- 2.1 Create Astra Account
- 2.2 Create a Vector database
- 2.3 Create a token
- 2.4 Semantic Search with CQL
Part II - Retrieval Augmented generation
- 3.1 - Overview
- 3.2 - Prerequisites
- 3.3 - Run the notebook
- 3.4 - Check data in the database
- 3.5 - Cleanup
- 3.6 - Additional Information
Amazon Bedrock is a fully managed, fully serverless service offering access to foundation models from various AI companies in a single API, together with additional capabilities such as facilities for fine-tuning and agent frameworks.
Amazon Bedrock aims at simplifying development, especially for Generative AI, while maintaining privacy and security. Experimenting with foundation models is easy, and models can be further customized in a privacy-aware fashion within Bedrock.

✅ 1.1.a- Connect to yourAWS Management Consoleand look for serviceAmazon Bedrock

✅ 1.1.b- On home page select Get started

✅ 1.1.c- In the following tutorials we will be using the modelsClaude V2andTitan. To see what is available to you and ask for more model access theModel Accessitem in the menu.

-
✅ 1.1.d- In the left hand side menu pickChat -
✅ 1.1.e- Select model Provider and model
| Attribute | Value |
|---|---|
| Provider | Anthropic |
| Model | Claude V2 |

✅ 1.1.f- In the prompt enter the question and clickrun
Explain me what Datastax Astra Vector is
✅ 1.1.g- Above the prompt clickUpdate inference instructionto check for a few options

-
✅ 1.2.a- Start a new chat window with theStart new chat -
✅ 1.2.b- In the instructions provide the following block (few shot learning)
You are a text analyzer that need to tell me if the sentiment is positive or negative. Here a sample with results.text:I hated this movie
Sentiment: negative
Sentiment: positive
Text: most boring 90 minute of my life
Sentiment:negative
I will now give you some text and will repeat the process

✅ 1.2.c- Validate the instructions and clickrun

✅ 1.2.d- Start a a new chat and now try the following (Chain of thought)
When i was 6 my sister was half my age. Now I am 70. How old is my sister ?

ℹ️ Note: Here's a comparison table that outlines the key differences between a Chat Model and a Language Model in the context of Large Language Models (LLMs):
Feature Chat Model Language Model Primary Function Engage in conversational dialogue Generate text based on input Interactivity High, designed for back-and-forth exchange Varies, typically less interactive Context Management Maintains context over a session Limited context retention Output Tailored responses, can handle commands Broader text generation Training Objective Optimized for chat interaction Optimized for a wide range of text tasks Use Cases Customer service, virtual assistants, etc. Content creation, summarization, etc. Personalization Can adapt to user's style and preferences Less personalization Continuity Can reference previous dialogue May not reference earlier content as well Response Length Typically shorter, conversational Can be longer and more detailed Real-time Adaptation Can adjust to new topics in real-time Follows the prompt, less adaptive
✅ 1.3.a- In the menu pick Playgrounds / Text

✅ 1.3.b- Select model Provider and model
| Attribute | Value |
|---|---|
| Provider | Anthropic |
| Model | Claude V2 |
✅ 1.3.c- Enter the code and run
Write me a Cassandra CQL Statement to create a table and perform queries by user identifier

✅ 1.4.a- In the menu pick Getting Started / Examples

✅ 1.4.b- Slect a model using Claude and select open in playground. Run the model.

ℹ️ Account creation tutorial is available in awesome astra
✅ 2.1.a- click the image below or go to https://astra.datastax./com
✅ 2.2.a- Find the create database button

✅ 2.2.b- Populate the create db form
| Attribute | Value |
|---|---|
| Database Type | Vector Database |
| Database Name | db_iloveai |
| Keyspace Name | default_keyspace |
| Cloud Provider | Amazon |
| Region | us-east-2 |
✅ 2.2.c- Click the[Create Database]button.

