionstring"
created in the DatabaseExtract operation.
After the definitions are extracted for each database, they are fed through a series of three joins starting on line 7 of the DefinitionProcess. You only see the Right() part of the join because the left side defaults to whatever is in the pipeline. In this case, definitions from the previous operation are on the left and usage is on the right.
What is usage? Usage is an estimate of how many times
an object has been used, and when it was last used
(since the server was last restarted). Each one of
the three joins incorporate a different kind of usage. First, there is CachedObjectStatsExtract, which pulls in object usage (e.g. procedures, views, etc.). Second, there is TableStatsExtract, which obviously pulls in table related usage. Finally, there is IndexStatsExtract usage. Let's take a look at one of the join operations to illustrate how Rhino ETL's join operation works:
public class CachedObjectStatsJoin : JoinOperation {
protected override Row MergeRows(Row leftRow, Row rightRow) {
var row = leftRow.Clone();
row["use"] = rightRow["use"];
row["lastused"] = DateTime.Now;
return row;
}
protected override void SetupJoinConditions() {
LeftJoin.Left("database", "objectid").Right("database", "objectid");
}
}Rhino ETL's JoinOperation asks you to override two methods. They are SetupJoinConditions, and MergeRows. Setting up the join requires a join type, and the keys (or fields) to join on. Rhino ETL supports inner, left outer, right outer, and full outer joins. Line 11 indicates a left join, because I want the definition to pass through regardless if I have usage statistics for it (that is, regardless if I have a match on the right side of the join).
In MergeRows, we need to take two rows; a left row and a right row, and make them one. Another helpful method on Row is the Clone() method. It lets us get everything from one row, and add specifics from the other. In this case, line 4 clones everything from the left row (the definition) and adds "use" from the right row. For cached objects, I set "lastused" to DateTime.Now. My thinking is that if it's in the cache (which is where these stats come from), it's basically being used right now.
Going over the next two joins would be non-productive. They are very similar to the CachedObjectStatsJoin. Now we have to bounce back up the the ServerCrawlProcess and see what's next.
The DefinitionProcess is just one of four things running simultaneously in the ServerCrawlProcess. The CachedSqlProcess is running too.
public class CachedSqlProcess : PartialProcessOperation {
public CachedSqlProcess(string connectionString) {
Register(new CachedSqlExtract(connectionString));
Register(new CachedSqlPreTransform());
Register(new CachedSqlAggregate());
Register(new CachedSqlPostTransform());
}
}This PartialProcessOperation is concerned with queries that do not have stored definitions. The adhoc and prepared queries are important to SQLoogle because they represent dependencies on SQL objects. We'll cover the first three operations in this process.
The CachedSqlExtract is another InputOperation. When I first examined the query's results, I was surprised by the duplicates I saw. Well, they're not exactly duplicates. Although they look like duplicates, they have small differences with parameters, spacing, and/or punctuation. To illustrate, here's a screen-shot of some common duplicate cached plans:

Above, there are 14 ad-hoc queries, but SQLoogle must reduce this to 1 query with a "use" of 14. If it didn't reduce this, search results would be full of these very similar ad-hoq queries, introducing too much noise and making the results useless. To avoid this, SQLoogle must replace the different parameters with a place holder, and only store "SELECT * FROM UserArea WHERE UserArea.UserKey = **@Parameter**." This is done in the CachedSqlPreTransform operation.
This is an AbstractOperation with the Execute method implemented:
public override IEnumerable<Row> Execute(IEnumerable<Row> rows) {
foreach (var row in rows) {
var sql = Trim(row["sqlscript"]);
if (sql.StartsWith("/* SQLoogle */")) continue;
if (!IsOfInterest(sql)) continue;
sql = ReplaceParameters(sql);
row["sqlscript"] = RemoveOptionalDetails(sql);
yield return row;
}
}Line 6 filters out anything starting with /* SQLoogle */, because an ad-hoc query starting with this is SQLoogle itself. The ReplaceParameters method uses a compiled regular expression to convert literal parameters to a @Parameter place-holder. I spent a fair amouunt of time working in Expresso to get this regular expression working. Rather than show it to you and struggle to explain regular expression syntax, I'll show you the unit test instead:
[Test]
public void TestReplaceSimpleParameters() {
const string sql = @"
select 0 from t where c = @z;
select 1 from t where c = 1
select 2 from t where c = 15.1
select 3 from t where c = 1.
