Have you watched Mike Boyd’s channel on youtube?. Mike, as he likes to put it, is an average guy that tries to learn skills like juggling, stacking dice, and others while recording himself until he / masters the task at hand. On one of this challenges, he tries to learn QWOP (http://www.foddy.net/Athletics.html) a game (writen by Bennett Foddy) in which there are four input buttons Q,W,O,P that control tighs and calves of an infuriating runner on a 100 meter track. As simple as it might seem, reaching the 100 meter mark took Mike approximately 8 hours.
Inspired by this video, the following is an attempt to code an agent using reinforcement learning that reaches consistently the 100 meter mark with under 8 hours of training.
Before we dig into the approach, here’s what I found to be the most useful writeup about getting started with reinforcement learning and an example of what is used in this project.
http://karpathy.github.io/2016/05/31/rl/
And a lecture about it here: https://www.youtube.com/watch?v=tqrcjHuNdmQ
Besides that here this are some useful resources to get started with RL.
As usual, some leg work is required in order to have a runnable environment. The first thing is figuring out a way to run the game reliably without the need to make requests to the official site that hosts the game. Unfortunately, I found no way of getting the javascript code that runs the game (read: I didn't try hard enough), and instead had to cope with the flash player version. The .swf (flash format) can be embedded in a browser testing environment, like selenium, after setting some obscure chrome flags that enable playing flash multimedia.
To run the game in a local server:
cd game
npm i
node server
With the game running on demand and with less delay, the environment should have the ability to return at least, and as is usual in openAIs gym environments, an observation, a score, and a way to determine if the current game has reached an end state. Obtaining the observation, that is, the raw pixels of the current frame of the game can be accomplished in several ways such as using the native selenium take_screenshot which turns out to be extremely slow, in the order of 1.6 ms between each frame (less than a frame per second), consider that 60 FPS is approximately 0.016 ms between each frame. After discarding this method, taking a screenshot using the mss library seems to be the more sensible choice. The only issue is that I had to hard code the position of the game in my screen hence ruining the ability to reliably reproducing the code without this parameter being tweaked. With mss taking the screenshot, frames were taken every ~0.006s (166 FPS!!).
Reinforcement learning is all about rewards, rewards are based on the game scoring system, in the QWOP case the distance score should somehow be related to distance and if possible time and running style. In order to get the score in this setup, pixel data on top of the screen (see picture 1) must be interpreted as text. There are multiple ways of achieving this, for instance training another neural net to overfit score image data. It sounded like a fancy option until I realized that it would be no different than comparing each pixel of every attainable score with a very nasty for loop 😒. What I did instead was to use the pytesseract library that implements OCR.
Doing OCR with Tesseract also implied some bit of pre processing. Long story short, I needed an image with at least 300dpi and also that the image to be processed had to have black characters with a white background. This last thing showed to be extremely important for Tesseract, here's a comparisson.
Detecting when the game has reached an end state was as simple as recognizing the end score screen, for this, a simple comparison of 16 indexes did the job.
To run the agent with random actions use:
cd agent
pip install requirements.txt
python3 RandomRunner.py
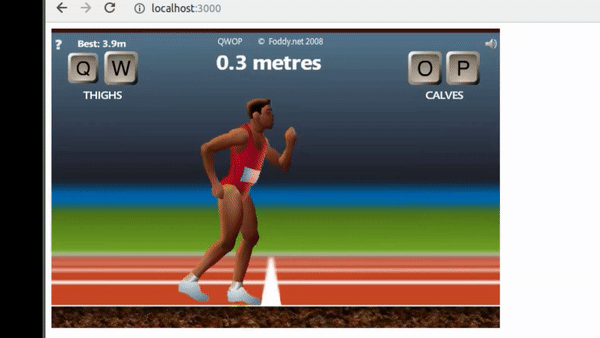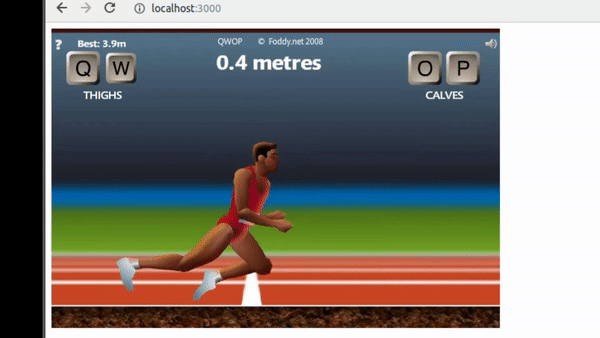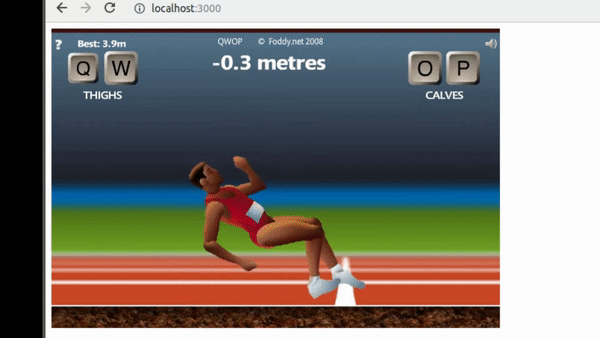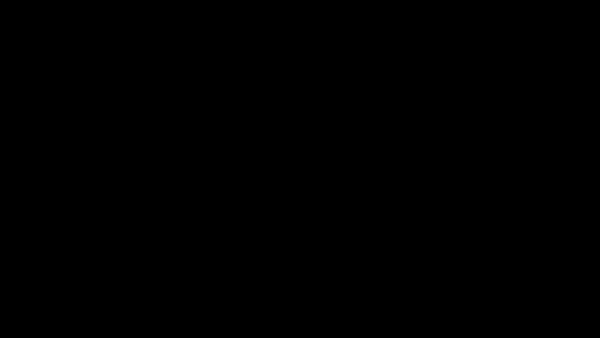
Once the game environment was stable enough, the approach was to implement a 1 layer policy network to start tuning hyperparameters.