Wait for for the database to change status from pending to active active.
✅ 2.3.a- Select the connect TAB and click on Generate token
Database Administration

✅ 2.3.b- Save the token for later as a json file

The Token is in fact three separate strings: a Client ID, a Client Secret and the token proper. You will need some of these strings to access the database, depending on the type of access you plan. Although the Client ID, strictly speaking, is not a secret, you should regard this whole object as a secret and make sure not to share it inadvertently (e.g. committing it to a Git repository) as it grants access to your databases.
{
"ClientId": "ROkiiDZdvPOvHRSgoZtyAapp",
"ClientSecret": "fakedfaked",
"Token":"AstraCS:fake"
}✅ 2.4.a- Locate the tabCQL Consoleand open the CQL Console

✅ 2.4.b- Select the keyspace we createdefault_keyspace
USE default_keyspace;✅ 2.4.c- Use this code to create a new table in your keyspace with a five-component vector column.
CREATE TABLE IF NOT EXISTS products (
id int PRIMARY KEY,
name TEXT,
description TEXT,
item_vector VECTOR<FLOAT, 5>
);✅ 2.4.d- Create the custom index with Storage Attached Indexing (SAI). Creating the index and then loading the data avoids the concurrent building of the index as data loads.
CREATE CUSTOM INDEX IF NOT EXISTS ann_index
ON products(item_vector) USING 'StorageAttachedIndex';✅ 2.4.e- Insert sample data into the table using the new type.
INSERT INTO products (id, name, description, item_vector) VALUES (
1, //id
'Coded Cleats', //name
'ChatGPT integrated sneakers that talk to you', //description
[0.1, 0.15, 0.3, 0.12, 0.05] //item_vector
);
INSERT INTO products (id, name, description, item_vector)
VALUES (2, 'Logic Layers',
'An AI quilt to help you sleep forever',
[0.45, 0.09, 0.01, 0.2, 0.11]);
INSERT INTO products (id, name, description, item_vector)
VALUES (5, 'Vision Vector Frame',
'A deep learning display that controls your mood',
[0.1, 0.05, 0.08, 0.3, 0.6]);✅ 2.4.f- Query vector data with CQL
To query data using Vector Search, use a SELECT query.
SELECT * FROM products
ORDER BY item_vector ANN OF [0.15, 0.1, 0.1, 0.35, 0.55]
LIMIT 1;✅ 2.4.g- Calculate the similarity: Calculate the similarity of the best scoring node in a vector query for ranking, filtering, user feedback, and system optimization in applications where similarity/relevance are crucial. This calculation helps you make informed decisions and enables algorithms to provide more tailored and accurate results.
SELECT description, similarity_cosine(item_vector, [0.1, 0.15, 0.3, 0.12, 0.05])
FROM products
ORDER BY item_vector ANN OF [0.1, 0.15, 0.3, 0.12, 0.05]
LIMIT 3;In the following example, you will be able to run a standard RAG (retrieval-augmented generation) application that makes use of AI models from Amazon Bedrock and uses Astra DB as a Vector Store.
The integration is built with the LangChain framework, which conveniently offers native support for Amazon Bedrock as well as Astra DB. Using LangChain is a popular and well-established choice -- but certainly not the only one. See the references at the end of the page for further options.
To run the integration demo notebook, you need:
-
✅An Amazon account with access to Amazon Bedrock and Amazon SageMaker Studio. In particular, you will be asked to provide a set of credentials for programmatic access (i.e.AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEYandAWS_SESSION_TOKEN); -
✅Alternatively, if you run the notebook from within SageMaker Studio, it is sufficient to add the Bedrock policy to your SageMaker role instead of explicitly providing the above secrets. Please refer to this link for details. -
✅An Astra account with a Serverless Cassandra with Vector Search database. You will need the Database ID and an Access Token with role "Database Administrator".
The integration example is a Python 3.8+ runnable notebook. The suggested method is to import the notebook in your Amazon SageMaker Studio and run it from there on a standardized environment, which also makes the necessary AWS access credentials readily available. As a side note, however, the code can be executed on any environment able to run Python notebooks.

