-
Notifications
You must be signed in to change notification settings - Fork 35
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
fixed pypi, enabled cli usage w/ 0.0.4, changed package name, using p…
…oetry
- Loading branch information
1 parent
4ab7c84
commit ca31ef4
Showing
12 changed files
with
93 additions
and
93 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -4,12 +4,12 @@ | |
| | | | ( | ( | ( | \ \ \ / | __/ | | ||
| _| _| _| \__._| \___| _| \__._| \_/\_/ _| \___| _| | ||
| ---------------------------- | ||
| md_crawler.py by @paulpierre | ||
| ---------------------------- | ||
| --------------------------------- | ||
| markdown_crawler - by @paulpierre | ||
| --------------------------------- | ||
| A multithreaded 🕸️ web crawler that recursively crawls a website and creates a 🔽 markdown file for each page | ||
| https://github.com/paulpierre | ||
| https://x.com/paulpierre | ||
| https://x.com/paulpierre | ||
| ``` | ||
| <br><br> | ||
|
|
||
|
|
@@ -39,23 +39,23 @@ If you wish to simply use it in the CLI, you can run the following command: | |
|
|
||
| Install the package | ||
| ``` | ||
| pip install md_crawler | ||
| pip install markdown-crawler | ||
| ``` | ||
|
|
||
| Execute the CLI | ||
| ``` | ||
| md_crawler -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith | ||
| markdown-crawler -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith | ||
| ``` | ||
|
|
||
| To run from the github repo, once you have it checked out: | ||
| ``` | ||
