The project is currently under construction
Papers
| [paper name](paper url)<br/>*authors*<br/>> affiliations<br/>> journal year<br/>> tags<br/>> Cited by (cites num)<br/>> [[code](code url)]<br/>> [[demo](demo url)]<br/>> [[page](page url)] | <div align="center"><img src="main image url" width="300"></div><br/>description |
Datasets
| [dataset name](paper url)<br/>> affiliation<br/> >language<br/>> year<br/>> (categories) categories<br/>> (total images num) images<br/>> resolution | <div align="center"><img src="main image url" width="300"></div><br/>dataset description |
Popular Implementations
| [仓库名称](仓库地址) | [论文名称](论文链接) | 框架 |
Blogs
| [Blog标题](Blog地址) | 作者 | 一句话概括 |- [arXiv 2024] [0] Large Language Models for Captioning and Retrieving Remote Sensing Images João Daniel Silva et al. [paper]
- [arXiv 2024] [0] LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model Dilxat Muhtar et al. [paper][Code]
- [TGRS 2024] [1] EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain W. Zhang et al. [paper][Code]
- [arXiv 2024] [0] H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model Chao Pang et al. [paper][Code]
- [Remote sensing 2024] [0] RS-LLaVA: A Large Vision-Language Model for Joint Captioning and Question Answering in Remote Sensing Imagery Yakoub Bazi et al. [paper][Code]
- [arXiv 2024] [0] SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding Junwei Luo et al. [paper][Code]
- [CVPR 2023] [0] GeoChat: Grounded Large Vision-Language Model for Remote Sensing Kartik Kuckreja et al. [paper][Code]
- [arXiv 2023] [0] RSGPT: A Remote Sensing Vision Language Model and Benchmark Yuan Hu et al. [paper][Code]
- [TGRS 2024] [0] HCNet: Hierarchical Feature Aggregation and Cross-Modal Feature Alignment for Remote Sensing Image Captioning Zhigang Yang et al. [paper][Code]
- [Remote sensing 2024] [1] TSFE: Two-Stage Feature Enhancement for Remote Sensing Image Captioning Guo et al. [paper]
- [TGRS 2024] [0] A Multiscale Grouping Transformer with CLIP Latents for Remote Sensing Image Captioning Meng et al. [paper][Code]
- [TGRS 2022] [28] Remote-Sensing Image Captioning Based on Multilayer Aggregated Transformer Cheng et al. [paper][Code]
- [TGRS 2022] [9] NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning Cheng et al. [paper]
- [TGRS 2022] [6] Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset Liu et al. [paper]
- [TGRS 2022] [2] A Joint-Training Two-Stage Method For Remote Sensing Image Captioning Ye et al. [paper]
- [TGRS 2022] [10] Global Visual Feature and Linguistic State Guided Attention for Remote Sensing Image Captioning Zhang et al. [paper]
- [TGRS 2022] [5] Change Captioning: A New Paradigm for Multitemporal Remote Sensing Image Analysis Hoxha et al. [paper]
- [TGRS 2022] [15] Recurrent Attention and Semantic Gate for Remote Sensing Image Captioning Li et al. [paper]
- [TGRS 2022] [40] High-Resolution Remote Sensing Image Captioning Based on Structured Attention Zhao et al. [paper]
- [TGRS 2022] [22] A Novel SVM-Based Decoder for Remote Sensing Image Captioning Hoxha et al. [paper]