✅ 3.3.a- Download the notebook from this repository at this link and save it to your local computer. (You can also view it on your browser.)
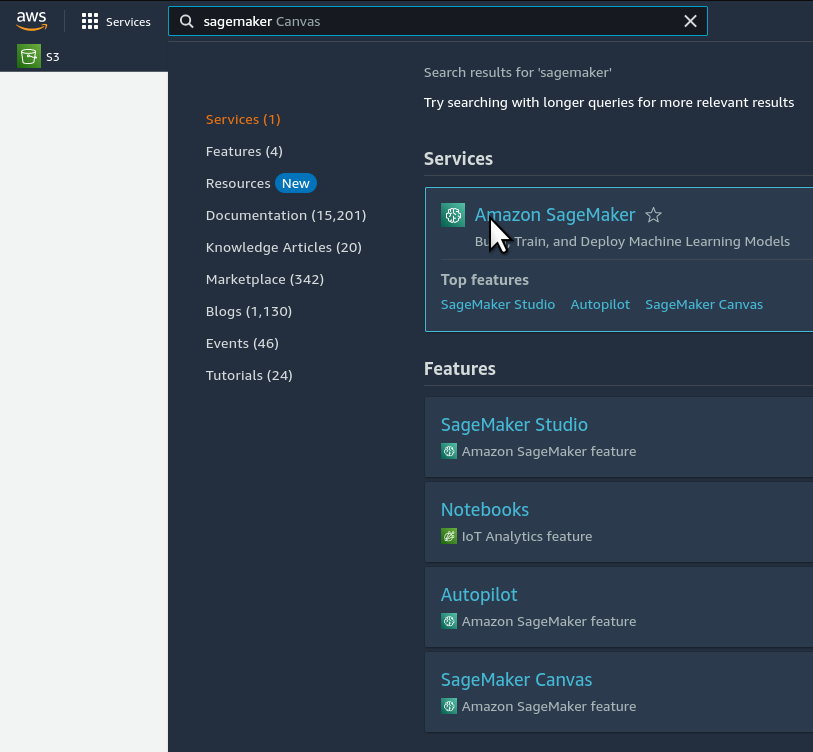
✅ 3.3.b- Open your Amazon SageMaker console and click the "Studio" item in the left navbar. Do not choose "Studio Lab", which is a different thing.
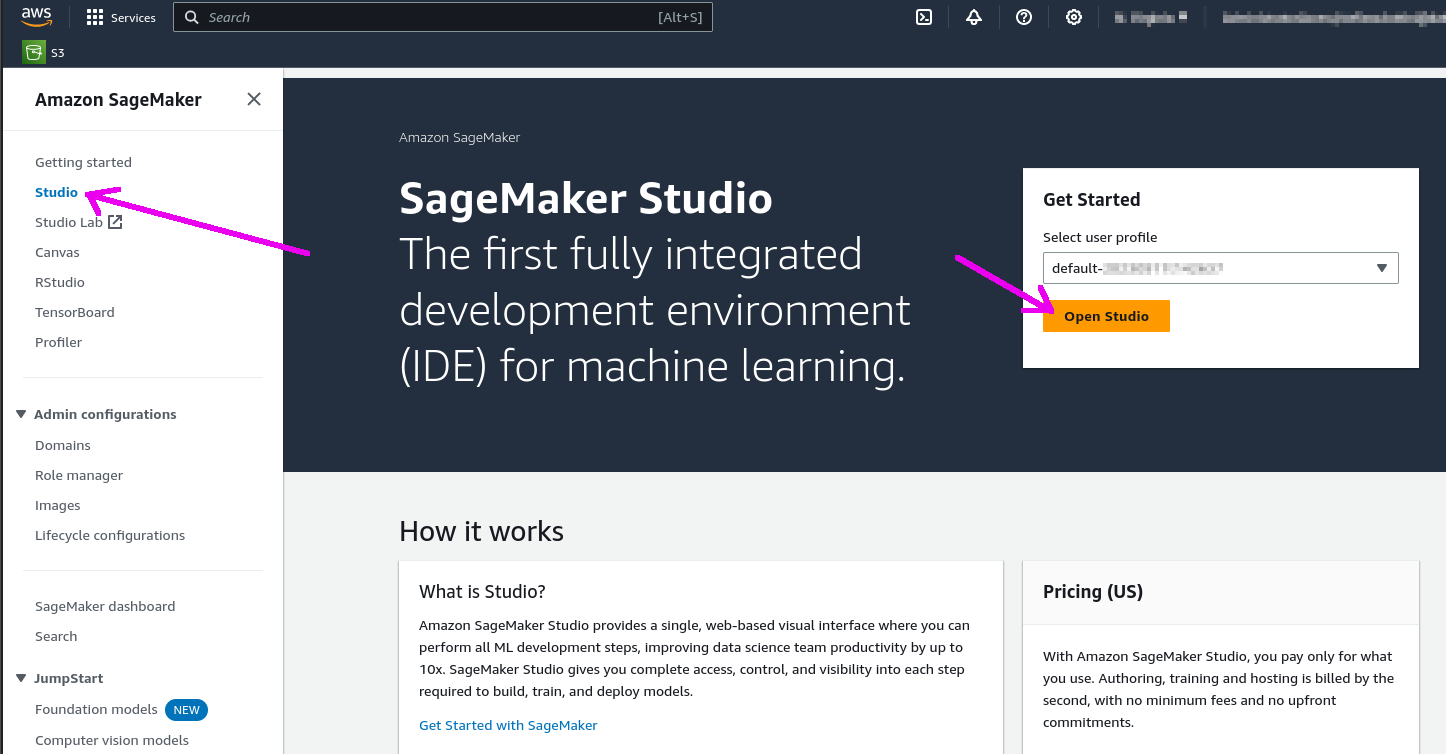
✅ 3.3.c- Click the "Open Studio" button after choosing a user profile: this will bring