select 4 from t where c = .15
select 5 from t where c=2
select 6 from t where c > 1
select 7 from t where c < 1
select 8 from t where c <> 1
select 9 from t where c != 1
select 10 from t where c != 1;
select 11 from t where c1 = 1 and c2 = 2;
select 12 from t where c1 = 'dale' and c2 = 3.0
select 13 from t where c = 'Newman'
select 14 from t where c1 = '' and c2 = 3
select 15 from t where c1 = 'stuff' and c2 = '3'
select 17 from t where c like 'something%'
select 18 from t where c not like 'something%'
select 19 from t where c = 'dale''s'
select 20 from t where c1 = 'dale''s' and c2 = 'x'
select 21 from t where c = -1
select 22 from t where c LIKE '%something%'
select 23 from t where ""t"".""c""='0000089158'
select 24 from t1 inner join t2 on (t1.field = t2.field) where t2.field = 'x';
select 25 from t where c = @Parameter
select 26 from t where c = N'Something'
select 27 from t1 inner join t2 on
(""t1"".""field""=""t2"".""field"")
where double_quotes = 'no'
select 28 from t where [c]='brackets!';
select 29 from t where x = 0x261BE3E63BBFD8439B5CE2971D70A5DE;
";
const string expected = @"
select 0 from t where c = @z;
select 1 from t where c = @Parameter
select 2 from t where c = @Parameter
select 3 from t where c = @Parameter
select 4 from t where c = @Parameter
select 5 from t where c= @Parameter
select 6 from t where c > @Parameter
select 7 from t where c < @Parameter
select 8 from t where c <> @Parameter
select 9 from t where c != @Parameter
select 10 from t where c != @Parameter;
select 11 from t where c1 = @Parameter and c2 = @Parameter;
select 12 from t where c1 = @Parameter and c2 = @Parameter
select 13 from t where c = @Parameter
select 14 from t where c1 = @Parameter and c2 = @Parameter
select 15 from t where c1 = @Parameter and c2 = @Parameter
select 17 from t where c like @Parameter
select 18 from t where c not like @Parameter
select 19 from t where c = @Parameter
select 20 from t where c1 = @Parameter and c2 = @Parameter
select 21 from t where c = @Parameter
select 22 from t where c LIKE @Parameter
select 23 from t where ""t"".""c""= @Parameter
select 24 from t1 inner join t2 on (t1.field = t2.field) where t2.field = @Parameter;
select 25 from t where c = @Parameter
select 26 from t where c = @Parameter
select 27 from t1 inner join t2 on
(""t1"".""field""=""t2"".""field"")
where double_quotes = @Parameter
select 28 from t where [c]= @Parameter;
select 29 from t where x = @Parameter;
";
var actual = CachedSqlPreTransform.ReplaceParameters(sql);
Assert.AreEqual(expected, actual);
}The sql variable tries to simulate as many different combinations of operators and literal parameters that might come in from cached query plans. The expected variable is what the sql should look like after running it through the ReplaceParameters method. This unit test reduces my fear of re-factoring the regular expression. It is also a case where I really couldn't have worked it out without constantly re-running the test to make sure I didn't mess it up!
After CachedSqlPreTransform transforms many similar queries to exact duplicates, CachedSqlAggregate is used to eliminate (or group on) the duplicate queries. This operation inherits from the AbstractAggregationOperation. So, it's going to be our introduction to Rhino ETL's aggregation feature.
