在笔者心中,消息队列,缓存,分库分表是高并发解决方案三剑客。
分库分表之所以被广泛使用,因为工程相对简单,但分库分表并不仅仅是分片,还是需要考虑如何扩缩容(全量同步、增量同步、数据校验等)。

因此笔者做了一个教学型分库分表示例项目 ,计划将分库分表的技术体系都实际演示一遍。
当前项目包含三个模块 :
- shardingjdbc4-spring:使用 shardingsphere-JDBC 4.X 实现分库分表功能
- shardingjdbc5-spring:使用 shardingsphere-JDBC 5.X 实现分库分表功能
- idgenerator: 基于 grpc 实现一个简单的服务端 ID 生成器
本文档重点讲解 shardingsphere JDBC 4.x 如何整合 spring。
笔者曾经为武汉一家 O2O 公司订单服务做过分库分表架构设计 ,当企业用户创建一条采购订单 , 会生成如下记录:
-
订单基础表 t_ent_order :单条记录
-
订单详情表 t_ent_order_detail :单条记录
-
订单明细表 t_ent_order_item:N 条记录
订单每年预估生成记录 1 亿条,数据量不大也不小,笔者参考原来神州专车的分库分表方式,制定了如下的分库分表策略:
- 订单基础表按照 ent_id (企业用户编号) 分库(四个分库),订单详情表保持一致。
- 订单明细表按照 ent_id (企业用户编号) 分库 (四个分库),同时也要按照 ent_id (企业编号) 分表(八个分表)。
创建 4 个库,分别是:ds_0、ds_1、ds_2、ds_3 。
然后这四个分库分别执行 doc 目录下的 shardingjdbc-spring.sql 文件。
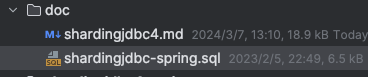
执行结果如下图所示,每个分库都包含订单基础表 , 订单详情表 ,订单明细表 。但是因为明细表需要分表,所以包含多张表。