you to the Studio interface. You may need to create a Studio instance ("SageMaker domain") if you don't have one already.
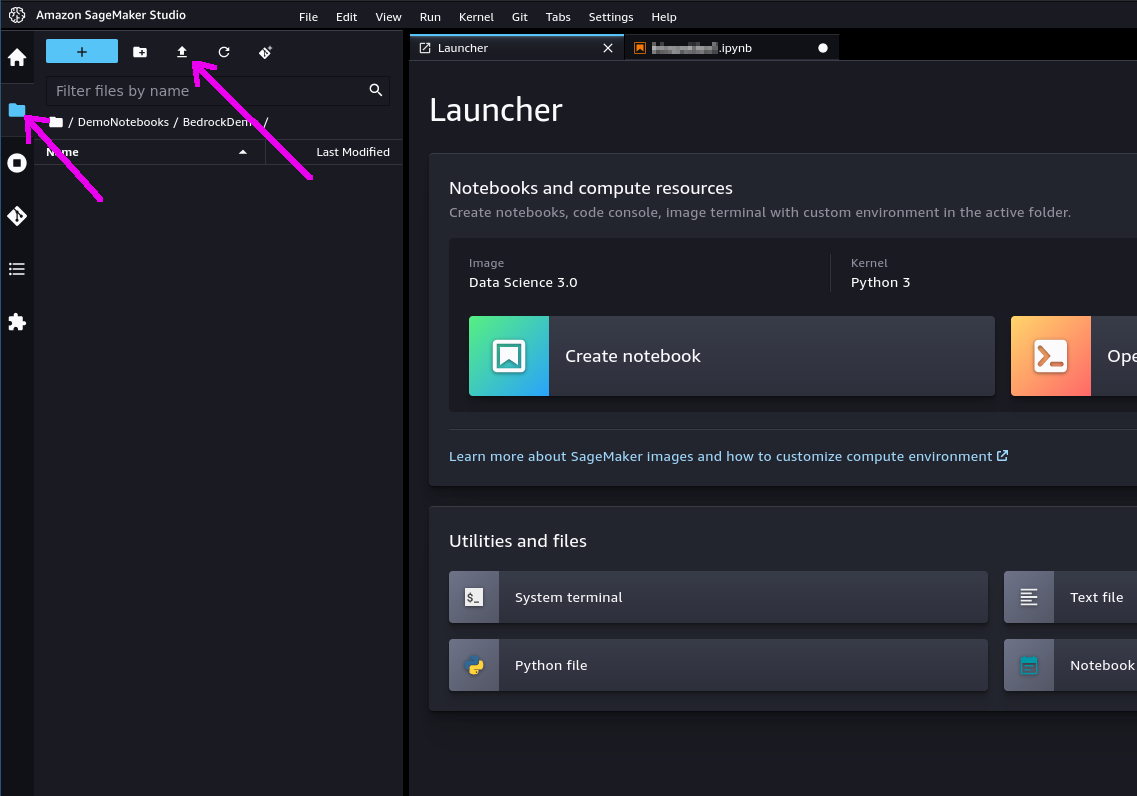
✅ 3.3.d- In the left toolbox of Sagemaker Studio, make sure you select the "File Browser" view and locate the "Upload" button: use it to upload the notebook file you previously saved. The notebook will be shown in the file browser.
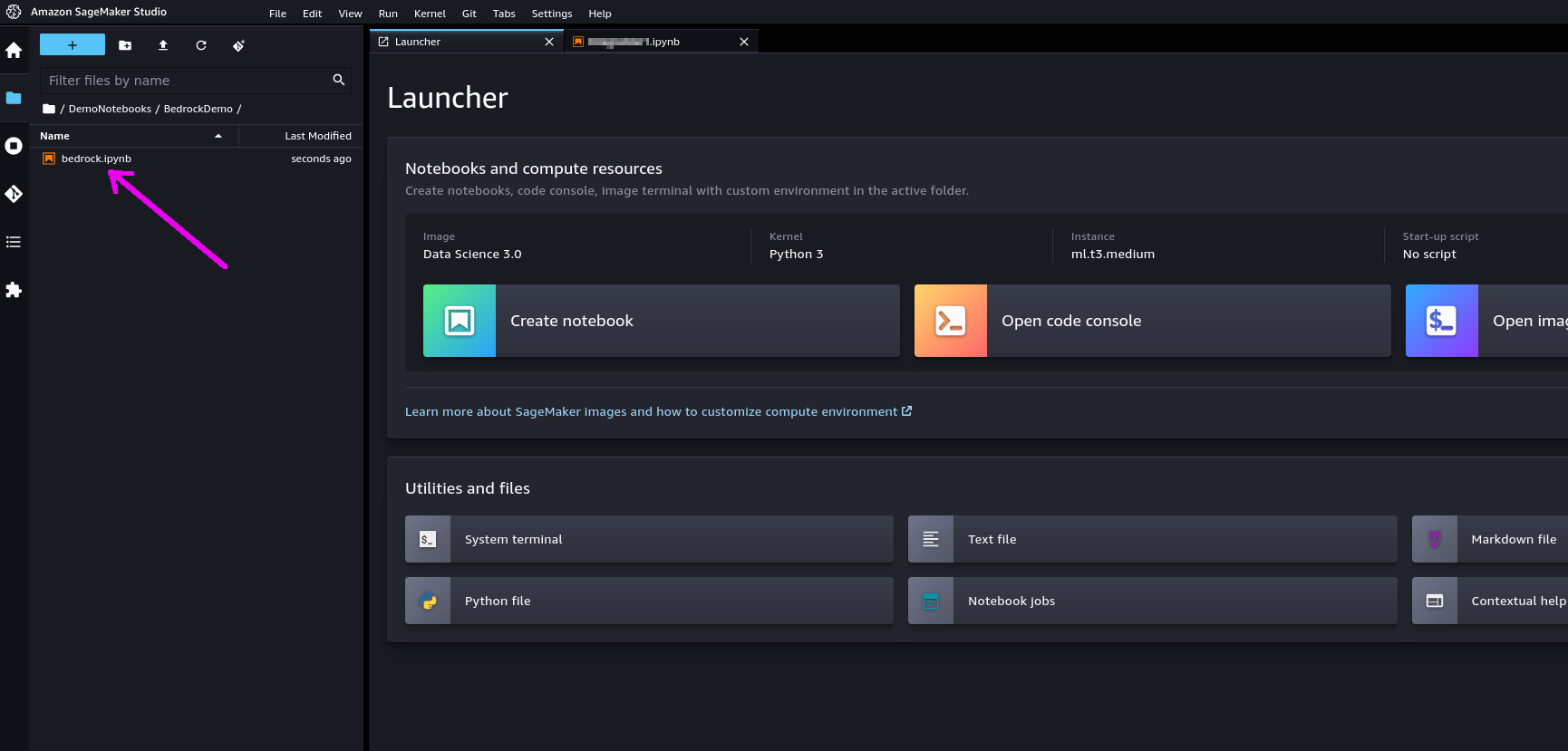
