


![]()
![]()
How to explain a machine learning model such that the explanation is truthful to the model and yet interpretable to people?
Ramaravind K. Mothilal, Amit Sharma, Chenhao Tan
FAT* '20 paper | Docs | Example Notebooks | Live Jupyter notebook
Blog Post: Explanation for ML using diverse counterfactuals
Case Studies: Towards Data Science (Hotel Bookings) | Analytics Vidhya (Titanic Dataset)
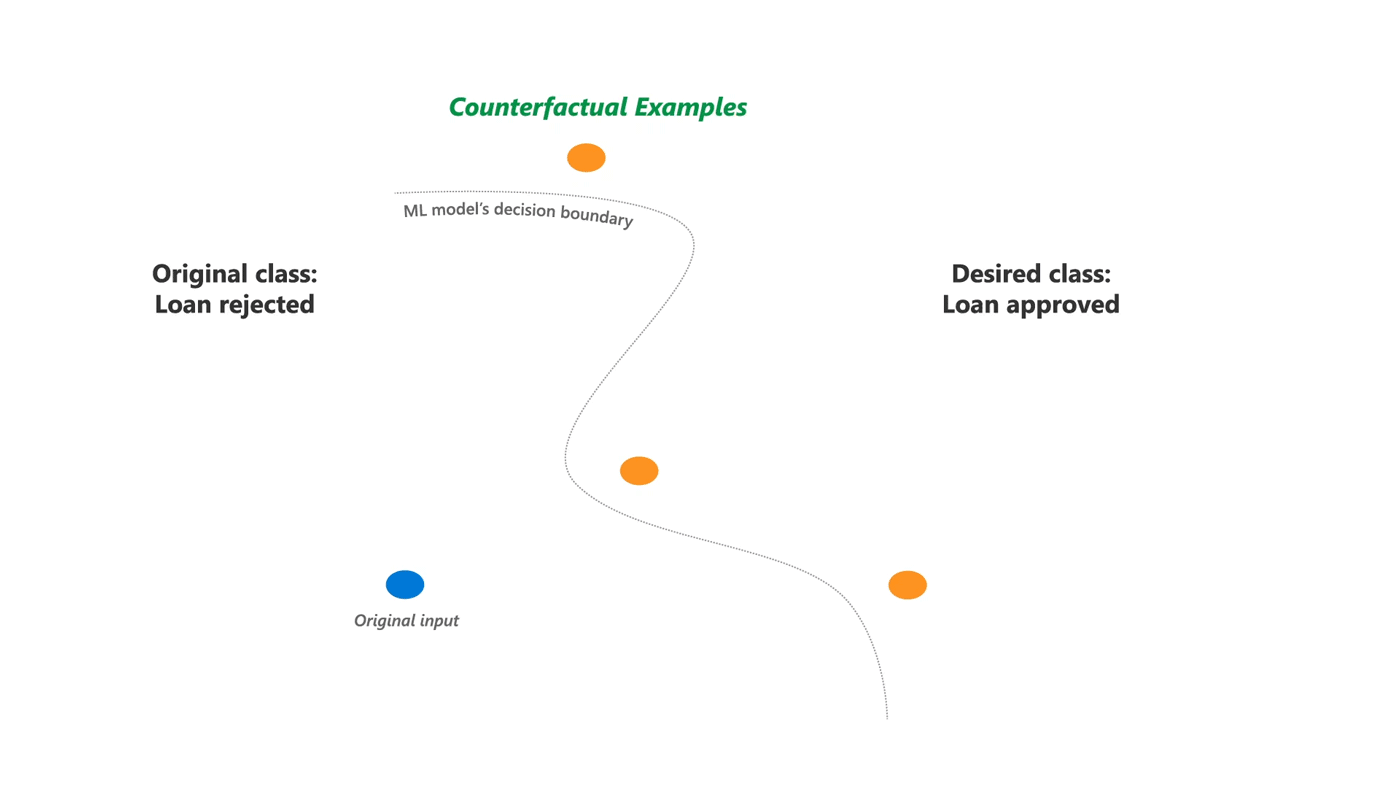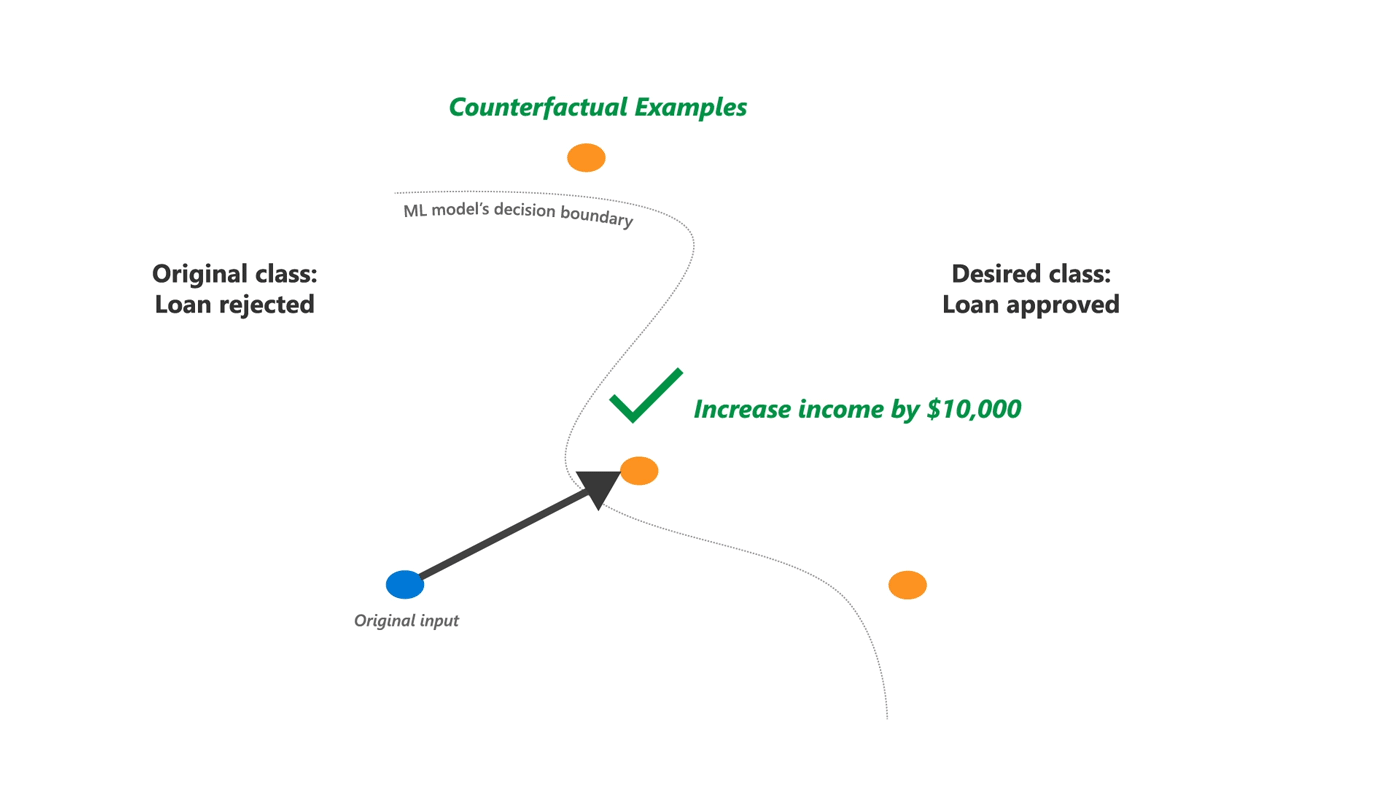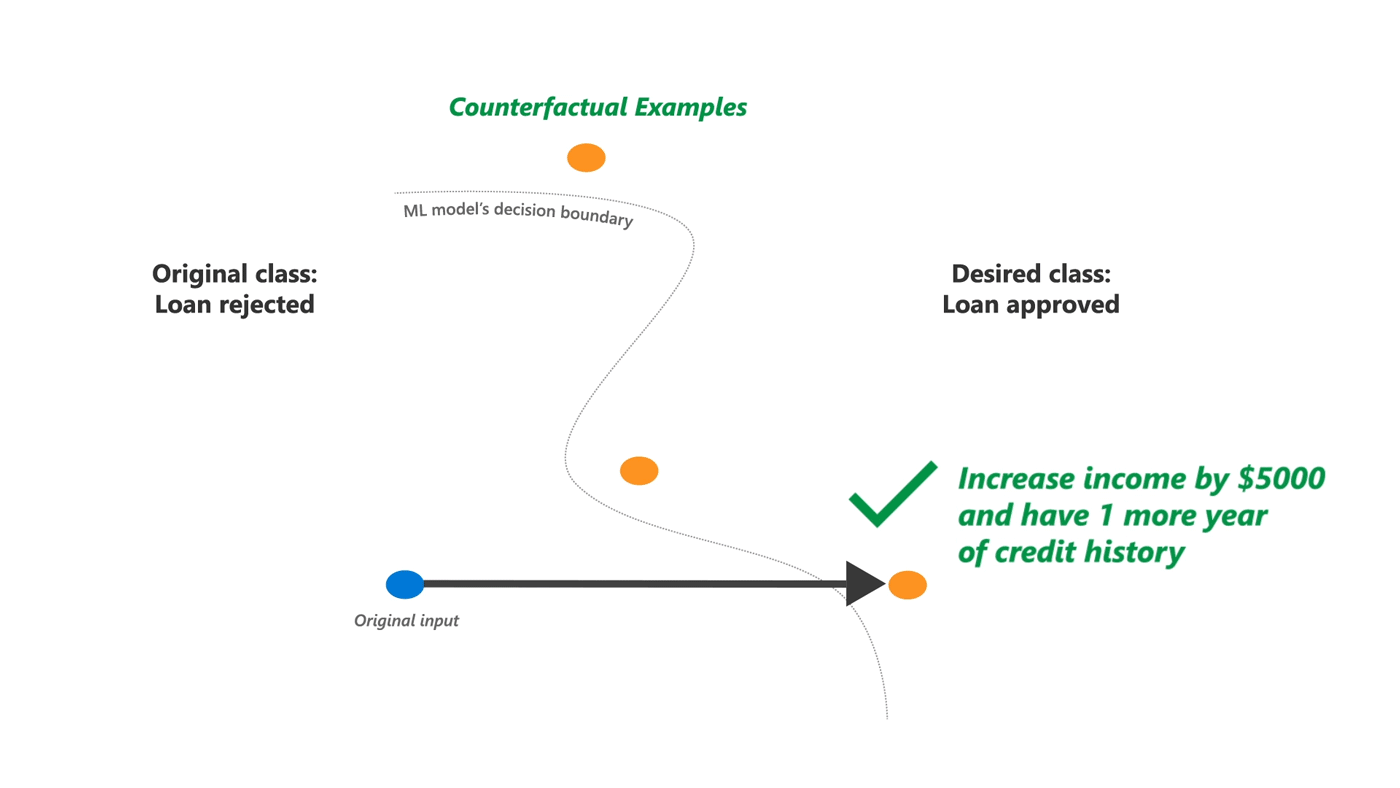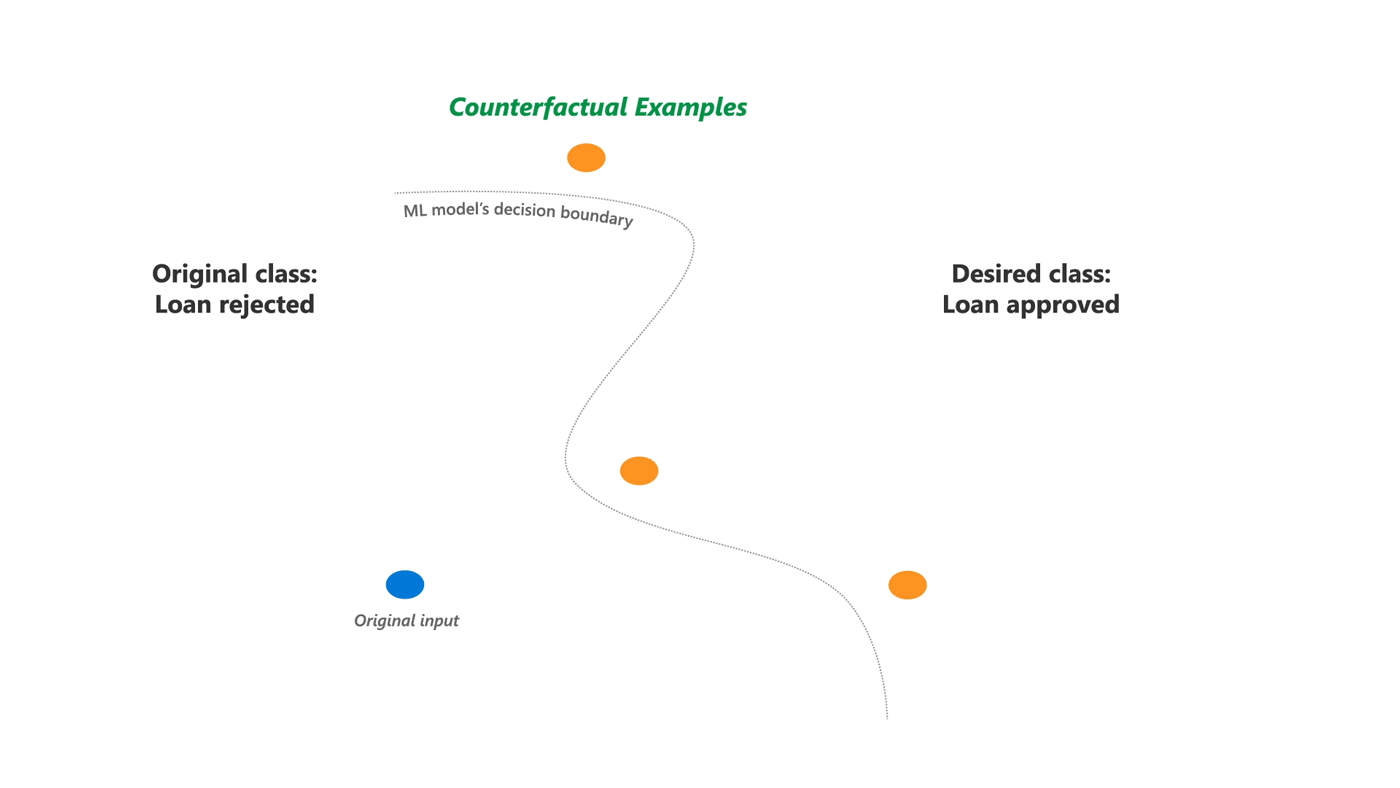
Explanations are critical for machine learning, especially as machine learning-based systems are being used to inform decisions in societally critical domains such as finance, healthcare, education, and criminal justice. However, most explanation methods depend on an approximation of the ML model to create an interpretable explanation. For example, consider a person who applied for a loan and was rejected by the loan distribution algorithm of a financial company. Typically, the company may provide an explanation on why the loan was rejected, for example, due to "poor credit history". However, such an explanation does not help the person decide what they should do next to improve their chances of being approved in the future. Critically, the most important feature may not be enough to flip the decision of the algorithm, and in practice, may not even be changeable such as gender and race.