- [ISPRS 2022] [8] Meta captioning: A meta learning based remote sensing image captioning framework Qiao et al. [paper] [code]
- [ISPRS 2022] [4] Generating the captions for remote sensing images: A spatial-channel attention based memory-guided transformer approach Gajbhiye et al. [paper] [code]
- [IJAEOG 2022] [0] Multi-label semantic feature fusion for remote sensing image captioning Zia et al. [paper]
- [TGRS 2021] [42] Truncation Cross Entropy Loss for Remote Sensing Image Captioning Li et al. [paper]
- [TGRS 2021] [35] SD-RSIC: Summarization-Driven Deep Remote Sensing Image Captioning Sumbull et al. [paper][code]
- [TGRS 2021] [43] Word–Sentence Framework for Remote Sensing Image Captioning Wang et al. [paper]
- [GRSL 2020] [45] Denoising-Based Multiscale Feature Fusion for Remote Sensing Image Captioning Huang et al. [paper]
- [Remote Sensing 2019] [26] A Multi-Level Attention Model for Remote Sensing Image Captions Li et al. [paper]
- [TGRS 2019] [57] Sound Active Attention Framework for Remote Sensing Image Captioning Lu et al. [paper]
- [GRSL 2019] [77] Semantic Descriptions of High-Resolution Remote Sensing Images Wang et al. [paper]
- [IEEE Access 2019] [29] VAA: Visual Aligning Attention Model for Remote Sensing Image Captioning Zhang et al. [paper]
- [IGARSS 2019] [30] Multi-Scale Cropping Mechanism for Remote Sensing Image Captioning Zhang et al. [paper]
- [IEEE Access 2019] [32] Exploring Multi-Level Attention and Semantic Relationship for Remote Sensing Image Captioning Yuan et al. [paper]
- [Intelligence Science and Big Data Engineering 2018] [6] Intensive Positioning Network for Remote Sensing Image Captioning Wang et al. [paper]
- [TGRS 2017] [299] Exploring Models and Data for Remote Sensing Image Caption Generation lu et al. [paper]
- [TGRS 2017] [142] Can a Machine Generate Humanlike Language Descriptions for a Remote Sensing Image? Shi et al. [paper]
- [CITS 2016] [145] Deep semantic understanding of high resolution remote sensing image Qu et al. [paper]
| Paper info | Description |
|---|---|
| NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning Qimin Cheng; Haiyan Huang; Yuan Xu; Yuzhuo Zhou; Huanying Li; Zhongyuan Wang > Huazhong University of Science and Technology > TGRS 2022 > Contextual attention, NWPU-Captions> Cited by 58 |
 The paper propose a novel encoder–decoder architecture — multilevel and contextual attention network (MLCA-Net), which improves the flexibility and diversity of the generated captions while keeping their accuracy and conciseness. |
| Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset Chenyang Liu; Rui Zhao; Hao Chen; Zhengxia Zou; Zhenwei Shi > Beihang University > TGRS 2022 > Change captioning (CC), change detection (CD), Transformer> Cited by 71 |
 The paper proposes a novel Transformer-based RSICC (RSICCformer) model, which consists of a CNN-based feature extractor, a dual-branch Transformer encoder (DTE) and a caption decoder. |
| A Joint-Training Two-Stage Method For Remote Sensing Image Captioning Xiutiao Ye; Shuang Wang; Yu Gu; Jihui Wang; Ruixuan Wang; Biao Hou; Fausto Giunchiglia; Licheng Jiao > Xidian University > TGRS 2022 > joint training, multilabel attributes> Cited by 30 |