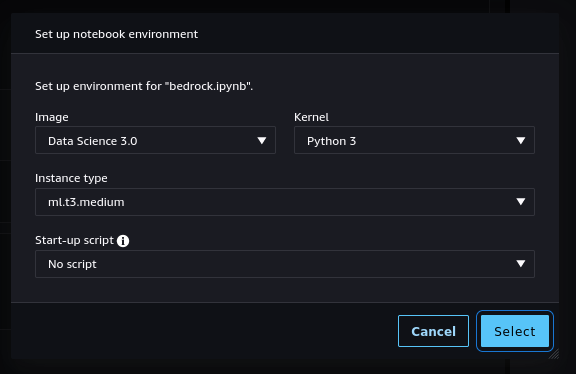
✅ 3.3.e- If you double-click on it, the notebook will be opened in Studio. In order to run it, you will be asked to start a "notebook environment" (essentially, a Python runtime). Choose the "Data Science 3.0" image and a "Python 3" kernel and hit "Select".
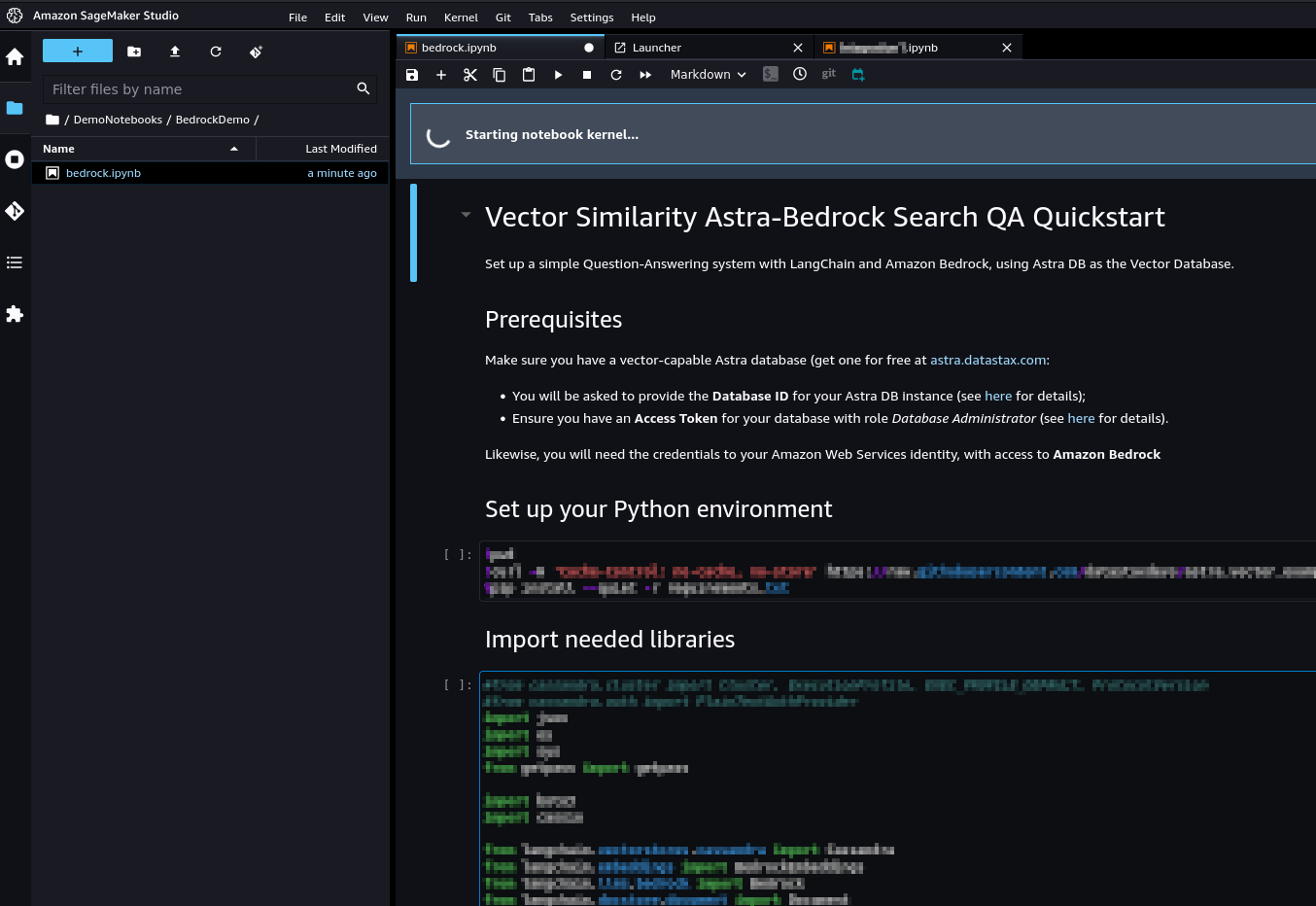
✅ 3.3.f- Once the kernel has fully started, you can run each cell in sequence by clicking on them and pressing Shift+Enter. You will be asked for the secrets during execution.