DiCE implements counterfactual (CF) explanations that provide this information by showing feature-perturbed versions of the same person who would have received the loan, e.g., you would have received the loan if your income was higher by $10,000. In other words, it provides "what-if" explanations for model output and can be a useful complement to other explanation methods, both for end-users and model developers.
Barring simple linear models, however, it is difficult to generate CF examples that work for any machine learning model. DiCE is based on recent research that generates CF explanations for any ML model. The core idea is to setup finding such explanations as an optimization problem, similar to finding adversarial examples. The critical difference is that for explanations, we need perturbations that change the output of a machine learning model, but are also diverse and feasible to change. Therefore, DiCE supports generating a set of counterfactual explanations and has tunable parameters for diversity and proximity of the explanations to the original input. It also supports simple constraints on features to ensure feasibility of the generated counterfactual examples.
DiCE supports Python 3+. The stable version of DiCE is available on PyPI.
pip install dice-mlDiCE is also available on conda-forge.
conda install -c conda-forge dice-mlTo install the latest (dev) version of DiCE and its dependencies, clone this repo and run pip install from the top-most folder of the repo:
pip install -e .If you face any problems, try installing dependencies manually.
pip install -r requirements.txt
# Additional dependendies for deep learning models
pip install -r requirements-deeplearning.txt
# For running unit tests
pip install -r requirements-test.txtWith DiCE, generating explanations is a simple three-step process: set up a dataset, train a model, and then invoke DiCE to generate counterfactual examples for any input. DiCE can also work with pre-trained models, with or without their original training data.
import dice_ml
from dice_ml.utils import helpers # helper functions
from sklearn.model_selection import train_test_split
dataset = helpers.load_adult_income_dataset()
target = dataset["income"] # outcome variable
train_dataset, test_dataset, _, _ = train_test_split(dataset,
target,
test_size=0.2,
random_state=0,
stratify=target)
# Dataset for training an ML model
d = dice_ml.Data(dataframe=train_dataset,
continuous_features=['age', 'hours_per_week'],
outcome_name='income')
# Pre-trained ML model
m = dice_ml.Model(model_path=dice_ml.utils.helpers.get_adult_income_modelpath(),
backend='TF2', func="ohe-min-max")
# DiCE explanation instance
exp = dice_ml.Dice(d,m)For any given input, we can now generate counterfactual explanations. For example, the following input leads to class 0 (low income) and we would like to know what minimal changes would lead to a prediction of 1 (high income).
# Generate counterfactual examples
query_instance = test_dataset.drop(columns="income")[0:1]
dice_exp = exp.generate_counterfactuals(query_instance, total_CFs=4, desired_class="opposite")
# Visualize counterfactual explanation
dice_exp.visualize_as_dataframe()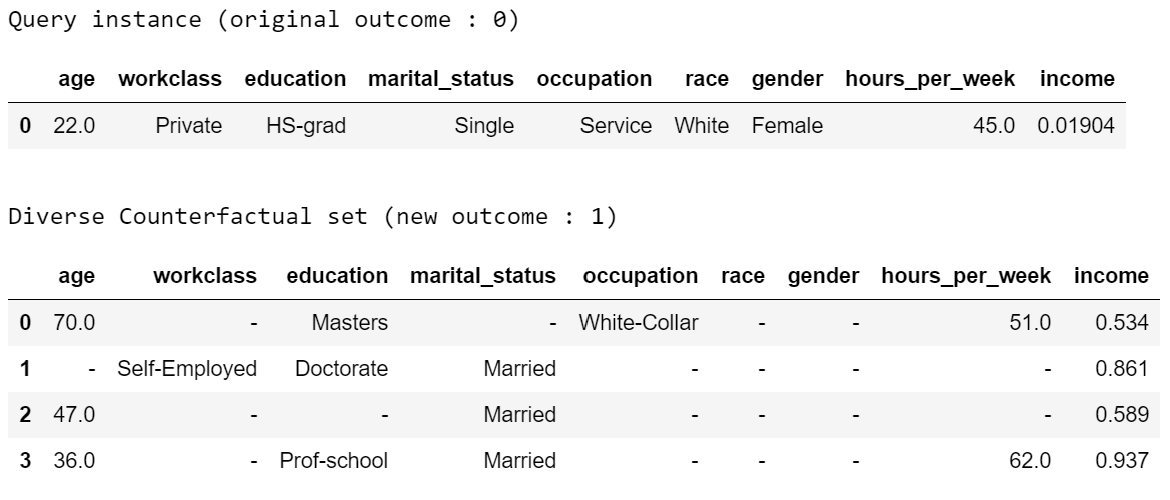
You can save the generated counterfactual examples in the following way.