 A novel joint-training two-stage (JTTS) method improves remote sensing image captioning by integrating multilabel classification for prior information, utilizing differentiable sampling, and employing an attribute-guided decoder. |
| Global Visual Feature and Linguistic State Guided Attention for Remote Sensing Image Captioning Zhengyuan Zhang;Wenkai Zhang;Menglong Yan;Xin Gao;Kun Fu;Xian Sun > Chinese Academy of Sciences > TGRS 2022 > Attention mechanism> Cited by 57 |
 This article proposes a global visual feature-guided attention mechanism for remote-sensing image captioning, which introduces global visual features, filters out redundant components. |
| Change Captioning: A New Paradigm for Multitemporal Remote Sensing Image Analysis Genc Hoxha;Seloua Chouaf;Farid Melgani;Youcef Smara > University of Trento > TGRS 2022 > change detection (CD), support vector machines (SVMs)> Cited by 46 |
 This article proposes change captioning systems that generate coherent sentence descriptions of occurred changes in remote sensing, which utilize convolutional neural networks to extract features and recurrent neural networks or support vector machines to generate change descriptions. |
| Recurrent Attention and Semantic Gate for Remote Sensing Image Captioning Yunpeng Li;Xiangrong Zhang;Jing Gu;Chen Li;Xin Wang;Xu Tang;Licheng Jiao > Xidian University > TGRS 2022 > Attention mechanism, encoder-decoder> Cited by 57 |
 This article introduces a novel RASG framework for remote sensing image captioning, and it utilizes competitive visual features and a recurrent attention mechanism to generate improved context vectors and enhance word representations. |
| High-Resolution Remote Sensing Image Captioning Based on Structured Attention Rui Zhao;Zhenwei Shi;Zhengxia Zou > Beihang University, Beijing > TGRS 2022 > structured attention> Cited by 108 |
 A fine-grained, structured attention-based method is proposed for generating language descriptions of high-resolution remote sensing images, utilizes the structural characteristics of semantic contents and can generate pixelwise segmentation masks without requiring pixelwise annotations. |
| A Novel SVM-Based Decoder for Remote Sensing Image Captioning Genc Hoxha;Farid Melgani > University of Trento > TGRS 2022 > support vector machines (SVMs)> Cited by 52 |
 This article introduces a novel remote sensing image captioning system by using a network of support vector machines (SVMs) instead of recurrent neural networks (RNNs). |
| Meta captioning: A meta learning based remote sensing image captioning framework Qiaoqiao;YangZihao;NiPeng Ren > China University of Petroleum (East China) > ISPRS 2022 > Meta learning> Cited by 8 > [Code] |
 The paper presents a meta captioning framework that utilizes meta learning to address the limitations of remote sensing image captioning, transferring meta features extracted from natural image classification and remote sensing image classification tasks to improve captioning performance with a relatively small amount of caption-labeled training data. |