who die first romeo or Astra ?
✅ 3.4.a- Locate the tabCQL Consoleagain and open the CQL Console
✅ 3.4.b- Validate that the database is created
use default_keyspace;
describe tables;
describe table shakespeare_act5;✅ 3.4.c- Count records after import
clear
select count(*) from shakespeare_act5;✅ 3.4.d- Show content of the table
select row_id,attributes_blob,body_blob,metadata_s from shakespeare_act5 limit 3;
During the above steps, some resources are created, which you may want to cleanly dispose of after you are done.
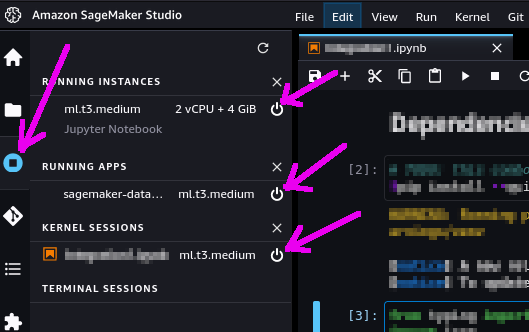
These have been stared to run the notebook itself. You can shut them down from within SageMaker Studio: select the "Running Terminals and Kernels" view on the left toolbar (see picture below) and click the "shut down" icon next to all instances, apps and sessions associated to the notebook you just ran.