{kind=link}
Capillary is a small web application that displays the state and deltas of Kafka-based storm topologies with a Kafka >= 0.8. It also provides an API for fetching this information for monitoring purposes.
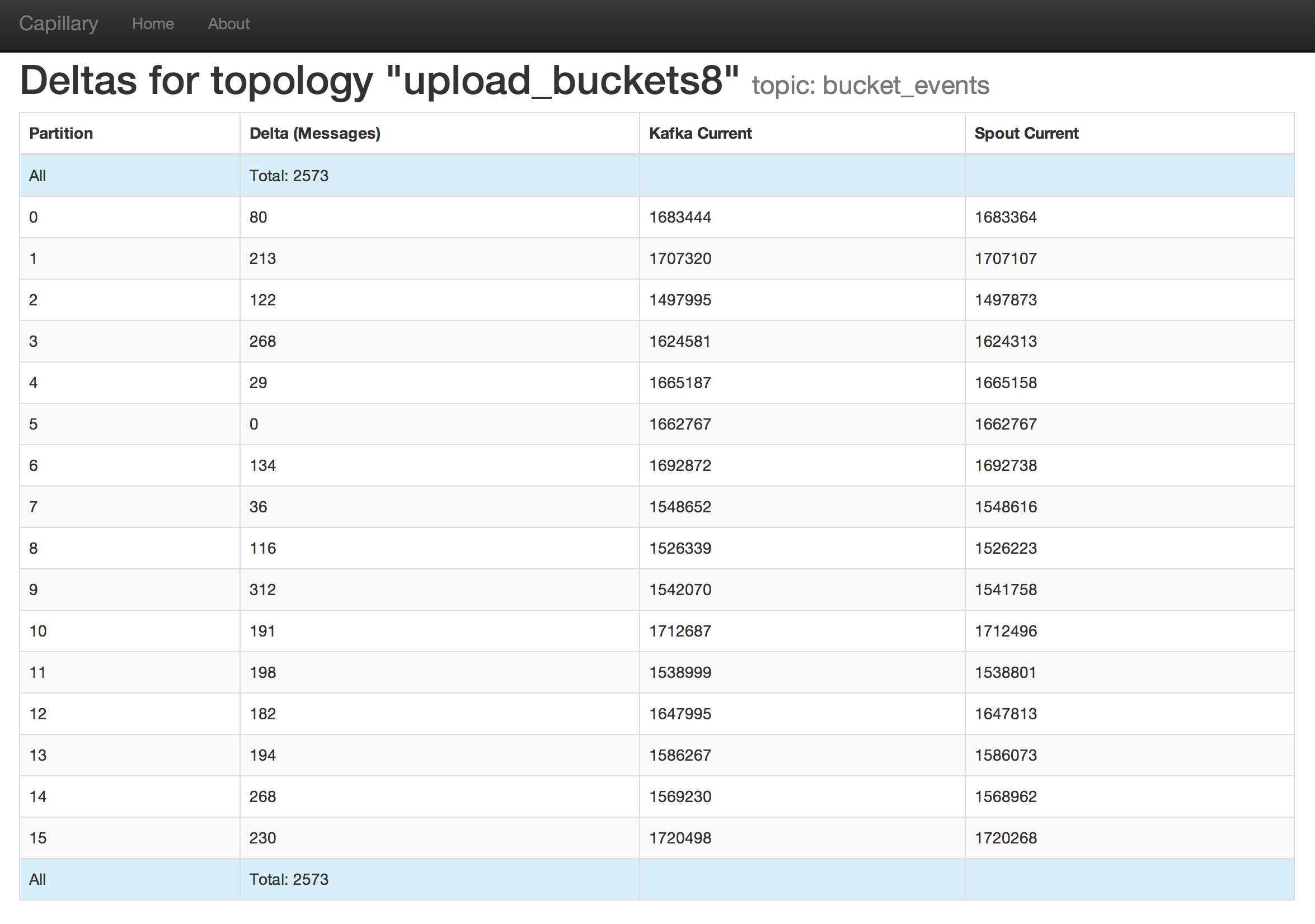
Capillary does the following:
- Fetches information about running topologies from Zookeeper
- Fetches information about the topic's partitions and offsets from the Storm spout state in Zookeeper
- Fetches information about the partition's leaders from Zookeeper
- Fetches information from Kafka about the latest offset from the partitions leaders
- Optionally displays messages from Kafka.
You can hit /api/status?toporoot=$TOPOROOT&topic=$TOPIC to get a JSON output.
At Keen IO we name our projects after plants. Services often use tree or large plant names and large infrastructure projects may use more general names.
Capillary action moves water through a plant's xylem. Since Kafka and Storm handle the flow of data (water) through our infrastructure this seems a fitting name!
Wanna run it? Awesome! This is a Play Framework app so it works the way all other Play apps do:
$ sbt universal:package-zip-tarball
… lots of crazy computer talk …
[success] Total time: 4 s, completed Aug 8, 2014 2:04:06 PM
You should find a tarball at target/universal/capillary-VERSION.tgz.
That there tgz file can be untarballerated (or whatever the technical term is for that) and run like so:
tar xzf capillary-1.2.tgz
cd capillary-1.2
bin/capillary
Play server process ID is 24223
[info] play - Application started (Prod)
[info] play - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
Then you can hit that URL via your web browser with some args:
http://127.0.0.1:9000
Capillary will try and dig information out of Zookeeper to show what topologies you have running.
By way of Play Capillary uses Typesafe Config so you have lots of options.
Most simply you can specify properties when starting the app or include conf/application-local.conf at runtime. Here's our runtime properties:
bin/capillary -Dcapillary.zookeepers=sj01-prod-zk-0000:2181,sj01-prod-zk-0001:2181,sj01-prod-zk-0002:2181 -Dcapillary.kafka.zkroot=kafka8 -Dcapillary.storm.zkroot=keen_storm
Here are the configuration options:
Set this to a list of your ZKs like every other ZK thingie it uses something like host1:2181,host2:2181.
If your Kafka chroots to a subdirectory (or whatever it's called) in Zookeeper then you'll want to set this. We use 'kafka8' after upgrading from 0.7.
If your Storm chroots to a subdirectory (or whatever it's called) in Zookeeper then you'll want to set this. We use 'keen-storm'.
Set this to a list of your Kafkas (looks like: sjc01-staging-kafka-0000:9092,sjc01-staging-kafka-0001:9092,sjc01-staging-kafka-0002:9092,sjc01-staging-kafka-0003:9092,sjc01-staging-kafka-0004:9092)
- Uses Scala 2.10.4 because Kafka (at the time of this writing) doesn't have 2.11 artifacts and explodes
- Doesn't use watches, so updates every time you refresh the page
Storm's Kafka spout stores it's committed state in a ZK structure like this:
/$SPOUT_ROOT/$CONSUMER_ID/$PARTITION_ID
Each $PARTITION_ID stores state as a JSON object that looks like:
{
"topology": {
"id": "$SOME_UNIQUE_ID",
"name": "$TOPOLOGY_NAME"
},
"offset": $CURRENT_OFFSET,
"partition": $PARTITION_NUMBER,
"broker": {
"host": "$HOST_ADDRESS",
"port": 9092
},
"topic": "$TOPIC_NAME"
}