| pip install -r requirements.txt | ||
| python3 md_crawler.py -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith | ||
| pip install . | ||
| markdown-crawler -t 5 -d 3 -b ./markdown https://en.wikipedia.org/wiki/Morty_Smith | ||
| ``` | ||
|
|
||
| Or use the library in your own code: | ||
| ``` | ||
| from md_crawler import md_crawl | ||
| from markdown_crawler import md_crawl | ||
| url = 'https://en.wikipedia.org/wiki/Morty_Smith' | ||
| md_crawl(url, max_depth=3, num_threads=5, base_path='markdown') | ||
| ``` | ||
|
|
@@ -73,7 +73,7 @@ md_crawl(url, max_depth=3, num_threads=5, base_path='markdown') | |
|
|
||
| The following arguments are supported | ||
| ``` | ||
| usage: md_crawler [-h] [--max-depth MAX_DEPTH] [--num-threads NUM_THREADS] [--base-path BASE_PATH] [--debug DEBUG] | ||
| usage: markdown-crawler [-h] [--max-depth MAX_DEPTH] [--num-threads NUM_THREADS] [--base-path BASE_PATH] [--debug DEBUG] | ||
| [--target-content TARGET_CONTENT] [--target-links TARGET_LINKS] [--valid-paths VALID_PATHS] | ||
| [--domain-match DOMAIN_MATCH] [--base-path-match BASE_PATH_MATCH] | ||
| base-url | ||
|
|
@@ -82,7 +82,7 @@ usage: md_crawler [-h] [--max-depth MAX_DEPTH] [--num-threads NUM_THREADS] [--ba | |
| <br><br> | ||
|
|
||
| # 📝 Example | ||
| Take a look at [example.py](https://github.com/paulpierre/md_crawler/blob/main/example.py) for an example | ||
| Take a look at [example.py](https://github.com/paulpierre/markdown-crawler/blob/main/example.py) for an example | ||