打开项目,如下图所示:
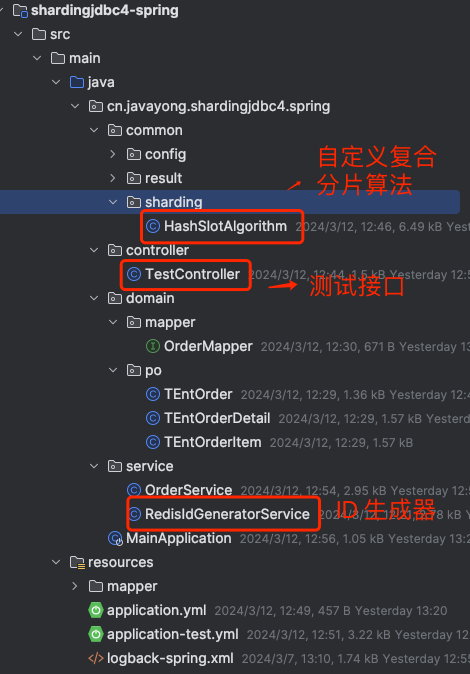
这是一个典型的 springboot 项目,包含控制器层、实体层、服务层 。
1、pom 文件配置依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>2、分片配置 application-test.yml
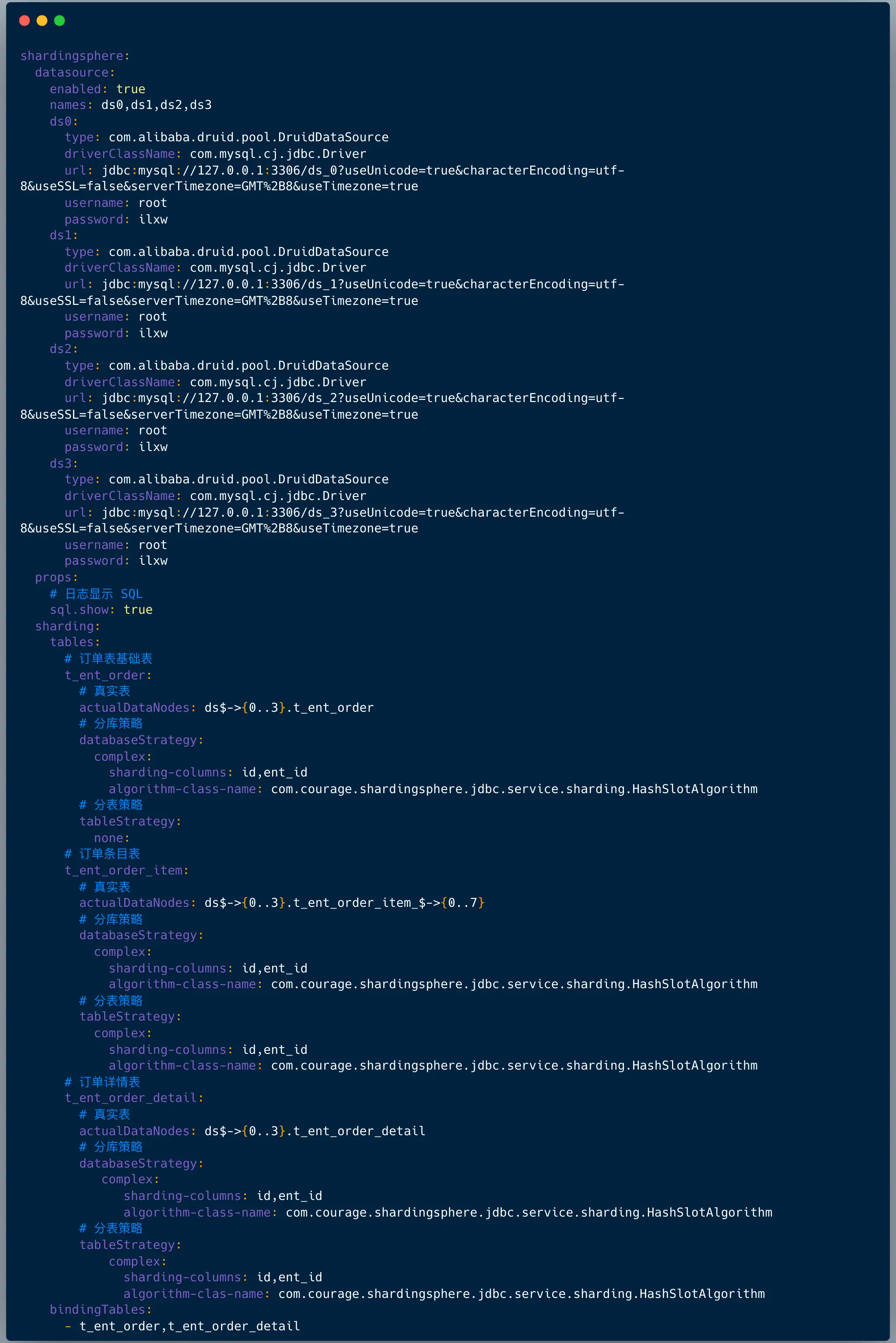
- 配置数据源,上面配置数据源是: ds0、ds1、ds2、ds3 ;
- 配置打印日志,也就是:sql.show ,在测试环境建议打开 ,便于调试;