This class requires an implementation for two methods: GetColumnsToGroupBy, and Accumulate. Let's take a look at it.
public class CachedSqlAggregate : AbstractAggregationOperation {
protected override string[] GetColumnsToGroupBy() {
return new[] { "sqlscript" };
}
protected override void Accumulate(Row row, Row aggregate) {
// init
if (aggregate["sqlscript"] == null)
aggregate["sqlscript"] = row["sqlscript"];
if (aggregate["type"] == null)
aggregate["type"] = row["type"];
if (aggregate["database"] == null) {
aggregate["database"] = new Object[0];
}
if (aggregate["use"] == null) {
aggregate["use"] = 0;
}
//aggregate
if (row["database"] != null) {
var existing = new List<Object>((Object[])aggregate["database"]);
if (!existing.Contains(row["database"])) {
existing.Add(row["database"]);
aggregate["database"] = existing.ToArray();
}
}
aggregate["use"] = ((int)aggregate["use"]) + ((int)row["use"]);
}
}I designate "sqlscript" as the grouping field in the GetColumnsToGroupBy method. Rhino ETL takes care of grouping, but you need to tell it how to aggregate the data in the Accumulate method. There are really only two things you have to do in the Accumulate method; initialize, and then aggregate.
Initialization occurs when the first row enters the operation. The aggregate Row doesn't have any keys in it, so you should initialize it to the incoming row's value, or to a default value. Initialization needs to include the grouping column as well, so don't forget that.
After that, when you know for sure the aggregate variable has keys and initial values , it's time to decide how you want to aggregate. Above, the only fields that truly need aggregation are database and use. I store databases in an array, and I add up (or sum) the use, and this does the trick. It reduces my example above (of 14 similar) cached SQL records, to 1 record, with a use of 14.
The AbstractAggregationOperation is just one way to aggregate in Rhino ETL. If you prefer, you could use LINQ group by operators in an AbstractOperation instead. Just always keep in mind that the whole .NET framework is at your disposel.
That's all we need to see from the ServerCrawlProcess. Now it's time to jump back all the way to the top level; the SqloogleProcess. I'll skip SqloogleAggregate, because if you've seen one aggregation, you've seen them all, no?
The SqloogleTransform operation is next. It is an AbstractOperation used to prepare the data for Lucene. Here is the Execute method:
public override IEnumerable<Row> Execute(IEnumerable<Row> rows) {
foreach (var row in rows) {
row["id"] = row["sqlscript"].GetHashCode().ToString(
CultureInfo.InvariantCulture).Replace("-","X");
row["sql"] = row["sqlscript"] + " " + SqlTransform(row["sqlscript"]);
row["created"] = DateTransform(row["created"], DateTime.Today);
row["modified"] = DateTransform(row["modified"], DateTime.Today);
row["lastused"] = DateTransform(row["lastused"], DateTime.MinValue);
row["server"] = ListTransform(row["server"]);
row["database"] = ListTransform(row["database"]);
row["schema"] = ListTransform(row["schema"]);
row["name"] = ListTransform(row["name"]);
row["use"] = Strings.UseBucket(row["use"]);
row["count"] = row["count"].ToString().PadLeft(10,'0');
row["dropped"] = false;
yield return row;
}
}The id field should be unique for each Lucene document. I'm relying on the GetHashCode method. I replace the "-" with an "X" because the "-" character is the prohibit operator in Lucene's query syntax.
The sql field includes everything in sqlscript field, plus additional transformed SQL. The SqlTransform method returns a string of distinct words split by title case. Splitting by title case helps Lucene find something like "GetOrder" when you search for "Get" and/or "Order."
The created, modified, and lastused fields are all dates. In order to support range queries and sorts in Lucene, I transform the dates to YYYYMMDD format. The second parameter on DateTransform is the default date, if for some reason the field is null.
The server, database, schema, and name fields are arrays. I join them into a delimited string.
The use, and count fields are numbers. Like dates, they are left padded with zeros to support range queries and sorts. In addition, the UseBucket method replaces every digit except the most significant digit with zeroes. It does this to reduce the number of updates to the Lucene index. After all, I'm only interested in an idea of how much it's used, not the exact number.
The dropped field is a boolean. Obviously, anything the ServerCrawlProcess finds isn't dropped, so it's set to false.