| implementation of the library. In this configuration we set: | ||
| - `max_depth` to 3. We will crawl the base URL and 3 levels of children | ||
| - `num_threads` to 5. We will use 5 parallel(ish) threads to crawl the website | ||
|
|
@@ -95,13 +95,13 @@ implementation of the library. In this configuration we set: | |
|
|
||
| And when we run it we can view the progress | ||
| <br> | ||
| >  | ||
| > 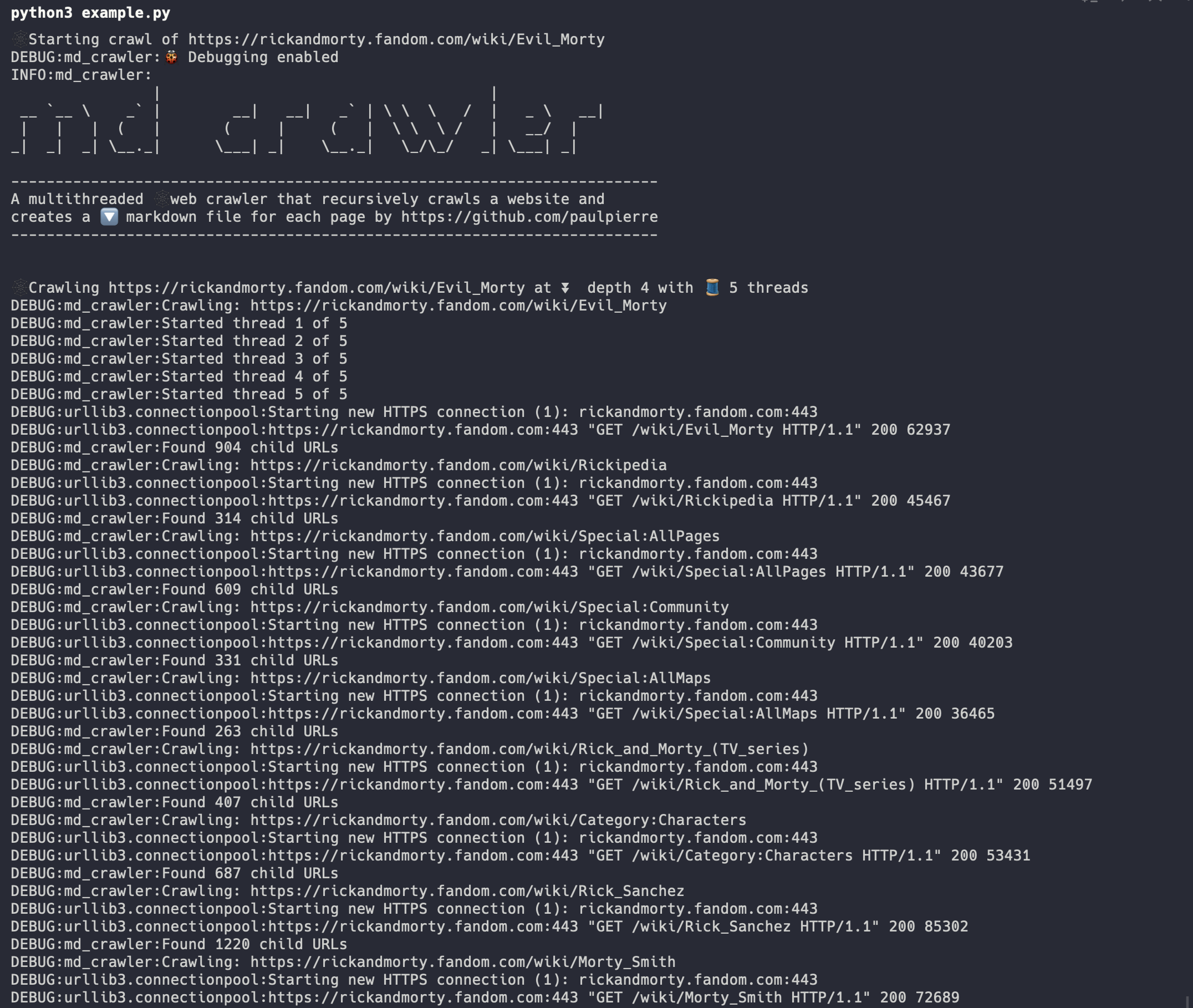 | ||
| We can see the progress of our files in the `markdown` directory locally | ||
| >  | ||
| > 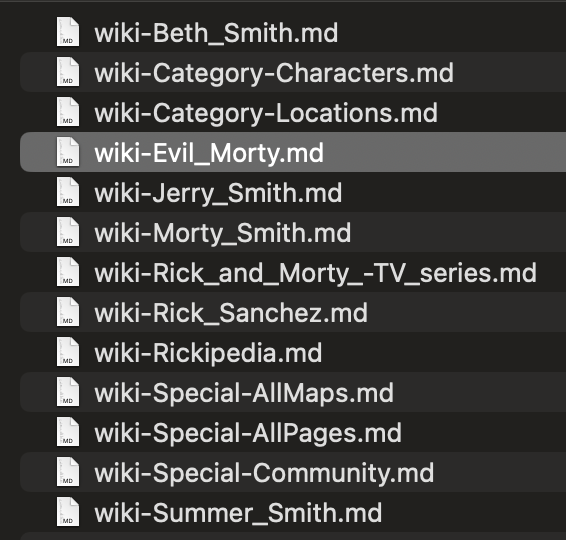 | ||
| And we can see the contents of the HTML converted to markdown | ||
| >  | ||
| > 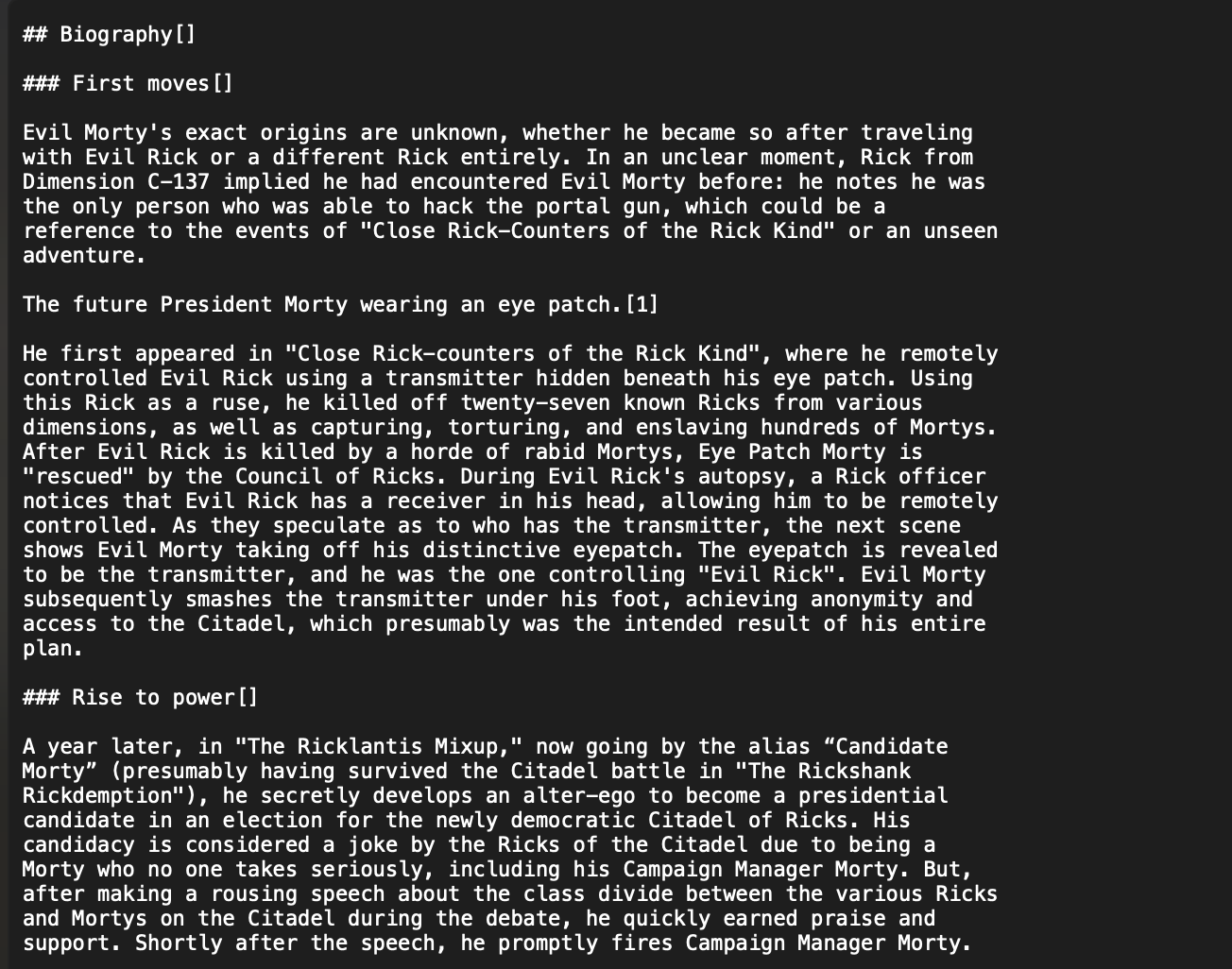 | ||
| <br><br> | ||
| # ❤️ Thanks | ||
|
|
@@ -134,4 +134,4 @@ SOFTWARE. | |
| <br><br> | ||
|
|
||
| ### html2text credits | ||
| `md_crawler` makes use of html2text by the late and legendary [Aaron Swartz]([email protected]). The original source code can be found [here](http://www.aaronsw.com/2002/html2text). A modification was implemented to make it compatible with Python 3.x. It is licensed under GNU General Public License (GPL). | ||
| `markdown_crawler` makes use of html2text by the late and legendary [Aaron Swartz]([email protected]). The original source code can be found [here](http://www.aaronsw.com/2002/html2text). A modification was implemented to make it compatible with Python 3.x. It is licensed under GNU General Public License (GPL). | ||
Binary file not shown.