| Generating the captions for remote sensing images: A spatial-channel attention based memory-guided transformer approach Gaurav O. Gajbhiye;Abhijeet V. Nandedkar > SGGS Institute of Engineering and Technology > ISPRS 2022 > Spatial and channel-wise visual attention, Transformer, Memory guided decoder> Cited by 4 > [Code] |
 A novel fully-attentive CNN-Transformer approach is proposed for automatic caption generation in remote sensing images, integrating a multi-attentive visual encoder and a memory-guided Transformer-based linguistic decoder, with a statistical index to measure the model's ability to generate reliable captions across datasets. |
| Multi-label semantic feature fusion for remote sensing image captioning Usman ZiaM. Mohsin RiazAbdul Ghafoor > National University of Sciences and Technology (NUST), Pakistan > IJAEOG 2022 > > Remote sensing image retrieval,Multi-modal domains> Cited by 0 |
 This paper proposes a model for generating novel captions for remote sensing images by utilizing multi-scale features and an adaptive attention-based decoder with topic-sensitive word embedding. |
| Truncation Cross Entropy Loss for Remote Sensing Image Captioning Xuelong Li;Xueting Zhang;Wei Huang;Qi Wang > Northwestern Polytechnical University > TGRS 2021 > overfitting, truncation cross entropy (TCE) loss> Cited by 83 |
 This article introduces a new approach called truncation cross entropy (TCE) loss to address the overfitting problem in remote sensing image captioning (RSIC), which explores the limitations of cross entropy (CE) loss and proposes TCE loss to alleviate overfitting. |
| SD-RSIC: Summarization-Driven Deep Remote Sensing Image Captioning Gencer Sumbul;Sonali Nayak;Begüm Demir > Technische Universität Berlin > TGRS 2021 > Caption summarization> Cited by 35 > [Code] |
 The novel SD-RSIC approach addresses the issue of redundant information in remote sensing image captioning, which utilizes summarization techniques, adaptive weighting, and a combination of CNNs and LSTM networks to improve the mapping from the image domain to the language domain. |
| Word–Sentence Framework for Remote Sensing Image Captioning Qi Wang;Wei Huang;Xueting Zhang;Xuelong Li > Northwestern Polytechnical University > TRGS 2021 > word–sentence framework> Cited by 83 |
 This article introduces a new explainable word-sentence framework for remote sensing image captioning (RSIC), consisting of a word extractor and a sentence generator. |
| Denoising-Based Multiscale Feature Fusion for Remote Sensing Image Captioning Wei Huang; Qi Wang; Xuelong Li > Northwestern Polytechnical University > GRSL 2020 > encoder–decoder, feature fusion, multiscale> Cited by 72 |
 This paper proposes a denoising-based multi-scale feature fusion (DMSFF) mechanism for remote sensing image captioning, which improves caption quality by addressing the limitations caused by large-scale variation in remote sensing images. Experimental results on two public datasets validate the effectiveness of the proposed method. |
| A Multi-Level Attention Model for Remote Sensing Image Captions Y Li; S Fang; L Jiao; R Liu; R Shang > Xidian University > Remote Sensing 2019 > attention, encoder-decoder> Cited by 48 |