# Save generated counterfactual examples to disk
dice_exp.cf_examples_list[0].final_cfs_df.to_csv(path_or_buf='counterfactuals.csv', index=False)For more details, check out the docs/source/notebooks folder. Here are some example notebooks:
- Getting Started: Generate CF examples for a sklearn, tensorflow or pytorch binary classifier and compute feature importance scores.
- Explaining Multi-class Classifiers and Regressors: Generate CF explanations for a multi-class classifier or regressor.
- Local and Global Feature Importance: Estimate local and global feature importance scores using generated counterfactuals.
- Providing Constraints on Counterfactual Generation: Specifying which features to vary and their permissible ranges for valid counterfactual examples.
DiCE can generate counterfactual examples using the following methods.
Model-agnostic methods
- Randomized sampling
- KD-Tree (for counterfactuals within the training data)
- Genetic algorithm
See model-agnostic notebook for code examples on using these methods.
Gradient-based methods
- An explicit loss-based method described in Mothilal et al. (2020) (Default for deep learning models).
- A Variational AutoEncoder (VAE)-based method described in Mahajan et al. (2019) (see the BaseVAE notebook).
The last two methods require a differentiable model, such as a neural network. If you are interested in a specific method, do raise an issue here.
Data
DiCE does not need access to the full dataset. It only requires metadata properties for each feature (min, max for continuous features and levels for categorical features). Thus, for sensitive data, the dataset can be provided as:
d = data.Data(features={
'age':[17, 90],
'workclass': ['Government', 'Other/Unknown', 'Private', 'Self-Employed'],
'education': ['Assoc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Prof-school', 'School', 'Some-college'],
'marital_status': ['Divorced', 'Married', 'Separated', 'Single', 'Widowed'],
'occupation':['Blue-Collar', 'Other/Unknown', 'Professional', 'Sales', 'Service', 'White-Collar'],
'race': ['Other', 'White'],
'gender':['Female', 'Male'],
'hours_per_week': [1, 99]},
outcome_name='income')Model
We support pre-trained models as well as training a model. Here's a simple example using Tensorflow.
sess = tf.InteractiveSession()
# Generating train and test data
train, _ = d.split_data(d.normalize_data(d.one_hot_encoded_data))
X_train = train.loc[:, train.columns != 'income']
y_train = train.loc[:, train.columns == 'income']
# Fitting a dense neural network model
ann_model = keras.Sequential()
ann_model.add(keras.layers.Dense(20, input_shape=(X_train.shape[1],), kernel_regularizer=keras.regularizers.l1(0.001), activation=tf.nn.relu))
ann_model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
ann_model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.01), metrics=['accuracy'])
ann_model.fit(X_train, y_train, validation_split=0.20, epochs=100, verbose=0, class_weight={0:1,1:2})
# Generate the DiCE model for explanation
m = model.Model(model=ann_model)Check out the Getting Started notebook to see code examples on using DiCE with sklearn and PyTorch models.