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,47 @@ | ||
| import argparse | ||
| from markdown_crawler import ( | ||
| md_crawl, | ||
| DEFAULT_TARGET_LINKS, | ||
| BANNER | ||
| ) | ||
|
|
||
| def main(): | ||
| print(BANNER) | ||
| arg_parser = argparse.ArgumentParser() | ||
| arg_parser.add_argument('--max-depth', '-d', required=False, default=3, type=int, help='Max depth of child links to crawl') | ||
| arg_parser.add_argument('--num-threads', '-t', required=False, default=5, type=int, help='Number of threads to use for crawling') | ||
| arg_parser.add_argument('--base-dir', '-b', required=False, default='markdown', type=str, help='Base directory to save markdown files in') | ||
| arg_parser.add_argument('--debug', '-e', required=False, type=bool, default=False, help='Enable debug mode') | ||
| arg_parser.add_argument('--target-content', '-c', required=False, type=str, default=None, help='CSS target path of the content to extract from each page') | ||
| arg_parser.add_argument('--target-links', '-l', required=False, type=str, default=DEFAULT_TARGET_LINKS, help='CSS target path containing the links to crawl') | ||
| arg_parser.add_argument('--valid-paths', '-v', required=False, type=str, default=None, help='Comma separated list of valid relative paths to crawl, (ex. /wiki,/categories,/help') | ||
| arg_parser.add_argument('--domain-match', '-m', required=False, type=bool, default=True, help='Crawl only links that match the base domain') | ||
| arg_parser.add_argument('--base-path-match', '-p', required=False, type=bool, default=True, help='Crawl only links that match the base path of the base_url specified in CLI') | ||
| arg_parser.add_argument('base_url', type=str, help='Base URL to crawl (ex. 🐍🎷 https://rickandmorty.fandom.com/wiki/Evil_Morty') | ||
| if len(arg_parser.parse_args().__dict__.keys()) == 0: | ||
| arg_parser.print_help() | ||
| return | ||
| # ---------------- | ||
| # Parse target arg | ||
| # ---------------- | ||
| args = arg_parser.parse_args() | ||
|
|
||
| md_crawl( | ||
| args.base_url, | ||
| max_depth=args.max_depth, | ||
| num_threads=args.num_threads, | ||
| base_dir=args.base_path, | ||
| target_content=args.target_content.split(',') if args.target_content and ',' in args.target_content else None, | ||
| target_links=args.target_links.split(',') if args.target_links and ',' in args.target_links else [args.target_links], | ||
| valid_paths=args.valid_paths.split(',') if args.valid_paths and ',' in args.valid_paths else None, | ||
| is_domain_match=args.domain_match, | ||
| is_base_path_match=args.base_match, | ||
| is_debug=args.debug | ||
| ) | ||
|
|
||
|
|
||
| # -------------- | ||
| # CLI entrypoint | ||
| # -------------- | ||
| if __name__ == '__main__': | ||
| main() |
File renamed without changes.
Binary file not shown.
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,27 @@ | ||
| [build-system] | ||
| requires = ["setuptools>=61.0"] | ||
| build-backend = "setuptools.build_meta" | ||
|
|
||
|
|
||
| [project] | ||
| name = "markdown-crawler" | ||
| version = "0.0.4" | ||
| authors = [ | ||
| { name="Paul Pierre", email="[email protected]" }, | ||
| ] | ||
| description = "A multithreaded 🕸️ web crawler that recursively crawls a website and creates a 🔽 markdown file for each page" | ||
| readme = "README.md" | ||
| requires-python = ">=3.4" | ||
| classifiers = [ | ||
| "Programming Language :: Python :: 3", | ||
| "License :: OSI Approved :: MIT License", | ||
| "Operating System :: OS Independent", | ||
| ] | ||
|
|
||
| [project.urls] | ||
| "Homepage" = "https://github.com/paulpierre/markdown-crawler" | ||
| "Bug Tracker" = "https://github.com/paulpierre/markdown-crawler/issues" | ||
| "Twitter" = "https://twitter.com/paulpierre" | ||
|
|
||
| [project.scripts] | ||
| markdown-crawler = "markdown_crawler.cli:main" |