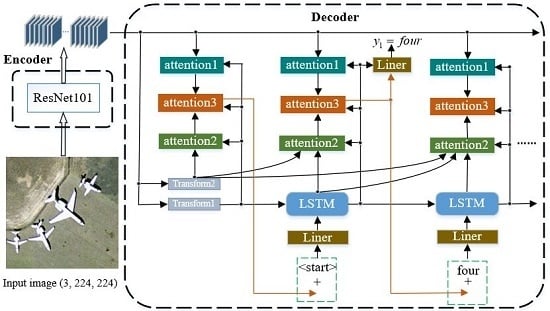 This paper proposes a multi-level attention model for remote sensing image captioning, which mimics human attention mechanisms by incorporating three attention structures for different areas of the image, words, and vision and semantics, achieving superior results compared to previous methods. |
| Sound Active Attention Framework for Remote Sensing Image Captioning Xiaoqiang Lu; Binqiang Wang; Xiangtao Zheng > Chinese Academy of Sciences > TGRS 2019 > sound activate attention> Cited by 83 |
 It proposes a novel sound active attention framework for more specific caption generation according to the interest of the observer. |
| Semantic Descriptions of High-Resolution Remote Sensing Images Binqiang Wang; Xiaoqiang Lu; Xiangtao Zheng; Xuelong Li > University of Chinese Academy of Sciences > GRSL 2019 > semantic embedding, sentence representation> Cited by 113 |
 This paper proposes a framework that uses semantic embedding to measure the image representation and the sentence representation. |
| VAA: Visual Aligning Attention Model for Remote Sensing Image Captioning Zhengyuan Zhang; Wenkai Zhang; Wenhui Diao; Menglong Yan; Xin Gao; Xian Sun > University of Chinese Academy of Sciences > IEEE Access 2019 > Visual Aligning Attention Model> Cited by 38 |
 This paper proposes a Visual Aligning Attention model (VAA) and ensures that attention layers accurately focus on regions of interest. |
| Multi-Scale Cropping Mechanism for Remote Sensing Image Captioning Xueting Zhang; Qi Wang; Shangdong Chen; Xuelong Li > Northwestern Polytechnical University > IGARSS 2019 > multi-scale cropping> Cited by 42 |
 It proposes a training mechanism of multi-scale cropping for remote sensing image captioning in this paper, which can extract more fine-grained information from remote sensing images and enhance the generalization performance of the base model. |
| Exploring Multi-Level Attention and Semantic Relationship for Remote Sensing Image Captioning Zhenghang Yuan; Xuelong Li; Qi Wang > Northwestern Polytechnical University > IEEE Access 2019 > Multi-level attention, Graph convolutional networks> Cited by 48 |
 This paper proposes a remote sensing image captioning framework based on multi-level attention and multi-label attribute graph convolution is proposed to improve the performance from two aspects. |
| Intensive Positioning Network for Remote Sensing Image Captioning Shengsheng Wang; Jiawei Chen; Guagnyao Wang > Jilin University > Intelligence Science and Big Data Engineering 2018 > Intensive positioning network (IPN)> Cited by 7 |
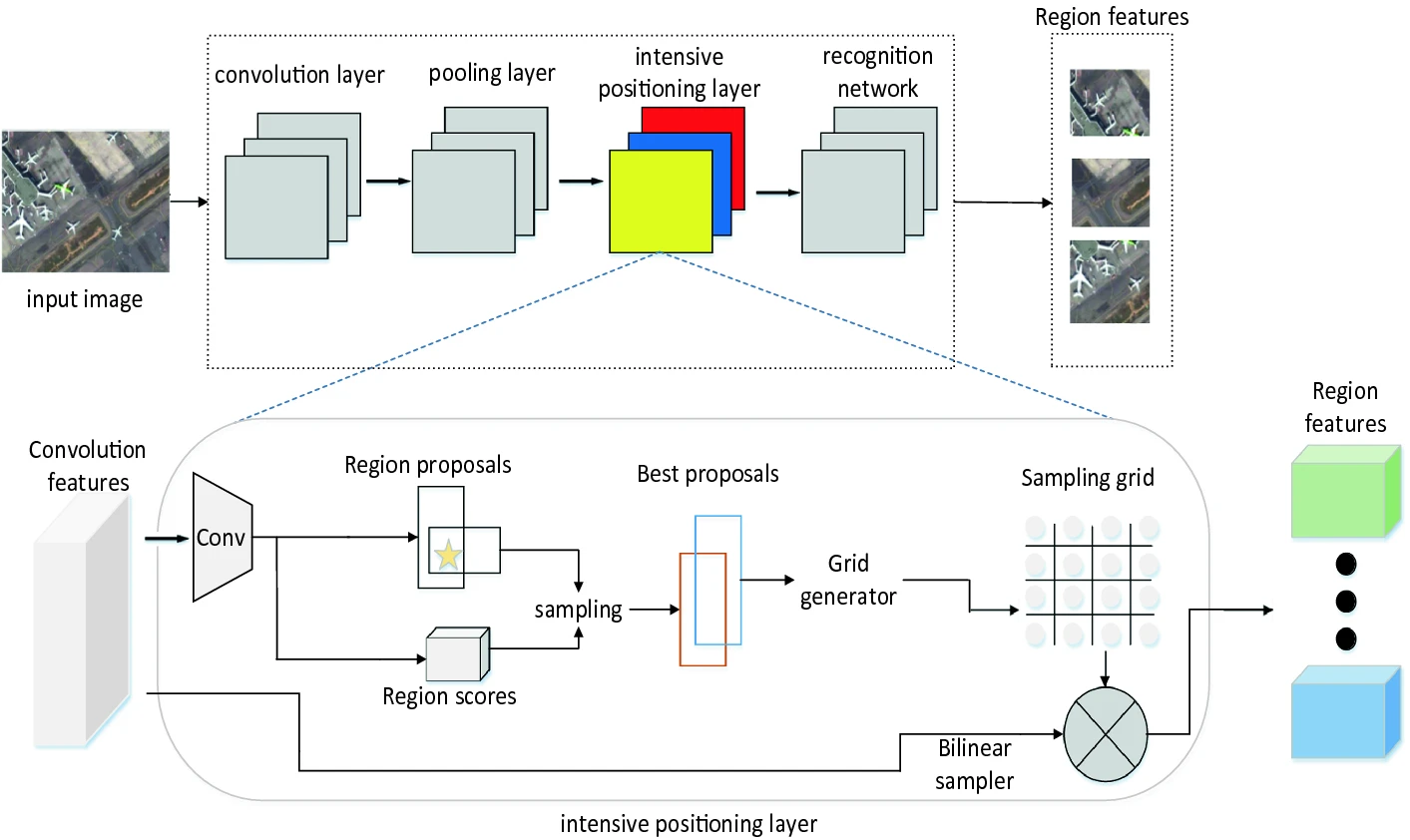 The paper proposes a new network: intensive positioning network (IPN) , which can predict regions containing important information in the picture and output multiple region description blocks around these regions. |
| Exploring Models and Data for Remote Sensing Image Caption Generation Xiaoqiang Lu; Binqiang Wang; Xiangtao Zheng; Xuelong Li > University of Chinese Academy of Sciences > TGRS 2017 > RSICD> Cited by 491 |