The output was a softmax function with 5 outputs encoding the regular Q,W,O,P and the "do nothing" action.
The results were not satisfactory, it samples the policy correctly but improvements do not capture efficient running mechanics.
Hyper params used:
| Parameter | Value |
|---|---|
| hidden layer units | 200 |
| gamma | 0.99 |
| learning rate | 1e-3 |
Knee scraping policy:
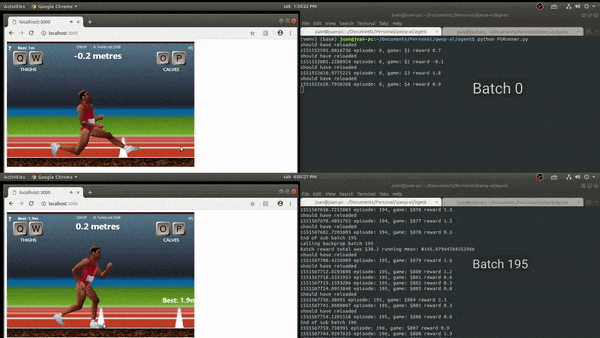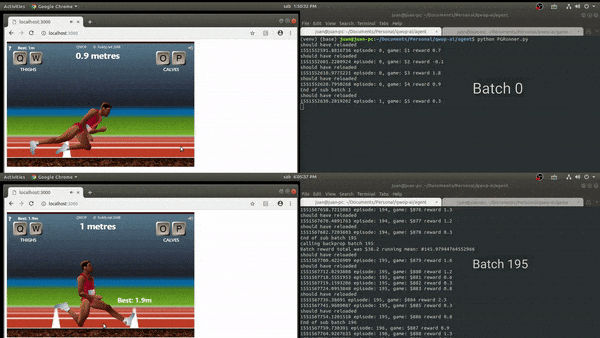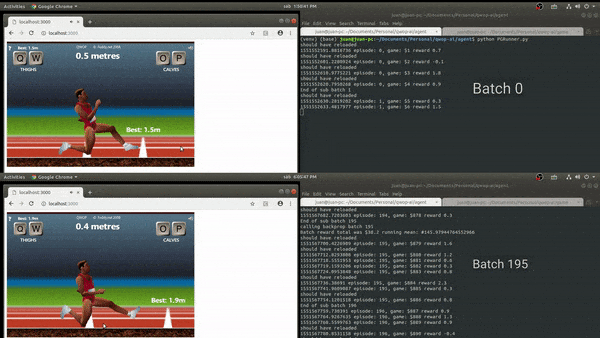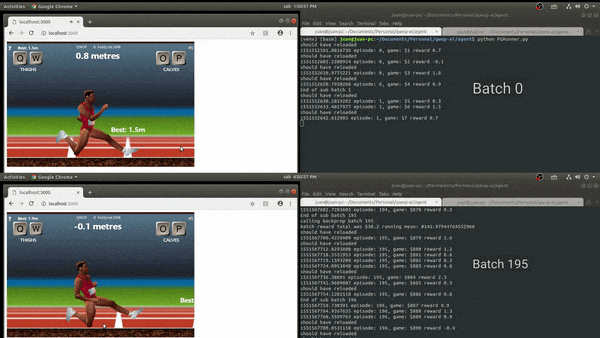
Although the output of the training was not what I expected, in comparison to other attempts to automate QWOP, the knee scraping pose is a common factor.
For reference, here are some other projects with the same goal that ended up learning similar mechanics.
Genetic algorithms:
- Uses QWOP direct interaction instead of a model
- Explains the knee scraping pose as a stability gene
Stanford CS229 Project: QWOP Learning
- Models QWOP with their own ragdoll physics engine
- Uses value iteration to improve base on rewards
There are plenty of issues that can produce this kind of outcome for instance sparse rewards or insufficient input representation.
...