{kind=link}
███████╗██╗ ██╗██████╗ ██╗ ██╗██╗███████╗ ██╔════╝██║ ██║██╔══██╗ ██║ ██║██║╚══███╔╝ ███████╗██║ ██║██████╔╝ ██║ █╗ ██║██║ ███╔╝ ╚════██║██║ ██║██╔══██╗ ██║███╗██║██║ ███╔╝ ███████║╚██████╔╝██████╔╝ ╚███╔███╔╝██║███████╗ ╚══════╝ ╚═════╝ ╚═════╝ ╚══╝╚══╝ ╚═╝╚══════╝
A recon tool that uses AI to predict subdomains. Then returns those that resolve.
pip install subwiz
Use subfinder ❤️ to find subdomains from passive sources:
subfinder -d example.com -o subdomains.txt
Seed subwiz with these subdomains:
subwiz -i subdomains.txt
usage: cli.py [-h] -i INPUT_FILE [-o OUTPUT_FILE] [-n NUM_PREDICTIONS]
[--no-resolve] [--force-download] [-t TEMPERATURE]
[-d {auto,cpu,cuda,mps}] [-q MAX_NEW_TOKENS]
[--resolution_concurrency RESOLUTION_LIM]
options:
-h, --help show this help message and exit
-i INPUT_FILE, --input-file INPUT_FILE
file containing new-line-separated subdomains.
(default: None)
-o OUTPUT_FILE, --output-file OUTPUT_FILE
output file to write new-line separated subdomains to.
(default: None)
-n NUM_PREDICTIONS, --num_predictions NUM_PREDICTIONS
number of subdomains to predict. (default: 500)
--no-resolve do not resolve the output subdomains. (default: False)
--force-download download model and tokenizer files, even if cached.
(default: False)
-t TEMPERATURE, --temperature TEMPERATURE
add randomness to the model, recommended ≤ 0.3)
(default: 0.0)
-d {auto,cpu,cuda,mps}, --device {auto,cpu,cuda,mps}
hardware to run the transformer model on. (default:
auto)
-q MAX_NEW_TOKENS, --max_new_tokens MAX_NEW_TOKENS
maximum length of predicted subdomains in tokens.
(default: 10)
--resolution_concurrency RESOLUTION_LIM
number of concurrent resolutions. (default: 128)
Use subwiz in Python, with the same inputs as the command line interface.
import subwiz
known_subdomains = ['test1.example.com', 'test2.example.com']
new_subdomains = subwiz.run(input_domains=known_subdomains)
Use the --no-resolve flag to inspect model outputs without checking if they resolve.
Subwiz is a ultra-lightweight transformer model based on nanoGPT ❤️:
- 17.3M parameters.
- Trained on 26M tokens, lists of subdomains from passive sources.
- Tokenizer trained on same lists of subdomains (8192 tokens).
The model is saved in Hugging Face as HadrianSecurity/subwiz. It is downloaded when you first run subwiz.
Typically, generative transformer models (e.g. ChatGPT) predict a single output sequence. Subwiz predicts the N most likely sequences using a beam search algorithm.
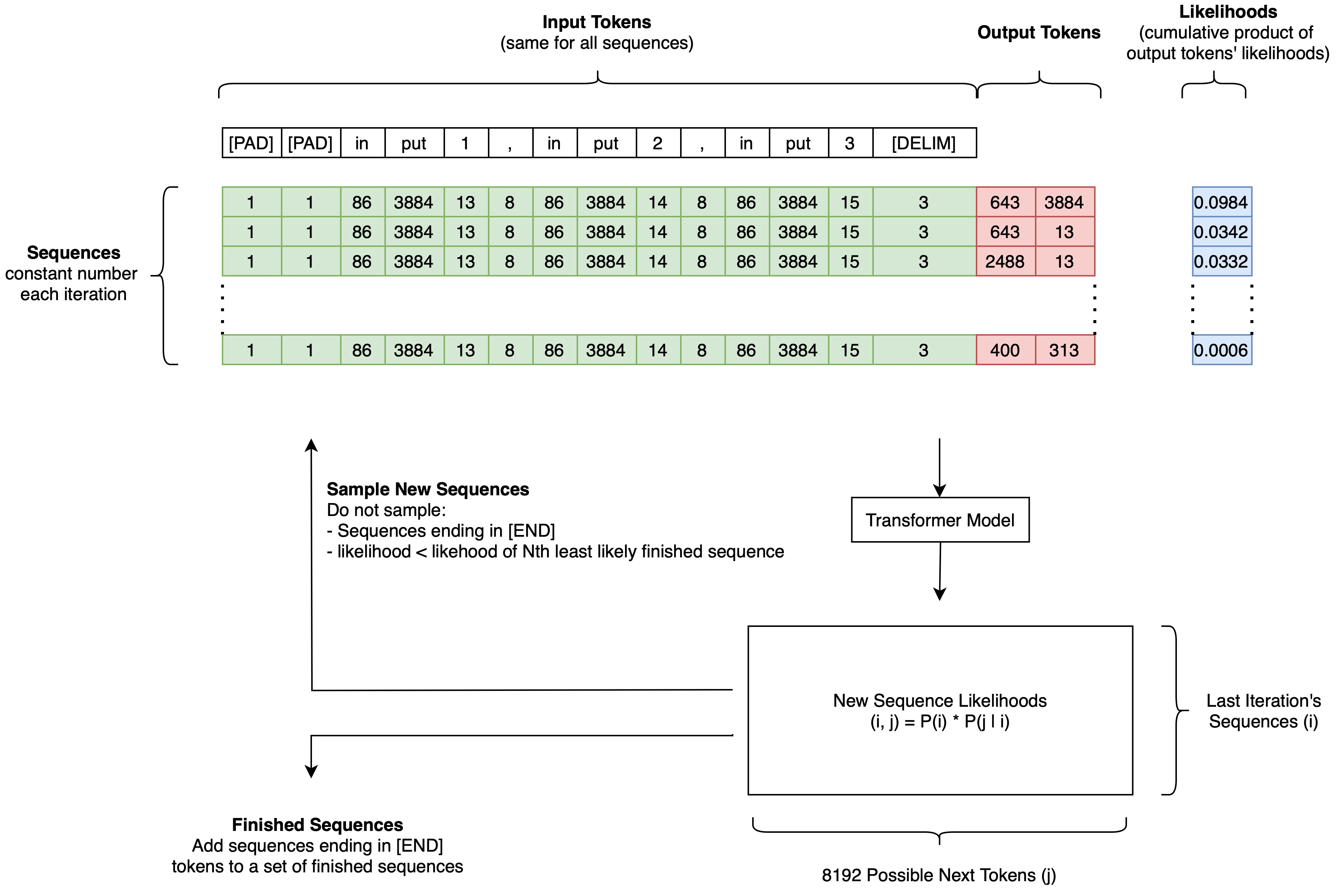
Beam algorithm to predict the N most likely outputs from a generative transformer model.