 The paper constructs a remote sensing image captioning dataset (RSICD) and evaluates different caption methods based on handcrafted representations and convolutional features on different datasets. |
| Can a Machine Generate Humanlike Language Descriptions for a Remote Sensing Image? Zhenwei Shi; Zhengxia Zou > Beihang University > TGRS 2017 > Fully convolutional networks> Cited by 194 |
 The paper investigates an interesting question of can a machine automatically generate humanlike language description of remote sensing image and proposes a remote sensing image captioning framwork, where the experimental results on Google Earth and GF-2 images have demonstrated the superiority and transfer ability of the proposed method. |
| Deep semantic understanding of high resolution remote sensing image Bo Qu; Xuelong Li; Dacheng Tao; Xiaoqiang Lu > University of the Chinese Academy of Sciences > CITS 2016 > HSR image> Cited by 253 |
 This paper proposes a deep multimodal neural network model to solve the problem of understanding HSR remote sensing images in the semantic level and the VGG19-layers network with LSTMs is the best combination for HSR remote sensing image caption generation. |
| Dataset info | Description |
|---|---|
| NWPU-Captions > Huazhong University of Science and Technology >English > 2022 > 45 categories > 31500 images > 30 m - 0.2 m |
 The NWPU-Captions dataset is a larger and more challenging benchmark dataset for remote sensing image captioning, containing 157,500 manually annotated sentences and 31,500 images, offering a greater data volume, category variety, description richness, and wider coverage of complex scenes and vocabulary. |
| LEVIR-CC > Beihang University >English > 2022 > 10 categories > 10077 images > 0.5 m - 0.5 m |
 The LEVIR-CC dataset is a large-scale dataset designed for the RSICC task, consisting of 10077 pairs of RS images and 50385 corresponding sentences describing image differences. |
| RSICD > University of Chinese Academy of Sciences >English > 2018 > 30 categories > 10921 images |
 It contains more than ten thousands remote sensing images which are collected from Google Earth, Baidu Map, MapABC and Tianditu. |
| Sydney captions > University of the Chinese Academy of Sciences >English > 2016 > 7 categories > 613 images > 0.5m |
 It contains 7 different scene categories and totally has 613 HSR images. |
| UCM captions > University of the Chinese Academy of Sciences >English > 2016 > 21 categories > 2100 images > 0.3048m |
It is based on the UC Merced Land Use Dataset and has 2100 HSR images which are divided into 21 challenging scene categories. |
DataSet: UCM-CAPTIONS
| Method | Year | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|---|
| VLAD-LSTM | 2018 | 0.7016 | 0.6085 | 0.5496 | 0.5030 | 0.3464 | 0.6520 | 2.3131 | -- |
| SIFT-LSTM | 2018 | 0.5517 | 0.4166 | 0.3489 | 0.3040 | 0.2432 | 0.5235 | 1.3603 | -- |
| PCSMLF | 2019 | 0.4361 | 0.2728 | 0.1855 | 0.1210 | 0.1320 | 0.3927 | 0.2227 | -- |
| FC-ATT+LSTM | 2019 | 0.8135 | 0.7502 | 0.6849 | 0.6352 | 0.4173 | 0.7504 | 2.9958 | -- |
