LLM Annotations
With factgenie, you can query LLMs to annotate spans in the generated outputs:

The LLMs need to run externally: factgenie will query them through an API.
Caution
Use only the most capable models for satisfactory results. Smaller and less capable models may often fail to generate outputs in a valid format, return empty outputs, invalid annotations etc.
Currently, factgenie supports the following APIs:
- proprietary:
- self-hosted:
💡 In principle, factgenie can operate with any API as long as the response is in JSON format: see factgenie/metrics.py. If you wish to contribute here, please see the Contributing guidelines.
You can easily set up a new LLM eval (i.e., a campaign using LLMs for annotations) through the web interface:
- Go to
/llm_evaland click on New LLM campaign. - Insert a unique campaign ID .
- Configure the LLM evaluator.
- Select the datasets and splits you want to annotate.
Let us now look into the steps 3 and 4 in more details.
The fields you need to configure are the following:
-
Annotation categories: Names, colors, and descriptions of the categories you want to annotate.
- The colors will be later used for the highlights in the web interface.
- You need to specify the details about the categories in the prompt (see below).
- Prompt template: The prompt for the model.
Important
See below for the instructions for setting up the prompt.
-
System message: The text describing the role of the model.
-
LLM evaluator: The LLM evaluator you will be calling through an API,
-
API URL: For Ollama API, this is the API URL, e.g.
http://my-server.com:11434/api/generate. The parameter is ignored for OpenAI API. -
Model: The identifier of the model you are querying.
-
Model arguments: Additional arguments for the model API, e.g.,
temperature,top-k,seed, etc. -
Extra arguments: Additional arguments for the metric class.
The pre-defined YAML configurations for LLM campaigns are stored in factgenie/config/llm-eval. If you wish, you can also edit these files manually. You can also save the configuration in a YAML file through the web interface.
After creating the campaign, all the configuration parameters will be saved in the file factgenie/campaigns/<llm-eval-id>/metadata.json (and also alongside each generated example).
It is important to set up the prompt for the model correctly so that you get accurate results from the LLM evaluator.
To help you with that, you can use the following two buttons:
- ✨ Pre-fill prompt template
- This button will insert a basic prompt template with your custom error categories into the prompt template textbox.
- You can then modify the prompt template in the textbox.
- You can also modify the basic template itself in
factgenie/config/default_prompts.yml.
- 📝 Add example to template
- This button will open a wizard for adding an example of error annotation.
- Follow the instructions in the wizard for adding an example.
- The example will be appended to the existing prompt template.
- It is highly recommended to add at least one example to the prompt.
If you decide to write the prompt manually, follow carefully the following instructions.
For including the input data and the generated output in the prompt, use the placeholders:
-
{data}for inserting the raw representation of the input data, -
{text}for inserting the output text.
The placeholders will be replaced with the actual values for each example.
Factgenie also needs to parse the model response. Even though our example API calls should return a valid JSON, you still need to prompt the model to produce JSON outputs in a specific format:
{
"annotations": [
{
"text": [TEXT_SPAN],
"type": [ANNOTATION_SPAN_CATEGORY]
},
...
]
}
where:
-
TEXT_SPANis the actual text snippet from the output. -
ANNOTATION_SPAN_CATEGORYis a number from the list of annotation categories.
💡 Optionally, you can also ask the model for the field reason (or note, which is equivalent), which is a string containing a reasoning trace about the annotation. The content of this field will be visible on hover in the web interface.
For instructing the model about the annotation categories, you can include a variant of the following snippet in the prompt (customized to your needs):
The value of "type" is one of {0, 1, 2, 3} based on the following list:
- 0: Incorrect fact: The fact in the text contradicts the data.
- 1: Not checkable: The fact in the text cannot be checked in the data.
- 2: Misleading: The fact in the text is misleading in the given context.
- 3: Other: The text is problematic for another reason, e.g. grammatically or stylistically incorrect, irrelevant, or repetitive.
Note that we do not ask for indices since the model cannot reliably index the output text. Instead, we perform forward string matching:
- If we match the string in the output, we shift the initial position for matching the next string to the next character after the currently matched string.
- If we do not match the string in the output, we ignore the annotation.
Caution
You should ask the model to order the annotations sequentially for this algorithm to work properly.
In the next step, you can select the datasets and splits you want to annotate.
Note that for make the selection process easier, we always select a cartesian product of the selected datasets, splits, and model outputs (existing combinations only).
You can then filter the selected combinations in the box below.