- 配置哪些表需要分库分表 ,在 shardingsphere.datasource.sharding.tables 节点下面配置:

上图中我们看到配置分片规则包含如下两点:
1.真实节点
对于我们的应用来讲,我们查询的逻辑表是:t_ent_order_item 。
它们在数据库中的真实形态是:t_ent_order_item_0 到 t_ent_order_item_7。
真实数据节点是指数据分片的最小单元,由数据源名称和数据表组成。
订单明细表的真实节点是:ds$->{0..3}.t_ent_order_item_$->{0..7} 。
2.分库分表算法
分别配置分库策略和分表策略 , 每种策略都需要配置分片字段( sharding-columns )和分片算法。
修改配置文件 application-test.yml ,配置好 MySQL 数据库 和 Redis 服务 。
启动 Main 函数:
启动过程中,会打印 shardingsphere jdbc 日志 。
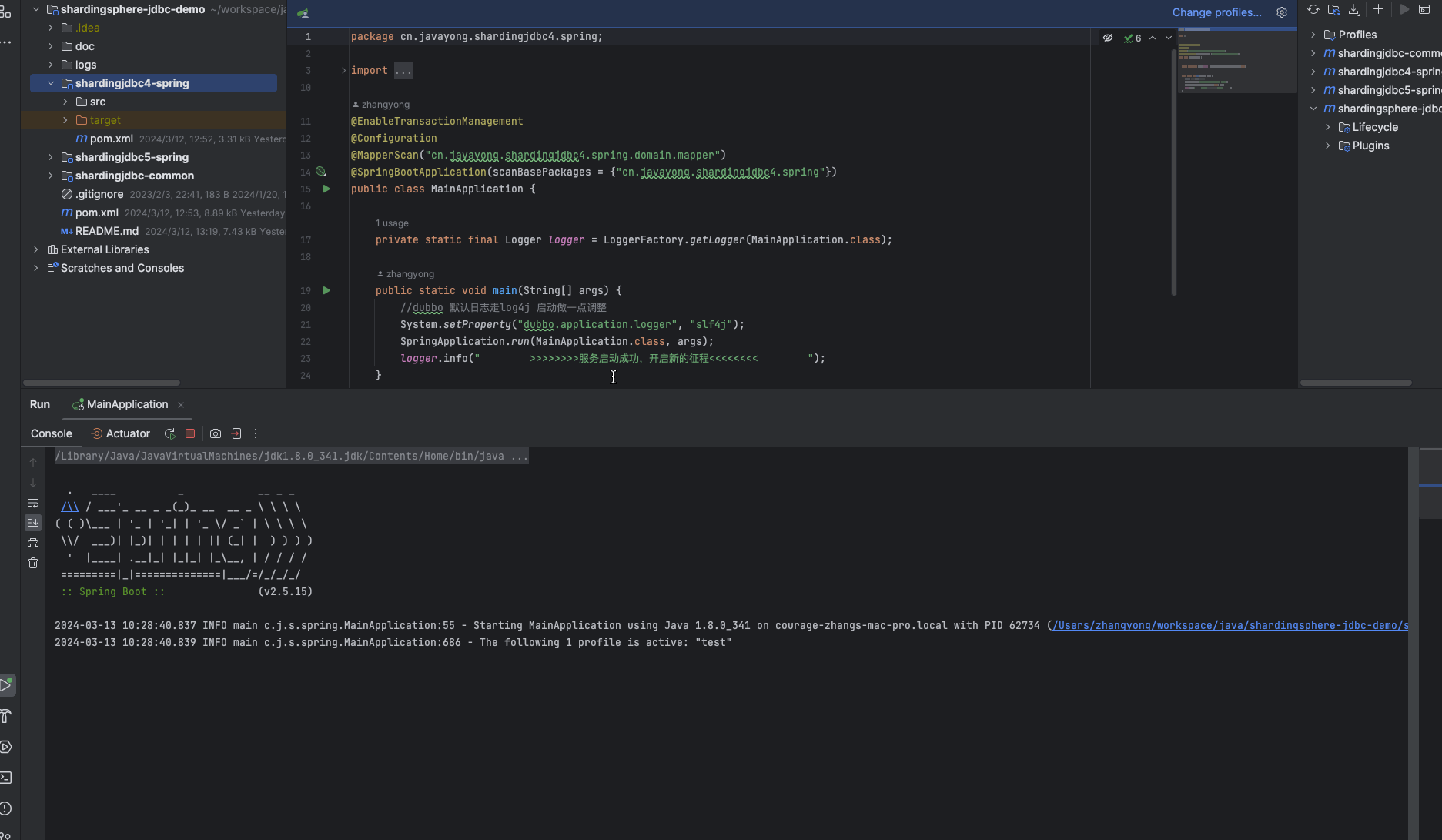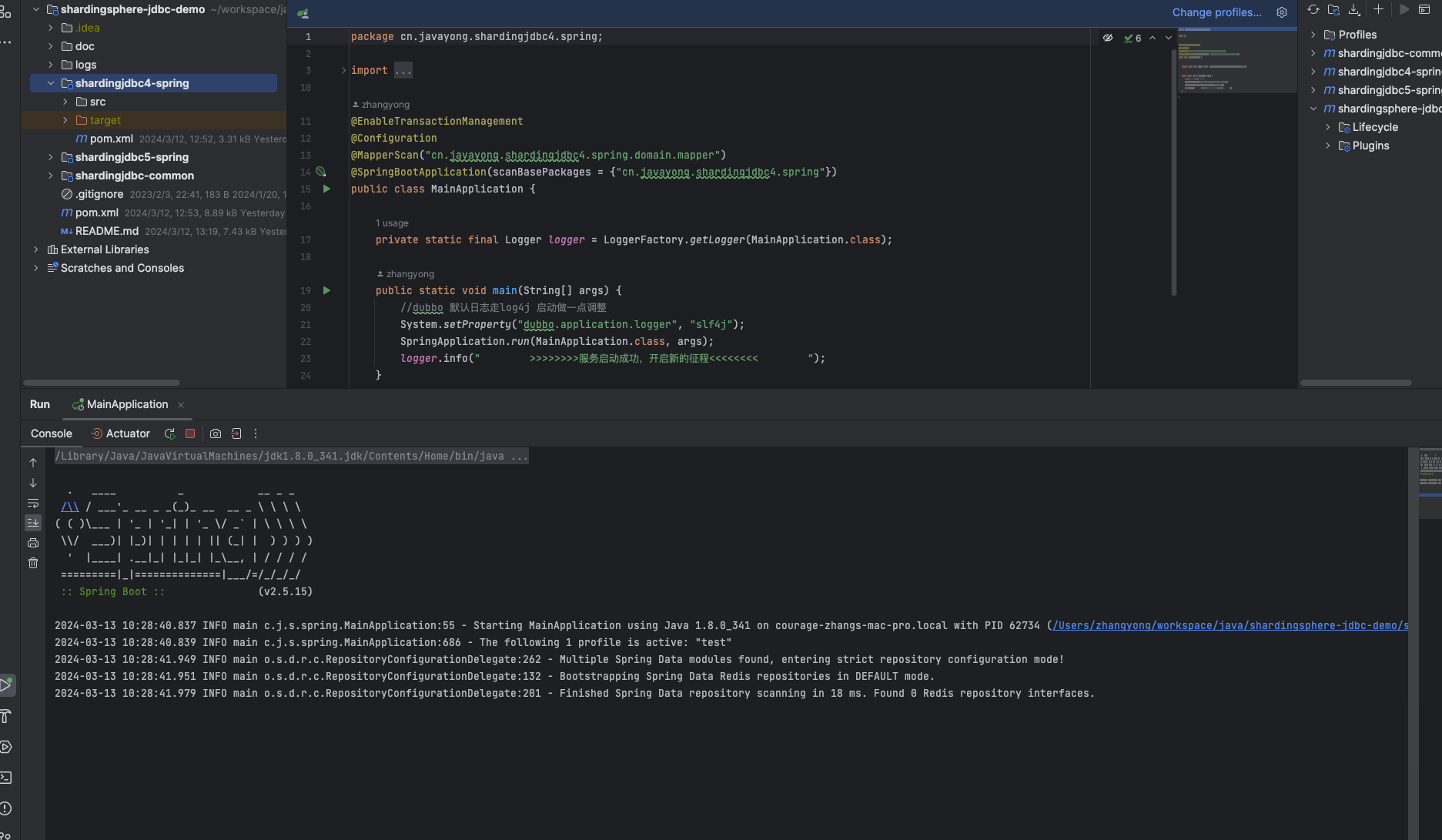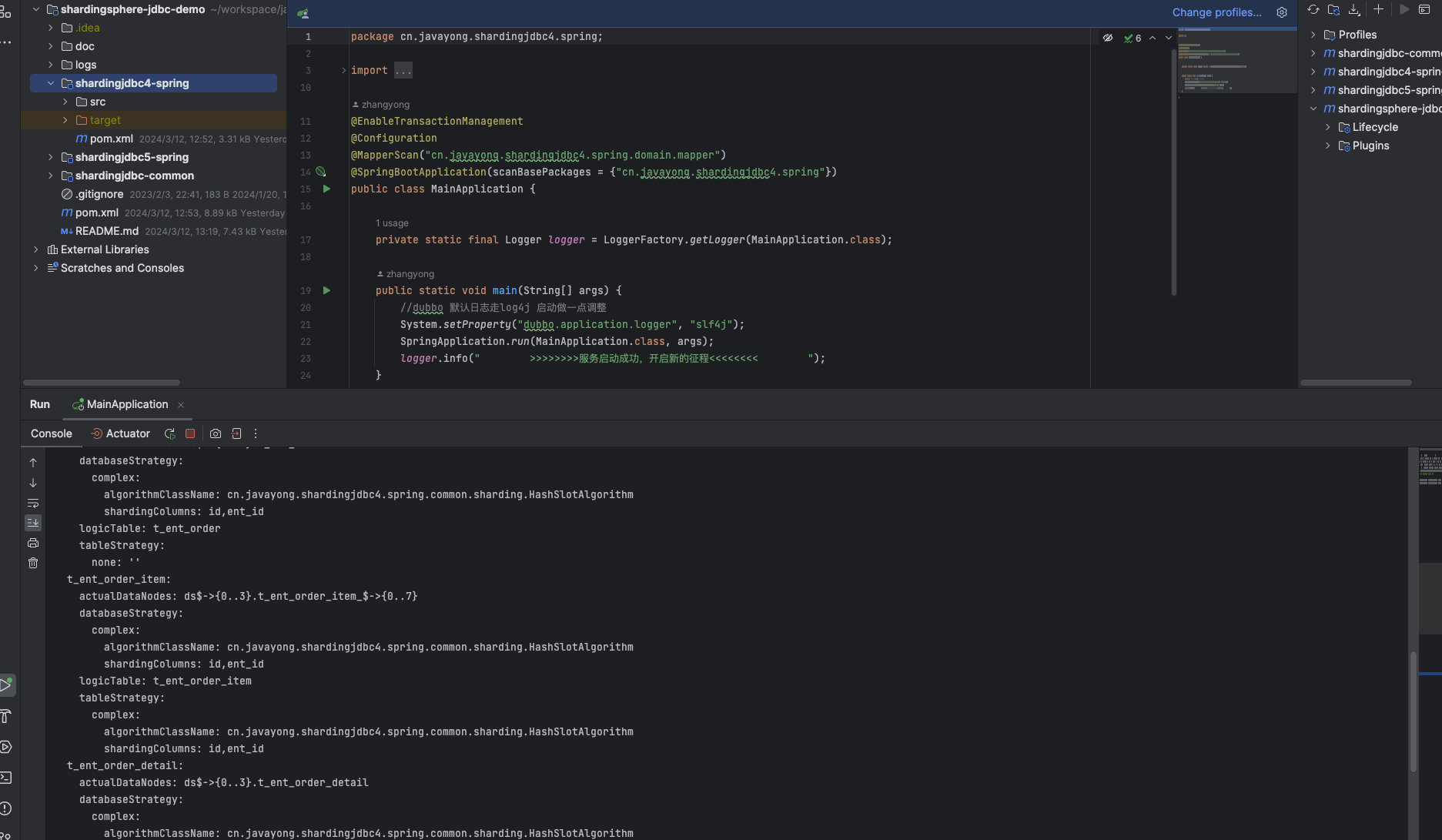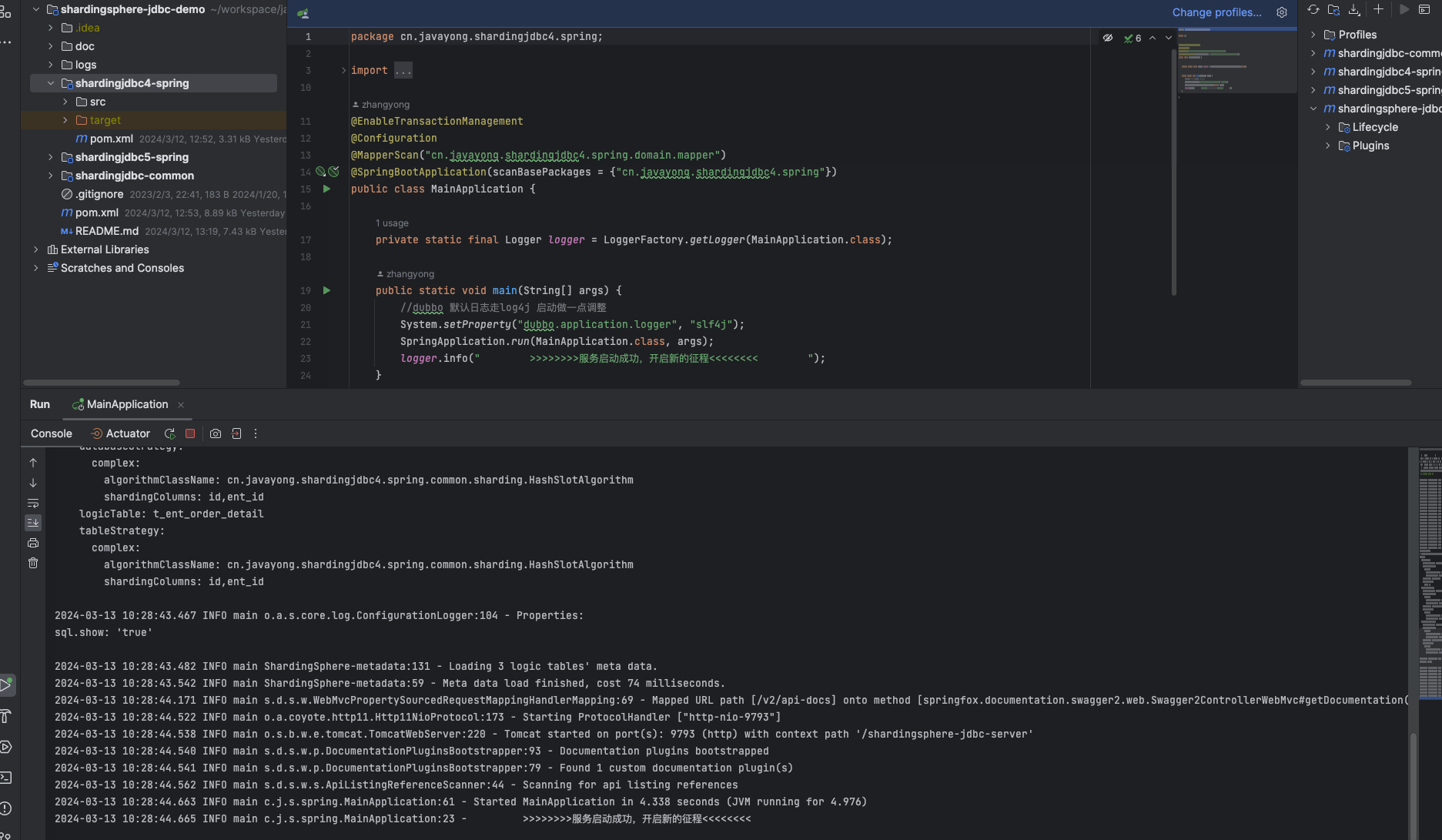