| SM-ATT+LSTM | 2019 | 0.8154 | 0.7575 | 0.6936 | 0.6458 | 0.4240 | 0.7632 | 3.1864 | -- |
| Soft Attention | 2019 | 0.7454 | 0.6545 | 0.5855 | 0.5250 | 0.3886 | 0.7237 | 2.6124 | -- |
| Hard Attention | 2019 | 0.8157 | 0.7312 | 0.6702 | 0.6182 | 0.4263 | 0.7698 | 2.9947 | -- |
| Sound-a-a | 2020 | 0.7484 | 0.6837 | 0.6310 | 0.5896 | 0.3623 | 0.6579 | 2.7281 | 0.3907 |
| SAT(LAM) | 2019 | 0.8195 | 0.7764 | 0.7485 | 0.7161 | 0.4837 | 0.7908 | 3.6171 | 0.5024 |
| ADAPTIVE(LAM) | 2019 | 0.8170 | 0.7510 | 0.6990 | 0.6540 | 0.4480 | 0.7870 | 3.2800 | 0.5030 |
| TCE loss-based | 2020 | 0.8210 | 0.7622 | 0.7140 | 0.6700 | 0.4775 | 0.7567 | 2.8547 | -- |
| Recurrent-ATT | 2021 | 0.8518 | 0.7925 | 0.7432 | 0.6976 | 0.4571 | 0.8072 | 3.3887 | 0.4891 |
| GVFGA+LSGA | 2022 | 0.8319 | 0.7657 | 0.7103 | 0.6596 | 0.4436 | 0.7845 | 3.3270 | 0.4853 |
| SVM-D BOW | 2022 | 0.7635 | 0.6664 | 0.5869 | 0.5195 | 0.3654 | 0.6877 | 2.7142 | -- |
| SVM-D CONC | 2022 | 0.7653 | 0.6947 | 0.6417 | 0.5942 | 0.3702 | 0.6877 | 2.9228 | -- |
| MLCA-Net | 2022 | 0.8260 | 0.770 | 0.7170 | 0.6680 | 0.4350 | 0.7720 | 3.240 | 0.4730 |
| Structured attention | 2022 | 0.8538 | 0.8035 | 0.7572 | 0.7149 | 0.4632 | 0.8141 | 3.3489 | -- |
| AJJTTSM | 2022 | 0.8696 | 0.8224 | 0.7788 | 0.7376 | 0.4906 | 0.8364 | 3.7102 | 0.5231 |
DataSet: SYDNEY-CAPTIONS
| Method | Year | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|---|
| VLAD-LSTM | 2018 | 0.4913 | 0.3472 | 0.2760 | 0.2314 | 0.1930 | 0.4201 | 0.9164 | -- |
| SIFT-LSTM | 2018 | 0.5793 | 0.4774 | 0.4183 | 0.3740 | 0.2707 | 0.5366 | 0.9873 | -- |
| CSMLF | 2019 | 0.5998 | 0.4583 | 0.3869 | 0.3433 | 0.2475 | 0.5018 | 0.9378 | -- |
| FC-ATT+LSTM | 2019 | 0.8076 | 0.7160 | 0.6276 | 0.5544 | 0.4099 | 0.7114 | 2.2033 | -- |
| SM-ATT+LSTM | 2019 | 0.8143 | 0.7351 | 0.6586 | 0.5806 | 0.4111 | 0.7195 | 2.3021 | -- |
| Soft Attention | 2019 | 0.7322 | 0.6674 | 0.6223 | 0.5820 | 0.3942 | 0.7127 | 2.4993 | -- |
| Hard Attention | 2019 | 0.7591 | 0.6610 | 0.5889 | 0.5258 | 0.3898 | 0.7189 | 2.1819 | -- |
| Sound-a-a | 2020 | 0.7093 | 0.6228 | 0.5393 | 0.4602 | 0.3121 | 0.5974 | 1.7477 | 0.3837 |
| SAT(LAM) | 2019 | 0.7405 | 0.6550 | 0.5904 | 0.5304 | 0.3689 | 0.6814 | 2.3519 | 0.4038 |
| ADAPTIVE(LAM) | 2019 | 0.7323 | 0.6316 | 0.5629 | 0.5074 | 0.3613 | 0.6775 | 2.3455 | 0.4243 |
| TCE loss-based | 2020 | 0.7937 | 0.7304 | 0.6717 | 0.6193 | 0.4430 | 0.7130 | 2.4042 | -- |
| Recurrent-ATT | 2021 | 0.8000 | 0.7217 | 0.6531 | 0.5909 | 0.3908 | 0.7218 | 2.6311 | 0.4301 |
| GVFGA+LSGA | 2022 | 0.7681 | 0.6846 | 0.6145 | 0.5504 | 0.3866 | 0.7030 | 2.4522 | 0.4532 |
| SVM-D BOW | 2022 | 0.7787 | 0.6835 | 0.6023 | 0.5305 | 0.3797 | 0.6992 | 2.2722 | -- |
| SVM-D CONC | 2022 | 0.7547 | 0.6711 | 0.5970 | 0.5308 | 0.3643 | 0.6746 | 2.2222 | -- |
| MLCA-Net | 2022 | 0.8310 | 0.7420 | 0.6590 | 0.5800 | 0.3900 | 0.7110 | 2.3240 | 0.4090 |
| Structured attention | 2022 | 0.7795 | 0.7019 | 0.6392 | 0.5861 | 0.3954 | 0.7299 | 2.3791 | -- |
| AJJTTSM | 2022 | 0.8492 | 0.7797 | 0.7137 | 0.6496 | 0.4457 | 0.7660 | 2.8010 | 0.4679 |
DataSet: RSICD
| Method | Year | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|---|