Now that the data crawled is ready for loading into Lucene, it needs to be run through SqloogleCompare in order to see what to do with it. This is a JoinOperation. It is a full outer join that will compare the crawled data with what's already in the Lucene index. It will determine an action to perform with each row on both sides of the join. Here is the implementation of the MergeRows() method:
protected override Row MergeRows(Row newRow, Row oldRow) {
Row row;
// if the old row doesn't exist, then newRow is new, and it should be created
if (oldRow["id"] == null) {
row = newRow.Clone();
row["action"] = "Create";
return row;
}
// if the new row doesn't exist, then oldRow has been
// dropped, and it should be marked as dropped and updated
if (newRow["id"] == null) {
row = oldRow.Clone();
row["dropped"] = true;
row["action"] = "Update";
return row;
}
// if new and old rows are the same, then we have nothing to do.
if (Equal(newRow, oldRow)) {
row = oldRow.Clone();
row["action"] = "None";
return row;
}
// if we end up here, the sql is the same but other properties have been updated, so we should update it.
row = newRow.Clone();
row["action"] = "Update";
row["modified"] = _today;
return row;
}Hopefully the comments in the MergeRows method are helpful. I've renamed the MergeRow arguments from leftRow and rightRow to newRow and oldRow. The newRow represents the SQL just crawled and prepared by SQLoogle. The oldRow represents the SQL already in SQLoogle's Lucene index.
On line 6, if the old row from the Lucene index does not exist, then SQLoogle has found a new sql definition in the new row. So, newRow's action is set to "Create", and it's returned.
If the opposite is true on line 13; that is, an old row is present but there is no matching new row, then the old row's SQL definition has been dropped (or is temporarily missing, off-line, etc). I could delete it from the index, but instead, I choose to update it's dropped field to true and set it's action to "Update". By default, it will be filtered out of the search results. However, it may be included in results if dropped:true is added to the Lucene query. This comes in handy sometimes when something is accidently dropped.
Line 21 will only run if both the old and new rows are present. If they are, the Equal() method checks the equality of other fields. It they're all the same, then the action is "None", and the SQL object can rest easy in the Lucene index; untouched.
Line 28 starts a catch all. Anything making it this far means that the SQL is the same, but 1+ properties have changed, so it's an "Update". To record the update, I set the "modified" field to today.
Now every record should be ready to go into Lucene, and have an action key of Create, Update, or None. This action will be used in LuceneLoad, the next, and final ETL operation we'll cover.
Finally, the data in the pipeline is ready for Lucene. LuceneLoad inherits from AbstractLuceneLoad. We'll start with the concrete, and move into the abstract class.
public class LuceneLoad : AbstractLuceneLoad {
public LuceneLoad(string folder) : base(folder) {}
public override void PrepareSchema() {
Schema["id"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["use"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["count"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["score"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["created"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["modified"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["lastused"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["lastneeded"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS);
Schema["sql"] = new LuceneFieldSettings(Field.Store.NO, Field.Index.ANALYZED);
Schema["sqlscript"] = new LuceneFieldSettings(Field.Store.YES, Field.Index.NO);
}
}The constructor requires a folder. This will be the folder where the Lucene.NET index is stored. The PrepareSchema method gives us a chance to set Lucene storage and index options for specific fields. If we do not specify a LuceneFieldSettings for a field, the default is used.
You get a choice to store and/or index each field in a Lucene Document. In order to get something back in search results, you have to store it (Field.Store.YES). In order to be able to search a field, you have to index it (something other than Field.Index.NO). I'm doing three things in PrepareSchema:
- Storing the predictable fields, and using the bare minimum indexing strategy (i.e.
Field.Index.NOT_ANALYZED_NO_NORMS). Examples of these types of fields are my dates; they are always the same format. They're not really full text, so they won't need any special analysis. - Not storing the transformed "sql" field, but using the maximum indexing strategy (i.e.
Field.Index.ANALYZED). The transformed SQL is for enhancing search results, so it needs full text analysis. However, it will never be returned in search results, so there is no need to store it (and waste space). - Storing the "sqlscript" field (the exact sql script), but not indexing it at all (i.e. Index.NO). This will be returned in search results, because SQLoogle needs to provide valid SQL scripts. Yet, I don't need to index it, because the transformed SQL includes the valid SQL script, and more.