启动成功之后,访问 swagger ui 地址:
http://localhost:9793/shardingsphere-jdbc-server/doc.html#/home
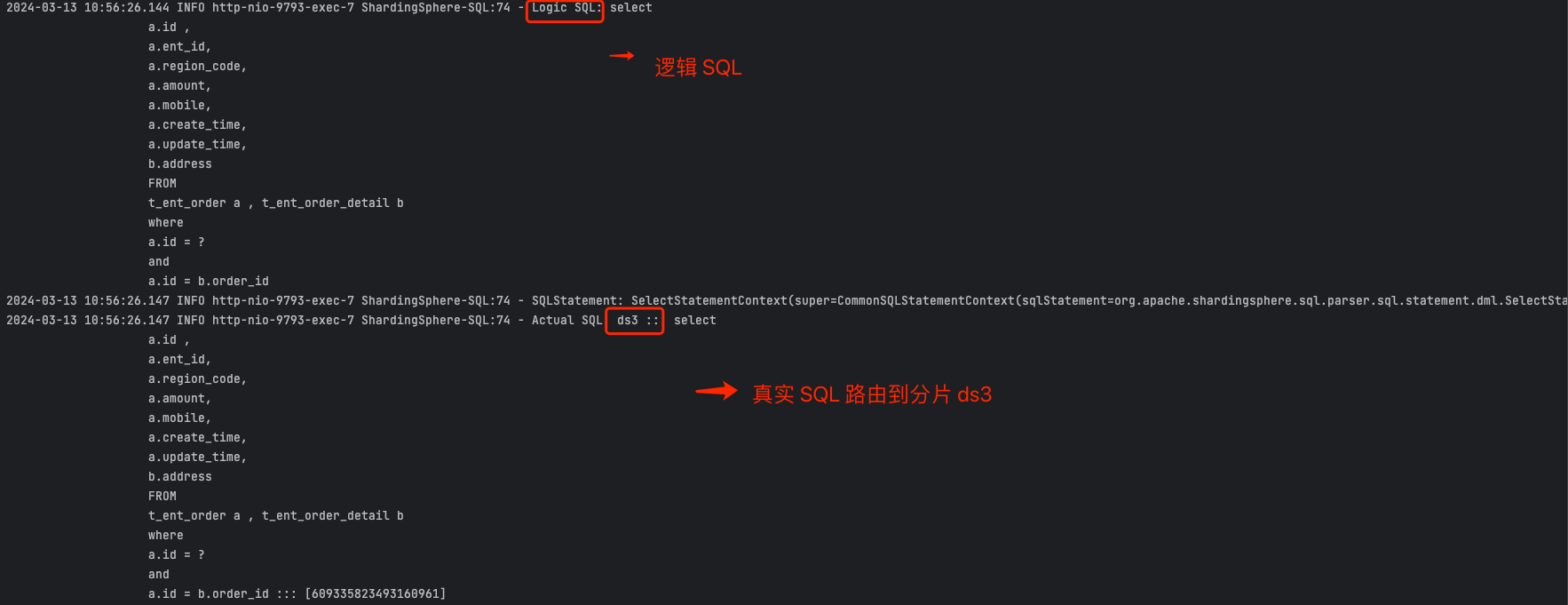
接下来,我们进行两个测试:新增订单和按照订单 ID 查询
1、测试存储订单

点击发送按钮,接口响应成功。
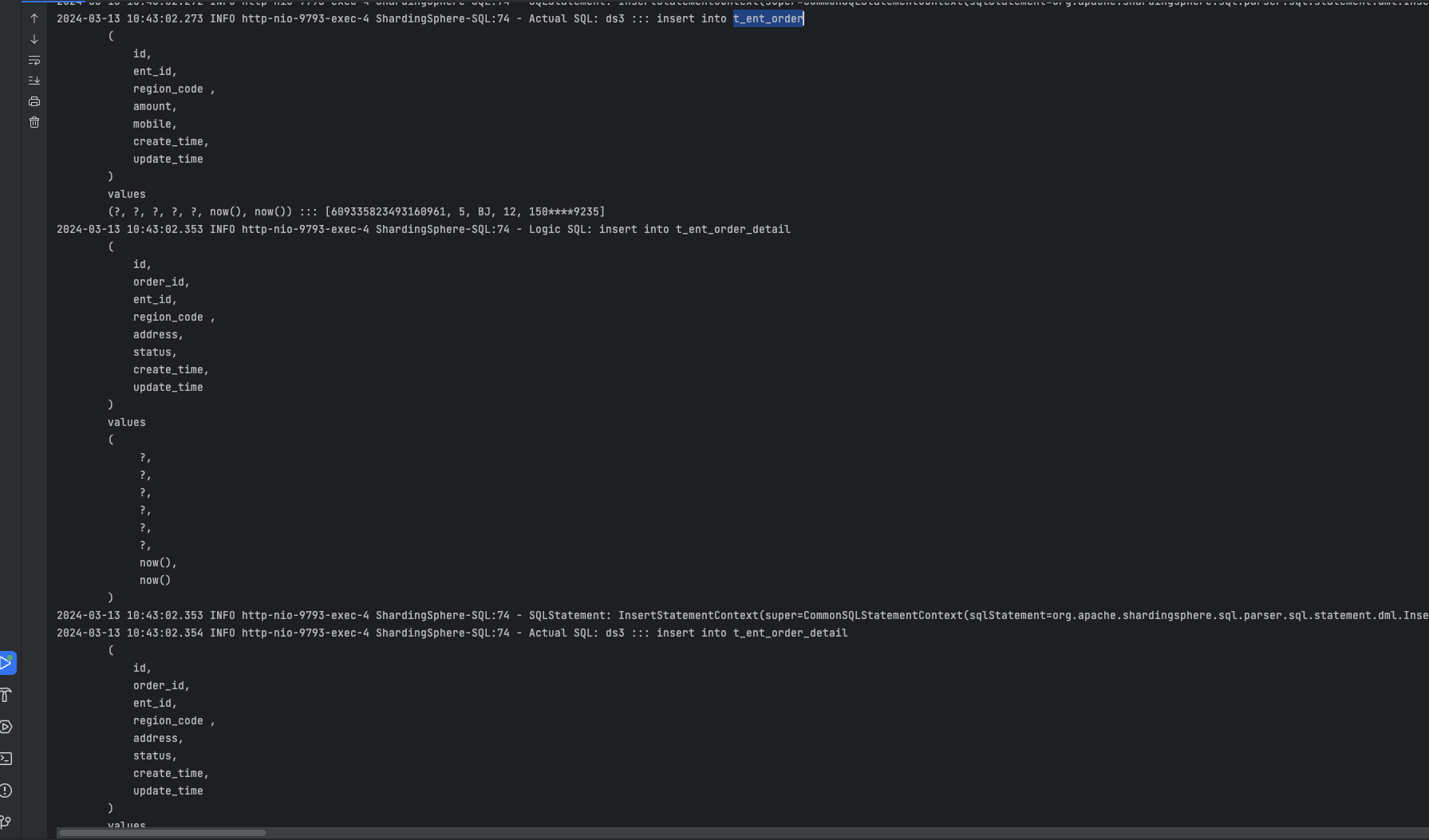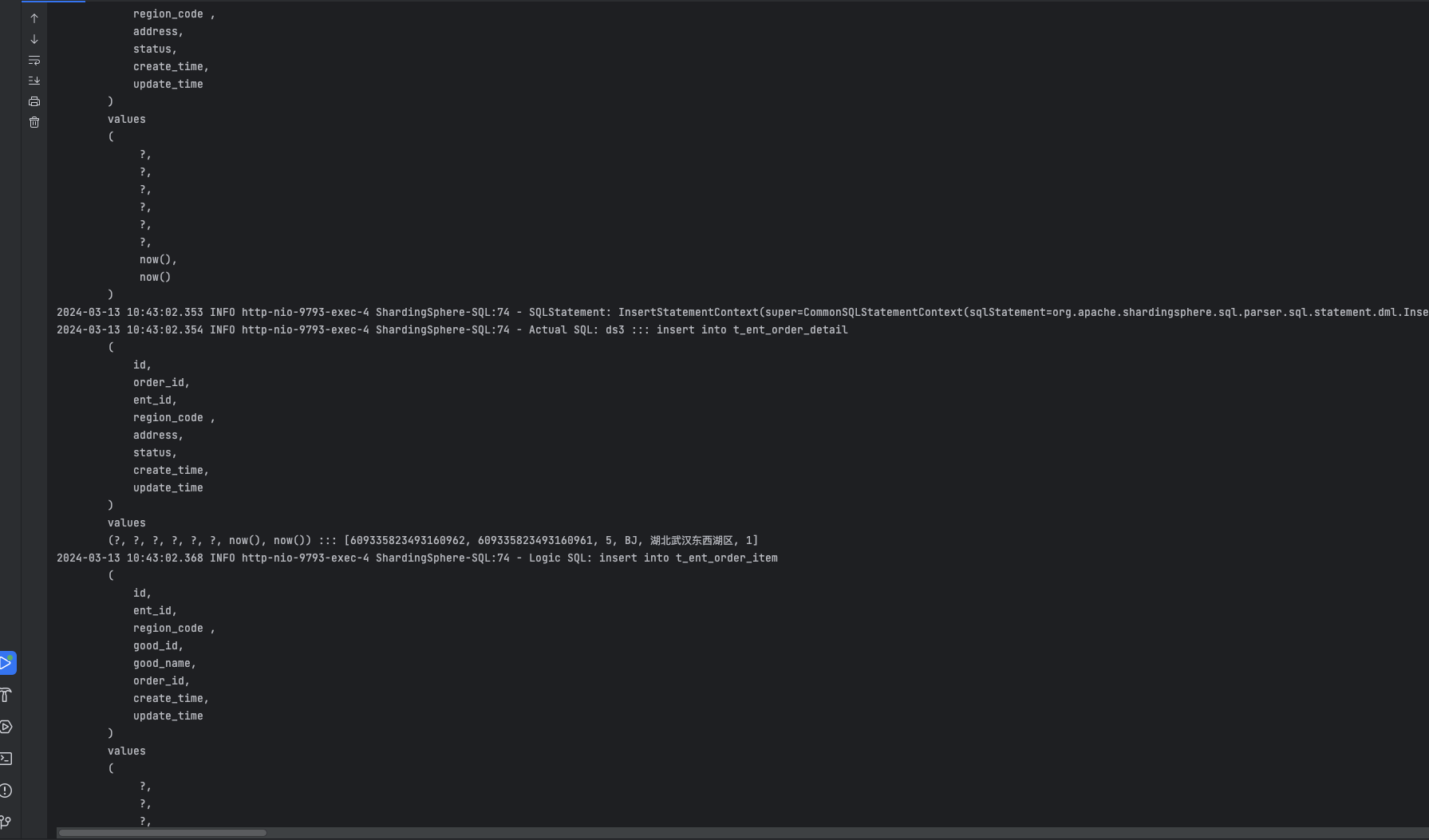