This code is the official implementation of the following works (train + eval):
-
Shafin Rahman, Salman Khan, and Nick Barnes. "Polarity Loss for Zero-shot Object Detection." arXiv preprint arXiv:1811.08982 (2020). (Project Page)
-
Shafin Rahman, Salman Khan, and Nick Barnes. "Improved Visual-Semantic Alignment for Zero-Shot Object Detection," 34th AAAI Conference on Artificial Intelligence, (AAAI), New York, US, 2020.
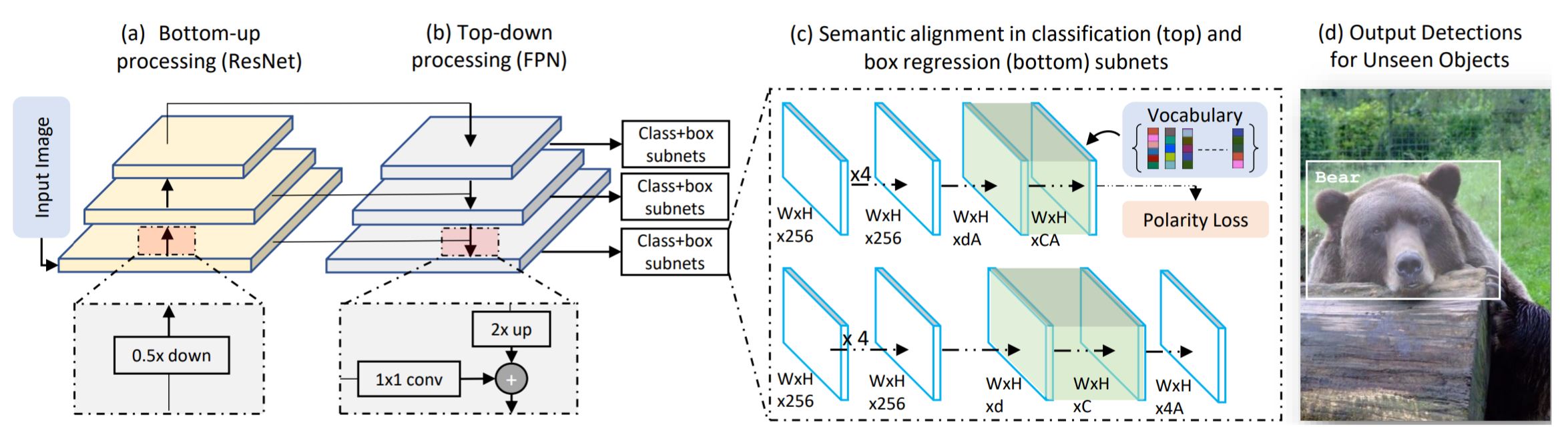
- Other requirements:
- Python 2.7 (or 3.6)
- Keras 2.1.4
- OpenCV 3.3.0
- Tensorflow 1.3.0
- We have provided
.yamlfiles in theConfig/directory to seamlessly set-up conda enviornemnt with all the required dependencies. Simply runconda env create --file=environment_keras_pyZZ.yamland replaceZZwith27or36depending on the python version.