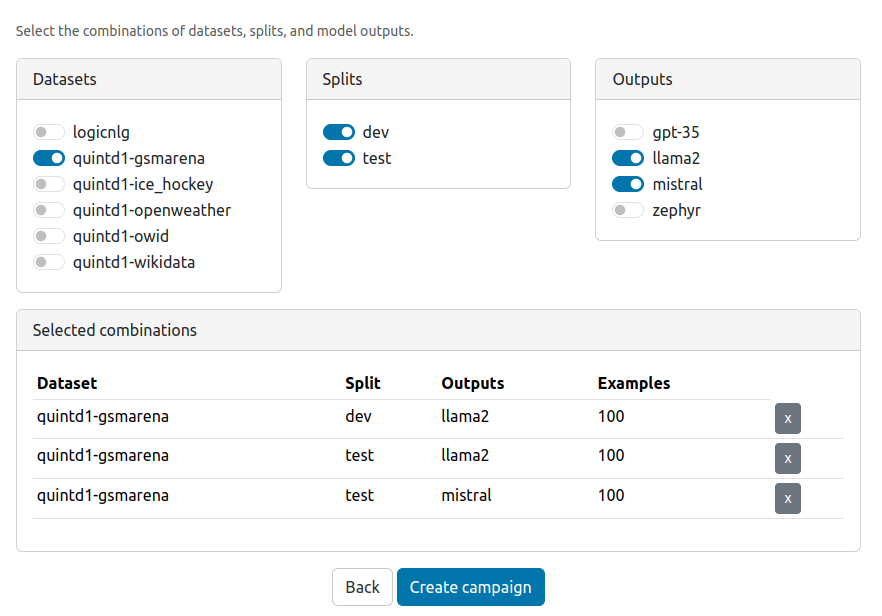
After the campaign is created, the selected examples will be listed in factgenie/annotations/<llm-eval-id>/db.csv. You can edit this file before starting the campaign if you wish to customize the data selection, e.g. down to specific examples.
After the LLM evaluation campaign is created, it will appear in the list on the /llm_eval page:

Now you need to run the evaluation by clicking the "play" button. The annotated examples will be marked as finished:
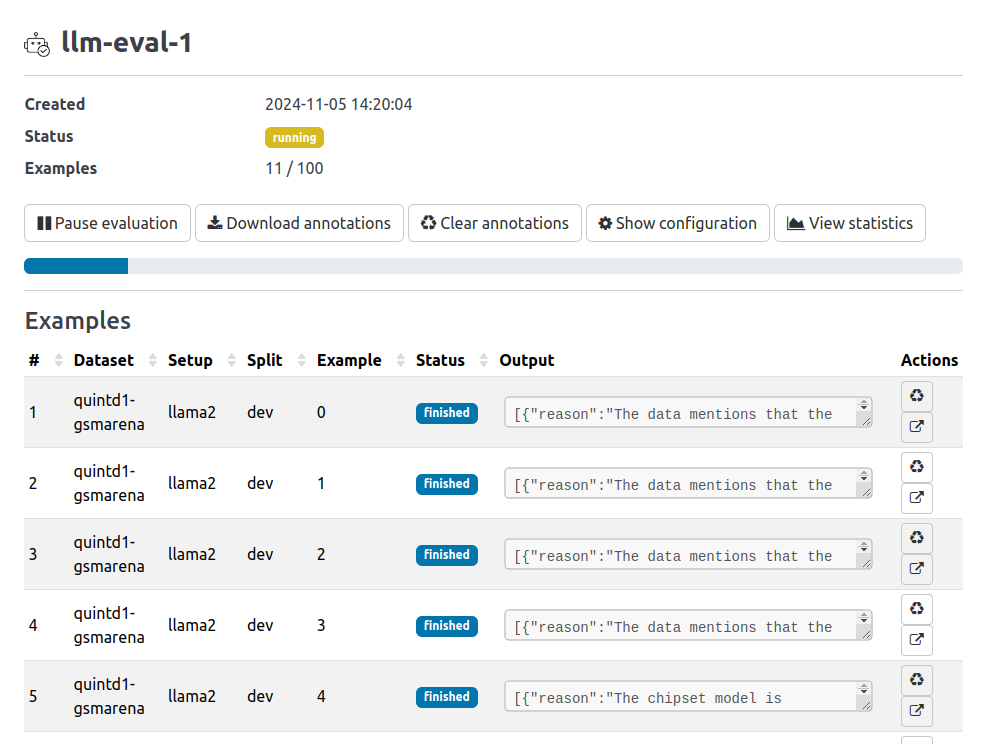
You can view the annotations from the model as soon as they are received.
Alternatively, you can run an evaluation campaign from the command line, see the page on command line interface.