| VLAD-LSTM | 2018 | 0.5004 | 0.3195 | 0.2319 | 0.1778 | 0.2046 | 0.4334 | 1.1801 | -- |
| SIFT-LSTM | 2018 | 0.4859 | 0.3033 | 0.2186 | 0.1678 | 0.1966 | 0.4174 | 1.0528 | -- |
| CSMLF | 2019 | 0.5759 | 0.3959 | 0.2832 | 0.2217 | 0.2128 | 0.4455 | 0.5297 | -- |
| FC-ATT+LSTM | 2019 | 0.7459 | 0.6250 | 0.5338 | 0.4574 | 0.3395 | 0.6333 | 2.3664 | -- |
| SM-ATT+LSTM | 2019 | 0.7571 | 0.6336 | 0.5385 | 0.4612 | 0.3513 | 0.6458 | 2.3563 | -- |
| Soft Attention | 2019 | 0.6753 | 0.5308 | 0.4333 | 0.3617 | 0.3255 | 0.6109 | 1.9643 | -- |
| Hard Attention | 2019 | 0.6669 | 0.5182 | 0.4164 | 0.3407 | 0.3201 | 0.6084 | 1.7925 | -- |
| Sound-a-a | 2020 | 0.6196 | 0.4819 | 0.3902 | 0.3195 | 0.2733 | 0.5143 | 1.6386 | 0.3598 |
| SAT(LAM) | 2019 | 0.6753 | 0.5537 | 0.4686 | 0.4026 | 0.3254 | 0.5823 | 2.5850 | 0.4636 |
| ADAPTIVE(LAM) | 2019 | 0.6664 | 0.5486 | 0.4676 | 0.4070 | 0.3230 | 0.5843 | 2.6055 | 0.4673 |
| TCE loss-based | 2020 | 0.7608 | 0.6358 | 0.5471 | 0.4791 | 0.3425 | 0.6687 | 2. 4665 | -- |
| Recurrent-ATT | 2021 | 0.7729 | 0.6651 | 0.5782 | 0.5062 | 0.3626 | 0.6691 | 2.7549 | 0.4719 |
| GVFGA+LSGA | 2022 | 0.6779 | 0.5600 | 0.4781 | 0.4165 | 0.3285 | 0.5929 | 2.6012 | 0.4683 |
| SVM-D BOW | 2022 | 0.6112 | 0.4277 | 0.3153 | 0.2411 | 0.2303 | 0.4588 | 0.6825 | -- |
| SVM-D CONC | 2022 | 0.5999 | 0.4347 | 0.3550 | 0.2689 | 0.2299 | 0.4557 | 0.6854 | -- |
| MLCA-Net | 2022 | 0.7500 | 0.6310 | 0.5380 | 0.4590 | 0.3420 | 0.6380 | 2.4180 | 0.4440 |
| Structured attention | 2022 | 0.7016 | 0.5614 | 0.4648 | 0.3934 | 0.3291 | 0.5706 | 1.7031 | -- |
| AJJTTSM | 2022 | 0.7893 | 0.6795 | 0.5893 | 0.5135 | 0.3773 | 0.6823 | 2.7958 | 0.4877 |
DataSet: NWPU-CAPTIONS
| metrics | sota | method | paper |
|---|---|---|---|
| BLEU-1 | 0.745 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| BLEU-2 | 0.624 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| BLEU-3 | 0.541 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| BLEU-4 | 0.478 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| METEOR | 0.337 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| ROUGE | 0.601 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
| CIDEr | 1.264 | MLCA-Net | NWPU-Captions Dataset and MLCA-Net for Remote Sensing Image Captioning |
DataSet: LEVIR-CC
| metrics | sota | method | paper |
|---|---|---|---|
| BLEU-1 | 0.8481 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| BLEU-2 | 0.7639 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| BLEU-3 | 0.6914 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| BLEU-4 | 0.6307 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| METEOR | 0.3961 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| ROUGE | 0.7418 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| CIDEr | 1.3468 | RSICCformer | Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset |
| Title | Author | Overview |
|---|---|---|
| illustrated-transformer | Jay Alammar | Visualize the principle of the Transformer |
| visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention | Jay Alammar | Visualize the principle of the Machine Translation |