sample_input.txt: a sample input file containing test image pathsgzsd.py: to perform generalized zero-shot detection task using sample_input.txtkeras_retinanet: directory containing the supporting code of the model. This directory is a modified version from original RetinaNet implementation [1] (Link)bin/train_vocab_w2v.py: use this file to train the PL-ZSD network on MSCOCO datasetbin/evaluate.py: use this file to evaluate the trained PL-ZSD network on MSCOCO dataset
Dataset: directory containing sample input and output images. For training, you will have to place train and val datasets in this directory.Config: directory containing configuration files to set up conda environment.Model: directory containing a pre-trained model using the polarity lossresnet5-_polar_loss.h5, used in thegzsd.pydemo code. If you want to train the model, you will need to place a version of retina-net trained with wordvectorsresnet50_csv_50_focal_seen_w2v.h5in this directory to initiate the training process.MSCOCO: This directory contains the source of data, proposed 65/15- seen/unseen split and experimental protocol used in experiments.cls_names_seen_coco.csv: list of 65 MSCOCO seen classes. Each line contains a class name followed by an index.cls_names_test_coco.csv: list of 80 MSCOCO object classes. Each line contains a class name followed by an index. Index 0 to 64 are from seen objects, and index 65 to 79 are from unseen.train_coco_seen_all.zip: it is a zip version of csv filetrain_coco_seen_all.csvcontaining training image paths and annotations used in the paper. Each line contains a training image path, a bounding box co-ordinate and the ground-truth class name of that bounding box. For example, Filepath,x1,y1,x2,y2,class_namevalidation_coco_seen_all.csv: test images with annotations for traditional object detection on only seen objects. File format, Filepath,x1,y1,x2,y2,class_namevalidation_coco_unseen_all.csv: test images with annotations for zero-shot object detection on only unseen objects. File format, Filepath,x1,y1,x2,y2,class_namevalidation_coco_unseen_seen_all_gzsd.csv: test images with annotations for generalized zero-shot object detection on both seen and unseen objects together. File format, Filepath,x1,y1,x2,y2,class_nameword_w2v.txt,word_glo.txt, andword_ftx.txt: word2vec, GloVe and FastText word vectors for 80 classes of MSCOCO. The ith column represents the 300-dimensional word vectors of the class name of the ith row ofcls_names_test_coco.csvvocabulary_list: The list of vocabulary atoms from NUS-WIDE tag dataset [2] used in the paper.vocabulary_w2v.txt,vocabulary_glo.txt, andvocabulary_ftx.txt: word2vec, GloVe and FastText word vectors of all vocabulary tags. The ith column represents the 300-dimensional word vectors of the class name of the ith row ofvocabulary_list.txt
- Running Demo Code: To run generalized zero-shot detection on sample input kept in
Dataset/Sampleinput, simply rungzsd.pyafter installing all dependencies like Keras, Tensorflow, OpenCV or alternatively use the.yamlfile (see above underRequirements) to create a new environment with all dependencies. Place the pre-trained model available from (Link to pre-trained model for demo (h5 format)) in theModeldirectory. This code will generate the output files for each input image toDataset/Sampleoutput. - Running Train/Test Code on MSCOCO: Extract the dataset
train2014.zipandval2014.zipinside the folder Dataset. These files are downloadable from Link. Make sure the pre-trained model is present inside the Model folder ('Model/resnet50_csv_50_focal_seen_w2v.h5'). This pre-trained model is trained by focal loss on 65 seen classes without considering any vocabulary metric. This model is available to download from (Link to pre-trained model for training (h5 format)). Also, make sure thesnapshotsfolder is already created to store intermediate models of each epoch. Then, run the following commands for training and testing.
- Training:
python keras_retinanet/bin/train_vocab_w2v.py --snapshot-path ./snapshots csv MSCOCO/train_coco_seen_all.csv MSCOCO/cls_names_seen_coco.csv - Testing GZSD:
python keras_retinanet/bin/evaluate.py csv MSCOCO/validation_coco_unseen_seen_all_gzsd.csv MSCOCO/cls_names_test_coco.csv snapshots/resnet50_csv_30.h5
The resources required to reproduce results are kept in the directory MSCOCO. For training and testing, we used MSCOCO-2014 train images from train2014.zip and validation images from val2014.zip. These zipped archives are downloadable from MSCOCO website (Link). Please find the exact list of images (with annotations) used for "training" in MSCOCO/train_coco_seen_all.csv. The lists of images used for "testing" different ZSL settings are:
- For traditional detection task:
MSCOCO/validation_coco_seen_all.csv, - For zero-shot detection task:
MSCOCO/validation_coco_unseen_all.csv, and - For generalized zero-shot detection task:
MSCOCO/validation_coco_unseen_seen_all_gzsd.csv.