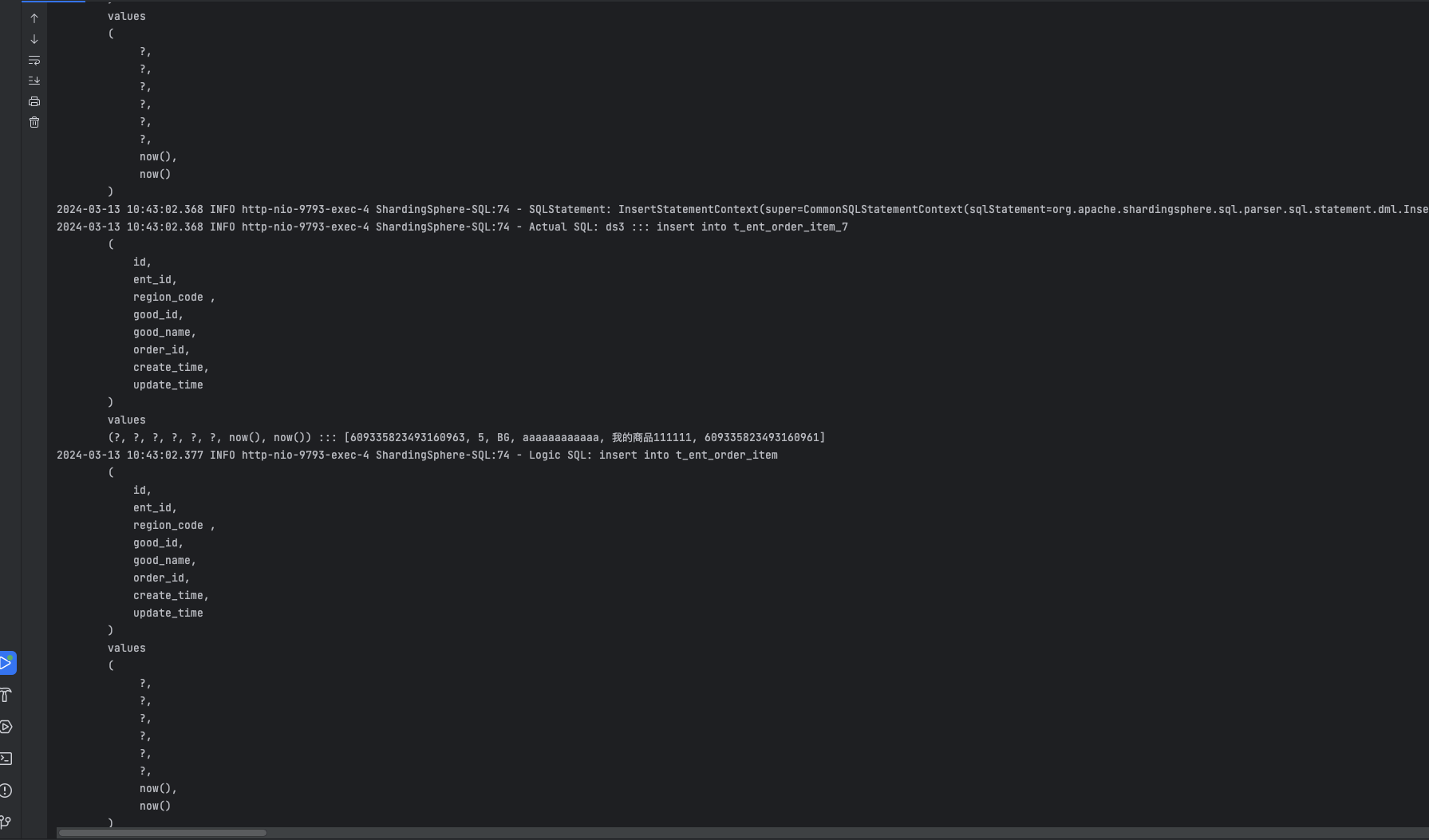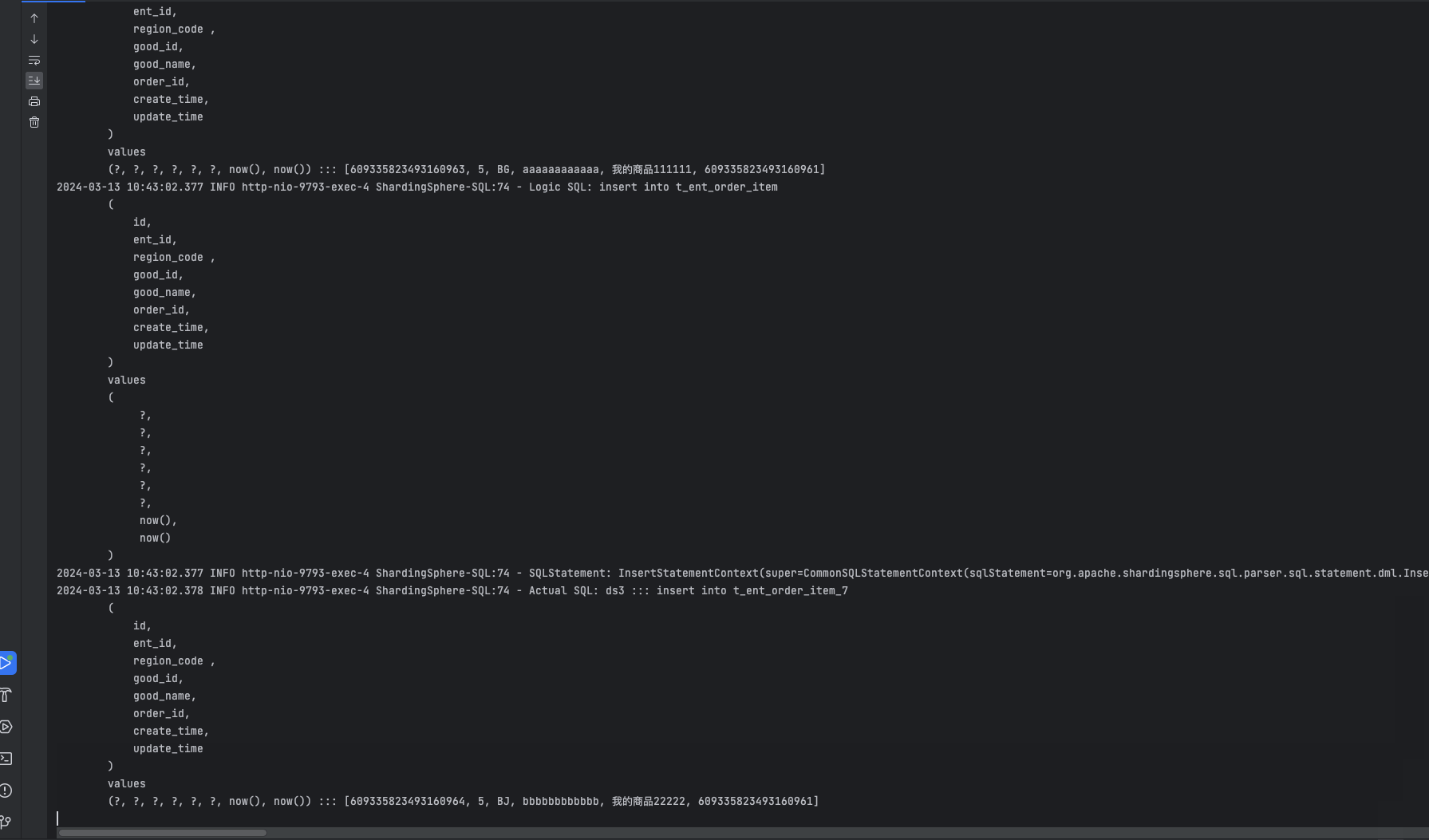
我们插入1 条订单记录、1 条订单详情表进入 ds3 分片,并且 2 条订单条目表进入 ds3 分片的 t_ent_order_item_7 表。
2、测试存储订单
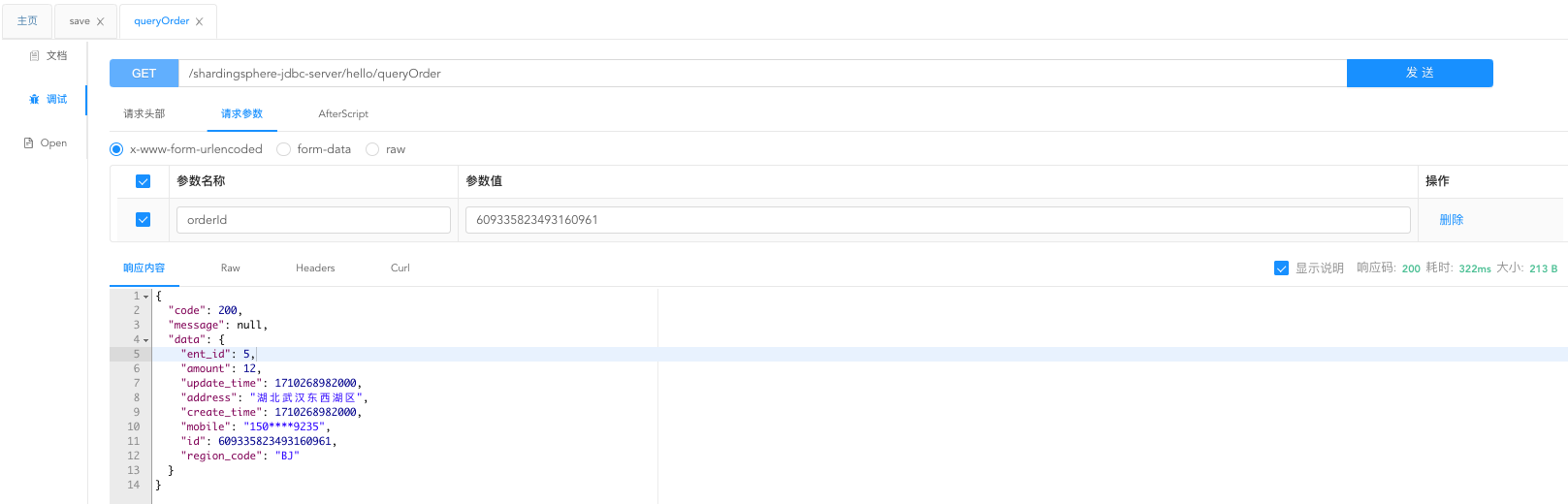
参数名称是 orderId , 参数值:609335823493160961 ,点击发送按钮,接口响应成功 , 返回订单信息。