スピーカーやヘッドフォンから出力される話し声のオフライン文字起こしです。 文字起こしされた結果はターミナルに表示されます。 音声認識にはVOSKを用いています。
VOICEVOXから出力された音を文字起こししました。
*480p以上でないと、文字起こしされた結果が見えにくいかもしれません。
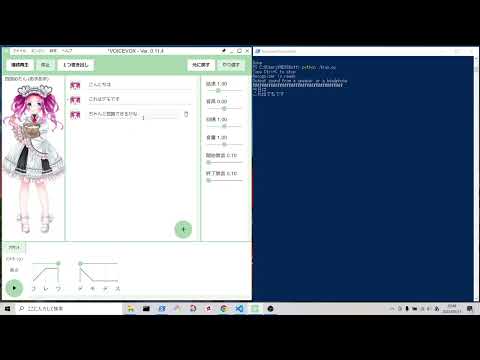
Windows10とUbuntu18.04上での動作を確認しています。 macOSは手元に環境がないため、動作を確認できていません。
- copy
- json
- typing
- multiprocessing
- numpy
- soundcard
- sounddevice
- vosk
python run.pyQiitaの方で紹介しました。