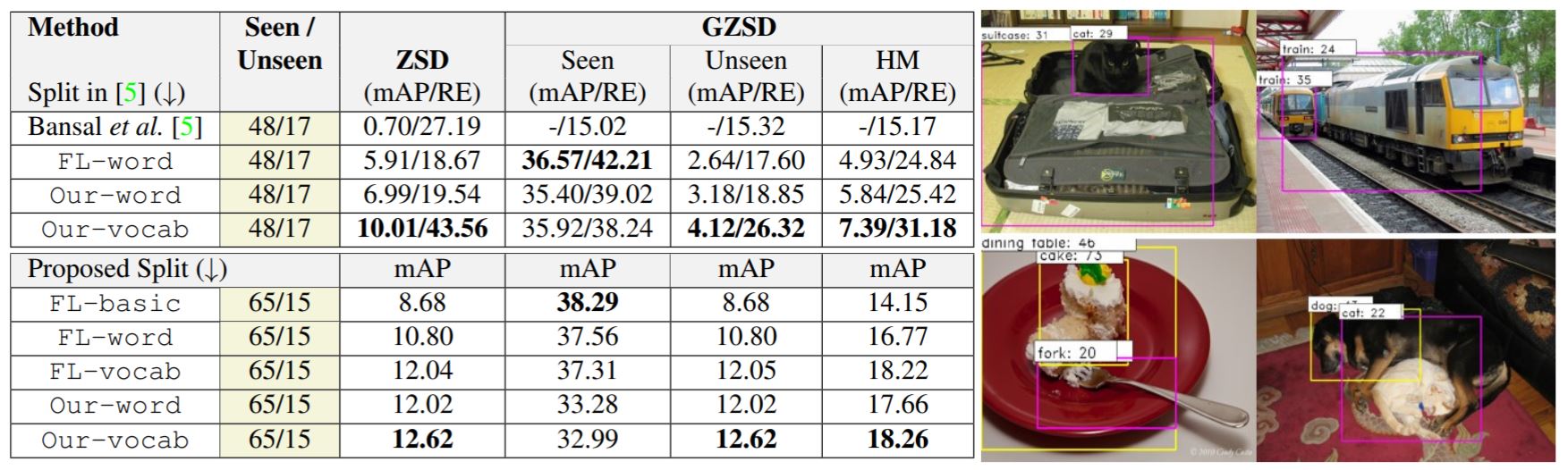

The number of images used to evaluate seen classes is not mentioned in the paper. We have used 4836 images from test+val set of 2007, where no unseen image appeared. Thus, the seen performances are the traditional detection performance of the final model. It is not generalized ZSD. To get exact images used for seen detection, please find VOC/testval_voc07_seen.csv at the following link.
We run the PL-ZSD model on two example videos from the Youtube-8M dataset from Google AI. The demo videos contain several seen (e.g., pottend plant, person, hand-bag) and unseen classes (cat, train, suitcase). Note that we do not apply any pre/post processing procedure across temporal domain to smooth out the predictions.
| Link to Video 1 | Link to Video 2 |
|---|---|
 |
 |
The above results are for Generalized Zero-shot detection setting. The seen/unseen objects are enclosed in yellow/red bounding boxes.
[1] Lin, Tsung-Yi, Priyal Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. "Focal loss for dense object detection." IEEE transactions on pattern analysis and machine intelligence, 2018.
[2] Chua, Tat-Seng, et al. "NUS-WIDE: a real-world web image database from National University of Singapore." Proceedings of the ACM international conference on image and video retrieval. ACM, 2009.
If you use this code, model and dataset splits for your research, please consider citing:
@article{rahman2020polarity,
title={Polarity Loss for Zero-shot Object Detection},
author={Rahman, Shafin and Khan, Salman and Barnes, Nick},
journal={arXiv preprint arXiv:1811.08982},
year={2020}}
@article{rahman2020improved,
title={Improved Visual-Semantic Alignment for Zero-Shot Object Detection},
author={Rahman, Shafin and Khan, Salman and Barnes, Nick},
journal={34th AAAI Conference on Artificial Intelligence},
publisher = {AAAI},
year={2020}}
We thank the authors and contributors of original RetinaNet implementation. We also thank Akshita Gupta her refinements.