By doing this, SQLoogle is saving space, and keeping the search index fast. Now let's take a look at the abstract class.
public abstract class AbstractLuceneLoad : AbstractOperation {
private readonly FSDirectory _indexDirectory;
private readonly StandardAnalyzer _standardAnalyzer;
private readonly IndexWriter _indexWriter;
private readonly Dictionary<string,> _counters = new Dictionary<string,>();
public Dictionary<string,> Schema { get; set; }
protected AbstractLuceneLoad(string folder, bool clean = false) {
_indexDirectory = FSDirectory.Open(new DirectoryInfo(folder));
_standardAnalyzer = new StandardAnalyzer(Version.LUCENE_30);
_indexWriter = new IndexWriter(_indexDirectory,
_standardAnalyzer, IndexWriter.MaxFieldLength.UNLIMITED);
_counters.Add("None", 0);
_counters.Add("Create", 0);
_counters.Add("Update", 0);
Schema = new Dictionary<string,>();
}
public abstract void PrepareSchema();
public override IEnumerable<row> Execute(IEnumerable<row> rows) {
PrepareSchema();
foreach (var row in rows) {
if (row["action"] == null) {
throw new InvalidOperationException("There is no action column." +
" A valid action is None, Create, or Update!");
}
var action = row["action"].ToString();
row.Remove("action");
_counters[action] += 1;
switch (action) {
case "None":
continue;
case "Create":
_indexWriter.AddDocument(RowToDoc(row));
continue;
case "Delete":
_indexWriter.DeleteDocuments(new Term("id", row["id"].ToString()));
continue;
case "Update":
_indexWriter.DeleteDocuments(new Term("id", row["id"].ToString()));
_indexWriter.AddDocument(RowToDoc(row));
continue;
}
}
yield break;
}
private Document RowToDoc(Row row) {
var doc = new Document();
foreach (var column in row.Columns) {
if (Schema.ContainsKey(column)) {
doc.Add(new Field(column.ToLower(), row[column].ToString(),
Schema[column].Store, Schema[column].Index));
} else {
doc.Add(new Field(column.ToLower(), row[column].ToString(),
Field.Store.YES, Field.Index.ANALYZED));
}
}
return doc;
}
public sealed override void Dispose() {
Info("Lucene Create: {0}, Update: {1}, and None: {2}.", _counters["Create"],
_counters["Update"], _counters["None"]);
Info("Lucene Optimizing.");
_indexWriter.Optimize();
Info("Lucene Committing.");
_indexWriter.Commit();
_indexWriter.Dispose();
_indexDirectory.Dispose();
_standardAnalyzer.Close();
_standardAnalyzer.Dispose();
base.Dispose();
}
}The AbstractLuceneLoad inherits from the AbstractOperation. So, we have to implement the Execute() method as usual. In addition, we need a place to setup and teardown the Lucene.NET plumbing. I'm use the constructor to set it up, and the Dispose() method to tear it down.
The constructor prepares an index writer. The writer needs a directory, and an analyzer. Once it has them, it's ready to manipulate the index. By manipulation, I mean to say it can add documents, delete documents, and even optimize the index. It does not update documents, so updates are performed by deleting, and then adding the updated document again.
To make any action final, you have to call the Commit() method. It's kind of like a database transaction; you have to Commit() or Rollback() your changes.
The Execute calls our PrepareSchema() method defined in LuceneLoad. This will setup our storage and indexing strategy. Now we're ready to process the rows. First, we have to check if the "action" field is there. If it's not, something is wrong, so I just throw an exception because I want to know about it. Then, because I don't want the "action" field stored in the Lucene index, I remove it from the Row instance with the helpful Remove() method.
The switch statement goes about the task of performing the action on the lucene index. As you can see, the Lucene API is pretty straight forward, there is an AddDocument() method for adding, and a DeleteDocuments() method for deleting. Converting the Row instance to a Lucene Document instance is easy. The RowToDoc method just loops through the columns in the row and adds them to the document. This is where the Schema can override the default storage and index choices.
The Dispose() method cleans up everything. Rhino ETL is going to call this for us. I've added all kinds of nice logging to see what's happening.
Running the crawler on a schedule keeps your Lucene index up to date. Now you can search all your objects. SQLoogle includes an ASP.NET MVC website project that you can deploy so everyone can search.