Explanations
We visualize explanations through a table highlighting the change in features. We plan to support an English language explanation too!
We acknowledge that not all counterfactual explanations may be feasible for a user. In general, counterfactuals closer to an individual's profile will be more feasible. Diversity is also important to help an individual choose between multiple possible options.
DiCE provides tunable parameters for diversity and proximity to generate different kinds of explanations.
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
proximity_weight=1.5, diversity_weight=1.0)Additionally, it may be the case that some features are harder to change than others (e.g., education level is harder to change than working hours per week). DiCE allows input of relative difficulty in changing a feature through specifying feature weights. A higher feature weight means that the feature is harder to change than others. For instance, one way is to use the mean absolute deviation from the median as a measure of relative difficulty of changing a continuous feature. By default, DiCE computes this internally and divides the distance between continuous features by the MAD of the feature's values in the training set. We can also assign different values through the feature_weights parameter.
# assigning new weights
feature_weights = {'age': 10, 'hours_per_week': 5}
# Now generating explanations using the new feature weights
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
feature_weights=feature_weights)Finally, some features are impossible to change such as one's age or race. Therefore, DiCE also allows inputting a list of features to vary.
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
features_to_vary=['age','workclass','education','occupation','hours_per_week'])It also supports simple constraints on
features that reflect practical constraints (e.g., working hours per week
should be between 10 and 50 using the permitted_range parameter).
For more details, check out this notebook.
Being truthful to the model, counterfactual explanations can be useful to all stakeholders for a decision made by a machine learning model that makes decisions.
- Decision subjects: Counterfactual explanations can be used to explore actionable recourse for a person based on a decision received by a ML model. DiCE shows decision outcomes with actionable alternative profiles, to help people understand what they could have done to change their model outcome.
- ML model developers: Counterfactual explanations are also useful for model developers to debug their model for potential problems. DiCE can be used to show CF explanations for a selection of inputs that can uncover if there are any problematic (in)dependences on some features (e.g., for 95% of inputs, changing features X and Y change the outcome, but not for the other 5%). We aim to support aggregate metrics to help developers debug ML models.
- Decision makers: Counterfactual explanations may be useful to decision-makers such as doctors or judges who may use ML models to make decisions. For a particular individual, DiCE allows probing the ML model to see the possible changes that lead to a different ML outcome, thus enabling decision-makers to assess their trust in the prediction.
- Decision evaluators: Finally, counterfactual explanations can be useful to decision evaluators who may be interested in fairness or other desirable properties of an ML model. We plan to add support for this in the future.
Ideally, counterfactual explanations should balance between a wide range of suggested changes (diversity), and the relative ease of adopting those changes (proximity to the original input), and also follow the causal laws of the world, e.g., one can hardly lower their educational degree or change their race.
We are working on adding the following features to DiCE:
- Support for using DiCE for debugging machine learning models
- Constructed English phrases (e.g.,
desired outcome if feature was changed) and other ways to output the counterfactual examples - Evaluating feature attribution methods like LIME and SHAP on necessity and sufficiency metrics using counterfactuals (see this paper)
- Support for Bayesian optimization and other algorithms for generating counterfactual explanations
- Better feasibility constraints for counterfactual generation
If you find DiCE useful for your research work, please cite it as follows.
Ramaravind K. Mothilal, Amit Sharma, and Chenhao Tan (2020). Explaining machine learning classifiers through diverse counterfactual explanations. Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency.
Bibtex:
@inproceedings{mothilal2020dice,
title={Explaining machine learning classifiers through diverse counterfactual explanations},
author={Mothilal, Ramaravind K and Sharma, Amit and Tan, Chenhao},
booktitle={Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency},
pages={607--617},
year={2020}
}
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.microsoft.com.
When you submit a pull request, a CLA-bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., label, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.